基于K-means聚类与张量分解的社会化标签推荐系统研究
2012-11-21孙玲芳李烁朋
孙玲芳, 李烁朋
(江苏科技大学 经济管理学院, 江苏 镇江 212003)
随着Web 2.0技术的发展,含有社会化标签(social tag)数据的大众标注(folksonomy)网站在电子商务领域蓬勃发展.为了给用户提供有效的项目信息,多种推荐技术被广泛运用在电子商务领域.而在大众标注网站中,用户通常会对自己感兴趣的对象有一个标注行为,所产生的标签(tag)数据会对推荐系统的推荐效果产生较大影响[1].而传统的推荐方法,例如协同过滤系统通过计算用户之间或是项目之间的相似度来完成推荐过程,若在大众标注网站中忽略了大量的标签数据,则评价矩阵的数据稀疏性问题依然存在,并且会影响到推荐精度[2].提高推荐精度的传统方法之一是利用矩阵奇异值分解(singular value decomposition, SVD),对数据矩阵进行分解后将无用数据去除,达到降噪和降低稀疏性的目的,但是对含有标签数据集的多元数据矩阵改进效果不佳.奇异值分解对二维矩阵稀疏问题具有良好处理特性,在此基础上,文中首先对标签数据进行K-means聚类,然后以用户(user)、标签(tag)、项目(item)数据建立多维张量模型,运用K-means HOSVD(high order singular value decomposition)对模型进行分解运算,两个算法皆是保证数据的非稀疏性.以书签标注网站Decilous.com的数据为测试集对该模型的推荐效果进行检验.
1 大众标注概念
1.1 大众标注和标签
SNS(social network service)网站的出现给用户之间的交互过程提供了一个崭新平台,网络社区由此建立,大众标注的概念也因此而产生.大众标注是众多信息用户根据自己的需求,选择合适的网络信息资源,并根据自己的认知水平,确定与之相匹配的社会化标签进行标注的过程[3].用户根据自身的理解与喜好程度,对自身感兴趣的网络资源添加“标签”,便会对其他用户共同所感兴趣的对象提供一种推荐与参考.大众标注研究最早起源于国外学者对Web 2.0系统的研究,其基本要素包括:含有标签信息的元素、众多用户自下而上对资源进行标注与共享的过程,以及以人为本提供组建网络社区与构建关系网络等服务[4].
标签的范围也随着大众标注网站的发展而不断扩大,从对书籍共享网站进行标注所形成的“书签”,到音乐、照片、视频、博客网站中各种信息资源形成的一种标注信息[5].国外学者认为,标签是一种以自然语言形式出现的关键词元数据,概念、类别、分面与实体都可以成为标签的要素[6].由于“标签”的表述使用正常语言而非抽象的代码,因此用户之间通过标签可以轻易挖掘出与自身喜好相近的其他用户和资源,从而为构建网络社区提供了基本群体要素.
1.2 标签数据的特点
大众标注网站不同于其他电子商务网站,拥有标注数据的社区网站通常含有大量的语义分析元素.此时,用户把在电子商务平台中对商品或对象进行评分的过程,改为对自身感兴趣的项目进行标注的行为[7].传统算法,如协同过滤推荐系统是基于分析近邻用户之间的相似偏好来过滤信息,达到向其他用户推荐的目的;但是标签不是确定的评分数值而是含有大量语义信息的文本数据,若仍采用传统的推荐方法,虽也有一定的推荐效果,但推荐精度会随着矩阵数据稀疏性的增加而下降.两者数据类型之间的差异如表1,2.
Movie Lens是一个在线的电影评分网站;Last FM是基于用户标签的音乐网站,用户对自己喜爱的歌手添加标签,并与在线的其他用户进行共享.

表1 数据来源为Movie Lens网站

表2 数据来源为Last FM网站
从表中数据可以看出两者的差别之处,大众标注网站包含更多的语义信息,因此两者的推荐系统模型也有所差别.如何在大众标注网站的海量信息中进行有效推荐,以及如何有效解决数据矩阵的稀疏性问题,是当前电子商务推荐系统研究的热点问题.
2 电子商务推荐系统算法的研究
Resnick & Varian于1997年首次定义了电子商务推荐系统[8],该系统利用网站平台向客户推荐相关的商品信息,以帮助客户完成购买过程.推荐系统通过分析相关数据得到顾客的购买偏好,然后针对性地进行商品推荐.传统的个性化推荐技术主要有以下3种:
1) 基于规则推荐.该算法对不同情况下如何提供不同的服务定义了许多规则,系统利用这些规则来产生推荐,因此推荐的质量依赖于规则的质量和数量.但是该方法所推荐的商品一定是曾经被其他用户浏览过的,所以新的商品在任意客户浏览之前便无法获得推荐,导致该算法个性化程度较低.规则数量随着商品数量的添加而增多,规则质量难以保障,系统也趋于繁杂.
2) 内容过滤推荐.该算法通过相关特征的属性来定义商品或项目,系统基于用户评价商品的特征学习用户兴趣,依据用户资料与待预测商品的匹配程度进行推荐.基于内容的推荐算法也存在缺点:模型有效性和过度特征化问题使得模型当中信息之间的关联性无法很好体现,导致系统无法识别客户新发现的兴趣资源;自主进化能力较差.若新的商品数量迅速增加,系统不能对这样的新特征产生进化能力.
3) 协同过滤推荐.采用最近邻技术利用客户的历史偏好信息计算用户之间的距离.然后利用目标客户的最近邻居对商品评价的加权平均值来预测他对特定项(商品)的偏好程度.系统根据这一偏好程度来对目标客户进行推荐[9].协同过滤推荐主要有3个步骤:① 评分矩阵,根据系统中用户和评分的数据可以建立一个M×N阶矩阵R来表示;② 相似度计算,相似度计算用来发现最近邻居用户,一般有余弦相似度和相关相似性2种方法;③ 最后是top-n推荐生成.
3 HOSVD模型
高阶奇异值分解:HOSVD是在矩阵奇异值分解SVD的概念上的延伸.对于任意N阶张量Y∈RI1×I2×IN,其中ai1, i2,iN为张量Y中的元素,定义张量Y的n-模(n-mode)分解矩阵A,把张量Y沿第n模式展开的矩阵A的操作称为张量展开[10].
令U∈RJn×In,则A可表示为Y×nU.A的结果是一个(I1×I2×…×In-1×Jn×In+1×…×IN)阶张量,张量Y与矩阵U的第n模式的Tucker积可由下列公式得到:
(1)
在大众标注网站中,数据结构为用户、标签和项目的三元数据,所以取n∈ {1, 2, 3},则展开矩阵A分别为A1∈RI1×I2I3,A2∈RI2×I1I3,A3∈RI3×I1I2.
当张量为2阶时,对2维矩阵进行SVD分解,可得
F=S×1U(1)×2U(2)
(2)
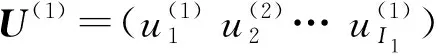
Y′=S×1U(1)×2U(2)×3U(3)
(3)
式中:U(1),U(2)和U(3)均是对分解矩阵A1,A2和A3在列空间向量上的正交化处理,包含1-模、2-模和3-模的奇异值向量;S是具有完整正交性的核心张量,控制各子空间矩阵间的相互作用,类似于SVD中的奇异值矩阵,但不是对角结构;Y′是对张量Y的重新构建,包含了新的数据信息.
4 基于K-means HOSVD的推荐模型设计
4.1 K-means聚类
K-means聚类是一种经典的距离聚类方法,在很多领域得到广泛运用[11].文中根据大众标注网站数据中所提供的标签和项目之间的权重值来建立项目—标签权重矩阵Wm×n(表3),其中M行代表M个项目,N列代表N个标签,Wi,j表示项目Ii对标签Tj的标签权重.对该矩阵进行K-means聚类,将众多分散的标签和项目进行初步聚类得到相对密集的数据集,使数据具有初始的聚合性.
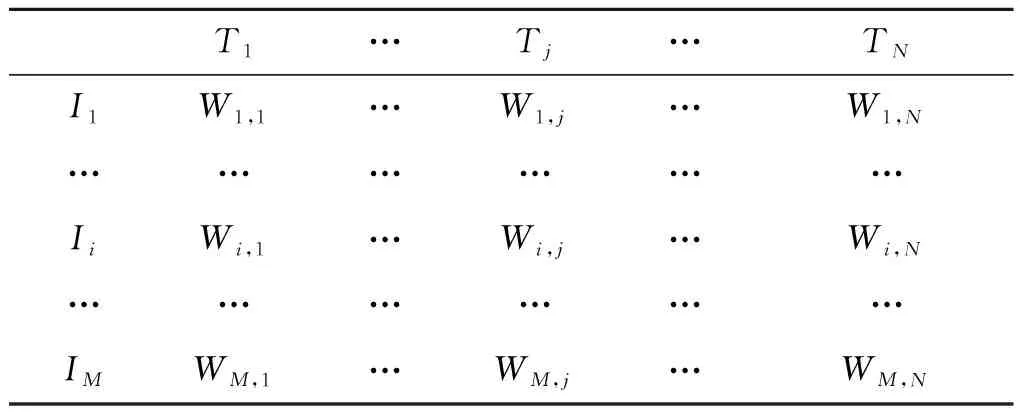
表3 项目—标签权重矩阵Wm×n
基于项目—标签矩阵Wm×n的K-means聚类过程如下:
输入为项目聚类的数目K,用户-标签矩阵Wm×n
输出:K个聚类.
方法:
1) 从矩阵Wm×n中检索得到全部M个项目数,记为I={i1,i2,…,in};
2) 从矩阵Wm×n中检索得到全部N个标签项,记为T={t1,t2,…,tn};
3) 随机选择K个项目作为初始聚类中心,记为集合Q={q1,q2,…,qk};
4)K个聚类P1,P2,…,Pk均初始化为空,各聚类与其聚类中心相对应;
5) 计算项目ii与各个聚类中心qj之间的欧氏距离如下式:
(4)
式中:Tij表示项目ii与作为聚类中心的项目qj共同标注过的标签集合,Wii和Wqj分别是项目ii和qj的标签权重;
6) 若D(ii,qj)=max {D(ii,q1),D(ii,q2), …,D(ii,qk)},则项目ii属于聚类Pj;
7) 计算相同聚类中所有项目的标签权重平均值,生成新的聚类中心;
8) 若聚类中心不再发生改变,则退出;否则转到第5)步重新计算.
初始聚类完成后,将聚类数据输入数据库建立聚类信息表.通过对项目的初始聚类,可以将拥有相似标签的项目分配到同一聚类中,使得同一聚类中的项目相似性尽可能高.同时,通过参照聚类后的标签—权重数据可以确定项目所对应的标签,再根据项目—标签定位出用户,此时用户在一定程度上也完成了初始聚类.
4.2 张量分解模型
根据先前的聚类数据,将K组数据集中进行推荐,通过用户、标签和项目数据建立一个初始张量Bu×t×i[12].为了更好地表达模型概念,随机从聚类数据集中选取4组数据为例进行建模(表4).

表4 用户标注示例
注:数据来源为Delicious.com
表4中共有3个用户,对2个项目用3个标签做出了4次标注.设产生标注的权重为1,没有产生标注的权重为0.则初始张量B如图1.
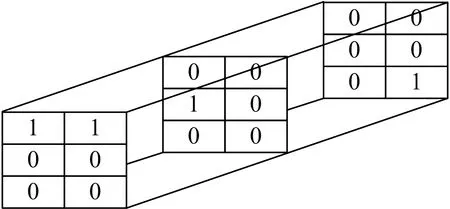
图1 张量B的图例
B中的各个元素均为每个用户用标签标注项目后产生的权重.得到初始张量B后,将其沿第1,2,3模式展开得到3个展开矩阵A1,A2和A3如下:
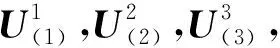
S=Y×1(U(1))T×2(U(2))T×3(U(3))T
(5)
将核心张量S带入公式(3),计算重新构建的张量Y′(图2).
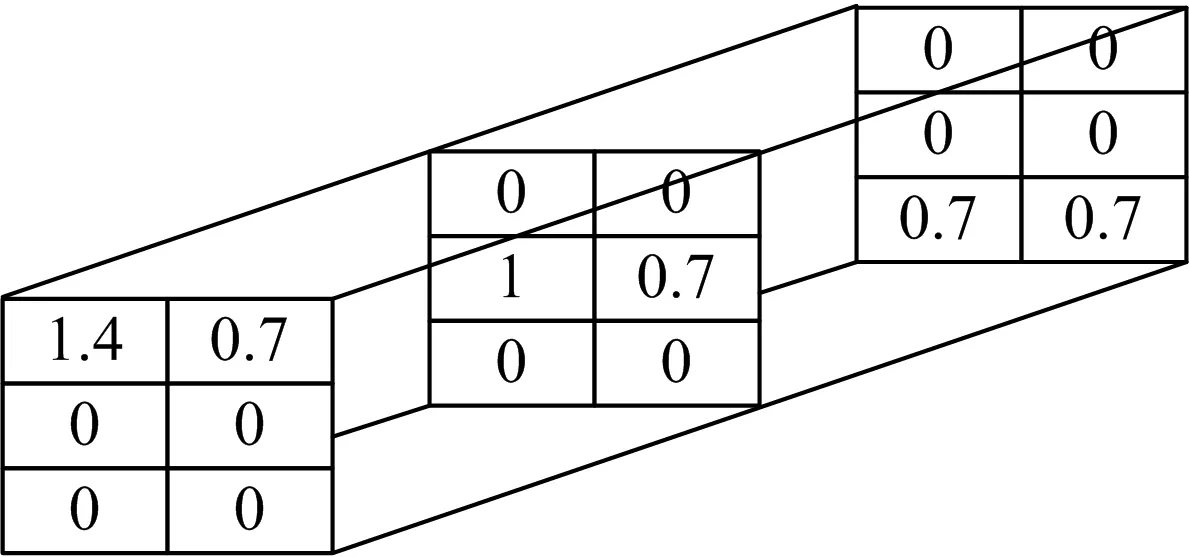
图2 新的张量Y′图例
在{U2,I2,T2}以及{U3,I1,T3}项的值由原来的0变为0.7,因此新的推荐生成.
5 实验及结果分析
5.1 数据集
文中采用Decilious.com网站的标签数据进行分析.该网站是在线网页书签网站,用户可以对各种网页链接进行标注是该网站的一大特点.该数据包含165个用户,368个书签以及760个标签.本实验将数据集划分为训练集和测试集,其中75%作为训练集,25%作为测试集.
5.2 评估标准
推荐系统的准确性和有效性一般用精确度(Precision,P)、召回率(Recall,R)来测量,精确度的定义如下:
P=(命中的数目)/(推荐的数目)
R=(命中的数目)/(测试集的大小)
为避免精确度和召回率之间相互冲突,设定新的F测度,F的指标越好则模型的推荐质量越好.如下式:
(6)
5.3 实验方案及结果分析
K-means聚类的聚类数目K的选择是一个关键,由于预处理数据中的三组数据相对于平均值有大于等于或小于两种情况,因此设定K为2×2×2=8.在分析过程中对聚类结果的类别间距离进行方差分析,类别间距离差异的概率值均小于0.05,即聚类效果好.
在HOSVD模型中,对展开矩阵A进行SVD分解得到酉矩阵U的维数K进行实验确定.保留的维数很重要,若K太小, 则不能得到评分矩阵中的重要结构;若K太大,则失去了矩阵降维的意义[13].
本实验以经典的协同过滤算法为比较对象,采用相同的数据集和评估标准.实验按照top-n的值分别取3,5,10,15和20进行计算分析,计算结果见表5.根据表5可以得出文中算法和传统算法的性能比较(图3).
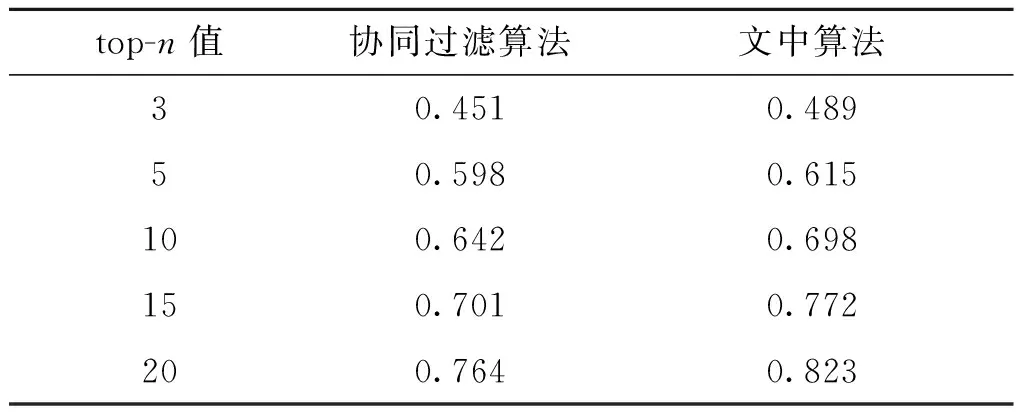
表5 两种算法的F值比较
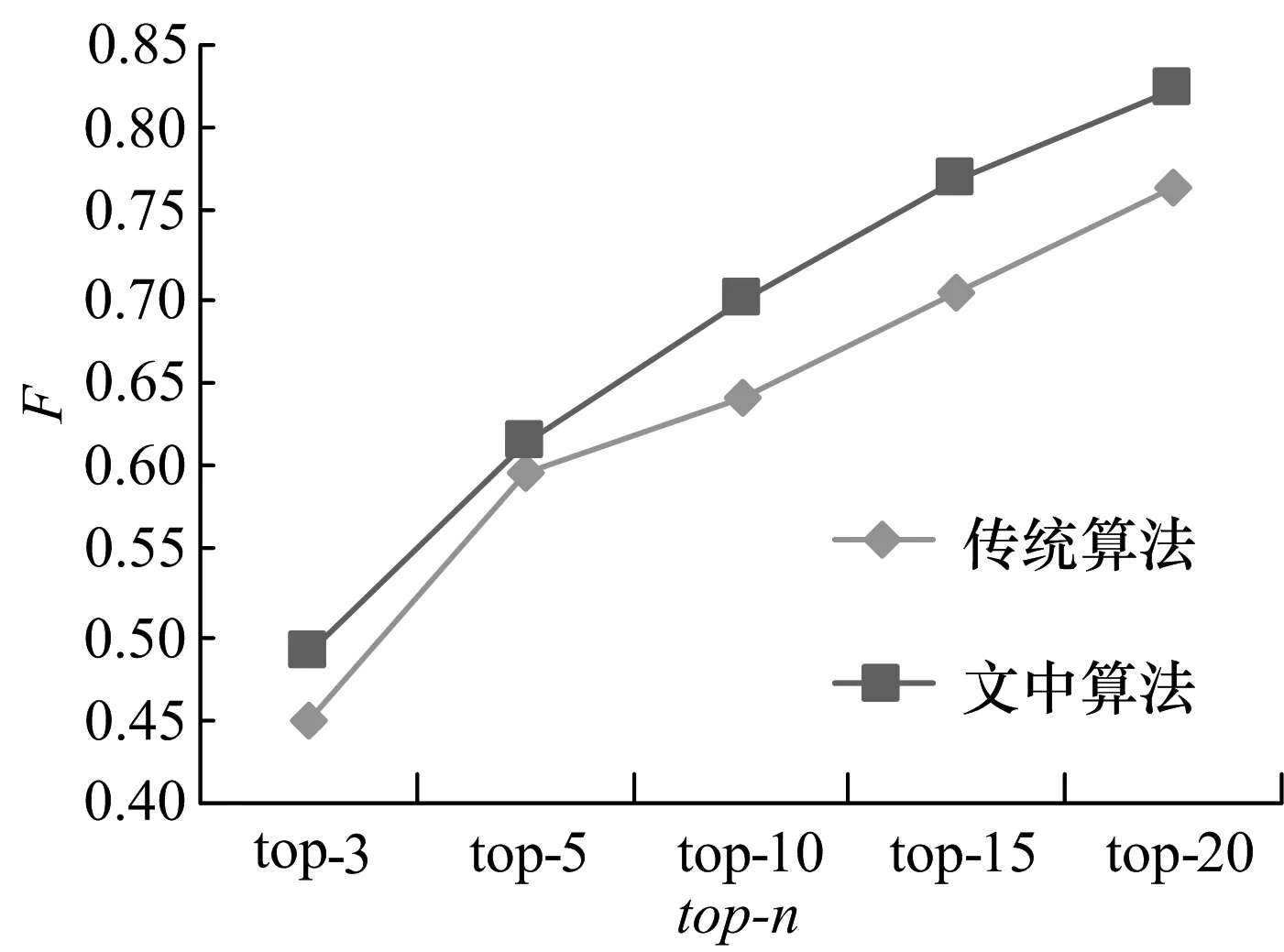
图3 两种算法性能比较
实验数据证明,文中算法在推荐不同项目个数top-n的情况下具有较大的F值,因此文中的高阶奇异值推荐算法比传统推荐方法更加有效.
6 结论
针对传统推荐算法中存在的数据稀疏性导致推荐效果下降的问题,文中结合大众标注网站中含有标签的数据,将K-means聚类和高阶奇异值分解相结合对推荐算法进行了改进,使得原始数据中包含的标签信息能够充分利用,从而达到更好的推荐效果.
随着电子商务网站数据量的不断攀升,以及标签作为重要的项目信息得到越来越广泛的运用,传统的推荐系统在处理此类问题上受到了挑战.如何有效提高推荐精度是当前推荐系统研究的热门话题.文中算法以高阶奇异值分解为基础加入对原始数据的聚类步骤,以求进一步解决数据稀疏性问题.在今后的研究工作中还可以将其他算法进行揉合改进推荐系统,以取得更加有效的推荐精度.
[1] 窦玉萌,赵丹群. 协作标注系统研究综述[J]. 现代图书情报技术,2009,175(2):9-17.
[2] Vozalis M G, Margaritis K G. Using SVD and demographic data for the enhancement of generalized collaborative filtering[J].InformationSciences,2007,177(15):3017-3037.
[3] 黄国彬. 大众标注研究进展[J]. 图书情报工作,2008,52(1):13-15.
[4] Mangold W G, Faulds D J. Social media: The new hybrid element of the promotion mix[J].BusinessHorizons,2009,52:357-365.
[5] Meo P D, Nocera A. Recommendation of similar users, resources and social networks in a social internetworking scenario[J].InformationSciences,2011,181(7):1285-1305.
[6] 程慧荣,黄国彬,孙坦. 国外基于大众标注系统的标签研究[J]. 图书情报工作,2009,53(2):121-124.
[7] Nan Zheng,Qiudan Li. A recommender system based on tag and time information for social tagging systems[J].ExpertSystemswithApplications,2011,38(4):4575-4587.
[8] Resnick P,Hal R V. Recommender system[J].CommunicationsoftheACM,1997,40(3):56-58.
[9] 孙玲芳,张婧. 基于RFM 模型和协同过滤的电子商务推荐机制[J]. 江苏科技大学学报:自然科学版,2010,24(3):285-289.
Sun Lingfang, Zhang Jing. Electronic recommendation mechanism based on RFM model and collaborative filtering[J].JournalofJiangsuUniversityofScienceandtechnology:NaturalScienceEdition,2010,24(3):285-289.(in Chinese)
[10] Symeonidis P, Nanopoulos A, Manolopoulos Y. A unified framework for providing recommendations in social tagging systems based on ternary semantic analysis[J].TransactionsonKnowledgeandDataEngineering,2010,22:179-191.
[11] 吴文亮. 聚类分析中K-均值与K-中心点算法的研究[D]. 广州:华南理工大学,2011:15-18.
[12] Symeonidis P, Ruxanda M, Nanopoulos A. Ternary semantic analysis of social tags for personalized music recommendation [J].KnowledgeRepresentation,Tags,Metadata,2008(2):219-224.
[13] Markaki M, Stylianou Y. Discrimination of speech from nonspeeech in broadcast news based on modulation frequency features[J].SpeechCommunication, 2011,53:726-735.
