基于语义依存的中文本体非分类关系抽取方法
2012-11-30古凌岚孙素云
古凌岚,孙素云
(广东轻工职业技术学院 计算机工程系,广东 广州510300)
0 引 言
近年来,本体的应用越来越广泛,如语义网、搜索引擎、知识工程、信息提取等领域,而本体的构建是本体应用的基础和关键,尽管目前已有许多本体构建工具,能够提供本体建立和校验等功能,但完全依靠人工进行本体领域知识的获取 (包括搜集领域概念、定义概念间关系),不仅费时费力,而且无法保持本体的更新。因此,本体学习技术应运而生。
本体学习是指利用机器学习和统计等技术自动或半自动地从已有的数据资源中获取期望的本体[1]。由文献 [1]可知,本体学习主要任务是定义概念和概念关系 (分类关系和非分类关系),而概念关系学习为高层任务,其中分类关系体现了两个概念之间的包含关系 (上下位关系),非分类关系则是除上下位以外的关系。非分类关系学习包括提取所涉及的概念对、进行关系语义标注两方面。
1 相关工作
目前多数本体学习研究致力于术语和分类关系抽取,相对而言,非分类关系的抽取更加困难,同时得到的关注也较少。本体构造中发现得到的非分类关系多数是人类本体工程师标注所得。现有方法主要有两种:基于模式的方法和基于关联规则的方法,国内对中文本体学习的研究多集中于后者。
基于模式的方法[2]是通过分析领域相关文本,归纳出频繁使用的语言模式作为规则,而后作为文本中词序列匹配的模式,来识别相应的关系。Hearst等人率先提出词汇—句法模式方法,利用手工构造的模式实现了自动地抽取关系。这种方法的主要问题是:①关系抽取的效果受限于模式是否完备;②机械地使用模式匹配,导致所获取的关系中包含大量无用概念对。
基于关联规则的方法是一种常用方法,它是利用最初在数据库领域定义的关联规则,由Maedche等率先应用于本体学习,继而以概念层次为背景知识,用来发现概念间非分类关系的方法。文献 [2]也是基于这种思想抽取概念间的非分类关系。这种方法的缺点是,只能判断概念间是否存在关系,无法对关系进行语义标注。
上述方法主要局限于共现规则和频率统计,而本体是领域知识语义的形式化标志,且所用的数据资源是文本,因此,引入语义和句子语法分析开展非分类关系学习将更为有效。文献 [3]通过提取 “主谓宾”结构,构建 [动词概念]和 [概念 动词]检索模式,实现了自动获取非分类关系,并用动词标记关系。文献 [4]基于依存语法中动词为中心的思想,提出了扩展的关联规则方法,通过提取“主谓宾”结构的概念对和动词,发现关系和标记关系。但以上研究提取中文非分类关系时,仅考虑了单句结构,且忽略了词间的语义关联。
针对现有方法中存在的抽取正确率低、缺少语义标注问题,在文献 [3-4]基础上,本文针对中文非分类关系抽取,提出了一种基于语义依存分析的方法,通过分析语句中成分的语义角色和依存关系,发现动词为中心的、具有语义依存关系的词汇框架,并以语义相似度为依据,识别中文本体概念间的非分类关系,实现对关系的语义标注。该方法克服了关联规则无法标识关系名称缺点,以及仅考虑概念对和动词共现词频所带来的关系抽取性能问题。
2 研究基础
2.1 语义角色标注
语义角色是谓词与论元的语义关系。常见的语义角色有施事、受事、与事、结果、工具和处所等。从语义上看,一个论元的语义角色分配主要取决于谓词语义。例如:“我拿了一本书”,其中 “拿”为谓词,“我”为施事者,“书”为受事者。
语义角色标注是在句法分析基础上,对句子中的词语序列分组,并按照语义角色对它们进行分类[5]。该方法不对整个句子进行详细的语义分析,而是以动词框架为考察对象,只标注与谓词相关论元的语义角色,这些论元作为此谓词的框架中一部分被赋予了一定的语义含义,从而反映出句子中的谓词与其它成分间的语义关系。
语义角色标注的基本单元可以是句法成分[6]、短语[6]、词[6]或者依存关系[7]等等。目前实现方式有两种,一是建立在短语结构句法分析方法的基础之上,如基于统计的学习方法[8];另一种使用依存句法分析结果进行语义角色标注[7],两者分析效果相近。
2.2 依存语法和依存语法分析
依存语法是一个用词之间的依存关系 (dependency relationship)来描述语言结构的框架,又称从属关系语法。由法国语言学家L.Tesniere最先提出,其核心思想是以谓语动词为中心,研究句子中其它成分与谓词的依存关系。依存语法认为,句子中词与词之间的关系是有方向的,一个词支配另一个词,则称这种支配与被支配的关系为依存关系,支配词又被称为被支配词的中心词,通常可表现所在短语的主要语法、语义特征。
依存语法将句子结构表示为词对的二元关系。而句子成分间相互支配与被支配、依存与被依存的现象普遍存在于汉语的词汇 (合成语)、短语、单句、复合直到句群的各级能够独立运用的语言单位之中,这一特点为依存关系的普遍性[9]。依存语法分析的目的是发现词语间的语义联系,根据依存语法5条公理[10],在一个完整的句子中,所有语义联系相互交织的结果将句子的线性结构层次化,构造成为语义依存树的形式,从而反映出句子中各成分间的语义修饰关系,且与成分的物理位置无关。
依存语法分析方法目前已较成熟,利用已有的依存句法分析器 (这里采用哈尔滨工业大学信息检索研究中心开发的依存句法分析器,目前该分析器对依存弧的标记准确率达到86%以上),可进行句子语法分析,并以此为基础发现依存关系,最终生成依存树。例如:“家庭是孩子的第一个课堂。”分析得到的依存树如图1所示。其中 “是”句子的中心词 (核心关系HED),“家庭”与中心词有主谓依存关系 (SBV),“课堂”则与中心词有动宾依存关系 (VOB),另外,还有定中关系 (ATT)、介宾关系 (POB)等。
依存树将形式化的语法规则和约束表述为结点、边,以及它们所携带的信息,使得对句子的依存分析转化为寻找句子中的一组依存对。
3 基于语义依存的非分类关系抽取
非分类关系一般由动词及与之相关的两个概念构成,可有以下定义。

图1 依存树
定义1 非分类关系形式表示为:R=<Cpre,Vrel,Csuc>,其中Cpre,Csuc均为本体概念 (依存树中依存于中心词的名词或名词词组),称Cpre为关系R前驱概念,Csuc为关系R后继概念,Vrel(中心词)是关系R的语义标注。
由定义1,对于中心词、主语、宾语构成主干结构的句子,如 “涡轮喷气发动机主要用于超声速飞机。”句子中的非分类关系可以表述为:< “涡轮喷气发动机”,“用于”,“超声速飞机”>,即主语 (“涡轮喷气发动机”)为前驱概念,而对于用中心词、施事者、受事者描述主干结构的句子,则施事者为前驱概念。
本文以本体概念集为学习种子,查找充当语句所含动词框架中不同语义角色的概念对,而后计算动词框架的语义相似度来识别非分类关系。通过加入句子结构和语义关系因素,来改善文献 [3-4]方法的不足。该方法包括3个方面:①对文集进行语义依存分析,获得已标记的句子集合;②分析句法结构,提取动词框架构成的句子主干;③计算语义相似度,发现非分类关系。
3.1 语义依存分析
根据中文术语特点,对于未标注语料集进行初步筛选。采用中国科学院计算技术研究所开发的ICTCLAS对文本进行分词,将每条语句切分为一组具有词性标注信息的中文组词及符号,去掉对于句子意思表述无贡献的词,如感叹词、语气词、助词等。而后利用基于汉语的依存语法分析器 (采用哈尔滨工业大学信息检索研究中心开发的中文依存句法分析器,该分析器能够实现词性标注、语义角色标注、依存语法分析等功能),给定语料集中的一个句子作为输入,产生一棵标注了依存关系、语义角色的语法分析树,由依存关系确定句子中以动词中的从属关系框架,而语义角色标注则确定该从属关系框架中相对应的语义角色。
通过语义依存分析,对文集句子成分的语义角色、依存语法信息实现标记,从而获得文集中句子的语义依存结构信息。
3.2 提取句子主干
由于中文语法的复杂性,一个复杂句子的依存信息结构也会相当庞大,如果直接对完整句子进行分析处理,工作量巨大并且没有必要。依存语法认为每个句子都以动词为中心的从属关系结构,则保留句中谓语 (中心动词)、及其主语、宾语 (对于缺少主语或宾语的动词框架,因无法确定中心词所涉及的另一个概念,不作考虑)框架,或是谓词 (中心动词)、及其施事者、受事者 (类似地,过滤掉缺少施事者或受事者的动词框架)角色,构成句子的主体架构,而且非分类关系抽取关注的是概念 (名词或名词词组)之间的关系,因此,将句子进行剪切,以去掉噪音,得到由中心词、主语、宾语以及主语/宾语附属成分 (依存于主语/宾语和主语/宾语依存的词为附属成分),或是中心词、施事者、受事者以及施事者/受事者附属成分所形成的动词框架构成的句子主干 (当句子为复句时,句子主干可能包含多个动词框架,仅考虑直接依存于中心词的成分,会遗漏可能的非分类关系),且依存于中心词的成分应是名词 (词组),用于非分类关系抽取。由于中文句法分析器是以词为单位进行句子成分的,而中文本体概念多为复合词,在上述句子修剪过程中,将保留依存于主干成分的词,作为主干成分的一部分,以提高抽取效率。动词框架提取算法描述:
输入:标记语义依存信息的句子集合S;
输出:动词框架组成的句子主干集合S′;
(1)若S为空,则退出;
(2)对于S中的任一句子s,查找中心词 (核心关系HED)V;
(3)若s中同时有依存于V的SBV、VOB依存关系的角色Rs,Rv,则提取由V、Rs、Rv构成的动词框架;
(4)若s中还同时有施事者、受事者语义角色Ra0,Ra1,且为名词 (词组),则V、Ra0、Ra1构成的动词框架;
(5)若句子s存在与V并列 (并列关系 W)的中心词Va,则转步骤 (3);否则将s中所提取的动词框架集构成句子s的主干加入S′,转步骤 (1)。
为了便于理解算法,给出动词框架提取的具体示例:
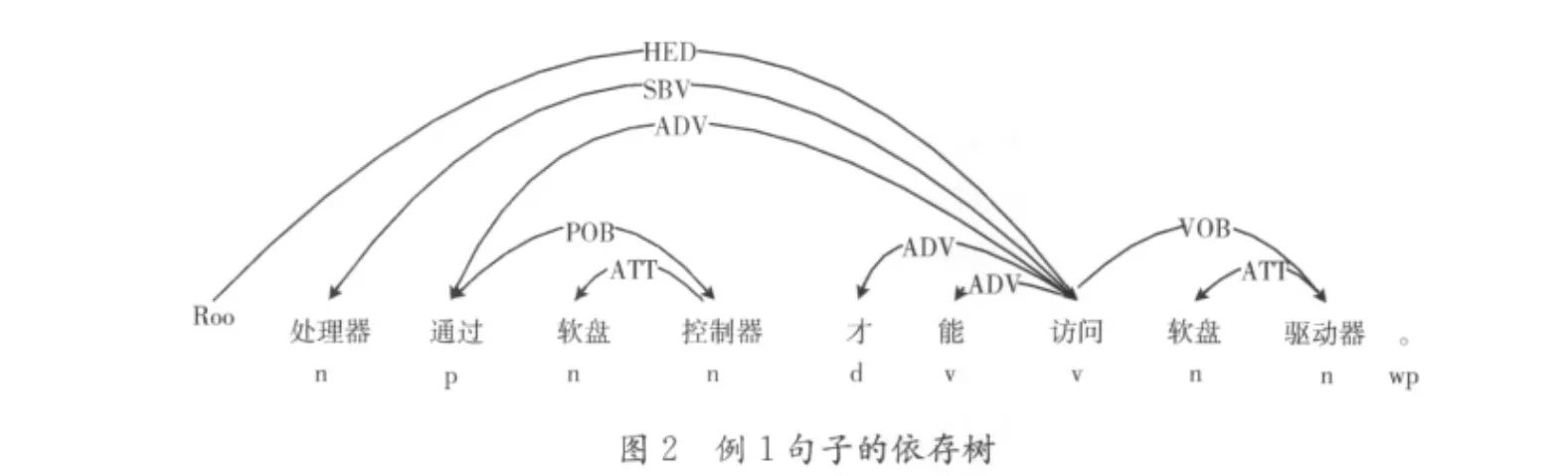
例1:处理器通过软盘控制器才能访问软盘驱动器。
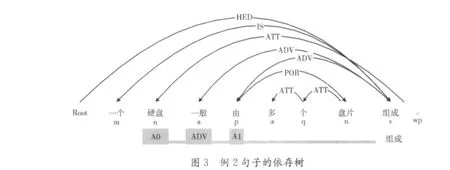
例2:一个硬盘一般由多个盘片组成。
例3:网络技术利用高速互联网,为我们提供一体化的信息服务。
例1是主谓宾结构的句子,依存语法分析的结果如图2所示。“访问”为中心词,“处理器”为主语 (SBV关系),“驱动器”为宾语 (VOB关系),均依存于 “访问”,而“软盘”依存于 “驱动器”,提取的句子主干为 “处理器访问软盘驱动器。”。而例2属于另一类句子,采用中心词、施事者、受事者框架提取句子主干更为适合,其依存结构信息如图3所示。由图可知, “组成”是中心词, “硬盘”是施事者 (A0),而 “由”是受事者 (A1), “盘片”是“由”的附属成分,提取的句子主干为 “硬盘由盘片组成”。例3是复句,其中 “利用”和 “提供”是并列关系 (W),可提取句中的两个动词框架,即 “网络技术”, “利用”,“高速互联网”和 “网络技术”,“提供”,“信息服务”。
通过对文集中句子进行语义角色标注、依存语法分析及句子主干提取,得到了标注有句法结构信息、语义关系的、由动词框架刻画句子的文本。
3.3 语义相似度计算
对于经过语义依存分析和句子主干提取的句子集,可表示为S= {F1,F2,…,Fm},Fi(i=1,2,…,m)为动词框架,表示为Fi= {Ei1,Ei2,Ei3},Eij是框架元素(谓词,主语/施事者,或宾语/受事者),且Eij= (rij,fij,mij)(j=1,2,3),其中rij表示语义角色 (依存关系),fij表示词性,mij表示语义 (HowNet提供的语义描述)。框架元素匹配权重定义为:对于元素Ei1和Ei2,若ri1和ri2,fi1和fi2,mi1和mi2均相同,则匹配权重为1;若ri1和ri2,mi1和mi2相同,但fi1和fi2不同,则匹配权重为0.6;否则为0。语义相似度计算公式如下
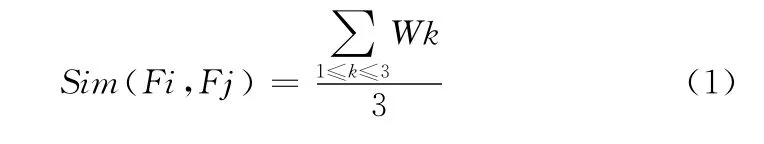
利用式 (1)计算句集中动词框架的语义相似度,当大于相似度阈值的动词框架出现频率达到某一阈值时,则认为语义角色所对应的本体概念间具有非分类关系,中心词即关系名称。
3.4 非分类关系的抽取算法
非分类关系的抽取是发现概念对及语义标注的过程,其基本思路如图4所示。另外,通过依存分析中标注的同位关系 (APP),还可以发现同义关系。
非分类关系学习是在已构建本体概念集,语料集已经过无用词过滤处理的前提下进行的。具体算法步骤:
(1)利用中文依存语法分析器对语料集进行分析,得到句子语义依存结构集合S;
(2)根据语言学规则,提取句子主干,得到由动词框架组成的句子主干集合S′;
(3)从本体概念集C中任取一个概念Ck,若C为空或概念均已标记,则转 (7);
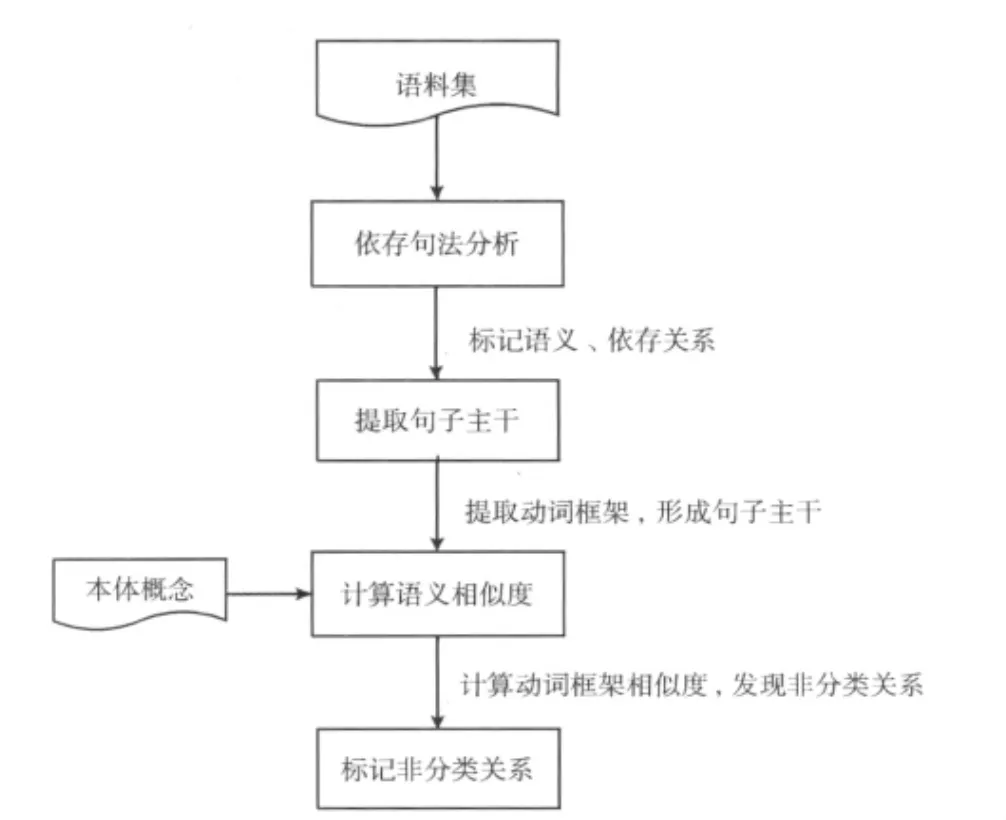
图4 非分类关系抽取流程
(4)在S中搜索包含Ck,且Ck充当主语/施事者或宾语/受事者角色的所有动词框架F1,F2,…,Fm,计算Fi、Fj(1≤i,j≤m)的语义相似度,若存在相似度大于阈值λ,则为候选框架,并加入候选框架集合CF中;否则转 (3);
(5)若CF中某候选框架个数达到给定阈值ω,且C中存在与框架中宾语/受事者或主语/施事者角色的概念相似度超过阈值δ的概念Cl,则Ck、Cl具有非分类关系,根据依存结构确定前趋概念、后继概念,并用中心词赋予关系语义标注,同时对C中Ck、Cl标记;
(6)若S中存在Ck、Cl的同位关系词,则作为Ck、Cl的同义关系,加入其同义词集合,并在C中作相应标记;转 (3);
(7)结束。
若第 (4)步出现Ck与句中多个动词框架有依存关系时,将看作新的候选非分类关系,另行计算。第 (5)步中概念相似度计算采用了文献 [8]的本体概念匹配算法。
4 实验及结果分析
由于目前没有标准的中文语料库,实验采用了复旦大学文本分类语料库中计算机专业领域作为测试文集。该语料库多来源于新闻或互联网科普类,具有信息量大、覆盖面广、用语规范特点,从而使得实验结果具有较强的代表性。
从测试文集中选取了95个与计算机相关的概念作为实验本体概念集,设句子语义相似度阈值为0.53,对测试文集进行了非分类关系的抽取。为了测试实验的有效性,采用基于关联规则统计[1]、基于 “主谓宾”结构提取概念对及关联动词的方法 (简称基于 “主谓宾”结构)、本文提出的方法分别进行了实验,并通过正确率计算对实验结果进行了比较,其结果如表1所示。正确率的计算方式是正确抽取的非分类关系数与测试文集中所有的非分类关系数之比。
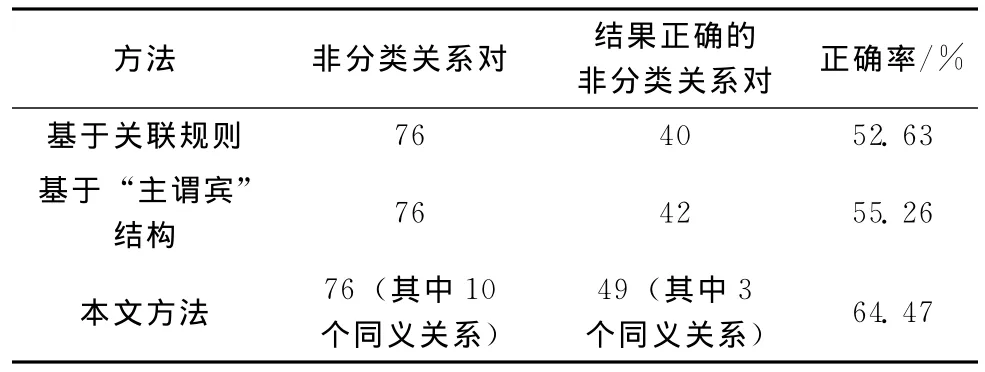
表1 3种方法的实验结果对比
从实验结果来看,本文提出的方法抽取正确率明显要高,并发现了同义关系。这是由于通过语义依存分析,提取了由动词框架构成的句子主干,剔除了句子中对关系抽取的干扰因素,从而提高了正确率。而加入依存于主/宾语的附属成分在一定程度上避免了分词造成的错误,如:例1句中 “软盘驱动器”用自动分词将会误切分成 “软盘/n驱动器/n”,使得复合概念的非分类关系抽取更为有效。
跟踪分析抽取过程发现,影响实验效果的主要因素有:①测试文本的选取。选择不当将导致召回率低,非分类关系对识别效率下降。如新闻类文本中与专业领域密切相关的内容偏少,因此,应以科普类或专业研究类文章为主。②句子中心词的选用。有些动词 (如 “是”、“使”)作为中心词时,所构成的非分类关系多是错误的,例如,句子“数据库管理系统是一种系统软件。”,抽取后得到< “数据库管理系统”,“是”,“系统软件”>,显然数据库管理系统与系统软件是上下位的分类关系。而以 “是”为谓语的句子是一种常见的中文句子结构,因此,有必要针对中心词建立一个停用词表。
另外,实验中同义关系的抽取不是很理想,主要原因是语法分析标注同位关系时,因中文表述方式的多样性而无法正确识别,如,“能力成熟度模型 (CMM)”表述方式被识别为同位关系,但是 “CMM (能力成熟度模型)”将被标注为其它关系。
5 结束语
本文提出了一种基于语义依存分析的中文非分类关系抽取方法。该方法将语义角色标注和依存关系分析相结合,从句中提取中心词和与之依存的语义角色构成的动词框架,通过计算动词框架的语义相似度,获得充当不同语义角色的概念间非分类关系,并用中心词标注之。下一步将进一步探讨,如何结合中文语法特点,更有效地利用句子语义依存结构中的信息,提高关系抽取的效果。
[1]DU Xiaoyong,LI Man,WANG Shan.A survey on ontology learning research [J].Journal of Software,2006,17 (9):1837-1847(in Chinese).[杜小勇,李曼,王珊.本体学习研究综述 [J].软件学报,2006,17 (9):1837-1847.]
[2]XIANG Yang,ZHANG Bo,HAN Jie.Agent driven intelligent construction of Chinese ontology [J].Computer Engineering and Applications,2009,45 (10):133-137 (in Chinese).[向阳,张波,韩婕.Agent驱动的中文本体智能构建研究 [J].计算机工程与应用,2009,45 (10):133-137.]
[3]WANG Suihua,ZHAO Ailing,MA Weiwei.Approach to extracting non-taxonomic relationships for Chinese ontology from web [J].Computer Engineering and Design,2010,31 (2):451-454(in Chinese).[王岁花,赵爱玲,马巍巍.从 Web中提取中文本体非分类关系的方法 [J].计算机工程与设计,2010,31 (2):451-454.]
[4]WEN Chun,SHI Zhaoxiang,XIN Yuan.Chinese Non-taxonomic relation extraction based on extended association rule[J].Computer Engineering,2009,35 (24):63-65 (in Chinese).[温春,石昭祥,辛元.基于扩展关联规则的中文非分类关系抽取 [J].计算机工程,2009,35 (24):63-65.]
[5]Johansson R,Nugues P.The effect of syntactic representation on semantic role labeling[C].Manchester,UK:Proc of the 22nd International Conference on Computational Linguistics,2008.
[6]CHEN Yaodong,WANG Ting,CHEN Huowang.Shallow semantic parsing research [J].Journal of Computer Research and Development,2008,45 (zl):321-325 (in Chinese).[陈耀东,王挺,陈火旺.浅层语义分析研究 [J].计算机研究与发展,2008,45 (zl):321-325.]
[7]CHE Wanxiang,LI Zhenghua,HU Yuxuan,et al.A cascaded syntactic and semantic dependency parsing system [C].Manchester,UK:Proc of CoNLL,2008.
[8]LIU Ting,CHE Wanxiang,LI Sheng.Semantic role labeling with maximum entropy classifier[J].Journal of Software,2007,18 (3):565-573(in Chinese).[刘挺,车万翔,李生.基于最大熵分类器的语义角色标注 [J].软件学报,2007,18 (3):565-573.]
[9]PENG Hui,SHI Zhongzhi.Matching algorithm of semantic web service based on similarity of ontology concepts [J].Computer Engineering,2008,34 (15):51-53 (in Chinese). [彭晖,史忠植.基于本体概念相似度的语义Web服务匹配算法[J].计算机工程,2008,34 (15):51-53.]
[10]LIU Huaijun,CHE Wanxiang,LIU Ting.Feature engineering for Chinese semantic role labeling [J].Journal of Chinese Information Processing,2007,21 (1):79-84 (in Chinese).[刘怀军,车万翔,刘挺.中文语义角色标注的特征工程[J].中文信息学报,2007,21 (1):79-84.]
[11]LIU Baoyan,LIN Hongfei,ZHAO Jing.Chinese sentence similarity computing based on improved edit-distance and dependency grammar [J].Computer Applications and Software,2008,25 (7):33-34 (in Chinese). [刘宝艳,林鸿飞,赵晶.基于改进编辑距离和依存文法的汉语句子相似度计算 [J].计算机应用与软件,2008,25 (7):33-34.]
[12]Ciramita M.Unsupervised learning of semantic relations between concepts of a molecular biology ontology [C].Edinburgh,UK:Proc of the 19th International Joint Conference on Artificial Intelligence,2005.
[13]Kavalec M,Svatek V.A study on automated relation labeling in ontology learning [C].Ontology Learning From Text:Methods Evaluation and Applications.Amsterdam:IOS Press,2005.
[14]WEN Xu,ZHANG Yu.Syntactic structure parsing based Chinese question classification [J].Journal of Chinese Information Processing,2006,20 (2):33-39 (in Chinese). [文勖,张宇.基于句法结构分析的中文问题分类 [J].中文信息学报,2006,20 (2):33-39.]
[15]YANG Jianming.Ontology learning method based on semantic dependency [D].Hefei:University of Science and Technology of China,2008(in Chinese).[杨建明.基于语义依存的本体学习方法 [D].合肥:中国科学技术大学,2008.]
