二阶段孪生图卷积神经网络推荐算法
2024-03-21荆智文张屿佳孙伯廷
荆智文,张屿佳,孙伯廷,郭 浩
(太原理工大学 信息与计算机学院,山西 晋中 030600)
0 引言
近年来,随着各类电子商务平台的蓬勃发展,商品种类日渐繁多,但在通常情况下,用户单位时间内能接受信息密度有限,造成了严重的信息过载问题[1]。而推荐系统因能通过在大规模商品中筛选用户可能感兴趣的商品,缓解信息过载问题,得到广泛研究。大规模推荐系统最关键的任务之一,是快速且准确地为每一位用户计算大量商品的分数排序。一种普遍采用的方法是将推荐系统分为召回和排序两阶段架构。具体而言,首先从大规模商品集中召回与给定用户相关的相对数较少的商品;然后使用排序模型根据学习到的用户兴趣,对召回阶段筛选过的相关商品排序[2]。一个高性能的召回模型是整个推荐系统的基础;但由于电子商务平台具有数据规模大、用户行为稀疏和数据长尾等特性,传统的数据召回模型对用户和商品之间关系的学习可能出现不平衡或不充分的情况。
为了解决上述问题,Huang 等[3]提出了双塔型神经网络算法DSSM(Deep Structured Semantic Models)。它的核心思想是将用户和商品映射到同一维度的语义空间,分别训练用户侧和商品侧的深度神经网络(Deep Neural Network,DNN),以最大化用户和商品的相似性。该算法虽然一定程度上提高了大规模召回的性能,但由于DNN 之间相互独立,两塔之间缺乏信息交互,算法无法充分学习用户和商品之间更深层次的交互信息。因此,如何增强DSSM 的信息交互,提升DSSM 的召回性能值得深入研究。
综上所述,如果能在DSSM 之间建立合适的连接机制,在避免信息串联的情况下,让DNN 学习尽可能多的用户和商品之间的交互信息,就能提升推荐算法的准确性。因此,本文提出二阶段孪生图卷积神经网络推荐算法(Two-stage Siamese graph convolutional Neural network recommendation algorithm,TSN),通过引入基于图学习的孪生网络,增强DSSM 的图特征学习能力和用户-商品交互捕捉能力。
本文的主要工作如下:
1)为推荐系统设计通过用户行为连接的异质图,提出基于图卷积神经网络的孪生网络结构,对异质图建模,在学习异质图连接信息的同时,在用户和商品侧DNN 之间双向传递信息,使DNN 学习到更多交互特征。
2)提出二阶段学习技术,该机制能在避免孪生网络串联两侧DNN 的基础上,使DNN 学习到包括正向和负向的全量样本,同时使共享机制具备学习能力。
3)在两个真实数据集上与若干算法在不同指标下进行比较,证明了TSN 算法能显著提升推荐系统的性能。
1 相关工作
1.1 增强双塔型神经网络
为了增加DSSM 中用户侧和商品侧之间的信息交互,Yu等[4]在DAT(Dual Augmented Two-tower model for online largescale recommendation)中设计了一种自适应模拟共享机制为每个用户和商品提供增强向量,增强向量中蕴含内容特征。对于每个带有正标签的样本,根据另一个DNN 的输出表示向量生成增强向量,作为输入特征的增强向量便携带了另一DNN 中有价值的信息,便可在隐语义空间模拟两塔之间的信息交互。
虽然DAT 在一定程度上缓解了DSSM 缺乏信息交互的问题,但仍存在一些局限:
1)自适应模拟共享机制的结构决定在训练阶段只能使用正样本进行增强,模型缺乏对负面信息的学习。
2)自适应模拟共享机制在一次训练结束后,通过乘积生成增强向量,本身不具备对信息交互过程的学习能力。
3)该算法需要调整较多参数,这一定程度上增加了优化模型的工作量。
1.2 孪生神经网络
最早由Bromley 等[5]提出的孪生神经网络是一种特殊的DNN 结构,它由两个或多个子网络构成,同时接收特征数据的输入,且相互之间共享DNN 权值。
如图1 所示,孪生网络整体结构的核心是找到一个合适的映射关系,该映射关系能将输入的特征数据映射到目标语义空间,并让目标语义空间中不同实体之间的简单距离(如欧氏距离、余弦相似度等)逼近输入空间实际的语义距离。具体地,孪生网络结构尝试通过更新参数,找到一组可以使两个或多个实体的表示在实际意义上相似的情况下拥有更小的相似性度量,而在不相似的情况下拥有更大的相似性度量[6]。
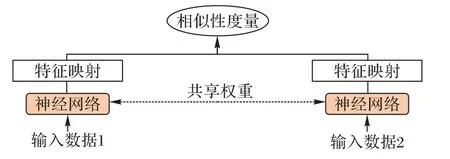
图1 孪生神经网络结构Fig.1 Structure of Siamese neural network
孪生网络中不同神经网络之间共享权重在一定程度上限制了各神经网络之间的学习内容应具有高相似性,所以通常用于处理两个输入差异不是非常大的问题,如对比两张图片、两个句子、两个词汇的相似度。对于输入差异较大的学习任务,如图片与相应的文字描述、文章标题与文章段落的相似度等,孪生网络起到的作用比较有限。双塔型神经网络的最终目的是学习用户向量和商品向量的相似性,孪生网络可能会在一定程度上有增强双塔型神经网络召回性能的作用。
1.3 异质图卷积网络
在推荐系统中,将用户对商品的评分作为边,用户和商品的特征信息作为节点信号,便可将推荐系统问题转化为异质图学习问题[7]。以卷积神经网络(Convolutional Neural Network,CNN)[8]为理论基础的异质图卷积网络(Hetero Graph Convolutional Network,HGCN)[9-13]因其强大的特征表征能力而被广泛应用。具体地,HGCN 会在图的异质节点间进行图卷积操作。若异质图由m个用户节点和n个商品节点构成,则HGCN 会将异质图视为(m+n) × (m+n)的二分图,以节点特征为信号,以评分信息为图进行图卷积,挖掘二分图中包含的连接信息[14]。
2 模型设计
如图2 所示,为了缓解DSSM 算法在推荐系统中的局限性,TSN 使用一对DNN 分别学习用户和商品的特征信息。为了解决用户侧和商品侧DNN 缺乏高质量交互的问题,本文提出基于异质图的孪生卷积神经网络(Hetero Siamese Graph Convolutional Neural network,HS-GCN)连接两侧DNN。在进行两侧DNN 全量交互的同时,挖掘由用户和商品构成的二分图的连接特征信息。为避免直接连接HS-GCN 和两侧DNN 后,在训练过程中出现的神经网络串联问题,本文设计基于梯度冻结(Gradient Freeze,GF)技术的二阶段学习技术。通过多层感知机进行相似度打分,按照降序排序,进行TOP-K推荐。TSN 的重要符号定义见表1。

表1 重要符号定义Tab.1 Definition of important notations

图2 二阶段孪生图卷积神经网络推荐算法架构Fig.2 Architecture of two-stage Siamese graph convolutional neural network recommendation algorithm
2.1 神经网络文本嵌入
为使用户侧和商品侧的DNN 学习到有效特征,DSSM 的输入包含用户对商品的评论、用户的画像信息、商品的详情信息和标签的内容信息。通过使用文档嵌入,将内容信息映射到低维密集的内容向量。文档嵌入的代表工作为Doc2Vec,包含分布式内存(Distributed Memory,DM)和分布式词袋(Distributed Bag Of Word,DBOW)两个子模型。考虑到内容向量不应受到每段文档词序的影响,本文采用在训练过程中不学习词序的DBOW。具体地,对于给定用户ui∈U,结合ui的用户画像文档ufi和包含对商品的评论及标签信息的评论文档Coi*获得用户文档doci,对于商品vj∈V,结合商品详细信息vdj和商品评论Co*j,获得商品文档docm+j,通过LTP(Language Technology Platform)对文档D={d1,d2,…,dm+n}进行清洗和分词,再使用Doc2Vec 将文档D分别映射为用户和商品的密集向量UD和VD。
2.2 DSSM
TSN 的DSSM 包含用户侧和物品侧两部分,两侧分别为用户和商品提供基于DNN 的编码器。以用户ui和商品vj为例,在实际训练过程中,为了获得用户和商品的信息,向量udi∈UD和vdj∈VD将输入到具有ReLU 激活功能的全连接层当中。用户侧的全连接深度DNN 处理过程如下:
其中:huser(1)和huser(x)分别为用户侧DNN 的第1 层和第x层;和bx分别是第x层的权重矩阵和偏置向量。商品侧全连接DNN 结构同用户侧相似。两侧DNN 的输出将作为进行相似度计算的输入,通过计算相似度与实际标签的损失优化DNN。本文在DSSM 的相似度计算中采用余弦相似度,公式如下:
其中uei∈UE和vej∈VE分别为用户侧和商品侧DNN 的输出。在构建样本时,选择用户对商品的评分作为标签,同时考虑隐式和显式反馈:
其中:rij∈R为用户ui对商品vj的评分,fst(⋅)为将评分限制在0~1 的标准化函数。在计算损失时采用归一化交叉熵损失作为损失函数,公式如下:
其中max(⋅)是取最大值函数。
2.3 用户行为二分图
m个用户对n个商品的评分矩阵为R∈Rm×n,评分范围为{1,2,…,X},则用户和商品的交互图为:
在后续的HS-GCN 的卷积操作中,u1的特征表示来自它评分的商品i1、i3、i4;商品i4的特征表示来自为它评分的用户u1和u2。
2.4 孪生卷积神经网络
2.4.1 用户和商品子图构建算法
在输入阶段,通过在二分图以用户为起点,交替随机游走,形成步长为k的用户链路,算法如下。
算法1 用户和商品子图构建算法。
2.4.2 网络结构
HS-GCN由两个相同的CNN组成,分别为CNNL和CNNR。设以用户为起始节点构成的子图和以商品为起始节点构成的子图为HS-GCN的一对实例。由此提出计算兼容性的函数:
HS-GCN 采用随机梯度下降(Stochastic Gradient Descent,SGD)训练。在每次SGD 的迭代中,两个结构相同的CNN 对训练样本进行处理。式(9)用于计算训练误差,模型根据误差在训练过程中更新HS-GCN,直至满足停止条件。
2.4.3 孪生卷积架构
孪生网络由一对由若干卷积层和一个全连接层的CNN构成,共包含5 层,输入子图尺寸由步长k决定。本节以大小为32 × 32 的子图为例,将Cx作为卷积层,Sx作为下采样层,Fx作为全连接层,x为各层的索引。C1层是卷积层,使用6 个5 × 5 的卷积核对子图卷积,得到具有6 个28 × 28 的特征图;S2为下采样层,使用2 × 2 下采样得到6 个14 × 14 的特征图;C3是卷积层,通过16 个5 × 5 的卷积核对特征图卷积,得到16 个10 × 10 的特征图;经下采样层S4和核卷积层C5分别得到16 个5 × 5 的特征图和120 个1 × 1 的特征图;F6为全连接层。
2.5 二阶段孪生信息共享机制
介于用户侧和商品侧DNN 之间的孪生网络通过二阶段孪生信息共享机制在避免孪生网络将两侧DNN 串联的基础上,捕捉来自对方的异质特征,并动态学习用户和商品的交互信息。该机制由共享连接、二阶段学习技术和信息交叉融合三部分构成。
2.5.1 共享连接
首先,为使孪生网络能同时学习异质图中用户侧和商品侧的异质信息,用户侧和商品侧的孪生网络分别接收经卷积层得到的用户和商品的输出然后,通过共享两侧孪生网络的权重矩阵WSia实现两侧信息的交互。最后,通过信息交叉融合使用户侧和商品侧DNN 学习到来自对方的特征信息。但是,直接使用该方法会导致用户侧和商品侧DNN 形成信息串联,使DSSM 的双塔型结构能天然区分用户和商品的特质失去意义,并将TSN 在结构上与基于图学习的YoutubeDNN 等价。因此,需要一种特殊的二阶段学习技术完成非串联的信息共享。
2.5.2 二阶段学习技术
为了防止DSSM 被HS-GCN 训练过程完全串联,为模型设计了二阶段学习机制(Two-Stage learning Mechanism,TSM)。TSM 将算法的训练过程分为两个阶段,两个阶段交替完成一次,即为一轮训练。
在第一阶段,首先,冻结DSSM 的权重参数,即WDNN中各元素的值保持不变;然后,使用HS-GCN 和DSSM 分别对经神经网络嵌入得到的特征矩阵及交互二部图进行非线性编码,并将HS-GCN 和DSSM 输出的特征矩阵进行信息交叉融合(融合方法在2.5.3 节中介绍);最后,使用交叉融合后的矩阵特征向量更新WSia的参数,完成对HS-GCN 一个批次的训练。在这一阶段中,若为首轮训练,则算法仅学习图卷积操作中提取的交互二分图连接信息;若不为首轮训练,则可学习到交互二分图连接信息及上一轮训练中DSSM 之间的交互信息。该阶段解决了DSSM 无法提取图拓扑结构特征,以及缺乏对用户和商品交互信息学习能力的问题。
第二阶段与第一阶段相对应,冻结HS-GCN 的权重参数WSia,通过信息交叉融合得到特征矩阵,完成DSSM 一个批次的训练。在这一阶段,算法将由HS-GCN 建模的交互图连接信息及用户侧和商品侧的交互信息融入DSSM 的训练过程。该阶段解决了直接连接HS-GCN 和DSSM 导致的网络完全串联问题。
TSN 实际部署于工业生产环境中时,为尽可能减少从原始输入到最终结果的人工处理,并具有根据数据自动调整模型参数的能力,提出梯度截断技术(Gradient Truncation,GT)实现TSM,将TSN 优化为端到端模型。具体地,GT 同时训练DSSM 和HS-GCN,交替截断DSSM 和HS-GCN 损失的反向传播,在实现TSM 功能的同时,将TSN 转化为一个端到端的模型,TG 的实现逻辑见算法2。
算法2 基于梯度截断的二阶段学习技术。
输入梯度更新标记pstep,特征向量feature_vec,DSSM 权重参数WDNN,HS-GCN 权重参数WSia,训练批次大小batch_size;
2.5.3 信息交叉融合
由图2 所示,在信息交叉部分,来自双塔网络和孪生网络的信息进行交叉。为了更细粒度地融合来自DSSM 和HSGCN 的特征信息,采用哈达玛积方法实现信息交叉,对于用户:
2.6 训练
本文将召回任务视为二分类任务。在训练过程中,对于给定的用户,模型分别将匹配正确的商品和随机选择的商品作为正样本和负样本。在信息交叉后计算的余弦相似度,最后通过计算归一化交叉熵损失函数得到预测的损失。
3 实验与结果分析
本文通过实验验证TSN 的有效性,实验包括对比分析、消融实验和训练强度分析三部分。对比分析将TSN 与主流的召回算法在不同性能维度上进行比较;消融实验将TSN 的部分模块拆除,以验证模型各部分的有效性;训练强度分析通过观察分析不同训练强度下的孪生网络对双塔型神经网络的增强效果,选择最优的孪生网络训练强度。
3.1 实验设置
为验证TSN 的召回性能,本文选择了现实世界中的离线大规模数据集:来自MovieLens 数据集[15]和豆瓣电影数据集[16],这些数据集已经被广泛用于推荐系统的研究和开发。其中,MovieLens 是一个开源的电影推荐数据集,该数据集提供了大量电影评分和用户行为数据;豆瓣数据集是指从豆瓣网上爬取的大量电影、图书、音乐等数据的集合,本文仅使用豆瓣数据集中的电影部分。内容详细信息见表2。

表2 实验数据集统计信息Tab.2 Statistics of experimental datasets
将数据打乱,随机选择80%的数据作为训练集,10%的数据作为验证集,10%的数据作为测试集。
3.2 比较模型和指标
将TSN 与7 个广泛应用于工业领域的基准模型算法进行比较,包括TF-IDF(Term Frequency-Inverse Document Frequency)[17]、FM(Factorization Machines)[18]、YoutubeDNN(Deep Neural Networks for Youtube recommendations)[19]、DSSM[3]、STAN(Spatio-Temporal Attention Network for next location recommendation)[20]、HIRS(Hypergraph Infomax Recommender System)[14]和DAT[4]。上述基准算法囊括了基于直接统计的推荐算法、基于矩阵分解的推荐算法和基于深度学习的推荐算法。根据命中率(Hit Ratio,HR)@N[21]、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)@N[22]、平均倒数排名(Mean Reciprocal Rank,MRR)@N[7](N=10,50,100)三种评价标准评估所有算法。其中,HR 表示推荐列表中被用户实际点击或购买商品所占的比重,NDCG 用来衡量推荐列表的排序质量的指标,MRR 用来衡量推荐列表的排序质量和推荐物品的多样性。
3.3 参数设置
将训练批量大小设置为512,向量的维度设置为32。为了达到更好的训练效果,选择Adam 作为优化器,初始学习率设置为0.001,并在[0.001,0.001 5,0.002 5,0.005,0.008,0.01]寻找最优值,初始epoch 设置为16,并在[16,32,64,128,256]中寻找最优值。对比分析中,将2.4.1 节的默认步长设置为最优值10。
3.4 对比分析
实验结果如表3、4 所示,其中TSN(GC)为标准TSN 算法,它在每个训练批次中先更新DSSM。对表3、4 分析可知:
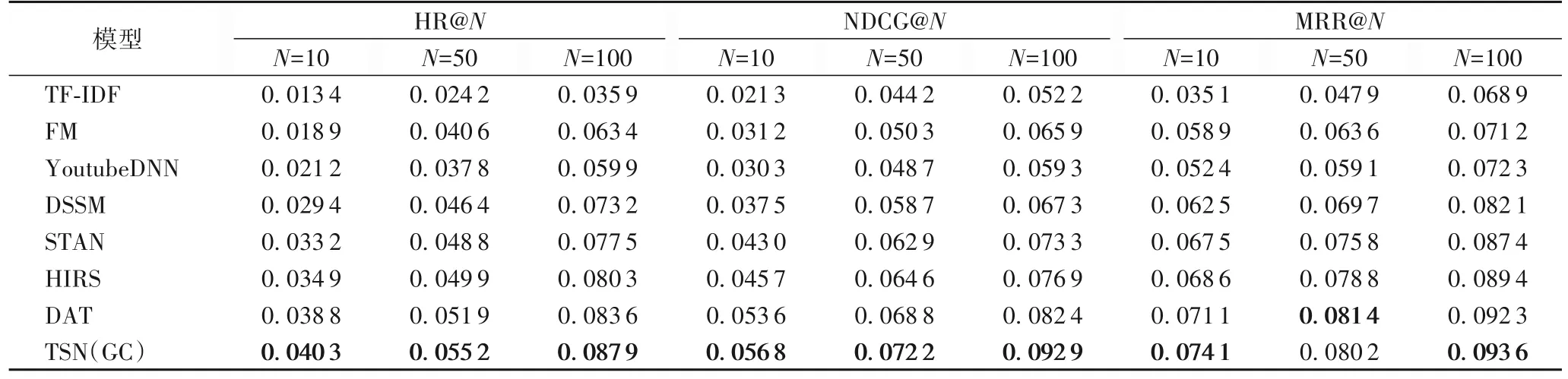
表3 各算法在MovieLens数据集的实验结果Tab.3 Experimental results of different models on MovieLens dataset
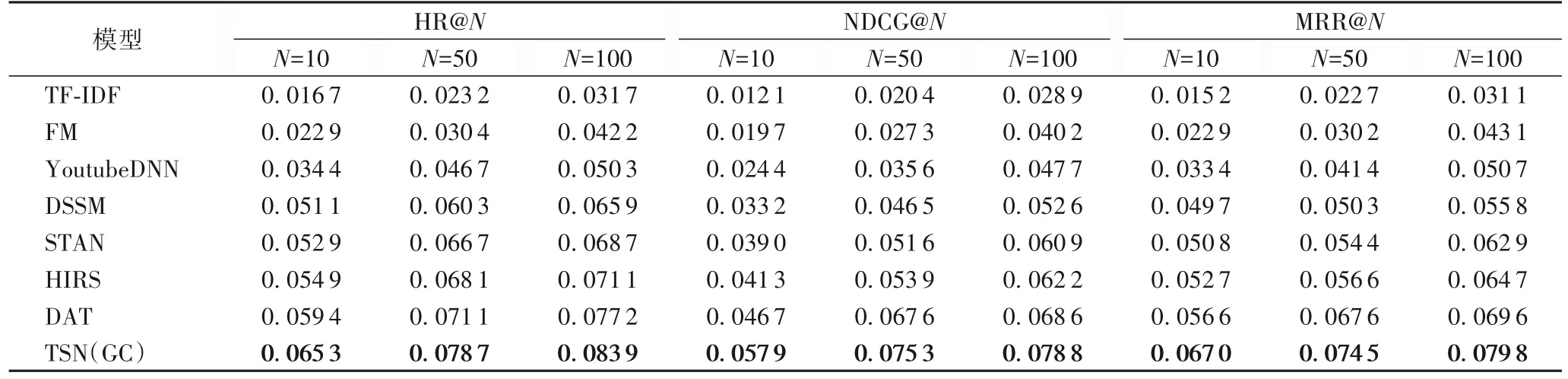
表4 各算法在豆瓣电影数据集的实验结果Tab.4 Experimental results of different models on Douban movie dataset
1)FM 通过分解用户-商品矩阵,实现基于向量的二阶特征交叉,它在稀疏场景中的表现明显优于基于频率的TF-IDF,在MovieLens数据集上,FM相较于TF-IDF在HR@10、HR@50、HR@100性能指标上提升40.06%~76.61%。
2)得益于DNN 强大的学习能力,用户和商品信息在DSSM 生成的向量中得到了较好的表示,相较于YoutubeDNN,DSSM 在豆瓣电影数据集中的NDCG@10、NDCG@50、NDCG@100 性能指标上提升了10.27%~36.07%。而YoutubeDNN 的表现相较于FM 整体上略有降低,这可能是由于全连接层过拟合导致的。
3)STAN 基于FM,使用自注意力机制提取用户行为的相对时空信息,MRR@10、MRR@50、MRR@100 性能指标相较于DSSM,在MovieLens数据集上提升了6.46%~8.75%。
4)HIRS 先将数据集映射为超图,再使用超边预测直接生成有益的特征交互,提高模型推荐性能。对超图的有效学习使得HIRS 的HR@10、HR@50、HR@100 性能指标相较于STAN,在MovieLens 数据集中提升了1.30%~3.96%。
5)在DSSM 的基础之上,DAT 自适应模拟机制生成的增强向量获取了用户侧和商品侧DNN 之间丰富的交互信息,这使得DAT 的HR@10、HR@50、HR@100 性能指标相较于传统的双塔模型在豆瓣数电影剧集中提升了16.24%~17.91%,NDCG@10、NDCG@50、NDCG@100 性能指标相较于HIRS 在豆瓣电影数据集中至少提升了10.29%。由于DAT的自适应模拟机制只能学习到正样本中用户和商品之间的交互信息,且双向共享机制不具备学习能力,其推荐性能仍有可提升空间。
6)TSN(GC)能通过对异构图进行卷积,提取用户和商品之间的连接信息,并使用具有二阶段学习技术的孪生神经网络对正样本和负样本进行全量训练的同时,学习到了用户侧和商品侧DNN 的深层次交互信息,提高了DSSM 对样本特征的学习能力。它的NDCG@10、NDCG@50、NDCG@100性能指标相较于DAT 在豆瓣电影数据集上提升了11.39%~23.98%。
为了更加直观地表示TSN 和基准算法的特征分布差别,本文将验证集通过TSN 和最优基准算法DAT 计算得到的用户及商品特征矩阵进行t-SNE 可视化降维,生成特征散点图,如图3。
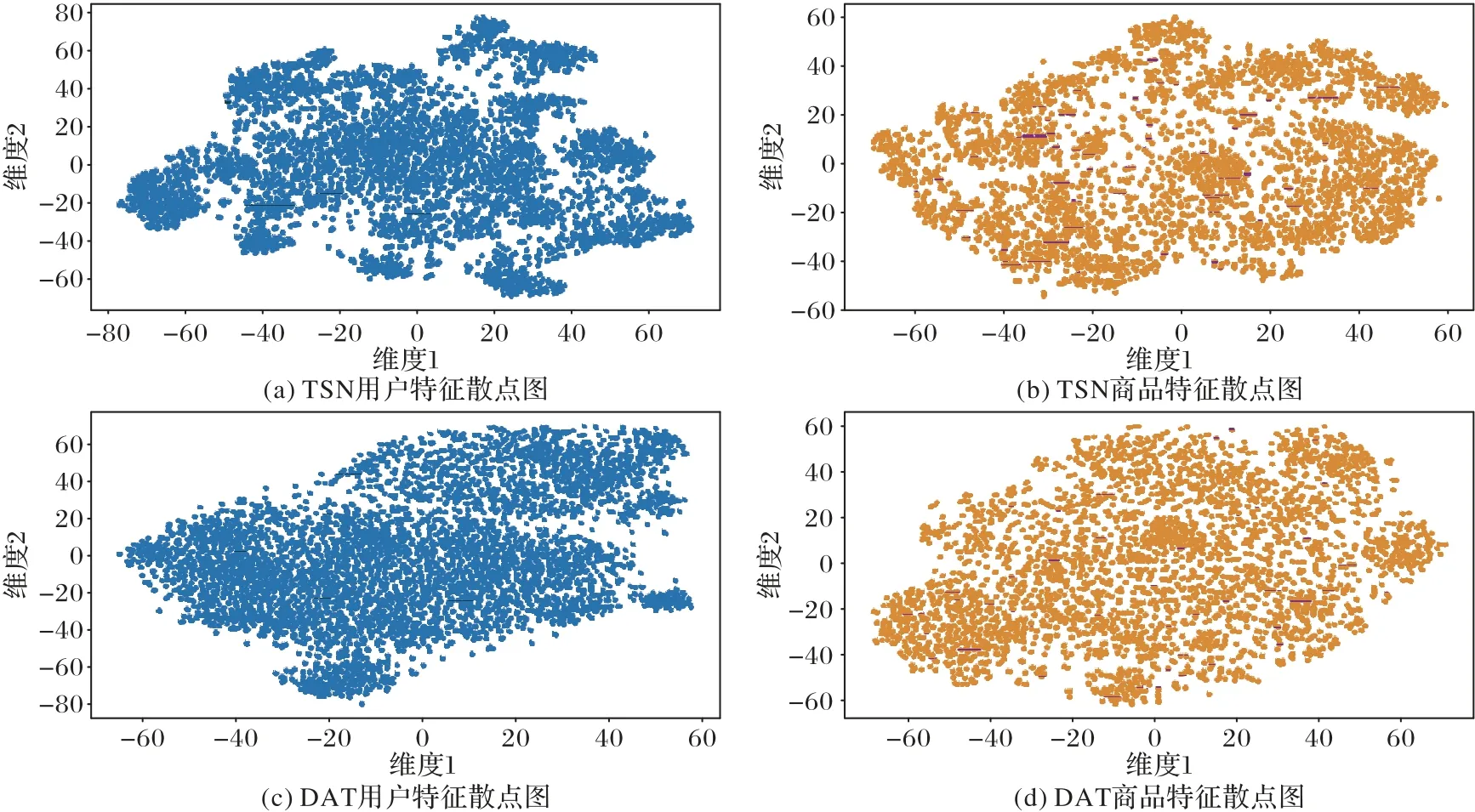
图3 TSN及最优基准算法DAT的用户和商品特征散点图(t-SNE)Fig.3 Scatter diagrams(t-SNE)of user and item features for TSN and optimal benchmark algorithm DAT
从图3 中可以观察到,TSN 和DAT 整体的分布比较均匀,没有出现非常明显的整体聚类现象,这说明TSN 和DAT都能针对不同类型的用户进行有效的推荐。此外,相较于DAT,TSN 在某些区域内对用户和商品的聚合能力更强,这说明TSN 更能根据用户的兴趣划分用户群体,根据商品特征划分商品类别,从而更好地完成推荐。
3.5 消融实验
为了验证TSN 中各部分功能的有效性,本文在豆瓣电影数据集上为TSN 设计了相应的消融实验。如表5 所示,TSN(w/o TS,GC)为去掉TSM 部分的TSN 模型,让孪生网络和双塔网络同时进行学习,不加限制地相互传递信息。TSN(U-GC)将HS-GCN 和DSSM 的商品侧DNN 之间的信息交互通道切断,仅保留和用户侧DNN 之间的信息交互通道,并采用TSM 的方式与用户侧塔进行信息交互。TSN(I-GC)仅保留HS-GCN 和商品侧DNN 之间的信息交互通道,同样采用TSM 的方式与商品侧塔进行信息交互。TSN(TS)在每个训练批次中先对HS-GCN 进行更新。

表5 TSN(GC)及其变体在豆瓣电影数据集的实验结果Tab.5 Experimental results of TSN(GC)and its variants on Douban movie dataset
从表5 中可看出,TSN(w/o TS,GC)在不采用TSM 的情况下,HR@10、HR@50、HR@100 性能指标相较于TSN(GC)至少下降了69.15%,甚至相较于传统DSSM 下降了32.86%~58.70%。可能是由于HS-GCN 将用户侧和商品侧DNN 完全串联,导致双方没有分别从用户和商品的特征数据中学习到正确的信息。TSN(U-GC)和TSN(I-GC)的NDCG@10、NDCG@50、NDCG@100 性能指标比传统的DSSM 分别提升18.44%~37.05%和20.34%~38.25%,这说明不论在用户侧还是商品侧进行HS-GCN 的增强,都能有效提高双塔模型的召回性能,且在用户侧增强的效果更好,这可能和HS-GCN能从异质图中提取到更多用户节点信息有关。而TSN(GC)的 MRR@10、MRR@50、MRR@100 性能指标相较于TSN(U-GC)和TSN(I-GC)分别提升了18.79%~29.34% 和22.26%~28.67%,这证明了HS-GCN 对DSSM 双向增强的有效性。此外,TSN(GC)和TSN(TS)的平均召回性能在三类指标中均无明显差异,这说明在训练过程中,HS-GCN 和DSSM的更新顺序对算法不造成实质影响。
3.6 HS-GCN训练强度分析
对HS-GCN 采用不同强度的训练,会在很大程度上影响最终模型在测试集上的表现。因此,以不同强度训练HS-GCN,观察分析HS-GCN 的训练强度对TSN 及其变体在召回性能上的影响。由于篇幅限制,本文仅对豆瓣电影数据集上的HR@100、NDCG@100、MRR@100 性能指标进行分析和对比。其余的性能指标与上述三种指标结果的趋势相似。
图4 中的横坐标为对于同一批样本,HS-GCN 和DSSM 训练次数的比值。实验中DSSM 的训练次数固定不变,因此该比值可以DSSM 的训练强度为单位,描述HS-GCN 的训练强度。实验将训练强度限制在0.4~2.0,步长为0.2。
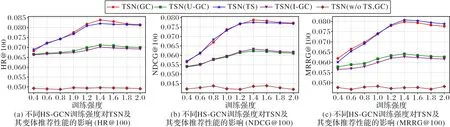
图4 HS-GCN训练强度对TSN及其变体性能的影响Fig.4 Effect of HS-GCN training intensity on performance of TSN and its variants
从图4 中可以看出,除了TSN(w/o TS,GC),训练强度从0.4~1.4,随着训练强度的提升,各算法的召回指标均不断上升,而超出1.4 后,都呈现出缓慢下降的趋势。这说明训练强度低于1.4 时,提升HS-GCN 的训练强度对双塔网络起到正向增强作用,1.4 为最佳训练强度,在训练强度超过1.4后,继续提升HS-GCN 的训练强度,将会对整个模型产生微负向的作用。TSN(GC)和TSN(TS)的指标折线缠绕比较紧密,无明显优劣之分,这支持了3.5 节中HS-GCN 和DSSM 的更新顺序对算法的影响很小的结论。关于TSN(U-GC)和TSN(I-GC),它们的变化趋势与TSN(GC)和TSN(TS)相似,这从另一角度证实了HS-GCN 的有效性,且验证了上述HSGCN 最佳训练强度的正确性,但由于仅进行了用户侧或商品侧的部分信息交换,TSN(U-GC)和TSN(I-GC)在性能整体上弱于TSN(GC)和TSN(TS)。此外,TSN(w/o TS,GC)将双塔网络的用户侧塔和商品侧塔完全串联,不仅使双塔网络丧失了独立学习用户特征和商品特征的优势,也无法让孪生网络学习正确的交互信息;所以,TSN(w/o TS,GC)的性能表现始终处于较低水准,且孪生网络训练强度的变化对TSN(w/o TS,GC)的性能表现几乎没有影响。
4 结语
本文提出一种二阶段孪生图卷积神经网络推荐算法TSN,该算法基于用户-商品二分图设计孪生图卷积神经网络,不仅连接双塔型神经网络的两侧,而且引入用户和商品的连接特征,实现双塔型神经网络用户侧与商品侧之间的深度信息交换。为了避免双塔型神经网络完全串联,减少训练参数和人工成本,提出以梯度截断技术为核心的二阶段学习机制,使TSN 更适合用于大规模的推荐环境中。此外,本文对孪生网络的训练强度进行分析,并得到最佳训练强度。大量实验表明,TSN 可以有效提高双塔模型的召回性能。
