汉语框架自动识别中的歧义消解
2011-06-14李济洪高亚慧王瑞波李国臣
李济洪,高亚慧,王瑞波,李国臣
(1. 山西大学 计算中心,山西 太原 030006; 2. 山西大学 数学科学学院,山西 太原 030006;3. 太原工业学院,山西 太原 030008)
1.问题背景
语义分析是自然语言处理的目前研究的热点。近年来,语义分析的相关评测任务在在SemEval2007[1]、CoNLL Shared Task 2008[2]、2009[3]、SemEval-2(2010)[4]等重要评测中频繁出现。这些评测有效地推动了自然语言处理技术的研究和发展。
近十年来,基于认知的框架语义学以及在其上构建的英语FrameNet[5]得到许多研究者的关注,成为Senseval-3[6]、SemEval2007、SemEval-2(2010)语义分析评测任务的主要使用的语义资源。按照评测任务中的要求,对给定一个句子中的动词(或事件名词),首先要自动识别出其所属框架,再标注出该词所支配的语义角色,进而形式化出句子,乃至整个篇章的语义信息的一种描述,为问题回答、篇章理解、信息检索等应用提供可用的语义线索。
汉语框架语义知识库[7](CFN,Chinese FrameNet )是参照英语FrameNet而构建的。类似于英文的框架自动识别任务(SemEval2007 Task 19)[1],在汉语的框架识别(Frame Identification)中,对给定的一个目标词,需要判定其所属框架。如例句: 全书的观点
文献中基于FrameNet对框架识别的研究已作过初步探讨。Erk等[9]于2005年使用传统的词义消歧的方法针对德语FrameNet的框架消歧的任务进行了研究。他们将消歧看作分类问题,采用朴素贝叶斯分类器,并使用词语的上下文窗口、词包以及一些词语搭配等特征。在其测试集上框架消歧的性能可以达到74.7%的F值。对未知框架检测,Erk[10]将这个任务看作“异常点检测”,在其实验中取得了78%的精确率。SemEval 2007的Task 19主要针对英文FrameNet的框架识别、语义角色标注和整个句子中词语间语义关系的抽取进行了评测[1]。其中,框架识别是其中的子任务之一。只有三个评测队伍提交了框架识别任务的评测结果。其中,Richard Johansson等的结果最好,他们使用SVM分类器来对框架识别任务进行建模,并从依存句法分析树上抽取出目标词、目标词的子节点的词及它们的依存关系,以及相应的子范畴框架等信息作为特征。在给定的评测三篇语料“Dublin”、“China”和“Work”上,框架识别的结果分别达到了60.12%、69.18%和74.88%的F值。
目前,CFN的建设尚处于初始阶段,共构建了219个框架,涵盖1 760个词元和21 600条已标注的句子。CFN构建中,主要采用的辅助工具有山西大学FC2000,框架的语义角色自动标注器(在给定目标词及其框架下)[7],因此,进一步研究框架消歧,将为自动构建CFN知识库提供更多的辅助标注工具,加快CFN的建设步伐。从CFN中统计结果看,其中有88个词元可以激起两个以上框架,涉及框架14个,相应的例句2 077条。本文正是基于这部分语料,对汉语框架消歧的研究进行了初步探索,将框架消歧任务看作典型的单点分类问题,使用最大熵对其进行建模,选用词、词性、基本块、依存句法树上的若干特征,并且借助于开窗口技术和BOW策略,采用3-fold交叉验证方式进行了实验,结果表明,框架消歧的精确率(Accuracy)达到69.28%,这是目前汉语框架消歧实验最好结果。
本文的组织结构如下: 第2节描述了框架消歧任务;第3节描述了实验所用的各种特征;第4节介绍了本文采用的评价指标;第5节给出了具体的实验结果及分析;第6节为总结与展望。
2 框架消歧任务描述
根据上文的描述,框架识别任务可以分为三个子任务,1)词元检测;2)未知框架检测;3)框架消歧(Frame Disambiguation,简记为 FD)。本文主要研究整个框架识别任务中的第三个子任务,即框架消歧: 给定一个句子中目标词,已知其可以激起多个框架,要求计算机能够基于上下文环境,从现有的框架库中,为该目标词自动地标注一个适合的框架。 子任务的形式化描述如下。
给定一个句子,记为S, 将S看作一个由词组成的序列,记为S=(w1,w2,…,wn),这里wi代表组成句子的第i个词语,1≤i≤n。记wt∈S为给定的待标注的目标词,且其可以激起的框架集合记为F={f1,f2,…,fm},那么,框架消歧的任务为,寻找唯一一个f∈F,使其满足:
显然,给定句子S及目标词wt,上式是个一个典型的分类问题,本文选用最大熵(ME,Maximum Entropy)来建立模型,其详细描述请参见文献[11]。由于自然语言处理中存在大量的稀疏特征,这会影响最大熵模型参数估计的稳健性,因此,一般在其似然函数中加入惩罚项,采用最大后验估计的方法进行参数估计。本文实验中选用的惩罚项为服从均值为0, 方差为C的高斯分布,通过调节参数C(下文中称为Gauss平滑参数),使得模型的分类性能达到最优。
3 特征提取和选择
最大熵模型是较为常用的分类模型,其分类性能主要依赖于上下文中抽取的特征。如何抽取特征,并充分利用特征信息是框架消歧系统建模首先要解决的问题。
本文选取的特征主要取自三个层面,词层面、基本块层面(BC,Base-Chuck)及依存语法关系层面(DP,Dependence-Tree),详见表1。 词层面主要包括词、词性以及目标词所在句子的词包(BOW,Bag-of-Word)。语料库中分词和词性体系使用的是山西大学FC2000体系。在下文的实验中,训练和测试集上的特征的提取直接取自语料库中已分好词(含命名实体标注)的例句。
基本块层面特征用来描述目标词所在基本块与相邻块的块层面组合关系。采用的是清华大学周强的基本块描述体系[12],主要包括句法标记(如np、vp等)、结构标记(如,定中结构DZ、单词块SG等)、中心词。实验中先采用周强的自动分析器对每个例句自动分析,然后再提取所用基本块层面特征信息,因此,这部分的特征信息全部是自动提取的,参见下文的例句和表2。
依存语法关系层面特征用来描述目标词在依存句法树中与直接连接的成分及依存关系。本文采用的特征详见表1的第三部分。考虑到目前的汉语依存句法自动分析器还有待完善,实验中,本文分别使用了目前较好的三种分析器,它们是Stanford大学的依存句法分析器(v1.6)[15]、Mate依存分析器[13]和哈尔滨工业大学信息检索研究中心(HIT)依存分析器[14],对所有例句进行自动分析,获取相应特征信息。具体的特征取值实例参见下文的例句和图1。
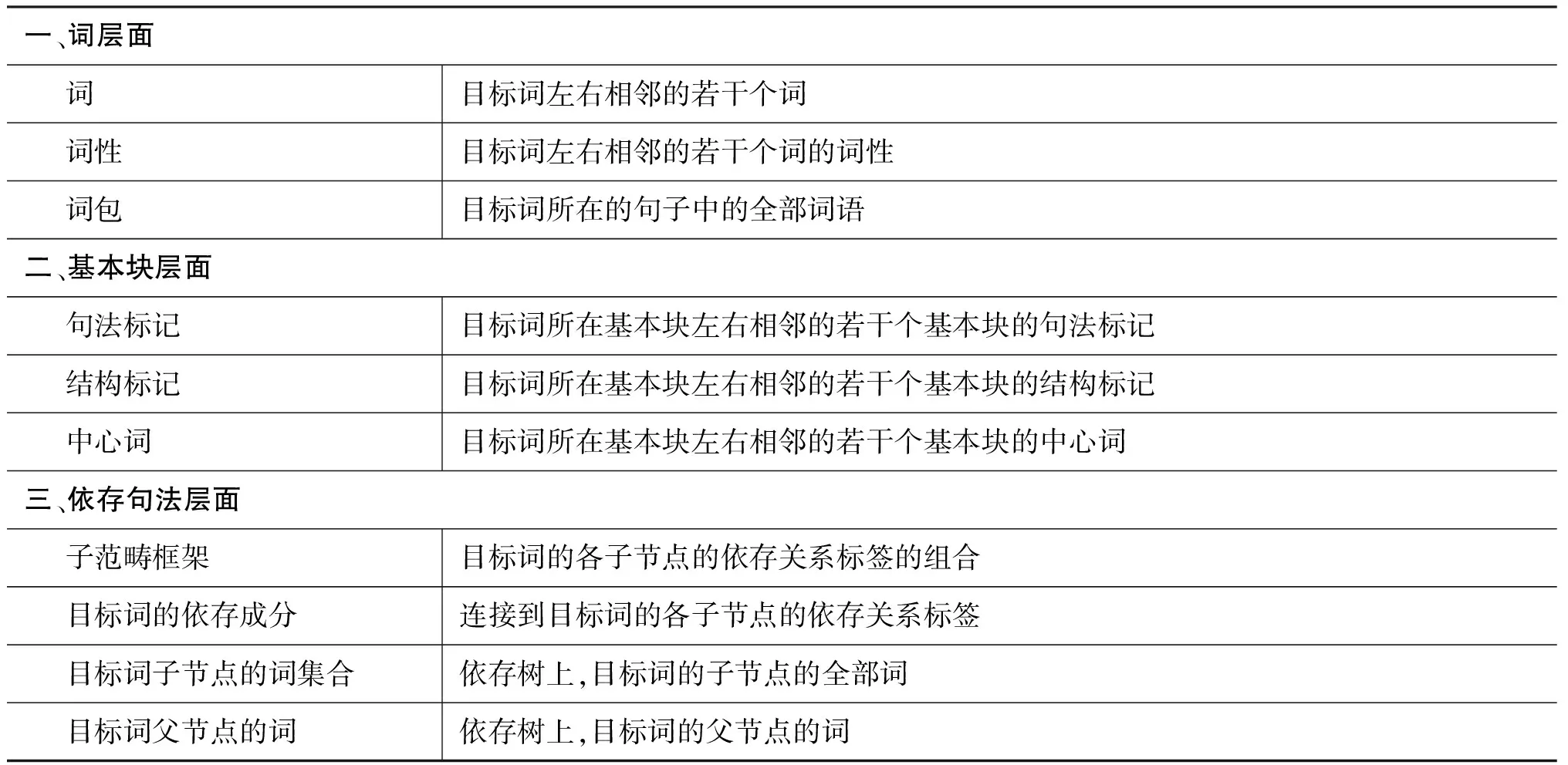
表1 特征列表
为了对比评价各层面特征对框架消歧系统的贡献,本文将各特征进行组合,设计了以下六个模型的实验:
(1) Baseline: 仅使用词和词性特征,调节特征的窗口大小(从[-1,1]到[-5,5]),选择最优结果的特征窗口大小作为Baseline模型;
(2) Baseline +BOW: 在Baseline模型基础上加入词包特征。即一个句子中所有词的集合,且与词的顺序无关;
(3) Baseline +BC: 在Baseline模型基础上加入基本块特征,BC特征的窗口大小可以取[-1,1]到[-3,3];
(4) Baseline+DP: 在Baseline模型基础上加入表1中依存句法特征;
(5) Baseline +BOW+DP: 在Baseline模型基础上加入词包特征和依存句法特征;
(6) Baseline+All: 表1中罗列的全部特征。
其中,使用词、词性和基本块特征时,窗口的选择从[-1,1]到[-5,5]。这里[-n,n](n=1,2,…,5)表示选取特征的窗口大小,-n代表所选特征位于目标词左边,n代表所选特征位于目标词右边,开大小为n的窗口(例如,以词特征为例,窗口大小 [-2,2] 代表选取目标词左边的两个词和右边的两个词作为特征,其他依此类推)。下面以实例说明相应特征的取值,假设特征窗口取[-2,2],词、词性和基本块特征的具体取值如表2所示。
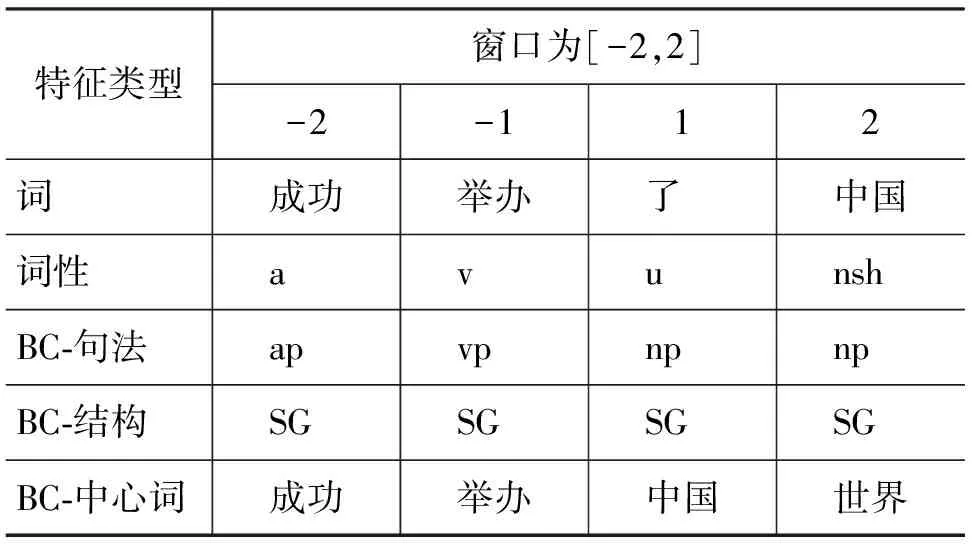
表2 目标词“增加”的特征窗口取[-2,2]时,相应的词、词性和基本块特征的具体取值
例句: [np-SG 奥运会/jn ] 的/u [ap-SG 成功/a ] [vp-SG 举办/v ] [vp-AD 增加/v 了/u ] [np-SG 中国/nsh ] 在/p [np-SG 世界/n ] 的/u [np-SG 知名度/n ] 。/w
本文基于自动获得的依存句法分析树,抽取四种依存句法特征如下。参照上文的例句,下图给出其基于Stanford、Mate、HIT三个自动分析器得到的依存句法分析树(见图1)。
针对目标词“增加”,以Stanford分析器得到的依存句法分析树为例,四种依存特征的具体取值如下给出:
(1) 子范畴框架: nsubj+dobj+asp ;
(2) 目标词的依存成分: {nsubj,asp,dobj};
(3) 目标词子节点的词集合: {举办,了,知名度};
(4) 目标词父节点的词: {null}。
其他两种依存句法分析器的特征取值类似。

图1 Stanford、Mate、HIT自动分析的依存句法分析树
4 评价指标
给定一个目标词Wi(i=1,…,n),n为所选词的总数(如本文n=88),在三份交叉验证试验CVj(j=1,2,3)下, 全部目标词的分类精确率(Accuracy)如下计算:
其中,Nij是目标词wi的第j份交叉验证实验CVj中测试例句的个数,ccij是目标词wi的第j份交叉验证实验CVj中框架分类正确的测试例句个数。
本文以实验中选取的全部目标词的分类精确率作为评价指标。
5 实验结果与分析
针对框架消歧任务,本文选取汉语框架语义知识库中可以激起多个框架的词语的相应例句作为训练、测试数据集。经统计这样的词有88个,其中,可以激起4个框架的词有1个,可以激起3个框架的词有13个,激起两个框架的词有74个。实验中,将所选出的88个词中全部2 077条例句,按照每个词元所属的不同框架,将例句均匀分为3份。任意2份为训练集,另1份做测试集,做3-fold 交叉验证。以下的实验中Gauss平滑参数取1,2,3,…,20。
表3给出了仅以词、词性两特征,在不同窗口大小以及最大熵模型的不同Gauss平滑参数(C >7的略去)下,框架消歧的实验结果。

表3 词、词性两特征的实验结果(Accuracy/%)
从表3看出,框架消歧系统的性能分别在以下两种情况时最好: 第一种情况,词、词性特征窗口为[-2,2],Gauss平滑参数C=2;第二种情况,词、词性特征窗口为[-3,3],Gauss平滑参数C=5,此时,框架消歧系统精确率为64.42%。进一步考虑到最大熵模型在词、词性特征窗口取2时,特征数相对较少,训练时间较短,因此,本文以词、词性特征窗口取2时得到的模型为Baseline。以下分析分别加入其他特征对系统性能的影响。
(1) 在Baseline基础上加入BOW特征后,框架消歧系统的性能取得了68.37%的结果,比Baseline提高了3.95%。BOW特征主要体现了在句子中常常与目标词同现的词语。框架消歧系统性能的明显提高说明,目标词与其他词的搭配信息在目标词的框架消歧任务中起重要作用,这基本符合语言学的规律。
(2) 在Baseline基础上加入自动获得的BC特征,结果(为节省篇幅,将Gauss平滑参数C >5的略去)如下:
基于Baseline+BC,将BC特征窗口大小依次从[-1,1]到[-3,3]调整,发现框架消歧系统的性能在基本块特征窗口为[-2,2]时最大。此时系统性能达到64.42%,与Baseline系统相同。这表明BC特征对框架消歧任务基本不起作用。 这其中可能的原因是: 本文使用的是基本块的自动分析器,而自动分析器的性能在开放语料环境下并不理想。

表4 Baseline基础上基本块特征的实验结果
例如,本文上面所给出的例句的BC特征的具体取值(见表2),自动分析的结果大多为单词块(SG),BC特征与词特征相比,除了标记记号不同以外,基本上没有为模型增加更多的信息,因此,对系统性能的提高作用不大。本文将以下含有BC特征的模型实验的BC特征的窗口统一固定为[-2,2]。
(3) 在Baseline基础上加入自动分析获得的DP特征,结果如下:
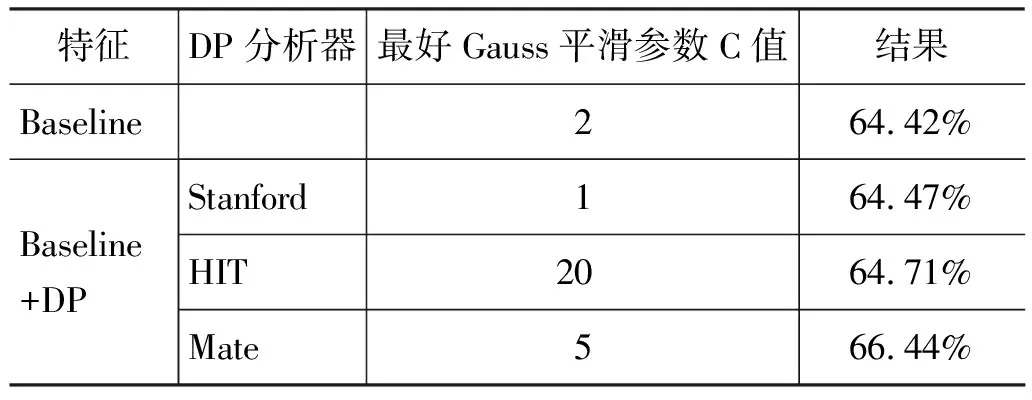
表5 在Baseline基础上加入三种依存句法分析器的结果
需要说明的是,在使用Stanford的DP分析器对语料中所有句子自动分析中,有14个句子不能输出结果,占14/2 077=0.67%。即使如此,从上表可以看出,系统基于三种不同的依存句法分析器的结果抽取DP特征,系统性能均有不同程度的提高,说明DP特征对框架消歧有一定的作用。系统性能提高的幅度不高,主要是由于目前在开放语料测试环境下,自动分析器的性能并不理想。
(4) 在Baseline+BOW的基础上,加入自动分析获得的DP特征,结果见表6。
从表6可以看出,在Baseline+BOW基础上加入DP特征,各系统性能也均有提高,这进一步说明DP特征对框架消歧任务有用。
(5) 使用全部特征, 即Baseline +BOW +DP+BC,结果见表7。
在Baseline+BOW+DP基础上加入BC特征,系统性能均有不同程度下降,这进一步说明BC特征对系统没有作用。

表6 在Baseline+BOW基础上加入三种依存句法分析器的结果
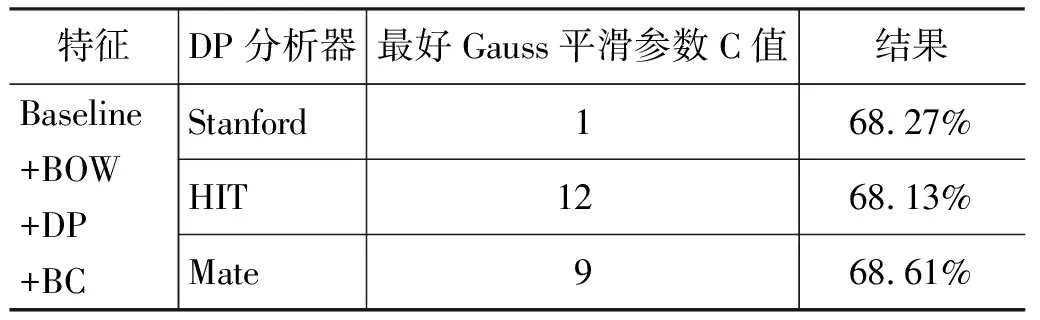
表7 在Baseline+BOW+DP基础上加入BC特征的结果
结论: Baseline +BOW +DP(Mate)组合特征的系统性能69.28%为所有模型中最好。图2是六个模型的性能随Gauss平滑参数C值变化的图,其中DP特征是从Mate句法分析器自动获取的依存句法分析树中抽取的。
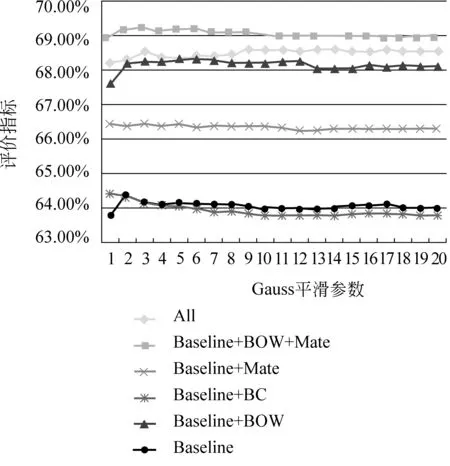
图2 各模型的性能随Gauss平滑参数C值变化图
6 总结与展望
本文将汉语框架消歧任务看作典型的分类问题,使用最大熵对其进行建模,并且借助于开窗口技术和BOW策略分别选取了词、词性、基本块、依存句法树上的若干特征,构建了汉语框架消歧模型,该模型的精确率(Accuracy)达到69.28%,这是目前汉语框架消歧实验的最好结果。综合分析本文的实验结果,归纳几点主要结论如下:
(1) 自动分析得到的基本块特征对框架消歧任务不起作用;
(2) 依存句法特征对框架消歧任务有作用。三种自动依存句法分析器中Mate最好,其他两个没有差别;
(3) 词包特征(BOW)对框架消歧任务作用明显;
(4) 基于词、词性、词包、依存句法(Mate)组合特征的模型,性能最高。
框架消歧是汉语框架网络自动语义分析中重要的步骤,与传统的词义消歧(主要是名词的消歧)不同,框架消歧主要针对句子中核心动词或事件名词,这些词是句义的主要承担者。框架语义学认为,框架是人类认知中逐渐形成且固定下来的概念结构,这些概念结构相互联系形成网络。一个概念(框架)的理解不只是孤立考察这个概念本身,而是要将其放在整个框架网络中才能理解。一个句子乃至篇章的语义是由其中的词语激起的框架以及这些框架之间的关系来表达的。同一个词语在不同的句子中可以激起不同的框架(概念结构),导致不同的理解。因此,根据上下文正确识别出词元的适当框架对句子的理解非常重要。
然而,本文所构建的汉语框架消歧模型中涉及的上下文只在句子层面。直观地说,就是根据目标词在句中经常搭配的词语,以及目标词所在依存句法分析树的句法信息来判别目标词所激起的框架。这样只用到句子层面的上下文信息是否充分,是否还需要更为丰富的上下文信息(比如段落或篇章),以及如何用?这是下一步需要研究的。 在SemEval-2007 Task 19评测任务中,测试是建立在整篇文本之上的,这说明基于整个篇章对框架消歧任务进行建模和评测更实用。事实上,框架语义学的初衷并不局限于句子层面的理解,而是瞄准整个篇章的语义分析,因此,在英文FrameNet的语料中,有几十篇的全文框架标注,其目的是明确的。
另外,仅从框架消歧模型的技术层面来说,消歧模型可以考虑使用CFN中相应框架定义描述中的信息,或定义中的例句信息,这些新特征都有可能增加系统的性能。另一方面,目前语料规模较小,虽然本文采用了交叉验证方法,减少了结果的波动,但是系统性能的提升仍受语料规模的限制,需要考虑如何使用未标注语料,扩大语料规模,减少特征信息的稀疏性,此外,也可以尝试使用其他的分类模型,如SVM、神经网络等。这些都是下一步研究的主要方向。
致谢
实验过程中使用了山西大学FC2000分词软件、清华大学周强教授提供的汉语基本块自动标注器、Stanford大学的句法分析器(v1.6)、哈尔滨工业大学信息检索研究中心语言技术平台LTP,Mate依存句法分析器,在此表示谢意!
[1] Collin Baker, Michael Ellsworth, Katrin Erk, SemEval’07 Task 19: Frame Semantic Structure Extraction [C]//Proceedings of the 4th International Workshop on Semantic Evaluations Prague, Czech Republic, June 23-24 2007: 99-104.
[2] Surdeanu M, Johansson R, Meyers A, Màrquez L, Nivre J. The CoNLL 2008 Shared Task on Joint Parsing of Syntactic and Semantic Dependencies [C]//Clark A, Toutanova K, eds. Proc.of the CoNLL-2008. Manchester: ACL Press, 2008: 159-177.
[3] Hajic J, Ciaramita M, Johansson R, Kawahara D, Marti MA, Màrquez L, Meyers A, Nivre J, Padó S, Stěpánek J, Stranak P, Surdeanu M, Xue NW, Zhang Y. The CoNLL-2009 shared task: Syntactic and Semantic Dependencies in Multiple Languages [C]//Stevenson S, Carreras X, eds. Proc. of the CoNLL-2009. Boulder: ACL Press, 2009.
[4] Josef Ruppenhofer,Caroline Sporleder and Roser Morante.SemEval-2010 Task 10: Linking Events and Their Participants in Discourse[C]//Boulder: ACL Press, 2010: 45-50.
[5] Baker CF, Fillmore CJ, Lowe JB. The Berkeley FrameNet project [C]//Morgan K, ed. Proc. of the COLING-ACL’98. Montreal: ACL Press, 1998: 86-90.
[6] Litkowski KC. Senseval-3 task automatic labeling of semantic roles [C]//Mihalcea R, Edmonds P, eds. Proc. of the 3rd Int’l Workshop on the Evaluation of Systems for the Semantic Analysis of Text. Barcelona: ACL Press, 2004. 9-12.
[7] 李济洪,王瑞波,王蔚林,李国臣. 汉语框架语义角色的自动标注研究[J].软件学报, 2010,30(4): 597-611.
[8] Navigli, R. 2009. Word Sense Disambiguation: A Survey [J]. ACM Computing Survey. 41, 2 (Feb. 2009), 1-69. DOI=http://doi.acm.org/10.1145/1459352.1459355.
[9] Erk, K. (2005). Frame Assignment as Word Sense Disambiguation [C]//Proc.of IWCS-6, Tilburg University, Tilburg, the Netherlands, 2005.
[10] Erk, K. 2006. Unknown word sense detection as outlier detection [C]//Proc.of the Main Conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics (New York,June 04-09,2006). Human Language Technology Conference. Association for Computational Linguistics, Morristown, NJ, 128-135. DOI=http://dx.doi.org/10.3115/1220835.1220852.
[11] Berger, A.L.,Pietra, V.J., and Pietra, S.A. A Maximum Entropy Approach to Natural Language Processing [J]. Computational Linguistic, 1996, 22(1): 39-71.
[12] 周强.汉语基本块描述体系[J].中文信息学报, 2007, 21(3): 21-27.
[13] Bernd Bohnet. Top Accuracy and Fast Dependency Parsing is not a Contradiction[C]//The 23rd International Conference on Computational Linguistics (COLING 2010), Beijing, China. 2010.
[14] 马金山.基于统计方法的汉语依存句法分析研究[D].哈尔滨工业大学博士学位论文. 2007.
[15] Marie-Catherine de Marneffe, Bill MacCartney and Christopher D.Manning. Generating Typed Dependency Parses from Phrase Structure Parses[C]//LREC 2006. 2006.
