基于多策略蜜獾算法的TDOA定位
2024-04-28蒲红平
张 岳,蒲红平*,陈 伟
(1.四川轻化工大学,四川 宜宾 644000;2.人工智能四川省重点实验室,四川 宜宾 643000)
0 引言
随着无线传感器网络的发展,大规模物联网已逐渐成型,人们在日常生活中对基于位置服务的需求变多。全球导航卫星系统(Global Navigation Satellite System,GNSS)的定位性能在室外环境下非常可靠和准确,能充分满足人们的室外定位需求。室内环境或高楼大厦之间的狭窄空间会导致GNSS定位精度下降,无法提供可靠信息,室内定位技术难以依赖GNSS实现。因此,对提高室内定位技术的性能和精确度的研究是非常重要的。室内定位算法可分为测距算法和非测距算法。非测距算法无需额外设备,通过接收和处理来自环境中已有的无线信号,定位精度较低。测距算法通过测量物体与基站之间的距离来确定其位置。测距算法可以分为到达时间、到达时间差、到达角度等。
到达时间差定位算法(Time Difference of Arrival, TDOA)是一种基于信号传播的测距算法,通过比较不同基站接收到信号的时间差来计算距离。该算法无需基站和移动台时间同步,仅需基站间同步,降低了信号源与各个基站之间的时间同步要求,定位精度更高[1]。TDOA本质上是求解双曲线方程组的问题,求解方法分为线性求解和非线性求解2种。Chan氏算法、Taylor算法是传统的线性求解方法,Chan氏算法在测量误差服从高斯分布时定位效果较好,但在实际环境中非视距误差影响下,Chan算法的定位效果不佳[2]。Taylor级数展开的定位算法需要一个与实际位置相近的展开点增加算法的收敛性,对初始值要求较高[3]。粒子群算法、模拟退火、鲸鱼算法、哈里斯鹰算法等智能优化算法应用于TDOA定位,是将非线性求解的定位问题转化成智能优化问题,目标是寻找最优解。智能优化算法在搜索范围内初始化大量随机点,通过建立自适应函数评估随机点和测量值之间的评价体系,通过迭代搜索过程在全局空间中寻找随机点,进而得到定位目标位置。王田等[4]为了实现算法的局部搜索能力与全局搜索能力的平衡,将免疫过程融入自适应粒子群算法,解决粒子容易陷入局部最优的问题,可以使算法能快速地收敛到全局最优解。李继明等[5]为了减少非视距环境导致的TDOA定位精度下降,通过信息熵和轮盘赌的改进鲸鱼算法,同时将改进的鲸鱼算法和泰勒级数展开算法相结合,进一步缩减误差。唐菁敏等[6]为解决利用时差定位计算困难的问题,通过乌鸦搜索算法设计一种自适应感应概率模型,既保留了算法的优良特性,又避免了算法陷入局部最优,从而提升了算法的收敛速度。Dong等[7]为了降低随机误差对定位精度的影响,在麻雀搜索算法的基础上,引入两步加权最小二乘算法,搜索边界自适应调整,生产者-拾荒者数量自适应调整。蜜獾算法(Honey Badger Algorithm,HBA)是Hashim等[8]在2021年提出的一种新型元启发智能算法[8],是模仿蜜獾捕食和习性的一种优化算法,模拟蜜獾的挖掘和寻找蜂蜜等动态搜索行为的灵活和高效特点,具有较好的应用前景和学术价值[9-10]。但蜜獾算法全局开发能力较弱,在较复杂的优化问题中容易陷入局部最优。本文在文献[4-7]的基础上,为解决TDOA定位算法非视距环境中误差较大的问题,提出多策略改进蜜獾算法并和Taylor级数展开算法结合,增强了蜜獾算法的局部探索能力与全局搜索能力,同时利用Taylor级数展开算法进行进一步迭代,减小定位误差。
1 TDOA定位
TDOA定位是以无线信号传播时间为基础的定位方式,首先固定1个基站为主机站,设备向多个基站发送信号,基站接收信号后,计算信号到达时间,利用空气中信号传播速度的一致性,可以得到到达主基站和其他基站之间的距离差。通过距离差可以得到双曲线方程组,对非线性方程组求解可以得到定位信息,如图1所示,BS1为主机站,M为定位点[1],式(1)—(2)为理想状态下的TDOA定位模型。
(1)

图1 TDOA定位原理
c(tr-t1)=Rr,1=Rr-R1
(2)
其中,(x,y)为定位目标坐标;(xr,yr)为定位基站坐标;Rr,1为各基站到固定基站的距离差;i为基站个数;c为电磁波传播速度。
2 变异的蜜獾算法
蜜獾算法是根据自然界中蜜獾挖掘和寻找蜂蜜的动态行为,提出的一种新型元启发式搜索算法,具有实验效果好和结构简单的优点。蜜獾算法分为2种模式,通过狂嗅到达食物源进行挖掘食物的挖掘模式和通过跟着向导鸟寻到食物源的采蜜模式[8]。
2.1 改进的初始化种群
传统的种群初始化是通过公式随机产生,无法确保初始种群的均匀分布,导致搜寻不充分使算法搜索能力变低。本文引入Tent混沌映射进行种群初始化,通过混沌函数产生混沌序列,以相应的公式转化到搜索空间,增加种群的随机性和遍历性,提高算法的优化速度和求解能力,Tent映射公式如式(3)—(4)所示。
(3)
x=lb+(ub-lb)xn+1
(4)
其中,α为混沌参数;lb和ub为种群的上限和下限。
Tent混沌映射与随机生成的初始种群在200次迭代下生成的效果对比如图2所示。

图2 Tent混沌映射与随机产生种群对比
蜜獾的嗅觉强度Ii与猎物的集中强度S、猎物和蜜獾的距离di有关,定义公式如式(5)—(7)所示。
(5)
S=(xi-xi+1)2
(6)
di=xprey-xi
(7)
密度因子是蜜獾算法中一个关键参数,影响着算法的搜索能力和收敛速度。蜜獾算法的密度因子定义如式(8)所示。
(8)
其中,tmax为迭代最大次数;C为一个大于1的常数,一般设置为2。
2.2 引入正余弦策略位置更新
正余弦策略是通过利用正余弦函数的数学性质,通过正余弦模型震荡变化的特性对粒子位置扰动,维持个体多样性,提高算法的全局搜索能力[11],如式(9)所示。
(9)
(10)
其中,η为大于等于1的调节系数;a=1;r1为控制参数,控制正余弦函数的振幅;r2为随机数,实现正弦方式或余弦方式的位置更新。
在挖掘阶段,蜜獾运动范围类似心形,定义如式(11)所示。
xnew=xprey+FβIxprey+Fr3wdi|(cos(2πr4))[1-cos(2πr5)]|xgnew
(11)
其中 ,xprey为当前猎物的全局最优位置;β为蜜獾获取食物能力;r3,r4,r5∈(0,1)的随机数;F为可以搜索方向的标志,定义如式(12)所示。
(12)
其中,r6∈(0,1)内的随机数。在挖掘阶段,蜜獾对嗅觉强度Ii、与猎物之间的距离di、更新密度函数因子w的依赖性很强,同时挖掘期间会受F的干扰,以便找到更好的猎物位置。
在采蜜阶段向导鸟到达蜂巢情况可以用式(13)表示。
xbest=xprey+Fr7αdi
(13)
其中,xbest为蜜獾的新位置;xprey为猎物的位置;F和di分别由式(12)和式(7)得出;α为更新密度因子。
2.3 融合Levy飞行
采蜜阶段是在深度上尽可能地挖掘最优解,但当搜索陷入局部最优时,是对一个局部范围展开的局部精细化搜索,无法得到全局最优值,本文引入Levy飞行策略。该策略是一种融合大步长和小步长的随机游走模型,可提升算法的局部搜索能力和维持种群多样性,防止出现早熟现象。大概率在小步长游走在局部区域进行细致化探索有利于局部开发,小概率出现大步长在搜索空间快速移动,有利于跳出局部最优,增加解的可靠性。
(14)
其中,xprey为食物源;α为步长收缩因子;⊕为*运算;levy(β)为Levy随机路径,并且满足levy~u=t-λ。由于Levy分布情况复杂,常用正太分布求解随机数的方法进行,生成的随机步长的方法如式(15)所示。
(15)

2.4 基于改进蜜獾算法的TDOA定位算法
通过上述多种策略改进蜜獾算法,增加了算法的全局探索能力和局部深挖能力。将上述多策略改进的蜜獾算法与TDOA定位算法结合实现定位。改进蜜獾算法与TDOA算法结合的计算流程如图3所示。
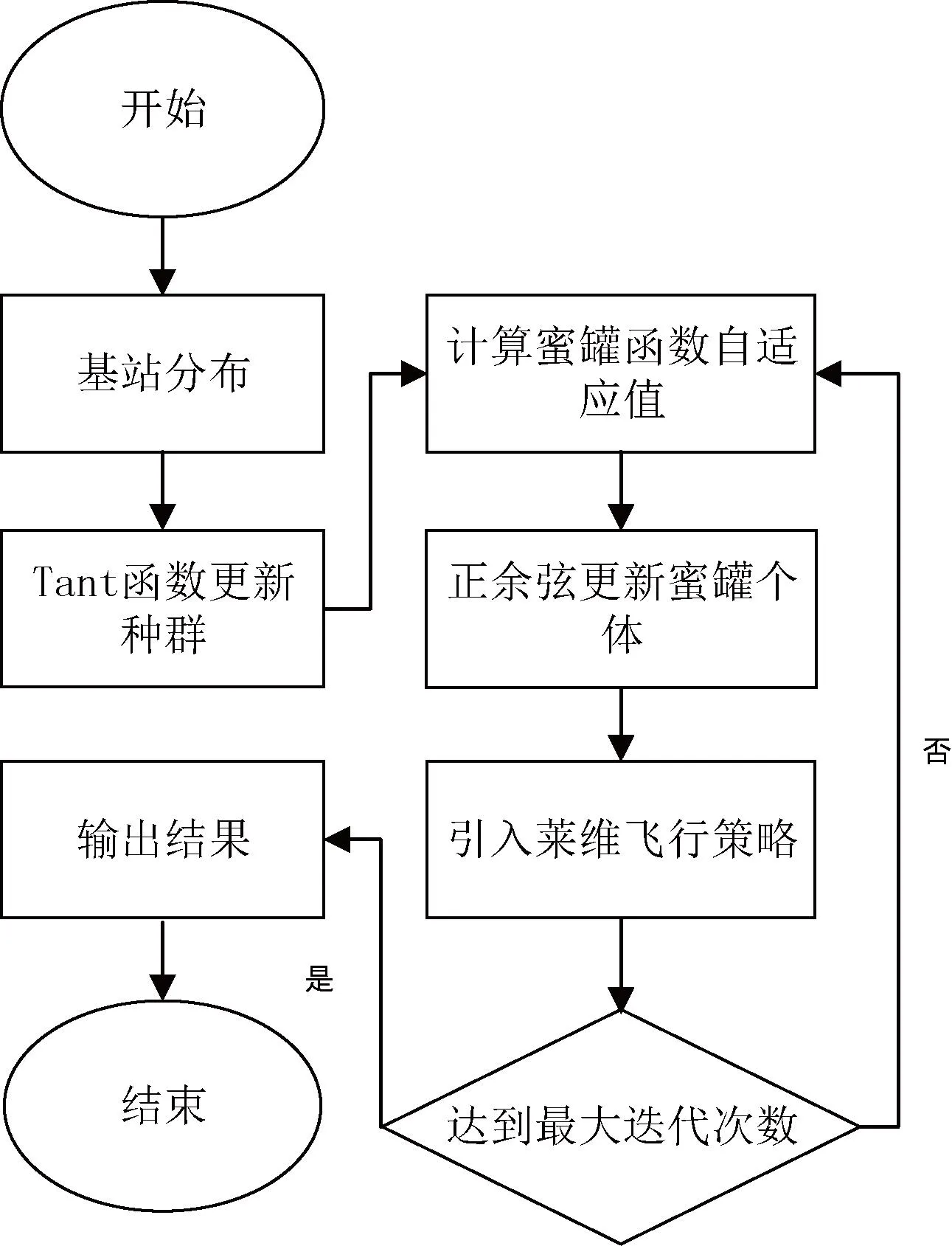
图3 IHBA-TDOA定位流程
3 基于变异蜜獾算法的TDOA算法
3.1 变异蜜獾算法与Taylor级数展开算法结合
Taylor级数展开算法是基于加权最小二乘法(Weighted Least Square ,WLS)的一种迭代算法,它是通过不断迭代修正待定位标签位置的估计值,逐渐逼近标签真实的位置坐标。Taylor级数展开算法存在初始值设置不稳定、定位效果不佳的问题。改进的蜜獾优化算法所求的定位目标与真实定位目标存在误差,而Taylor级数展开算法需要先定义一个初始值,因此两者结合可以进一步减小误差,将多策略改进的蜜獾算法得到的最优定位结果作为Taylor级数展开算法的初始值,经过Taylor级数展开算法进行层层迭代处理,可以进一步提高定位精度。
假设标签和基站之间的约束关系可以用函数f(x,y,xi,yi)表示,将利用改进的蜜獾算法得到的测量值作为初始值为(x0,y0),真实坐标为(x,y)
x=x0+Δx
y=y0+Δy
(16)
基于TDOA的定位方法由公式(2)给出,是理想状态下的双曲线公式,在存在非视距误差环境中,则如公式(17)所示。将fi(x,y,xi,yi)在(x0,y0)处进行Taylor展开,忽略二阶以上分量。
f(x,y,xi,yi)=c(ti-t1)=Ri-R1+δi
(17)
fi(x,y,xi,yi)=fi(x0,y0,xi,yi)+
(18)
转化为矩阵形式:
ψ=hi-Giδ
(19)
其中,ψ为误差矢量;
(20)
(21)
(22)
当αx+αy<η时可以停止迭代。
3.2 多策略改进蜜獾算法与Taylor级数展开算法结合在TDOA定位中的步骤
步骤1:种群初始化,根据Tent混沌映射函数对种群进行初始化。
步骤2:计算初始适应度值,通过基站布置和TDOA测量,构建适应度最优的个体函数。
步骤3 :位置更新,通过多策略改进的蜜獾函数进行位置更新,输出最新的位置。
步骤4:结合Taylor级数展开算法,将改进的蜜獾算法得到的最优解作为Taylor级数初始值。
步骤5:求解Taylor级数,迭代方法求解Taylor级数,得到标签位置的估计值。
步骤6:判断输出,用迭代过程中位置估计的误差是否满足设定的值来判断接着迭代还是输出最终位置。
如图4所示是将改进的蜜獾算法与Taylor级数展开算法相结合的流程。

图4 IHBA-Taylor混合TDOA定位
4 实验仿真结果
本文在MATLAB2021b环境下进行多策略改进的蜜獾算法和结合Taylor级数展开算法的性能仿真测试,仿真场景在10 m×10 m的范围内进行8个基站的设置,基站位置为(0,0)(0,5)(5,0)(0,10)(10,0)(10,10)搜索上界是[10,10],搜索下界是[0,0],基站布局如图5所示,BS是定位基站。

图5 基站布局
本文选用均方根误差(Root Mean Square Error,RMSE)作为评价指标,如式(23)所示。
(23)
其中,(xi,yi)(x,y)分别为i测试点的真实位置和得到的预测位置;m为总测试数,即种群数。
将本文算法与自动设置初始值的Taylor定位算法进行比较,如图6所示,可以明显看出本文算法均方根误差更小,具有优势。将改进后的蜜獾算法与传统的蜜獾算法进行仿真测试,如图7所示,可以看出随着误差增加,均方根误差不断增大,但是改进后的蜜獾算法表现更好。

图6 Taylor-IHBA效果对比

图7 HBA和IHBA效果对比
将本文算法与Chan算法[2]、鲸鱼优化算法(Whale Optimication Algorithm,WOA)[5]、麻雀搜索算法(Sparrow Search Algorithm,SSA)[7]、哈里斯鹰优化(Harris Hawk Optimization,HHO)算法[12]、 鼠群优化(Rat Swarm Optimization,RSO)算法[13]进行对比,不同噪声下均方根误差数据如表1所示,与其他算法对比,随着误差增加均方根误差的变化如图8所示,能够直观地看出误差越大,均方根误差越大。而与其他算法相比,本文算法误差更小,因此本文的算法在非视距环境下能够有效抑制误差对定位的影响,提高定位效果。
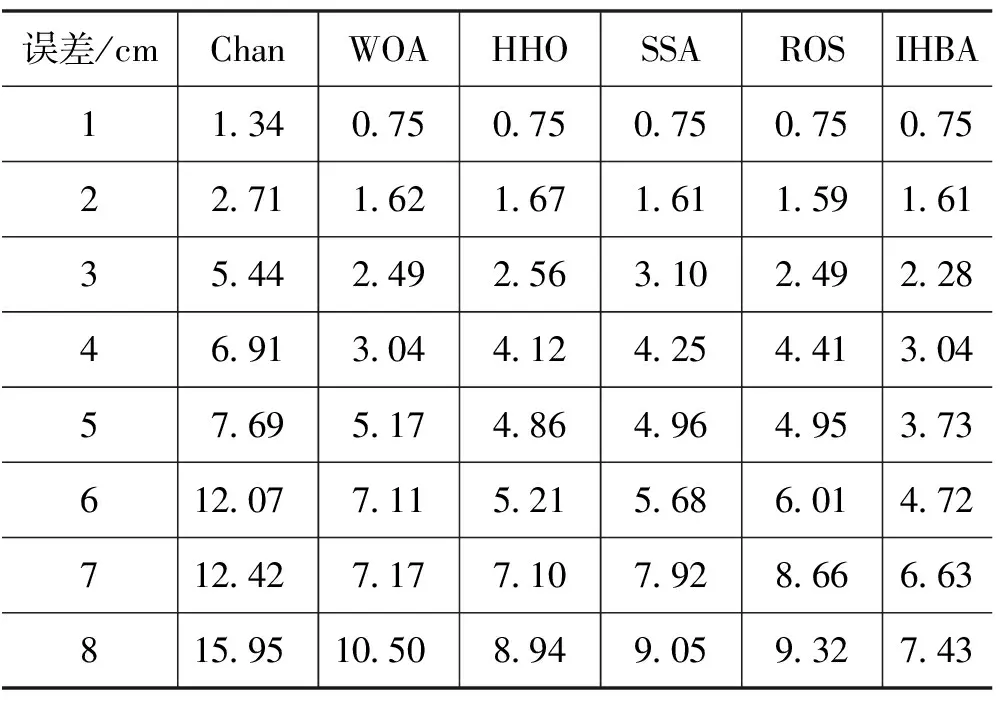
表1 不同距离噪音下均方根误差数据

图8 多种智能算法对比测试
基站数目也会影响定位的精确度,仿真基站数目从4个到7个对定位算法有影响,由图9可知,当基站为4个时均方根误差为29.265,基站为7个时均方根误差为13.876,明显得知基站数为7时具有更小的均方根误差。

图9 不同基站数的本文算法误差影响
5 结语
本文提出一种融合多策略优化蜜獾算法与Taylor级数展开算法的TDOA定位策略。通过多种策略对蜜獾算法进行优化,并通过仿真实验与多组其他定位算法进行对比分析,结果显示本文提出的算法定位精度较高且误差较低。
