对抗与蒸馏耦合的高光谱遥感域自适应分类方法
2024-03-09于纯妍徐铭阳宋梅萍胡亚斌张建祎
于纯妍,徐铭阳,宋梅萍,胡亚斌,张建祎,4
1.大连海事大学 信息科学技术学院 高光谱遥感中心,大连 116026;2.自然资源部第一海洋研究所,青岛 266061;3.自然资源部海洋遥测技术创新中心,青岛 266061;4.马里兰大学 计算机科学与电气工程系 遥感信号与图像处理实验室,马里兰州 美国 21250
1 引言
高光谱遥感探测技术利用可见光至中红外范围内的数百个连续波段对观测地物成像,其影像特有的精细化光谱描述能力为地物识别提供了不可比拟的优势。高光谱图像HSI(Hyperspectral Image)分类是遥感智能解译领域中的重要应用之一(杜培军 等,2016),其基本任务是对HSI 中的每个像元赋以唯一类别归属。随着星载与机载高光谱成像仪的发展,高光谱遥感图像分类HSIC(Hyperspectral Image Classification)技术为城市建设(Ghamisi等,2015)、海洋监测(Wang 等,2018)、智慧农业(赵庆展 等,2021)等领域注入了新的行业发展驱动力。
近年来,依靠深度卷积神经网络CNN(Convolutional Neural Network)的强大特征表达能力,基于监督式的CNN 分类模式发展为HSIC 的主流方法(Lu等,2017)。该模式取得广泛成功的因素取决于训练大规模标注样本,可以得到具有较强判别性的分类子空间(薛朝辉 等,2022)。然而,由于HSI数据固有的光谱复杂性,使得样本标注工作不仅费时费力,而且还需要具备领域专业知识的专家进行辅助(Lu等,2020)。为了降低对标注样本的依赖,利用迁移学习进行高光谱遥感跨场景分类逐渐发展起来(Gong 等,2022)。无监督域自适应UDA(Unsupervised Domain Adaption)作为迁移学习的一个重要分支,其实现思想是通过将有标签的源域数据中提取到的知识转移至含有无标注样本的目标域场景,从而实现目标域场景的无监督分类。早期,研究者通过寻找降低域间差异的公共特征表示实现高光谱遥感域自适应分类。Xia等(2017)提出利用集成学习与主成分分析相结合寻找双域的公共特征表示,实现样本与特征的自适应;此外,最大平均差异MMD(Maximum Mean Discrepancy)在UDA 中被广泛使用,用来度量两个不同但相关的随机变量分布的距离,通过缩小双域间的距离完成域自适应(Pan 等,2011)。Shen 和Ma(2019)提出增强的跨域极限学习机算法,利用MMD 使高光谱目标域和变换的源域数据在极限学习机网络中更好地共享输出权值。
生成对抗网络GAN(Generative Adversarial Networks)(Goodfellow 等,2014)利用生成器与鉴别器迭代训练,为域自适应分类领域提供了新的特征对齐模式(张健 等,2022)。依照生成器使鉴别器无法正确地判断出样本来源的思路,Zhan 等(2018)提出了首个针对HSIC的对抗式半监督框架。Liu 等(2021)选用多域鉴别器与特征提取器完成对抗训练,并施加MMD减小高光谱双域间的差异。Ma 等(2021)基于变分自动编码器和双分类器结构,提出一种基于对抗的域自适应分类模型,针对域中的局部类别差异进行了优化。Yu 等(2022)提出一种基于内容对齐的UDA 框架,利用对抗实现局部分布的高光谱遥感类对齐以获得更好的特征表示。Fang 等(2022)提出了一种将域自适应与置信学习相结合的对抗式新框架,在实现HSIC特征对齐的同时逐渐增加目标域中高置信标签的比例,以提高分类精度。
为了使浅层小型网络可以同深层大型网络一样学习大量的知识,Hinton等(2015)提出利用知识蒸馏KD(Knowledge Distillation)完成网络间知识的迁移。根据知识的迁移方式不同,KD可分为离线蒸馏(Hinton 等,2015)、在线蒸馏(Zhang 等,2018)和自蒸馏(Yun等,2020)3种类型。如今,已有一些学者将KD 与HSIC 相结合,用来提高模型的分类精度和速度。Cao 等(2020)将知识蒸馏与深度随机森林相结合,将由原始训练样本和大型网络生成的虚拟样本结合作为浅层小型网络的新训练集。Yue 等(2022)提出一种基于自适应KD 的自监督学习方法,通过空间光谱相似性测量生成的自适应标签完成HSIC。上述方法仅利用KD降低模型复杂度,或利用软标签提高模型最终的分类精度,并未考虑KD 在HSI 域间知识迁移过程中的作用。
综上,现有的高光谱域自适应分类方法在保证双域特征对齐的条件下取得了较好的分类精度(Hu 等,2020),然而仍存在源域信息未充分提炼并迁移至目标域这一关键问题。对此,本文提出一种基于蒸馏与对抗耦合的高光谱遥感无监督域自适应分类方法(UDAACD),利用对抗与蒸馏耦合机制相互补充、相互促进,使源域有监督信息能够充分迁移至目标域场景,提升高光谱目标域场景的无监督分类精度。
2 本文方法
2.1 整体框架
本文提出的高光谱遥感域自适应分类方法(UDAACD)的模型结构如图1 所示。其中,双域特征提取模块使用注意力密集网络充分提取源域与目标域内HSI样本的判别性特征;类间自蒸馏约束模块通过在同类别样本间添加自蒸馏约束匹配预测分布,以充分提炼出源域的有监督知识;对抗-蒸馏式域特征对齐模块利用双分类器产生的预测分歧与生成器进行对抗,同时融入经过“蒸馏归一化”(T-softmax)操作得到的蒸馏知识,从而提升知识在高光谱双域间的迁移能力。以下章节对各模块及实现细节进行详细阐述。

图1 UDAACD模型框架图Fig.1 Overview of hyperspectral cross-scene classification with the UDAACD
2.2 高光谱遥感分类的对抗自适应框架
2.2.1 双域特征提取模块
设HSI 源域数据集为DS,样本集表示为{XS,YS}={(xS1,yS1),(xS2,yS2),…,(xS,yS)},其中xS表示样本特征,yS表示类别标签;目标域数据集为DT,其样本集表示为{XT}={xT1,xT2,…,xT},其中xT表示样本特征。针对HSI数据的“空谱合一”特点(刘雪峰 等,2022),本文构建了一个轻量的双注意力密集网络充分提取HSI 中的判别性特征。该特征提取网络记作G,参数为θG,其网络结构如图2所示。具体而言,该网络由两个不同核大小的卷积层与激活层组成的密集块(Denseblock)构成;在每一个Denseblock 后添加了CBAM(Convolutional Block Attention Module)(Woo 等,2018)、Transition 层,从通道和空间两个维度上提取注意力特征信息并通过减少特征映射数量以降低网络模型深度。
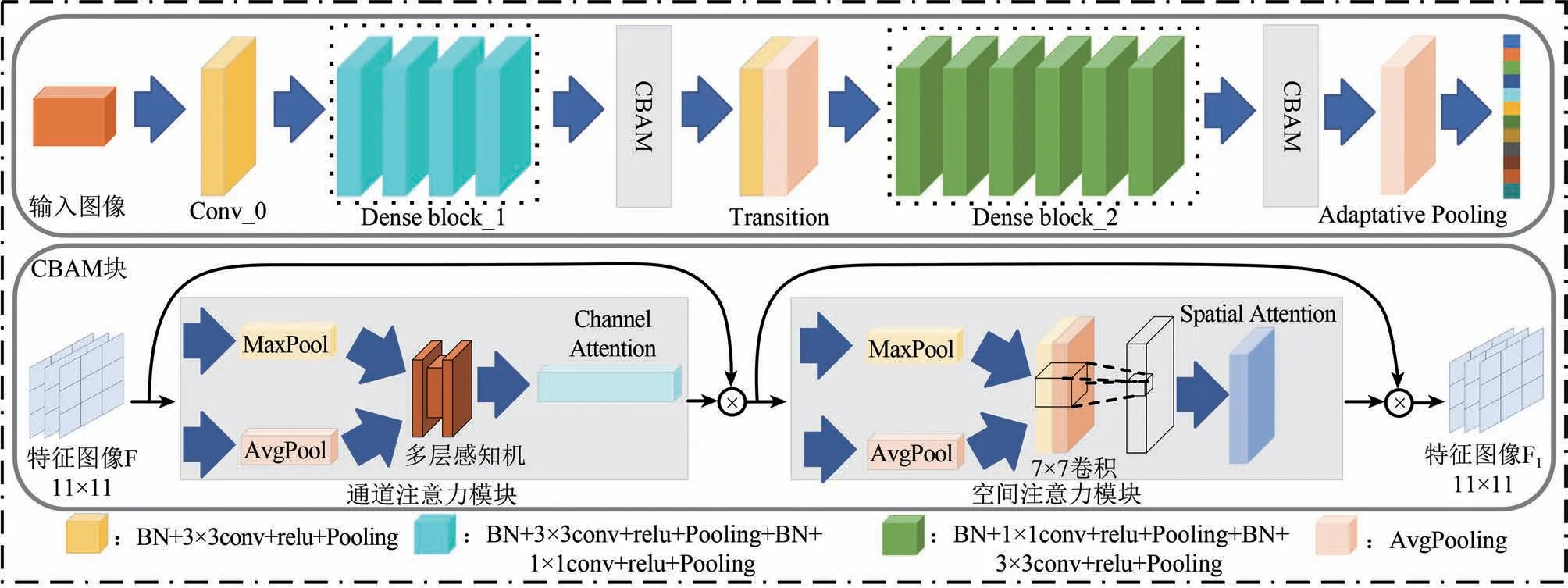
图2 特征提取网络G结构图Fig.2 Structure of feature extraction network G
DenseBlock 作为G的核心模块,每一层输入均为前面所有层的特征映射之和,并以前馈方式连接所有先前层的输出,减小梯度消失的可能性。其主要采用归一化(BN),激活(Relu),池化(Pooling)及卷积(Conv)等非线性转换操作提取特征。同时,为了减小Denseblock输出的特征映射数量,本模块在两个Denseblock块间添加Transition层进行数据降维,其能够将前一个Denseblock的输出特征通道缩小γ倍,γ∈(0,1],从而起到压缩模型的作用。
为了强调HSI中通道和空间两个主要维度上的重要特征,在每一个Denseblock 后添加了CBAM 注意力模块。该模块通过最大池化(MPool)与平均池化(APool)相结合的注意力机制提取输出特征的显著信息及位置编码信息。首先,利用特征间的通道关系生成通道注意力图像:对不同通道的特征映射做池化操作后,将结果输入至含一个隐藏层的多层感知机MLP(Multilayer Perceptron),利用Sigmoid 函数激活获得注意力图像;接着,利用特征间的空间关系生成空间注意力图像:沿相同通道方向对不同特征图的同一个位置做池化操作,将结果输入至一个由7×7卷积和Sigmoid函数结合的模块进行拼接和激活,从而获得一个二维注意力图像。
2.2.2 双分类器结构
为了提升源域及目标域的样本对齐质量,本文采用双分类器结构(Saito 等,2018)对HSI 进行类别归属判定,并直接充当鉴别器身份与生成器G 完成对抗训练。相较于原始的生成器—鉴别器—单分类器模式,生成器—双分类器对抗自适应网络一方面通过最大化两个分类器的分歧检测出远离源域的目标域样本;另一方面,通过最小化分歧使得特征生成器在分类器边界附近生成目标域特征。在实现HSI源域和目标域样本同步训练的同时缩小分歧样本的数目,使得域间的分类特征充分对齐。本文的两个分类器分别记为C1、C2,二者均由3 个线形层组成的MLP 构成。随机初始化后双分类器的网络参数分别为。
2.3 对抗—蒸馏耦合的高光谱域自适应分类
2.3.1 类间自蒸馏约束模块
源域内的有监督信息对于高光谱UDA 极为重要,为克服HSI的“同物异谱”现象对模型分类结果带来的干扰,提高源域分类网络的泛化能力及HSI域中的特征表达,本节设计了类间自蒸馏约束模块,其结构示意图如图3所示。该模块利用蒸馏损失在同类别随机训练样本上匹配预测分布,在减小类内差异的同时,防止网络进行过度预测。

图3 类间自蒸馏约束模块示意图Fig.3 Diagram of class-wised self-distillation model
源域样本xS输入至任意分类器后,经MLP 输出并进行“蒸馏归一化”(T-softmax)操作,可以得到输入样本图像的软标签P(y|xS;θ,T),相较于未加入超参数T的Softmax 函数,软标签蕴含更加丰富的分布知识。其计算公式为
式中,fy表示真实类概率,fk表示分类器输出,θ表示输入网络参数,K为总类别数,T为温度超参数。
首先,将HSI源域样本集{XS,YS}切割为两个相等的子样本集,分别记为{XS1,YS1},{XS2,YS2};接着,对生成器G、分类器C1、C2的参数进行随机初始化,将样本xS1∈{XS1,YS1}经G 特征提取后分别输入C1、C2;同时,在{XS2,YS2}随机采样另一个与xS1标签相同的样本xS2;最后,利用Kullback-Leibler 散度匹配样本xS1、xS2的预测分布。本模块中使用的类间自蒸馏损失函数定义为
式中,KL(·)表示Kullback-Leibler散度,i∈{1,2}。
此外,在使两个标签一致的样本预测分布靠近的同时,还应保证样本进行自我知识提炼,防止样本xS2学习到来自xS1中错误的知识。为此,定义如下损失函数:
式中,LE(·,·)表示交叉熵损失函数,α为损失权重,i∈{1,2}。
综上所述,本模块中生成器G 及分类器C1、C2在HSI源域上训练时使用的损失函数为
2.3.2 对抗—蒸馏式域特征对齐模块
为了保障高光谱遥感双域在特征对齐时能够将源知识充分提炼并传递到目标域场景,本方法设计对抗—蒸馏式域特征对齐模块。该模块通过处理双分类器产生的样本预测分歧分两阶段完成分类器、生成器的对抗训练过程。其中,样本预测分歧定义为
首先,模型进行双分类器的训练过程:当源域HSI训练样本xS输入模块时,因源域含有丰富的标签,双分类器并未产生预测分歧,利用交叉熵损失函数LE直接训练双分类器;当目标域内无标签HSI训练样本xT输入模块时,使用条件熵增强对其标签的预测,定义条件熵损失函数为
式中,i∈{1,2}。
因源域内样本含有丰富的标签,在源域上训练的网络可能存在一些对HSI目标域场景无监督分类有价值的软标签,利用知识蒸馏可以将这些知识充分提炼并传递给在目标域上训练的网络。本模块将在源域及目标域分类模型分别视为两个不同的网络,且目标域分类模型在获取源域知识的同时须保证自我知识的不断提炼。定义双分类器训练过程中的蒸馏损失为
进一步地,HSI目标域中存在部分与源域特征差异较大的样本,为了降低分歧样本的影响,一方面,需要训练分类器使预测分歧最大化,为其后的训练过程能够快速消除预测分歧奠定基础。第一阶段训练双分类器的损失函数定义为
另一方面,生成器利用目标域样本训练集及第一阶段最大化的分歧损失,针对两个分类器分别提取不同的重要特征表示,进而最小化预测分歧。第二阶段训练生成器的损失函数定义为
在两个阶段不断对抗的训练过程中,HSI样本的预测分歧逐渐消失,同时蒸馏知识的加入使得对抗过程中的知识不断从源域迁移至目标域场景。当对抗训练完成时,意味着已经实现高光谱遥感双域间的特征对齐。
2.4 本文方法的具体分类步骤
UDAACD算法模型训练过程描述如下:

3 实验及结果分析
3.1 数据集简介
本文利用4个流行的高光谱数据集对所提出方法的分类效果进行验证与分析。
第一组数据集为PaviaU(Pavia University)和PaviaC(Pavia Center)。两个数据集均由反射光学系统成像光谱仪(ROSIS)于2002 年在意大利北部帕维亚市收集获得,其空间分辨率为1.3 m,有9 种地物类别。消除噪声后,PaviaU 数据集图像大小为610×34,含有103个波段,波长范围为0.43—0.86 μm,共有35074个样本,以波段(34,97,85)生成的伪彩色图像如图4(a)所示,真实地物分布图像如图4(b)所示;PaviaC 数据集图像大小为1096×492,波段数目为102,波长范围为0.43—0.86 μm,共有39032 个样本。为了确保两个数据集的光谱波段数相同,实验中移除了PaviaU 数据集的最后一个波段,并选取了两个数据集公共的7 个类别进行实验分析。以波段(34,97,85)生成的PaviaC 伪彩色图像如图4(c)所示,真实地物分布图像如图4(d)所示。
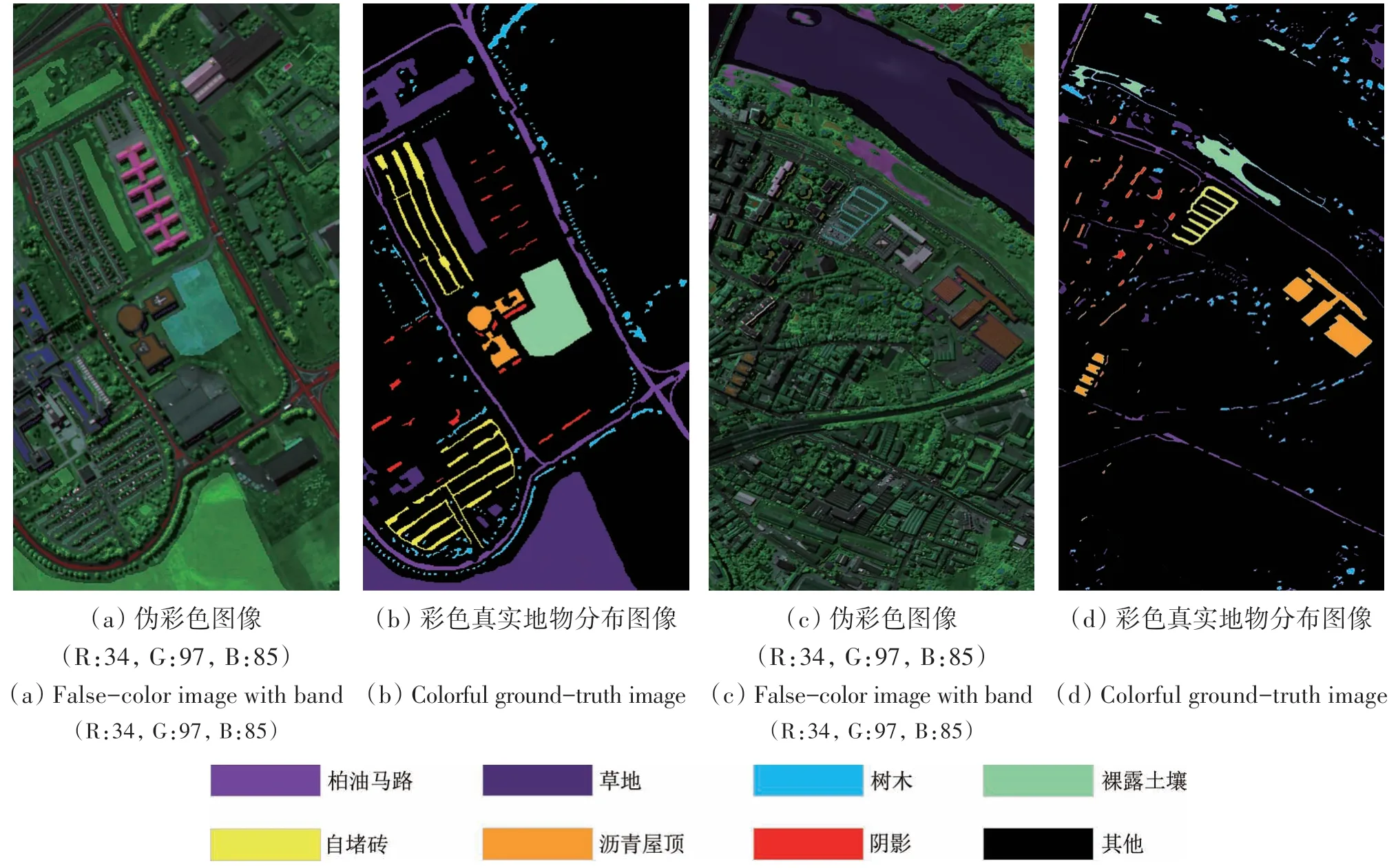
图4 PaviaU和PaviaC数据集Fig.4 PaviaU and PaviaC dataset
第二组数据集为Houston 2013(Hou13)和Houston 2018(Hou18)。该组数据集是由美国国家机载激光测绘中心(NCALM)于2012年及2017年在休斯顿大学附近采集获得。Hou13数据集由ITRES CASI 1500 光谱仪拍摄,包含349 像素×1905 个像素和144 个波段,空间分辨率为2.5 m,含有15 个地物类别和2530 个样本。以波段(17,47,29)生成的伪彩色图像如图5(a)所示,真实分布图像如图5(b)所示。Hou18 数据集的采集光谱仪为ITRES CASI 1500,波段数目只有48。该数据集的分辨率为209像素×955像素,空间分辨率为1 m,包括20 个地物类别和53200 个样本。以波段(17,47,29)生成的伪彩色图像如图5(c)所示,真实分布图像如图5(d)所示。

图5 Hou13和Hou18数据集Fig.5 Hou13 and Hou18 dataset
3.2 实验设置
3.2.1 实验环境与评价标准
本实验在配备64 位Windows 10 操作系统,NVIDIA GeForce FTX 1650 GPU,12 GB 显存的PC机上进行。实验以PyCharm 为开发环境,Pytorch 3.9 Cuda11.3-cudnn8 1.10.1 为开发框架,Python 3.9 为编程语言。采用总体准确度(OA)、平均准确度(AA)、一致性检验系数(Kappa)、运行时间(Time)作为客观标准来评估每种方法的性能。其中,OA将视为模型分类精度。
3.2.2 对比方法与参数设置
为了评估UDAACD 的分类效果,本文选择了6 种高光谱图像分类的UDA 方法进行对比实验。其中包括:基于梯度反转层的DANN(Gani 等,2016)、利用Wasserstein距离减小域差异的WDGRL(Shen 等,2018)、利用对抗性判别的ADDA(Tzeng等,2017)、基于最大分类器差异的MCDDA(Saito等,2018)、基于置信学习的CLDA(Fang等,2022)及针对内容对齐的UDACA(Yu等,2022)。
为了使实验结果更具有说服力,本文设置对比方法的参数基本一致。在全部对比实验中,样本尺寸大小为11×11,Batch size 设置为16,利用Adam 作为训练优化器,训练样本数目为50。对于WDGRL 和ADDA 方法,特征提取网络使用ResNet18,二者使用的鉴别器结构一致,并且使用了同本文模型相同结构的分类器,学习率均设置为0.0001,两种方法在源域训练200 次,在目标域训练1000 次;对于DANN、UDACA,二者使用与本文模型相同的密集网络特征提取器,其他设置与ADDA 相同;对于MCDDA 与CLDA,设置与本文方法一致的1∶4 分类器—生成器对抗训练比例,训练迭代次数为1000,并均选用C2分类器的输出结果作为最终判定;对于本文模型,设置类间自蒸馏温度T为4,域自适应蒸馏温度t为1.5,其他设置与MCDDA 相同。本文采用的所有对比方法及提出的UDAACD 算法的时间复杂度均为O(n2)。
3.3 对比方法实验结果及分析
第1组高光谱域自适应分类实验的源域为有标注样本的PaviaU 数据集,目标域为无标注样本的PaviaC数据集。各对比方法在PaviaC数据集上分类得到的OA、AA、Kappa 系数及运行时间如表1所示,分类结果图如图6所示。UDAACD 在PaviaC场景上无监督分类得到的OA 为91.75%,AA 为92.11%,Kappa系数为0.9,均优于其他UDA方法,并在大多数类别上取得了较好的精度。WDGRL 和ADDA 方法得到的OA 值分别为74.01%和73.1%,使用同UDAACD 相同特征提取网络的DANN 方法OA值为78.39%,MCDDA方法精度在79.97%左右,较CLDA、UDACA 等方法存在一定差距,说明在保证预测分歧样本对齐的前提下,添加正则化约束以及样本优化对HSI域自适应分类结果有一定的提高;同样使用双分类器进行对抗的CLDA、使用密集网络对抗并强调类间差异的UDACA 的OA 值分别为88.02%、90.24%,二者与UDAACD的OA值相比略低,体现出类间的自蒸馏和域间的知识蒸馏在对抗自适应过程中的优异效果。

表1 不同方法在PaviaC数据集上的分类结果(PaviaU->PaviaC)Table 1 Classification performance from the results with all the compared methods of the PaviaC(PaviaU->PaviaC)

图6 不同方法在PaviaC数据集上的分类结果图(PaviaU->PaviaC)Fig.6 Classification maps provided by different approaches on the Pavia Center(PaviaU->PaviaC)
第2组实验的源域使用PaviaC 数据集,目标域使用PaviaU 数据集。各对比方法在PaviaU 数据集上分类得到的OA、AA、Kappa 系数及运行时间如表2 所示,分类结果图如图7 所示。UDAACD 在PaviaU场景上无监督分类得到的OA为74.41%,AA为80.57%,Kappa系数为0.66,均优于其他UDA方法;UDAACD对第7类地物的预测准确率最高,而UDACA 方法在第1、3 及第4 类地物上取得了最高的精度,体现出UDACA 针对类间差异对齐的有效性。使用含注意力模块特征提取网络的DANN 在本组实验中精度为70.82%,远超于使用普通网络的WDGRL 及ADDA,说明CBAM 注意力模块在高光谱图像特征提取的有效性。

表2 不同方法在PaviaU数据集上的分类结果(PaviaC->PaviaU)Table 2 Classification performance from the results with all the compared methods of the PaviaU(PaviaC->PaviaU)
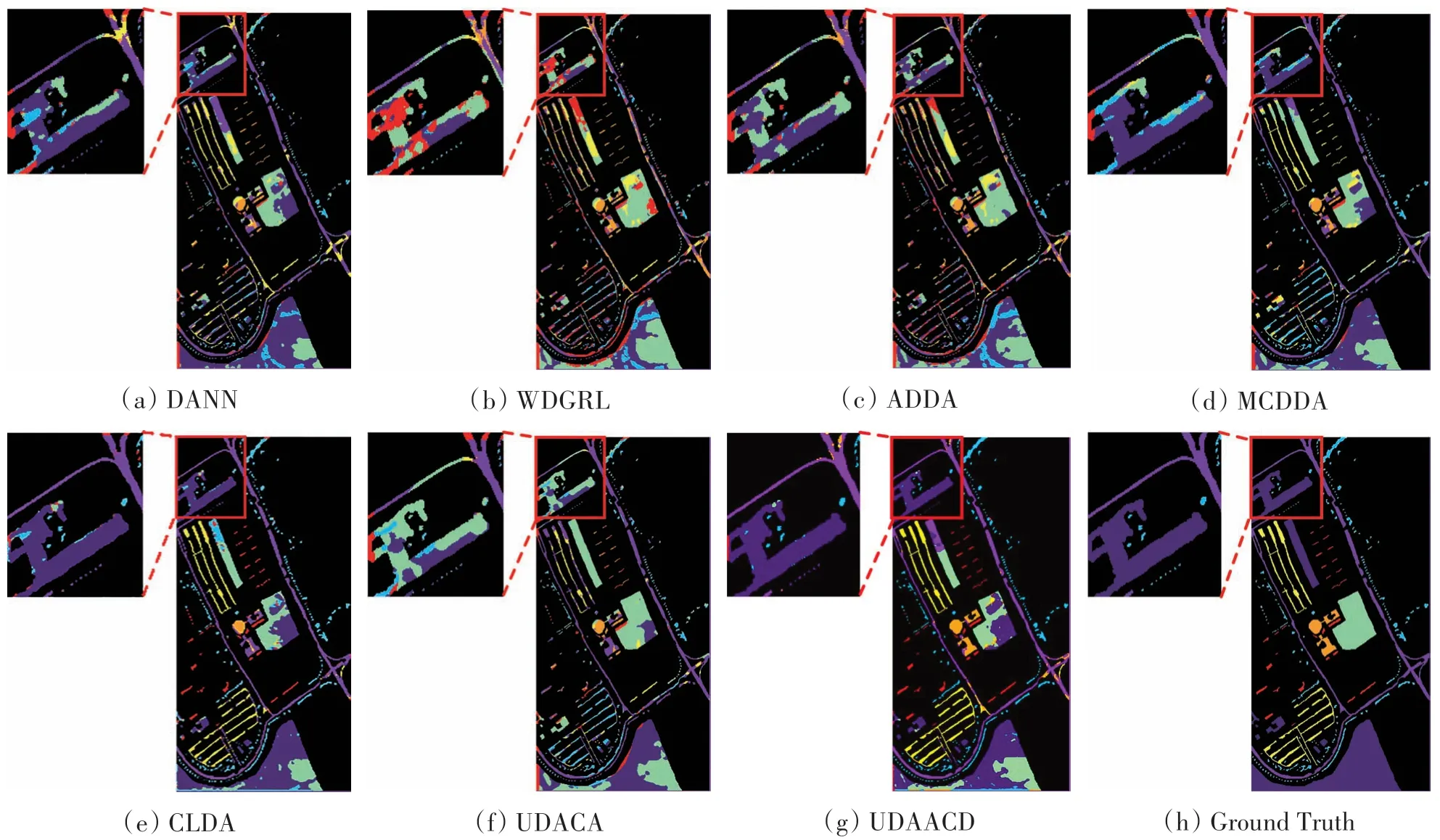
图7 不同方法在PaviaU数据集上的分类结果图(PaviaC->PaviaU)Fig.7 Classification maps provided by different approaches on the PaviaU(PaviaC->PaviaU)
第3 组实验的源域使用Hou13数据集,目标域使用Hou18数据集。在实验中,本文选用了两个数据集共有的7个类别作为待分类地物,同时在Hou13数据集中截取了209×955与Hou18数据集重叠的区域,48 个波段的选择方式与文献(Fang 等,2022)相同。各对比方法在Hou18 数据集上得到的OA、AA、Kappa系数及运行时间如表3所示,分类结果如图8所示。UDAACD 在Hou18场景上无监督分类得到的OA 为70.68%,AA 为74.65%,Kappa 系数为0.56,优于其他UDA 方法,在大多数类别上的预测精度高于其他对比方法;从表3观察得知,该场景上的分类精度明显低于前两组实验,表明分布差异较高场景的分类结果要低于差异较低的场景。DANN 取得的分类精度高于MCDDA 方法,说明DANN在该场景上具有较好的适应性。

表3 不同方法在Hou18数据集上的分类结果(Hou13->Hou18)Table 3 Classification performance from the results with all the compared methods of the Hou18(Hou13->Hou18)

图8 不同方法在Hou18数据集上的分类结果图(Hou13->Hou18)Fig.8 Classification maps provided by different approaches on the Hou18(Hou13->Hou18)
第4 组实验的源域为Hou18数据集,目标域为Hou13 数据集,实验参数设置与第3 组实验相同。各对比方法在Hou13 数据集上分类得到的OA、AA、Kappa系数及运行时间如表4所示,分类结果图如图9 所示。在本分类场景中,CLDA 方法获得了最高的精度,其OA值为80.21%,AA值78.73%,Kappa 系数为0.77。UDAACD 在本场景中精度排名第二,其OA 和AA 值分别为67.76%和70.22%,Kappa 系数为0.62,在第2 类和第4 类地物上取得了最高分类精度,该组实验结果表明本文方法在Hou18->Hou13 场景上的实验结果要低于Hou13->Hou18场景。
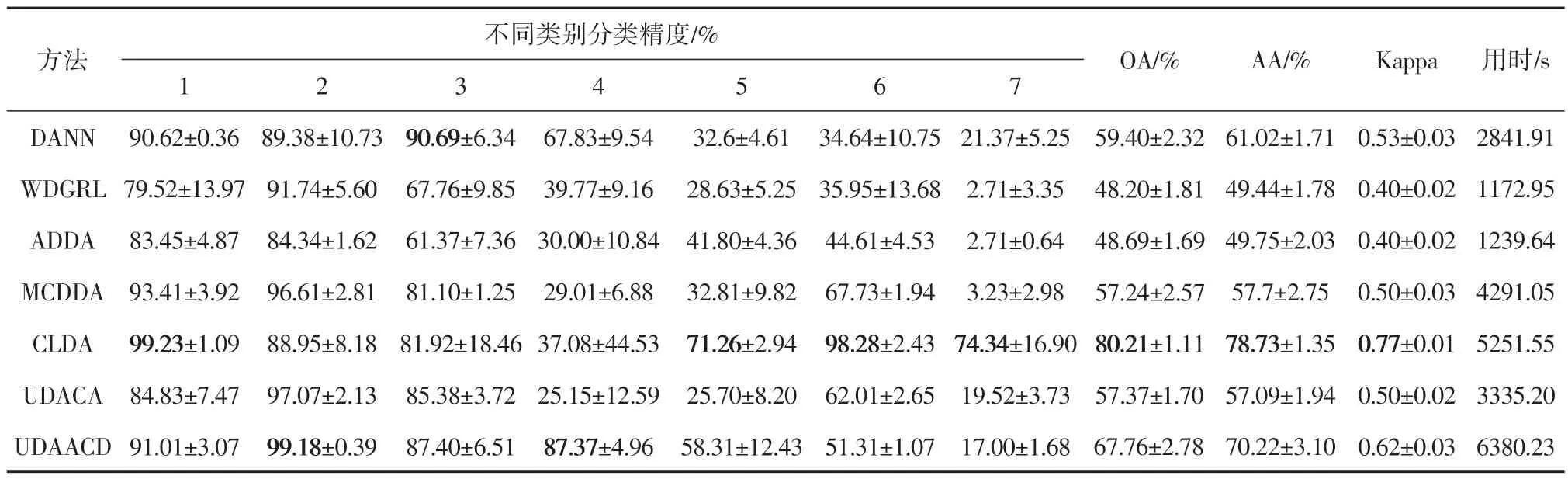
表4 不同方法在Hou13数据集上的分类结果(Hou18->Hou13)Table 4 Classification performance from the results with all the compared methods of the Hou18(Hou18->Hou13)

图9 不同方法在Hou18数据集上的分类结果图(Hou18->Hou13)Fig.9 Classification maps provided by different approaches on the Hou18(Hou13->Hou18)
3.4 超参数分析
为了寻找到适配UDAACD 模型的蒸馏损失权重α及温度T、t,本节选用不同取值的损失权重及温度,以PaviaU->PaviaC,Hou13->Hou18 两组实验场景为代表进行分析。
当确定T=4,t=1.5 时,在两组场景上选用不同蒸馏损失权重得到的平均分类精度曲线图如图10(a)所示。其中,横轴表示损失权重,纵轴表示模型预测精度OA。当权重α取值为0.6时,在PaviaC 分类场景上取得了最好的平均精度,为91.75%;当权重α取值为0.5 时,在Hou18 分类场景上取得了最好的平均精度,为70.97%。当α取0.7 时,在PaviaC 分类场景上分类精度最差,仅为81.22%;当α取0.1 时,在Hou18 分类场景上的平均分类精度最差,仅为65.34%。从整体上来看,不同权重下两组实验的OA值变化趋势基本相同。

图10 不同超参数下UDAACD模型分类精度变化图Fig.10 Curves of UDAACD classification accuracy under different super parameters
当确定α=0.6时,在两组场景上选用不同蒸馏温度T、t得到平均分类精度曲线图分别如图10(b)、(c)所示。其中,纵轴表示模型预测精度OA。当T=1 时,模型在两个场景上的平均分类精度最低,分别为86.38%、61.92%;当T=3 时,模型在两个场景上的平均分类精度越高,分别为89.35%、68.10%;t=1.5 时,模型在PaviaC 场景的平均分类精度最低,为86.98%;t=2.5 时,模型在Hou18 场景的平均分类精度最低,为64.30%;t=4.5 时,模型在两个分类场景上的分类精度最高,分别为88.86%、68.72%。
3.5 域自适应特征的可视化分析
为了模拟UDAACD 模型从不同域中提取的特征分布变化情况,本节利用t 分布随机邻域嵌入(t-SNE)算法对PaviaU->PaviaC,Hou13->Hou18两组实验中训练初始及完成阶段的域内特征进行了可视化展示,可视化结果分别如图11 和12 所示,其中,训练初始阶段为源域和目标域未对齐之前的阶段,而训练完成阶段为两个域经过UDAACD 模型完成域对齐之后的阶段。在初始阶段,各域中的样本均是无序的且在子类空间的分布差异较大,经过域对齐之后的样本空间具有一定的分布一致性。从图11(b)和图12(b)可以看出,UDAACD 模型的两组实验在源域上均得到了较好的对齐结果,且在目标域PaviaC 上的对齐效果较好,其样本空间已呈现明显聚类性;由于Hou18 场景相对复杂,域对齐之后的样本仍有部分类别混合现象。

图11 PaviaU和PaviaC数据集在不同阶段的特征分布t-SNE可视化图Fig.11 t-SNE visualization of the feature maps of PaviaU and PaviaC dataset at different stages

图12 Hou13和Hou18数据集在不同阶段的特征分布t-SNE可视化图Fig.12 t-SNE visualization of the feature maps of Hou13 and Hou18 dataset at different stages
3.6 消融实验及分析
为了验证CBAM模块及知识蒸馏在UDAACD模型中的真实效果,本节在PaviaU->PaviaC,Hou13->Hou18两组实验场景上进行消融实验,实验结果如表5 所示,表5 中数值表示连续3 次实验结果获得的OA均值。
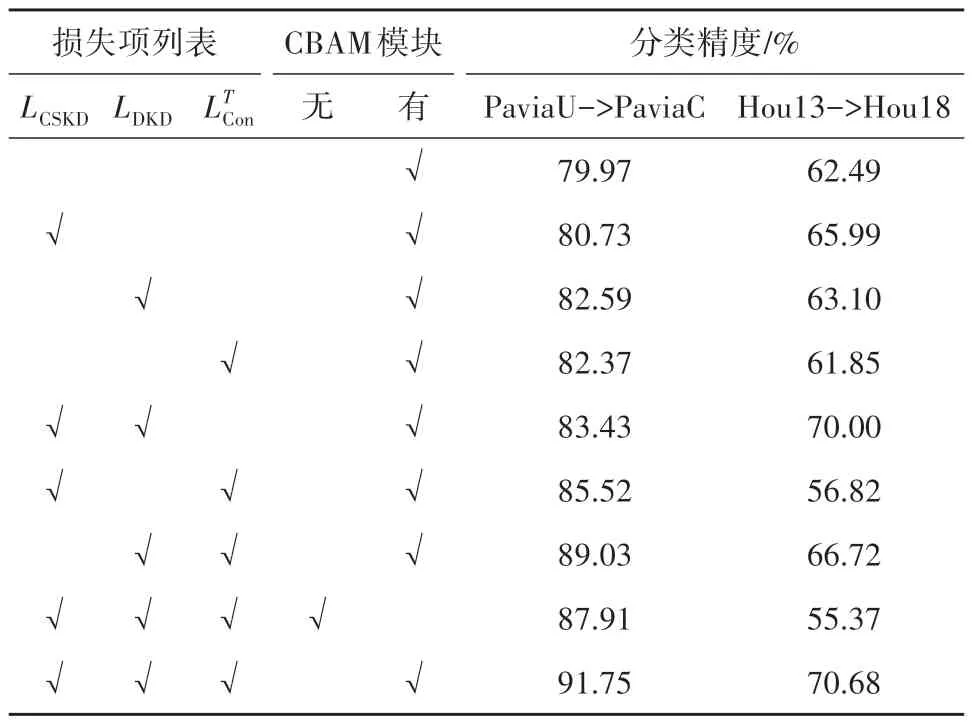
表5 不同条件下UDAACD模型的消融分析Table 5 Ablation studies of UDAACD model under different conditions
首先,由表5观察可得知,当特征提取网络含有CBAM 模块时,UDAACD 模型在两个场景上的精度有明显提高,且在使用CBAM 模块后,模型Hou13->Hou18 场景中,UDAACD 模型精度得到较大的提升,证实了该模块对于高光谱图像空谱特征提取的有效性。
其次,通过表5可以发现知识蒸馏对UDAACD模型分类效果的影响。不使用3种损失的模型视为本实验的标准(baseline),即在HSI 双域特征对齐过程中仅使用LE及LDis。观察得知,使用LCSKD+LDKD+在两组HSI 分类场景上均取得了最好的精度。在PaviaU->PaviaC 场景中,baseline 实验精度最低,为79.97%;而在Hou13->Hou18 场景中,同时使用LCSKD和时精度最低,仅为56.82%,不及该场景上的baseline,且仅使用LDKD时精度为65.99%,略高于baseline。在Hou13->Hou18场景上,同时使用3种损失的精度有明显的提升。两组分类场景的分析结果可以得出仅使用一种额外损失对实验精度提升不大,而当存在两种及两种以上损失约束时,精度大多拥有了较高提升,说明了3种损失约束项在HSI域自适应分类过程中起到了相互促进的作用;与此同时,向任意场景模型中加入蒸馏损失LDKD时,相比仅含有时精度均有提升。
4 结论
针对现有高光谱跨场景分类中存在源域知识提炼及迁移不充分的问题,本文提出了一种利用对抗机制和知识蒸馏相耦合的域自适应分类方法。该方法通过在样本训练和特征对齐过程中加入自蒸馏及域间蒸馏约束,提高源域监督信息的提炼与迁移效果,保证目标域分类模型充分学习源域中的知识。在流行的国际高光谱数据集上进行的4 组UDA分类实验表明该方法效果的优越性。
本文主要贡献包括:
(1)提出了一种基于自蒸馏强化的高光谱遥感图像源域知识提炼方式,通过在源域同类别样本间加入自蒸馏正则化约束以减少分类子空间的类内差异,提高源域分类模型的知识表达能力;
(2)提出了一种对抗与知识蒸馏耦合的高光谱域自适应分类方法,通过在双分类器与生成器的对抗训练过程中融入蒸馏知识,在提高网络对域内混淆样本识别能力的同时,保证高光谱源域知识在特征对齐过程充分迁移,提升目标域场景的知识获取能力;
(3)对比了多种方法在不同高光谱跨场景分类中的性能差异,并通过消融分析验证了对抗蒸馏耦合机制对于高光谱遥感域间知识迁移具备有效性。
对于特征差异较大的高光谱跨场景分类时,论文方法的单类别分类精度仍不够稳定。未来将继续研究知识蒸馏与域自适应的内在联系,探寻多种向高光谱目标域传递监督信息的途径,保证域间信息能够更加稳定地迁移。
