基于监督对比学习的小样本甲骨文字识别
2024-04-09毕晓君毛亚菲
毕晓君,毛亚菲
(1.民族语言智能分析与安全治理教育部重点实验室, 北京 100081; 2.中央民族大学 信息工程学院, 北京 100081; 3.哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001)
作为中华文化的瑰宝,甲骨文字所承载的不仅是古代王朝的兴衰更替的信息,更是我们中华五千年文化传承的历史见证[1]。自甲骨片挖掘工作的展开以来,国内外学者对于甲骨文的研究就不曾停止。据目前所掌握的甲骨文字数据资料来看,古代人民对各个甲骨文字的使用度也大小不一,部分常用字的出现频率可达成百上千乃至上万,但也有不常用字的出现频率仅有十个以内甚至一个。任何一个文字中所包含的信息及意义都将对我们了解历史以及传承文化产生长远的影响,因此,在深度学习长足发展的今天,甲骨文字识别领域中存在的小样本数据情况更是我们关注的重中之重。卷积神经网络优秀的分类表现依赖于充足的样本数据[2],而甲骨学研究却有着特殊性,随着对甲骨文字的发掘和研究越来越深入,未来发现的甲骨文字的样本数量会有相当一部分存在数据有限的问题[3]。因此深度神经网络会出现严重的过拟合及较差的泛化性。随着现实世界的强烈需求,小样本学习成为各领域研究者关注的热点,它的提出旨在解决深度学习对大量数据的依赖性[4]。研究者提出了大量利用少量样本甚至单样本进行识别的优秀方法,并且取得了极其优秀的效果[5-10],而目前将其成果应用在甲骨文字识别领域的却极少,由此,利用小样本学习方法解决甲骨文字识别中存在的小样本问题则显得更为必要和迫切。
通过结合当前主流小样本图像识别算法对目前存在的小样本甲骨文字识别的研究现状进行分析,存在以下2点问题:
1)Orc-Bert算法框架[11]在解决甲骨文字小样本识别问题的过程中需要大量的未标记源数据来学习笔划特征,无法直接利用已有的少量标注样本训练识别模型。
2)现有方法在小样本的条件下,网络学习到的特征十分有限,从而导致识别效果较差。
针对以上问题,本文提出了一种基于监督对比学习的小样本甲骨文字识别方法。EASY框架集合了骨干网络训练、数据增强、多骨干网络集成、特征向量投影等训练策略,可以直接使用少量带标签样本训练识别模型,同时达到先进的效果。在此基础上,将监督对比学习的思想引入到模型训练中来,将输入图片进行数据增强后输入特征提取网络,然后提出联合对比损失来对网络进行优化和参数学习,使特征空间中类内特征向量距离更近,类间特征向量距离更远,骨干网络获得了更加充足的特征,最终实现了识别效果的提升。
1 小样本甲骨文字整体识别框架
小样本学习作为消除深度神经网络对大数据依赖的最佳方法而备受研究者瞩目,尽管目前研究成果颇丰,但应用在甲骨文字识别领域的研究成果整体较少。针对目前提出的小样本甲骨文字识别方法仍然需要在大型数据集上进行预训练的问题,而不能直接利用少量标记样本训练模型,为此本文引入了新的小样本图像识别框架EASY[12],它主要汇集了目前领域中常见的骨干网络训练[13]、数据增强[14]、多骨干网络集成[15]、特征向量投影[16]等优秀训练策略,可以直接使用少量标注样本训练识别模型,同时达到先进的效果。在基于EASY的小样本图像识别框架上,针对现有方法小样本的条件下,网络学习到的特征有限,将导致识别效果差的问题,本文引入了监督对比学习的思想[17],将输入图片进行数据增强后输入特征提取网络,然后提出联合对比损失来对网络进行优化和参数学习,使特征空间中类内特征向量距离更近,类间特征向量距离更远,骨干网络获得了更加充足的特征,从而实现了识别效果的提高。本文提出的小样本甲骨文字识别整体框架如图1所示。
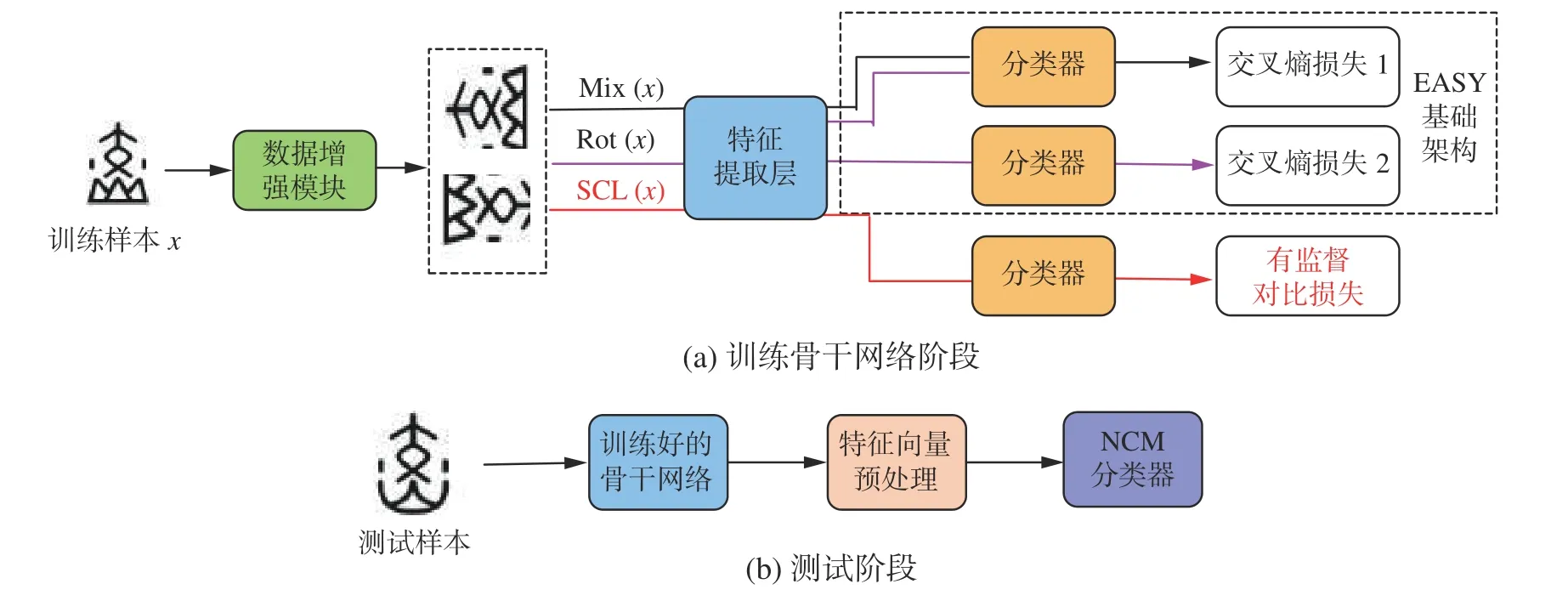
图1 甲骨文字小样本识别模型整体框架Fig.1 Overall framework of oracle bone script few-shot recognition model
此识别框架沿用了EASY的整体架构,并根据任务的实际情况进行了优化。首先在训练阶段利用训练集对骨干网络进行训练,在这个过程保留了原框架中使用的自监督多样混合(self-supervised manifold mixup,S2M2)训练策略,并且结合了监督对比学习的思想。在输入一张图像之后,经过图像增强模块,会产生2张增强后的输入图像,将增强后的数据作为新的输入,在模型学习的过程中除了使用混合[18]和旋转的训练策略外,还利用多组正负样本对进行样本对比学习,使特征空间中类内特征向量距离更近,类间特征向量距离更远,由此骨干网络获得的特征更加充足。原框架中利用2个交叉熵损失函数L1和L2来对训练集分类任务和图像旋转角度预测的辅助任务进行监督,交叉熵损失函数为
式中:n为批大小,C为输入一批数据的类别数,yi,j为第i个样本在第j类上的真实标签,pi,j为第i个样本在第j类上的预测概率。则原框架中的损失函数可以表示为
式中L1和L2的形式同L。在加入对比学习的策略之后,本文引入了监督对比损失函数为
式中:k∈I≡{1,2,···,2n},P(k)是增强后的样本中所有的正样本索引集合,|P(k)|是集合中样本的数量,A(k)则为增强后除了锚点外所有样本索引的集合,zk代表锚点的特征向量,zp代表任意正样本的特征向量,za代表增强后样本集合中除锚点外任意样本的特征向量,τ∈R+为一个标量温度系数。
因此,本文提出的联合对比损失函数为
本文利用提出的联合对比损失来对网络进行优化和参数学习,然后利用循环余弦退火算法[19]获得多个优化到局部最小值解的模型,最终将模型进行参数冻结。在对新类进行测试的阶段,首先利用训练好的骨干网络对输入的新类图像进行特征提取,接着将得到的特征向量进行中心化和归一化操作,最终利用最近类平均分类器[20](nearest class mean classifier,NCM)得到分类结果。
2 小样本甲骨文字识别网络结构
本节主要对提出的小样本甲骨文字识别框架的各个组成部分进行详细介绍。
2.1 EASY小样本图像识别框架
EASY是一种简单的小样本图像识别框架,其中组合了许多常见的方法如骨干网络训练、特征向量投影等。虽然结构简单,但是在训练中却很容易达到先进的性能且不会产生巨大的计算消耗。最重要的是,EASY不需要用大型数据集进行预训练,仅用少量带标签样本即可训练模型。EASY小样本图像识别框架如图2所示。

图2 EASY基础架构Fig.2 Basic structure of EASY
如图2所示,EASY基础架构包含4个步骤:
1) 利用训练集训练一个骨干网络集合。在这个过程中,使用循环余弦退火算法,在每一步学习率都在更新。在余弦循环期间,学习率在初始学习率和0之间变化,在循环结束时,重启学习程序,以降低的初始学习率重新开始。初始学习率设置为0.1,在每个循环中降低10%,训练过程设置5个循环周期,每个周期有100个epoch。训练骨干网络使用的是S2M2R的方法,其原理是采用标准分类架构(如ResNet12[21]),并在倒数第2层之后分支一个新的逻辑回归分类器,此外还有一个用于识别样本类别的分类器,从而整个模型呈Y型。这个新的分类器是用来检索4种可能的旋转,即0°、90°、180°、270°,哪一种被应用于输入样本。在训练的每一步中使用2步前向-后向传播,第1批输入数据与Mixup方法结合仅被送到第1个分类器,第2批输入数据在进行随机旋转后被同时送到2个分类器。训练结束后,骨干网络参数被冻结,然后被用于从训练集和测试集中提取特征向量。
2)新类图像经过第1)步产生的骨干网络集合后,会产生一个相应的平均特征向量集合,将这些平均向量进行拼接操作,则获得新类图像的最终特征表示。整个过程如图3所示。

图3 拼接操作示意Fig.3 Schematic diagram of the concat operation
3)对第2)步所获得的终极特征向量进行2次预处理。假设代表了训练集的平均特征向量,则第1次操作称作中心化:
第2次操作是在第1次操作的基础上进行超球面上的投影:
4)使用最近类平均分类器进行分类。通过首次标记样本类重心来获得预测,类重心计算为
然后将最近的重心与查询集进行关联:
式中:Si(i∈{1,2,···,n})表示支持集中第i类经过第2)步预处理之后的特征向量集合,Q代表经过预处理的查询集的特征向量集合。
2.2 监督对比学习
虽然利用EASY框架解决了小样本甲骨文字识别过程中无法使用少量标注数据直接训练分类模型的问题,但是在研究EASY框架的骨干网络训练部分时,发现在输入一批训练样本时,由于样本量较小,在交叉熵损失函数的指导优化下,骨干网络获得的特征十分有限。因此利用此种设置下训练好的网络在进行测试的时候,在特征空间中,利用已学习到的特征不足以区分文字的各个类别,从而影响了识别准确率的提升。
为了解决上述问题,本文引入了监督对比学习的相关思想[11]。在监督对比学习的思想提出之前,对比学习领域中也出现过许多优秀的相关工作[22-24]。这些工作的共同思想是在特征空间中将锚点和正样本拉得更近,而将负样本从锚点处推得更远。这里要提到2种经典的对比损失:三元组损失和N对损失。三元组损失对于每个锚点仅使用一个正样本和一个负样本,相当于使用了一个正负样本对;而N对损失则是对每个锚点使用一个正样本和多个负样本,因此可以以一个正样本构建多个正负样本对。不同于前面2个损失,监督对比学习在考虑多个负样本的同时考虑多个正样本,这样就更有效地利用标签信息,通过对比更好地使特征空间中类内特征向量距离更近,类间特征向量距离更远,从而使骨干网络学习到更为充足的特征,有助于更好的识别精度的提升。引入监督对比学习的EASY框架的训练部分如图4所示。
输入一个训练样本,经过数据增强模块后,生成2个随机的增强数据。其中数据增强模块中包含随机水平翻转、随机改变图像属性及随机灰度化操作。这些增强数据表示出原始数据不同的视角,并包含了原始数据的部分信息。然后将增强的2个数据分别输入同一个特征提取网络,然后在原有损失基础上加入监督对比损失,即构造出新的联合对比损失来对网络进行优化和参数学习。
3 仿真实验及结果分析
3.1 数据集的选取与处理
本文所选用的数据集有Oracle-FS[25]和HWOBC-FS,其数据示例如图5所示。Oracle-FS是于2020年由Han等[11]提出的用来进行小样本甲骨文字识别的公开数据集。Oracle-FS中包含了200个甲骨文字,对于小样本的设置分为3种。k-shot任务所对应的训练集中每个类包含了k个样本,如对于1-shot任务,对应的训练集中仅有1个训练样本。而3种设置下的测试集中均包含20个样本。在本文中,设置k的取值为1、3、5。Oracle-FS的具体情况如表1所示。HWOBC是一个公开的手写甲骨文字数据集,由22位来自不同专业的甲骨学研究者,通过手写甲骨字搜集软件比照甲骨文标准字形书写并整理而成,数据集共包含3 881类,共包含样本图片83 245张,其中每类包含样本19~25张不等。数据集HWOBCFS是基于上述数据集产生的,数据集的制作设置以Oracle-FS作为参照。本文从HWOBC中随机挑选200类,在k-shot任务中,训练集每个类包含了k个样本,测试集均包含了15个样本。在HWOBCFS数据集中,训练集和测试集中的样本在随机划分阶段保证了互不相交。HWOBC-FS的具体情况如表2所示。
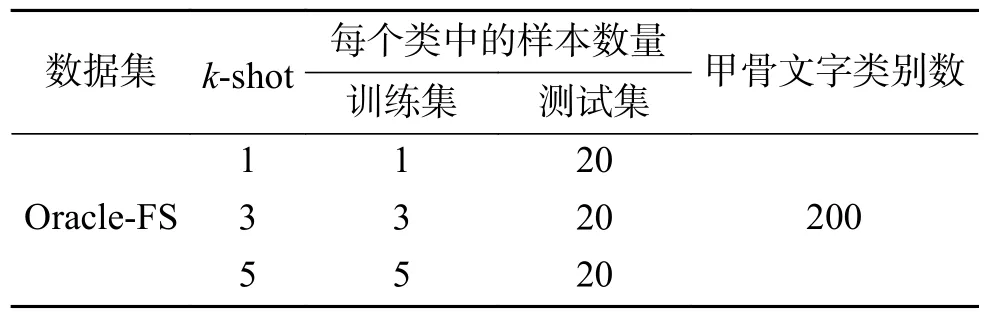
表1 数据集Oracle-FS的具体情况Table 1 Specific situation of the dataset Oracle-FS

表2 数据集HWOBC-FS的具体情况Table 2 Specific situation of the dataset HWOBC-FS
图5 Oracle-FS和HWOBC-FS的数据示例Fig.5 Data example for Oracle-FS and HWOBC-FS
3.2 实验环境及参数设置
本文所有实验的硬件配置为:TITAN X GPU用于计算加速,内存16 GB,Ubuntu 16.04操作系统,编程框架为Pytorch 1.7.1。本文算法训练时设置训练批次大小为64,迭代次数为100个epoch。初始学习率设置为0.1,并且在此使用了循环余弦退火算法,在100个epoch之内,学习率在初始学习率和0之间变化。超参数n-way设置为5,超参数n-runs设置为10 000。
3.3 评价指标
为了验证提出的基于监督对比学习的小样本甲骨文字识别方法的分类性能,本文使用kshot分类准确率(k-shot acc)来作为小样本甲骨文字识别的分类指标。k-shot分类准确率是用来定量评估本文提出的方法在k-shot任务中进行多类别分类的能力。首先在训练集中随机抽取N类,每类中包含k张甲骨文字样本构成一个支持集。然后输入一张待测试的甲骨文字图片进行所属类别测试,其中测试样本所属类别包含在支持集的N类中,称其为一次k-shot任务。定义Pi为一次kshot任务所得到的结果,如果识别正确,则值为1,错误则为0。假设M为进行k-shot任务的次数,则k-shot分类准确率可以表示为
3.4 模型的有效性验证
为了验证本文提出的基于监督对比学习的小样本甲骨文字识别方法的有效性,本文选用了小样本学习研究中常见的3种骨干网络,在上述提到的2个公开数据集上分别对基本框架EASY和引入监督对比学习的框架EASY+SCL进行了实验验证及对比,在数据集Oracle-FS上的实验验证结果如表3所示,在HWOBC-FS上的实验验证结果如表4所示。

表3 在数据集Oracle-FS上的实验验证结果Table 3 Experimental verification results on dataset Oracle-FS%
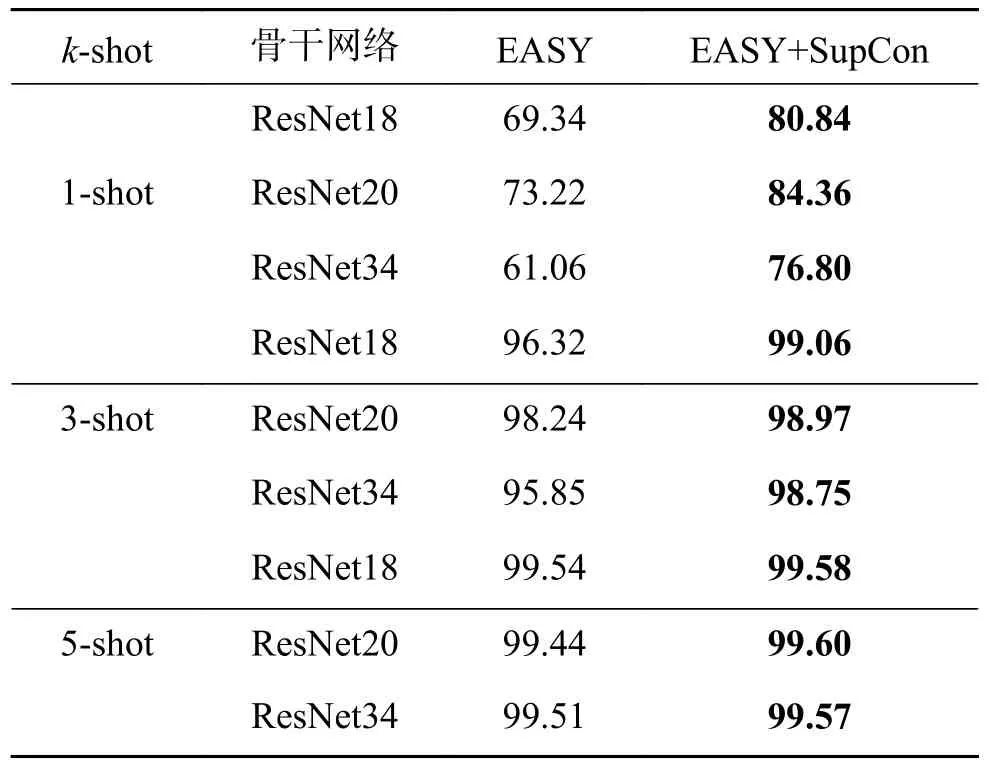
表4 在数据集HWOBC-FS上的实验验证结果Table 4 Experimental verification results on dataset HWOBC-FS%
从表3可以看出,在骨干网络为ResNet18时,引入监督对比学习后,1-shot、3-shot、5-shot任务的准确率相较于原框架分别提升了5.62%、3.18%和2.13%;在骨干网络为ResNet20时,1-shot、3-shot、5-shot任务的准确率相较于原框架分别提升了3.94%、2.10%和0.47%;在骨干网络为ResNet34时,1-shot、3-shot、5-shot任务的准确率相较于原框架分别提升了3.25%、0.44%和1.48%。
从表4可以看出,在骨干网络为ResNet18时,引入监督对比学习后,1-shot、3-shot、5-shot任务的准确率相较于原框架分别提升了11.50%、2.74%和0.04%;在骨干网络为ResNet20时,1-shot、3-shot、5-shot任务的准确率相较于原框架分别提升了11.14%、0.73%和0.16%;在骨干网络为ResNet34时,1-shot、3-shot、5-shot任务的准确率相较于原框架分别提升了15.74%、2.90%和0.06%。
综上所述,对于k-shot任务,在引入监督对比学习后,在不同的骨干网络上均有不同程度的识别精度的提升,由此可以证明本文提出的小样本甲骨文字识别方法有效地拉近了特征空间中类内特征向量的距离,推远了类间特征向量之间的距离,骨干网络获得了更加充足的特征,有效地实现了k-shot任务识别精度的提升,最终证明本文提出的小样本甲骨文字识别方法是有效的。
3.5 模型的先进性验证
为了验证本文提出的基于监督对比学习的小样本甲骨文字识别方法的先进性,将本文提出的方法与现阶段具有代表性的小样本甲骨文字识别方法Orc-Bert进行了实验对比,对比结果如表5所示。

表5 模型先进性验证实验结果Table 5 Experimental results of model advanced verification%
在本次模型先进性验证实验中,选取与Orc-Bert使用的相同的数据集Oracle-FS,且骨干网络的选取与Orc-Bert相同,均为ResNet18,在此种设置条件下,从表5的实验结果中可以看出,本文提出的基于监督对比学习的小样本甲骨文字识别方法,1-shot、3-shot、5-shot任务的准确率相较于Orc-Bert分别提升了26.42%、28.55%和23.98%。而且,本文提出的小样本甲骨文字识别模型不需要大规模的未标记数据集进行预训练,直接使用现有的少量有标签数据即可实现分类模型的训练,解决了小样本甲骨文字识别任务中训练数据有限的问题。综上所述,本文提出的基于监督对比学习的小样本甲骨文字识别方法具有先进性。
4 结束语
针对当前小样本甲骨文字识别方法需要依赖大规模未标注数据集来学习相应笔划特征,无法利用现有少量标注样本直接进行分类模型训练的问题,本文引入了目前先进的小样本图像识别框架EASY,其中结合了多种优秀且有效的训练策略,可以直接使用少量带标签样本训练识别模型,达到了较好的效果。并且针对现有方法在小样本的条件下,网络学习到的特征十分有限,从而导致识别效果较差的问题,在EASY框架的基础上,将监督对比学习的思想引入到模型训练中来,将输入图片进行数据增强后输入特征提取网络,然后提出联合对比损失来对网络进行优化和参数学习,有效地拉近了特征空间中类内特征向量的距离,推远了类间特征向量之间的距离,骨干网络获得了更加充足的特征,最终实现识别效果的提升。为了验证本文方法的有效性和先进性,在实验部分将本文提出的方法与基础框架在不同数据集和不同的骨干网络上对k-shot分类任务的精度进行了比较,同时将本文提出的方法与现阶段具有代表性的小样本甲骨文字识别方法进行了对比,本文方法均有不同程度的提升,充分验证了本文提出方法的有效性和先进性,为今后的小样本甲骨文字识别研究奠定了良好的基础。
