论网络爬虫搜索策略
2013-04-27李耀华杨海燕
□李耀华,杨海燕
(1.山西大学继续教育学院,山西 太原 030006;2.山西广播电视大学,山西 太原 030027)
网络爬虫是搜索引擎的重要组成部分。搜索引擎借助于网络爬虫才能在互联网海量数据中有效搜集到相关的网页信息。如何提高网络爬虫的搜索效率,是该领域研究的热点。本文将分别对目前常用的网络爬虫的搜索策略进行初步分析研究。
一、网络爬虫基本工作原理
网络爬虫Web Spider又叫Web Crawler或者Robot,是一个沿着链接漫游web文档集合的程序。它一般驻留在服务器上,并且利用标准的http协议根据超链接和web文档检索的方法遍历整个Internet网信息进行搜索。
(一)网络爬虫的基本结构。传统的网络爬虫包括一个协议处理模块。URL(统一资源定位符,Uniform Resource Locator的缩写,也被称为网页地址,是因特网上标准的资源的地址。它最初是由Tim Berners-Lee发明用来作为万维网的地址的)由两部分构成:协议模块和检测模块。其中,协议模块用来提供网络爬虫所需的网络协议,解决如何获取网页;检测模块负责对采集的URL信息进行排序,处理网络上重复内容,以提高网络爬虫的搜索效率。
(二)网络爬虫的工作流程。网络爬虫也是一个自动提取网页的程序,是搜索引擎的重要组成部分,其作用是为搜索引擎从Internet网上下载页面。网络爬虫在获取网络信息时,通常会从一个“种子集”出发,获得初始网页上的URL,下载页面并提取已下载页面中的连接,抽取新的URL放入队列,然后访问提取出的连接所对应的网页,如此不断重复便可遍历整个网络信息,直到满足系统的一定停止条件。其中,种子集指种子链接集合,通常为几个知名网站主页连接地址。工作流程如图1所示。但通用爬虫搜索有以下几方面不足:
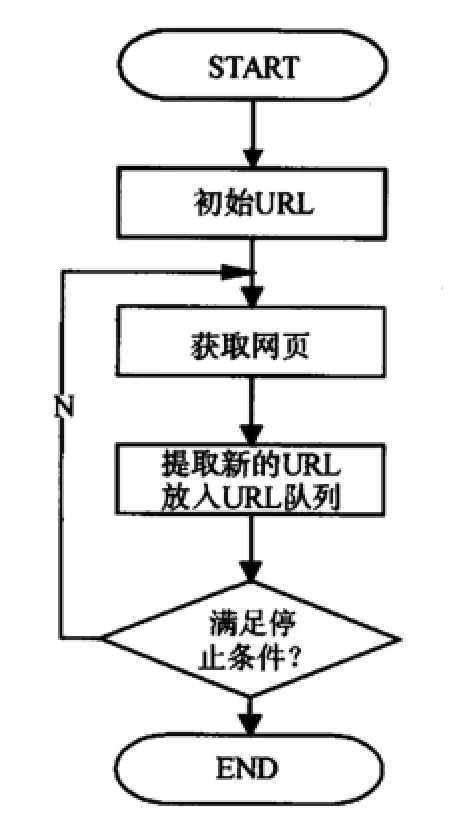
图1 通用网络爬虫工作流程图
(1)因为抓取的目标是覆盖尽可能大的网络,所以爬行的结果中必然会包含大量用户不需要的网页;
(2)无法很好地搜索和获取信息含量密集而且具有一定结构的数据;
(3)通用搜索引擎大多是基于关键字的检索,对于支持语义信息的查询和索引擎智能化的要求则难以实现。
由此,通用爬虫想在爬行网页时,既保证网页的质量和数量,又要保证网页的时效性是很难实现的。
(三)网络爬虫的搜索策略。为提高网络爬虫的搜索效率,网络爬虫需要在既定时间内搜索到尽可能多的高质量网页,这是其面临的主要技术难题。
一般而言,有五种方式表示页面质量的高低:Similarity(页与爬行主题之间的相似度)、Backlink(面在Web图中的入度大小)、PageRank(指向它的所有页面平均权值之和)、For-wardlink(页面在Web图中的出度大小)、Location(页面的信息位置);Parallel(并行性问题)。
搜索策略就是指提取出页面链接后如何访问。通用的搜索引擎往往希望得到较高的网络覆盖率,所以常采用遍历的方式进行访问,见图2。相反,主题搜索引擎的服务范围则是限制在特定的人群和主题范围内,通常采用“最好优先”的原则,选择最有价值的连接进行访问,见图3,其关键就在于如何评价最有价值的连接。
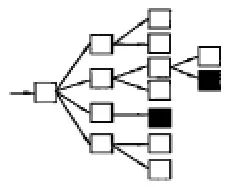
图2
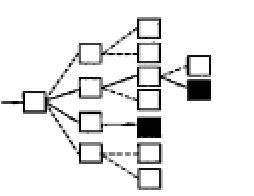
图3
二、遍历搜索策略
该搜索策略对所有提取出的链接都一一进行爬取,目的在于遍历网络上的所有信息资源。
(一)宽度优先策略。宽度优先搜索(Breadth-First Search)是一种简便常用的搜索算法(又称广度优先搜索)。这一算法也是其他很多重要算法之原型,其主要用来解决最优解问题。其基本思想是:从起始网页源顶点p开始,沿着树的宽度遍历树的每一个节点,获取相关所有链接网页,进而再沿这些节点继续抓取该网页中的所有链接页面,最终遍历所有顶点。即,首先完成一个层次的搜索,其次再进行下一层次的搜索,也称之为分层处理。该算法的设计模式和技术实现比较简单且能获得较高的网页覆盖率,但该算法的设计和实现相对简单,属于盲目搜索,因而效率较低。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。为尽可能覆盖较多网页,宽度优先搜索方法是较好的选择。
(二)深度优先策略。深度优先搜索(Depth-First Search),也是一种早期在开发爬虫过程中使用较多的方法。其设计思路是尽量“深”入地搜索信息资源。在深度优先搜索中,针对最新发现的网页源顶点p,如果它还有以此为起点而尚未搜索到的路径,则沿此路径继续搜索下去。反之,如果当顶点p的所有路径均己被搜索过,则回溯到初始点。这一搜索过程将一直持续到已发现的从源顶点p可达到的所有顶点为止。但是如果仍然存在未被发现的顶点p’,则继续选择其中一个作为源顶点并重复以上过程,最终实现所有顶点都被遍历。
但是深度优先策略不足之处是,深度优先策略在很多情况下会导致网络爬虫的陷入问题(trapped),导致盲目搜索。
三、最好优先策略
“最好优先”(Best-First Search)的爬虫也称聚集爬虫,是根据相关网页分析算法,预测候选URL与目标网页的相似度,根据“最好优先”原则进行访问,选取评价最好的一个或几个URL,以便快速、有效地获得更多的与目标网页相似度高的页面进行抓取。最好优先策略只访问经过网页分析算法预测为“有用”的网页。专业的搜索引擎网络爬虫通常会采用“最好优先”原则访问WEB。但由于所有搜索链接均包含在相关网页中,因此页面价值往往与页面内链接价值存在正相关关系,于是对链接价值的评价有时也可转换为对页面价值的评价。
但最好优先策略存在一个问题:因最佳优先策略只是一种局部最优搜索算法,所以网络爬虫在抓取有用信息的过程路径上会有很多相关网页被忽略。因此该策略在应用时应结合具体情况进行必要改进,以跳出局部最优点。
(一)基于内容评价的搜索策略。互联网上不良信息、不安全信息日益增多已成为危害社会的严重问题,对互联网信息内容进行必要的监控成为一项迫切任务。而网络爬虫在信息搜索中起着明显的作用。
基于内容评价的搜索策略是根据搜索内容的主题与被链接网页文本的相似度来评价链接价值的高与低,进而决定搜索策略。其中,相似度评价通常一般采用以下公式:

其中,di为新获取文本的特征向量值,dj为第j类链接文本的中心向量值,m为特征向量di的维数,wk为向量w的第k维。
基于内容评价的搜索策略并不只有这一种计算方法,除上述公式外,还有 Best-First Search,Fish Search和 Shark Search算法。
(二)基于链接结构评价的搜索策略。基于链接结构评价的搜索策略属于web页面的半结构化设计,通过对页面间的超链接进行关联分析其引用关系来确定链接的重要性,由此确定链接访问的次序。因此这种结构化特征使文本链接的重要性可通过链接分析来加以确定,主要根据文献计量学的引文分析理论来进行。常规认为有较多入链或出链的页面具有较高的价值。PageRank算法和Hits算法是其中具有代表性的算法。
1.PageRank(网页级别)算法。PageRank算法是Google创始人Larry Page和Sergey Brin于1997年构建早期的搜索系统原型时提出的链接分析算法。该算法随着Google在商业上获得巨大成功后成为其它搜索引擎和学界所关注的计算模型。可以说PageRank算法是后来很多链接分析算法的基础。
例如Google搜索引擎信息检索中对查询结果的排序过程。其对web页面的排序,在揉合了诸如Title标识和Keywords标识等所有其它因素之后,根据搜索的信息内容在页面中的出现次数,并用页面长度和html标签的重要性提示等进行权重修订。使那些更具等级的网页在搜索结果中的排名获得提升,最终提高搜索结果相关性和搜索质量。近年来被应用于网络爬虫对链接重要性的评价。Google通过PageRank来调整结果,其级别从0到10级,10级为满分。链接提供的页面越重要则此链入值越高。此外,还可通过其它文档链接到当前页面的链接数量来确定当前页面的重要性,这样可以有效地抵制那些被人为加工过的页面欺骗搜索引擎的手法。
该算法中,通常用PageRank值表示页面的价值,若设页面p的PageRank值为PR(p),则PR(p)用如下公式表示:
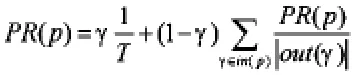
其中:T为所计算中页面总量,γ<1为阻尼系数,in(p)为所有指向页面p的集合,out(γ)为页面γ出链的集合。按照PageRank算法,爬虫在信息搜索过程中,通过计算已访问页面的PageRank值来确定页面的重要性,并确定访问次序。
2.Hits算法。1997年康奈尔大学(Cornell University)的Jon Kleinberg首次提出了Hits算法(Hyperlink-Induced Topic Search)。Hits算法也是Web结构挖掘中最具有权威性和使用最广泛的算法之一。该算法中引入了两个重要的概念:内容权威度(Authority Scores)和链接权威度(Hub Scores)来对网页质量进行评估。其基本思想是利用页面之间的引用链来挖掘隐含在其中的有用信息,具有计算简单且效率高的特点。
Hits算法中网页的Authority值表示所有导入链接所在的页面的Hub值之和,即一个页面被其它页面所引用的次数,被其它页面引用的次数越多,则这个页面的Authority值就会越大;页面的Hub值表示指的是页面上所有导出链接指向页面的Authority值之和,一个页面指向其他页面的次数,指向其它页面的次数越多,这个页面的Hub值就会越大。由于在Hub值高的页面中通常都包含了指向Authority页面的链接,因而能够起到说明页面权威性的作用。Hits算法正是利用这种相互关系来发现Authority页面的。
(三)基于巩固学习的搜索策略。相关研究表明,多数类似网站在设计方式上,同类网页存在一定相似性,因而有人将巩固学习(Reinforcement Learning)搜索策略引入到网络爬虫的研究中以减小搜索空间,提高效率。在该模型中,将网络爬虫遍历无关页面访问后才能获得的主题页面称之为未来回报,即搜索到隐含的结构信息。在综合考量计算立即回报价值和未来回报价值结合的前提下确定正确的搜索方向。
随着互联网技术的广泛应用,互联网信息量的海量增长使传统的通用搜索引擎面临着巨大的挑战,各类针对特定人群的“专业搜索引擎”便应运而生。网络爬虫搜索就是典型代表。网络爬虫各类搜索策略各有利弊,尚无单一标准去评价其优劣。互联网搜索问题属于“多目标”规划问题。降低计算的复杂程度,提高搜索链接价值的准确性,增加网络爬虫的自适应能力,是提高网络爬虫效率的核心问题。
[1]欧阳柳波等.专业搜索引擎搜索策略综述[J].计算机工程,2004,(30):32 -33.
[2]李勇,韩亮.主题搜索引擎中网络爬虫的搜索策略研究[J].计算机工程与科学,2008,(3):4 -6.
[3]欧阳柳波等.网络蜘蛛搜索策略进展研究[J].小型微型计算机系统,2005,(4):703 -703.
[4]刘世涛.简析搜索引擎中网络爬虫的搜索策略[J].阜阳师范学院学报,2006,(3):59 -62.
[5]龚勇.搜索引擎中网络爬虫的研究[D].武汉:武汉理工大学,2010.
[6]李学勇.搜索引擎中网络蜘蛛搜索策略比较研究[J].计算机技术与自动化,2003,(4):63 -65.
[7]李学勇等.网络蜘蛛搜索策略比较研究[J].计算机工程与应用,2004,(4):63 -67.
[8]刘汉兴,刘财兴.主题爬虫的搜索策略研究[J].计算机工程与设计,2008,(12):33 -38.
[9]刘伟.搜索引擎中网络爬虫的设计与实现[J].科技传播,2011,(20):178 -181.
