原始RFID数据流上复杂事件处理研究
2012-11-30李强,陈琳
李 强,陈 琳
(1.西北工业大学 软件与微电子学院,陕西 西安710129;2.西北工业大学 计算机学院,陕西 西安710129)
0 引 言
RFID作为一种先进的自动识别技术已经广泛应用于诸如供应链管理、产品流水线跟踪、物品监管、医疗监控等领域。复杂事件处理[1](complex event processing,CEP)是RFID的重要应用,主要是通过将简单事件进行关联,得到语义更复杂的事件。现有的RFID复杂事件处理假设数据是准确的。实际上,由于读写器本身和环境的影响,RFID数据流往往是不准确的。不准确的RFID数据流主要有下面3种情形:
(1)重复读。为了更好地覆盖RFID应用的读写区域,往往在一个逻辑点安装多个天线或多个读写器。当一个带标签的对象经过这个区域时将可能产生很多对事件检测无用的、重复的RFID记录。
(2)拒真。拒真是只读取对象已经在读写器的读写范围,但由于某些原因 (如反射,干扰等)读写器不能给出该物品的标签信息。这样的信息丢失使得事件检测不能正确地给出符合条件的复杂事件。
(3)纳伪。纳伪是只本不应该在读写器读写范围的物品由于某些原因 (如信号反射、读写器的读写范围较大等)而被该读写器读到。纳伪数据的产生使得事件检测给出错误的复杂事件。
对于RFID数据流中的这些不准确信息,应用往往是在中间件层对数据进行清洗和平滑,去除重复、纳伪的标签信息,并尽量将拒真数据补齐。由于RFID数据量的巨大,对于数据流进行一场扫描进行数据清洗后再一次进行复杂事件处理的代价是很大的。再由于复杂事件处理的实时性要求[2],在数据清洗后进行事件检测有可能使一些复杂事件失去意义。针对上述问题,本文提出在原始数据流上直接进行复杂事件处理的方法,利用事件间的各种约束,在一遍扫描数据流的基础上对原始数据流进行清洗,同时进行事件检测,实验结果表明,该算法的CPU和内存耗费明显优于经过数据清洗后的算法,且算法的吞吐量和原算法相当。
1 概念描述及相关工作
RFID原始数据 (简单事件)是一个三元组: (RID,OID,time)。RID是读写器的标识,在应用中为某逻辑点;OID是要识别的对象的标识,这个标识在全球是唯一的,且要遵循相关标准;time为读写器读取标签的时间。
复杂事件则是将原始事件通过一定的规则和实际应用的逻辑关联起来构成的事件。复杂事件具有更丰富的语义,可以为上层应用提供更多的信息。
复杂事件检测早在主动数据库领域已经进行了广泛研究[3],但应用于RFID数据流却是最近几年[4-6],这些模型和方法中,假设处理的数据是经过数据清洗,复杂事件处理引擎再处理这些数据。由于前期数据主要是去除重复[7]、纳伪[8]事件,没有结合到复杂事件查询本身的语义和现实场景的信息。RFID应用场景中,数据清洗往往是在前端数据采集上进行。文献 [9]提出了一种基于概率统计模型的数据清洗模型,通过事件的统计信息调整滑动窗口的大小,来保证数据的完整性和动态性。文献 [10]提出了一种用SQL-TS来定义清洗规则清洗方法,但此方法假设RFID数据存储于RMDB中,其操作均为离线,比如离线查询与离线清洗,因此不能用于实时的复杂事件处理。
2 RFID数据清洗及复杂事件示例
RFID数据流中,简单事件序列可表示复杂事件,当然须在合理的时间窗口内。下面介绍经典的SASE[11]算法:
SASE算法以其基于NFA的特点,在处理方法上面具有更大的灵活性,且可以对大数据量可实施优化。在SASE算法中,一个查询对应一个自动机,可将不同简单事件分散在不同自动机中,状态间迁移通过对象引用来完成[12]。当NFA达到末态,可根据对象引用回溯输出复杂事件。图1是SASE方法示例。其中简单事件用小写字母表示,事件类型用大写字母表示,小写字母的下标表示简单事件的时间戳,如bi表示事件类型为B且时间戳为i的简单事件。
下面使用一个最为常见的RFID应用场景说明RFID数据清洗及复杂事件处理过程。
在零售业中 (如沃尔玛、麦德龙等),检测一个物品被出售的过程可以用SASE语言描述为如下的事件查询Q1:
EVENT SEQUENCE (SHELF_READING shfr,
COUNTER_READING corr,EXIT_READING extr)
WHERE shfr.OID =corr.OID =extr.OID
WITHIN 1hour

图1 SASE方法框架
这个查询的意思是:一小时内物品被先后 (SEQ定义)货架上、结账处和出口被读写器读到,则该物品通过了合法的零售逻辑。如果物品的标签信息只在货架和出口处被读到,而未在结账处未被读到,则要报警说明物品可能被盗 (即非事件)。在这里物品在货架、结账处和出口被读到的信息就是所谓的简单事件,而通过上面的语言检测到的序列则是我们感兴趣的复杂事件。SASE检测上面的复杂事件的模型是NFA。
例如,当前时间窗口的RFID数据流为:S1= (a1,1;a2,2;a1,3;a2,4;a1,5;b1,6;b1,7;c1,8;d2,9;b2,11;c2,12),其中Ei,j表示标识为i的标签在j时刻被读写器读到,E为事件类型。对于RFID数据流S1,有3个事件类型,分别为A,B,C。a1,1表示编号为1的物品在时刻1被A处的读写器读到。数据流S1主要存在的不准确性是重复读和纳伪的数据。对上S1进行数据清洗,得到的数据流S′1= (a1,1;a2,2;b1,6;c1,8;b2,11;c2,12)。事件查询 Q1在S′1上所得到的复杂事件为:(a1,1→b1,6→c1,8),(a2,2→b2,11→c2,12)。
3 集成数据清洗的事件检测引擎
可以看到,这里的数据清洗去除了不确定的信息,但存在的问题是:RFID数据流可能为很多应用程序使用,每个应用程序所提交的查询是不一样的,如有的是计算聚集,有的复杂事件处理,复杂事件处理的事件模式又可能不一样。这就导致单一的数据清洗算法不适用多个RFID的应用。且数据清洗和复杂事件处理分别要扫描一次数据流,这就加重了系统的资源的开销。我们设计了一个集成数据清洗的复杂事件检测模型,其架构如图2所示。
“事件定义”模块是用来定义用户感兴趣的模式,可使用如SASE或Cayuga等事件检测语言描述,当前我们主要针对的是SASE语言定义的查询;“清洗逻辑解析器”则根据事件查询模式和实际应用的规则生成数据清洗的检测规则,实际应用规则是指将应用场景抽象为一个 (有向)图的模型,根据物品在图上点与点间移动的统计信息得到一定的规则,将这些规则应用于数据清洗和事件检测。“事件检测算法”里面集成了清洗规则和事件检测模型,常见的模型有NFA,图模型和Petri网,用户也可以插入自己定义的算法,本文使用的是和SASE类似的NFA模型。结合清洗规则事件检测算法如算法1所示。

图2 集成数据清洗的复杂事件检测引擎架构
算法1:结合清洗规则的事件检测算法
输入:原始RFID数据流,事件pattern,清洗规则,时间窗
输出:复杂事件
(1)建立一个Hash-table,记录原始事件的TagID和状态;
(2)对pattern中的每个事件类型,建一堆栈;
(3)对于每一个原始事件,通过哈希函数将其映射到Hash-table中对应位置;如果该位置上有数据,且当前状态和新状态的交为pattern的字串,则更新状态。如果没有状态改变,则可知当前数据为重复数据;如果状态发生改变且不是pattern的字串,则可判断当前数据为false positive,丢弃;
(4)将pattern字串对应的事件放入堆栈,更新前驱指针;
(5)当Hash-table状态达到终态时 (满足查询),当前事件通过TagID搜索对应的堆栈前向指针将复杂事件输出;
(6)清空已输出事件对应的栈空间和 Hash-table;//可以使用批处理的删除方法避免内存抖动
(7)重复步骤 (3)-(6),直至整个窗口的数据被处理完。
4 实验与分析
为了验证上面的事件检测引擎的性能,我们设计了一个数据生成器 (RFID的实验数据没有标准集,且从设备中采集大量的数据所需的周期很长)。数据生成器模拟的是一个超市的环境。实验采用的复杂事件查询是Q1。所有算法用C++实现,硬件环境是PC Pentium IV 2.8GHz CPU,1GB内存。我们主要对比两个算法:一个算法是在数据清洗后进行事件检测,但没有用到一些逻辑规则[13];另外一个算法是直接在原始数据流上进行事件检测[14],但用到了一些统计信息和逻辑规则对数据进行清洗。算法对比的指标为CPU时间耗费和内存占用率。本文用到的统计信息是基于这样的观察:物品从货架到结账处的时间近似服从正态分布,当拿到一个物品在货架上的读数后,可以通过这样的统计信息推断物品在结账处的可能时间,那么在结账点时间前的重复数据就可只保留一次,而结账点后的非出口处物品被其他读写器交叉读到的数据都可过滤掉,这就同时达到了数据清洗和事件处理的目的。
我们生成了两类数据集:一类是RFID数据流中含有重复的标签,另外一类是RFID数据流中存在纳伪的数据。在这两类数据上,数据清洗和复杂事件处理的性能对比如图3和图4所示。
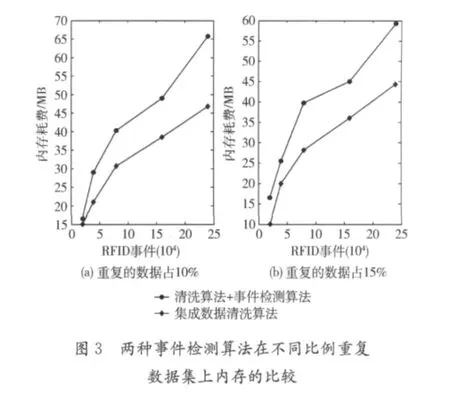

从图3和图4可以看出,数据清洗后进行复杂事件处理的算法比直接在原始数据流上进行事件检测的算法要占用很多的内存。这是因为,数据清洗要单独占系统的资源,复杂事件处理一遍数据流要占用系统资源。两次扫描数据流且没有利用一些参考信息是占用更多系统资源的主要原因。
图5和图6为两种算法CPU时间耗费对比。
在进行数据清洗时,RFID数据要时往往要求保证顺序性,这是因为RFID数据的顺序对某些监控场景是很关键的 (如在医疗监控场景中,医务人员操作的顺序对医疗事故的鉴定很关键)。保证数据流的顺序性需要额外的系统开销。本文借鉴文献 [15]的算法来保证数据的顺序。


实验中设定纳伪数据的比例为1%和4%是因为纳伪数据在实际应用中不可能占整个数据的大部分,否则这个RFID应用的设计就是失败的,但由于RFID读写器和环境的影响,系统肯定会存在一定比例的纳伪数据。重复数据是RFID的主要特性之一。所以本文关注RFID的这两类数据特征。实验中采用的规则除了一些统计特性外,还有就是对整个应用场景的抽象:我们把一个应用场景抽象成一个有向图,利用有向图边间的关系,对RFID的数据流进行过滤,达到快速检测事件和去除冗余的中间结果的目的。
5 结束语
本文利用事件查询的语义约束和实际应用的逻辑规则,在原始的数据流上进行事件检测,避免了一般的事件处理算法先进行简单的数据清洗,再进行事件检测所带来的巨大系统资源开销;然后我们编程实现了该方法并且将其集成到复杂事件处理引擎中;最后通过仿真实验验证了本文所提方法的正确性与高效性。下一步的主要工作是将复杂事件处理引擎加入到更为底层的RFID中间件中,通过真实场景所遇到的问题进一步完善我们的复杂事件处理引擎。
[1]GU Yu,YU Ge,ZHANG Tiancheng.RFID complex event processing techniques [J].Journal of Computer Science and Frontiers,2007,1 (3):255-267 (in Chinese)[谷峪,于戈,张天成.RFID复杂事件处理技术 [J].计算机科学与探索,2007,1 (3):255-267.]
[2]LEE C H,CHUNG C W.Efficient storage scheme and query processing for supply chain management using RFID [C].Proc of the 27th ACM SIGMOD Conf.New York:ACM,2008:291-302.
[3]Roussos G.Enabling RFID in retail[J].IEEE Computer,2006,39 (3):25-30.
[4]LI M,LIU M,DING L P,et al.Event stream processing with out-of-order data arrival[C].27th ICDCS Workshops.Los Alamitos,CA:IEEE Computer Society,2007:67-74.
[5]Chandramouli B,Goldstein J,Maier D.High-performance dynamic pattern matching over disordered streams[J].PVLDB,2010,3 (1):220-231.
[6]Johnson T,Muthukrishnan S,Rozenbaum I.Monitoring regular expressions on out-of-order streams [C].Proc of the 23rd ICDE Conference.Los Alamitos,CA:IEEE,2007:1315-1319.
[7]LIU M,LI M,Golovnya D,et al.Sequence pattern query processing over out-of-order event streams [C].Proc of the 25th ICDE Conference.Los Alamitos,CA:IEEE,2009:784-795.
[8]Re C,Letchner J,Balazinska M,et al.Event queries on correlated probabilistic streams[C].Proc of the 27th ACM SIGMOD Conference.New York:ACM,2008:715-728.
[9]Shawn R Jeffery,Minos Garofalakis,Michael Franklin.Adaptive cleaning for RFID data streams [C].Proc of the 20th VLDB.Seoul Korea:ACM,2006:163-174.
[10]RAO Jun,Sangeeta Doraiswamy,Hetal Thakkar,et al.A deferred cleansing method for RFID data analytics [C].Proc of the 20th VLDB.Seoul Korea:ACM 2006:175-186.
[11]WU E,DIAO Y,Rizvi S.High-performance complex event processing over streams[C].Proc of the 25th ACM SIGMOD Conference.New York:ACM,2006:407-418.
[12]CHEN Yuan,LI Zhanhuai,CHEN Qun.Complex event processing over unreliable RFID data streams [J].Journal of Application Research of Computers,2009,26 (7):2537-2539(in Chinese).[陈远,李战怀,陈群.不可靠RFID数据上的复杂事件处理研究 [J].计算机应用研究,2009,26(7):2537-2539.]
[13]MEI Y,Madden S.ZStream:A cost-based query processor for adaptively detecting composite events[C].Proceedings of the 35th SIGMOD International Conference on Management of Data.New York:ACM,2009:193-206.
[14]Aleri CEP 3.0 [EB/OL].[2010-06-01].http://www.aleri.com/.
[15]WANG F,LIU S,LIU P,et al.Bridging physical and virtual worlds:Complex event processing for RFID data streams [C].10th International Conference on Extending Database Technology.Berlin Heidelberg,Germany:Springer,2006:588-607.
