采用改进重采样和BRF方法的定义抽取研究
2011-06-14顾宏斌
潘 湑, 顾宏斌
(南京航空航天大学 民航学院,江苏 南京 210016)
1 简介
随着国内航空业的发展,对于民航从业人员的培训需求迅速增长。当前各种培训材料主要来源于各种技术文档和维护手册,而针对特定目的的培训教材和考核试题则完全由培训教员手动编写。术语可以是单个的词或者短语,其定义是培训素材中可以用来描述术语所描述的事物的本质特点、作用、发生原因、位置、成分结构,或者其来源、形成情况等的句子[1]。这样的句子不仅包含了可用于培训教材的认知型信息,而且其结构很适合作为考核题库以及领域本体系统的备选资料。
现有的定义抽取技术主要用于在自动问答系统中抽取答案,抽取的定义限于表达‘what is’和‘who is’类型的知识,利用的语料一般是使用给定术语词汇从搜索引擎或者语料库中抓取的相关文本信息。抽取的一般步骤是先用规则匹配方法获取候选定义句,之后用分类的方法作进一步划分以提高准确率,或者用排序的方法选出得分较高的句子作为给定术语的定义。
本文的目标是从航空民航专业语料库中识别出所有包含航空、民航专业术语定义的单句,和现有的定义抽取技术的目标相比有一些不同之处。首先是要求获得语料中所有的包含术语定义的单句,而不是给定术语的定义句;其次,要求可以获得类型多种多样的定义句,而不仅仅是‘what is’和‘who is’类型;再次,要求抽取的结果能够达到尽可能高的召回率和准确率,而不仅仅是保证排序较高的少数几个句子的准确性;最后,现有方法大多利用经初步筛选后的语料中包含的词语的出现频率来计算排序分值,这种方法既不利于按领域划分术语定义也不利于保证最终结果中术语定义的时效性。由此可见,现有的定义抽取方法无法满足本文的要求,因此本文提出了一种完全依靠分类方法来进行发现语料中的所有专业术语定义的方法。
本文的以后的内容安排如下: 第2节介绍了近年来国内外对于各种术语定义抽取方法的研究和应用,并在最后提出了本文所使用方法的基本思想。第3节介绍了本文实验所采用的语料库的情况以及本文实验的一些设计。第4节首先在本文实验的语料库上进行了仅使用BRF方法的实验,之后介绍了本文提出的基于实例距离分布信息的过采样方法的实验。第5节是全文的结论。
2 研究现状
2.1 用于自动问答系统的定义抽取
当前用于自动问答系统的定义抽取,大多先用规则匹配方法获取候选定义句。使用的规则模板大致分为两类,一类是硬匹配模式(Hard Patterns)[2-3],另一类为柔性模式(Soft Pattern)[4-5]。大部分针对英文语料的实验,主要针对系动词和核心动词建立模版;而在中文研究中,采用的模版包含了除核心动词外的其他一些词汇,同时,在目前所见的研究中,均为硬匹配模版,模式的数量一般在5~8个之间。
而柔性模式,则是从大量正例文本中通过结合词汇片段和语言学标注,结合概率模型和上下文顺序来获取不同层次的模式[6],这种方法在一些信息抽取项目中已被广泛应用[7]。
在分类阶段所使用的方法包括了大多数已知的分类方法,如K-临近(Knn)法、朴素贝叶斯(Naïve Bayes)法、支持向量机(Svm)方法等。从报告的结果看,在针对斯拉夫语的实验中,单纯是用机器学习方法而不使用规则模式的时候,准确率最低只有不到9%(正例:反例为1∶1),而综合了规则模板和多分类器的方法则可以达到20%的准确率[8-9]。而在针对英语的实验中,综合了机器学习方法和模式规则的方法效果较好,在定义句占训练语料58.1%的实验中,可以达到85%以上的准确率。但是,采用不同核的SVM 效果差异较大,径向基(Radial Base Function, RBF)核效果最好,而线性核的效果甚至不如朴素贝叶斯方法[10]。
排序的方法主要见于李航和张榕的论文[2-3],排位越高的句子,越倾向于认为是定义。张榕利用词在术语和非术语语料中的出现频率来定义词和句子的隶属度;李航等使用句子的基本名词短语为特征,用Svm方法排序。在选取排序前三的结果进行比较时,前者在中文语料上达到83%的准确率,后者在包含16.5%的定义句的英文语料上达到88%的准确率。
2.2 使用分类方法的定义抽取
近期也有学者开始用处理不平衡数据分类的方法作为单一步骤来处理术语定义分类的问题。当一个数据集中的一个类别包含的实例数量远远小于其他类别时,这个数据集被认为是不平衡的。本文使用的语料库中,定义句的数量远远少于非定义句,可以被认为是一种二分类的不平衡数据集[11-12]。在现实世界中,存在很多类似的问题如网络入侵检测[13]、利用卫星图像进行原油泄漏检测[14]、罕见疾病诊断、飞机故障检测等。在面对这样的极不平衡数据时,一般的分类器极难准确预测作为少数类的正例。
处理不平衡数据分类问题的策略主要有两类。其一是对原始数据集进行重采样[16-19],既可以对少数类数据进行过采样,也可以对多数类数据进行欠采样,直至达到一个能够获得较好分类结果的数据分布[20]。其二是通过给不同的类别设置不同的误分类代价来提高分类敏感的学习方法的分类性能[21-23]。
重采样技术在将数据交给分类器处理前先对数据分布进行调整,达到合适分布。其中最简单的方法是进行随机的过采样和欠采样[17],前者随机的复制正例加入到少数类中,后者随机的从多数类中去除反例,但是前者会导致过拟合的问题,而后者会去除数据中很多重要信息。为了解决这些问题,近年来相关研究人员针对重采样方法进行了诸多改进。
Chawla等人于2002年设计了过采样技术SMOTE(Synthetic Minority Over-Sampling TEchnique)[19],通过在两个相邻正例之间生成一个合成实例来对少数类进行过采样,可以在一定程度上避免过采样算法中的过学习问题。但是在处理高偏问题时效果有限,因为高偏问题中少数类往往过于稀疏,从而导致少数类和多数类最终混杂在一起。
Han等人,于2005年在SMOTE的基础上进行改进,提出了Borderline-SMOTE技术[24],将正例划分为噪声、边界、安全三个区域,采用和SMOTE相同的过采样方法,但是只对边界域中的少数类进行过采样。
Chumphol Bunkhumpornpat等人于2009年,对SMOTE做了进一步改进,提出了Safe-Level-SMOTE技术[25],通过计算一个少数类实例的safe level,来确定不同的过采样合成实例的生成位置。该方法可以得到比SMOTE和Borderline-SMOTE更高的准确率。
改进欠采样的方法有Condensed Nearest Neighbor[26]、Neighborhood Cleaning Rule[27]、One-sided Selection[17]、Tomek Link等[28]。这些方法通过一些方法,找出边界样本和噪音样本,有选择地去掉对分类作用不大,即远离分类边界或者引起数据重叠的多数类样本,并将其从大类中去掉,只留下安全样本和小类样本作为分类器的训练集。通常改进的欠采样方法得到的分类效果比随机欠采样理想一些。
Bagging(Bootstrap AGGregatING)算法[29]是一种集成学习(ensemble learning)技术[30],该算法在训练阶段,各学习器的训练集由原始训练集利用可重复采样(bootstrap sampling)技术获得,训练集的规模通常与原始训练集相当。原始训练集中的某些实例可能在新的训练集中出现多次,而另一些实例可能不出现。Bagging可以显著提高不稳定的分类器的泛化能力。大部分集成学习算法在生成多个独立的分类器之后,通常是对所有的分类器的结果进行聚合,因此很多研究者尝试使用大规模的集成来解决问题。BRF方法是在Bagging基础上发展起来的,利用可放回的重采样方法以不平衡数据为基础获得平衡训练集的集成学习技术[15]。
本文采用完全依靠分类的方法来解决定义抽取的问题,首先使用基于实例距离分布信息改进的过样方法调整语料的不平衡分布,之后结合随机欠采样方法构建多个平衡训练集用以训练C4.5决策树,之后使用BRF方法获得C4.5决策树分类结果的聚合。该方法既获益于重采样方法对数据分布的调整,又获益于Bagging方法对不稳定分类器性能的提升。
3 实验设计
3.1 语料库建设
本文使用的语料库及其预处理过程和文献[31]相同,由4本航空专业教材构成,总计16 627个句子,其中包含1 359个定义句或包含定义的句子。如果以定义句为正例,非定义句为反例,则正例占实例总数的约8%,正例与反例的数量比是1∶11.2,是一种极不平衡的数据集。
3.2 分类器
本文的实验使用新西兰怀卡托大学开发的怀卡托智能分析环境(Waikato Environment for Knowledge Analysis,WEKA)中的J48算法来构建分类树,这是C4.5算法的一个变种。
3.3 评价指标
本文的实验使用的评价方法包括召回率(Recall)、准确率(Precision)、F-measure,定义如下:
F-measure中β的取值由实验中召回率和准确率的重要性来决定,当β取值为1的时候(F1指标),认为召回率和准确率同等重要;当β取值为2的时候(F2指标),认为召回率比准确率更加重要。
3.4 特征选择和权重设置
本文使用词袋模型作为文本表达方式,使用的特征为经哈尔滨工业大学LTP中文处理平台分词得到的中文词[32]。使用词汇的TF×IDF(词频×逆文档频率)作为特征的权重。
通过以前的研究表明,使用IG(Information Gain)或者CHI(开方检验)方法可以在使用较少数量的特征时,依然能够保证分类器的性能[31],本文最终使用IG作为本文实验的特征选择依据。如图1 所示(针对单颗树选取不同比例的特征对结果的影响图),分别给出了使用随机重采样技术和本文提出的改进重采样技术情况下,在选用占总特征数不同比例的特征时单个分类器分类结果F2指标的变化情况。两组实验分别使用对原始数据集进行50次重采样得到的数据作为训练集,以原始数据集作为测试集,实验结果取平均值。实验结果表明,使用IG作为特征选择方法,单个分类器的F2评价指标随着选用特征的数量不同而变化。从选用特征数量为特征总数的1%开始,F2指标逐步提高。当选用特征数量达到特征总数的30%~40%时,F2指标达到最高值,随后F2指标开始下降。之后的实验均按照IG方法选取占总数35%的特征进行实验。

图1 单颗C4.5树使用不同比例特征时的结果
4 使用随机重采样的方法及改进
4.1 采用BRF方法的实验
如前所述,本文使用的术语定义语料库是一种极不平衡的数据集,所以在该数据集上应用任何一种分类方法时,必须考虑到这种实例分布的特殊性带来的影响。本文首先按照ukasz Kobyliński等人[15]的方法建立基础实验,仅作两点改动,一是用C4.5决策树代替CART树,二是用信息增益(Information Gain)方法进行特征选择。
该实验结果如图2所示,实验结果同时表明了在使用Bagging方法处理航空领域术语定义抽取问题时,聚合结果和参与聚合的树的数量之间的变化关系。由于使用偶数颗树进行聚合时,投票结果中会出现对有些实例的正例判决得票数和反例判决得票数相等的情况,图中将这类实例称为未定实例,并按照将其划归正例和反例分别给出了F1-measure和F2-measure。从该图可以看出,在树的数量少于30时,聚合结果随着树的数量的增长快速提高,并达到59%的F1-measure成绩和73%的F2-measure成绩。但是在树的数量超过30以后,聚合结果不能继续提高。所以当处理大规模的术语定义抽取问题,需要兼顾模型的性能和训练速度时,选用的聚合树的数量可以定在30颗左右。

图2 聚合树数量和F-measure的对应关系
4.2 语料库实例距离分布分析
本文使用实例间的欧氏距离分析航空领域术语定义语料库的实例分布,存在以下特点:
1) 如图3(a)所示,语料库中的反例到最近的10个反例和最近的10个正例的距离均值集中在0.75~5.5之间,且大多数反例到最近的反例和到正例的距离均值相同或者很接近,仅有少量反例到反例的距离均值明显小于到正例的距离均值,但是没有反例到反例的距离均值小于到正例的距离均值。如图3(b)所示,反例到最近的10个反例距离的方差密集分布于0.25~1.75之间,而反例到最近的10个正例距离的方差则密集分布在0到0.2之间。由此可见每个反例到最近10个正例和反例的平均距离很接近,但是到反例的距离在其均值附近的变化幅度远大于到正例的距离。距离每个反例最近的10个实例中,依然是反例占多数。

图3 反例到最近的10个实例的距离分布
2) 如图4(a)所示,语料库中的大部分正例到最近的10个正例的欧氏距离密集分布于1~2.5之间,且大多数正例到最近的正例和到反例的距离均值相同或者很接近,仅有少量正例到正例的距离均值明显大于到反例的距离均值。如图4(b)所示大部分正例到最近的10个正例距离的方差方法密集分布于0.3~0.8之间,而到最近的10个反例的距离方差密集分布于0~0.1之间。语料库中正例到最近的10个正例的距离均值和到最近的10个反例的距离均值非常接近,而正例到最近的10个正例的距离方差远远大于最近的10个正例的距离方差。大部分正例的10个最近邻实例中,依然是正例占多数,并且呈现出正例和反例间隔出现的情况。同时,也存在少量实例的10个最近邻实例都是反例的情况。

图4 正例到最近10个实例的距离方差
3) 如图5所示,(a)是语料库中少数类的正例到最近的10个正例的距离均值—数量的对应分布,表明全部正例的35.7%(485个)到最近10个正例的距离均值在1.20~1.425之间,而到10个最近正例的距离均值在0.975~1.875之间的正例更是占到总数的89%(1 210个),这是一个密集分布区。(b)是语料库中少数类的正例到最近的10个反例的距离均值—数量的对应分布,表明全部正例的33.6%(456个)到最近的10个反例的距离均值在1.20~1.425之间,而到10个最近反例距离均值在0.975~1.875之间的正例更是占到总数的84.5%(1 149个)。这表明单个正例到10个最近邻实例,不论是同类实例还是异类实例,均集中在0.975~1.875之间,这个区域将成为本文下一步进行过采样处理的重点区域。
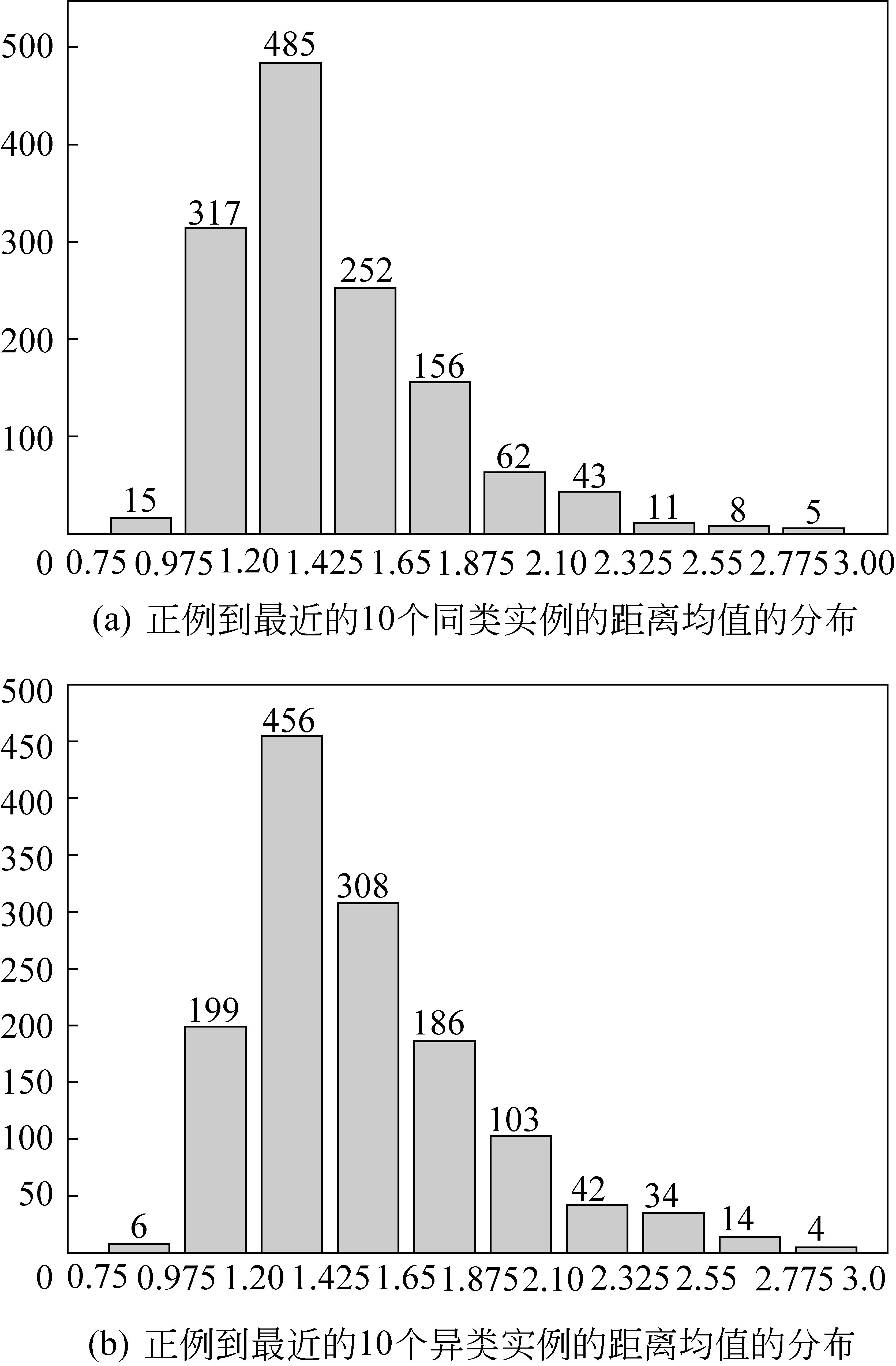
图5 正例到最近10个最近实例的距离均值的分布
4.3 基于实例距离分布信息改进的重采样方法
基于以上对术语定义数据集中实例间距离的分析,本文对随机重采样算法做如下改进:
定义1: 假设整个术语定义数据集中的实例总数为T,少数类实例总数为m,其中一个实例Pi到另一个同类实例Pj的距离为Dij,1 定义2: 设数据集中的少数类实例Pi(1 1) 对于少数类中的每个实例Pi,在T中计算它的5个近邻实例并按照距离由小到大的顺序排列于队列Pi-5NN中。 2) 如果Pi与Pi-5NN中首个实例构成一个不安全实例对或者中等安全实例对,则Pi不参与合成新样本,其Pi-SYN为空,否则从Pi-5NN中逐个取出实例并与Pi比较。 3) 如当前Pi-5NNk实例为正例,且〈Pi,Pk〉为安全实例对或者中等安全实例对(非首个近邻实例时),将Pi-5NNk加入Pi-SYN;如果当前Pi-5NNk实例为反例,则检查Pi-5NN剩余实例(含当前实例)中反例的占比和分布,如果反例的占比大于等于50%或者最近的连续的25%实例均为反例,则终止为当前Pi挑选新的合成实例集实例,否则跳过当前反例,重复步骤3)直到Pi-5NN为空。 4) 当确定了少数类实例的Pi-SYN后,将开始生成新的少数类合成样本。本文使用数据仅包含数值型特征,合成实例包含的特征用与SMOTE相同的方法确定,但是采用新的随机数生成方法如下。 定义3: 假定Pi为当前少数类实例;Pcur为Pi-SYN中的当前候选合成实例;Ppre为Pi-SYN中位于Pcur之前的实例并满足以下条件: 在Pi-5NN中,Ppre到Pcur之间不存在异类实例且Pi-SYN中不存在比Ppre更靠前的实例Ppre′在Pi-5NN中到Pcur之间也不存在异类实例。 令Pcur到Pi的距离为Dcur,Ppre到Pi的距离为Dpre。图5(a)将少数类实例到最近的同类实例的距离均值从近到远划分为等距离的10档,表示为Level1~Level10,Dpre落在第Leveli档中,Dcur落在第Levelj档中。令Xpre为从Level1~Leveli包含的实例数量占少数类实例总数的比例,Xcur为从Level1~Levelj包含的实例数量占少数类实例总数的比例,则令合成新样本过程中的随机数取为rand[Xpre,Xcur]。 5) 在对多数类实例进行欠采样前,去除反例中到最近10个同类实例的距离均值超过9.0的所有实例。去除反例中最近的10个实例中正例数量超过绝对多数的所有实例。 经过以上处理后,少数类实例被过采样约1.8倍,之后再用可放回的重采样方法生成多个训练集。每个训练集中的少数类实例数量和多数类实例数量相等,且都为过采样后少数类实例的数量。用以上训练集训练C4.5决策树,用全部数据集作为测试集,用投票法获取最终结果。由于使用偶数颗树进行聚合时,投票结果中会出现对有些实例的正例判决得票数和反例判决得票数相等的情况,图中将这类实例称为未定实例,并按照将其划归正例和反例分别给出了F1-measure和F2-measure。实验结果如图6所示,在仅使用10颗聚合树并将所有未定实例划归正例的情况下,就达到了F1-measure=0.658、F2-measure=0.78的最佳成绩,比使用随机采样的Bagging方法的最好成绩各提高了约5%。随后,聚合成绩有所下降,但是F1-measure稳定在0.63~0.64之间,F2-measure稳定在0.75~0.76之间。但是与随机采样的Bagging方法的结果不同的是,后者的实验结果中,将未定实例划归反例可以获得更好的成绩,但是改进后的实验中将未定实例划归正例可以获得更好的成绩。 图6 聚合树数量和F-measure对应关系 通过以上诸多实验表明,在本文使用的语料的特征空间中,定义句比非定义句表现出更强的聚集性,并呈现出定义句的绝对稀疏性和在特定区域的相对密集分布。因此,本文的过采样方法倾向于将合成样本的生成位置确定在拥有更多可以构成安全实例对正例近邻的区域,通过合成样本有效强化了原数据集中的正例密集区域的分布。同时,本文在合成新样本时对于夹杂在少数类近邻中的零星多数类实例的处理方法,使得合成样本能够进一步巩固原有少数类实例密集区域的边界。最后,本文去除了部分距离较远的多数类实例。通过以上方法,一方面调整了数据集中正反例的数量比,另一方面强化了正例的分布区域,配合之后的随机采样方法,构建了多个平衡训练集用于训练决策树。实验结果证明该方法比使用随机欠采样的Bagging方法更加有效。 本文的实验表明,采用基于实例距离分布信息改进的重采样方法对比随机重采样方法,能够有效的调整数据集分布,并提高Bagging方法的分类性能,是应对不平衡数据分类的有效方法。但是由于不同的数据集的数据分布情况差异较大,必须根据相应的数据分布特点来确定重采样策略。 本文的实验同时表明,用处理不平衡数据分类的方法来处理术语定义抽取问题是一种可行的思路,能够将原有用于评价分类器的诸多评价指标引入到术语定义抽取领域。但是也面临很多问题,如特征数量很多,导致样本的特征空间是一种高维的稀疏空间,这也会极大的影响分类性能,这是我们下一步研究的重点之一。 [1] 冯志伟. 现代术语学引论[M],语言文化出版社,1997: 31-34. [2] Jun Xu, Yunbo Cao, Hang Li, Min zhao. Ranking Definitions with Supervised Learning Methods[C]//Proc. 14th International World Wide Web Conference Committee, Chiba, Japan: 2005: 811-819. [3] 张榕. 术语定义抽取、聚类与术语识别研究[D]. 北京: 北京语言文化大学, 2006. [4] Hang Cui, Min-Yen Kan, Tat-Seng Chua. Soft pattern matching models for definitional question answering[J]. ACM Transactions on Information Systems (TOIS), 2007, 25 (2): 8-es. [5] H. Cui, M. Kan, and T. Chua. Generic soft pattern models for definitional question answering[C]//Proc. SIGIR’05, Salvador, Brazil: 2005: 384-391. [6] Hang Cui, Min-Yen Kan, Tat-Seng Chua: Unsupervised learning of soft patterns for generating definitions from online news[C]//Proc. 13th international conference on World Wide Web, New York, NY, USA: 2004: 90-99. [7] Eugene Agichtein and Luis Gravano. Snowball: Extracting relations from large plain-text collections[C]//Proc. the Fifth ACM International Conference on Digital Libraries, San Antonio, Texas, USA: 2000: 85-94. [9] Przepiórkowski, A., Marcińczuk, M., Degórski..: Dealing with small, noisy and imbalanced data: Machine learning or manual grammars?[C]//Proc. TSD2008, Brno, Czech Republic: September 2008. [10] Ismail Fahmi and Gosse Bouma. Learning to identify definitions using syntactic features[C]//Proc. the EACL workshop on Learning Structured Information in Natural Language Applications, Trento, Italy: 2006. [11] Chawla, N., Japkowicz, N., Kolcz, A. Editorial: Special Issue on Learning from Imbalanced Data Sets[N]. SIGKDD Explorations 6(1), 1-6 2004. [12] Prati, R., Batista, G., Monard, M. Class Imbalances versus Class Overlapping: an Analysis of a Learning System Behavior[C]//Proc. MICAI(2004). Heidelberg: Springer, 2004: LNAI 2972, 312-321. [13] Fan, W., Miller, M., Stolfo, S., Lee, W., Chan, P. Using Artificial Anomalies to Detect Unknown and Known Network Intrusions[C]//Proc. ICDM 2001, San Jose, CA, USA: 2001: 123-130. [14] Kubat, M., Holte, R., Matwin, S. Machine Learning for the Detection of Oil Spills in Satellite Radar Images[J]. Machine Learning 30, 1998, 2-3: 195-215. [16] Japkowicz, N. The Class Imbalance Problem: Significance and Strategies[C]//Proc. IC-AI 2000, Las Vegas, NV, USA: 2000 :111-117. [17] Kubat, M., Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection[C]//Proc. ICML 1997, Morgan Kaufmann, Nashville: 1997: 179-186. [18] Lewis, D., Catlett, J. Uncertainty Sampling for Supervised Learning[C]//Proc. ICML 1994, Morgan Kaufmann, New Brunswick: 1994: 148-156. [19] N.V.Chawla, K. W. Bowyer. L.O.Hall, and W.P.Kegelmeyer. SMOTE: Synthetic Minority Over-sampling Technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357. [20] G. M. Weiss and F. Provost. The effect of class distribution on classifier learning: An empirical study[R]. Computer Science Department, Rutgers University,. 2001. [21] Domingos, P. Metacost: A General Method for Making Classifiers Cost-sensitive[C]//Proc. ACM SIGKDD 1999, San Diego: 1999: 155-164. [22] Fan, W., Salvatore, S., Zhang, J., Chan, P. AdaCost: misclassification cost-sensitive boosting.[C]//Proc. ICML 1999, Bled, Slovenia: 1999: 97-105. [23] Pazzani, M., Merz, C., Murphy, P., Ali, K., Hume, T., Brunk, C. Reducing Misclassification Costs.[C]//Proc. ICML 1994, Morgan Kaufmann, San Francisco: 1994: 217-225. [24] Han, H., Wang, W., Mao, B. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning.[C]//Proc. ICIC2005, LNCS 3644, Springer, Heidelberg: 2005: 878-887. [25] Chumphol Bunkhumpornpat, Krung Sinapiromsaran and Chidchanok Lursinsap. Safe-Level-SMOTE: Safe-Level-Synthetic Minority Over-Sampling Technique for Handling the Class Imbalanced Problem[C]//Proc., PAKDD 2009, Springer Berlin/Heidelber: 2009: 475-482. [26] Hart, PE. The Condensed Nearest Neighbor Rule[J]. IEEE Transactions on Information Theory.1968, 14(3):515-516. [27] Laurikkala, Jorma. Improving Identification of Difficult Small Classes by Balancing Class Distribution[R]. Department of Computer and Information Science, University of Tampere, Finland. 2001. [28] Tomek, I. Two Modifications of CNN.[J].IEEE Transactions on Systems Man and Communications.1976,6(6): 769-772. [29] Breiman, L, Bagging predictors[J]. Machine Learning, 2002, 26(2), 123-140. [30] Dietterich TG. Machine Learning Research: Four current directions[J]. AI Magazine, 1997,18(4): 97-136. [31] 潘湑,顾宏斌,孙婵娟. 使用分类方法的航空领域术语定义识别[C]//Proc. CCPR2009, Nanjing, China: 2009 : 663-669. [32] Jingyang Li, Maosong Sun, Xian Zhang. A Comparison and Semi-Quantitative Analysis of Words and Character-Bigrams as Features in Chinese Text Categorization[C]//Proc. COLING-ACL06, Sydney, Australia: 2006: 545-552.4.4 采用改进重采样方法的实验结果

5 结论
