基于统计和结构特征的手写数字识别研究
2012-11-30双小川
双小川,张 克
(中国矿业大学 计算机科学与技术学院,江苏 徐州221116)
0 引 言
手写数字识别是光学字符识别技术领域的重要研究方向,在邮政编码、财务报表、银行票据等方面有着广泛应用。由于手写数字随意性大,经常出现连笔、断笔等现象,识别精度不高。近年来,国内外研究者提出了一些识别方法,大致可分为两类[1]:基于统计特征和基于几何结构特征的方法。统计特征通常包括点密度、特征区域等,特点是易于训练;几何结构特征通常包括圆、端点、交叉点、轮廓和凹凸性等,特点是可以描述数字的结构。两种特征各有优劣。几何结构特征因手写数字的随意性而改变,因此需要进行许多细节处理;统计特征可降低书写随意性的干扰。
提高手写数字识别率的重要方法是提取数字的可靠特征和设计对应的识别算法。目前的特征提取方法[2]有逐像素特征提取法[3]、骨架特征提取法[4]和垂直方向数据统计特征提取法[5]等。这些特征提取值因手写数字的随意性而产生偏差,需要进行细节处理,往往带来较大的计算复杂度和识别精确度不高。这些方法适应性不佳[6]。
针对特征提取方法不佳,本文提出了新的特征提取方法,从统计和结构两方面来提取特征。统计特征包括数字的空间,旋转和层次特征。其中旋转特征,改进了以前单一向横轴或纵轴投影的局限性。可以使手写数字沿任意直线投影,计算投影在在直线上各区间的像素比例。由于数字的形态不相同,不同数字投影的像素比例不同,从而实现手写数字的识别。提取手写数字的结构特征,包括端点、分支点和交叉点。结合统计和结构特征,降低了随意性的干扰,利用LibSVM算法对提取的数字特征进行训练识别,达到很高识别率。
1 基于组合统计特征的预处理
手写数字形变复杂,噪声多。在提取特征之前,需要对手写数字进行必要的预处理。本文预处理包括去除图像噪声、二值化图像和提取数字的外界矩形框。
常用的图像去噪声方法有邻域平均法、低通滤波法、中值滤波、小波变换等。小波变换去除噪声是利用其时频局部化及小波基选择灵活性的特点,可以成功地去除信号中局部高频化的噪声。本文采用小波变换方法去除噪声,从而降低了噪声对特征的干扰。
利用OSTU算法对图像二值化。OSTU是在判决分析最小二乘法原理的基础上,推导得出的自动选取阀值的二值化方法。基本思想是将图像直方图用某一灰度值分割成两组,当被分割成的两组方差最大时,此灰度值就作为图像二值化处理的阀值。图像经过二值化后方便计算特征值。
提取数字的外界矩形框。外界矩形框是指包含数字的最小矩形框,如图1矩形ABCD所示。通过遍历图像数组,记录数字图像中最左、右、上、下黑点的位置坐标。根据最左和最上黑色像素位置组成矩形框的左上顶点A,最右和最下黑色像素位置组成矩形框的右下顶点C,由此可得外界矩形框ABCD。提取外界矩形框后可以消除手写数字大小对特征值的影响。

图1 手写数字0的外界矩形框
2 基于统计和结构特征的特征提取
手写数字特征的选择是决定识别率的关键。当特征值过少时,由于决定性的分类特征太少,使得分类器无法发挥学习分类的功能,造成系统无法辨识。当特征值过多时,除了使系统存储量变大之外,也会因特征值的某些部分与其他特征值冲突,从而造成系统辨识的误差。
2.1 统计和结构特征提取流程
在大量样本情况下,每一个手写数字的统计量都趋于一个常数——概率。width和height分别表示外界矩形框的宽度和高度,M表示投影的区间数,dist表示区间的长度。P(i,j)=1表示数字图像在位置 (i,j)的像素是黑色,P(i,j)=0表示数字图像在位置 (i,j)的像素是白色。d为归一化空间,max(X)和min(X)分别表示特征值xk的最大和最小值。
(1)提取数字图像的空间特征。将图像分成m×n块,统计每块子图中的黑色像素数,该步骤产生m×n个特征值。countMN(i,j)表示第 (i,j)块子图中的黑色像素总数,max(X,Y),min(X,Y)分别表示countMN(i,j)的最大和最小值。特征值xi,j的计算公式为
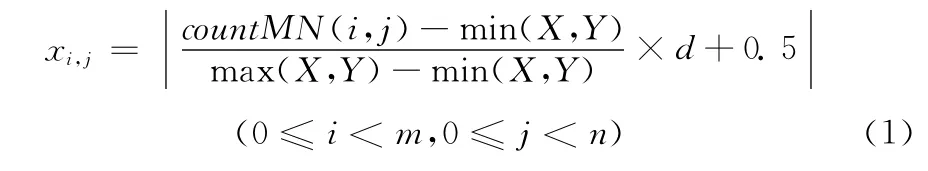
(2)提取数字图像沿横轴投影的特征。将图像沿横轴投影,投影区间M等分,计算落在每等分区间内黑色像素的总数,该步骤产生M个特征值。特征值xk的计算公式为
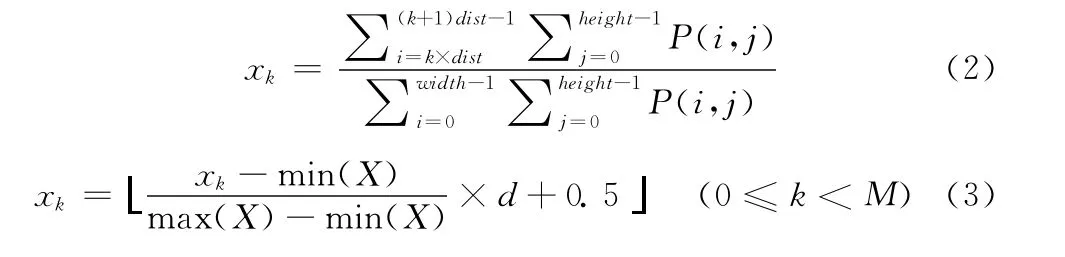
(3)提取数字图像沿某一直线投影的特征。横轴以一定角度θ逆时针旋转,将图像沿这条直线投影,投影区间M等分。计算投影在旋转直线上的每等分区间内黑色像素的总数,该步骤产生 M个特征值。count(k)为第k段投影区间内的黑色像素总数,特征值xk的计算公式为
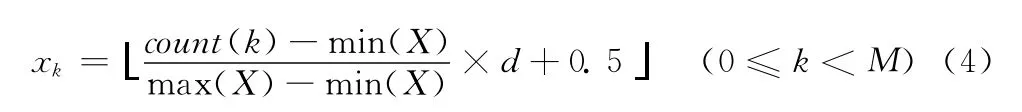
(4)提取数字图像沿旋转直线投影的特征。将步骤3中直线以角度θ继续逆时针旋转,图像沿这条直线投影,投影区间M等分。计算投影在旋转直线上的每等分区间内黑色像素的总数。重复步骤4直到旋转次数达到180/θ-1。该步骤产生 (180/θ-1)×M个特征值。特征值xk的计算公式同式 (4)。
(5)提取数字图像的层次特征。将图像从中心到边框分成L层矩形框,即将图像沿横轴、纵轴等分成2L段,从图像最内层开始统计每一层矩形框所包含的黑色像素总数,直到数字的外界矩形框为止。该步骤产生L个特征值。countL(k)为第k层内黑色像素数,特征值xk的计算公式为
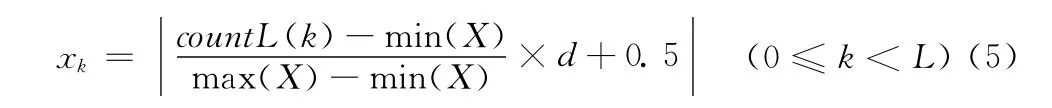
(6)提取数字图像的端点数、分支点数和交叉点数。图像为二值化的八连接图像。当连接数为1时,为断点或边界点;当连接数为2时,为连接点;当连接数为3时,为分叉点;当连接数为4时,为交叉点。共3个特征值。
通过以上步骤,提取了手写数字的空间、旋转、层次和结构四类特征。空间、旋转、层次和结构特征分别对应于特征提取流程的第1、2-4、5、6步。提取出的特征数有m×n+ (180/θ)×M+L+3个。
图2(a)将图像分成2×2块;2(b)将图像沿横轴分成4个投影区间;2(c)是将数字图像向倾斜角度为θ的直线投影,投影区间分成7段;2(d)将数字图像分为4层,从内向外分别为第1,2,3,4层。
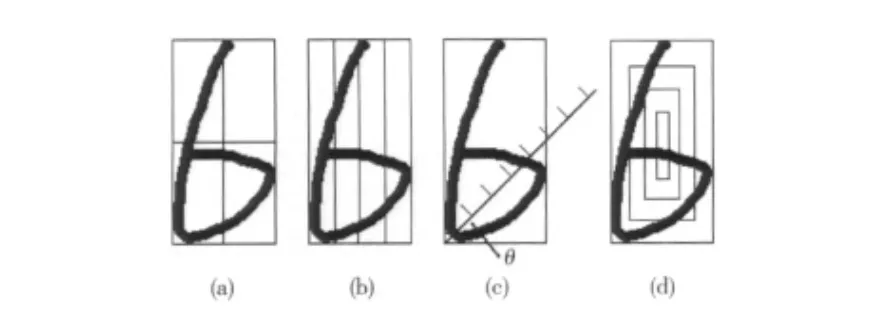
图2 数字图像6的特征提取
2.2 组合统计特征值分析
手写数字6(见图2(a))的统计特征值,设归一化参数d为20。图3(a)是手写数字6在m=4,n=2(4×2=8个特征值)时的特征值曲面图;图3(b)是在M=10时向横轴投影的特征值曲线图;图3(c)是在L=4时,矩形框由内向外包含黑色像素的特征值曲线图。当各参数确定时,手写数字有相对稳定的特征值曲线和曲面图。本文是通过这些特征值图来研究手写数字的识别。

图3 手写数字6对应的统计特征值
3 基于组合统计特征的手写数字识别方法
目前常用的识别算法有贝叶斯算法[7]、人工神经网络算法[8]、多分类器组合算法[9]、基于图论的算法[10]、支持向量机[11]、决策树和K近邻算法等。
支持向量机最初于20世纪90年代由VaPnik提出,根据有限的样本数据在学习能力和模型复杂性间寻求最佳效果,希望获得最好的应用能力。支持向量机通过非线性映射把样本空间映射到一个高维甚至无穷维的特征空间中,把样本空间中非线性可分的问题转化为在高维特征空间中线性可分的问题。支持向量机主要有升维数和线性化两步骤。升维数就是把样本向高维空间映射,向高维空间映射一般会使计算复杂化,SVM应用核函数的展开定理[12]解决了这个问题。线性化是在低维样本空间中无法线性处理的样本集,通过线性超平面来实现高维特征空间中的线性划分。
选择不同的核函数,可以生成不同的SVM,常用的核函数有以下4种:线性核函数、多项式核函数、径向基函数、二层神经网络核函数。本文利用LibSVM对手写数字分类识别。
4 实 验
手写数字选自MNIST字体库,该字体库包含60 000条训练数据和10 000条测试数据,图像像素大小为28×28。实验选择其中1500条训练数据和600条测试数据,部分选取的数据如图4所示。本文实验环境:操作系统是Windows XP;CPU是Intel Core 2,主频是1.66GHz×2;内存是2G。

图4 部分选取的手写数字
为验证组合特征的有效性,提取每类特征后用LibSVM分类算法进行识别。识别率和统计参数的关系如图5所示。本文为了确定图像分块数m×n、区间数M、旋转角度θ和图像空间层次L的值,利用LibSVM算法计算三类组合特征的识别率。m,n取值范围是 [2,8]、旋转角度是 (0,90]、区间数是 [2,14]、层次数是 [2,8]。LibSVM采用C-SVC分类法并选择线性核函数、cost=64、eps=0.01、gamma=6.67×10-4。
手写数字端点数、分支点数和交叉点数不因统计特征而改变,因此没有识别率与结构特征的关系图。观察图5,当旋转角度θ=20度、区间数M=7时,仅用旋转特征和结构特征,其识别率达到极大值98.5%;当分块数m=5,n=5时,利用旋转、空间和结构三类组合特征,其识别率达到99.1667%;当层次数L=2时,运用四类特征,其识别率达到99.3333%。计算出组合特征的识别率如表1所示。
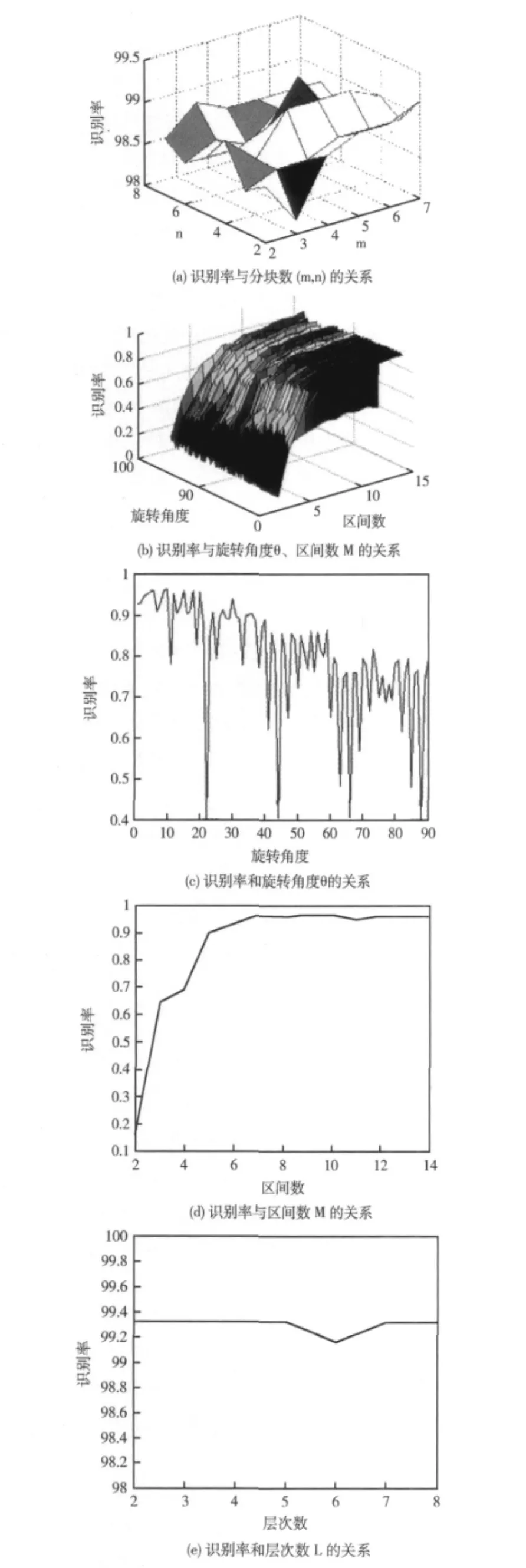
图5 识别率和统计参数的关系

表1 特征组合后利用LibSVM算法的识别率
通过LibSVM计算不同特征的识别率,发现四类组合特征效果明显,提高了手写数字识别率。确定组合特征后,由于识别率由图像分块数m×n、区间数M、旋转角度θ和分层数L共同影响。单一增长每个因子的精度时,识别率上升,但到达一定程度后下降。这是因为当特征维数过少,分类算法无法发挥学习分类的功能,当特征维数增加时,识别率上升。当特征数达到一定维数后,特征值之间有冗余和无关属性。同时特征的维数过高,即手写数字样本含有大量的特征时,还会导致:①过多的特征使手写数字训练样本集的数据量过大,分类器构造算法的训练时间过长。②过多的特征使训练集的维数过高,经训练后的分类器数值不稳定,因此分类器的分类准确率会下降。③训练集特征过多,训练后的分类器的分类规则复杂,不容易理解。这些使识别率下降。
通过Weka[13]中的分类算法对四类组合特征进行分类识别,由实验得出各分类算法的识别率和消耗时间如表2所示。表3是国内外学者对MNIST数据库进行识别的研究成果。
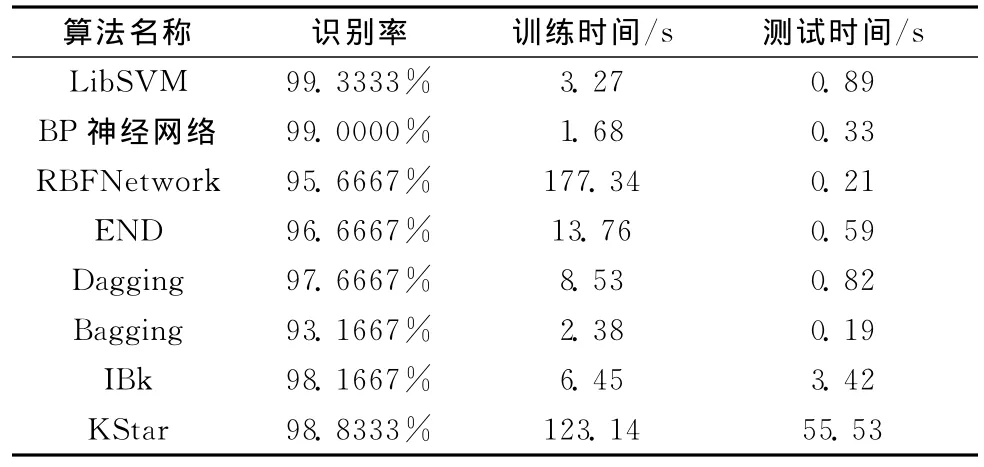
表2 不同分类算法的识别率与消耗时间
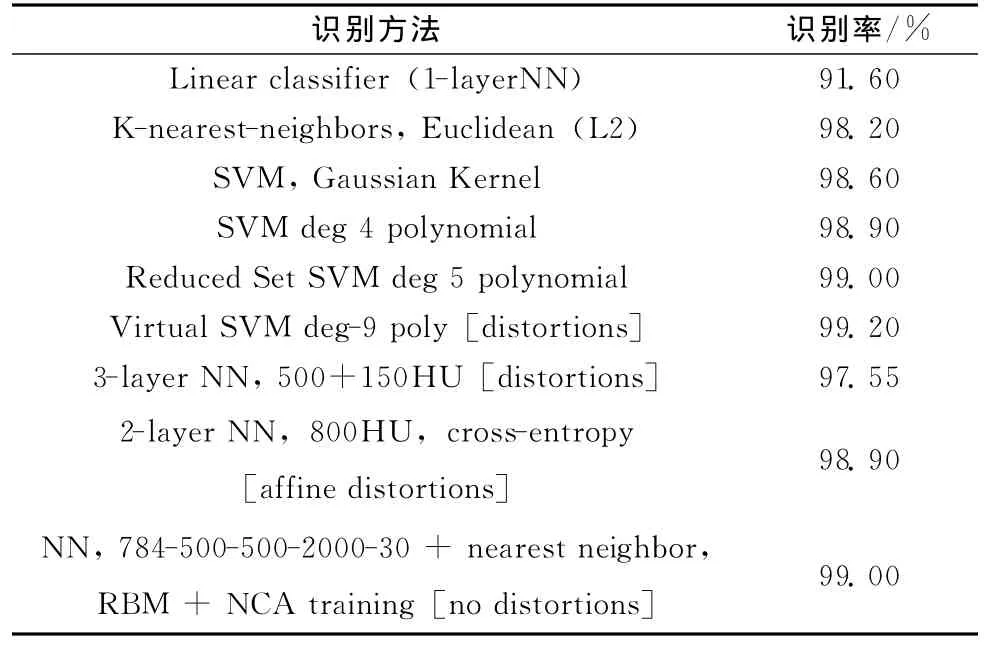
表3 现有部分方法对MNIST字体库的识别率[14]
LibSVM比BP神经网络的训练时间、测试时间长。其中BP神经网络算法的参数hiddenLayers=12,learningRate=0.3,momentum=0.1,trainingTime=10。根据表2可以选取适合需求的分类算法。按最佳参数值提取四类组合特征后,利用LibSVM分类算法得到的识别矩阵如图6所示。

图6 LibSVM分类算法的识别矩阵
本文在研究手写数字识别过程中,提出组合统计和结构特征,参数m、n、M、θ、L取值依次为5、5、7、20、2时识别率达到最大值。LibSVM分类算法的识别率高达99.3333%。
5 结束语
本文介绍了基于统计和结构的手写数字特征提取理论。统计特征包括空间,旋转和层次特征;结构特征包括端点、分支点和交叉点特征,提出了旋转统计特征和综合了特征提取方法。提取的特征全面表达了数字特点,用以区分不同的手写数字。通过实验验证了特征提取方法的有效性和正确性。然后对组合特征值利用不同的分类算法进行识别,LibSVM算法的识别率最高,超越了以前论文的识别率。以后工作中在如何降低特征的维数和设置算法中最佳的参数值还需要进一步研究。
[1]YANG Zhihua.Novel handwritten numeral recognition based on Radon transform [J].Computer Engineering and Application,2008,44 (30):13-15 (in Chinese).[杨志 华.利用Radon变换实现手写数字识别的新方法 [J].计算机工程与应用,2008,44 (30):13-15.]
[2]YANG Shuying.Pattern recognition and intelligent computing and Matlab technology [M].Beijing:Electronics Industry Press,2008:29-40 (in Chinese).[杨淑莹.模式识别与智能计算—Matlab技术实现 [M].北京:电子工业出版社,2008:29-40.]
[3]CHEN Yanping,ZHAO Lei.Minutiae extraction in fingerprint images based on 8neighborhoods region coding pursue pixel[J].Computer Knowledge and Technology,2008,4 (31):932-934(in Chinese).[陈艳平,赵磊.基于8邻域编码逐像素跟踪法的指纹细节特征提取算法 [J].电脑知识与技术,2008,4 (31):932-934.]
[4]LI Zhengguang,WU Liming.Study of skeleton extraction on machine vision recognition of failures for IC wafer [J].Semiconductor Technologys,2007,32 (4):53-56 (in Chinese).[李政广,吴黎明.骨架提取在IC晶片缺陷机器视觉识别中的研究 [J].半导体技术,2007,32 (4):53-56.]
[5]LIU Chunli,LV Shujing.Bangla handwritten numeral recognition based on blend features [J].Computer Engineering and Applications,2007,43 (20):214-215 (in Chinese).[刘春丽,吕淑静.基于混合特征的孟加拉手写体数字识别 [J].计算机工程与应用,2007,43 (20):214-215.]
[6]ZHONG Lehai,HU Wei.A new feature extraction method on handwritten digits recognition system [J].Journal of Sichuan University,2007,44 (5):1000-1004 (in Chinese). [钟乐海,胡伟.手写体数字识别系统中一种新的特征提取方法[J].四川大学学报,2007,44(5):1000-1004.]
[7]WEN Shangqing,HAO Zhifeng,LIAO Qin,et al.Intelligent offline handwritten Chinese character recognition based on Bayesian network [J].Computer Aid Edengineering,2006,15 (3):72-89 (in Chinese).[温尚清,郝志峰,廖芹,等.基于贝叶斯网络的脱机手写体汉字智能识别 [J].计算机辅助工程,2006,15 (3):72-89.]
[8]ZHANG Wei,WANG Kejian,QIN Zhen.The research of digital recognition based on artificial neural network [J].Microelectronics &Computer,2006,23 (8):206-208 (in Chinese).[张伟,王克俭,秦臻.基于神经网络的数字识别的研究 [J].微电子学与计算机,2006,23 (8):206-208.]
[9]GUI Jie,LI Xiaofeng,TANG Lei,et al.Methods of combining multiple classifiers and applications to totally unconstrained handwritten numbers[J].Computer Engineering and Design,2007,28 (11):2633-2636 (in Chinese). [桂杰,李晓风,唐磊,等.多分类器组合及其应用于手写体数字识别 [J].计算机工程与设计,2007,28 (11):2633-2636.]
[10]HONG Liurong, WANG Yaocai. Handwritten numeral recognition using graph theory and direction information [J].Computer Engineering,2006,32 (3):34-36 (in Chinese).[洪留荣,王耀才.应用图论和基元方向信息的手写数字识别[J].计算机工程,2006,32 (3):34-36.]
[11]SHANG Lei,LIU Fengjin.Handwritten number recognition based on support vector machine [J].Ordnance Industry Automation,2007,26 (3):39-41 (in Chinese). [尚磊,刘风进.基于支持向量机的手写体数字识别 [J].兵工自动化,2007,26 (3):39-41.]
[12]LI Wenqu.Application of SVM in handwritten numeral recognition[J].Journal of Quanzhou Normal University,2010,28 (4):18-21(in Chinese).[李文趋.SVM在手写数字识别中的应用[J].泉州师范学院学报,2010,28 (4):18-21.]
[13]Witten I H,Frank E.Data mining:Practical machine learning tools and techniques[M].2nd ed.San Francisco:Morgan Kaufmann Publishers,2005.
[14]YANN Lecun.Courant institute NYU [EB/OL].http://yann.lecun.com/exdb/mnist/,2009.
