轨道交通户外站台门与列车间隙背景灯带图像分割算法研究
2024-04-12郑仲星刘伟铭
郑仲星,刘伟铭
(华南理工大学土木与交通学院,广州 510641)
引言
轨道交通因其具有快速、运载量大等优点,已经成为我国交通的重要组成部分,而其中的高速铁路也开始向着公交化发展。为保障乘客安全与运营线路的正常运行,在车站轨行区与站台候车区间设置站台门进行分隔,因而形成列车与站台门间的风险区间。为保证列车发车前的乘客安全,站务员会在发车前对风险区间进行异物入侵的检查。列车关门到发车时间设计在15~20 s之间,而站务员需要在短时间内检查130~460 m的站台。在班次密集的情况下,运营人员劳动强度大,容易发生疏忽,从而造成生命与财产损失。同时,为提升运营效率,降低运营成本,轨道交通也逐步向智能化、无人化发展,预计到2023年将有40条全自动运行线路[1]。根据国家工程实验室发布国家标准(GB/T 32590.1—2016)[2]和《城市轨道交通全自动运行系统运营指南》白皮书[1],对于自动化程度GOA3等级及以上(无人驾驶列车运行及无人干预列车运行)的列车,对于乘客乘降检测的保障发车安全性与防止乘客在乘降两项功能都对系统提出自动检测的要求。因此,发车前对站台门和列车间隙的自动化异物入侵检测是轨道交通自动驾驶运行的重要一环。
自动异物入侵检测能够缩短在站停留时间,提升轨道交通运营效率,保障人民生命与财产安全。目前,已有的对风险间隙进行异物检测方法有红外光幕检测、红外激光对射检测[3]、红外激光扫描检测[4]、基于侧装式机器视觉检测[5-7]以及基于顶装式机器视觉检测[8-9]等方法。其中,基于侧装式的机器视觉检测方案由于具有检测范围广、设备简单、维护周期长、检测性能好、造价低廉等优点而受到青睐。
基于侧装式的机器视觉检测方案在广州、深圳、南宁等地都有被使用,其最初原型来自于列车司机对位于地铁站台尾端设置的背景灯带进行肉眼检查的方案。侧装式的机器视觉检测方案通过构造人工光学背景(即背景灯带)和设计图像算法,自动在图像中分割灯带,通过检测灯带在图像中的变化判断检测区间的异物存在,达到取代人工观察方案。对于地下站台,灯带处于黑暗背景,图像的分割算法通过自适应阈值方法可以提取得到,但是当安装站台位于户外,灯带分割背景复杂,简单的阈值方法难以适应,分割效果差。为解决侧装式的机器视觉检测方案在户外站台的应用问题,雷焕宇等[10]提出一种基于K均值算法的适用于户外光照的背景灯带分割方法。由于K均值算法属于迭代算法,对每张检测图片进行迭代运算耗时长,在实际运用中,对系统的运算性能也提出较高要求。
现阶段学界主流的基于神经网络的无监督图像分割方法大多数基于像素特征聚类[11]的方法。与传统聚类方法不同的是,这些方法往往都是在特征空间而非颜色空间上进行聚类。比如,文献[12]和文献[13]都基于互信息原理的聚类方法,文献[14]通过使用自回归模型的方法,在最大化互信息的条件下进行训练。上述方法虽然能够一定程度上实现无监督的图像分割,但是它们都基于结构复杂、运算量大的深度神经网络,难以在运算性能弱的设备上进行实际的部署。
为解决上述问题,提出一种轨道交通户外站台门与列车间隙异物检测背景灯带图像无监督分割检测算法。算法基于卷积神经网络,相比主流的深度神经网络,算法中使用的网络大幅缩减规模,其参数量小,对于运算资源要求低,更关注底层特征的表示。提出的算法对网络训练只需要单个样本,并设计3个损失函数,实现网络参数的无监督学习,其分别是基于特征相似及空间距离的损失函数、基于深度支持向量描述的损失函数以及基于几何和光度增强的损失函数。在实际实验中取得比其他算法更优秀的分割性能,并且运算耗时相比K均值算法少。
1 无监督的户外灯带图像分割算法研究
1.1 异物检测系统框架
轨道交通站台门与列车门的净距根据不同类型有不同的设计标准:《地铁设计规范》[15]规定,地铁直线站台门的滑动门门体至列车轮廓线之间的净距应控制在100~130 mm范围内,城际侧线站在0.2 m;而城际铁路与高铁站,《城际铁路设计规范》[16]中则未明确提出正线站台门的安装位置标准。实际上,位于户外的站台,站台边缘到站台门的净距在0.2~2 m之间,一般站台门安装位置为距站台边缘1.2 m处。
虽然高铁城际站台拥挤程度相对较低,但户外站台宽间隙的存在容易导致异物遗留地面事件。为方便运营人员快速清除,解决发车前对间隙的异物检测问题,于站台一端安装平行地表的背景灯带,并通过安装在另一端的摄像头进行拍摄,并设计算法对灯带图像判断是否被遮掩来判断异物是否遗留地面。本文提出的算法在数据采集时,为更好地排除来自其他光线及背景的干扰,使用能发出特定波长的红外光灯带作为目标灯带,而摄像头使用只拍摄相应波段红外光的型号。拍摄的实际图像如图1所示,可见来自户外自然光的红外光仍然会被摄像机所捕捉,导致分割背景相对复杂,为后续分割任务带来难度。

图1 拍摄背景灯带示例Fig.1 An example of background light strip
1.2 算法流程
算法首先对图像进行预处理,调整图像大小,然后使用基于卷积的神经网络对图像进行特征的提取。因为灯带的图像分割任务相比目标检测、图像识别等其他任务,更依赖于图像的细节信息,如光影细节和颜色细节等,所以通过设计合适的损失函数,训练特征提取网络提取图像偏向底层细节的信息。在特征提取得到特征图后,后续分类器对每个像素进行类别预测,分类器同样为基于卷积操作的神经网络。在实际进行应用时,流程到此结束就可以得到输出的分割图像;而在训练时,还会进行类别中心的计算,以进行后续的损失函数计算,并使用反向传播算法对网络参数进行更新。算法的处理流程如图2所示。

图2 算法处理流程Fig.2 The process flow of the proposed algorithm
1.3 网络设计
针对灯带的图像分割任务,算法中使用的特征提取网络采用基于图像卷积的神经网络。为更好地处理图像中的细节信息,特征提取网络使用的卷积核不宜过大。同时,特征提取的过程中,特征图在处理过程中维持尺寸不变。通道数上,除开始阶段从图片原有通道数到P后,后续处理保持不变。具有相同设计的模块会重复N次进行串联处理(图3中虚线框)。采用结构设计相对简单的卷积神经网络出于以下两点。

图3 算法中使用的卷积神经网络结构示意Fig.3 The architecture of the convolutional neural network in the algorithm
(1)针对图像分割任务,特别是灯带的分割,其对图像感知程度要求低,更关注细节信息。
(2)由于分割算法设计是为更好地完成后续站台门与列车间间隙的异物检测,对实时性要求较高,因此,参数量和复杂度过高的网络不利于实际应用。
在算法中,需要进行参数学习的是特征提取网络和分类器网络。其网络结构如图3所示,其中红色虚线框内为特征提取器网络,黄色虚线框内为分类器网络,图中‘Conv’表示卷积核为3×3的图像卷积(convolution)操作(Conv(输入通道数,输出通道数)),‘ReLU’为线性整流激活(rectified linear unit)函数,‘bn’为批归一化(batch normalization)。
在得到特征图后,会输入到分类器网络中。分类器网络会对每个像素进行类别分类。分类器输出的类别数会被作为超参数进行设置,因而输出类别数会提前固定,但随着训练的进行,实际的网络输出类别会逐渐变少。这意味着网络会将相似的像素通过学习进行聚类,然后判别后进行输出。在图3中分类器网络中的参数k表示预设的分类类别数。
1.4 损失函数设计
本文算法实现对神经网络单个训练样本的无监督学习,减轻对数据量和数据标记的依赖。训练过程中从3个方面考虑设计损失函数,分别是考虑特征相似度和空间连续约束的Lsim、以深度聚类为启发,基于深度支持向量描述的Ldsvdd以及基于几何与光度增强的损失函数LGP。总损失函数如式(1)所示,式中λ和γ为损失函数调节权重。
Ltotal=Lsim+λLdsvdd+γLGP
(1)
为便于表示,定义从特征提取网络Eθ输出的特征图为
FC×H×W={fi,j|i∈[0,H],
j∈[0,W],C,H,W∈},
其中,分类器输出分类
Rk×H×W={ri,j,m|i∈[0,H],j∈[0,W],m∈[0,k],k∈+},意为每个像素位置上对每个类别都有置信度输出;最终分割输出为
S1×H×W={ci,j|i∈[0,H],j∈[0,W]},
即在像素位置(i,j)通过选取置信度最大的类别,输出分割结果为类别ci,j∈[1,k]。
1.4.1 基于特征相似及空间连续的损失函数
KIM等[17]提出一种基于单纯的特征相似及空间连续的损失函数,可对卷积神经网络进行无监督图像分割任务的训练。其方法中指出损失函数Lsim设计出发点应该有两方面:(1)同类别像素的特征相似度应该要高;(2)同类别像素的空间分布应该连续。
因此,参考该方法,本文的Lsim由两部分组成,即
Lsim=αLfeature(S,R)+βLspatial(R)
(2)
式中,α,β为调节权重;考虑特征相似度的损失函数Lfeature(S,R)为输出类别与类别置信度的交叉熵,目标是促进网络对具有相似特征像素的分类学习,定义为
(3)
其中

(4)
考虑空间连续的损失函数为相邻像素的分类置信度向量L1范数之和,目的是促进相邻像素的分类结果具有空间上的连续性,定义如下
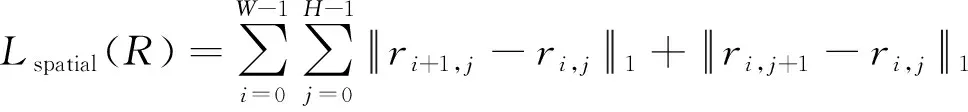
(5)
1.4.2 基于深度支持向量数据描述的损失函数
Ldsvdd的设计受到深度支持向量数据描述(deep support vector data description,DSVDD)的启发。DSVDD是支持向量数据描述基于深度神经网络特征提取能力上的扩展算法。最初由LUKAS等[18]提出用于单类别的分类任务,后YI等[19]提出Patch SVDD用于进行像素级的异常检测,并指出可以通过在训练时维护一组中心,然后在进行推断时根据数据样本在特征空间到中心距离衡量异常程度。因此,算法通过利用DSVDD的维护中心进行学习的特性,达到深度聚类的效果,并应用于灯带的图像分割任务中,以增强网络对于同类型像素的分类学习能力。
设训练过程中维护一组类别中心为Zk×P={zm|m∈[1,k]},类别中心为同类别的特征向量的均值,即

(6)
Ldsvdd则为预测输出相同类别的像素特征向量到对应中心zm的均方误差(mean square error,MSE),即

(7)
其中,n为每个类别像素数量。
1.4.3 基于几何及光度增强的损失函数
上述的两个损失函数都是为增强像素间的关联而设计的,在实际训练过程中,随着迭代次数的上升,分类器偏向把所有像素都分类为同一类别,导致训练崩溃,无法得到有效的分割输出结果。为抑制这一趋势,提出一种基于几何及光度增强的损失函数LGP。这一损失函数设计启发自CHO等[20]提出的无监督语义分割任务设计算法。设计的出发思路是网络对于不同的数据增强变换,不论是几何还是光度上的,都应该能够通过排除变换的干扰,得到相同的分割数据结果。其能够有效让网络在无监督的条件下,对图像整体进行感知并进行语义分割。
CHO等[20]的算法在进行训练前,需要对像素类别进行初始化,使用的方法是K均值聚类。与其不同的是:本文对原方法中K均值的聚类方式得到中心的方式进行改进,类别中心直接使用在基于深度支持向量数据描述的损失函数中计算得到的类别中心。这一替换能够使得网络动态地学习特征空间中的类别中心,同时减少需要的预处理。
具体而言,首先定义两大类数据增强方法:几何变换增强G(·)和光度变换增强P(·),然后对输入图像I进行两个分支处理(对于每次迭代都会随机选择两个分支的增强的变换参数,下文分别使用·(1)和·(2)进行分支的标注)V(1)=G(Eθ(P(1)(I)))和V(2)=Eθ(G(P(2)(I))),其中,Eθ为特征提取网络,VP×h×w={vi,j|i∈[0,h],j∈[0,w]},h,w为进行几何变化后特征图的二维尺寸。几何变换增强在本文中采用随机中心固定大小裁减,而光度变换增强则为随机对图像进行不同参数下的gamma变换。已知在1.4.2节中在计算Ldsvdd过程中类别中心为Zk×P={zm|m∈[1,k]},基于几何及光度增强的损失函数LGP由两部分组成,如式(8)所示,分别是同一变换根据类别中心与特征向量的计算交叉熵损失Linner和不同变换方式之间进行计算的交叉熵损失Lcross。
LGP=Lcross+Linner
(8)
其中,Linner和Lcross定义如下

(9)

(10)
使用交叉熵损失进行计算中心z与特征向量vi,j的距离损失,其中分割结果的类别S用于选取对应的类别中心zci,j,此处Lcluster为

(11)
式中,d(·,·)为距离度量函数,在此选取余弦距离。
2 实验
2.1 实验环境及训练参数设置
本文实验平台中央处理器(CPU)为Intel(R)Core i5-7500@3.40 GHz,图像处理单元(GPU)为Nvidia GeForce 1080,深度学习框架为Pytorch 1.6.1。
网络参数上,P=5,k=5,N=2;损失函数的权重参数建议设置为α=0.5,β=0.1,λ=0.2,γ=0.2;训练时,选择带动量的随机梯度下降法作为优化算法,动量参数为0.4,学习率设置为0.000 01,迭代次数为1 700次。
2.2 数据采集
为验证本文算法的有效性,数据采集位于广东某城轨户外站台,在日间晴朗条件下,使用红外摄像头拍摄灯带图像(采集时间为上午9:00到下午5:00,每隔2 h进行2 min视频采集)。城轨站台用于异物检测的背景灯带水平于地面进行安装,安装位置示意如图4所示,距离地表6 cm,背景灯带长110 cm,与摄像机距离约为184 m。使用的红外光采集视频摄像头分辨率为1 280×720,拍摄帧率为30帧/s,采集图像为RGB格式3通道图,拍摄焦距调节后,灯带在图像中成像面积约为300像素点。图像在输入网络前会进行尺寸缩小至480×320大小。
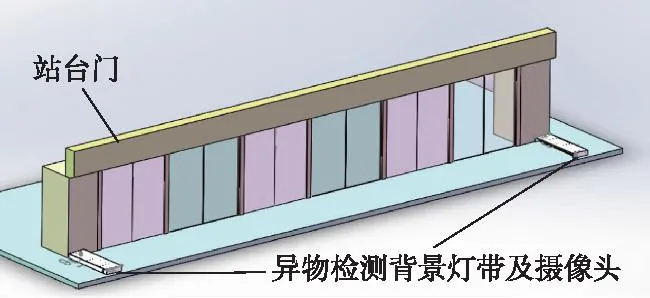
图4 背景灯带及摄像头安装示意Fig.4 The installation position of the background light strips and cameras
2.3 评价指标
本文算法属于图像分割任务,使用语义分割任务中常用的评价指标平均交并比(mean intersection over union,mIoU)、准确率(Accuracy)、召回率(Recall),F1分数以及在CPU和GPU上帧均耗时tCPU和tGPU,定义如下
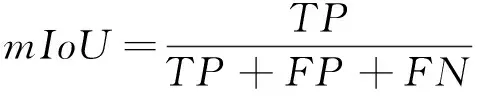
(12)

(13)

(14)

(15)
式中,TP,TN,FP,FN分别为正确分类为灯带的灯带像素数、正确分类为其他类别的其他类别像素数、错误分类为其他类别的灯带像素数和错误分类为灯带的其他类别像素数。
2.4 实验结果及算法对比
本文算法在户外日光较大时表现良好,分割示例结果如图5所示,其中分割结果通过不同颜色进行标记类别。本文算法分割效果在不同的复杂背景下,分割结果准确;对于不同视角的拍摄图像,分割性能表现一致,具有一定鲁棒性;在不同光照条件下,保持良好的分割效果。本文对比常用的无监督方法的分割方法,实验数据结果如表1所示,同时,为更直观地展示结果,图5中对比两张图像的不同算法的分割结果展示。
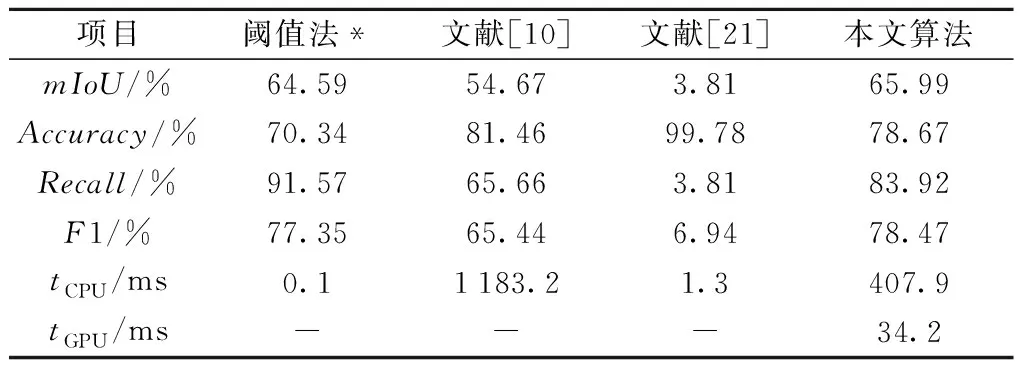
表1 不同算法实验结果对比Tab.1 Experiment results of different algorithms

图5 本文算法在不同环境下输出示例Fig.5 Visualization results of the proposed algorithm
从实验数据上可以看出,对比文献[10](K均值算法)和文献[21](最大类间方差法),本文算法在mIoU和F1分数上取得更高分数,意味着在户外条件下的灯带分割效果更好。同时,相比需要迭代的文献[10]算法,本文在不使用CPU加速耗时上能够减少65.5%,在具有GPU加速条件下,耗时减少97.1%。
从帧均耗时的角度来看,相比文献[10],本文算法更为实用且满足实际运行需求。在分割效果上,如图6所示,对于其他方法,容易把背景中对日光反射度较大的物体错误分割。文献[21]中的方法为大津算法,是基于类间方差最大化的原理。从图6最后一行的直方图曲线中可见,待检测图像的直方图大多为双峰形,而该方法计算的分割阈值落在双峰之间的范围内,根据该阈值的分割结果为将暗色的站台与较亮的户外背景进行分割,但是没有对灯带进行有效分割。因此,基于类间方差最大化的自适应阈值方法虽然帧均耗时低,但是分割效果差,难以在实际应用中使用。

图6 不同方法灯带分割结果对比Fig.6 The comparison of light strip segmentation results of various algorithms
作为实验对比的基准线,通过测试集上选取F1分数最高的阈值,对图像进行二值化后结果进行对比(表1)。此结果意味着是在已知测试集的条件下,各类基于全图的简单阈值方法的最佳效果。在其他算法测试中,无法提前得知测试集的样本,而这种简单阈值法虽然对于目标灯带图像总体像素值比背景高的情况,具有良好分割效果,但其出现的问题有:(1)对于背景较亮,和灯带亮度相似的情况,阈值方法会错误分割背景,同时设置太高阈值会导致召回下降;(2)由于基于灯带遮挡的异物检测方法是长时间在户外运行,成像效果也会随着光线变换而变化,同时,在长期运行条件下,灯带灯珠会因为老化原因,在图像中的成像也会变化。因此,简单的阈值化方法对于以上问题适应性不好,需要不断进行人工调节阈值参数,不具有自适应性。本文算法在仅有1个训练样本的条件下,对于其他光照条件与拍摄角度的灯带图像都具有良好的分割效果,且能够很好地克服来自于背景的干扰。
3 结论
针对轨道交通异物检测关键流程中一环的背景灯带图像分割任务,提出一种基于无监督的适应户外站台的图像分割算法。通过设计考虑特征相似度和空间连续约束、基于深度支持向量描述以及基于几何与光度增强的三种损失函数,实现在单样本训练下的卷积网络参数学习。实验结果表明,本文算法在处理与训练样本不同的视角、光照条件的图像依然保持良好的性能,具有鲁棒性。对比实验表明,在性能优于K均值算法的前提下,算法在CPU和GPU上的运算耗时可减低65.5%和97.1%。结果表明,本文提出算法可有效应对户外站台的背景灯带分割任务,为后续异物检测提供坚实的基础。
