基于单元度量的项目估计方法
2012-11-30吕良庆
王 晶,吕良庆
(中国科学院 空间科学与应用研究中心总体室,北京100190)
0 引 言
项目估计在项目开发中起着非常重要的作用,是制定项目计划的依据,其结果直接影响着项目资源分配的合理性。目前主流的项目估计方法按照规模的度量单位划分主要有两类:一种是基于功能点度量的估计方法 (例如IFPUG功能点[1]、MarkⅡ功能点[2]和 COSMIC功能点[3]),一种是基于LOC度量的估计方法 (例如Putnam模型[4]、COCOMO模型[5]和Pert算法[6])。基于功能点度量的估计方法实际操作比较复杂,在实际使用上存在一定的困难;基于LOC度量的估计方法依赖于专家的主观经验判断,而且LOC不能用于文档规模的估计。所以需要一种简单易操作的估计方法,这种方法应对主观经验具有比较低的依赖性,而且其度量单位应能度量所有产品的规模。
另外,历史项目的统计数据是一个组织宝贵的资产,具有重要的分析和使用价值。但是随着组织的发展,历史项目的统计数据会不断增加,如何使用这些统计数据将成为组织一个亟待解决的问题。
为了同时解决以上两方面的问题,本文提出了一种基于单元度量的项目估计方法。该方法具有比较完整的框架,包含测量项的定义、数据采集方法、数据分析方法和估计方法4个方面的内容。本文剩余部分将分别对这些内容进行介绍,在介绍完估计方法后还使用了来自于载人航天工程的30个实际项目的数据进行了验证。
1 测量项定义
为了不断提高估计的准确度,需要对新项目的相关参数进行测量。表1列出了与项目估计有关的测量项及其测量单位的示例。
2 数据采集方法
表1中列出的测量项有4类:时间类测量项,程序类测量项,测试类测量项和文档类测量项,这些测量项的统计数据由项目组提供。每一个测量项实际上需要统计两个数据:估计值和实际值。之所以需要对估计值进行采集,是为了分析估计数据和实际数据的差异,从而对各个估计因子进行适当地调整以提高估计的准确度。

表1 测量项定义示例
在项目启动阶段,应由专业的估计人员对项目进行估计。在项目结束后,由项目组统计测量项的实际值。在采集以上4类测量项的估计值与实际值时,可以使用与表2类似的统计表分别进行采集。值得指出的是,在采集文档类测量项的数据时还需要采集文档的版本数,以反映版本变更的工作量。

表2 程序规模统计
3 数据分析方法
指示器是进行数据分析的基础,它是经过多次测量后得到结果的体现[7],反映了一个组织当前的生产力水平和发展趋势。表3列出了与项目估计有关的指示器,指示器包含了一系列的估计因子,其使用的初始值可以通过对组织历史项目的统计数据进行计算和分析得到。而这项数据分析的任务需要由专业的项目估计人员来完成。
表3中的估计因子的定义说明如下:
(1)在计算估计因子 “测试各阶段发现的问题数占总的问题数的比率”时,直接将各阶段发现的问题数除以总的问题数,然后将各个值换算成百分制即可。
(2)估计因子 “测试用例的效率”指的是发现的问题数占测试用例总数的比例,在计算时分阶段计算,即将每个阶段发现的问题数除以该阶段使用的测试用例总数即可得到这个阶段测试用例的效率。
(3)估计因子 “缺陷密度”的度量单位为个/单元,表示平均一个单元会产生多少个缺陷,该因子的值是通过将测试阶段发现的所有缺陷数除以程序的单元个数得到的。
(4)估计因子 “单元代码行数”的度量单位为行/个,表示平均一个单元包含多少行代码,该因子的值是通过将程序的代码行数除以总的单元个数得到的。

表3 指示器列表
(5)估计因子 “单位复杂度单元数”是一个比率,表示复杂度为1的程序包含的单元个数,该因子的值是通过将程序的单元个数除以项目复杂度得到的。项目复杂度的度量方法将在4.1节中说明。
(6)估计因子 “单元文档页数”的度量单位为页/单元,表示平均一个单元需要用多少页文档进行描述,该因子的值是通过将某份文档的有效页数 (文档页数* (1+0.1*版本数))除以单元个数得到的。
(7)估计因子 “职工平均生产率”的度量单位为单元/人天,表示一个职工平均一天 (8小时)生产多少个单元,该因子按项目阶段的不同而不同。在计算某阶段的平均生产率时,用总的单元数除以该阶段持续的时间和该阶段参与的职工数即可得到。
(8)在计算估计因子 “各阶段工作量占总工作量的比例”时,将各阶段所花费的时间除以项目总时间,再换算成百分制即可。
这些估计因子的初始值是通过对组织历史项目的统计数据进行计算和分析得到的,并随着新项目建立而使用,新项目的完成而不断被调整,以符合组织当前的实际情况,从而提高估计的准确度。
项目估计人员主要根据偏差类的4个指示器的结果对估计因子进行调整。在计算偏差时,使用下式进行计算

偏差较小的估计结果 (例如小于25%),应该可以作为组织的现有生产水平的估计因子使用。如果偏差较大,则应由估计专家对项目完成的情况进行分析,判断造成估计偏差较大的原因是否是组织生产水平的改变。若是,则应调整估计因子使之符合当前组织的生产水平。若是其它特殊原因,则应转而关注这种特殊原因的影响,以决定是否需要调整估计因子。
估计因子的调整主要有两种方法:一种是求平均值法,一种是直接调整法。求平均值法是将各估计因子的值与使用当前项目统计数据计算得到的对应估计因子的值的平均值作为各估计因子调整后的值。直接调整法是将各估计因子的值直接调整为使用当前项目统计数据计算得到的对应估计因子的值。求平均值法采用的是逐渐过渡的思想,这种方法可以减少项目的偶然性对估计因子产生的影响,但是调整的周期比较长;直接调整的方法调整的周期短,但是增加了项目的偶然性对估计因子的影响。
4 进行项目估计
在计算得到表3中各个估计因子的初始值后,便可以将其应用于新项目的估计。项目估计的对象包括规模,工作量/成本,关键计算机资源和进度[8],本文提出的方法只对规模,工作量和进度进行估计,而且没有考虑需求蔓延的因素。在进行估计时,先估计项目规模,然后使用估计因子计算得到其它对象的估计值[9]。
4.1 初始的规模估计
在对新项目进行估计时,规模是对其它内容进行估计时的输入,所以规模的估计是最基本也是最重要的。项目的规模主要由程序的大小和文档的总页数来体现,本文使用程序的单元总数来表示程序的大小。在对单元总数进行估计时,可以使用两种方法:一种是类推法,一种是任务估算法。
类推法需要从组织的历史项目中找出与当前项目最为类似的项目,然后将找到的历史项目的单元数直接作为当前项目单元数的估计值。在判断历史项目与当前项目的类似程度时,主要从开发语言,项目类型和项目用途3个方面进行判断。这种方法要求组织对历史项目进行了细致的分类,而且对历史项目的单元数进行了统计和保存。这种方法需要组织级大量的分析整理工作,其结果应保存到组织资产库[10]中,并随着组织级数据的不断积累,逐渐获得组织级更准确的项目估计结果,从而支持整个组织的定量化管理。对项目而言则操作简单,适合于项目早期的估计。
任务估算法需要先计算项目复杂度。项目复杂度定义为项目所包含的操作过程个数。“操作过程”指的是软件与外部系统进行交互的操作和软件内部对数据进行加工,存储或者转发的操作,一个操作过程实现了一个简单的功能或者任务。判别一个操作过程的原则如下:
(2)若接收的数据来源于不同的外部设备,则为不同的操作过程;若处理或生成的数据格式或者类型不同,则为不同的操作过程;若数据输出的目的地为不同的外部设备,则为不同的操作过程。
(3)所有设备的维护与自检视为一个操作过程,维护与自检生成记录的过程也视为一个操作过程。
在实际计算复杂度时,需要先对软件项目的任务需求(例如任务书,接口协议等)有一定的了解,统计分析各类操作过程的个数,接着将所有操作过程的个数累加即可得到该项目的项目复杂度O (process)。
得到项目复杂度O (process)以后,将其乘以估计因子 “单位复杂度单元数”,即可得到该软件项目单元数的估计值N,将N乘以估计因子 “单元文档页数”,就可以得到各种文档的页数的估计值。例如,当前项目的软件需求规格说明书的页数估计值=N*I,其中I为软件需求规格说明书单元文档页数。使用上面的方法,可以计算得到所有文档页数的估计值。进行累加,即可得到当前项目产生文档总页数的估计值。
将N乘以估计因子 “单元代码行数”,可以得到程序代码总行数的估计值。将N乘以估计因子 “缺陷密度”,可以得到问题总数的估计值。将问题总数的估计值乘以估计因子“测试各阶段发现的问题数占总的问题数的比率”,可以得到各阶段可能发现的问题个数 (至少为1,若计算结果为0,则估计值用1代替)。接着将各阶段可能发现的问题个数除以估计因子 “测试用例的效率”,可以得到各阶段测试用例个数的估计值,进行累加即可得到测试用例总数的估计值。
这种任务估算方法适用于在类推法的基础上,对具体项目进行估计的调整,以确定对于项目的相对准确的估计值,为最初的项目策划提供估计依据。这种方法还可以在项目进展过程中,根据项目工作深入的情况,进行及时的调整和修正,以适应具体项目特殊情况的发生和变化,为短期工作的策划和计划提供估计依据 (例如在周例会上进行调整)。
4.2 规模估计基础上的后续估计
在进行工作量的估计时,将N除以估计因子 “职工平均生产率”,即可得到各阶段工作量的估计值 (单位:人天)。将这些估计值进行累加,即可得到项目的总工作量(单位:人天)。
假设某个阶段指派的职工人数为n,将该阶段工作量的估计值除以n即可得到该阶段持续时间的估计值。用同样的方法可以计算得到所有阶段持续时间的估计值,然后根据项目的启动时间即可估计出项目的进度。
潞新矿区内变形较大且较难控制的巷道基本都是实体煤掘进巷道,掘进过程中均出现煤炮频繁、煤体自行片冒、迸射等强烈矿压显现现象。冲击性载荷是造成潞新矿区巷道掘进成形困难和变形量大的主要原因,而冲击性载荷的根源则主要包括高应力、煤岩体的储能特性及结构特性。
4.3 方法验证
为了对方法进行验证,本文总共使用了30个来自于载人航天工程等项目的实际统计数据。先使用F组织的某实际嵌入式项目P3的数据对前面提出的估计方法进行试用,验证以及简单的分析。在对项目P3的规模进行估计时,使用的是任务估算的方法,并通过分析项目的软件任务书来确定软件中所包含的操作过程个数。软件任务书描述了用户对项目的任务要求,描述了软件应实现的主要功能,但没有涉及过多的细节。
表4列出了F组织各个估计因子的值,这些值主要是通过对F组织的两个小型嵌入式软件项目 (代码行小于10000行)的统计数据进行计算分析得到的。这两个项目是综合了工程标准要求的符合程度,过程执行的控制程度,发生的缺陷和反复的情况,发生缺陷的严重程度和影响,以及文档质量等因素,凭借主观经验判断选择的,一个过程执行效果比较好,一个过程执行效果比较差。这样选择,主要是考虑兼顾组织级的 “最好”,“最坏”过程水平的差异,而不是只强调最优的执行结果。在计算估计因子的初始值时,先分别使用两个项目的统计数据进行计算,然后将两组值进行平均即可得到表4中的各项值。
使用前面提出的估计方法,对项目P3进行估计,并将各项估计值和实际值填入表5,表6和表7。在估计单元总数时,使用的是任务估算法。由于项目P3的历史统计数据不全面,而为了保证估计值与实际值具有可比性,需要在估计时将 “概要设计”和 “详细设计”合并为 “设计阶段”,且不对测试用例总数,软件单元回归测试报告的页数,软件配置项回归测试报告的页数和软件组装回归测试报告的页数进行估计。
根据表5-表7中的数据,将规模估计值与实际值的偏差,工作量估计值与实际值的偏差,进度估计值与实际值的偏差分别使用图1,图2和图3进行表示。
根据表格中的数据可以计算得到程序规模估计的偏差为3%,文档规模估计的偏差为12%,工作总量估计的偏差为26%,各进度的偏差最大为45%,其中工作总量和进度估计的偏差比较大,需要分析具体的原因。从表5可以看到,造成工作总量和进度偏差比较大的原因主要是由于编码和测试阶段的实际完成时间比计划完成时间要长。对该项目的实际完成情况进行判断,编码阶段的任务完成的是比较好的,而测试阶段的任务完成的是比较差的,这说明估计因子 “职工平均生产率”的初始值体现的生产水平比当时组织的实际生产水平要高,所以需要将该估计因子调小。

表4 F组织的相关估计因子

表5 活动参数估计值与实际值

表6 程序参数估计值与实际值

表7 文档参数估计值与实际值
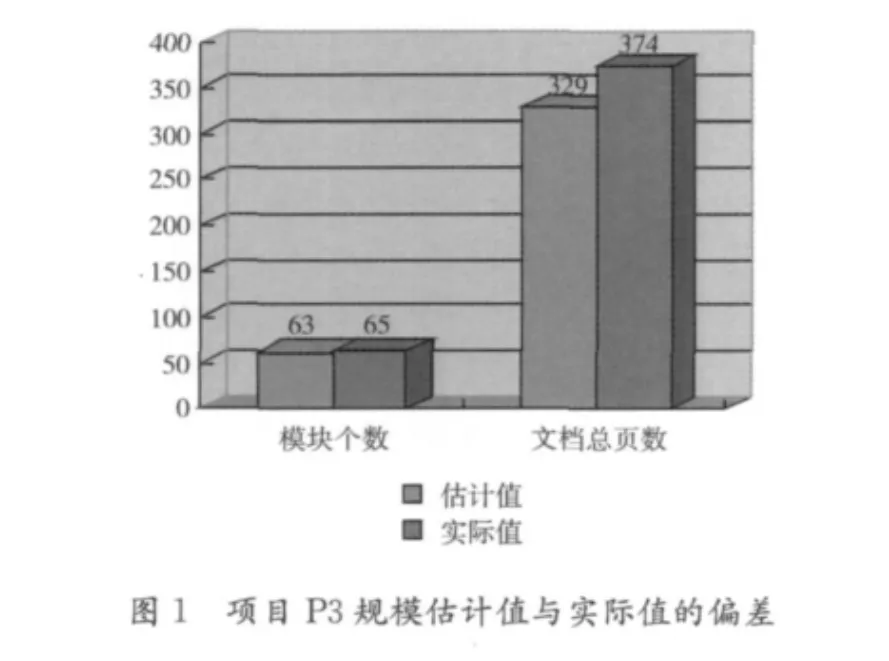


图3 项目P3进度估计值与实际值的偏差
本文接着对F组织的15个小型嵌入式项目P1,P2,P3,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13,P14和P15(其中P7和P11的代码行在10000行左右,其余项目的代码行皆小于10000行)使用本文提出的任务估计方法进行估计,并将估计结果与实际统计数据进行比较,比较的结果使用MRE(the magnitude of relative error)和相关系数r(the correlation coefficient)进行度量。这两种度量分别用于评价方法的准确度和一致性。MRE[11]和r[12]的计算公式如下

式中:Xi——第i个实际值,Yi——第i个估计值。
这15个项目都属于新研制的项目。在估计时,由于统计数据不全面,只估计了项目规模中的单元数和文档总页数两项。表8列出了这些项目的估计数据,实际数据以及对应的MRE值,图4描述了这些项目估计数据MRE值的分布情况,图5描述了这些项目的单元个数估计值与实际值的线性拟合情况,图6描述了这些项目的文档总页数估计值与实际值的线性拟合情况。由于部分项目的特殊性,项目生成的文档并不一致,所以表8列出的各项目文档的总页数和其程序的大小也不一致。
从表8以及图4可以计算得到这些项目估计数据的平均MRE值,其中单元数的平均MRE值为6.7,文档总页数的平均MRE值为16.2,这说明该估计方法的准确度是比较高的。
通过对表8中的数据进行计算可以得到相关系数r的值,其中单元数的r值为0.9963,文档总页数的r值为0.9691,结合图5和图6中的线性拟合情况,说明该估计方法的一致性也是比较好的。
从准确度和一致性两方面的数据可以得出结论:本文提出的项目估计方法适合用于F组织的小型嵌入式软件项目的估计。对于其它类型的软件项目是否适用,还有待实际数据的验证。

表8 新研项目的估计数据与统计数据
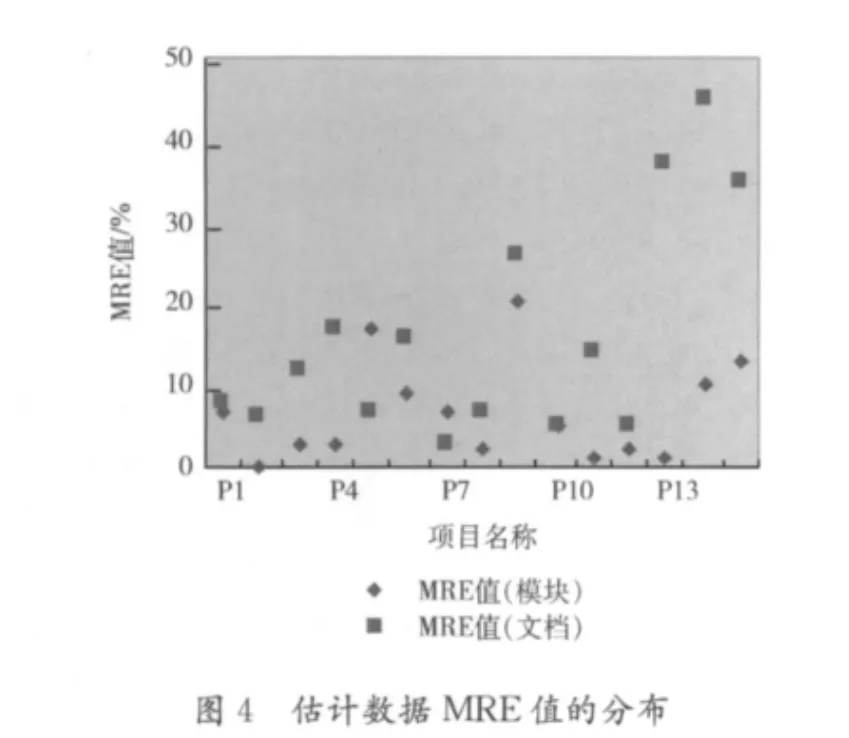


图6 文档总页数的估计值与实际值的线性拟合
本文接着对15个重用型的项目使用本文的方法进行了估计,表9列出了估计和计算的结果。与前面类似,图7,图8和图9分别描述了估计的准确度和一致性。通过对表9中的数据进行进一步计算,可以得到单元数的平均MRE值为9.5,文档总页数的平均 MRE值为65.6,单元数的r值为0.9932,文档总页数的r值为0.5324。这说明重用因素对项目估计结果的影响是比较大的,所以在实际操作时还需要考虑重用因素。在估计一个重用型的项目时,可以先由专家给出该项目的重用率R(重用率指的是组织已经研发实现过的操作过程占所有操作过程的比例),然后再使用本文提出的方法估计得到该项目的单元数N,于是可以得到该项目实际需要完成的单元数N’=N* (1-R),接着就可以使用N’来估计文档规模,工作量和进度等内容了。

表9 重用项目的估计数据与统计数据



5 结束语
本文提出了一种基于单元度量的项目估计方法。由于F组织在嵌入式软件项目中开发的是面向过程的程序,而一个操作过程的实现是由一个或多个单元共同完成的,所以使用项目的操作过程个数乘以平均每个操作过程包含的单元数,就可以得到该项目的单元数的估计值。由于F组织开发的大部分嵌入式软件项目包含的各类操作过程个数的分布是一致的,所以使用项目的操作过程的个数乘以一个操作过程包含单元数的平均值来得到项目单元总数的估计值是合理的,这也是本文提出的估计方法的准确度比较高的主要原因之一。
造成该估计值与实际值产生偏差的客观因素主要是当前项目包含的各类操作过程个数的分布与初始两个项目包含的各类操作过程个数的分布的差异。而产生偏差的主观因素主要是分析任务需求得到操作过程的个数与实际操作过程的个数的差异。由于不同的人对操作过程判别方法的理解程度不一样,分析任务需求得到的操作过程数也会不一样。该方法适用于与F组织类似的单位和企业的小型嵌入式软件项目的估计,实际操作简单,而且充分利用了组织历史项目的统计数据,而这是该方法的一个最基本最核心的思想。
[1]CPM 4.3.1.Function point counting practices manual release 4.3.1 [S].
[2]LI Xinchen.The application of markⅡFP method and function point measurement technology research [D].Changsha:National University of Defense Technology,2008:14-21 (in Chinese).[李新忱.MarkⅡFP方法的应用及功能点度量技术的研究 [D].长沙:国防科学技术大学,2008:14-21.]
[3]WANG Xinyu,HOU Hong,HAO Kegang.Research and application of COSMIC2FFP methodology [J].Computer Applications and Software,2008,25 (10):11-13 (in Chinese).[王昕渝,侯红,郝克刚.COSMIC2FFP方法的研究及应用[J].计算机应用与软件,2008,25 (10):11-13.]
[4]XIA Xiaoxiang.Research of software project estimation [D].Nanjing:Nanjing University of Science and Technology,2006:19-21(in Chinese). [夏晓翔.软件项目估算管理方法研究[D].南京:南京理工大学,2006:19-21.]
[5]Barry Boehm.Cost estimation with COCOMOⅡ [R].California:University of Southern California,Center for Software Engineering,2002:2-11.
[6]Jose Manuel Herren,Rafael Herren,Johan Renen.Revisiting the PERT mean and variance [J].European Journal of Operational Research,2011,210 (2):448-451.
[7]ZHANG Jin.Guideline for software quality management[M].Beijing:Publishing House of Electronics Industry,2009:123-126(in Chinese).[张瑾.软件质量管理指南 [M].北京:电子工业出版社,2009:123-126.]
[8]CHEN Jiayu,LI Yang,LIU Jinguo,et al.Estimation method of embedded software project [J].Computer Science,2008,35(11):236-238(in Chinese).[陈佳豫,李杨,刘金国,等.一种嵌入式软件项目估计方法 [J].计算机科学,2008,35(11):236-238.]
[9]Jones C.Estimating software costs [M].LIU Congyue,HAO Jiancai,SHEN Dongkai,transl.2nd ed.Beijing:Publishing House of Electronics Industry,2008:4-10(in Chinese).[Jones C.软件项目估计 [M].刘从越,郝建材,申冬凯,译.2版.北京:电子工业出版社,2008:4-10.]
[10]GJB5000A-2008,Chinese national military capability maturity model for software development [S] .(in Chinese) .[GJB5000A-2008,中华人民共和国国家军用软件研制能力成熟度模型 [S].]
[11]Mohammad Azzeh,Daniel Neagu,Peter I Cowling.Analogybased software effort estimation using fuzzy numbers [J].The Journal of Systems and Software,2011,84 (2):270-284.
[12]Luiz Fernando Capretz,Venus Marza.Improving effort estimation by voting software estimation models [J].Advances in Software Engineering,2009,2009:1-8.doi:10.1155/2009/829725
[13]Deshpande M V,Bhirud S G.Analysis of combining software estimation techniques[J].International Journal of Computer Application,2010,5 (3):1-2.
[14]ZHANG Junguang.A method for result validity verifying of software project schedule estimation [J].Beijing Post University Transaction,2008,31 (5):44-47(in Chinese).[张俊光.软件项目进度估计结果有效性验证方法 [J].北京邮电大学学报,2008,31 (5):44-47.]
[15]LIU Di.Apply research on the scale of software evaluation based on improved function point analysis[D].Hefei:Hefei University of Technology,2007:4-16(in Chinese).[刘迪.基于改进的功能点分析法在软件项目规模估计中的应用研究[D].合肥:合肥工业大学,2007:4-16.]
