基于AST的代码抄袭检测方法研究
2012-11-30刘呈龙贾胜颖张丽萍刘东升
刘呈龙,贾胜颖,张丽萍,刘东升
(内蒙古师范大学 计算机与信息工程学院,内蒙古 呼和浩特010022)
0 引 言
程序设计是高等院校计算机专业教学中不可或缺的实践与教学环节。作业以电子文档形式提交给教师是程序设计类课程的共同特点。学生完成作业的过程中从网上下载或拷贝其它同学的代码的现象愈演愈烈。因此,抑制抄袭现象、提高程序设计类课程的教学质量越来越重要。这就需要准确、快速的抄袭检测方法,因此,对有效的抄袭识别技术及其应用研究有重要的意义。本文主要研究基于AST的代码抄袭检测方法。首先将代码转换成AST;然后运用序列匹配[1]的方法进行相似度的计算;提取相似部分的特征生成空间向量,对生成的向量聚类分析,找到 “抄袭团伙”。
1 相关的代码抄袭检测方法
国外对程序相似度相关研究始于20世纪70年代。1976年,Halstead首先提出了用属性计数AC(attribute counting)的方法检测程序代码的抄袭问题。一年后,基于AC的代码抄袭检测系统诞生[2]。而随着程序的结构信息被加入到检测中,出现了基于程序结构的检测方法SM(structure metrics),虽然增加了空间和时间的开销,但大大提高了检测的精度。而现在的代码复制检测系统大多采用AC与SM相结合的检测方法。如德国Karlsruhe大学的JPlag[3]和美国Stanford大学的 Moss系统[4]等。
国内方面也取得了一些成果,有人提出了基于编译优化和反汇编的程序相似性检测方法[5]以及一种Java源代码和字节码都适用的剽窃检测方法[6]。内蒙古师范大学分别对源代码层面和非源码层面的相似度检测进行了较深入的研究,并取得了一些进展[7-10]。但目前国内大多数的研究仅停留在代码的相似度计算上,对相似度计算的结果进行分析、聚类的研究较少,很少能找出 “抄袭团伙”。本文在相似度计算的基础上使用聚类[11]的分析方法,对AST中的特征信息进行分析,在找到 “抄袭团伙”方面做出一些尝试。本研究运用比源代码具有更多结构信息的AST为模型,运用计算生物学中序列匹配算法得出代码相似度,而后提取特征进行聚类分析,从而找到 “抄袭团伙”。
2 基于AST的代码抄袭检测方法
基于AST的抄袭检测方法分3个阶段:代码形式化;相似度计算;聚类分析。如图1所示。源程序通过语法分析工具生成AST,存储AST序列生成序列表,进行相似度计算,提取相似部分特征生成特征向量,运用聚类的方法对特征向量进行分析。
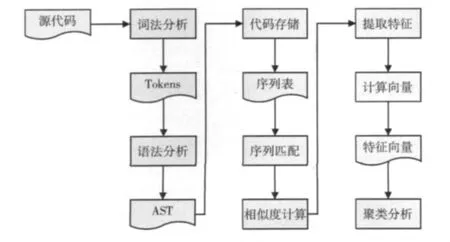
图1 基于AST的代码抄袭检测流程
2.1 代码形式化
本文采用AST作为相似度检测的模型,主要基于以下考虑:AST是程序的编译或者解释过程中的一个中间数据结构,从语法树中既可以体现出结构信息也可以保留源程序中的属性特征,为抄袭检测提供更加准确、全面的信息。生成AST有多种方法,本文采用ANTLR(another tool for language recognition)对源代码解析生成AST。
ANTLR是一个语法分析工具[12],使用ANTLR来生成AST主要因为:①ANTLR为开源的语法分析器,便于进行二次开发,优化生成的语法树。②ANTLR生成的AST中的冗余信息较少,便于阅读与优化。③ANTLR可以使用不同的文法文件生成不同的语法分析器,从而对不同的语言进行分析有很高的灵活性。
使用ANTLR生成AST分为两步[13]第一步,读取解析文件,在读取分析文法文件中的规则后,ANTLR可以生成相应词法和语法分析器;利用生成的词法分析器,先将输入的程序代码转换成由短语组成的流,再作为语法分析器的输入从而得出最终的结果——AST。通过遍历AST生成AST的序列代码段。例如:源代码1.cpp经过ANTLR解析后得到的AST如图2所示。
我们将源程序中的每一行代码与生成的AST进行比对发现,AST中包含了源代码的属性特征与结构特征,见表1所示。

图2 1.cpp对应的AST
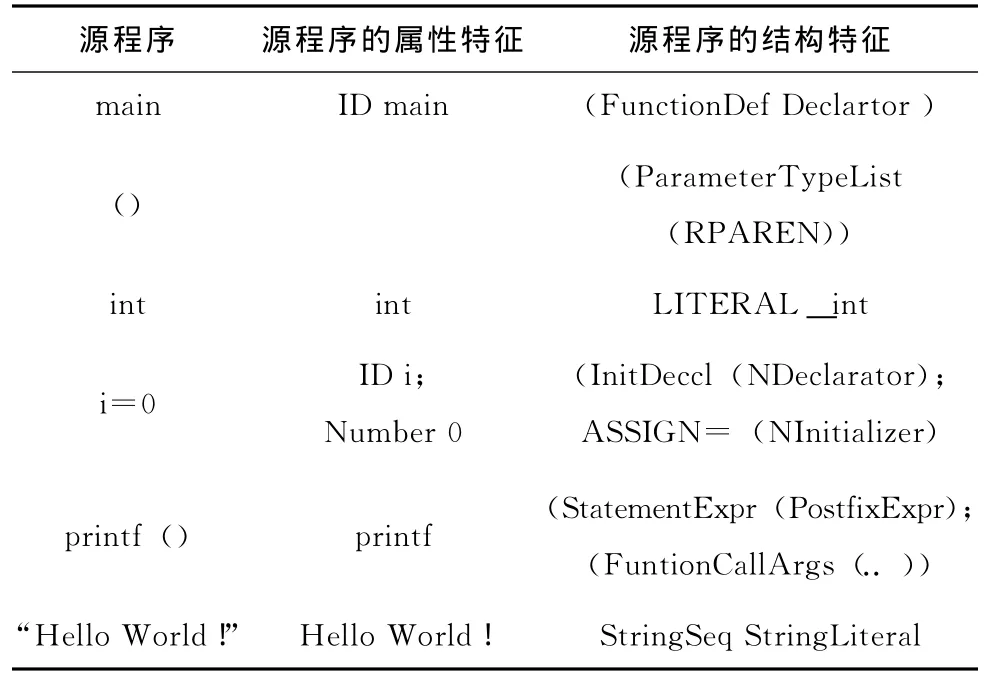
表1 源程序与AST特征对照
2.2 相似度计算
根据源代码抽象表示方式和相似度检测粒度选取层次的不同,所采用的检测技术也不同,常见的检测技术包括基于文本、基于树和基于图的检测方法。
本文采用先将源代码转换成AST,再对AST进行遍历生成代码序列,接下来采用基于序列匹配的代码相似度检测方法进性抄袭检测,同时兼顾速度和语义两个方面的要求,从而获得准确率更高、时间空间效率更好的检测结果。本文将比对粒度固定在函数级别,用函数所对应的AST序列进行比对。这样做有两个个好处:①将检测粒度定为以函数为单元,生成的AST序列不会过长,降低匹配算法的空间时间消耗;②将AST的序列进行比对,比源代码层面含有更多的结构信息,去除了源代码中如注释、空白符等对比对的干扰,提高了比对精度。
2.2.1 AST序列的存储
保存下来的代码序列包含了AST中的结构信息,还包含如文件名、函数名、程序行号等内容。本文把生成的代码序列存入Hashtable中,Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空 (non-null)的对象都可作为key或者value。对生成的AST进行优化,减少AST的长度,即把结点token名称的长度统一为两个字母,存入Hashtable中。生成的Hashtable如图3所示。
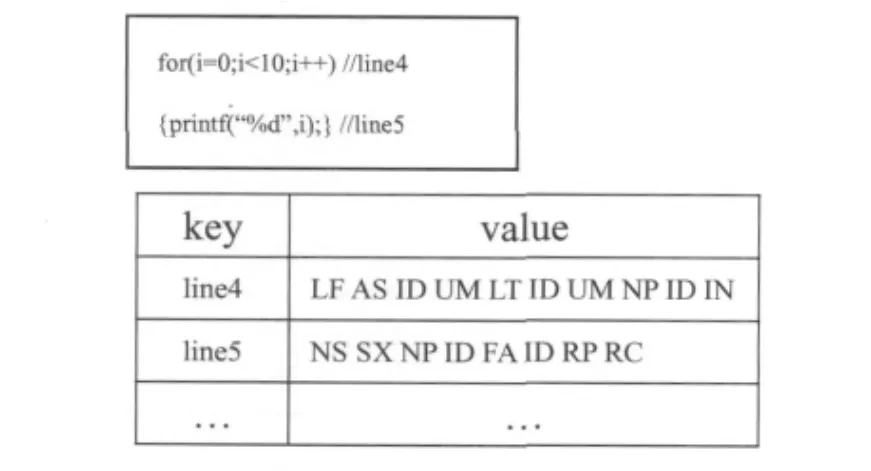
图3 AST序列存储格式
2.2.2 序列匹配
运用SmithWater-man算法进行相似度计算,得到程序相似度值,并进行有效性及适用性评价。该算法主要用于计算生物学领域,在寻找序列最优相似匹配方面有较好的效果。该算法首先以两个匹配序列为横纵坐标建立矩阵,然后运用迭代的方法生成分矩阵,其中包含着所有可能相似的分值,比较各分矩阵的分值,其中最高的为最优匹配。
对于给定的两条序列S=s1,s2,s3,…,sn和 T=t1,t2,t3,…,tm,它们对应的长度分别n和m,根据动态规划的算法,我们需要构造一个大小为 (n+1)× (m+1)的矩阵用来存放所有可能的比对结果,矩阵可以通过如下的公式计算得到:
(1)初始条件
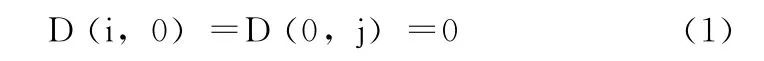
(2)递归关系
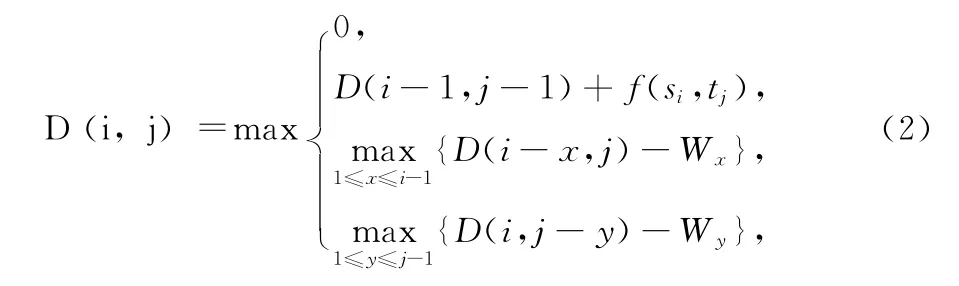
式中:1≤i≤n,1≤j≤m,Wx——在序列中添加一个长度为x的空位的罚分,Wy——在序列中添加一个长度为y的空位的罚分。运用动态规划的方法回溯寻找高分分矩阵即最佳匹配。分矩阵分数计算伪代码如图4所示。
2.2.3 代码的相似度计算
运用Smith Water-man算法可以得到代码X与Y的最大匹配集合,通过该集合可以计算两程序的AST序列的相似度,利用该结果运用以下公式度量两个对应的程序代码X,Y的相似度。

图4 Smith waterman算法分矩阵计算
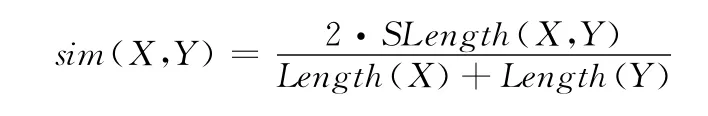
式中:X,Y——待比对序列。SLength (X,Y)——X与Y最大匹配集合的字符串长度。Length(X)——X中字符的个数。Length(Y)——Y中字符的个数。
2.3 聚类分析
相似度计算之后,通过保存下来的源程序的行号在二元序列表中找到相应的AST代码序列生成特征向量用于聚类分析,本文运用向量空间模型VSM (vector space model)来进行聚类分析。VSM是由Gerard Salton于1969年提出的[14],广泛应用于信息检索领域。该模型的主要思想是:将文档抽象为空间中的一个点,而空间的维数及点的坐标则由文档中的特征词和该词在文档中的权重决定的。VSM模型与空间映射关系表2所示。

表2 VSM模型与空间的映射关系
每一篇文档都可以用其中的一些有代表性的词或短语来表示,空间向量就是由这些词及其权重构成的:(W1,j,W2,j,W5,j…Wn,j)。其中,Wi,j为文档Di中词条i的权重。TF表示词条i在文档Di中出现的次数。
权重计算
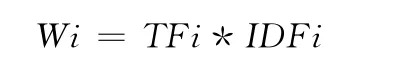
IDF的计算
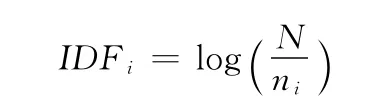
式中:N——文档集合中所有的文档数目,ni——整个文档集合中出现过词条i的文档的总数。
本文提取AST序列中的特征信息生成VSM,以函数为例,特征信息包括:FunctionDef函数声明、FunctionCall函数调用等特征。计算取得VSM后运用k-medoids算法[15]进行聚类分析。该算法属于划分方法中的一种常用的聚类算法并有较好的抗噪能力。具体算法如图5所示。

图5 k-medoids算法流程
3 实验与分析
3.1 抄袭检测实验
实验对12对C语言程序进行了测试,12对程序分别对应了12种抄袭手段,包括:完整拷贝;修改注释;重新排版;标识符重命名;代码块重排序;代码块内语句重排序;常量替换;改变表达式中的操作符或者操作数顺序;改变数据类型;增加冗余的语句或者变量;表达式拆分;替换控制结构为等价的控制结构。代码检测结果与Moss系统对比结果如图6所示。

图6 测试结果与Moss对比
从实验结果可以看出本文介绍的基于AST的抄袭检测方法对不同的抄袭行为有较好的检测效果,尤其在对完全拷贝、修改注释、常量替换、替换控制结构为等价的控制结构等方面效果显著。但是在检测增加冗余的语句或者变量、表达式拆分等抄袭手段时仍然有很多的误差。主要原因是冗余语句与拆分的表达式使生成的AST的长度与原型程序有较大的变化,影响了决策函数的分母,产生误差。由图7中的YX12.cpp与CX12.cpp的检测结果可以看出本方法的精度优于Moss系统。而Moss系统在检测控制结构的替换方面有较强的噪音干扰。
图7 YX12.cpp与CX12.cpp检测结果截图
3.2 聚类分析
本文对另外15份C语言程序代码进行聚类分析实验。其中包括3份原型代码,抄袭3份原型的代码各两份,其余6份分别为与原型有相同抄袭行为的代码。其中包括的抄袭方式有:程序逐行拷贝;for、while循环变换;变量名变换。代码1、4、5、10、11的抄袭方式为逐行拷贝;代码2、6、7、12、13的抄袭方式为循环替换;代码3、8、9、14、15为变量名替换。
相似度计算结果如图8所示。聚类分析实验结果表3所示。由表3的聚类分析结果可以看出基于AST的相似度检测及之后的聚类结果基本实现了对抄袭特征的分类,从而对抄袭集群进行汇总。

图8 部分程序相似度结果
4 结束语
运用了AST作为代码抄袭检测的模型,并结合生物学中序列匹配的方法进行相似度的计算。根据计算结果提取AST的特征值进行聚类分析找到 “抄袭团伙”。下一步我们的工作:①对提取的AST特征进行进一步分析同时对聚类算法进行优化,减少噪音的出现。②该实验系统实现了C代码的抄袭检测,后续只要制定和完善多语言的文法文件,实现对多语言的检测,从而提高实验系统的通用性和可扩展性。

表3 聚类结果
[1]WU Demin,CHENG Jun.Research on algorithm of pair wise alignment [J].Computer Engineering and Applications,2008,44 (36):48-50 (in Chinese).[吴德敏,陈俊.双序列比对的算法研究 [J].计算机工程与应用,2008,44 (36):48-50.]
[2]Aiken A.Moss:A system for detecting software plagiarism[EB/OL]. [2009-12-21].http://theory.stanford.edu/~aiken/moss/.
[3]Emeric K,Moritz K.JPlag:A system that finds similarities among multiple sets of source code files[EB/OL].[2009-02-01]http://www.ipd.Uni-karlsruhe.de/jplag/.
[4]Aiken A.Moss:A system for detecting software plagiarism[EB/OL]. [2009-02-01].http://theory.stanford.edu/~aiken/moss/.
[5]ZHAO Changhai,YAN Haihua,JIN Maozhong.Approach based on compiling optimization and disassembling to detect program similarity [J].Beijing University of Aeronautics and Astronautics,2008,34 (6):711-715 (in Chinese). [赵长海,晏海华,金茂忠.基于编译优化和反汇编的程序相似性检测方法 [J].北京航空航天大学学报,2008,34 (6):711-715.]
[6]LI Hu,LIU Chao,LIU Nan,et al.Method and its system of Java source and byte code plagiarism detection [J].Beijing University of Aeronautics and Astronautics,2010,36 (4):424-428(in Chinese).[李虎,刘超,刘楠,等.Java源代码字节码剽窃检测方法及支持系统 [J].北京航空航天大学学报,2010,36 (4):424-428.]
[7]LIU Dongsheng,ZHONG Mei,SHI Shumin,et al.An AST plagiarism detection model for procedural programming languages [C].The World Congress in Computer Science Computer Engineering & Applied Computing,2010:187-191.
[8]LI Yanchen,LIU Dongsheng.Suffix tree based plagiarism detection method for C code [C].International Conference on Future Computer Control and Communication,2010:210-213.
[9]ZHONG Mei,ZHANG Liping,LIU Dongsheng.Plagiarism detection algorithm based on XML for C code [J].Computer Engineering and Applications,2011,47 (8):215-218 (in Chinese).[钟美,张丽萍,刘东升.一种基于XML的C代码抄袭检测算法 [J].计算机工程与应用,2011,47 (8):215-218.]
[10]ZHANG Liping,LIU Dongsheng,LI Yanchen.Research on code copy detecting strategy and it’s evaluation mechanism based on syntax tree [J].Journal of Inner Mongolia University,2010,41(5):594-600 (in Chinese).[张丽萍,刘东升,李彦臣.基于语法树的程序代码复制检测方法及其评价机制的研究[J].内蒙古大学学报,2010,41 (5):594-600.]
[11]XIONG Yun.The research on biological sequential pattern mining and clustering [D].Shanghai:Fudan University,2007(in Chinese). [熊赟.生物序列模式挖掘与聚类研究[D].上海:复旦大学,2007.]
[12]XIAO Li,XIAO Jingzhong.Structure of field language base on ANTLR [J].Computer Science,2011,38 (7A):91-92(in Chinese).[肖丽,校景中.基于ANTLR的领域语言构造 [J].计算机科学,2011,38 (7A):91-92.]
[13]XIN Tianqing.Design and implementation of code clone analysis system based on sequence matching[D].Dalian:Dalian Polytechnic University,2008 (in Chinese). [辛天卿.基于序列匹配的代码克隆分析系统设计与实现 [D].大连:大连理工大学,2008.]
[14]YAO Qingyun.Research of VSM-based Chinese text clustering algorithms [D].Shanghai:Shanghai Jiaotong University,2008(in Chinese).[姚清耘.基于向量空间模型的中文文本聚类方法的研究 [D].上海:上海交通大学,2008.]
[15]XIA Ningxia,SU Yidan,QIN Xi.Efficient k-medoids clustering algorithm [J].Application Research of Computers,2010,27 (12):4517-4519 (in Chinese).[夏宁霞,苏一丹,覃希.一种高效的K-medoids聚类算法 [J].计算机应用研究,2010,27 (12):4517-4519.]
