近红外光谱结合化学计量学研究芝麻油的真伪与掺伪
2014-01-09武彦文李冰宁刘玲玲欧阳杰
杨 佳 武彦文 李冰宁 刘玲玲 欧阳杰
近红外光谱结合化学计量学研究芝麻油的真伪与掺伪
杨 佳1,2武彦文2李冰宁2刘玲玲1欧阳杰1
(北京林业大学生物科学与技术学院食品科学与工程系林业食品加工与安全北京市重点实验室1,北京 100083)
(北京市理化分析测试中心北京市食品安全分析测试工程技术研究中心2,北京 100089)
应用傅里叶变换近红外光谱(FTNIR)结合化学计量学分别建立了芝麻油的真伪鉴别与掺伪定量的快速分析方法。真伪鉴别分别采用FTNIR结合主成分分析-簇类软独立模式识别(PCA-SIMCA)和偏最小二乘法-人工神经网络(PLS-ANN),建立了芝麻油、大豆油、花生油、葵花籽油的分类模型。经过验证,两种分类模型的准确识别率均达到了100%。芝麻油中掺伪油的定量分析采用FTNIR结合PLS。通过采集不同比例的芝麻油-大豆油与芝麻油-葵花籽油二元系统的FTNIR谱图,应用PLS分别建立二元系统定量分析模型并通过验证集检验其可靠性,研究结果表明该模型可以准确预测芝麻油中10%~100%的掺假油,其预测值与实际值的相对标准偏差(SEP)分别为1.027(大豆油)和0.9660(葵花籽油)。
芝麻油 真伪鉴别 掺伪分析 近红外光谱 化学计量学
芝麻油香味浓郁,营养丰富,深受我国居民青睐。然而,近年来市场上出现芝麻油掺入大豆油、葵花油等低价植物油,甚至用芝麻香精与低价植物油勾兑成假冒芝麻油的现象[1]。为了维护广大消费者与合法商家的利益,尽快开发快速、准确的芝麻油真伪和掺伪分析方法非常必要。目前,分析芝麻油掺伪的方法主要有化学显色法、紫外-可见分光光度法(UV-Vis)、傅里叶变化红外光谱法(FTIR)、色谱法等等。化学显色与UV-Vis类似,都是利用芝麻油中特征成分与显色剂反应呈色进行定性定量分析[2],该方法操作简单,适于快速检测,但灵敏度较差,不能准确测定芝麻油的掺伪量。色谱法包括气相色谱(GC)分析芝麻油的脂肪酸组分含量[3],以及高效液相色谱(HPLC)测定芝麻油中芝麻素等木质素类化合物的含量[4]等。由于掺伪芝麻油的脂肪酸组成与纯芝麻油比较接近,芝麻油中芝麻素等成分的含量较低(μg/g),使得色谱法的分析难度较大,对分析条件和分析人员的要求也比较高。
近年来,随着FTIR的不断发展,FTIR在食用油脂定性鉴别与定量分析领域的应用越来越多[5-7]。针对芝麻油的掺伪分析,周志琴等应用近红外(FTNIR)结合温度微扰的二维相关光谱建立了大豆油、芝麻油、花生油等6种食用油的快速鉴别方法[8];范璐等[9]利用食用油脂的红外特征峰 1 746、2 855、1 099、1 119 cm-1的比值建立了花生油、大豆油和芝麻油的鉴别方法;梁丹[10]应用 NIR与主成分分析(Principal Component Analysis,PCA)结合 BP人工神经网络法(Artificial Neural Networks,ANN)建立芝麻油真伪的判别方法。这3种方法仅对食用油种类做出快速判定。在此基础上,冯利辉等[11]采用FTNIR结合偏最小二乘法(Partial Least Square,PLS)建立了芝麻油中菜籽油掺伪量的测定方法,该方法可以对10%的菜籽油准确定量。本试验提出将芝麻油定性鉴别与定量测定相结合,即利用FTNIR分别结合簇类软独立模式(Soft Independent Modeling of Class A-nalogy,SIMCA)、ANN和PLS建立芝麻油真伪判别与掺伪量的快速分析方法。
1 材料与方法
1.1 样品来源与制备
芝麻油(36种)、大豆油(30种)、葵花籽油(22种)和花生油(16种)纯品均由北京市粮油检定所提供。分别配制芝麻油中掺入不同大豆油或葵花籽油比例的二元掺伪油,其中大豆油或葵花籽油的质量分数分别为3%~100%(体积分数)共102个(分别51种)。
1.2 仪器设备与参数设置
Spectrum 400型傅里叶变换红外光谱仪:美国Perkin Elmer公司;DTGS检测器,光谱范围为10 000~4 000 cm-1,分辨率8 cm-1,扫描信号累加次数为64次,扫描时扣除了水和二氧化碳的干扰。
1.3 试验过程与数据处理
1.3.1 红外光谱分析
红外光谱获得:取样品约1 mL置于光程为1 mm石英比色皿中,透射法扫描获得FTIR谱图,每个样品至少扫描3次。数据处理包括建立定性分类和定量分析。
1.3.2 定性分析
定性分类是指对芝麻油与非芝麻油的分类识别。分别采用了PCA-SIMCA和PLS-ANN 2种方法建立分类模型。PCA-SIMCA模型采用Spectrum与Quant+软件分析建立。首先通过PCA分析样本的光谱数据矩阵,提取特征变量,在此基础上,分别选取芝麻油(28个)和大豆油(20个)、葵花籽油(16个)和花生油(14个)组成训练集,建立PCA分类方法;然后,应用SIMCA对上述训练集谱图进行分类识别,建立芝麻油的FTNIR-SIMCA的分类鉴别模型;最后通过验证集(其余的8个芝麻油、10个大豆油、6个葵花籽油和2个花生油)依据正确识别率验证该模型的可信度。
PLS-ANN模型采用NIRSA analyst Ver 3.0软件分析建立。首先,将芝麻油等104个样品的FTNIR谱图导入软件,随机选取78个样品组成训练集,剩余26个样品组成验证集(样品分类与PCA-SIMCA相同)。然后,比较不同预处理方法的保留相关系数(R2)、校正集(或训练集)标准偏差(SEC)和预测集标准偏差(SEP)的数值,以R2接近1,SEC与SEP的值接近0为优。在此基础上,通过PLS分析处理样本的光谱数据进行主成分压缩和降维提取主成分数,并将此作为ANN的输入层,依次设定参数(隐含层,输出层,训练步长,训练次数等),多次试验,确定定性分析模型。最后通过比较验证模型实际输出值与期望输出值的偏差,参考软件自动分类范围,得出模型预测分类结果。
1.3.3 定量分析
采用Quant+软件中的PLS建立芝麻油-大豆油和芝麻油-葵花籽油的二元混合物的定量分析模型。首先,将二元混合物样本的红外谱图导入软件,并输入对应样本的实际掺伪含量。然后比较不同预处理方法R2、SEC和SEP的数值,反复试验,确定光谱的预处理方式以及消除异常点后,其中,随机选取40个样品(3%~100%)作为校正集,剩余11个样品作为验证集,采用交互验证的方法确定最佳主因子数,利用PLS分析得到定量分析模型。
2 结果与讨论
2.1 植物油的近红外光谱图
图1是大豆油、花生油、芝麻油和葵花籽油的近红外光谱图。其中,9 000~8 000 cm-1的谱峰是油脂中—CH2—、—CH3和—═CH CH—的第2组合频;7 500~6 500 cm-1为油脂中—CH2和—CH3的二级倍频;6 500~5 500 cm-1内的吸收峰为—CH2—,—CH3和—═CH CH—等官能团的第1组合频;5 000~4 500 cm-1范围的谱峰是顺式双键的组合频,其峰强随不饱和度的增加而增大[12-13]。由图1可见,上述4种植物油的FTNIR谱图极为相似,它们在8 267、7 074、5 795、5 678、4 663、4 592 cm-1附近均出现相似的—CH2—,—CH3和—═CH CH—等振动吸收峰。这与食用植物油组成均为多种脂肪酸三酰甘油混合物的化学组成相符[14],因此,仅仅通过直观比较谱图是很难区分食用油的种类,必须借助化学计量学等数学处理方法进行分类鉴别。
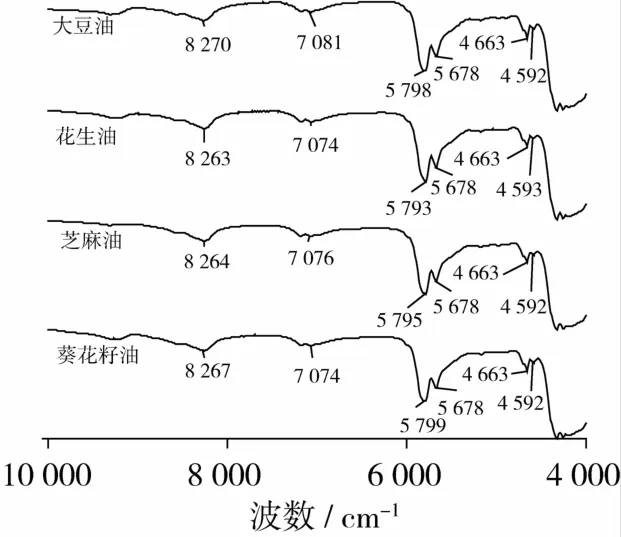
图1 芝麻油、大豆油、花生油和葵花籽油的近红外谱图
2.2 真伪鉴别分析
2.2.1 SIMCA分类模型的建立
SIMCA是一种有监督的模式识别方法,一般由4个步骤组成,包括:1)样本光谱数据的收集,采用常规方法对样本进行鉴别分析;2)光谱图的预处理,如取导数和标准化处理等;3)特征变量的提取,一般常用PCA和因子分析方法;4)SIMCA方法建立分类模型,并检验模型的可信度。通常,人们将不同样本的分子光谱数据经过模式识别进行样品的类别和质量等级的定性分析[15]。近年来,应用红外光谱结合SIMCA建立分析方法的研究逐渐增多[16-18],但应用FTNIR结合SIMCA建立鉴别芝麻油真伪的方法还鲜见报道。
2.2.1.1 谱图处理
由于采集的FTNIR光谱受到高频随机噪声、基线漂移、样品不均匀、光散射等影响,需要进行光谱预处理来消除噪声以提高谱图的分辨率。常用的光谱数学预处理方法主要有一阶求导、二阶求导、多元散射校正(MSC)、矢量归一化(SNV)等[19]。通常,一阶导数可以校正基线的平移变化,二阶导数可以校正基线的倾斜变化,对于混合物红外光谱来说,导数光谱的重要意义在于分辨重叠峰,提高谱图的分辨率。此外,对于由样品颗粒散射等因素导致谱图基线发生平移、吸收峰强度成比例改变的情况,可以采用MSC进行处理。SNV是针对每个样本的谱图分别校正,将每一个样品的光谱数据进行标准正态化。SNV经常与De-trending算法一起使用,一般认为其校正效果要优于MSC。本文在经过多次尝试,采用二阶求导(13点)和SNV预处理方法,选择了8 000~4 000 cm-1范围的谱图进行分析模型的建立。
2.2.1.2 主成分分析
以芝麻油和大豆油、花生油和葵花籽油为变量,将采集样品的谱图转化为数据矩阵,用PCA方法将所有光谱数据进行数据压缩,提取主成分得分数。以PC1和PC2得分分别作为横纵坐标绘制4种植物油品的二维得分图(图2),图中字母k代表葵花籽油、d代表大豆油、h代表花生油、z代表芝麻油,数字代表该油脂的编号。由图2可见,4种油的分布具有一定的聚类特性,同一类样品基本可以聚集在相同的区域,在PC1上的分布差别较大,分布范围分别是:-0.18~-0.08(葵花籽油),-0.08~-0.02(大豆油),0.00~0.08(芝麻油)及0.12~0.22(花生油)。
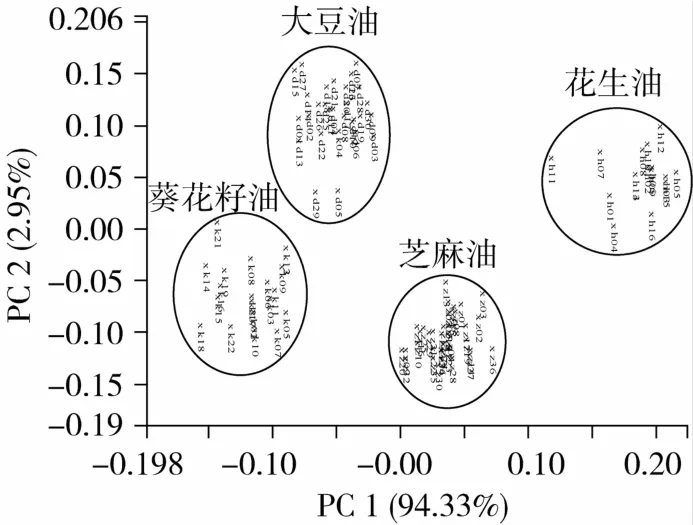
图2 芝麻油、大豆油、花生油和葵花籽油的PCA得分图
2.2.1.3 SIMCA模型建立与鉴别分析
为了精确建立芝麻油与其他植物油的分类识别模型,根据1.3.2节的方法,在PCA分析的基础上,分别随机选择28个芝麻油,20个大豆油、16个葵花籽油和14个花生油组成训练集,选取8 000~4 000 cm-1范围的光谱图,进行分析建立PCA分类模型;在此基础上应用SIMCA建立芝麻油和非芝麻油两类样本的识别模型(图3)。将余下的8个芝麻油与18个其他植物油共26个样本作为验证样本,用来检验模型的可靠性(图4)。
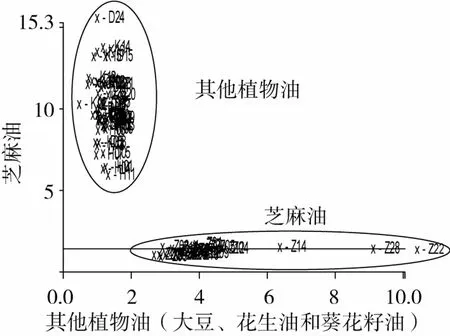
图3 芝麻油与其他植物油的SIMCA分析结果
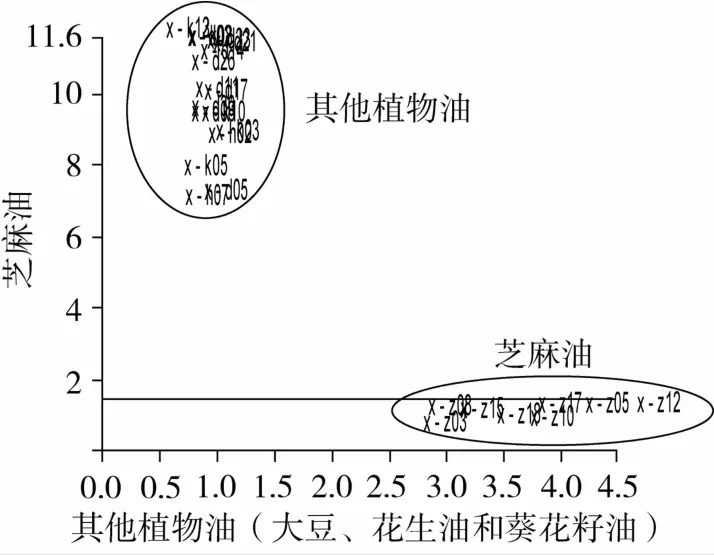
图4 芝麻油与其他植物油的SIMCA分类识别模型
由图3可以看出芝麻油与其他3种植物油之间没有重叠,互不干扰,聚类结果比较理想。一般,我们可以通过类间距(Inter Material Distances)来评价FTNIR-SIMCA模型的分类识别效果,类间距是两类(或几类)样本聚类中心之间的距离,类间距的数值越大表明样本类与类之间的差异越明显,则SIMCA模型的分类识别效果越好[20]。文中的真伪芝麻油的类间距为33.41,这个数值较大,说明基于食用植物油训练集建立的NIR-SIMCA模型的分类识别效果较好。此外,识别率(Recognition rate)与拒绝率(Rejection rate)是反映类模型之间聚类可信度的常用指标。当两个值都为100%时,表明两类样品之间没有重叠,可以较好的将其聚类分开[20]。图4为真伪芝麻油的SIMCA分类验证模型,结果表明:两类油品的正确识别率和拒绝率均为100%。一般来说,如果一个模型的正确识别率如果能达到60%以上,就说明该模型可行[21]。因此,本研究建立的真伪芝麻油的NIR-SIMCA分类识别模型基本可行。
2.2.2 ANN定性判别模型的建立
ANN算法是一种非线性建模方法。一般,ANN模型选用3层或3层以上的神经网络,即输入层,隐含层,输出层。在ANN的应用过程中,常采用PCA或PLS法对光谱数据降维,获得主成分得分并作为网络的输入变量。在建立ANN的过程中,需要确定一系列参数,如隐含层的节点数,输入层到隐含层、隐含层到输出层的初始权重,隐含层、输出层的传递函数,学习速率、动量等。根据传递函数并按照一定的学习规则自动调节网络各层之间的连接权重,进行迭代,以使得网络的实际输出值与期望输出值相比达到一定的精度要求[22]。
2.2.2.1 谱图处理与参数设置
按照1.3.2对芝麻油等4种植物油的FTNIR谱图数据依次运用二阶求导和中心化处理进行谱图预处理,并选择10 000~4 000 cm-1范围的谱图进行ANN分析模型的建立。
ANN建模过程中,选择合适的PLS主成分作为神经网络的输入变量,可以减小神经网络规模,降低训练时间;而且可以充分利用原始光谱图中的有用信息,剔除噪声。本试验将采集样品的所有谱图转化为数据矩阵,应用PLS法对所有光谱数据进行数据压缩,发现其中前4个主成分的累积贡献率为98.37%,确定每张谱图可以只需用前4个主成分代替,因此,设置ANN的输入层节点数为4。当输入层节点数确定后,其他参数不变,选择隐含层节点数范围,当隐含层节点数目为15,SEP为最小。网络输出层输出一个预测的结果,故输出层为1。考虑网络稳定性,按照从小到大的顺序选择训练速度,当最小训练速度设为0.025,预测误差达到最小。其中,动态参数取0.95,允许误差设为0.001,最大迭代次数设为10 000次。
2.2.2.2 建立人工神经网络ANN模型
选取28个芝麻油,20个大豆油、16个葵花籽油和14个花生油,共78个样品作为校正集,剩余的26个样品作为预测集。建模时,将大豆油、葵花籽油、花生油和芝麻油分别赋值为1、2、3、4;根据软件自动分类结果,预测得到的数值范围为:0.4~1.4为大豆油,1.6~2.4为葵花籽油,2.6~3.4为花生油,3.6~4.4为芝麻油。78个建模集的均方估计残差(RMSEC)值为0.111 4。该模型经过对26个未知样品进行预测,结果准确率为100%(表1),表明利用PLSANN法建立真伪芝麻油的鉴别模型是可行的。
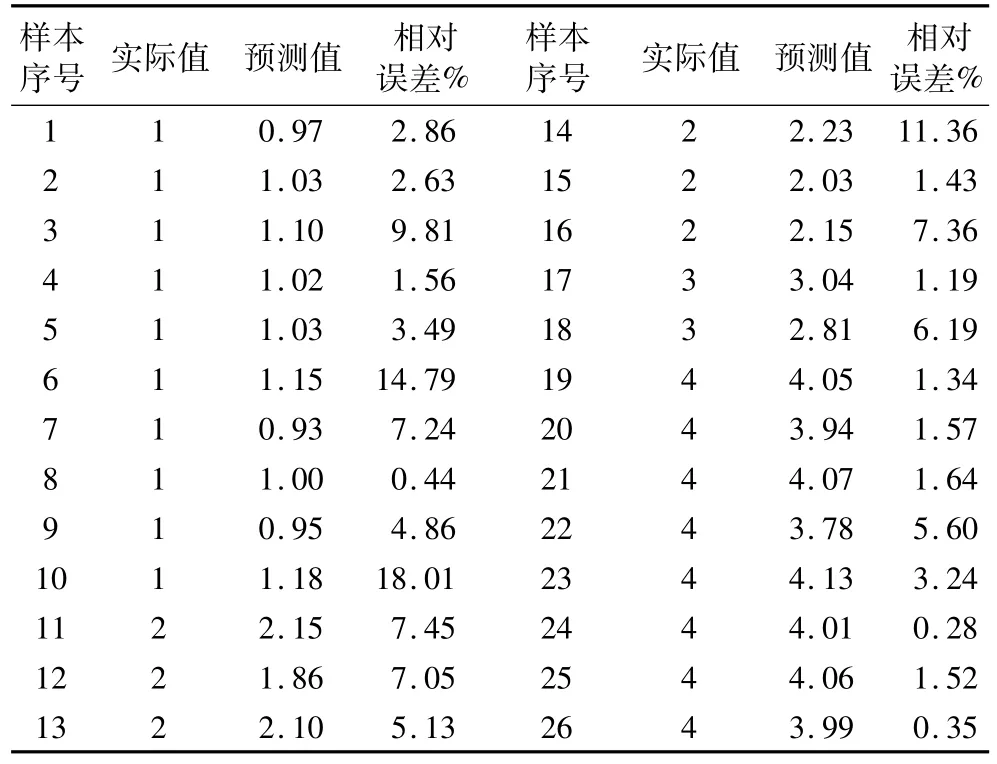
表1 人工神经网络ANN对预测集样品的识别结果
综上,本试验分别运用PCA-SIMCA以及PLSANN 2种分析法建立了芝麻油与其他植物油的分类模型,两个模型验证结果的准确率均为100%,表明两种方法均可用于真伪芝麻油的定性检测分析,可能成为快速鉴别芝麻油真伪的一种新方法。
2.3 定量分析
PLS通过因子分析将光谱数据压缩为较低维的空间数据,该方法是将光谱数据向协方差最大的方向投影。与传统多元线性回归模型相比,PLS的特点是:1)能够在自变量存在严重多重相关性的条件下进行回归建模;2)允许在样本点个数少于变量个数的条件下进行回归建模;3)PLS在最终模型中将包含原有的所有自变量;4)PLS模型更易于辨识系统信息与噪声(甚至一些非随机性的噪声);5)在PLS模型中,每一个自变量的回归系数将更容易解释。所以,PLS是一种具有较好发展前景的新型数据处理方法[23]。
2.3.1 芝麻油-大豆油二元体系定量模型的建立
按照1.3.3输入不同比例的芝麻油-大豆油二元混合物的FTNIR谱图与其对应的浓度,应用PLS进行分析处理,通过比较模型的R2、SEC数值确定谱图的处理方法。结果表明:谱图采用SNV结合Detrending算法,以及Offset基线校正处理,经过消除异常点,选择主因子数为10,可以建立芝麻油中大豆油含量的PLS分析模型,该模型经过验证,其R2值为0.999 4,SEP为1.027(图5a)。该模型可以预测的最低质量分数为10%,此时相对误差小于10%。表明FTNIR结合PLS可以快速分析掺入芝麻油中大豆油的含量。
2.3.2 芝麻油-葵花籽油二元体系定量模型的建立
同2.3.1,将FTNIR与PLS结合应用于芝麻油-葵花籽油二元体系的定量分析中,结果表明:采用SNV结合De-trending算法处理后,消除异常点,选择主因子数为13,能够建立芝麻油-葵花籽油的PLS定量分析模型。该模型经过验证,其预测值与实测值的相关性较好,R2为0.999 7,SEP为0.966 0。该模型对大于10%的葵花籽油预测效果良好。
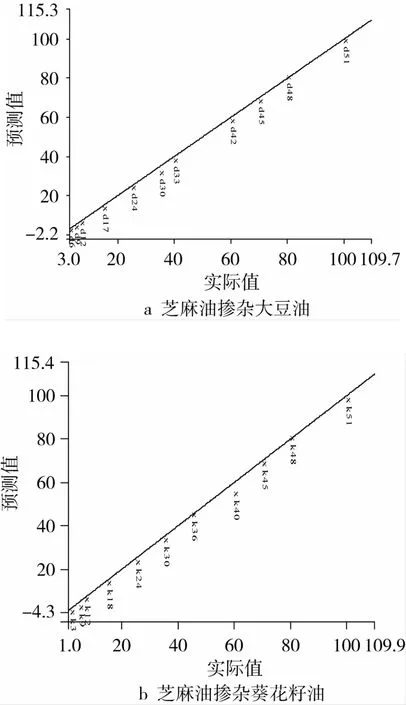
图5 实际值与预测值的PLS验证模型
3 结 论
根据近年来出现的芝麻油掺假现象,运用FTNIR结合化学计量学方法对芝麻油真伪鉴别与其中掺伪油的含量分析进行了研究。首先分别运用PCA-SIMCA以及PLS-ANN建立了针对芝麻油的两种分类识别模型,经过验证,这2种模型的正确识别率均达到100%。说明运用近红外光谱能够完成芝麻油的快速鉴别。进一步地,运用FTNIR结合PLS建立了芝麻油中大豆油和葵花籽油的定量分析模型,该模型可以对芝麻油中10%的大豆油或葵花籽油进行准确定量。本研究表明FTNIR结合化学计量学可以为油脂掺假提供一种快速、准确的分析方法。
[1]任小娜,毕艳兰,杨国龙,等.散装芝麻油品质检测及掺伪分析[J].中国粮油学报,2011,26(11):106-109
[2]李凝.芝麻油质量现状及掺假检检方法的探讨[J].化学分析计量,2011,20(3):99-101
[3]林丽敏.气相色谱法测定芝麻油掺伪的研究[J].粮食储藏,2006,35(3):43-51
[4]孙荣华,何良兴,李岗.芝麻油特征成分检测及防伪技术的研究[J].中国卫生检验杂志,2010,20(1):49-60
[5]Rodriguez-Saona L E,Allendorf M E.Use of FTIR for rapid authentication and detection of adulteration of food[J].Annual Review of Food Science and Technology,2011,2:467-483
[6]褚小立,许育鹏.用于近红外光谱分析的化学计量学方法研究与应用进展[J].分析化学,2008,36(5):702-709
[7]Costa Pereira A F,Coelho Pontes M J,Gambarra Neto F F,et al.NIR spectrometric determination of quality parameters in vegetable oils using iPLSand variable selection[J].Food Research International,2008,41:341-348
[8]周志琴,陈斌,颜辉.二维相关近红外光谱快速鉴别食用植物油种类[J].中国粮油学报,2011,26(9):115-118
[9]范璐,王美美,杨红卫,等.傅里叶变换红外吸收光谱识别五种植物油的研究 [J].分析化学,2007,35(3):390-392
[10]梁丹.应用近红外光谱分析判别芝麻油掺伪的研究[J].食品工程,2011(2):40-43
[11]冯利辉,刘波平,张国文,等.芝麻油中掺入菜籽油的近红外光谱研究[J].食品科学,2009,30(18):296-299
[12]Hourant P,Baeten V,Morales M T.Oil and fat classification by selected bands of near-infrared spectroscopy[J].Applied Spectroscopy,2000,54:1168-1174
[13]李娟,范璐,邓德文,等.近红外光谱法主成分分析6种植物油脂的研究[J].河南工业大学学报,2008,29(5):18-21
[14]毕艳兰.油脂化学[M].北京:化学工业出版社,2005
[15]禇小立.化学计量学方法与分子光谱分析技术[M].北京:化学工业出版社,2011:95
[16]杨忠,江泽慧,费本华,等.SIMCA法判别分析木材生物腐朽的研究[J].光谱学与光谱分析,2007,27(4):686-690
[17]于春霞,马翔,张晔晖,等.基于近红外光谱和SIMCA算法的烟叶部位相似性分析[J].光谱学与光谱分析,2011,31(4):924-927
[18]李娟,范璐,毕艳兰,等.红外近红外光谱簇类的独立软模式方法识别植物调和油脂[J].分析化学,2010,38(4):475-482
[19]刘波平,荣菡,邓泽元,等.近红外光谱-BP神经网络-PLS法用于橄榄油掺杂分析[J].分析测试学报,2008,27(11):1147-1150
[20]徐荣,孙素琴,刘友刚,等.基于PLS-自组织竞争神经网络近红外光谱技术对鲜乳和掺假乳的检测方法研究[J].光谱学与光谱分析,2009,29(7):1860-1863
[21]孙素琴,汤俊明,袁子民,等.红外光谱与聚类分析法无损快速鉴别肉苁蓉[J].光谱学与光谱分析,2003,23(2):258-261
[22]刘名扬,赵景红,孟昱.道地山药红外指纹图谱和聚类分析的鉴别研究[J].吉林大学学报,2007,45(5):849-852
[23]耿响.二维红外光谱分析技术在食用植物油品质检测中的应用研究[D].镇江:江苏大学,2010:55-61.
Fourier Transform Near Infrared Spectroscopy in the Authentication and Adulteration of Sesame Oil
Yang Jia1,2Wu Yanwen2Li Bingning2Liu Lingling2Ouyang Jie1
(Department of Food Science and Engineering,College of Biological Sciences and Technology,Beijing Forestry University1,Beijing 100083)
(Beijing Center for Physical and Chemical Analysis,Beijing Engineering Research Center of Food Safety Analysis2,Beijing 100089)
The rapidly analytical method has been established by Fourier transform near infrared spectroscopy(FTNIR)combined with chemometrics for the authenticity and quantity of sesame oil.FTNIR was combined with two types of authentication and recognition model to classify the sesame oil,soybean oil,peanut oil and sunflower oil by means of principal component analysis-soft independent modeling of class analogy(PCA-SIMCA)and partial least squares-artificial neural network(PLS-ANN)respectively.The results of two models are validated to be the correct recognition rate of 100%.FTNIR with PLS is used to quantify the adulterated sesame oil.Sesame oil with different proportions of soybean oil and sunflower oil were collected.FTNIR spectra PLSis used to establish the model of quantitative analysis for testing its reliability through the validation set.The model can accurately predicts the sesame oil with 10%to 100%adulterated oil.the square error of prediction is 1.027(soybean oil)and 0.966 0(sunflower oil),respectively.
sesame oil,adulteration,NIR,chemometrics
TS227
A
1003-0174(2014)03-0114-06
国家自然科学基金(30701107),北京市自然科学基金(710 2021)
2013-03-20
杨佳,女,1988年生,硕士,农产品加工及贮藏工程
欧阳杰,男,1971年生,副教授,食品加工与质量安全
