区间删失数据下Weibull 比例优势模型的参数估计
2024-03-04王淑影郭祥道李红伟
王淑影,郭祥道,李红伟,赵 波
(长春工业大学 数学与统计学院,吉林 长春 130012)
区间删失数据常出现于生物医学、工业工程学、经济学、人口统计学等众多交叉领域中[1],分析及推断此类数据的内在规律是发展学科交叉融合的重要基础和前提。尽管比例风险模型在这类数据的分析处理中有着极大的优势,但是许多实际问题中,风险率函数经常会收敛为一个常数,并不满足比例风险模型的假设,Bennett建立的比例优势模型,能很好地解决这类问题,较比例风险模型更有优势[2-4]。
许多学者研究了区间删失数据下各种模型的估计问题。文献[5-6]讨论了Ⅰ型区间删失数据半参数比例风险模型的估计问题以及估计结果渐近正态性;文献[7]讨论了Ⅰ型区间删失数据下线性变换模型的估计问题;文献[8-9]在Ⅰ型区间删失数据下建立加性风险模型,并证明了估计的大样本性质;文献[10]提出Ⅰ型区间删失数据(现状数据)下含有潜变量的加性风险回归模型,给出了两步估计方法;文献[11]讨论了Ⅰ型区间删失数据下广义极值分布回归的贝叶斯估计;文献[12-14]基于不同的估计方法建立Ⅱ型区间删失数据的加性风险模型;文献[15]基于比例风险模型提出Ⅱ型区间删失数据下的BAR惩罚变量选择方法,证明了估计的Orcale性质;文献[16]考虑了含有治愈亚组的区间删失数据的变量选择方法等。然而,已有文献主要集中于传统风险模型假设,感兴趣事件发生时间的危险率满足乘积假设或者加法假设。但在实际问题中,这些假设可能不成立,例如危险率函数收敛到常数时,经典模型的风险函数假设并不满足。因此,本研究充分考虑Ⅰ型区间删失数据与Ⅱ型区间删失数据之间的关系,应用参数模型假设的便利性,建立Weibull比例优势模型,并基于极大似然估计给出两种数据类型下参数的估计量。
1 数据及符号
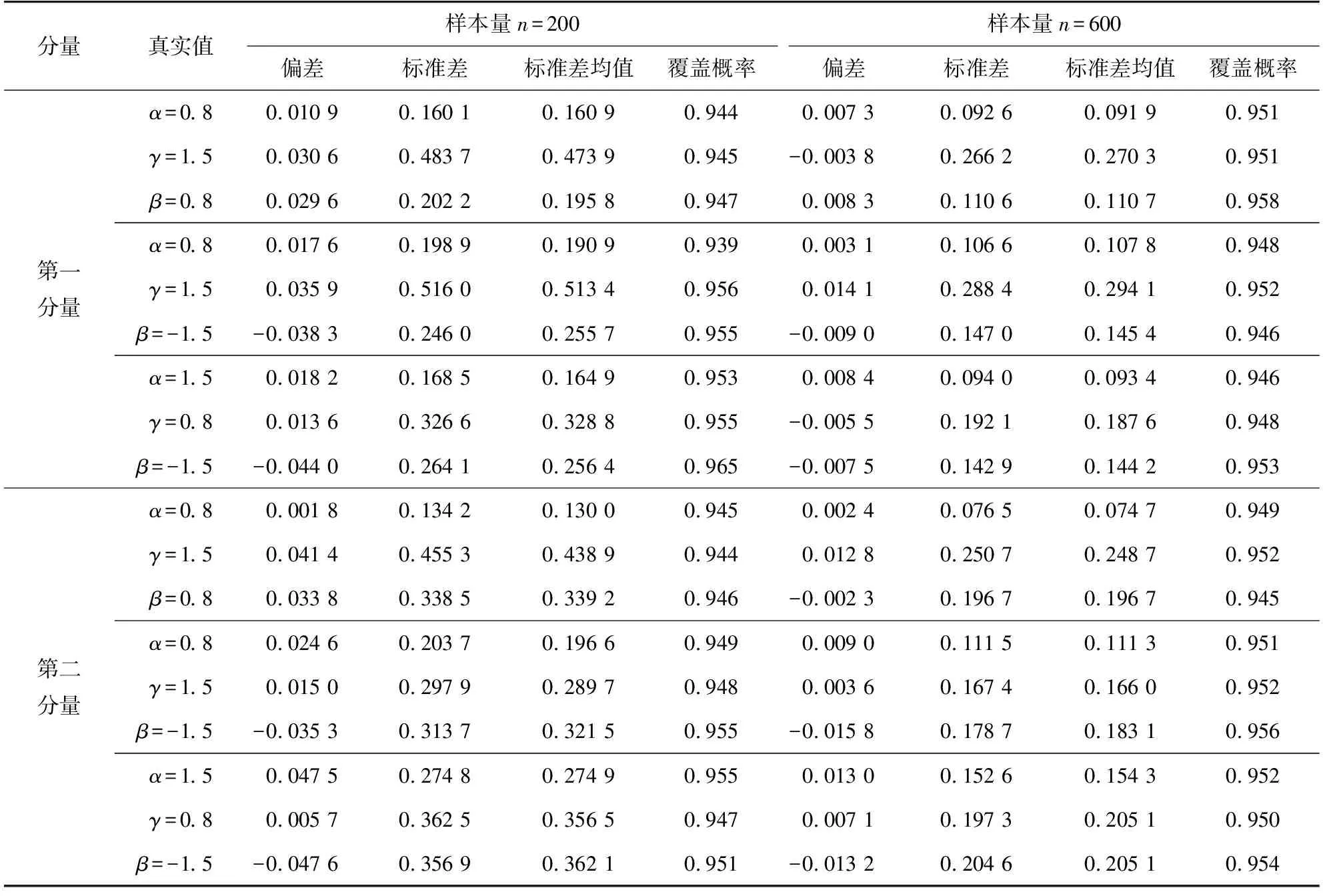
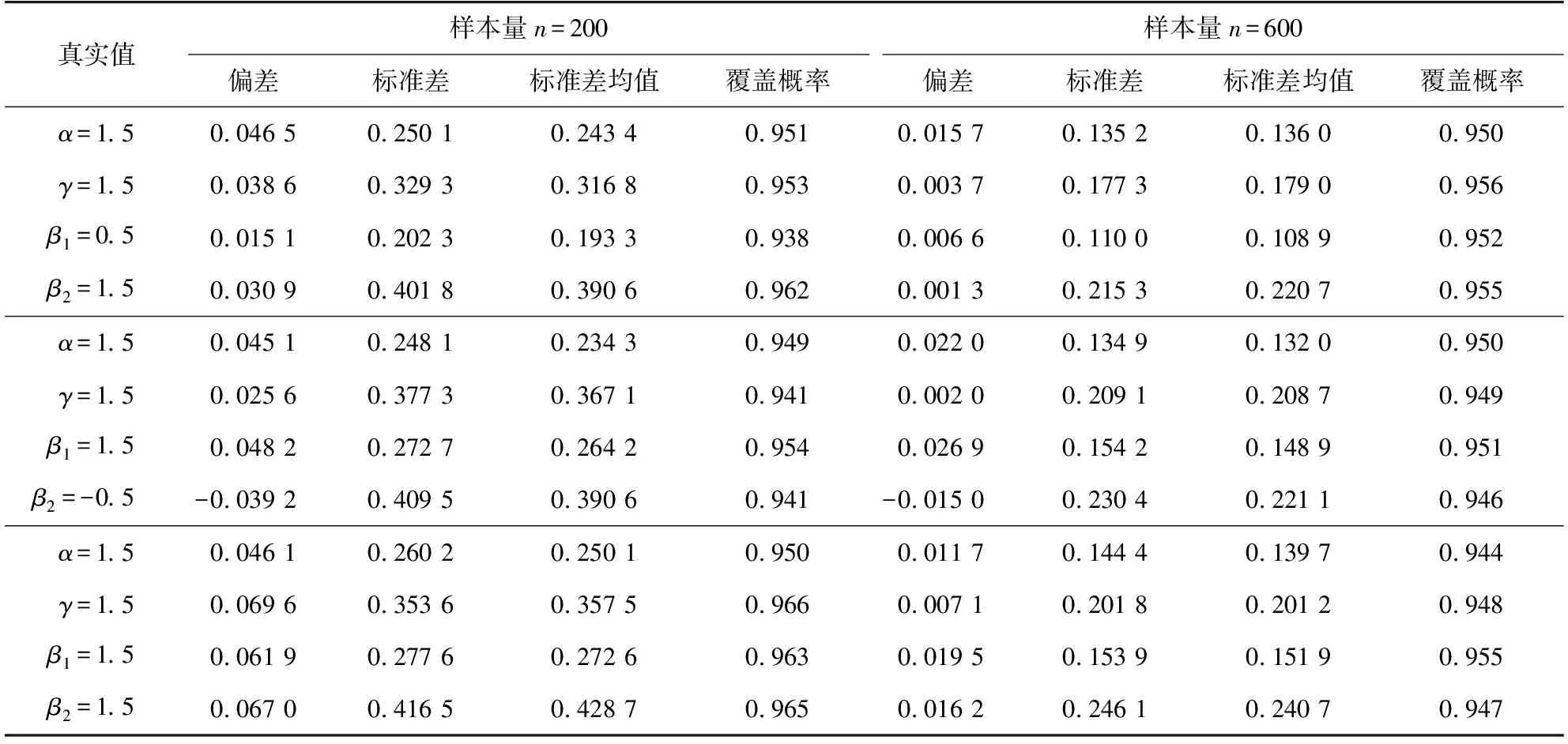
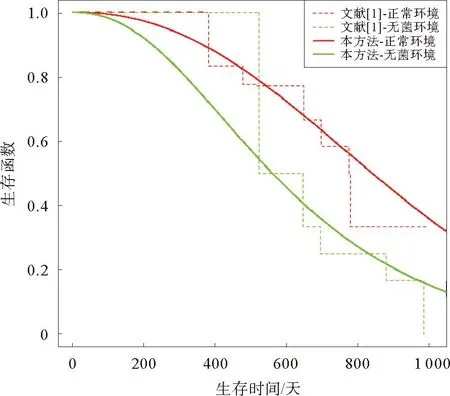
假设变量T表示感兴趣事件发生的时间,变量Z表示p维度的协变量。在有限的资源下,为了记录受试个体的更多信息,研究人员在实验中对受试者进行两次检测U和V(U≤V),感兴趣事件发生的时间会出现3种情况:①感兴趣事件发生在第一次检测时间U之前,即T≤U;②感兴趣事件发生在两次检测时间U和V的中间,即U {U,V,Z,δ1=I(T≤U),δ2=I(U (1) 式中:I为示性函数,δ1、δ2、δ3为示性变量。 当所有受试个体只在时间C被观测一次,则Ⅱ型区间删失数据退化为Ⅰ型区间删失数据(或者现状数据),即C=U=V,此时,所记录到的感兴趣事件发生时间只知道发生在某个观测时间C之前或之后,此时数据结构表示为: {C,Z,Δ}。 (2) 式中,示性变量Δ=I(T≤C)。 同比例风险模型类似,比例优势模型也是刻画感兴趣事件发生的时间与协变量关系的模型,但两个模型有所不同。比例风险模型假设个体的危险率是成比例的,而比例优势模型假设个体危险率收敛到常数,能很好地补充比例风险模型的假设缺陷[3,17]。因此本研究将在区间删失数据下研究比例优势模型。 假设给定协变量Z时,失效时间T与观测过程条件独立,则比例优势模型可表示为[2,17-18]: (3) 或 logit(F(t|Z))=logit(F0(t))+βTZ。 (4) 同理可得,生存时间T在比例优势模型的假设下的生存函数为: 在模型中非参数比例优势函数Λ0(t)的估计是困难的,考虑一种参数分布模型可以简化估计过程。Weibull分布是当前数据中主要的参数模型之一,其分布特征形状参数与尺度参数灵活性在可靠性分析以及生存分析中有着极其重要的作用[19]。综上,讨论Weibull分布下区间删失数据的建模并解释数据蕴含的实际规律,能极大提高估计的效率。 F0(t)=1-exp(-αtγ), (5) 生存函数为: S0(t)=1-F0(t)=exp(-αtγ)。 特别地,当形状参数γ=1时,Weibull分布退化为指数分布。 基于式(4)和式(5),建立Weibull比例优势模型为: 分布函数重新写作: (6) 或将Weibull比例优势模型写作线性形式,即 logit(F(t|Z))=logit(1-exp(-αtγ))+βTZ。 (7) 在区间删失数据结构下,假设Di={Ui,Vi,Zi,δi1,δi2,δi3},i=1,2,…,n是观测样本,设Ti表示第i个个体的失效时间。在给定协变量Zi时,观测时间Ui、Vi与失效时间Ti独立,则在Ⅱ型区间删失数据下Weibull比例优势模型的似然函数可表示为: (8) 对数似然函数为: (9) 在实际问题中,Ⅱ型区间删失数据的一个特殊例子是Ⅰ型区间删失数据或者现状数据。该类型数据表示对每个个体i仅观测一次,此时观测样本表示为Di={Ci,Zi,Δi},i=1,2,…,n,Weibull比例优势模型的似然函数为: (10) 式中:Ci表示第i个个体的观测时间,示性函数Δi=I(Ti≤Ci)。 对数似然函数为: (11) (12) 条件1) 对每个样本i,存在一个εi>0,使得P(Vi-Ui>εi)=1。 条件2) 参数θ∈R+×R+×Rp,且对数似然函数l(θ)的一、二、三阶导数存在。 条件3) 在参数真值θ0,有Eθ0[U(θ0)]=0,矩阵Eθ0[U(θ0)U(θ0)T]正定。 条件4) 协变量Z有界,即存在常数z0>0,满足P(|Z| 注意到: 为验证所提方法的有效性,分别对Ⅱ型区间删失数据和Ⅰ型区间删失数据进行数值模拟。同时,对于协变量Z考虑三种形式:①Z服从成功概率为0.5的伯努利分布;②Z服从标准正态分布;③Z是二维协变量,第一个分量协变量服从标准正态分布,第二个分量协变量服从成功概率为0.5的伯努利分布。在式(6)的假设下,基于逆变换方法反解生成失效时间T,即在区间(0,1)生成均匀分布L,令 (13) 可得: (14) 对Ⅱ型区间删失数据,为了生成观测时间,本研究首先分别在区间(au,bu)和区间(av,bv)(bu≤av)生成服从均匀分布的观测时间U和V,比较失效时间T和观测时间U和V的大小,生成示性变量δ1=I(T≤U),δ2=I(U 表1 Ⅱ型区间删失数据下单个协变量时的模拟结果 表2 Ⅱ型区间删失数据下两个协变量时的模拟结果 从表1和表2可以看出,估计的偏差较小,接近于0,样本标准差接近于估计值的样本标准差均值,覆盖概率接近0.95。随着样本量的增加,效果更加明显。因此,本研究方法获得估计量是相合的、渐近有效的。 为了更好地验证所提出方法的有效性,下面再讨论Ⅱ型区间删失数退化为Ⅰ型区间删失数据下的例子。为生成区间Ⅰ型区间删失数据,首先在区间(ac,bc)生成均匀C作为观测时间,通过调整ac、bc的取值控制左删失与右删失的比例。比较失效时间T与观测时间C生成示性变量Δ=I(T≤C)。表3和表4 分别给出协变量在一维和二维情形下,在不同参数真值设置时,样本容量200和600时的模拟结果。结果表明,在Ⅰ型区间删失数据下,得到结论与Ⅱ型区间删失数据的结论是一致的,获得的估计量仍然是相合的、渐近有效的。 表3 Ⅰ型区间删失数据下单个协变量时的模拟结果 表4 Ⅰ型区间删失数据下两个协变量时的模拟结果 将上述模型分别应用到Gómez等[20]研究的艾滋病临床试验数据和Sun[1]介绍的肺肿瘤实验数据中,验证所提方法的有效性。 艾滋病临床试验数据集[17]包括271名艾滋病患者,分为初始核糖核酸(ribonucleic acid,RNA)病毒拷贝数量大于20 000 copies/mL和初始RNA病毒拷贝数量低于20 000 copies/mL的两个分组。为了探索患者的初始RNA病毒拷贝数量对于患者RNA病毒拷贝数量首次低于500 copies/mL时的影响,每位患者进行不同次数的血样采集,次数最多的采集记录8次,最少采集记录1次。根据患者观察记录的时间,可获得患者RNA病毒拷贝数量首次低于500 copies/mL时的观测区间。若第一次观测时发现RNA病毒拷贝数量500 copies/mL以下,则此患者数据可转化为左删失数据;若RNA病毒拷贝数量在500 copies/mL以下出现在某两次观测之间,则此患者数据可转化为区间删失数据;若在最后一次观测RNA病毒拷贝数量在500 copies/mL以上,则此患者数据为右删失数据,因此数据是Ⅱ型区间删失数据。 假设Ti表示实验中患者RNA病毒拷贝数量首次低于500 copies/mL时的时间;定义协变量Zi,若Zi=0,则表示为初始RNA病毒拷贝数量低于20 000 copies/mL的患者,反之Zi=1,则表示为初始RNA病毒拷贝数量高于20 000 copies/mL的患者。分析结果如表5所示。 表5 艾滋病临床试验数据估计结果 图1 RNA数据生存函数的估计 肺肿瘤试验数据集[1]有144只小白鼠试验样本,以天为单位记录了每只小白鼠的准确死亡时间以及死亡时刻小白鼠的肺肿瘤发病情况,是一个经典Ⅰ型区间删失数据的例子。为了探索环境对肺肿瘤发病情况的影响,将96只小白鼠放置在常规环境,另外48只小白鼠放置在无菌环境。假设时间Ti表示小白鼠肺肿瘤发病时间,定义Zi=0表示小白鼠被放置在常规环境,Zi=1表示小白鼠被放置在无菌环境。分析结果如表6和图2所示。 图2 肺肿瘤发病时间的生存函数的估计 表6 肺肿瘤感染数据的估计结果 本研究提出Ⅰ型区间删失数据和Ⅱ型区间删失数据下的Weibull比例优势模型,通过极大似然估计获得了模型的参数估计,并讨论了估计的渐近性质。所提方法能较好地解决风险率函数收敛到常数的情况,同时方法简单易行。由于Weibull分布的灵活性,可以近似各种形态的风险函数,使建立的模型具有较强的灵活性。数值模拟结果表明估计是相合的、渐近有效的。艾滋病临床试验数据与肺肿瘤试验数据的分析结果表明所提方法具有较好的拟合效果。2 Weibull 比例优势模型
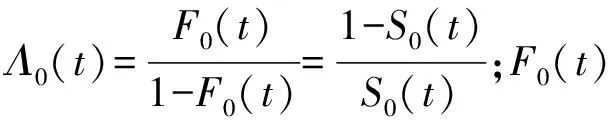
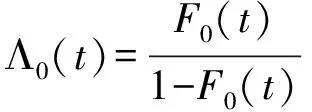
3 区间删失数据下模型的参数估计

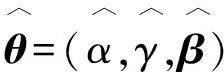
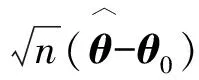
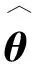
4 数值模拟


5 实例分析
5.1 艾滋病临床试验数据



5.2 肺肿瘤试验数据

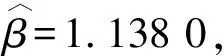
6 结论
