基于近邻关系特征的多态蠕虫防御方法
2011-11-06汪洁王建新刘绪崇
汪洁,王建新,刘绪崇
(1. 中南大学 信息科学与工程学院,湖南 长沙410083;
2. 湖南省公安厅 网络安全保卫与技术侦察总队,湖南 长沙 410001)
1 引言
近年来,蠕虫给全世界成千上万的系统造成了越来越大的危害。蠕虫是一个自动运行的程序,它攻击连入网络的计算机从而获得对它们的控制。一旦蠕虫已经成功地感染一台计算机,它们就将通过这台计算机持续地搜索新的受害者,然后自动的传播到整个网络。因此,网络蠕虫成为研究人员的重要课题[1]。
目前针对蠕虫的检测和防御方法主要包括引入良性蠕虫进行防御、基于异常的检测和基于特征的检测。其中,建模良性蠕虫的方法包括:文献[2]首次尝试研究良性蠕虫的引入是如何影响蠕虫的扩散过程的,并使用常微分方程建立了一个 SIAR模型来描述蠕虫和良性蠕虫的交互过程;在文献[3]中提出了良性蠕虫基于网络拓扑信息的扩散技术,并重点研究了基于平衡树的良性蠕虫扩散算法、平衡树的动态生成规则和稳定性增强策略。
基于异常的检测方法包括:在文献[4]中提出的基于网状关联分析预警网络蠕虫的新方法,该方法采用分布式体系结构,利用网络环境中各探测点提供的信息和数据,采用数据挖掘和异常检测的方法,通过对各探测点之间的数据作关联分析,实现大规模网络环境下的网络蠕虫预警;文献[5]提出了一种自适应的蠕虫检测和遏制方法,该方法利用连接的频繁性和目标端口的相似性作为检测的依据;文献[6]提出了使用本地网络协同检测蠕虫的方法CWDMLN等,该方法利用蠕虫的花瓣通信模式、无效链接以及在本地网络中部署蜜罐等检测手段,协同给出蠕虫入侵的预警信息。文献[7]提出了一种对蠕虫进行早期发现的新方法,并且实现了一个基于用户习惯的蠕虫早期发现系统。
本文主要考虑蠕虫的检测问题,以上检测方法可以比较好地检测网络蠕虫,然而当面对慢扫描蠕虫时,它们还需要进行优化[8]。目前大部分基于异常的蠕虫检测系统主要查找具体的攻击特性,只能用来检测已知蠕虫,但是无法检测新的蠕虫样本[9]。所以目前大部分的蠕虫检测系统都是基于特征的。基于特征的蠕虫检测系统能够在线的实时检测,并且较为简单,所以优于基于异常的蠕虫检测系统。
基于特征的蠕虫检测系统均需要首先提取蠕虫特征,然后基于提取的特征对蠕虫进行检测。因此,该类多态蠕虫防御系统的有效性取决于它们的特征正确检测蠕虫的能力。
随着多态和变形技术的出现,蠕虫可以在传播过程中改变其形态,同一类蠕虫的不同实例可能具有不同的形态,被伪装过的蠕虫负载可以逃避基于特征和基于异常的入侵检测系统的检测。蠕虫技术复杂性的日益增加给蠕虫的检测和防御提出了更高的要求。
目前,自动提取多态蠕虫特征的方法主要包括以下2类。
1) 基于字符串匹配的特征提取方法。
该类特征自动提取方法中,较为简单的是基于最大公共子串(LCS)的特征提取,如M. Cai 等人设计的WormShield[10]系统、G. Portokalidis等人设计的 SweetBait[11]系统和 S.Ranjan 等人设计的DoWicher[12]系统等。这些系统都是提取蠕虫序列的最大公共子串作为蠕虫的特征。然而,这样的特征无法检测多态蠕虫,例如,当多态蠕虫的样本中增加了花指令时,此类特征无法再检测出该变形后的样本。
在基于字符串匹配的方法中较为复杂且有影响力的主要包括J. Newsome等人设计的 Polygraph[13]系统、Zhichun Li等人设计的 Hamsa[14]系统,Lorenzo Cavallaro等人设计的特征自动产生器LISABETH[15]以及Burak Bayogle等人提出的元组对(称为Token-Pair)特征[16]和唐勇[17]等人提出的基于多序列联配的攻击特征自动提取方法等。这些方法有一个共同的特点,就是把攻击流中某些具体的字节序列作为攻击特征。
Polygraph[13]系统首先从可疑流量池中提取许多元组(称为token),这里的元组(token)是指在可疑池n个序列样本中出现至少K次的独立子序列串。在此基础上,Polygraph产生以下3类特征:联合特征、元组(token)子序列特征和贝叶斯特征。联合特征是将提取的所有元组(token)的集合作为特征。元组(token)子序列特征与联合特征的区别是特征集合中的元组(token)是有顺序的,该顺序是指元组(token)在可疑池序列中出现的次序。贝叶斯特征是为每个提取的元组(token)加上一个权值,加了权值后的元组(token)集合作为蠕虫特征。Hamsa[14]系统是在 Polygraph的基础上将元组(token)出现的次数作为了特征的一部分。通过得分函数score(COVs,FPs)来确定元组(token)的集合作为特征,对多态蠕虫进行检测。LISABETH[15]与 Hamsa的不同是特征集合包含了所有出现在可疑池中的元组(token)。Burak Bayogle等人提出的元组对(token-pair)特征[16]把可疑池中成对出现的元组(token)作为特征的一个部分。唐勇[17]等人提出了基于多序列联配的攻击特征自动提取方法。该方法包括奖励相邻匹配的全局联配(CMENW,contiguous matches encouraging needleman-wunsch)算法和层次式多序列联配(HMSA, hierarchical multi-sequence alignment)算法。CMENW 算法和HMSA算法都是建立在攻击序列中包含固定不变的子序列基础上的,它们不适合多态蠕虫的特征提取。以上所提出的蠕虫特征都依赖于蠕虫公共元组(token)本身。这样的特征对于普通的蠕虫有效,然而当蠕虫的形态发生变化后,如果某些公共子序列串发生了改变,例如蠕虫中有部分代码被加密,则此类特征就无法再进行有效地检测。而加密是多态技术中最常用的技术之一[18]。
2) 基于字节出现频率的特征提取方法。
Y. Tang[9]等提出的基于有位置意识分布特征(PADS, position-aware distribution signature)的蠕虫防御方法。PADS特征的每一个位置都是一个字节分布频率函数 fp(b),该函数是字节b在特征位置p出现的概率, b ∈ [ 0,255],。如果特征的长度为W,则 ( f1,f2,… , fw)就是蠕虫的PADS特征。PADS特征架起了传统特征和基于异常入侵检测系统之间的桥梁。然而,PADS特征仍然是建立在蠕虫负载本身的基础上,而蠕虫采用多态技术后,其形态发生变化,即负载的内容发生变化,与字节本身相关的特征将无法检测变形后的蠕虫。例如,当可疑池中并没有包含一类多态蠕虫的所有变形样本时,提取出来的字节分布频率函数 fp(b)是不正确的,无法检测可疑池中未包含的蠕虫样本。
以上2类蠕虫特征都是建立在蠕虫负载本身的基础之上,它们能够有效的检测普通的网络蠕虫。然而,它们在检测多态蠕虫时将会遇到困难。多态蠕虫将是下一代网络蠕虫[19]。它采用了多态和变形技术,使得蠕虫在传播过程当中改变其形态,有时某些隐秘的蠕虫可以做到数月之内不被人们注意到[18]。因此如何提取能成功检测多态蠕虫的特征成为了一个重要的研究问题。
目前的多态蠕虫技术主要包括以下几类。1)花指令插入,就是在蠕虫代码之间加入一些似乎没有什么意义的代码,这些代码不会妨碍程序正常的运行。花指令的插入并没有改变蠕虫代码内部字符之间的关系。2)简单加密技术,是指对蠕虫的某些主体代码采用固定的密钥进行加密,加密时一般采用XOR、OR、SUB、ADD等一些简单的变化。简单的加密虽然使得蠕虫代码字符发生了变化,但是依然保持了代码字节之间的关系。3)动态密钥加密技术。蠕虫在每次传播时,使用不同的密钥对解密后的蠕虫代码进行加密,从而会得到不同的加密代码。虽然加密的密钥不一样,但是还是采用的简单加密算法,所以蠕虫新的代码样本虽然字节发生了改变,但是依然能够保持蠕虫内部代码字节之间的关系。4)改变原始代码的加密技术。这是多态技术的最高形态。每次病毒变种时,原始病毒代码发生变化,然后再对改变后的代码进行加密。目前这类技术很少使用在蠕虫代码中,而且由于受到负载长度的限制,蠕虫只能具有有限的变种。所以我们容易获得采用这种技术的所有变种代码。
由上所述,除第4种加密技术外,其他技术虽然改变了负载内容,但是由于所有字节的变化规律是相同的,所以字节之间的相邻关系仍然没有发生变化;有的通过一定针对性的技巧,也可以把它还原到固定相邻关系的状态上来。
本文结合多态蠕虫的特点,提出基于近邻关系的特征NRS来进行蠕虫检测。NRS是相邻字节距离频率分布函数的集合。与简单的基于字节频率分布的 PADS(position-aware distribution)特征相比,NRS更加灵活。根据相邻字节间的距离,本文提出1-近邻特征1-NRS,2-近邻特征2-NRS和(1,2)-近邻特征(1,2)-NRS。在此基础上,进一步提出NRSGA特征产生算法。最后,本文将采用 Blaster蠕虫和SQL Slammer蠕虫作为测试样本来验证NRS检测多态蠕虫的有效性。
本文第2节提出基于近邻关系的特征,并对特征与蠕虫序列的匹配方式进行了详细的介绍;第 3节阐述基于近邻关系特征的产生算法;第4节给出了实验结果,并进行了分析和讨论,验证了本文提出的特征及其产生算法的正确性和有效性;第5节是结束语。
2 基于近邻关系的特征NRS
目前已有的基于特征的蠕虫检测方法大部分都是直接针对蠕虫负载字节或者子序列串来进行的,由于多态蠕虫的负载内容是经常发生变化的,所以这些方法无法有效地检测多态蠕虫。因此,本文结合多态蠕虫的特点,着重考虑负载字节以及子序列串之间的关系,设计了基于近邻关系的蠕虫特征NRS。
定义1(近邻)给定一个序列 Sj=c1c2…cm,ci为序列的第i个字节。称 ci+1为 ci的1-近邻,ci+2为ci的2-近邻。 cm无1-近邻, cm-1无2-近邻。
定义2(近邻距离)给定一个序列 Sj=c1c2…cm,ci和 ci+1的字节距离为。为了下文描述方便, di,i+1也称为序列S中位置i的1-近邻距离。 ci和 ci+2的字节距离为(i=1,…,m-2),即di,i+2为序列S中位置i的2-近邻距离。
每一类蠕虫序列中至少会有一个重要的区域来完成蠕虫的功能[9],采用重要区域字节的近邻距离出现的频率作为该类蠕虫的特征。
2.1 NRS的定义
设序列集合 S= { S1, S2,…,Sn}是一类蠕虫序列。假设已知该类蠕虫重要区域的长度为w,集合S中每条蠕虫序列重要区域的起始位置分别为a1, a2,…,an。接下来我们描述如何计算NRS。
1) 1-近邻关系特征1-NRS。
给定一个值 p (p=1,2,…,w-1),序列Si中位置1-近邻距离分布函数


本文定义 (f11,f21, …,fw1-1)为该 n条序列的1-NRS,特征长度为w-1。表1是从100条Blaster蠕虫序列中提取的1-NRS的例子,其中特征长度为9。
在表1中p表示特征的第几位,d表示字节距离。例如,当p=1、d=3时,表中的数据0.020 197 8表示蠕虫的重要区域位置1的1-近邻距离为3的频率。

表1 1-NRS特征实例
2) 近邻关系特征2-NRS。
给定一个值 p (p = 1,2,… ,w -2),序列Si中位置条序列中,第1条序列位置 a1+ p,第2条序列位置 a2+ p,…,第n条序列位置 an+ p的2-近邻距离为d的个数。
定义2-近邻距离分布函数
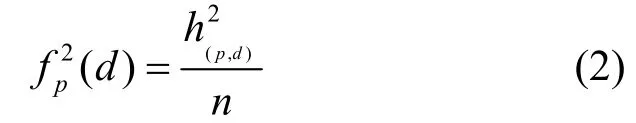
其中,
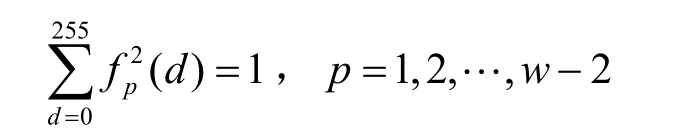
本文定义 (f12,f22, …,fw2-2)为该 n条序列的2-NRS,特征长度为w-2。
2.2 匹配过程

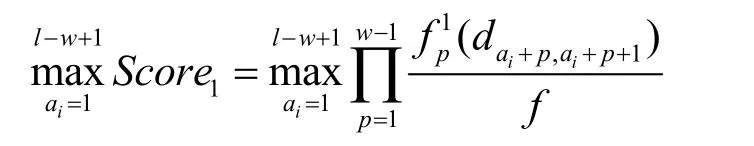


则序列 Si相对于2-NRS的最终匹配得分为

然而,由于单独使用1-近邻特征或者单独使用2-近邻特征仍然可能出现漏报的可能性,为了减小这种可能性,设计了 (1,2)-近邻特征来对蠕虫进行检测。该特征建立在1-近邻关系和2-近邻关系的基础上。
定义(1,2)-NRS为 ((f11,f21,…, fw1-1) ,( f12, f22,…,f2))。子序列串 K相对于(1,2)-NRS的匹配得w - 2 (Si , ai )分为

则序列 Si相对于(1,2)- NRS特征的最终匹配得分为

当序列的匹配得分Θ>0时,认为序列Si为与该特征相对应的蠕虫序列。该匹配得分所对应的长度为w的子序列串被认为是序列 Si的重要区域。
3 特征产生算法
如前所述,若已知n条序列的重要区域,可以计算出该蠕虫的1-NRS,2-NRS和(1,2)-NRS。反之,若已知某蠕虫的近邻关系特征,也可以计算出序列的重要区域。但是,在实际中,蠕虫的 NRS和它的重要区域都是未知的。所以,本文提出NRSGA(NRS generating algorithm)算法来计算蠕虫的重要区域以及提取蠕虫的近邻关系特征。
首先,随机选取蠕虫样本 S1, S2,…,Sn重要区域的开始位置 a1, a2,…,an,重要区域的长度设置为w。然后,在确定蠕虫序列重要区域与计算NRS 2个步骤之间进行迭代,从而产生最终的NRS。目前这样的迭代过程有很多方法来完成,其中应用的较为广泛的有(EM, expectation-maximization)[20]算法和Gibbs采样算法[20]2类。因此,NRSGA分别采用了以上2种算法来完成迭代过程,处理过程如下。
1)EM 算法:根据初始选择的重要区域的位置,按照式(1)和式(2)计算出近邻距离分布函数fp1(d)和 fp2(d),从而得到NRS。在计算出NRS后,反过来采用NRS与每一条序列Si进行匹配,根据式(3)~式(5),匹配得分最高的子序列作为序列 Si的重要区域,从而更新每一条序列重要区域的起始位置 ai。最后,算法进行迭代,根据重要区域的开始位置 a1, a2,…,an重新计算NRS。
2) Gibbs采样算法:首先,取出序列 S1,对剩下的 n - 1条序列根据重要区域的位置和式(1)、式(2)计算出近邻距离分布函数 fp1(d)和 fp2(d),从而得到NRS。在计算出NRS后,用NRS与序列 S1进行匹配,匹配得分最高的子序列作为序列 S1的重要区域,并更新序列 S1重要区域的起始位置 a1。然后取出序列 S2,对剩下的 n -1条序列提取特征,并重复以上过程。当取到 Sn之后,算法如果还没有终止,则重新取出 S1进行计算。
如果特征与蠕虫序列的平均匹配得分与前t次迭代所计算的匹配得分的平均值相差小于常数ε,则 NRSGA算法终止。NRSGA算法的描述如图 1所示。

图1 NRSGA算法
4 实验
实验采用Blaster蠕虫、SQL Slammer蠕虫作为测试用例。Blaster蠕虫利用Windows RPC DCOM漏洞进行传播。当攻击成功执行之后,Blaster蠕虫将获得被感染系统中的文件msblast.exe的副本[21]。SQL Slammer蠕虫是利用微软公司SQL Server的一个漏洞进行缓冲区溢出攻击。实验中,采用指令替代、花指令插入和加密等多态技术人工产生了Blaster蠕虫样本和SQL Slammer蠕虫样本。
4.1 特征产生算法的收敛性
分别产生了100条Blaster蠕虫样本序列和100条SQL Slammer蠕虫样本序列。应用NRSGA算法来计算2类蠕虫的1-NRS、2-NRS和(1,2)-NRS特征,其中,EM算法和Gibbs采样算法分别运行3次,每次随机选取100条序列的重要区域的起始位置。重要区域的长度设置为10w=。算法运行结果如图2和图3所示。
图2和图3中横轴x表示算法运行的时间,纵轴y表示100条蠕虫序列与所求特征的平均匹配得分。图2(a)、图2(b)和图2(c)分别表示EM算法和Gibbs算法提取 Blaster蠕虫 1-NRS、2-NRS和(1,2)-NRS的过程。图3(a)、图3(b)和图3(c)分别表示EM算法和Gibbs算法提取SQL Slammer蠕虫1-NRS、2-NRS和(1,2)-NRS的过程。从图2和图3可以看出,EM算法的收敛时间比Gibbs采样算法的收敛时间快。如图2(a)所示,EM算法在2s内所计算出的平均匹配得分就趋于稳定了,Gibbs采样算法需要超过 5s的时间才能使求出的平均匹配得分趋于稳定。这是因为Gibbs算法需要花费更多的时间才能使得所求的特征稳定。然而,EM 所求得的平均匹配得分小于Gibbs采样算法所求得的平均匹配得分。这主要是因为EM容易陷入局部最小化,而与EM算法相比,Gibbs采样算法能够获得较优的结果。如图2(c)所示, Gibbs采样算法所求得的平均匹配得分最高为 5.4,这应该是全局最大值,而EM算法所求得的匹配得分在3.1左右。比较图3(a)、图3(b)和图3(c),算法提取 (1,2)-NRS时所获得的最终平均匹配得分最高,这是因为提取(1,2)-NRS特征时同时考虑了 1-近邻关系和2-近邻关系,所以求得的匹配平均分会较高。
4.2 特征长度的影响
这个实验主要测试特征长度的选择与平均匹配得分的关系。实验选取100条Blaster蠕虫样本序列和100条SQL Slammer蠕虫样本序列作为特征提取的样本序列。应用EM算法和Gibbs采样算法分别来计算各类蠕虫不同长度的 1-NRS、2-NRS和(1,2)-NRS。其中特征的长度w分别取值为10,20,,100…。实验结果如图4所示。然后,使用10 000条Blaster蠕虫、10 000条SQL Slammer蠕虫序列和10 000条噪音序列对这些特征的质量进行测试。测试结果如图5所示。
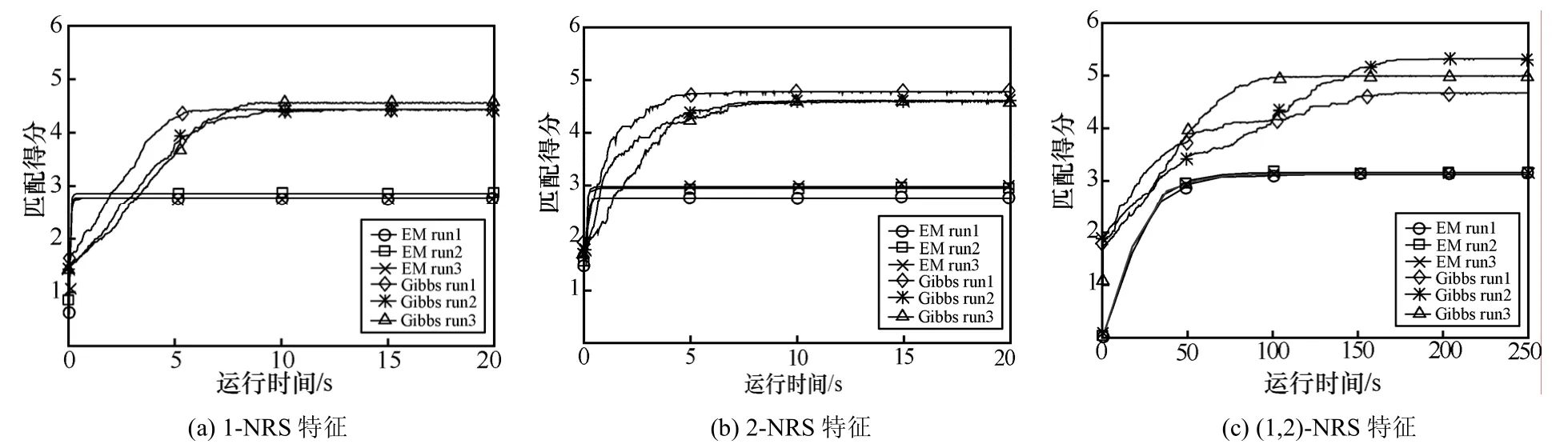
图2 Blaster蠕虫NRS特征

图3 SQL Slammer蠕虫NRS特征

图4 100条蠕虫序列与基于这些序列产生的特征的平均匹配得分
图4 (a)和图4(b)分别显示了100条Blaster蠕虫序列和100条SQL Slammer蠕虫序列与基于这些序列所提取的NRS特征的平均匹配得分。从图4可以看出,Gibbs采样所提取的特征的平均匹配得分高于EM算法提取的特征的平均匹配得分。例如在图4中,当特征长度 le ngth= 1 0时,Gibbs采样算法所提取的1-NRS的平均匹配得分为5.541,而与EM算法所提取的1-NRS的平均分为2.831。这主要因为Gibbs采样在计算蠕虫重要区域时,与EM算法相比能够获得较优的结果,而EM算法往往陷于局部最优。从图4还可以看出,随着特征长度的逐渐增加,平均匹配得分有逐渐下降的趋势。这里的特征长度即所认为的蠕虫序列中重要区域的长度。蠕虫序列中所设定的重要区域越长,则其中可能包含花指令的概率越高,每条蠕虫序列重要区域之间的差异就越大,那么蠕虫序列与基于这些蠕虫序列的重要区域所计算出的特征进行匹配时,所得到的平均匹配得分将可能越低。
图5(a)显示了10 000条Blaster蠕虫序列和10 000条噪声序列与NRS的平均匹配得分。图5(b)显示了10 000条SQL Slammer蠕虫序列和10 000条噪声序列与 NRS的平均匹配得分。这里的 NRS分别是Gibbs采样算法从100条Blaster蠕虫序列和100条SQL Slammer蠕虫序列中提取出来的。从图5中可以看出,蠕虫序列的平均匹配得分均高于 0,而噪声序列的平均匹配得分均低于0。所以0可以作为阈值来辨别蠕虫序列。

图5 10 000条蠕虫序列和10 000条噪声序列分别与NRS的平均匹配得分
4.3 误报率和漏报率
因为(1,2)-NRS同时考虑了1-近邻关系和 2-近邻关系,优于1-NRS和2-NRS,所以本文仅测试了(1,2)-NRS在检测蠕虫序列时的漏报率和误报率,并与 PADS[9]的漏报率和误报率进行了比较。由前面的测试可知,在NRSGA算法中应用Gibbs采样算法提取特征优于EM算法,所以本实验应用Gibbs采样算法进行特征提取。这里的误报率是指噪声序列被误判为蠕虫序列的数目与噪声序列总数的比。漏报率是指蠕虫序列被误判为正常序列的数目与蠕虫序列的总数的比。首先对100条Blaster蠕虫序列和100条SQL Slammer蠕虫序列分别提取(1,2)-NRS和PADS,然后用这些特征分别对10 000条蠕虫序列和10 000条随机序列来进行检测。NRSGA算法所提取的(1,2)-NRS特征和 PADS特征在检测蠕虫时产生的漏报率和误报率的结果比较如表2和表3所示。

表2 不同类型Blaster蠕虫特征的漏报率和误报率

表3 不同类型SQL Slammer蠕虫特征的漏报率和误报率
表 2和表 3分别显示了 Blaster蠕虫和 SQL Slammer蠕虫的(1,2)-NRS和PADS特征在特征长度为10,20,…,100时的漏报率和误报率。从表2和表3可以看出在特征长度为10时,(1,2)-NRS对于蠕虫的检测结果比较好。随着特征长度的增加,(1,2)-NRS的漏报率逐渐增加。在 2个表中,(1,2)-NRS特征与PADS特征的误报率都为0,说明它们都能较好地辨别噪声序列。然而,(1,2)-NRS特征的漏报率明显低于 PADS特征。例如在检测Blaster蠕虫序列时,当特征长度 le ngth= 2 0时,(1,2)-NRS特征的漏报率为0.042,而PADS特征的漏报率为1。这主要是因为PADS特征只考虑蠕虫负载字节本身出现的频率,所以当蠕虫序列中采用了加密等多态技术时,PADS特征就无法检测出来。而(1,2)-NRS考虑了蠕虫负载字节之间的关系,所以其漏报率低于PADS特征。
5 结束语
为了能够有效地检测网络中的多态蠕虫,本文提出了基于近邻关系的多态蠕虫防御方法。根据蠕虫序列的近邻关系,设计NRSGA算法提取了基于近邻关系的 1-NRS,2-NRS和(1,2)-NRS。该组特征考虑蠕虫负载内部之间的关系,而不是仅仅考虑负载本身,使得产生的特征更灵活,在检测多态蠕虫时更准确。本文进行了大量的实验对基于相邻关系的特征进行测试,并得出了以下结论:1) NRSGA算法能够正确的产生蠕虫特征;2) (1,2)-NRS特征由于综合考虑了蠕虫序列的 1-近邻关系和 2-近邻关系,所以优于1-NRS特征和2-NRS特征;3) 与PADS特征相比,(1,2)-NRS特征更灵活,所产生的漏报率较低,更适合于对复杂多变的多态蠕虫进行检测。
[1] 文伟平, 卿斯汉, 蒋建春等. 网络蠕虫研究与进展[J]. 软件学报,2004, 15(8): 1208-1219.WENG W P, QING S H, JIANG J C, et al. Research and development of internet worms[J]. Journal of Software, 2004, 15(8): 1208-1219.
[2] 杨峰, 段海新, 李星. 网络蠕虫扩散中蠕虫和良性蠕虫交互过程建模与分析[J]. 中国科学 E辑 2004, 34(8): 841-856.YANG F, DUAN H X, LI X. Modeling and analyzing interaction between network worm and antiworm during the propagation process[J].Science in China Ser E, 2004, 34(8): 841-856.
[3] 王佰玲, 方滨兴, 云晓春等. 基于平衡树的良性蠕虫扩散策略[J].计算机研究与发展, 2006, 43(9): 1593-1602.WANG B L, FANG B X, YUN X C, et al. A new friendly worm propagation strategy based on diffusing balance tree[J]. Journal of Computer Research and Development, 2006, 43(9): 1593-1602.
[4] 卿斯汉, 文伟平, 蒋建春. 一种基于网状关联分析的网络蠕虫预警新方法[J]. 通信学报, 2004, 25(7): 62-67.QING S H, WEN W P, GIANG G C. A new approach to forecasting Internet worms based on netlike association analysis[J]. Journal on Communications, 2004, 25(7): 62-67.
[5] 陈博, 方滨兴, 云晓春. 分布式蠕虫检测和遏制方法的研究[J]. 通信学报, 2007, 28(2): 9-16.CHEN B, FANG B X, YUN X C. Approach to early detection and defense against internet worms[J]. Journal on Communications, 2007,28(2): 9-16.
[6] 张新宇, 卿斯汉, 李琦. 一种基于本地网络的蠕虫协同检测方法[J].软件学报, 2007, 18(2): 412-421.ZHANG X Y, QING S H, LI Q. A coordinated worm detection method based on local nets[J]. Journal of Software, 2007, 18(2): 412-421.
[7] 王平, 方滨兴, 云晓春等. 基于用户习惯的蠕虫的早期发现[J]. 通信学报, 2006, 27(2): 56-65.WANG P, FANG B X, YUN X C, et al. User-habit based early warning of worm[J]. Journal on Communications, 2006, 27(2): 56-65.
[8] 肖枫涛, 胡华平, 刘波. HPBR: 用于蠕虫检测的主机报文行为评级模型[J]. 通信学报, 2008, 29(10): 108-116.XIAO F T, HU H P, LIU B. HPBR: host packet behavior ranking model used in worm detection[J]. Journal on Communications, 2008,29(10): 108-116.
[9] TANG Y, CHEN S. An automated signature-based approach against polymorphic internet worms[J]. IEEE Transactions on Parallel and Distributed Systems, 2007, 18(7): 879-892.
[10] CAI M, HWANG K, PAN J. WormShield: fast worm signature generation with distributed fingerprint aggregation[J]. IEEE Transactions on Dependable and Secure Computing, 2007, 5(2): 88-104.
[11] PORTOKALIDIS G, BOS H. SweetBait : zero-hour worm detection and containment using low- and high-interaction honeypots[J]. Computer Networks, 2007, 51(11): 1256-1274.
[12] RANJAN S, SHAH S, NUCCI A. DoWitcher: effective worm detection and containment in the internet core[A]. IEEE Infocom[C]. Anchorage, Alaska, 2007. 2541-2545.
[13] NEWSOME J, KARP B, SONG D. Polygraph: automatically generation signatures for polymorphic worms[A]. Proceedings of 2005 IEEE Symposium on Security and Privacy Symposium[C]. Oakland, California, 2005. 226-241.
[14] LI Z, SANGHI M, CHEN Y. Hamsa: fast signature generation for zero-day polymorphic worms with provable attack resilience[A]. Proceedings of IEEE Symposium on Security and Privacy[C]. Washington,DC, 2006. 32-47.
[15] CAVALLARO L, LANZI A, MAYER L. LISABETH: automated content-based signature generator for zero-day polymorphic worms[A].Proceedings of the fourth international workshop on Software engineering for secure systems[C]. Leipzig, Germany, 2008. 41-48.
[16] BAYOGLU B, SOGUKPINAR L. Polymorphic worm detection using token-pair signatures[A]. Proceedings of the 4th International Workshop on Security, Privacy and Trust in Pervasive and Ubiquitous Computing[C]. Sorrento, Italy, 2008. 7-12.
[17] 唐勇, 卢锡城, 胡华平. 基于多序列联配的攻击特征自动提取技术研究[J]. 计算机学报, 2006, 29(9): 1531-1539.TANG Y, LU X C, HU H P. Automatic generation of attack signatures based on multi-sequence alignment[J]. Chinese Journal of Computers,2006, 29(9): 1531-1539.
[18] STEPHENSON B, SIKDAR B. A Quasi-species approach for modeling the dynamics of polymorphic worm[A]. IEEE Infocom[C]. Barcelona, Catalunya, 2006. 1-12.
[19] SZOR. P. The Art of Computer Virus Research and Defense[M]. Symantec Press Publisher, 2005.
[20] BISHOP.CHRISTOPHER M. Pattern Recognition and Machine Learning[M]. Information Science and Statistics, 2006.
[21] CERT advisory CA-2003-20: W32/blaster worm computer emergency response team[EB/OL] http://www.cert.org/advisories/CA- 2003-20.html, 2003.
