面向不均衡数据的重采样算法
2024-03-05成金海
朱 深,徐 华,成金海
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
1 引 言
分类学习是机器学习的重要研究方向之一,传统的分类模型,比如决策树、神经网络、SVM等,在解决分类问题时,假设样本分布在本质上是平衡的,但是在实际问题上,为了更高的精确率,算法更容易倾向于识别多数类,少数类容易被误分,但更多的情况,识别少数类是更重要的.
针对不平衡问题,已有的解决方法主要分为两类:数据层面和算法层面.算法层面的方法有代价敏感学习和集成学习等.代价敏感学习的基本思想是对于不同类型的数据设置不同的误分类代价.集成学习通过构建并结合多个分类器来完成学习任务,Sun等[1]将Boosting集成和代价敏感因子[2-4]结合,AdaBoost(Adaboost Algorithm Based on Cost Sensitivity,AdaCost)集成算法由此被提出,Krawczyk等[5]结合代价敏感与Bagging集成,在基决策树中引入代价敏感因子.平瑞等[6]提出了基于聚类的弱平衡代价敏感随机森林算法(Weak Balance Cost-Sensitive Random Forest,WBC-RF),该算法通过对大类样本聚类后,随机选择每个聚类中的部分样本,进行欠采样,使用欠采样后的数据集训练代价敏感决策树,但是需要生成的聚类个数过多,导致时间复杂度变高.
数据层面一般采用过采样或欠采样来改变数据分布Chawla等[7]提出了合成少数类过抽样技术SMOTE算法,使用部分少数类合成新的样本点,但是合成的样本可能落在多数类的区间中,使多数类和少数类更难以区分.对此研究者对其做出了很多改进.Borderline-SMOTE[8]通过邻域样本数量区分边界与非边界区域,合成边界样本,但在某些情况下,边界样本难以被识别.赵清华等[9]提出了最远点算法(Max Distance SMOTE,MDSMOTE),只关注少数类样本质心点和距离质心点最远距离的样本点,但这样会有较高的时间复杂度.刘金平等[10]提出了融合谱聚类的自适应总和采样算法(SCF-ADASYN),但当样本数目较大时,效果不佳.
欠采样算法是仅选择数据集中部分的多数类样本.使用安全筛选[11,12]规则可以找到数据集中对分类决策没有作用的样本,石洪波等[13]提出了基于安全样本筛选的欠采样和SMOTE结合的抽样方法(Screening_SMOTE),既减少多数中的噪声样本,也减少了过抽样带来的过拟合问题.Rayhan等[14]提出抽样算法(Clustering based Under-Sampling approach with BOOSTing algorithm,CUSBOOST),该算法首先生成聚类,然后在每个聚类中随机选择部分样本;Lin等[15]种基于聚类的欠抽样方法,简称UC,生成和少数类样本同样多的聚类,然后将簇芯作为多数类样本,但当少数类样本较多时,需要产生的聚类个数过多,造成较大的系统开销,并且会加重噪声点对分类产生的影响.基于样本加权的欠抽样方法[16,17]通过多次聚类确定实例的权重,然后依据样本的权重对多数类数据进行欠抽样,但是这样时间复杂度会过高.魏力等[18]提出了CBNM(Clustering-Based NearMiss)算法,根据簇芯到样本的距离赋予该样本的选择权重.熊炫睿等[19]提出了一种基于簇内样本平均分类错误率的混合采样算法(SABER),该算法首先使用SMOTE算法过采样,随后使用聚类算法,根据簇内样本分类错误率进行欠采样.以上几种方法,在筛选过程中耗费了较多的系统资源,应进一步改进.
为了更进一步提高SMOTE算法的性能,Bastista等[20]提出了将SMOTE算法和数据清洗方法相结合的方法SMOTE+ENN(Edited Nearest Neighbor)和SMOTE+Tomek links.董明等[21]结合SMOTE和局部核心的过抽样算法LCSMOTE,该方法先使用自然近邻除去噪声,随后划分区域,计算区域内样本的稀疏权重,最后合成新样本.梅大成等[22]提出了一种征边界和密度适应的SMOTE算法,该算法找出每一个少数类样本的边界范围,同时根据样本的分布密度时刻改变算法参数.以上两种算法步骤较复杂,并且时间复杂度较高,可以进一步提升.崔鑫等[23]提出SMOTE的改进算法CSMOTE(Clustered Synthetic Minority Over-sampling TEchnique).该算法使用少数类的簇心,与对应簇中被筛选后的样本合成样本,一定程度上减少了噪声数据的干预,但是在面对大数据集,类别不平衡比较严重的时候,要合成的样本较多,筛选机制又较苛刻,会造成较大的系统开销.针对于该算法的缺点,本文基于此提出了一种SMOTE的改进算法,该算法先使用聚类算法将少数类分为若干个簇,从簇中随机选择若干个样本点,使用线性插值法合成一个中间样本点,再使用合成的中间样本点与聚类簇芯合成一个新的样本点,并将其添加到数据集中,使用簇内的样本在一定程度上减少了噪声数据的干扰.
本文将SMOTE的改进算法与随机欠采样RUS算法结合,提出了一种重采样算法RUSCSMOTE(Random Under-Sampling Clustered Synthetic Minority Over-sampling TEchnique),该算法先自适应的通过欠采样去掉部分多数类样本,这样既保留了部分多数类的信息,又减少了合成的少数类,因此也减少了系统开销和噪声点的干扰,同时降低了算法时间复杂度,再利用SMOTE的改进算法过采样,减少了新合成的样本落在多数类的样本空间中的概率,最终得到均衡的数据集.
1 RUCSMOTE算法
1.1 随机欠采样算法
随机欠采样即从多数类Smaj中随机选择一部分样本,组成样本集Sr.然后将Sr从Smaj中移除,原数据集如图1(a)所示,经过欠采样之后,数据分布如图1(b)所示,多数类样本点变少,使得样本均衡分布.

图1 随机欠采样Fig.1 Random under-sampling
算法缺点:对于随机欠采样,丢弃了一部分样本,因此会造成信息缺失,这意味着删除多数类样本有可能会丢失部分有用的信息.算法优点:算法简单易实验,减少模型训练的时间.
1.2 SMOTE改进算法思想
SMOTE算法如图2(a)所示,先随机选出一个少数类样本c,然后找出该样本的k个近邻(假设k=4),然后从k个近邻中随机的选择一个样本d,在该少数类样本c和被选中的d这个少数类样本之间的连线上随机找一点e,这就是合成的样本点.显然样本e出现在多数类的空间中,这种情况下非但不能帮助分类器的训练,反而会因为样本e让数据变得更难区分,因此要采取一些措施保证合成样本的合理性.
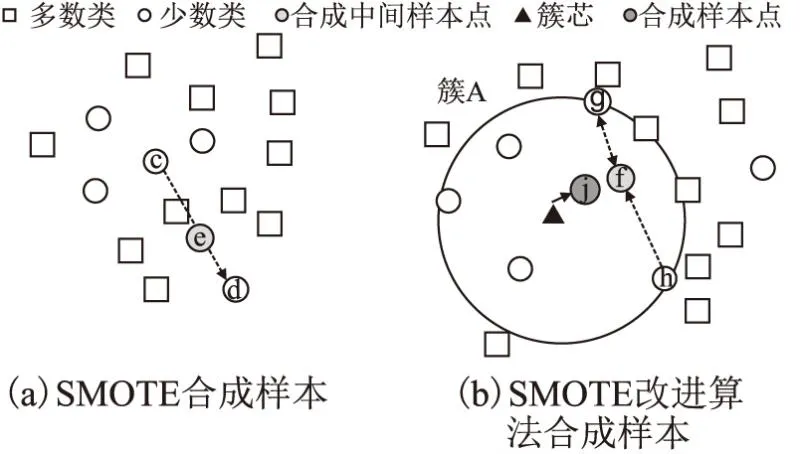
图2 SMOTE和SMOTE改进算法合成样本对比Fig.2 Comparison of synthetic samples of smote and improved smote algorithms
SMOTE改进算法首先在少数类上使用聚类算法,将少数类分为若干个簇,在各个簇中合成新样本.如图2(b)所示,首先在少数类上生成若干个簇,然后分别在各自簇中合成新的样本,以簇A举例,算法过程为:随机选择若干少数类样本,比如随机选择两个样本点,g点和h点,使用线性插值法,在两个点连线部分随机生成一个点f,然后使用新合成的少数类中间样本与聚类中心合成新样本j,最后将j加入到少数类样本集中.
该算法使用聚类算法,在簇中合成新样本,减少了新合成的样本位于多数类的样本空间中.由于参与合成的少数类聚类的簇芯,部分样本合成中间样本点,都不是原数据集中实际的数据点,增大了样本的分布,减少了过拟合的风险.
1.3 k-means聚类算法
给定样本集D={x1,x2,…,xn},该算法针对聚类所得簇划分C={C1,C2,…,Ck}最小化平方误差:
(1)

输入:样本集合D,聚类簇数k
1)从D中随机选择k个样本作为初始聚类中心;
2)计算样本集合中其他样本到聚类中心点的欧式距离,将样本分配到距离最近的聚类中心点所在的簇中;
3)根据已经划分好的簇,更新聚类中心点;
4)重复2)和3)的过程,直到中心点不再移动;
输出:簇划分C={C1,C2,…,Ck}
1.4 RUCSMOTE算法流程
RUCSMOTE算法是将随机欠采样算法和SMOTE的改进算法结合起来,简要步骤为:
1)自适应的对数据集使用随机欠采样,减少多数类样本数量;
2)将样本分为多数类和少数类;
3)在少数类上进行聚类,生成k个簇;
4)将所有的簇芯加入到合成的少数类集合中;
5)使用簇内的样本合成中间样本点,然后与各自的簇芯合成新的少数类;
6)将新合成的样本与原数据集合并,得到均衡的样本集.
rate表示多数类样本数量和少数类样本数量的比值,即不平衡比率,rate1表示欠采样后的不平衡比率.使用一个0~1之间的随机数R,点xi和xj合成新样本xnew的公式如下:
xnew=μi+R(xj-μi)
(2)
RUCSMOTE算法的具体步骤如下;
输入:不均衡数据集S={x1,x2,…,xn},聚类个数k,不平衡比率rate
过程:
1. 根据rate的数值,设置参数rate1控制欠采样比率,
2. 使用随机欠采样后,得到数据集S1;
3. 根据类别,将S1分成两个集合,分别是多数类集合
4.Smax和少数类集合Smin;
5. 令合成的少数类集合NewM=φ
6. 在集合Smin上使用k-means算法进行聚类生成k个
7. 簇C={C1,C2,…,Ck},求出各自的聚类中心
8. {μ1,μ2,…,μk},将聚类中心加到NewM中;
9.fori= 1,2,…,kdo
10. 依次遍历集合C,取集合中的Ci;随机选择两个样
11. 本点,使用公式2)合成中间点xtemp,利用簇Ci
12. 的簇芯ui和xtemp合成样本xnew,将xnew加入
13. 到NewM中;
14.endif
输出:将NewM与原样本集合并,合成均衡样本集NewS
1.5 RUCSMOTE算法复杂度分析
少数类样本数量用n表示,多数类样本数量用m表示,样本的维度为p.步骤1对多数类进行随机欠采样,时间复杂度为O(m),步骤2的时间复杂度为O(m+n),步骤3对少数类使用k-means聚类算法,算法时间复杂度为O(fpkn),其中f为迭代次数,k是类别数,因为一般情况下f,p,k远小于n,所以k-means算法时间复杂度简化为O(n).步骤4~步骤5中,假设簇是被等分的,则时间复杂度为O(m),综上RUCSMOTE的时间复杂度为O(m+n).
其相对于许多重采样算法,该算法的时间复杂度是较低的.因为引进了随机欠采样的步骤,不仅需要合成的样本减少,减低时间复杂度,同时减少了噪声点的干扰,减少过拟合风险.
2 实验结果与分析
2.1 实验数据集和评价指标
KEEL数据库是(KEEL:A software tool to assess evolutionary algorithms for Data Mining problems(regression,classification,clustering,pattern mining and so on))不平衡数据集,里面的很多数据集来源于现实生活中,本文算法适用于数值型数据,从KEEL数据库中选取20个不平衡数据集,数据集的详细信息见表1,为了方便表示,给每个数据集取标号.
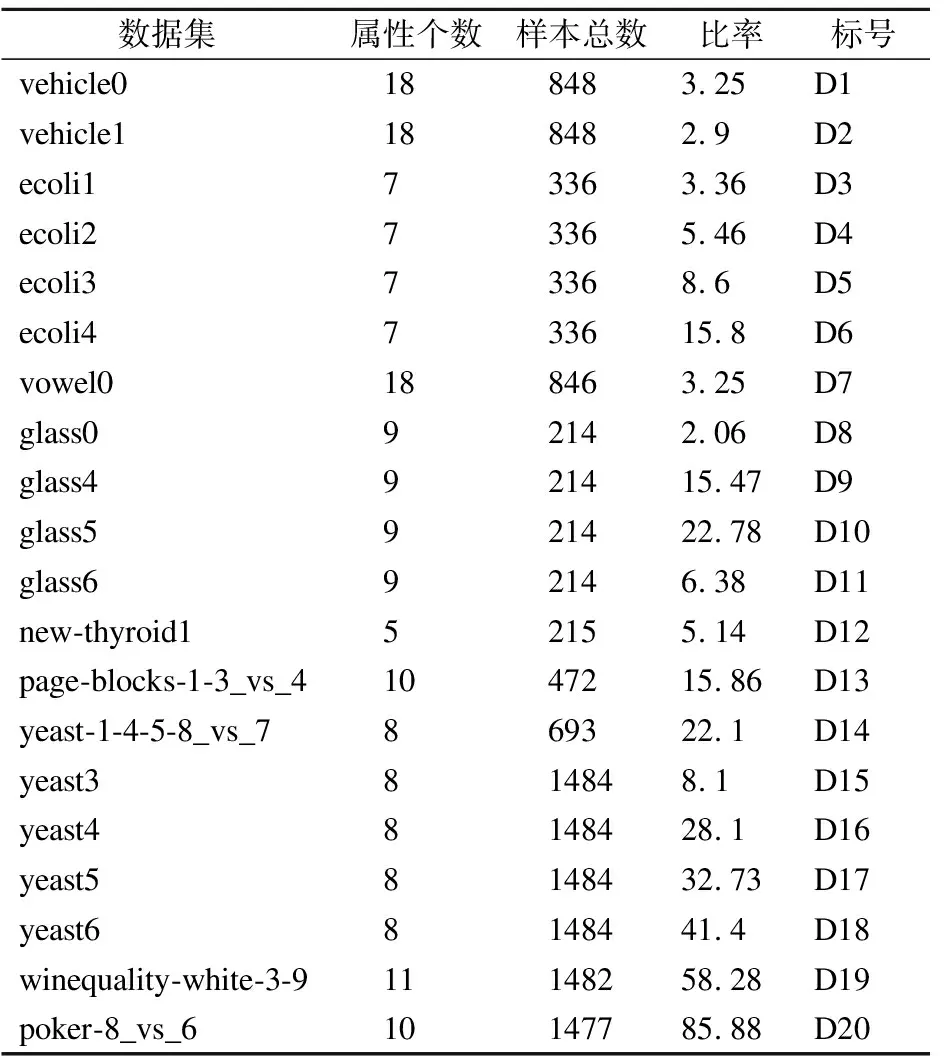
表1 数据集详细信息Table 1 Details of datasets
常用的分类准确率更偏向于多数类数据,因此不适合作为不平衡数据的性能度量.可以将根据样本的真实类别和分类器预测的类别的组合建立混淆矩阵,其中TP表示真正例的数量、FP表示假正例的数量、TN表示真反例的数量、FN表示假反例的数量,本文采用受试者工作特征曲线(Receiver Operating Characteristic,ROC)的面积,即AUC(Area Under ROC Curve)以及G-means来比较分类器的性能.
AUC是不平衡问题分类性能的通用度量方式,AUC的取值范围为[0,1],AUC的数值越大,其分类泛化性能越好,最理想状态下数值为1,而AUC为0.5时,效果等同于随机猜测.TPR表示“真正例率”,FPR表示“假正例率”,Specificity为多数类数据的预测准确率,三者定义如下:
(3)
(4)
(5)
AUC计算式如下:
(6)
G-mean通过计算多数类和少数类数据的预测准确率的几何平均值,只有其分类泛化性能越好的时候,才能得到较高的G-mean值,G-mean简记为GM,GM值的计算公式如下:
(7)
2.2 实验步骤
在进行最终实验之前,先做3个小实验确定算法参数,设置不同参数,选取7个数据集,对数据集进行5次五折交叉验证,求出分类器的GM值和AUC值的平均值,记录在表中,其中不同参数下第1行为AUC值,第2行为GM值,每种数据集上较优的算法已加粗显示.
最后对使用RUCSMOTE算法与另外7种经典的重采样算法,在20个数据集上,进行5次五折交叉验证,求出分类器的GM值和AUC值的平均值,对比不同算法的表现,为了更好体现该算法的性能,分类器使用单层决策树,本文对数据集进行标准化处理,减少不同变量的取值范围对算法的影响.
2.3 算法参数设置
算法有3个重要的参数,分别是少数类产生的聚类个数,参与合成新样本点的样本点个数,以及多数类的欠采样率,3个参数关联性不大,所以分开确定.
首先确定参与合成新样本的样本点,由理论分析可知,当只选择一个样本点与簇芯合成的时候,由于使用了一个真实的样本点,在合成的过程中可能会使得新合成的样本点与真实存在的样本点距离过近,容易导致过拟合,如果先随机选择两个样本点合成中间样本点xtemp,然后使用xtemp与簇芯合成新的样本点,由于两个点都不是真实的样本点,并且合成的点偏向聚类内部,所以可以更好的增加样本的分布.
如果使用3个或者3个以上的样本点合成,由于本就已经随机选择的两个点,再增加随机样本点可能会导致新合成的点偏离原本的分布,所以通过理论分析可知,选择随机选择两个数据点较为合适.
下面通过实验验证,设聚类个数k=5,先不使用随机欠采样,在选取的数据集上测试,结果如表2所示.

表2 随机点个数对算法性能影响Table 2 Influence of the number of random points on the performance of the algorithm
从试验结果来看,只有D19的GM值在样本点为3时超过了样本点为2的,其他数据集在选取两个数据点的效果是更好的,随着选取的样本点变多,分类效果反而变差,这也与理论分析一致.
聚类个数k会影响合成少数类的分布情况,在一些少数类样本较少的情况下,k过大可能会超过样本总数,并且随着聚类个数增多,噪声点对于分类器的影响也会变大,时间复杂度也较高,所以k不宜取的过大,但是选取的k过小会增加合成新样本落入多数类空间的概率,反而影响分类结果,所以参数k的选取对算法性能很重要.
取k∈{2,3,4,5,6,7},通过对比不同k下分类器所得的AUC值和GM值来确定最佳的k值,选取7个数据集进行测试,结果如表3所示.
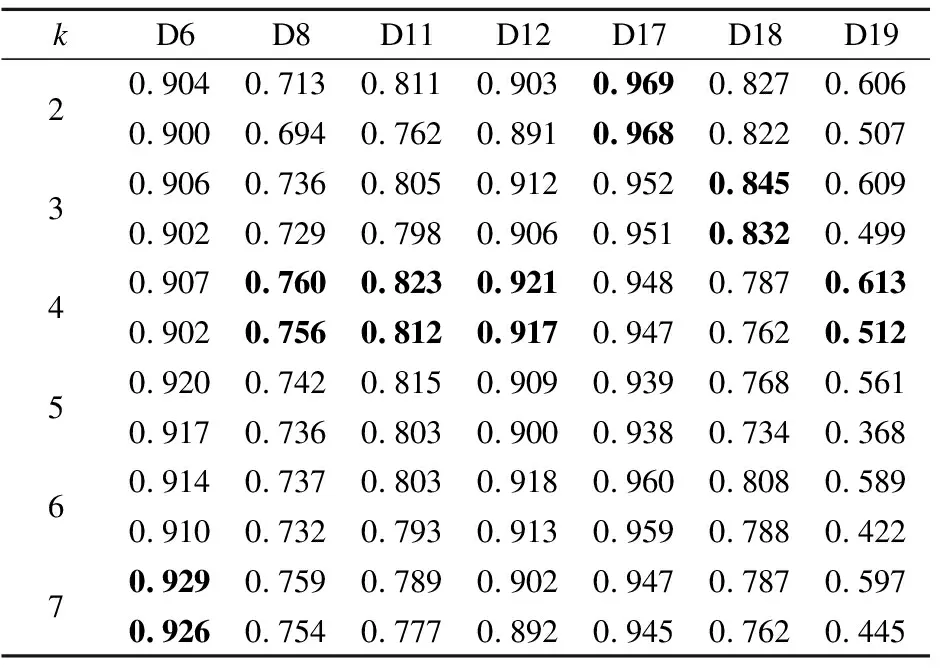
表3 不同k值的分类效果Table 3 Classification effect of different k values
表3中有4个数据集在k=4时取得了最优值,D17和D18分别在2和3时取得最优值,由于每种数据结的样本分布不同,k无法完全统一,但是聚类个数在4左右时,总能取得较好的结果,并且时间复杂度较低,受噪声影响也较小,因此默认情况下聚类个数k=4.
该算法还需要平衡过采样和欠采样,在实验中,尝试将rate等比例缩放或非线性的缩放,降低到rate1,对比两者的效果.等比例缩放是将不平衡比率rate降低到多数类和少数类差值的1/s倍,当s过于大时,近乎于只有欠采样,所以s不宜过大,取s∈{2,3,4,5},此时:
(8)
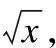
rate1=log2(rate+1)
(9)

(10)
在数据集上使用不同的rate1公式的重采样算法,如表4所示,可以看出,当不平衡比率较低时,非线性缩放的效果一般,但是随着不平衡比率的上升,非线性缩放普遍优于等比例缩放,其中公式(10)的效果更好,而且在面对大数据集,不平衡比率较高的情况下,可以减少更多需要合成的样本,因此使用公式(10)来确定欠采样的比率.

表4 不同欠采样公式的算法分类性能对比Table 4 Comparison of algorithm classification performance of different under sampling formulas
2.4 不同算法的性能比较
本文选取9种重采样算法对原始数据集进行抽样,然后与RUCSMOTE算法对比抽样数据集上构建的分类器的性能.它们分别是SMOTE[7]、MDSMOTE[9]、WBC-RF[6]、Borderline-SMOTE[8]简记为BLSMOTE、CSMOTE[23]、随机欠抽样RUS、SMOTE+ENN[20]、SMOTE+TomekLink以及文献[15]提到的基于聚类中心的欠采样,简称UC.对每个数据集分别使用这10种算法进行5次五折交叉验证,求出其AUC和GM的平均值,如表5所示,其中每个数据集的第1行为AUC值,第2行为GM值.

表5 不同数据集上8种算法分类性能对比Table 5 Classification performance comparison of eight algorithms on different datasets
由表5可知,RUCSMOTE算法在D2~D6由于样本数较少,并且不平衡比率较低,没有进行充分的欠采样和过采样,相对于其他算法优势不大,因此没有取得最佳的效果,但是和最优的是比较接近的,在后续不平衡比率较高的数据集上,性能更优.作为改进的SMOTE算法,对比SMOTE,AUC和GM均有提升,在D9,D10,D18,D19上的提升尤为明显,在不平衡比率较高的D19上AUC提升了13%,在GM上提升了40%,因为通过聚类选择的点相当于进行了筛选,更合理的扩充了数据集的分布,同时降低合成的数据点落入多数类样本的区间,降低了过拟合的风险与单纯的欠采样相比,由于保留了更多的多数类,模型可以学习到更多的多数类信息,除了在D14上,在其余的数据集上均优于单纯的欠采样算法,这是因为在一些少数类与多数类样本空间相互重叠较为严重的数据集,多使用欠采样更有利于二者的区分.求出不同算法在数据集上AUC和GM的平均值,可以看到RUCSMOTE算法的平均值最高,在AUC上超过SMOTE算法4.19%,超过随机欠采样2.89%,在GM上超过SMOTE算法7.68%,超过随机欠采样2.56%,这表明RUCSMOTE算法是可靠的.
3 结 语
本文从数据层面出发提出了RUCSMOTE算法,实现了不平衡数据再平衡,该算法先使用简单高效的随机欠采样丢弃一部分多数类,缓解一般欠抽样丢失样本过多导致的信息丢失问题,然后使用聚类算法分类,使用簇芯在聚类内合成新样本,解决了SMOTE算法模糊多数类和少数类的边界问题,同时使得扩充了样本的分布,使得新合成的样本更合理又因为使用欠采样使得需要合成的样本数减少,降低了过拟合的风险.在实际的实验中也证明了,尤其是在不平衡比率更高的时候,该算法有较好的分类效果,并且算法易于实现,时间复杂度更低,但是在样本数较少并且不平衡比率较低时,算法优势并不明显,这也是未来要进一步优化的方向之一.
