基于组残差块生成对抗网络的面部表情生成
2024-03-12林本旺赵光哲王雪平
林本旺,赵光哲,王雪平,李 昊
北京建筑大学电气与信息工程学院,北京 102616
面部表情是人与人之间进行非语言交流的重要方式之一,在理解人的心理活动时有着不可替代的作用。面部表情生成是指给定目标表情标签和输入图像,生成带有指定表情语义信息的面部表情图像。面部表情生成在医疗行业、电影行业、游戏行业和视频会议等多个领域都有着广泛的应用[1-2]。随着科技的进步和行业的发展,各个行业对于面部表情生成图像质量的要求越来越高。因此,如何生成高质量的面部表情图像成为了一项非常有挑战性的研究课题。
近年来,面部表情生成方法已经从早期的手工设计特征的方法发展到基于深度学习的方法。早期的研究主要是依赖于计算机图形技术,通过手动扭曲直接进行面部表情的制作[3-5]。虽然取得了一定的成果,但是需要人工干预和大量资源,无法大规模应用。随着深度学习的发展,基于深度生成模型逐渐成为主流算法[6-8]。Zhao等人[6]提出了一种新的基于分析的合成方法,通过将生成对抗网络和动作单元结合在一起用于面部表情生成,这种方法能够使面部表情生成图像富有真实性,但是对于细节的约束力不足,容易出现模糊问题。吴宇宁等人[7]提出一种能够对生成表情类型和强度控制的机制,结合面部动作单元结果能够生成不同强度和不同类型的面部表情图像,但是该方法过度依赖面部动作单元,无法单独生成高质量面部表情图像。Tang 等人[8]提出了一种结合了特征点检测的生成对抗网络模型,能够实现任意单幅面部表情图像向不同类别的面部表情图像的转换,但是该方法依赖特征点的标注,特征点的标注质量会直接影响面部表情生成图效果。
一般的基于深度学习的方法大多针对一般的人脸合成任务,没有考虑局部面部表情特征的变化,不适用于面部表情生成。事实上,当人类识别和区分不同表情时,注意力会集中在面部变化较大的区域,例如,做开心表情时,嘴部的变化是最为明显的。通过添加注意力机制能够妥善处理这个问题。Nie等人[9]为了更好的保留生成图像细节,提出了URCA-GAN 模型用于面部表情生成,用上行残差注意力模块来加强面部表情生成图像的细节控制,但是该模型没有对空间特征加以约束,生成图像缺乏真实性。以往基于生成对抗网络的方法常将面部表情生成归属于人脸属性编辑,将整个人脸当作整体处理,忽略了关键区域的变化,这就会导致部分区域出现重叠和模糊,生成图片质量低,导致生成的面部表情不够真实。
为了解决上述问题,本文提出了一种新的面部表情生成方法,即嵌入注意机制的组残差生成对抗网络(group residuals with attention mechanism-generative adversarial network,GRA-GAN),该方法通过在组残差块中嵌入混合注意力机制来生成面部表情。GRA-GAN能够通过混合注意力机制和带有注意力机制的组残差模块来逐级自适应加强面部表情变化明显区域的关注度,能够明显地提升生成图片的质量。综上所述,本文的贡献总结如下:
(1)为了解决面部表情生成部分区域出现重叠和模糊问题,提出了一种新的面部表情生成方法GRA-GAN,在生成对抗网络中加入混合注意力机制和嵌入混合注意力机制的组残差块(group residuals with attention mechanism,GRA),来增加对面部变化较大区域的关注度和加强残差块与残差块之间的联系,提升残差块之间的相关性,提升学习效果,从而避免生成的面部表情区域重叠和模糊问题。
(2)本文在RaFD 数据集上进行了面部表情生成实验。实验结果表明,本文提出的方法能够明显改善区域重叠和模糊现象,生成面部表情更加真实,实验结果优于相关方法。
1 相关工作
1.1 面部表情生成
目前,关于面部表情生成的研究方法总体可以分为基于传统的手工设计特征的生成方法以及基于深度学习的面部表情生成方法。
基于传统的手工设计特征的生成方法。自Blanz等人[10]提出三维可变形人脸模型以来,出现了很多基于三维可变形人脸模型的人脸表情合成生成技术[11],人脸动画[12-13]或者构建一个能够操纵的合成人脸[14]。尽管这种方法能够建模整个人脸,但是使用合成分析方法将三维模型拟合到目标人脸图像上,需要很高的计算成本。另一种方法就是使用基于加权扭曲的方法[15]来合成面部表情,为了控制源图像的面部表情生成,需要一个驱动面进行扭曲,创建细节如牙齿或者源图像不存在的脸,这些都需要从训练数据中学习。
近年来,随着深度学习的发展,以生成对抗网络等为代表的深度学习方法在图像生成方面有很大的进展,逐渐成为面部表情生成的主要研究方法。He等人[16]提出了一种基于多任务学习的ATTGAN模型来实现人脸属性编辑的模型,它能够通过属性分类约束来确保生成正确的人脸属性,这种做法能够控制面部表情生成图像属性,但是无法保证生成图像的质量。Chen等人[17]提出一种用插值做人脸编辑的HGAN 模型。它将图像先转移到隐空间中,在对其进行插值操作,逐渐把图像转移到目标域中,但是当源域和目标域差距过大时,模型效果会降低。Wu等人[18]提出一种渐进式人脸表情编辑模型Cascade EF-GAN。该模型不针对整张面部图片进行表情编辑,它采用渐进式训练模型将表情细分为眼睛、鼻子和嘴巴区域进行独立的表情编辑,能够有助于抑制重叠伪影问题。但是由于对三个区域独立操作,会出现生成表情不自然的问题。Tang 等人[19]提出了一种引导表达生成对抗网络EGGAN 用于人脸表情编辑。该模型采用对抗性自动编码器将源图像映射到隐空间,然后结合源图像给定目标标签,使用GAN 生成具有目标标签的人脸表情图像。但是该模型并未对生成表情细节进行针对性的约束,导致生成人脸图像出现了模糊问题。Pumarola 等人[20]提出一种基于动作单元的GANimation模型来用于面部表情生成,它打破了传统采用离散的表情种类控制人脸语义的方法,描述了连续流形中的标签,可以调节人脸表情的变化程度,但它的生成图像效果严重依赖于动作单元的注解。Tang 等人[21]提出一种注意力引导的生成模型,能够引导生成器生成注意力掩码,通过融合注意力掩码生成面部图像,该方法能同时生成八种面部表情图像,但是对于生成图像的细节处理表现不佳。Xia等人[22]提出一种局部网络与全局网络相结合的模型,能够利用局部网络处理细节特征,再结合全局网络进行面部表情生成,但是该方法对生成表情图像的细节控制不足。
现有的基于深度学习的方法主要将人脸作为一个整体,并没有区分不同区域变化程度的大小,这就会导致生成面部表情图片的区域重叠和模糊。而注意力机制[23]会首先关注变化大的局部信息,然后再把不同区域的信息组合起来,可以有效地提取图像的局部和全局特征之间的依赖关系,增强网络的学习能力。Yang等人[24]提出了一种结合了通道注意力机制和空间注意力机制的CASGCN生成对抗网络,来增强特征传递,提高生成图像质量,但CASGCN 只是将两种注意力机制简单的插入到生成器的前后,并未对残差块进行改进,生成图像出现了不同程度的虚影和模糊问题。
面部表情生成任务和一般的图像生成任务有很大的区别,图像变化的区域更加的固定,例如从“中性”表情变成“惊讶”表情,变化较大区域集中在嘴巴、眼部和额头区域,其他区域变化并不明显,如果在模型学习特征时平均分配权重显然是不合适的。因此本文结合了混合注意力机制来改善这个问题,通过混合注意力机制自适应的分配特征权重,不仅能够让模型在学习过程中关注变化较大的区域,提高生成图像质量,还能够在空间上关注特征分布,让生成图片更加真实。
1.2 生成对抗网络模型
生成对抗网络框架(generative adversarial network,GAN)是由Goodfellow 等人[25]引入的深度学习架构,由两个相互作用的神经网络组成,即生成器网络G和判别器网络D,该模型已经广泛且成功的应用于许多领域[26-27]。基于生成对抗网络的面部表情生成一直是研究热点,以前的研究只是把这个任务视为一般的图像到图像的转换,面部表情被认为是特殊的面部属性,这会导致模型在学习时会认为这种表情差异是均匀分布在整个人脸,不会对变化较大的关键区域给予特殊的关注。Mirza等人[28]提出了一种能够控制生成目标属性图像的CGAN 模型,它能够通过添加额外条件控制GAN 生成目标图像,而不是随机的生成图像,为之后的面部表情生成模型提供了新的思路,但它的生成图像有很多缺陷,例如图像边缘模糊、分辨率低等。Zhu等人[29]提出的CycleGAN 模型是一种典型的图像到图像的转换架构,它的目标是学习并保持内容图像特征的翻译映射。在CycleGAN中,不仅要生成目标风格的图片,还要保证生成图片内容不变,故提出了循环一致性损失来解决这一问题。但是由于该模型着重于整体属性变化,生成的面部表情图片还是会出现部分区域重叠和模糊问题。受到CycleGAN 的启发,本文引用了该模型的思想,在基础上进行了网络架构的重建,通过嵌入混合注意力机制和组残差块结构增强图像细节,提升生成图像的真实性。
1.3 注意力机制模块
注意力机制(attention mechanism)是一种能够将计算资源合理分布的和解决信息超载的一种资源分配方式。随着神经网络的不断发展,模型的参数越来越多。虽然模型的学习能力和表达能力越来越好,但是模型所需要储存的信息量也越来越大,这就会导致信息超载的问题。为了解决这一问题,使得模型能够合理分配计算资源处理更为关键的信息,提高模型效率和准确性,研究者们提出了一些即插即用的注意力机制模块。例如,Hu 等人[30]提出了一种通道注意力机制模块(squeezeand-excitation,SE)。该模块能够通过参数为每个特征通道生成权重,其中参数来表示特征通道之间相关性,然后通过权重来表示每个特征通道的重要性,从而完成在通道维度上对原始特征的重新标定,在计算量低的情况下有着优异的表现。Hou等人[31]提出一种将位置信息嵌入通道信息的注意力机制(coordinate attention,CA)。该模块将通道注意力机制分解两个平行的1D 特征编码,来有效整合空间坐标信息,从而生成注意力特征图。相对于SE 模块,CA 模块能跨通道处理特征,而且更具有目的性。Woo等人[32]提出一种轻量级卷积注意力模块(convolutional block attention module,CBAM)。该模块包含通道注意力模块和空间注意力模块两个子模块,能够分别从通道和空间两个维度上进行特征的重新标定。CBAM不仅能够大幅度节约计算力,还能够保证对于目标特征进行有效的标定。
2 方法
2.1 概述
给定任何输入的正面面部图像xs和一个输入标签c,其中,xs来自于源图像域Xs,c来自于目标表达域C′。本文的目标是学习一个映射函数G,它能够通过改变输入面部图像xs的面部表情,生成目标标签c所描述的面部表情图像G( )x,c。生成图像不仅要生成含有目标表情的图像,而且还不能丢失输入图像的特性。为了实现上述目标,本文借助了CycleGAN的思想,GRA-GAN整体框架如图1所示。
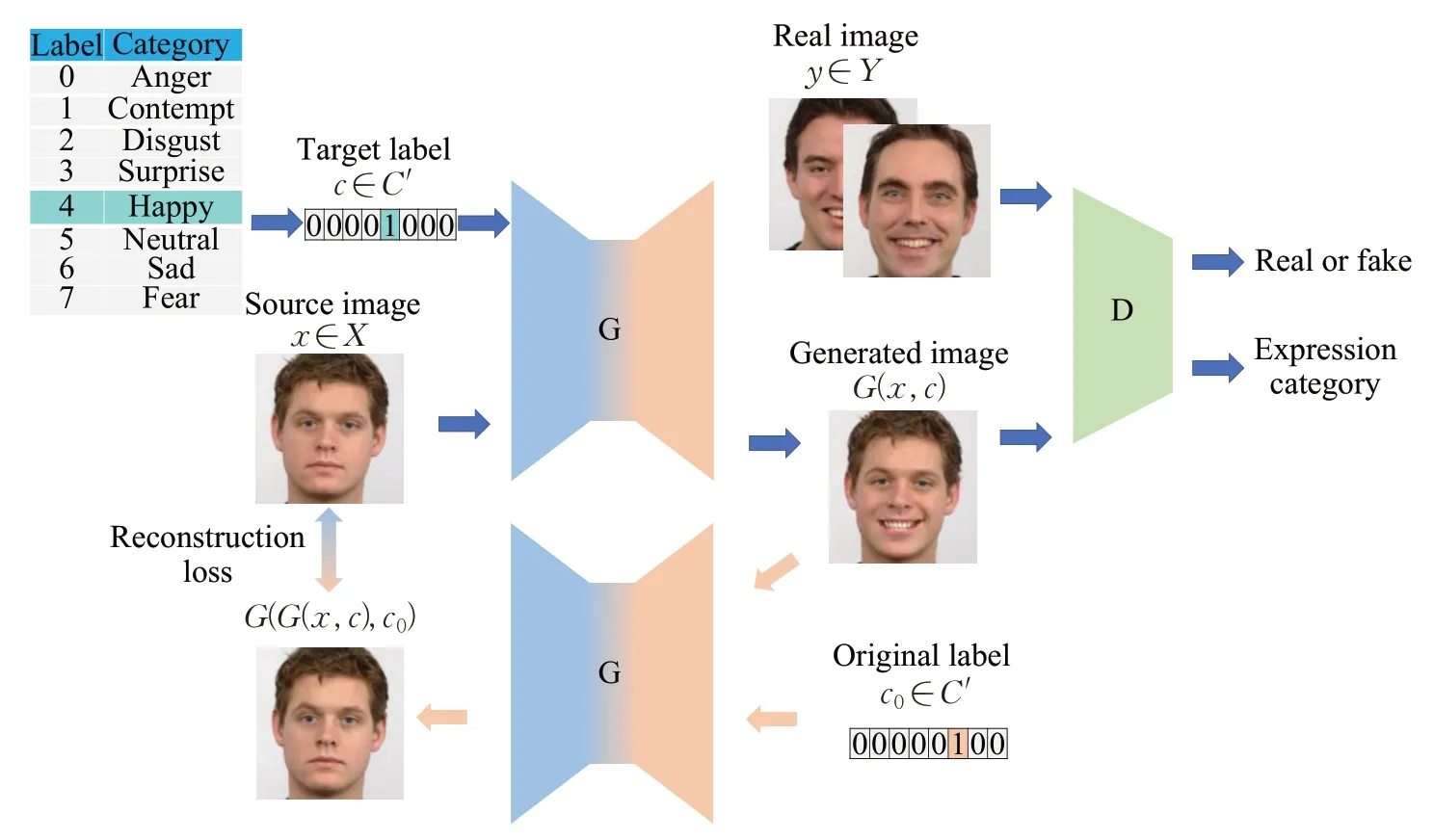
图1 GRA-GAN整体框架图Fig.1 Overall framework diagram of proposed GRA-GAN
GRA-GAN人脸表情生成框架主要包括两个部分:嵌入混合注意力机制的组残差块生成器G 和判别器D。嵌入混合注意力机制的组残差块生成器G 能够自适应加强学习表情变化丰富的区域特征,生成含有对应表情标签的面部表情图像;判别器D能够分别判别生成图像的真假和是否带有目标标签。
2.2 嵌入混合注意力机制的组残差块的生成器
为了改善面部表情生成图像区域重叠、模糊和缺乏真实性等问题,本文提出了一种嵌入混合注意力机制的组残差块的生成器,该生成器结构由一组用于下采样的卷积层、残差块和用于上采样的反卷积层组成,具体结构如图2所示。生成器的输入通道数为3+n,由输入图像的通道数和面部表情类别数等标签的维度定义。为了关注面部表情合成过程中变化较大的面部区域,本文在进行下采样之前和上采样之后分辨嵌入了混合注意力机制。它沿通道和空间两个维度顺序导出注意映射图,并将它们与输入特征图相乘以自适应细化特征。混合注意力机制(mixed attention mechanism,MAT)结构如图3所示,它由通道注意力机制模块和空间注意力机制模块组成,通道注意力模块关注通道的特征之间的相互依赖关系,空间注意力模块突出特征的重要空间位置。因此添加两个注意力模块能够进一步细化图像的特征表示并降低模型复杂度,最终实现局部特征在通道和空间维度上具有全局依赖性的自适应集成。

图2 生成器结构图Fig.2 Generator structure diagram

图3 混合注意力机制模型Fig.3 Mixed attention mechanism model
为了使得生成器G 在迭代过程中持续不断的关注变化较大的关键区域,本文提出了一种融入混合注意力机制的组残差块,具体结构如图4 所示,每一个残差块都有两个通道数相同的3×3卷积层,每一个卷积层后面都做一次ⅠnstanceNorm 归一化,在第一次激活后,采用ReLU激活函数进行激活。
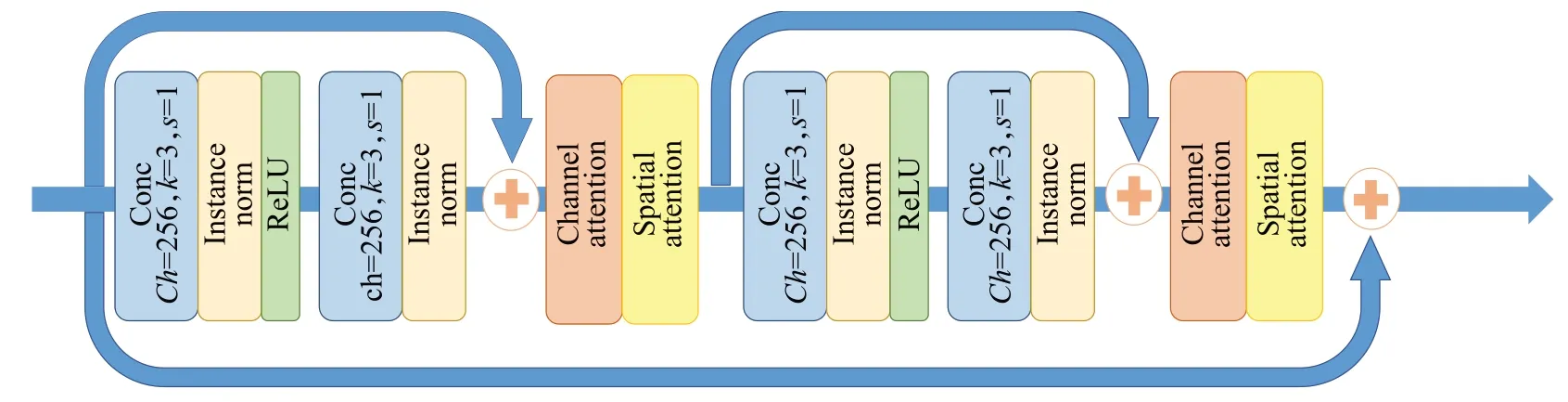
图4 嵌入混合注意力机制的组残差块结构图Fig.4 Group residuals with attention mechanism module structure diagram
本文通过将混合注意力机制嵌入残差块中,这样在每次传递特征时都能够通过注意力机制给予不同权重,增强面部变化较大区域的细节处理。原始的生成器结构有一个非常大的弊端,它只是把残差块简单的串联在一起,这样会使得在特征传递的过程中只关注上一层传递过来的信息,忽略了更前面的信息,为了使得残差块在传递特征时能够更全面的考虑较浅层信息,本文采用了分组的思想,将每两个带有混合注意力机制的残差块分为一组。通过实验发现,将残差块进行一次分组会比将残差块进行两两分组后再进行一次分组的效果要好。本文认为面部表情特征在传递的过程中,面部变化较大的区域特征会有明显变化,如果让残差块的输入信息来源于距离更远的残差块会影响最后的生成效果,所以本文最终采用了两两分组的结构,让残差块在处理特征时关注适当距离的残差块信息。
2.3 判别器
本文方法的判别器思想来源于的PatchGAN[33],普通的GAN 判别器是将输入映射成一个实数,即输入样本为真样本的概率,而PatchGAN 将输入映射为N×N的矩阵X,Xij的值代表每个patch 为真样本的概率,将Xij求均值,即为判别器的最终输出。判别器有两个功能,一是判断生成图像的真假,另一个功能是判断输入图像所属的表情类别。
如图5所示,主体网络包括6个4×4的卷积层,每一个卷积层后面连接一个LeakyReLU 激活层,以加速损失函数的梯度传播。在判别生成图像真假时采用一个3×3卷积层,通过判别每个patch是否为真,将结果求均值,作为最后判别生成图真假的结果。与此同时判别器还需要通过辅助分类器来预测生成图片面部表情的类别。
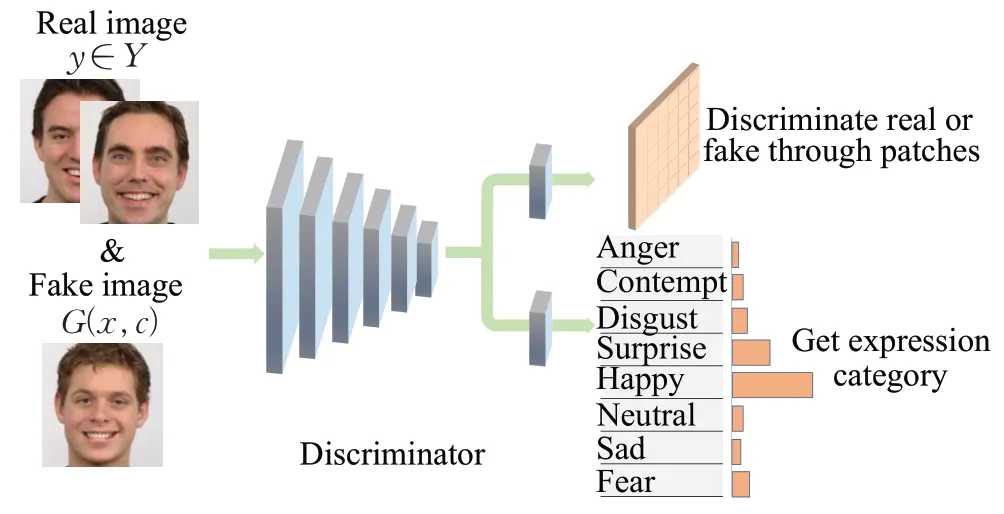
图5 判别器结构图Fig.5 Discriminator structure diagram
2.4 损失函数
训练中采用了三种损失函数,分别为对抗损失、重建损失和类别损失。采用对抗损失函数来约束生成图像更加真实。采用重建损失函数能够进一步保证生成图像在像素级和特征级上都能更加接近真实图像,保证输出图像G( )x,c不改变输入图像x的内容。采用类别损失函数能够保证输出图像G( )x,c能够正确的分类到目标域C。
对抗损失:对抗损失主要是基于鉴别器D和生成器G。损失函数的计算方法如下:
本文使用GAN 的常规函数,生成器G 通过输入图像x和目标域标签c生成图像G(x,c),生成器G 的目的是最小化该目标。判别器D 来判别真实图像与生成图像是否一致,判别器D的目的是最大化该目标。其中Dsrc(x)判别器D给出的源域上的概率分布。
重建损失:对抗损失函数能够保证生成图像的真实性,但是没法保证生成图像G( )x,c保留输入图像x的内容。为了解决这个问题,本文对重建损失函数的定义如下示:
再使用一次生成器,将原始标签和生成图像G(x,c)结合后再次放入生成器G 中再生成伪原始图像x0。通过比较原始图像x和伪原始图像x0的正则化距离,来保证生成图像G(x,c)保留输入图像x的内容。
类别损失:类别损失的目的是为了生成带有目标标签的面部表情图片,所以要使输入图像x转化为输出图像G(x,c)能够正确的分类到目标域c,为了达到此目的,本文对类别损失定义如下:
其中,Dcls(c′|x)代表判别器D将真实样本归于原始标签c′的概率分布,判别器的目的是最小化类别损失。生成器G 的目的是使生成图像G(x,c)尽可能地被判别器D分类成目标域c,因此类别损失越小越成功。
完整的损失函数如下公式所示:
其中,生成器G 的损失函数由对抗损失、重建损失和类别损失组成,超参数λcyc和λcls分别设置为10 和1。判别器损失函数由对抗损失和类别损失组成。
3 实验
3.1 数据集
本文使用Radboud Faces Dataset(RaFD)[34]作为训练数据集,RaFD 由4 824 张大小为681×1 024 的人脸图像组成,共有67名参与者参与,每位参与者的面部图像都是由摄像机从3 个不同角度进行拍摄。这个数据集中的面部图像标签中含有8种离散的面部表情类别,包括愤怒、蔑视、厌恶、惊讶、快乐、中性、悲伤和恐惧。为了保证面部表情的完整性,本文只使用了正面面部图像,总共1 608张正面面部图像。在本文实验中,按照67个身份进行分类,随机选择其中的90%作为训练集,剩下的10%作为测试集。
3.2 实验配置
本文使用PyTorch 构建并训练模型,PyTorch 版本为1.12 版本;操作系统为Window 10;编程语言使用Python 3.7。CPU和GPU分别为i7-12700K和RTX3070Ti(显存8 GB),服务器运行内存为16 GB。GRA-GAN 在该实验硬件平台上的训练时间为16 h,测试时间为(7.58±0.5)s。
训练阶段的batch size 设置为16;迭代次数设置为300 000 次;训练时将原始数据集裁剪成只含有面部图像的128×128图像作为输入数据;优化函数采用随机梯度下降算法Adam[35],学习率设定为0.000 2,beta1=0.5,beta2=0.999;损失函数超参数设定λcyc=10,λcls=1。
3.3 评价指标
本文采用3种常用评价指标作为评价生成图像质量的评价指标,分别是弗雷歇初始距离(Frechet inception distance,FⅠD)[36]、峰值信噪比(peak signal to noise ratio,PSNR)[37]和结构相似性(structural similarity,SSⅠM)[38],采用表情识别率验证生成图像对目标表情细节的保留。接下来,分别对每种评价指标进行简单介绍。
3.3.1 弗雷歇初始距离
弗雷歇初始距离是用来评估生成图像质量的一种度量标准,专门用来评估生成对抗网络的性能,得分越低说明两图像越相似,最佳情况下得分为0。FⅠD 计算的是真实图片和生成图片在特征层面的距离,因此对于作为评估生成对抗网络的性能的指标显得更为合理一些。计算公式如下:
其中,μr是真实图片的特征的均值,μg是生成图片的特征的均值,Σr是真实图片的特征的协方差矩阵,Σg是生成图片的特征的协方差矩阵,本质上是使用真实图像和生成图片提取特征向量之后的均值,协方差的距离评价。当生成图像和真实图像特征越相近时,均值差的平方越小,协方差也越小,则FⅠD也越小。
3.3.2 峰值信噪比
峰值信噪比常用于衡量两张图像之间的差异,是评价图像的客观标准之一,也是最普遍使用的评估图像质量的指标,峰值信噪比越高说明生成图像质量越好。计算方式如下:
其中,MaxValue为图像像素可取到的最大值,例如8位图像为28-1=255,MSE为两张图像的均方误差,具体计算过程如下所示:
MSE越大,PSNR数值越大,两张图像越相似。
3.3.3 结构相似性
结构相似性常用于评价两张图像的相似程度的指标取值范围为[0,1],SSⅠM得分越高,说明表情图像失真程度越小,图像质量越好。它主要由三个部分组成,分别是图像照明度比较部分l(x,y),图像对比度比较部分c(x,y),图像结构比较部分s(x,y)。详细公式如下所示:
其中,μx和μy、σx和σy分别为x和y的平均值和标准差,σxy为x和y的协方差,C1、C2、C3都是常数,用来保证分母为非负数。SSⅠM 的值越大,代表着两张图片的相似度越高。
3.3.4 表情识别率
在面部表情生成任务中,生成的表情类别的准确性是本文所关心的关键问题。因此在定量分析时,本文从表情识别率进行定量评估。为了验证生成的图像是否指定表情类别,采用Face++[39]计算生成图像的表情准确率。Face++是云端视觉服务平台,提供了完整的人脸分析的视觉技术服务,可以从图像中分析出人脸表情属于7种类别(愤怒、厌恶、惊讶、快乐、中性、悲伤和恐惧)的概率。但是GRA-GAN从RaFD数据集上可以生成8种面部表情,而Face++缺少轻蔑这一面部表情标签。为了公平起见,本文只对不包含轻蔑表情的面部表情生成图像进行识别,在此基础上计算面部表情识别准确率。
3.4 实验结果与分析
3.4.1 实验结果展示
图6 展示了GRA-GAN 生成的8 种基本表情图像。如图6 所示,本文提出的GRA-GAN 可以生成真实的不同类别的面部表情图像,能够有效解决局部区域重叠和模糊的问题,非常明显地反映出不同情绪。本文利用旷视Face++来对面部表情生成图像进行表情识别,通过GRA-GAN生成的面部表情图片平均识别率为91.41%。实验结果表明,GRA-GAN能生成高质量和具有真实性的面部表情图像。

图6 GRA-GAN表情生成图像示例Fig.6 Ⅰmage examples of GRA-GAN expression generation
3.4.2 对比实验
本文将从定性评估和定量分析两个角度来对本文方法与相关方法进行分析比较。相关对比方法包括CycleGAN、StarGAN[40]、HGAN、EGGAN、GANimation和AttentionGAN。CycleGAN 通过两个生成器和两个判别器能够实现不同域图像之间进行转换,而本身的形状特征保持不变,提出了循环一致性的想法保证生成图像保留源图像的内容。StarGAN 能够只使用一个生成器和一个判别器实现对多个域进行图像到图像的转换,通过输入图像和不同的目标标签就能够生成基于目标域标签的输出图像。HGAN 和EGGAN 都是对隐空间进行操作的人脸表情编辑方法,能够生成人脸表情序列。GANimation 基于动作单元(action units,AU)可以生成连续的人脸表情。AttentionGAN 将生成器输出与注意力掩码融合生成新的目标图像。
定性评估:图7 为在RaFD 数据集上使用不同方法生成8 种面部表情图像的定性比较。输入图像来自RaFD 数据集带有“中性”标签的面部人脸表情,不同行代表不同方法生成的面部表情图像。

图7 GRA-GAN与其他模型的对比实验示例Fig.7 Experimental examples of GRA-GAN compared with other modeles
如图7 所示,CycleGAN 和StarGAN 模型生成的面部表情图像出现了明显的区域重叠和模糊问题。由于面部区域存在较大的转换和变形,面部表情生成任务应该是更复杂的任务,而不能简单地当成人脸属性来简单处理。HGAN和EGGAN都是对隐空间进行编辑,能够生成高质量特定表情,例如带有“快乐”标签的人脸表情,但是针对部分表情表现不佳,例如带有“蔑视”标签的人脸表情,HGAN生成含此类标签的表情图片无法被明显识别为“蔑视”表情,而EGGAN生成含此类标签的表情图片出现了模糊问题。GANimation 结合了基于AU 注意力机制的模型表现良好,但是部分区域还是出现了明显的区域模糊,缺乏真实性。AttentionGAN生成的面部表情图像在唇部区域出现了模糊问题。主要原因是,AttentionGAN 过多依赖于注意力掩码的生成质量,对于细节处理不稳定。而本文提出的GRA-GAN,通过嵌入混合注意力机制,从通道和空间分布两方面加强细节处理,能够使得模型更好的学习细节,也能够生成更加自然真实的面部表情图像。通过与先进方法的比较,本文可以看出本文提出的方法GRA-GAN在面部表情生成任务中能够取得更好的效果。
定量分析:本文使用FⅠD、PSNR、SSⅠM 指标和表情识别率来综合评估生成面部表情图片的质量和真实性。通过将GRA-GAN在RaFD数据集上与其他方法进行比较来验证本文方法的有效性,表1呈现了GRA-GAN模型在4个定量指标上的客观结果。

表1 GRA-GAN与其他模型的评价指标得分对比Table 1 Comparisons of evaluation index scores of GRA-GAN and other models
从表1 可以看出,GRA-GAN 从这3 个图像质量评价指标上优于其他6个模型,表情识别准确率也高于其他6个模型。GRA-GAN通过注意力机制自适应去分配不同特征的权值,能够使得面部表情生成图像更好的呈现清晰的面部表情,比如嘴巴和眼睛这些容易重叠的区域。而对PSNR和SSⅠM这种从像素级层面比较和图像结构比较的评价标准,GRA-GAN在模型中嵌入混合注意力机制,能够在空间上更好约束生成图像,使得生成图像和原始图像在空间分布上有更好的相似性。
结果表明,本文所提出的GRA-GAN通过嵌入混合注意力机制的组残差块能够更好地适应面部表情生成任务,能够解决部分区域重叠和模糊的现象,增加面部细节生成,从而使得生成表情更加的真实。
3.4.3 消融实验
在本小节中,做了消融实验来评估MAT 模块和GRA 模块的贡献。本文比较了该模型的3 个版本,即原始模型(Ours w/o MAT&GRA)、只带有MAT 模块(Ours w/o GRA)的模型和嵌入GRA 模块(Ours)的模型。消融实验结果如图8所示,从生成面部表情图像来看,添加了MAT 模块能够明显地改善生成图像区域重叠和模糊现象,但是像厌恶这种嘴部变化较大的生成图像约束力还是不足,嘴部还是有轻微模糊,在加入GRA模块后,这种重叠明显缓解,而且使生成的图像更加真实自然。

图8 GRA-GAN消融实验结果示例Fig.8 Examples of GRA-GAN ablation experimental results
本文也对其使用FⅠD、PSNR、SSⅠM 和表情识别率进行了定量分析,如表2 所示,FⅠD、PSNR 和SSⅠM 分数说明了生成图像质量在逐步提升,面部表情识别率说明了生成图像的真实性也在逐步提升。添加MAT模块后各项指标有明显提升,表明添加注意力机制,有助于学习表情细节。GRA-GAN 通过加入GRA 模块来区分面部关键区域的重要程度,说明了关键面部区域在面部表情生成中有着十分重要的作用。

表2 消融实验的评价指标得分对比Table 2 Comparisons of evaluation index scores of ablation experiments
4 结束语
针对面部表情图像生成质量较低的问题,本文提出一种嵌入注意机制的组残差块生成对抗网络(GRAGAN)。所提出的GRA-GAN通过在生成对抗网络中嵌入混合注意力机制,从通道和空间两个方面关注特征传递,从而增强生成面部表情图像的细节,改善面部部分区域重叠和模糊现象,增加生成面部图像的真实性。为了进一步加强模型对关键区域的学习能力,提出了一种嵌入混合注意力机制的组残差块,来增加特征传递时的学习能力,加强残差块之间的联系,能够使得特征在残差块传递的过程中更好地保留关键信息。
目前该模型只适用于实验室环境下的正面面部表情生成。自然环境下的面部图片往往会有很多干扰,类似光照、姿态和遮挡等。针对自然环境数据集的高质量面部表情生成任务是今后主要的研究方向。
致谢本文由“机器人仿生与功能研究北京重点实验室”资助。
