基于eBPF和ConvLSTM的5G-R网络安全审计系统研究
2024-04-12陈律,李辉,刘畅
陈 律,李 辉,刘 畅
(1.中国铁道科学研究院研究生部,北京 100081; 2.中国铁道科学研究院集团有限公司通信信号研究所, 北京 100081;3.国家铁路智能运输系统工程技术研究中心,北京 100081)
1 概述
随着我国铁路的快速发展,铁路通信业务的需求不断增加,铁路网络安全的重要性也日益体现。国家出台多条相关政策规划[1],强化了信息安全在当今社会的战略地位。目前我国铁路已明确将采用5G-R实现铁路下一代移动通信系统[2],预示着对铁路网络安全的需求也更加复杂。铁路网络安全关系着人民生命财产安全,除了注重日常的安全风险管理,更要考虑从技术层面应对网络安全问题,以高可靠性承载铁路各项业务。
现阶段的网络系统对于外部攻击部署了多种网络安全服务应用,包括防火墙[3]、防病毒网关[4]、访问控制[5]、入侵检测(Intrusion Detection System, IDS)[6]及入侵防御(Intrusion Prevention System, IPS)[7]等。对于内部用户攻击导致网络泄露等其他安全事件,主要由能够监视和控制流量的网络安全审计系统来辅助处理。
网络安全审计系统是为了解决学校、企业等可能出现的网络安全问题,以及网络安全管理和信息审查而设计的一款系统[8]。根据数据来源可以分为三大类:基于网络的、基于主机的和基于日志的。基于网络的网络安全审计作为使用较为广泛的一种方式,主要通过串接或旁路来对网络信息进行监控;基于主机的网络安全审计针对用户所使用的主机设备进行监督;基于日志的网络安全审计则针对各种日志文件进行收集后统一分析处理。本文提出的网络安全审计系统采用基于网络的安全审计模式,具有更强的实时性,从而保证可以快速响应并减少可能的损害,提供全局视野来维护整个网络环境。

上述方法均着重于网络流量数据的分析或存储来提出改进方案,网络流量采集的实时性没有明显提高。此外,目前针对铁路5G专网这种典型应用场景的研究较少,成果理论不够充足、完善。5G-R作为一种专用的封闭网络,其特点是采用的协议和传输的业务内容模式相对固定,专用设备终端外部接口相对封闭。并且部分终端由工作人员手持使用,一旦发生被恶意盗用的风险事件,需要迅速发现异常并采取处理措施,以避免出现更大的损失和安全事故,更加强调实时监测的重要性。
因此,在5G-R的应用背景下提出一种实时在线进行通信网络流量检测的网络安全审计系统意义重大,也说明在相关问题上有很大的研究发展空间。基于此,本文提出一种采用eBPF(extend Berkeley Packet Filter, eBPF)技术实时采集铁路通信网络流量数据,在线应用深度学习中的卷积长短期记忆网络(ConvLSTM)模型进行流量特征提取和分析,最终直观呈现流量异常情况的网络安全审计系统。
2 网络安全审计关键技术
2.1 网络数据采集技术
网络数据通常包括网络流量、用户行为、系统日志等。这些数据可以从网络设备(如路由器、交换机)上收集,也可以通过专门的监控工具收集。数据采集的重点是确保获取到完整、准确、及时的网络数据,以便后续分析。本系统中选用eBPF技术,主要因为其在内核级别进行数据处理和过滤可以快速捕获大量网络数据,满足铁路通信网络的实时性需求。且eBPF在加载到内核前会进行严格的验证,适应于铁路通信网络的高安全性要求。
eBPF是起源于Linux内核的技术,最大的优势是无需更改内核源码或加载内核模块,便可安全扩展内核功能。其来源于伯克利包过滤器(Berkeley Packet Filter,BPF),BPF最早是由MCCANNE等[15]提出并在1993年发布[16]。BPF当时用于tcpdump,在内核中提前筛选数据包而不会破坏内核[17]。
eBPF的工作原理如图1所示,可以看作是在内核中运行的类虚拟机[18],通过系统调用与内核之间通信,并不会影响内核的安全性。借助如BCC(BPF Compiler Collection)等eBPF工具,将eBPF程序在用户态编写完成后,经过BTF(BPF Type Format)进行元数据格式编码,编译为eBPF字节码,通过Verifier安全验证后载入内核运行,之后使用eBPF()系统调用将eBPF字节码加载至内核[19],该系统具有多种静态或动态标记以便eBPF程序插入探针来进行事件追踪。以此实现eBPF程序在指定的系统调用发生时被执行,并将该系统调用发生时的关键信息传回到用户态,输出为对应的事件数据或统计数据。eBPF()系统同时支持不同类型的映射。针对网络流量,eBPF可以在网络封包到达内核协议栈之前就进行处理,便于实现网络流量控制。
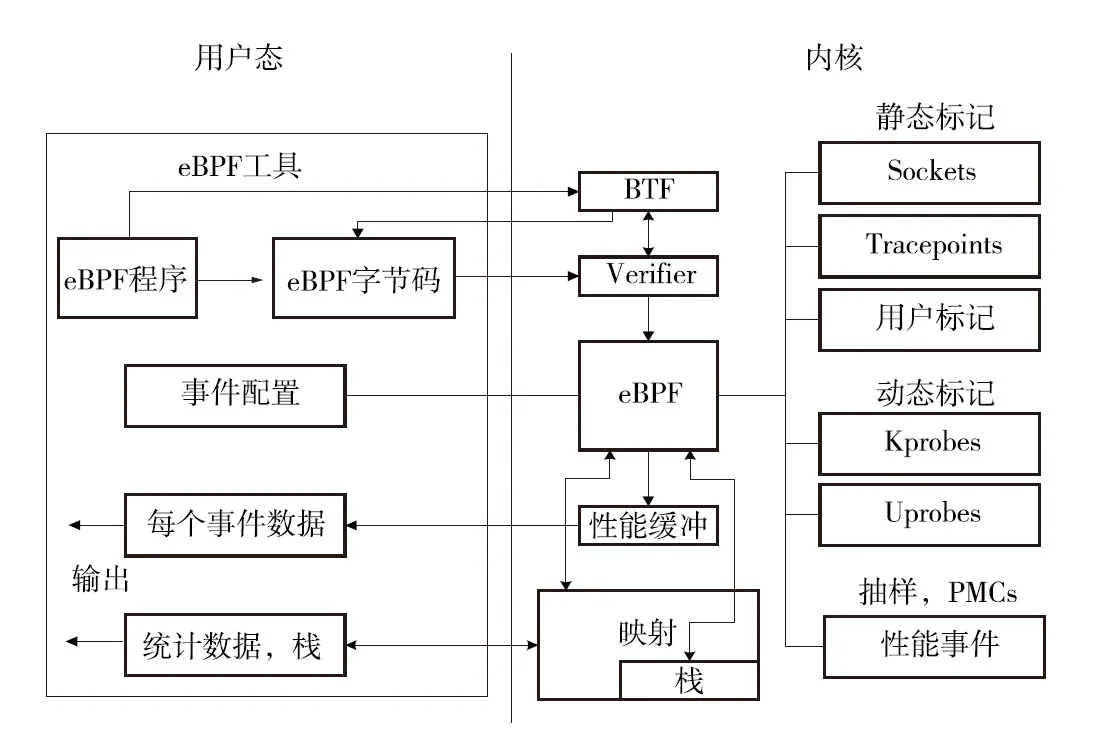
图1 eBPF工作原理Fig.1 eBPF working principle
2.2 数据解析技术
数据解析技术是从网络流量中提取和初步理解信息的过程。数据解析技术可以识别出网络数据包的具体内容,如协议、端口、数据报文等。有效的数据解析可以帮助使用者了解网络行为,以便于检测和预防安全威胁。
一般来说,5G-R数据通信的基本单位为以太网帧,包括源地址、目的地址、类型/长度字段、有效载荷(payload)以及检验尾部等多个部分。其中部分信息对于下一阶段的流量识别是冗余的,需要在数据解析技术中,应用相应技术进行数据的预处理,将原始的以太帧转换成适合后续算法分析的格式。
本系统采用深度学习方法进行数据预处理,相较于传统的预处理方法,深度学习方法有着更强大的特征提取和分类能力,处理速度更快。利用深度学习高效的特征提取能力,提取包括源IP地址、目的IP地址、源端口、目的端口、协议类型、报文长度和有效载荷等内容。
以上特征不仅可以用来初步分析铁路网络流量模式以理解网络的使用情况,同时也为后期训练分类器识别网络异常情况提供有力支持。由此可见,数据解析技术是网络安全审计的一个关键步骤,需要仔细设计和执行以确保流量识别阶段可以从中获取有用的信息。
2.3 流量识别技术
流量识别技术是网络安全审计的一个重要组成部分,其专注于分析网络流量数据,以判别网络上正在发生的活动和异常状态。通常涉及到一些算法和模型,包括但不限于模式匹配、异常检测、机器学习等。流量识别可以监测异常流量模式(可能指示着DDoS攻击或数据泄露)、分析用户行为(如是否有违规使用网络的行为)、优化网络性能等。
传统的机器学习方法是浅层学习方法[20],挖掘数据信息的能力有限。且由于识别异常的过程是针对小概率事件,且数据集存在极大的非均衡性,因此,需要使用集成学习或深度学习等鲁棒性相对较高的模型[21]。从训练耗费资源、数据量大小及实际应用场景考虑,本系统选用深度学习模型。杜浩良等[22]提出了CNN(Convolutional Neural Networks,卷积神经网)+LSTM(Long short-term Memory, 长短期记忆网络)的架构模型进行异常流量识别检测,CNN部分处理输入数据的空间信息,LSTM部分处理输入数据的时间信息,同时利用挖掘流量数据的时空特征,提高了检测的准确率。但是该模型时空信息分开处理会导致空间信息和时间信息中的一些交互关系被忽视。随机森林(Random Forest)[23]是一种集成学习方法,构建多个决策树并综合其结果进行预测。随机森林可以同时考虑所有特征,并自动学习特征之间的交互关系,从而提高检测的准确率。然而,如果输入数据是时间序列数据,随机森林并不能直接捕捉到这种序列中的时间依赖性。在这种情况下,需要先对时间序列数据提取滞后特征、滑动窗口统计特征等,然后再输入到随机森林中。
现有的模型在处理时空信息的交互性方面都存在一定不足。这些模型大多数是独立处理空间信息和时间信息,或者在处理过程中没有充分考虑二者之间的交互关系。基于此,本文使用ConvLSTM算法对异常流量进行检测,对于输入采用共享参数处理时空信息,同时更好地学习时空信息之间的交互关系,提高异常流量检测的准确度和效率。
3 系统设计
3.1 部署环境
5G-R 网络作为专用网络,其系统架构具有自主可控的特点。这种特性使得网络可以根据特定需求和环境进行定制和优化,从而提供更高效、更安全的服务,具体部署环境如图2所示。

图2 网络安全审计系统部署环境Fig.2 Network security audit system deployment environment
将网络安全审计系统采用旁路部署方式接入核心交换机。通过直接接入网络的核心部分,从而对网络的整体安全状况进行全面审计和监控。这不仅可以提高网络安全性,而且可以提高审计效率和准确性。
此外,网络安全审计系统也可以针对某一具体业务,接入关键业务系统的指定交换机。这种部署方式可以使网络审计系统更加精确地针对特定业务进行监控和审计,更加集中地对网络进行防护,从而提高防护效果和效率。
总的来说,5G-R网络采用这种系统架构和部署方式,不仅便于集中投入网络安全防护成本,而且在增强防护能力的同时避免了设备的重复建设。
3.2 结构设计
本系统的结构设计如图3所示。整体采用python语言编写,依据网络安全审计系统的关键技术,分为数据采集、数据解析、流量识别三大模块。首先基于eBPF技术,捕获需审计的系统间的流量数据,保存为pcap文件。之后利用ConvLSTM算法对数据进行预处理,并将其按照算法规则分类。
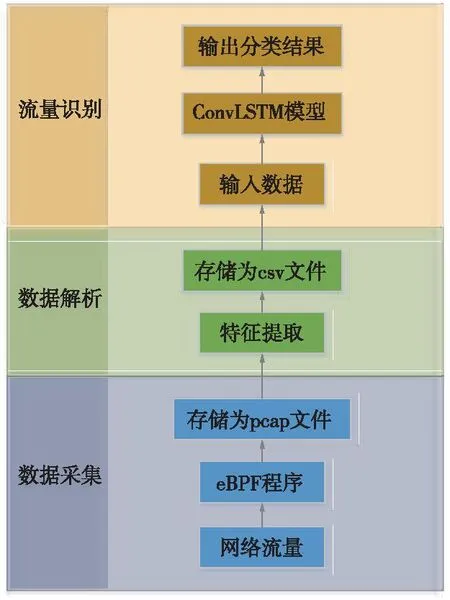
图3 网络安全审计系统结构设计Fig.3 Network security audit system structural design
3.2.1 数据采集模块
5G-R系统中多数设备采用Linux系统,该系统整体分为3层,从上至下依次为用户层、内核及硬件系统。捕获流量部分的代码在用户层编写和调试,最终目的是通过触发钩子函数执行内核的对应功能。在实际应用场景下,为从数据包级别跟踪各设备间通信状态,同时不影响业务性能和内核复杂度,采用eBPF抓取网络流量数据。
具体的设计思路是基于Linux系统提供的用户空间探针Uprobe来寻找用户态的程序或库的特定函数地址。Uprobe作为一个动态跟踪点,eBPF程序可以在此处设置Hook钩子函数,当内核执行到这些点时,将会调用设置好的钩子,触发中断,陷入内核态。由于网络流量数据在内核中流转,此时便可以直接对其进行监控和捕获,通过map映射将信息传递给用户态,之后程序再返回到用户态继续执行后续操作,将信息储存为pcap文件以备下一步的处理。
使用Hook机制同时解决了流量加密的问题。若网络流量数据采用了TLS和SSL安全保密协议,在系统库的SSL_write、SSL_read函数设置钩子函数,可以直接得到该函数的返回值。而传统方式下,必须得到认证机构服务签发的证书授权(Certificate Authority,CA),证明该实体的身份、公钥的合法性以及二者之间的匹配关系,才能获得被加密的信息。因此本程序可以在无CA证书的情况下获得网络流量明文数据,从而进行下一步数据解析提取特征。
3.2.2 数据解析模块
由于捕获到的网络流量数据保存为pcap文件,包含了pcap header和pcap data两个部分,数据区pcap data又可分为packet header和packet data。实际应用中,原始流量数据包含过多的冗余信息,其格式也不利于模型训练和预测。因此需要进行预处理,将可以明显体现数据特征的信息提取出来,改造成便于模型处理的结构。
本程序中利用python自带的scapy库,调用rdpcap()函数读取源文件,进行数据的整合和清理。用变量data遍历每条记录,生成对应的标签特征集合,并存储为csv文件,便于后续训练省去上述操作,直接调用。
3.2.3 流量识别模块
流量识别模块主要是通过ConvLSTM算法模型进行数据的判别。卷积长短期记忆网络(ConvLSTM)是一种特殊类型的长短期记忆网络(LSTM),其在LSTM的内部结构中加入了卷积操作,使得可以同时处理输入数据的空间信息和时间信息。ConvLSTM主要应用于处理具有空间和时间依赖性的数据的任务。
ConvLSTM的基本结构与普通的LSTM相似,如图4所示,都包括1个遗忘门、1个输入门、1个输出门及1个细胞状态。然而,与普通的LSTM不同的是,ConvLSTM中的所有组件都是通过卷积操作计算,这意味着ConvLSTM可以处理多维的输入数据,并且保留输入数据的空间结构。
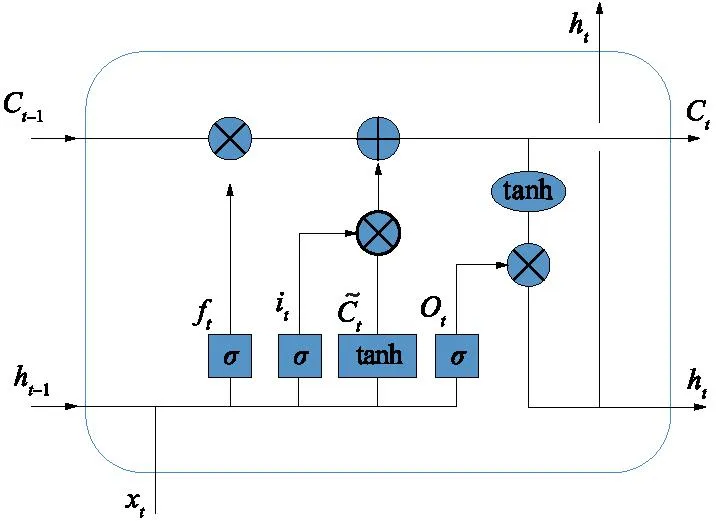
图4 ConvLSTM基本结构Fig.4 ConvLSTM basic structure
遗忘门(Forget Gate):遗忘门的作用是决定哪些信息应被遗忘或丢弃。其通过一个sigmoid函数计算得到一个介于0和1之间的值,决定细胞状态中的哪些信息应被保留,哪些信息应被丢弃。遗忘门的计算公式为
ft=σ(Wf*[ht-1,xt]+bf)
(1)
式中,*为卷积操作;ht-1为上一个时间步的隐藏状态;xt为当前时间步的输入;σ为sigmoid激活函数;Wf和bf为遗忘门的参数。
输入门的作用是决定哪些新的信息应该被更新到细胞状态中。其也通过一个sigmoid函数计算得到一个介于0和1之间的值,决定哪些新的信息应被添加到细胞状态中。输入门的计算公式为
it=σ(Wi*[ht-1,xt]+bi)
(2)
输出门的作用是决定细胞状态中的哪些信息应该被输出。其通过一个sigmoid函数计算得到一个介于0和1之间的值,决定细胞状态中的哪些信息应被输出为当前时间步的隐藏状态。输出门的计算公式为
ot=σ(Wo*[ht-1,xt]+bo)
(3)
候选细胞状态(Candidate Cell State):候选细胞状态是用于更新细胞状态的新的信息。其通过一个tanh函数计算得到一个介于-1和1之间的值,这个值表示当前时间步的新的信息。候选细胞状态的计算公式为

(4)
式中,tanh为双曲正切激活函数;Wc和bc为候选细胞状态的参数。
更新细胞状态(Update Cell State):更新细胞状态的作用是结合遗忘门、输入门和候选细胞状态,更新当前时间步的细胞状态。更新细胞状态的计算公式为
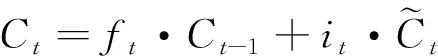
(5)
式中,·为元素级别的乘法操作;Ct-1为上一个时间步的细胞状态。
更新隐藏状态(Update Hidden State):更新隐藏状态的作用是根据输出门和更新后的细胞状态,计算当前时间步的隐藏状态。更新隐藏状态的计算公式为
ht=ottanh(Ct)
(6)
这些步骤的设计使得ConvLSTM可以学习和记忆输入数据中的长期和短期的依赖关系,同时又可以处理输入数据的空间信息。
4 仿真测试
4.1 公开数据集验证
4.1.1 数据集
为验证本文算法的有效性,使用公开数据集CIC-IDS-2017进行实验验证。CIC-IDS-2017是一个由加拿大新布伦瑞克大学的网络安全研究中心发布的用于入侵检测的数据集。这个数据集包含了一周的网络流量,大约280万条网络流量记录,使用的协议更加丰富, 包括FTP、HTTP、SSH、Email以及HTTPS协议[24]。其中有正常流量和各种类型的攻击流量,如DDoS攻击、蠕虫攻击、Web攻击、DoS攻击等,使得这个数据集可以用于训练和测试各种类型的入侵检测模型。数据集中每条网络流量包含85个特征,如源IP地址、目标IP地址、源端口、目标端口、协议类型、流量大小等。
一些攻击类型数量过少,因此在训练过程中需要对其进行舍弃,同时本文按照文献[25]进行了数据预处理。由于特征繁多,在训练时对所有特征进行评估会给模型带来过大的训练负担,因此在已有研究基础上,利用递归特征消除的方法进行特征筛选,递归特征消除方法步骤如下。
(1)初始化一个包含所有特征的特征集合。
(2)在特征集合中移除一个特征,然后用剩下的特征训练ConvLSTM模型,记录模型的性能。
(3)重复上一步,直到特征集合中的每个特征都被移除过一次。
(4)选取表现最优的前6个特征,这6个特征将作为训练模型的输入。
需要注意的是,上述提到的所有特征并不是所有的85个特征,而是在已有评估20个特征[25]的基础上进行。最终每个攻击类型特征选择如表1所示。
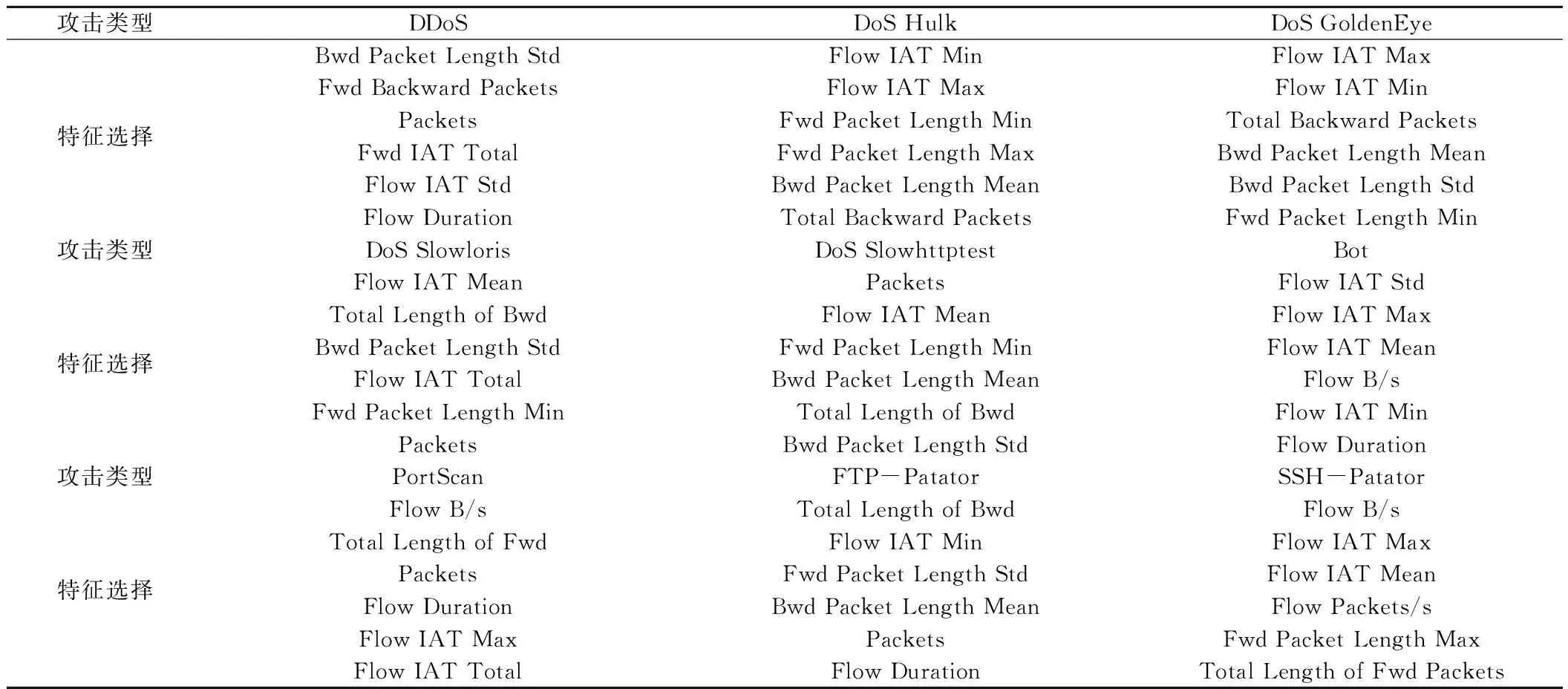
表1 攻击类型特征选择Tab.1 Feature selection of attack types
4.1.2 实验结果分析
深度学习中常用混淆矩阵作为结果可视化的表示方法,并引入FP、FN、TP与TN的概念,基于准确度的指标如表2所示。

表2 基于准确度的指标Tab.2 Indicators based on accuracy
准确率(acc)表示判断正确的结果与所有观测样本之比
acc=(TP+TN)/(TP+FP+FN+TN)
(7)
查准率(Precision)表示实际为正例的样本占所有预测为正例样本的概率值;查全率(Recall)表示模型正确判断出的正例占数据集中所有正例的概率值。
f1分数(f1-score)表示查准率和查全率的调和平均数,即在二者权重相同的情况下衡量算法性能的指标
f1-score=
2×(precision·recall)/(precision+recall)
(8)
为体现本文算法的有效性,与经典的异常流量识别算法进行对比。选取的方法分别为:基于随机森林的方法和基于CNN-LSTM的方法。使用acc和f1-score作为评估指标,结果如表3所示。可以看出,本文算法在整体性能表现上达到了最优。对比随机森林算法,本文所有数据集的acc提高了0.14;对比CNN-LSTM算法,本文所有数据集的acc提高了0.03,验证了本文算法的有效性。同时在具体攻击类型上,如DoS GoldenEye、DoS Slowloris相较于其他方法也取得了较大的性能提升。

表3 算法对比Tab.3 Comparison of algorithms
同时,为全面对比模型性能,三个模型的训练时间如表4所示。可以看出,本文算法在训练时间方面接近随机森林算法,远低于CNN-LSTM算法,综合取得最优表现。

表4 训练时间对比Tab.4 Comparison of training time
4.2 模拟5G-R通信环境验证
上一节采用CIC-IDS-2017数据集验证了本文算法在复杂特征下异常流量检测的能力,为模拟铁路通信网络中的流量,创建实验环境来真实模拟5G-R系统中设备之间的通信,如图5所示。使用虚拟机软件VMware Workstation Pro搭建Linux服务器,用于运行所设计的网络安全审计程序,系统为CentOS 7 64位,IP地址为192.168.40.115,使用NAT模式与本地主机连接,本地主机作为客户端,IP地址为192.168.40.1。
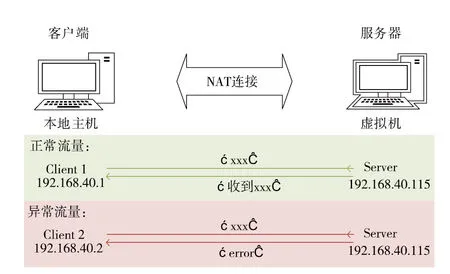
图5 模拟5G-R通信实验环境Fig.5 Simulation of 5G-R communication experimental environment
实验在客户端与服务器端使用python代码及网络传输助手实现二者之间的TCP通信。在Linux系统上创建目标服务器Server,开启socket并绑定IP为192.168.40.115,绑定端口为443,需要先开启运行服务器端才能与客户端成功通信。发送正常流量的客户端Client1,IP为192.168.40.1,通过python代码实现,通信规则为客户端发送任意内容“xxx”,服务器端回复“收到xxx”,即重复收到的内容。异常流量客户端Client2则更改本地主机IP地址为192.168.40.2,使用软件网络传输助手,与服务器建立连接后无论发送什么内容,服务器端均回复“error”。
首先运行Server并开启网络安全审计系统,使用Client1与之通信,一段时间后,关闭Client1并转换为Client2与之通信,最终审计系统能够识别出流量的异常变化情况,达到了设计的预期要求。
将系统判断结果与实际流量状态对比,准确率可以达到95.93%。将判断结果可视化为混淆矩阵,如图6所示,共采集流量123条,异常流量标记为“0”,正常流量标记为“1”。可以直观看出,其中正常流量共有108条,预测正确的108条,预测错误的0条;异常流量共有15条,预测正确的10条,预测错误的5条。说明本网络安全审计系统理论上可以较为准确地完成流量的状态判断工作。

图6 混淆矩阵Fig.6 Confusion matrix
5 结语
当前铁路5G专网已部署了成熟的网络安全设备来抵御外部的恶意侵入,但不包含内部通信异常状态的检测,基于此,本文设计了一种网络安全审计系统从内外两方面来提供更加全面的网络安全服务。结合5G-R的特殊网络特性,在数据采集环节采用eBPF技术,相比其他技术方式可以更加快速地捕获大量网络数据且具有验证机制,满足5G-R场景的实时性和高安全性要求;采用深度学习中的ConvLSTM算法分析数据,统筹时间信息和空间信息,创新性地解决了网络外部和内部的网络安全检测问题,不仅可以检测出可能存在的非法入侵攻击等外部安全隐患,还可以系统性地检测内部使用不当或通信异常带来的流量变化。
随着5G-R设备和资源越来越多的云化,网络安全审计的应用范围和功能也将不断得到拓展和升级。面对这一发展趋势,本系统可能存在数据不平衡、面对新类型的异常泛化能力不足的问题。未来可以考虑增加数据特征维度,进一步完善相关算法,以提升系统的检测和防护能力,更好满足日益增长的网络安全需求。
