多尺度特征与知识图谱融合的景区手写诗词识别
2024-03-10白佳豪冀振燕
何 坚, 杨 洺, 白佳豪, 冀振燕
(1.北京市物联网软件与系统工程技术研究中心, 北京 100124;2.北京工业大学信息学部, 北京 100124; 3.北京交通大学软件学院, 北京 100091)
随着我国经济快速发展,景区旅游参观成为人们日常生活不可缺少的内容。同时,景区通常会引用古今名人诗词的临摹作品以吸引旅客,并提高景区知名度。但是,这些临摹诗词字体风格迥异,游客常常难以完全辨认出其中的文字,解决此问题需要相关文本检测与识别技术的支持。
目前,主流文本检测方法可分为基于回归的文本检测方法和基于分段的文本检测方法。基于回归的文本检测方法是在普通目标检测方法的基础上改进而来的。其与传统目标检测任务不同的是,文本具有更为特殊的尺寸、大小和长宽比,而且经常以文本行或文本段形式出现,导致难以准确全面地框定文本内容。Tian等[1]针对此问题提出了连接文本建议网络(connectionist text proposal network,CTPN)算法,使用一组宽度为16像素的候选框表示文本区域,然后通过水平距离和竖直方向交并比连接候选框,并生成最终的文本预测框。此方法由于锚定框和后处理算法的限制,无法准确检测景区中竖向和倾斜的手写诗词。Liao等[2]针对多角度文本检测问题提出了TextBoxes,通过修改卷积核和锚定框等方式有效地捕捉多种文本形状。Liu等[3]结合四边形滑动窗口提出了基于深度匹配先验网络,进一步优化了该问题的解决方法。随后,Liao等[4]提出了旋转敏感回归检测器,其应用主动旋转卷积滤波器以充分利用旋转不变的特征,使问题得到了进一步解决。
总体而言,基于回归的文本检测算法通过改变长宽比和改进后处理算法等方式提升文本检测效果,可检测类型也从单一的水平文本变为多角度文本。因为其检测效果仍受到候选框和后处理算法制约,所以针对景区中的不规则和小尺寸手写诗词检测效果不佳。
基于分段的文本检测器是一种在像素级定位文本区域的方法。此类文本检测算法的思想来源于全卷积网络(fully convolutional networks,FCN)[5],通过上采样技术将最后一个卷积层输出的特征图放大到与输入图像同一尺寸,从而预测每个像素属于文字区域的概率。Zhang等[6]设计了一种基于区域特征提取的字符级文本检测器,但其在某些情况下会导致文本检测的鲁棒性受限。Lin等[7]引入特征金字塔网络(feature pyramid networks,FPN)以实现特征图的高层语义信息与底层位置信息融合,并在不同特征层上检测不同大小的目标,进而提高文本检测精度。She等[8]同时预测不同尺度的分割(segments)和连接(link),提出层内连接和跨层连接,可以检测任意长度、任意方向的文本。
基于分段的文本检测算法克服了基于坐标回归的文本算法人为设置候选框的弊端,可以更好地检测景区中的多尺寸文本和不规则文本,具有更好的鲁棒性。
在文字识别领域,Wang等[9]通过滑动窗口提取图片中的单个字符,但其文字识别效果依赖滑动窗口大小。Bai等[10]采用方向梯度直方图训练字符分类器,并取得较好的文字识别效果,但人工成本较高。Bissacco等[11]使用卷积神经网络(convolutional neural networks,CNN)和聚焦注意力网络(focusing attention network,FAN)对图片中的字符进行特征提取,同时,结合自然语言处理领域的N元模型进行字符识别,取得了比传统方法更高的识别效果,但其也存在适应性差等问题。Sutskever等[12]通过深度神经网络对图片进行方向梯度直方图特征提取,然后将特征图序列输入到循环神经网络(recurrent neural networks,RNN)以得到识别的文字序列。Shi等[13]通过空间变换网络结构对特殊字体以及其他非标准结构文字进行修正和格式化,然后进行标准的文字识别处理,此方法在一定程度上解决了特殊字体识别性能较差的问题,但该网络训练难度较大,格式化效果有限。Liu等[14]提出了一种字符感知神经网络对图像中的文本进行逐字校正和格式化,相比文献[13]取得了更好的校正效果,并提升了自然场景中图像文字识别准确率。目前,主流的文字识别网络是卷积循环神经网络(convolutional recurrent neural networks,CRNN)[15]使用卷积循环神经网络提取文本的序列特征,然后使用联结主义时间分类(connectionist temporal classification,CTC),将序列特征转录为具体字符。此类方法在识别长文本时计算成本较高,而且文本行形变会影响CTC的识别效果。
综上所述,虽然文本检测和识别技术取得了较大发展,但面向景区手写诗词的检测识别技术依然面临挑战,进一步提升景区手写诗词的检测和识别准确率需要语义上下文理解技术的支持。针对游客难以识别景区手写诗词的问题,本文设计了景区诗词检测网络(detection of poetry in scenic areas-network,DPSA-Net)和卷积循环聚合网络(convolutional recurrent aggregation network,CRA-Net)与知识图谱融合的景区手写诗词识别技术。DPSA-Net基于传统FPN进行了改进,有效解决了手写诗词中的小文本漏检的问题。CRA-Net将聚合交叉熵(aggregation cross-entropy,ACE)技术引入CRNN,提高了文本识别效率。该技术可帮助游客准确识别景区诗词,提升游客景区旅游体验,进而促进我国旅游业的发展。
1 基于FPN的手写诗词检测算法
本文针对景区中的手写诗词图像,设计了手写诗词检测算法。首先,使用DPSA-Net提取多层次融合的图像文本特征;其次,构建了基于单字符的文本区域关键点检测网络,将提取到的文本特征转化为位置信息;最后,经过多字符文本框链接算法的处理得到景区手写诗词图像的文本检测结果。
1.1 DPSA-Net
传统文本检测算法仅依赖深层神经网络的单一维度特征,易丢失手写诗词图像中的笔画、纹理和色彩等局部细节特征,导致小文本漏检,无法满足景区手写诗词检测的需求。针对此问题,本文设计了DPSA-Net,用于提取不同尺度的特征并将其融合。该网络基于FPN做出改进,增加了特征提取层,可用于检测更小的景区手写诗词文本,并增加了Def-Incept模块,用于检测扭曲诗词文本,增强不规则诗词的检测效果。DPSA-Net输出的特征图中既包含景区手写诗词图像中的文字笔画、纹理和色彩等表层信息,又包含语义、诗词文本结构等深层信息。
DPSA-Net结构如图1所示,不同尺度的特征分别通过一个自下而上和自上而下的路径进行融合。
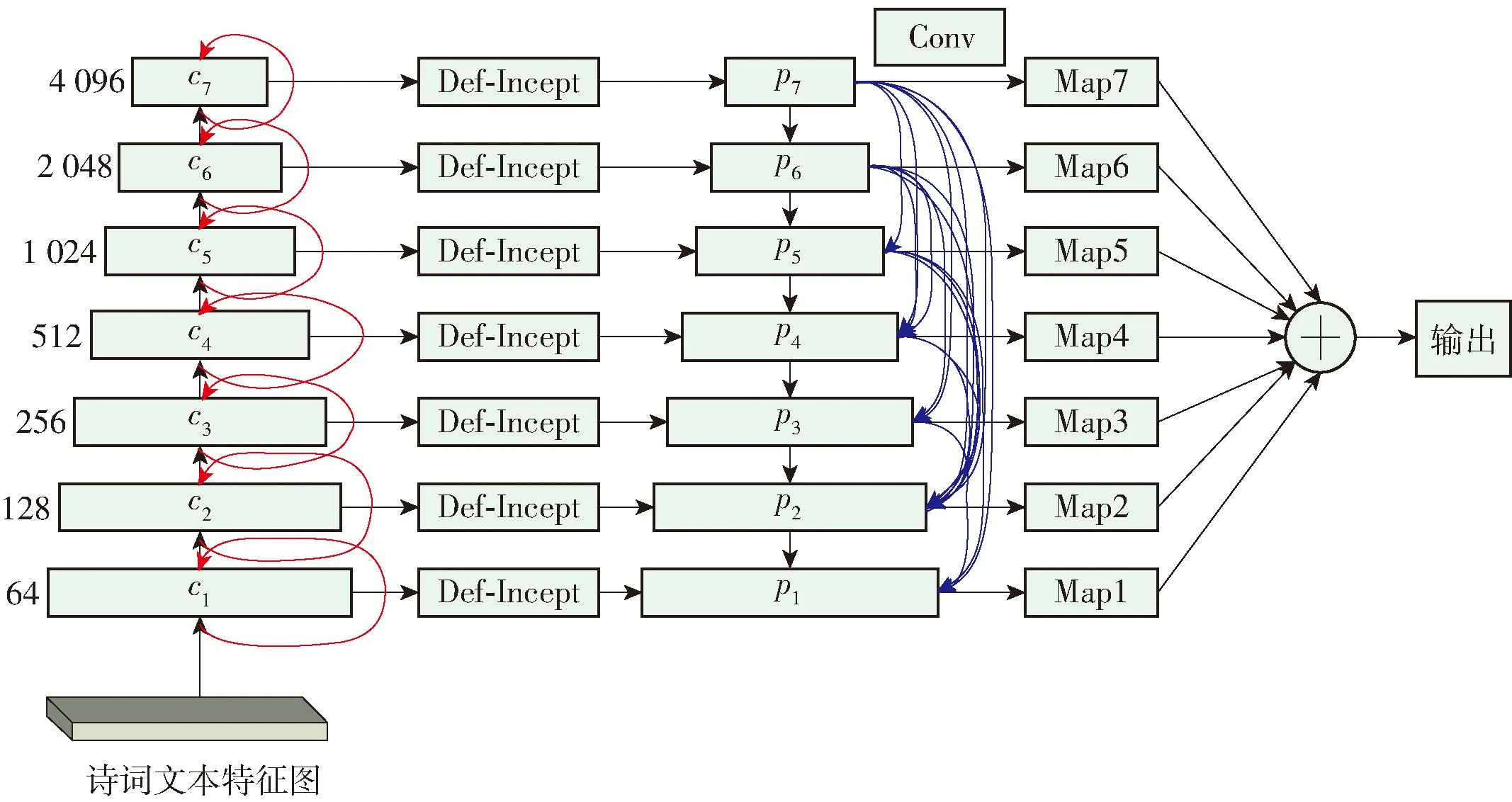
图1 DPSA-Net结构Fig.1 DPSA-Net structure
1) 自下而上路径:7层FPN中的每层均由卷积层、池化层、激活函数层和循环模块构成。通过该路径可得到7种尺度的特征图,不同尺度的特征图记录了图像在不同感受野下的纹理和文本特征。其中,层级越低的特征图包含的单个文字特征越多,层级越高的特征图包含的文字间关联关系的特征越多。
2) 自上而下路径:通过对特征图进行上采样,提供包含较强语义信息的特征图。层级越低的特征图融合的前面层级特征图的特征越多,那么其包含的语义特征就越多,因此,自上而下的通路能够更加全面地提取诗词中文字以及文字之间的关系特征。
此外,该网络在2个路径之间增加了可变形卷积模块Def-Incept,以提取图像中扭曲的诗词文本特征。其与自上而下通路融合,生成包含7个不同尺度的多层特征图{p1,p2,p3,p4,p5,p6,p7}。最后,7个不同尺度特征图通过一次卷积运算消除了形变导致的混杂效应,并减少了网络参数数量。
DPSA-Net能够将图像的浅层特征与深层特征进行融合,并将深层的语义信息加入浅层特征图中,有利于提高文字的检测效率和准确率。
1.2 单字符关键点标定算法
本文借鉴卷积姿势机[16]思想构建了基于单字符的文本区域关键点检测网络,将提取到的文本特征转化为位置信息。
设Z为图像中所有诗词文字字符位置坐标(u,v)的集合,Yk表示图像中每个关键点在景区手写诗词图像中的位置,文本区域关键点检测网络由多阶段检测器gt(·)组成。这些检测器经过训练,可以检测同一图像中不同感受野下每个关键点的位置。多阶段检测器可表示为
(1)
式中下标t∈{1,2,…,T}表示分类的各个阶段,每个阶段有各自的感受野,随着阶段增加感受野会逐步增大,进而能收集到更多的Yk周围的上下文信息。在每个感受野下,图像中的点z属于关键点Yk的置信度由检测器预测,即b(Yk=z)(z∈Z),其中b表示置信度。这些检测器具有相同的目标函数值,即ground truth。当t>1时,检测器将从图像位置z处采集的特征值xz和各关键点Yk在t-1时刻的预测值进行拼接,得到预测关键点的置信度高斯热力图,即
ψ(z)→xz,z∈Z
(2)
式中xz为图像卷积特征提取器在z位置提取的图像特征值。
当t=1时,检测器在第1阶段的输出公式为
(3)

(4)
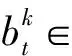
如果图像中的文本包含n个字符的关键点,则图像中发现的所有字符关键点的置信度高斯热力图表示为bt∈Rw×h×n。
对于图片中包含的每一个文本字符的关键点,都可以通过上述步骤生成相应的置信度高斯热力图。经过T个阶段,字符关键点位置的置信度最高,有
(5)
通过式(1)~(4)可确定每个字符的关键点在文字图片中的位置,而通过式(5)可确定初步的文字区域。本文字符关键点标定算法降低了深度神经网络识别文本区域的难度,增加了字符关键点预测的容错率。
1.3 多字符文本框链接算法
本文对基于连通区域分析的文本框标定方法进行了扩展,设计了一种多字符文本框链接算法。该算法以图像文本的字符关键点高斯热力图为基础,通过计算字符关键点之间的链接关系,得出最终的景区手写诗词图像文本检测框。首先,通过对景区手写诗词图像文本中每个字符关键点的高斯热力图进行分析计算,得出高斯热力图的最大直径,以最大直径为边长画出正方形框,用来标记单个字符的文本框位置,以避免高斯热力图形状有旋转角度导致文本框难以全部包含字符区域。其次,选取单字符文本框对角线长度的一半作为向外辐射圆半径r的初始值,然后不断增大辐射圆的半径至与其他字符文本框相遇,再将2个文本框的中心进行链接。若同时遇到2个字符文本框,则根据景区手写诗词文本通常为竖排的特征,选取该文本框垂直方向上相遇的文本框;若半径达到最大值则停止文本框链接。最后,将链接起来的文本框进行整合,得出最终的景区手写诗词文本检测区域的位置结果。多字符文本框链接算法具体过程如图2所示。

图2 多字符文本框链接算法示意Fig.2 Schematic of multi-character text box linking algorithm
本文本框标定算法只关注字符关键点之间的关系,并不关注整个文本实例,因此,本算法可同时用于长文本和短文本实例,具有良好的鲁棒性。
2 CRA-Net与知识图谱融合的景区手写诗词识别技术
目前,主流场景文本识别算法准确率完全依赖神经网络模型且无法有效利用诗词的语义信息和景区的相关信息。因此,本文融合CRA-Net和景区知识图谱,设计了一种景区手写诗词识别矫正框架(如图3所示),以充分利用诗词的语义信息和景区的相关信息提高景区手写诗词的识别准确率。

图3 知识图谱与CRA-Net融合的景区手写诗词识别框架Fig.3 Framework for recognition of handwritten poetry in scenic areas based on the fusion of knowledge graph and CRA-Net
该框架左侧通过位置等上下文信息检索景区知识图谱,获取对应的景区手写诗词集,同时右侧通过CRA-Net识别景区手写诗词,然后,将左右两侧网络输出的向量通过向量空间模型(vector space model,VSM)算法进行识别和校正,进而输出匹配度最高的结果。
2.1 CRA-Net架构
CRNN在识别长文本时计算成本较高,会导致游客等待时间长,进而失去耐心。针对此问题,本文设计了CRA-Net,该网络转录层使用效率较高的ACE算法对文本序列特征进行预测,以提高手写诗词的识别效率,进而提升游客体验。CRA-Net的架构如图4所示。
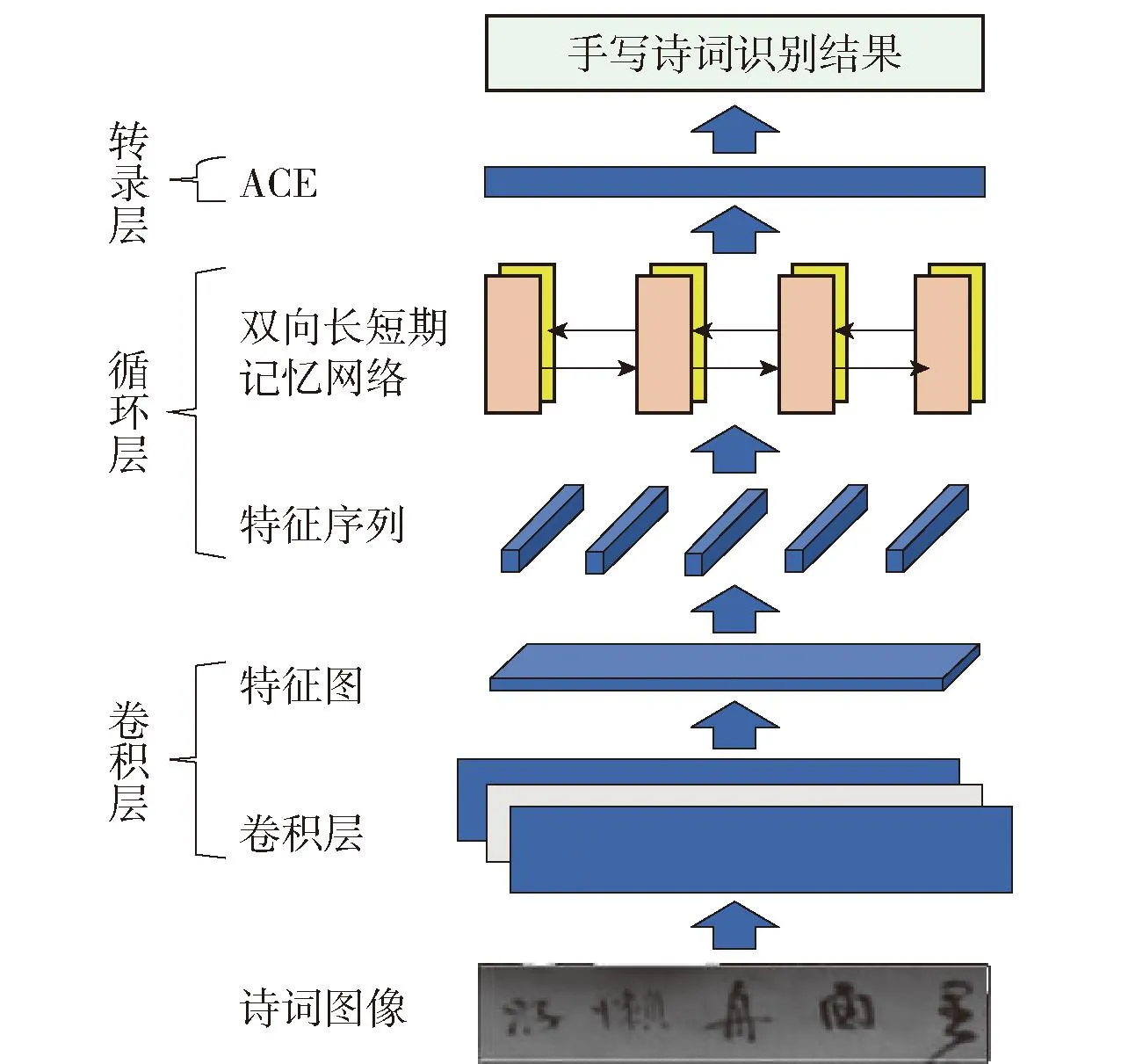
图4 CRA-Net架构Fig.4 CRA-Net structure
CRA-Net主要由卷积层、循环层和转录层构成。首先,将预处理之后的诗词文本图像输入到卷积层,提取到图像的卷积特征图;然后,将提取到的卷积特征图输入到循环网络层,在卷积特征的基础上进一步提取文字序列特征,该特征包含了诗词文本的上下文信息,能提高字符识别的准确率;最后,通过ACE算法依据文字间的序列特征提取文本。
ACE算法的目标是将增益值乘以图像中内容的高频部分,并对其进行重组,进而获得更好的图像文字识别效果。因此,计算图像内容中高频部分的增益系数是ACE算法的核心,本文通过计算图像高频部分的方差来计算增益值。
如果图像中的一个像素点用x(i,j)表示,则以(i,j)为中心、窗口大小为(2n+1)2的区域内的局部均值的计算公式为
(6)
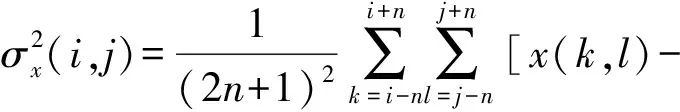
(7)
图像的高频部分局部均方差较大,导致其增益值较低,而图像平滑区的局部均方差较小,导致此时的增益值相对较高,这可能会放大噪声信号。引入增益值限制高频部分的局部方差能提高文本识别效果。ACE算法既可以适应长文本识别情况,又能够解决不定长序列带来的对齐问题,帮助解码景区手写诗词文本特征序列。
2.2 景区知识图谱构建
首先,通过人工整理与网络爬虫等方式对景区手写诗词数据进行采集,其中包括景区中景点位置经纬度信息、所属地点信息以及该景点所包含的诗词文本信息和诗词相关属性信息(诗词作者、诗词朝代和诗词文本方向等),将采集到的半结构化数据存储在可扩展标记语言(extensible markup language,XML)文件中,结构化数据存储在逗号分隔值(comma-separated values,CSV)文件中。
其次,利用正则表达式、Pandas以及Xpath对采集到的景区手写诗词知识进行数据清洗,并利用Pandas对CSV文件中的缺省数据进行过滤,通过Xpath路径查询语言对XML文件中的数据进行筛选,结合正则表达式,将数据处理为结构化数据。本文景区知识图谱包含6类实体:省份、城市、景区、景点、诗词、作者。每个实体类别所含关键属性描述字段如表1所示。
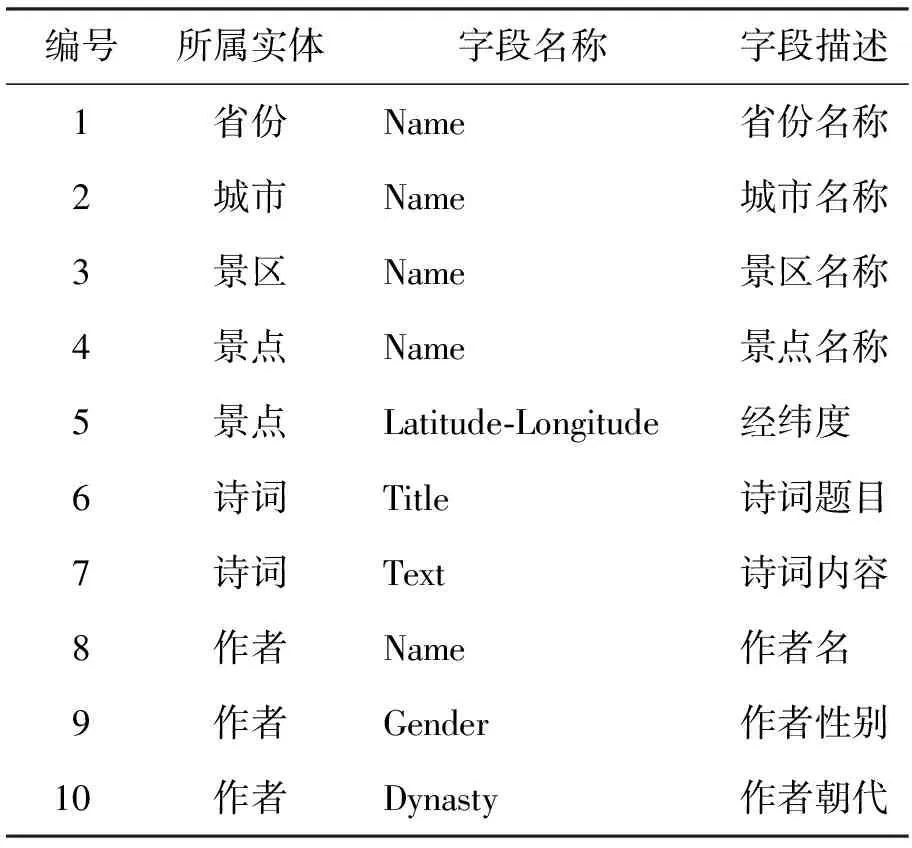
表1 各实体所含信息示例
然后,采用三元组法的方式表征实体之间的关系,将各类实体联接,如:“又当投笔请缨时,别妇抛雏断藕丝”,属于,郭沫若。
最后,采用主流的Neo4j图数据库对知识融合后的景区手写诗词实体数据与关联数据进行存储,将知识实体作为节点、知识实体之间的联系作为关系,组建景区知识图谱。Neo4j图数据库具有较高的搜索性能,能够满足本文对景区手写诗词相关信息的高效查询。
2.3 基于知识图谱的景区手写诗词匹配
基于构建好的景区知识图谱,将其与CRA-Net融合,从而实现景区手写诗词的识别与矫正。具体的方法如下。
1) 通过景区的地理位置信息检索景区知识图谱,得到搜索结果集关键字矩阵Sn×m以及景区手写诗词文本图像初步识别结果矩阵E1×m,计算公式为
Sn×m=f(C)
(8)
E1×m=f(x)
(9)
式中:x为景区手写诗词文本图像的初步识别结果;C为景区知识图谱搜索结果集;f(·)为分词算法;n为搜索结果集中的实体数量;m为处理后的关键字数量。
2) 利用词向量分布模型对所得到的矩阵中的实体关键字进行计算,并依据
(10)
计算每个实体的关键字向量。式中:e表示矩阵中的单个样本;g(·)表示产生词向量的分布模型函数;i表示实体关键字的索引位置。
将诗词文本向量ve按照
(11)
进行归一化处理,得到最终文本向量v。
将CRA-Net输出的文本也进行上述处理,得到最终的景区手写诗词文本图像初步识别结果向量q。
3) 采用VSM算法计算向量q与C中每个实体的v的文本相似程度。
在使用VSM处理文本相似性时,将每个词作为一个维度,将每个词的频率作为其值,从而形成一个词向量。利用文本词频建立了一个i维空间图,并按照
(12)
计算q与v中文本的相似性。2个词向量s1、s2之间的角度越小,相关度越高。
最后,按照
(13)
取景区手写诗词初步识别结果向量q与C中相似度最高的诗词文本Result 进行输出,作为景区手写诗词图像文本识别结果。式中:VSM(·)表示向量空间模型计算函数;Vi表示搜索结果向量集。
3 实验结果分析
为验证本文景区手写诗词识别矫正框架的有效性,采集了景区手写诗词图像数据集,并以此为基础分别对本文的景区手写诗词检测算法、识别算法进行了实验验证。该数据集包含2 071张景区手写诗词图像,其中,训练集1 243张、验证集414张、测试集414张。此外,对每张图像的文本区域位置、文本内容、景点经纬度、诗词作者等信息都进行了人工标注。
3.1 景区手写诗词检测算法验证
本文在显卡为NVIDIA Titan X、处理器为 Intel Xeon ES、操作系统为Ubuntu 16.04的环境下进行实验。同时,本文采用精确率、召回率及它们的加权调和平均F1作为景区手写诗词图像文本检测效果的评价标准。
1) 特征提取效果分析
本文比较了一些使用广泛的特征提取模型,如VGG16[17]、GoogleNet[18]和BertNet[19]等,验证了本文算法DPSA-Net在特征提取方面的优势。实验数据集是景区手写诗词数据集,表2为详细的对比结果。可以看出,在景区手写诗词数据集上,DPSA-Net与其他算法相比在提取文本特征精确率上有明显的提高。
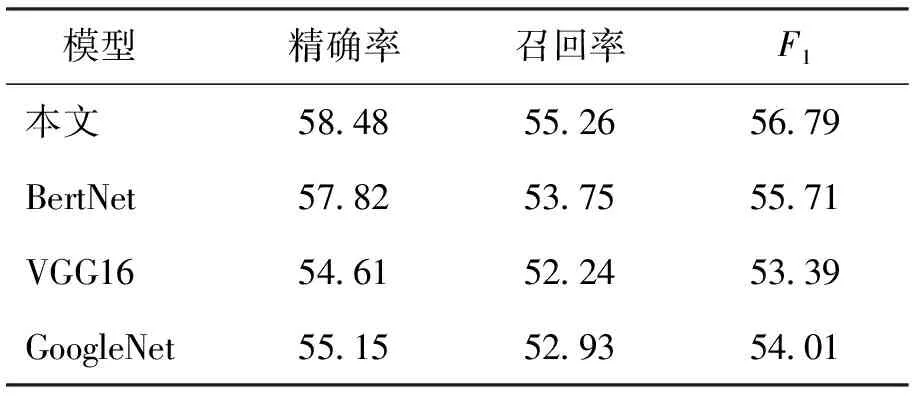
表2 不同特征提取网络文本检测结果对比
2) 文本检测算法效果对比
本文选择具有代表性的场景文本检测算法——分段链接(segment linking,SegLink[8])、单步文本检测(single shot text detector,SSTD[20])、EAST[21]和渐进式尺度扩展网络(progressive scale expansion network,PSENet[22])进行对比实验,对比结果如表3所示。实验结果表明,本文算法将多尺度特征融合,可有效识别出景区中各种风格的手写诗词,同时可有效避免小文本漏检,取得了更好的检测结果。本文算法的精确率为61.28%、召回率为57.93%、F1为59.55%。
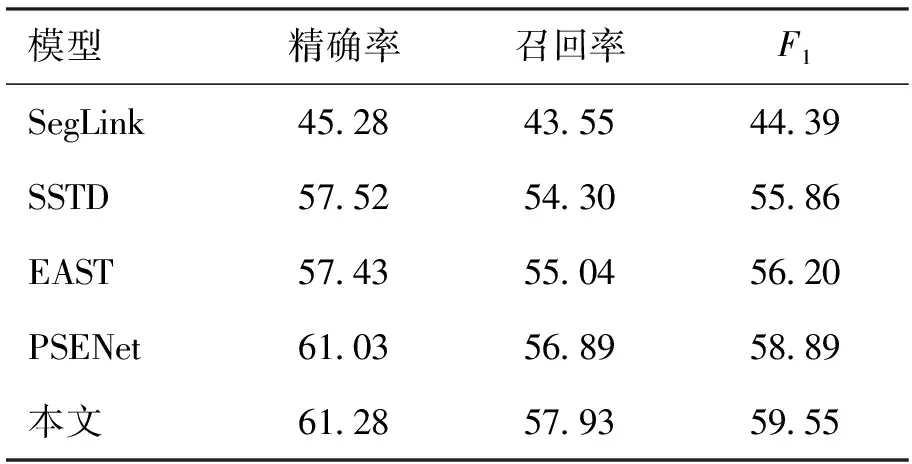
表3 不同文本检测模型的文本识别结果对比
此外,课题组在自然场景拍摄了多幅诗词文字图像,如图5所示。这些手写诗词图像背景多样,字体风格和文本尺寸迥异。本文景区手写诗词文本检测算法的检测结果为红色方框内的文字。其中,文本框的位置信息由所包含的文本区域位置信息决定,目标是在不增加不必要背景的情况下,尽可能准确地标记景区手写诗词文字的位置信息。图5结果证明了提出的文本检测算法能够适应不同场景,具有良好的鲁棒性。

图5 景区手写诗词文本检测算法的测试示例Fig.5 Example of text detection algorithm for handwritten poetry in scenic areas
3.2 景区手写诗词识别与矫正技术验证
本文为了验证ACE算法在字符解码识别方面的优点,对比了一些常用的字符识别器模型,例如:CTC算法和注意力机制算法Attention。实验数据集为景区手写诗词数据集,详细对比结果如表4所示。通过对实验数据分析可知,ACE算法与CTC算法都具有较高的识别准确率,但ACE算法的耗时却比CTC算法更少。Attention虽然识别准确率较低,但在耗时方面却处于中等水平。总体来说,ACE算法能够使文本识别算法具有很好的识别效果且耗时较少。
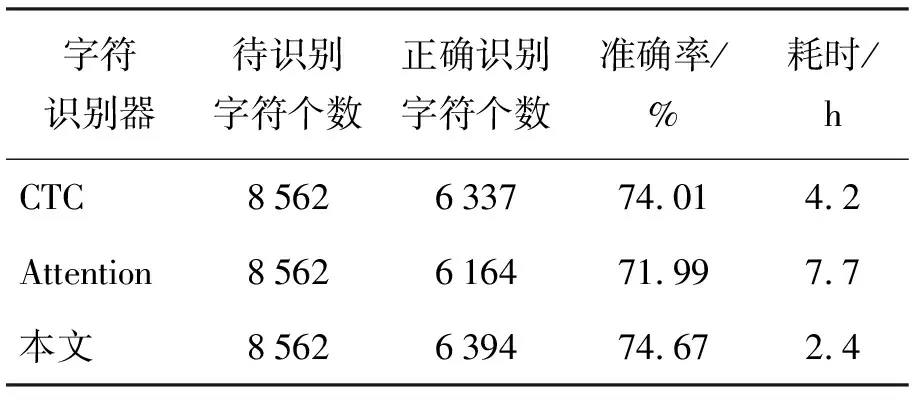
表4 不同字符识别器文本识别结果对比
目前,文本识别算法的评价标准一般采用VSM、词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)模型以及编辑距离等算法。本文手写诗词识别算法基于上下文进行识别,因此,本文采用统计字符识别准确率的方法作为算法评价标准。其计算方法为
(14)
式中:A表示准确率;I表示完全识别正确的字符总数;N表示测试中的字符总数。
本文选取主流的文字识别算法CRNN[15]、FAN[23]及新的展示、参加、阅读(show,attend and read,SAR)算法[24]和Master[25]算法与本文算法CRA-Net进行实验对比,实验数据集为景区手写诗词数据集,详细对比结果如表5所示。

表5 不同字符识别器的文本识别结果对比
实验结果表明,本文算法在景区手写诗词数据集上的识别准确率达到74.67%,与主流的CRNN和FAN相比,识别准确率均有提高,但比SAR、Master的识别准确率低。本算法使用ACE算法进行转录,在提高景区手写诗词识别准确率的同时确保了识别效率(耗时为2.4 h)。与其他算法相比,本文提出的CRA-Net在执行效率方面有比较明显的优势。
此外,本文分别测试了单纯基于CRA-Net的识别准确率和CRA-Net与景区知识图谱融合的手写诗词识别算法的识别准确率,矫正所用的景区知识图谱采用本文2.2节所述方法构建,涉及的景区有蔡元培故居、故宫、极乐寺、景山公园和颐和园,对比结果如表6所示。

表6 诗词矫正技术对文本识别结果的影响
由表6的实验结果可知,本文采用基于知识图谱的手写诗词矫正技术,使文本算法的识别准确率提升了4.37%。
4 结论
1) 本文针对游客难以完整识别景区手写诗词的问题,构造了DPSA-Net以提取手写诗词图像的多尺度特征,并引入字符关键点标定算法和多字符文本框链接算法来实现文字的准确定位。
2) 设计了CRA-Net,结合CNN和双向长短期记忆网络提取手写诗词图像的序列特征,并通过ACE算法实现特征向文本的转换。
3) 结合景区知识图谱对CRA-Net输出的景区手写诗词文本进行校正,进而提高景区手写诗词的识别准确率。景区手写诗词数据集的实验结果,证明了本文所提出技术的有效性。
4) 下一步,将增加知识图谱中诗词间的关联度信息,通过给游客推送所识别诗词的相关知识信息,帮助游客更加深入地了解景区手写诗词,进一步提升游客的旅游体验。
