基于对比优化的多输入融合拼写纠错模型
2024-03-02伍瑶瑶黄瑞章白瑞娜曹军航赵建辉
伍瑶瑶 黄瑞章 白瑞娜 曹军航 赵建辉
随着社会发展,涌现出许多与中文文本编辑相关的工作,如企业的合同拟定、公务员的公文撰写及公关声明撰写等.如果在这类文本中出现错别字,会造成不可估量的损失和影响.与自然语言处理(Natural Language Processing, NLP)相关的研究所需的语义信息,依赖于BERT(Bidirectional Encoder Representations from Transformers)[1]、GPT(Genera-tive Pretrained Transformer)[2]和XLNet[3]等对正确文本的语义理解.如果仅通过人工校对不同场景下文本中出现的拼写错误,会降低工作效率,而文本纠错任务在当前工作和科研中显得尤为重要.当前文本生成方式主要有拼音输入、语音输入和扫描输入(Optical Character Recognition, OCR)三种,由这些方式生成的文本容易出现与拼音或字形相关的拼写错误.
目前,中文拼写纠错(Chinese Spelling Error Co-rrection, CSC)是一项具有挑战性的任务.由于对纠错任务的迫切需要,中文拼写纠错的研究经过从基于规则和统计的方法到基于机器学习和深度学习方法的不断发展.Chang等[4]和Chu等[5]针对中文文本中的不同错误设计不同的纠错规则,但是基于规则或统计的方法缺乏对句子上下文的语义理解.Wang等[6]引入的条件随机场(Conditional Random Field, CRF)和Zhang等[7]引入的隐马尔可夫模型则与机器学习相关.Wang等[8]将中文拼写纠错任务看作一个序列标注问题,并使用Bi-LSTM(Bidi-rectional Long Short-Term Memory)预测句子中的正确字符,由此说明深度学习算法在中文拼写纠错领域的有效性.
随着大型预训练语言模型取得成功,各种相关的拼写纠错方法相继出现.Zhang等[9]提出Soft-Masked BERT,利用错误检测和错误纠错两阶段式的级联架构进行中文拼写纠错.Wang等[10]提出自回归指针网络,可从混淆集而不是整个词汇表中生成一个汉字.针对混淆集中候选字符的选择方式,Cheng等[11]提出SpellGCN(Spelling Check Convo-lutional Graph Network),将图卷积网络在音近和形近混淆集上对字符相似度进行建模.但是,因为混淆集不能涵盖所有的相似关系,所以文字特征嵌入也成为一种提高CSC性能的方式.Huang等[12]提出PHMOSpell(Phonological and Morphological Knowle-dge Guided Chinese Spelling Check),可分别从发音和视觉两个模态获得汉字的拼音和字形表示,以此提升CSC在多模态下的性能.Wang等[13]提出DCN(Dynamic Connected Networks),先通过拼音增强候选汉字生成器生成候选汉字,再基于注意力网络对两个相邻汉字之间的依赖关系进行建模.Xu等[14]直接利用汉字的多模态信息,提出REALISE(Read, Listen, and See),捕获汉字的语义、语音和图形信息以及有选择地融合这些信息,用于预测句子.Li等[15]提出LEAD(CSC Models to Learn Heterogeneous Knowledge from the Dictionary),除了引入语音和视觉方面的特征以外,还将文字的字典解释含义融入CSC任务的参考信息中.根据字典中字符语音、字形和定义的知识构建正样本和负样本,再采用统一的基于对比学习的训练方案对CSC的表示进行细化.
随着中文拼写纠错模型性能的不断突破以及对中文文本特征嵌入的不断钻研,为了进一步提升模型性能,模型优化成为一种常见的方式.Li等[16]提出能不断识别模型的弱点并产生更有价值训练实例的方法,不断生成对抗性示例添加到训练集中.Li等[17]提出ECOPO(Error-Driven Contrastive Probabi-lity Optimization),改进预训练语言模型的知识表示,并引导模型通过错误驱动的方式预测候选字的特征.
综上所述,现有的中文拼写纠错模型大多是单输入模型,获得的语义信息仅来自单个句子.由于中文文本构成的复杂性(通常由字组词到造句成段),在实际纠错任务中,单输入模型在学习句子语义时容易被句子中的错误字符误导.学到的语义信息具有局限性并缺乏可靠性,最终导致其不能完全纠正句子中的错误或过度纠正句子,即将错误句子预测成一个其认为更正确但是与目标不符的句子.此外,序列到序列的纠错模型相当于执行从错误句子到正确句子的翻译任务.在此过程中模型平等关注句子中的每个字符,当句子中存在多个错误字符时,由于输入句子的语义信息缺乏可靠性,仅依靠模型进行一次纠错,难以将句子中的错误字符完全纠正,纠错结果缺乏完整性.因此,在模型执行纠错任务时,为模型提供更充分、可靠的语义信息,使模型能进行完善的语义理解并避免过度纠正句子,提升纠错结果的完整性是当前亟待解决的问题.
本文提出基于对比优化的多输入融合拼写纠错模型(Multi-input Fusion Spelling Error Correction Mo-del Based on Contrast Optimization, MIF-SECCO),包含多输入语义学习阶段和对比学习驱动的语义融合纠错阶段.在多输入语义学习阶段,首先集成多个现有的单输入模型,有效利用不同模型的纠错特性,获得多个语义之间互补的初步纠错结果,初步降低错误字符对句子语义的误导.然后使用Transformer[18]对多个纠错结果进行语义学习,为MIF-SECCO执行多语义融合纠错任务提供多个可靠的互补语义信息.在对比学习驱动的语义融合纠错阶段,首先基于对比学习的方法,将语义学习后的句子语义表示与其对应的正确句子语义表示进行对比学习优化,最大化它们语义之间的相似性,在克服错误字符语义误导的同时缓解MIF-SECCO对错误句子的过度纠正.最后融合前序多个优化后的互补语义,对错误句子进行再纠错,进一步保证纠错的完整性.此外,多语义融合改善单输入模型语义局限性和缺乏可靠性的问题,进一步提升纠错性能.在公开的错别字数据集SIGHAN13、SIGHAN14、SIGHAN15上的实验表明,MIF-SECCO可有效提升纠错性能.
1 基于对比优化的多输入融合拼写纠错模型
本文提出基于对比优化的多输入融合拼写纠错模型(MIF-SECCO),模型架构如图1所示.
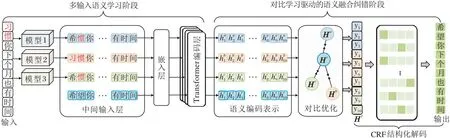
图1 MIF-SECCO架构图
1.1 多输入语义学习阶段
为了降低错误字符对句子语义的误导并为MIF-SECCO执行语义融合纠错任务提供多个可靠的互补语义信息,多输入语义学习阶段主要起到两个作用:1)集成多个现有单输入模型的语义之间互补的初步纠错结果;2)利用Transformer对前序的多个纠错结果进行充分的语义学习,为语义融合纠错任务提供更充分、可靠的互补语义信息.
本文以集成3个单输入模型为例对多输入语义学习阶段的工作原理进行详细阐述.具体地,在多输入语义学习阶段,给定一个包含n个字符的、有拼写错误的句子
X={x1,x2,…,xn},
首先分别集成3个单输入模型对句子X进行初步纠错,获得3个初步纠错结果:
A={a1,a2,…,an},B={b1,b2,…,bn},
C={c1,c2,…,cn}.
初步纠错过程可形式化为
A=Model1(X)={a1,a2,…,an},
B=Model2(X)={b1,b2,…,bn},
C=Model3(X)={c1,c2,…,cn}.
作为同个输入句子X的初步纠错结果,A、B、C包含互补的语义信息,为MIF-SECCO进行后序语义融合纠错提供更充分、可靠的语义信息.
中文拼写错误包含形近和音近混淆、多音字和字词误用等多种错误类型.由于现有模型的结构以及嵌入特征的不同,各模型对不同错误类型的纠错效果存在差异.集成单输入模型初步纠错结果能有效整合各模型的纠错优势.本文在多输入语义学习阶段,集成DCN[13]、REALISE[14]和LEAD[15]这3个现有的单输入模型,并且,此阶段可根据单输入模型的纠错特性集成不同的单输入模型,以此提升MIF-SECCO的纠错性能.
为了实现对多输入互补语义信息的捕获,该阶段还引入Transformer,对前序纠错结果进行双向语义建模.在单输入模型分别对句子进行初步纠错后,将获得的初步纠错结果A、B、C作为中间输入句子,使用针对中文文本进行预训练的语言模型“BERT-Base-Chinese”初始化嵌入层和Transformer层堆栈进行语义建模,对初步纠错结果进行语义学习,有效降低错误字符对句子语义的误导.具体地,对于前序3个预测结果中的句子
A={a1,a2,…,an},
首先,通过嵌入层获得具体的句子向量:

其中L表示Transformer的层数.最后一层的输出
作为输入句子A的上下文语义表示.同理,句子B和句子C的语义表示Hb、Hc也可通过Transformer进行语义学习得到:
前序语义表示Ha、Hb、Hc分别表示3个句子A、B、C的语义表示.集成3个单输入模型对错误句子进行初步纠错,降低句子中错误字符对句子语义的误导,并利用Transformer对初步纠错结果进行语义学习,获得3个语义之间互补的语义信息,为MIF-SECCO进行多语义融合纠错提供更充分、可靠的互补语义信息.
1.2 对比学习驱动的语义融合纠错阶段
现有的纠错模型大多使用BERT进行句子语义学习,BERT在学习句子语义时,句子语义容易受到错误字符的误导,纠错结果也存在局限性.因此,为了改善现有单输入模型语义信息局限性和缺乏可靠性问题,MIF-SECCO在对比学习驱动的语义融合纠错阶段主要起到两个作用:1)利用对比学习优化的方法优化句子语义信息,最大化前序句子语义表示与其对应的正确句子语义表示之间的相似性;2)融合多个优化后的句子语义信息对错误句子进行再纠错,提升模型纠错结果的完整性,实现纠错性能的提升.
具体地,在训练过程中,同时基于Transformer对正确句子R进行语义编码表示,即
在每个训练步骤中,随机抽取N条数据构成一个批次,针对句子A,这N条数据与其对应正确句子可构成2N个数据样本,对应的语义表示为
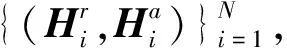
其中,k1=a,r,k2=a,r,i=1,2,…,n,j=1,2,…,n.为了在不损失一般性的情况下,针对句子A,给定第i个样本的损失:

基于对比学习优化的方法优化句子A、B、C的语义信息,将它们的语义表示与对应的正确句子的语义表示进行对比学习,拉近与正确句子语义相似的语义表示,推远与正确句子不相似的语义表示,最大化多个句子语义表示与其对应的正确句子语义表示之间的相似性.
前序三个语义互补的初步纠错结果A、B、C为MIF-SECCO进行语义融合纠错提供更充分、可靠的语义信息.因此,为了改善单输入模型语义信息仅来自单个句子的局限性,在分别对3个句子的语义信息进行优化后,MIF-SECCO对多个互补语义进行融合:
Hf=Fusion(Ha,Hb,Hc)=
(Add(Ha,Hb,Hc)Wf)+bf,
其中,Add(·)表示3个互补语义信息的融合,Wf表示可学习的权重,bf表示偏置参数.多个互补语义融合可为MIF-SECCO进行拼写纠错提供更充分的语义信息.进行语义融合之后获得的语义表示向量Hf可直接通过softmax(·)计算第i个字符的概率分布:
P(yi)=softmax(Wohi+bo),hi∈Hf,
其中,Wo和bo为可学习网络参数,
yi=arg max(P(yi)),
为基于字符的概率分布直接推断的字符.MIF-SECCO最终的预测结果为:
Y={y1,y2,…,yn}.
此过程中本文采用极大似然估计进行参数学习,并将负对数似然函数作为损失函数.考虑到输入句子中包含的错误字符占少数,引入焦点损失惩罚,解决句子中字符不平衡问题,最终的优化目标为:
其中,γ1=0.5,表示控制惩罚权重的超参数.
本文在解码过程中引入Sun等[19]基于CRF的结构化解码模块,综合考虑句子相邻字符之间的关系,预测一个最优结果.对于给定的句子X,在CRF框架下,长度为n的目标序列Y的似然函数为:
Pcrf(Y|X)=
其中,Z(X)表示归一化因子,s(yi,x,i)表示yi在位置i处的标签得分,t(yi-1,yi,x,i)表示yi-1到yi的过渡得分.此模块使用负对数似然损失与神经网络进行端到端的联合训练,同时也引入焦点损失惩罚,解决句子中字符不平衡问题,最终的优化目标为:
lcrf=-(1-Pcrf(Y|X))γ2lnPcrf(Y|X),
其中,γ2=0.5,表示控制惩罚权重的超参数.
1.3 总体优化目标
MIF-SECCO在多输入语义学习阶段,集成多个单输入模型,对句子进行初步纠错,并利用Transfor-mer对多个语义之间互补的纠错结果进行语义学习,为MIF-SECCO进行多语义融合纠错提供更充分、可靠的互补语义信息.在对比学习驱动的语义融合纠错阶段,利用对比学习优化的方法,最大化前序多个句子语义表示与其对应的正确句子语义表示之间的相似性,并融合多个互补的句子语义信息,综合推理一个更具可靠性的结果.总之,MIF-SECCO的总体优化目标:
l=(lpredict+lcrf)+λlcontrastive.
其中:lpredict+lcrf表示一个整体,共同实现纠错模型训练过程中的参数优化目标;λ表示对比学习语义优化目标lcontrastive的权重,主要发挥两个优化目标之间平衡因子的作用.
2 实验及结果分析
2.1 实验设置
本文在训练时使用SIGHAN13[20]、SIGHAN14[21]、SIGHAN15[22]数据集的训练集以及271 329个由Wang等[8]自动生成的样本(简记为Wang271K)作为训练集.在测试时,使用SIGHAN13、SIGHAN14、SIGHAN15数据集的测试集.数据集的统计信息如表1和表2所示.
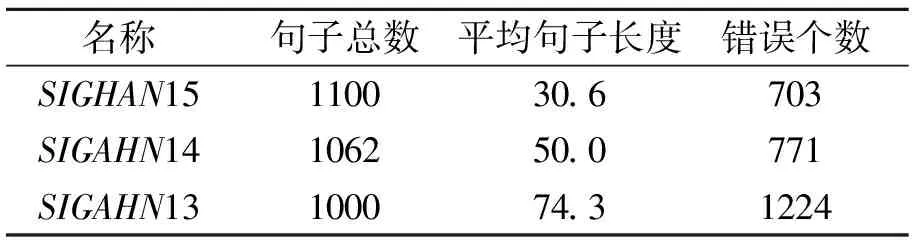
表2 测试集统计信息
本文使用针对句子级别的准确性(Accuracy)、精确性(Precision)、召回率(Recall)和F1值评估模型在句子错误检测和错误纠错两个级别的性能.4个指标的计算公式如下:
其中,tp表示正样本被预测为正类的数量,tn表示负样本被预测为负类的数量,fp表示负样本被预测为正类的数量,fn表示正样本被预测为负类的数量.
实验中各单输入模型的训练参数设置与原文献的参数设置保持一致.MIF-SECCO参数设置与BERT-Base-Chinese相同,最后根据实验环境和调优过程调整训练批次大小和迭代次数,最终确定的模型具体训练参数设置如表3所示.

表3 模型训练参数
实验过程使用的CPU为Intel(R) Xeon(R) Platinum 8370C,内存为48 GB,GPU为A6000.代码开发环境为PyCharm(2021.3.2),使用的深度学习框架为PyTorch(1.9.0+cu111).
2.2 对比实验
为了验证MIF-SECCO在中文拼写纠错任务中的有效性,分别选择2020年至2022年的6个基线模型与MIF-SECCO进行性能对比.
1)Soft-Masked BERT[9].提出一种神经体系结构,解决BERT错误检测能力较弱的问题.由一个基于Bi-GRU(Bidirectional Gate Recurrent Unit)的错误检测网络和一个基于BERT的错误校正网络组成,前者通过Soft-Masking技术与后者进行连接.
2)SpellGCN[11].通过专门的图卷积网络,将字符的语音和视觉相似性知识纳入中文拼写纠错模型中,利用音近和形近混淆集对字符之间的关系进行建模,合并到BERT的纠错模块中开展纠错任务.
3)DCN[13].通过拼音增强候选汉字生成器生成候选汉字,再利用基于注意力的网络对相邻汉字之间的依赖关系进行建模.
4)REALISE[14].基于汉字多模态信息融合的中文拼写纠错模型,通过语义、语音和图形3个编码器捕获输入字符的对应信息.使用的多模态信息融合机制可控制3种模态特征中参与融合的信息量.
5)LEAD[15].中文拼写纠错框架,使中文拼写纠错模型从语音、字形和定义3个维度学习字典中的异构知识,并基于这些知识构建正负样本,采用统一的基于对比学习的训练方案对模型的表示进行细化.
6)SCOPE(Spelling Check by Pronunciation Pre-
diction)[23].基于共享编码器的中文拼写纠错模型,建立两个编码器,一个用于主CSC任务,另一个用于细粒度辅助CPP(Character Pronunciation Prediction)任务,并采用一种自适应加权方案平衡两个任务.
6个基线模型和MIF-SECCO在错别字数据集SIGHAN13、SIGHAN14、SIGHAN15上测试对比结果如表4~表6所示,表中黑体数字表示最优值.由表可知,在错误检测和错误纠正两个级别,对于6个基线模型,SCOPE在SIGHAN13、SIGHAN14数据集上表现最优,LEAD在SIGHAN15数据集上表现最优.MIF-SECCO在SIGHAN13、SIGHAN14、SIGHAN15数据集上的F1值分别比次优方法提升0.9%、1.9%和2.9%,由此表明MIF-SECCO的有效性.
但是,MIF-SECCO仍然存在不足,由表4~表6可知,为了实现多个互补语义的融合纠错,同一错误句子经过多个单输入模型初步纠错阶段和互补语义融合纠错阶段,存在句子在经过单输入模型初步纠错后,在互补语义融合纠错阶段,多个句子语义融合后可能将该句子推测成原句的情况,导致MIF-SEC-CO的召回率低于单输入模型的召回率.同时MIF-SECCO在SIGHAN13、SIGHAN14数据集上的准确性低于REALISE.但综合来看,相比6个基线模型,MIF-SECCO依然实现纠错性能的提升.

表4 各模型在SIGHAN15数据集上的指标值对比

表5 各模型在SIGHAN14数据集上的指标值对比
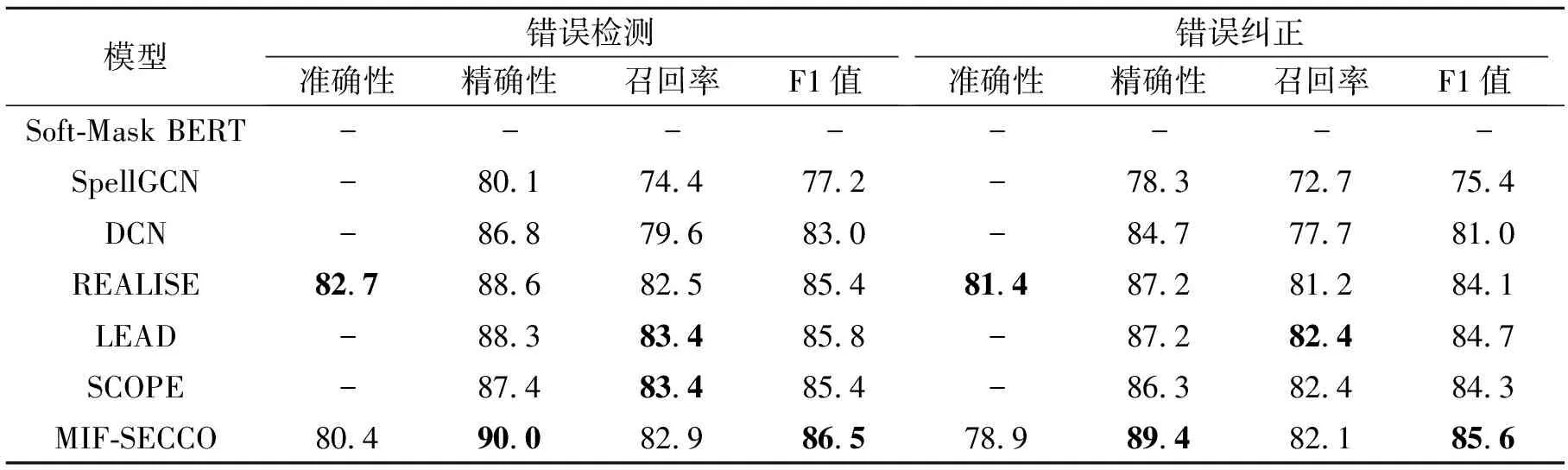
表6 各模型在SIGHAN13数据集上的指标值对比
2.3 消融实验
为了验证MIF-SECCO的有效性以及各模块存在的合理性,在MIF-SECCO的多输入语义学习阶段和对比学习驱动的语义融合纠错阶段进行消融实验.
在多输入语义学习阶段,分别给出3个单输入模型DCN、REALISE和LEAD在语义之间互补的初步纠错结果.再给出仅使用两个单输入模型进行初步纠错的结果.在对比学习驱动的语义融合纠错阶段,给出直接集成的结果.上述消融实验只要预测结果与正确句子相同则认为预测结果正确.
各方法在SIGHAN15数据集上的F1值对比如表7所示.
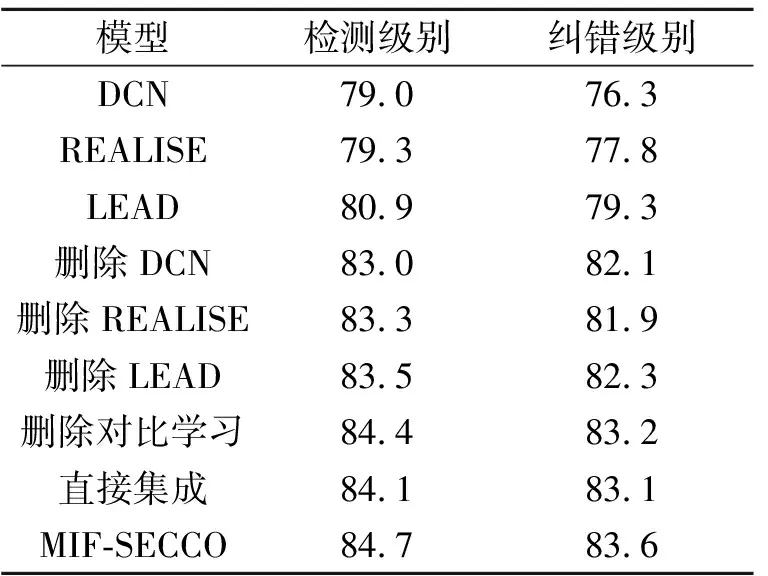
表7 各模型在SIGHAN15数据集上的F1值对比
由表7可见,仅融合两个纠错结果的互补语义时的纠错F1值低于MIF-SECCO的F1值.同时,当融合两个纠错结果的互补语义时,相比单输入模型,F1值提升3.0%.如果仅是对三个纠错结果进行直接投票集成,集成结果降低0.5%.如果未使用对比学习对多个句子语义进行优化,F1值达到83.2%,当使用对比学习优化并融合三个初步纠错结果的互补语义信息进行纠错时,F1值可达到83.6%.结合上述分析可见,MIF-SECCO综合提升纠错性能.
2.4 平衡因子取值分析
总体优化目标中设置的对比损失权重参数λ可作为总体优化目标中对比学习语义优化目标lcontrastive和模型的纠错任务参数优化目标lpredict+lcrf之间的平衡因子.本文定义λ=0.1,1.0,10,100,验证其在总体优化目标中发挥的作用,具体F1值对比如图2所示.
从平衡因子发挥作用的维度分析,当λ=1.0,100时,纠错F1值相近.主要原因在于当λ=1.0时,MIF-SECCO参数优化目标lpredict+lcrf的优化作用大于对比学习语义优化目标lcontrastive的优化作用.而当λ=100时,对比学习语义优化目标lcontrastive的优化作用大于纠错模型参数优化目标lpredict+lcrf的优化作用.当λ=10时,两个优化目标相对平衡并且都发挥较好的优化作用,因此在3个公开的数据集上,当λ=10时,MIF-SECCO的纠错F1值最高.

图2 不同λ对MIF-SECCO性能的影响
从语义优化的维度分析,本文使用对比学习作为模型语义优化的方法,但是关于正负对的构造过程依然采用在批量数据中依次构造正负对的简单方式,未对负例进行进一步语义级别的筛选,可能存在一定的噪音.因此当对比优化目标的权重λ取值发生变化时,MIF-SECCO在SIGHAN13、SIGHAN14、SIGHAN15数据集上的纠错F1值的变化趋势相对平缓.但是根据消融实验可知,对比学习在语义优化的过程中依然发挥一定作用.
2.5 语义融合策略分析
在拼写纠错任务中,模型获取有用句子语义信息越充分,越有助于模型进行错误纠正.因此,本文分别两两组合集成不同的单输入模型和同时集成3个单输入模型,对句子进行初步纠错,并融合初步纠错结果的多个互补的句子语义对错误句子进行再纠错,根据模型纠错性能验证语义融合策略的有效性,具体F1值如图3所示.
由图3可见,分别融合两个不同的纠错结果的句子语义和MIF-SECCO的纠错性能存在差异.显然,当融合的语义个数相同时,MIF-SECCO的纠错F1值因为各单输入模型的性能不同而存在差异,主要原因在于不同单输入模型纠错结果的错误分布存在区别,纠错结果语义信息的质量存在差异.当融合三个句子的语义信息时,MIF-SECCO的纠错F1值不仅高于融合两个语义时的纠错F1值,同时高于各单输入模型的纠错F1值.由此说明,进行多语义融合纠错时,融合语义的质量以及语义的数量都会对MIF-SECCO的纠错性能产生影响,这也说明多语义融合纠错的有效性.

图3 语义融合策略对性能的影响
2.6 泛化性能分析
由于中文文本错误的复杂性,通用的拼写纠错模型应具备优异的泛化性能.为了验证MIF-SECCO的泛化性能,构造不同的训练集训练模型.通过去除SIGHAN15数据集的训练集以构造MIF-SECCO和3个单输入模型的训练集,并利用训练的模型在SIGHAN15数据集的测试集上进行测试.当训练集上不包含SIGHAN15数据集时,MIF-SECCO的检测F1值和纠错F1值分别为84.1%和82.9%,训练集上包含SIGHAN15数据集时,MIF-SECCO的检测F1值和纠错F1值分别为84.7%和83.6%,相比不包含SIGHAN15训练集时F1值,仅降低0.6%和0.7%.并且,相比6个基线模型,当训练集上不包含SIGHAN15训练集时,MIF-SECCO在SIGHAN15测试集上的纠错F1值依然实现2.2%的提升.由于SIGHAN15数据集的训练集上包含2 338个句子,训练集的数量也是影响方法性能的因素,因此验证MIF-SECCO具备较优的泛化性能.这得益于MIF-SECCO包含单输入模型初步纠错阶段和多语义融合纠错阶段,这两个纠错阶段在句子纠错过程中相互补充,不仅弥补单输入模型初步纠错的不足,还进一步保证整个句子纠错的完整性.
2.7 案例分析
MIF-SECCO包含多输入语义学习阶段和对比学习驱动的语义融合纠错阶段,分别涵盖单输入模型的初步纠错和多语义融合纠错两个纠错过程.
如表8所示,利用单输入模型对“原句”进行直接投票集成的纠错结果缺乏完整性.同时,如果利用MIF-SECCO,在多输入语义学习阶段,对3个语义互补的初步纠错结果进行语义学习,并在对比学习驱动的语义融合纠错阶段对语义进行对比学习优化后执行互补语义融合纠错,最终实现“原句”的完全纠正.由此表明互补语义融合纠错可保证纠错的完整性,提升纠错性能.

表8 互补语义融合纠错示例
3 结 束 语
针对文本编辑过程中出现的拼写错误,现有的中文拼写纠错模型大多为单输入模型,由于单输入模型仅有一个输入句子,只能获取单个句子的语义信息,纠错结果存在局限性.此外,当句子中存在多个错误字词时,纠错结果缺乏完整性.本文提出基于对比优化的多输入融合拼写纠错模型(MIF-SEC-CO),包含多输入语义学习阶段和对比学习驱动的语义融合纠错阶段.在中文拼写纠错公开的数据集SIGHAN13、SIGHAN14、SIGHAN15上的实验表明,MIF-SECCO可有效提升纠错性能.今后可考虑引入更多语义理解的神经网络进行充分语义学习,并开展对比学习中的负例筛选工作,进一步提升模型错误句子的召回率,同时在多输入语义学习阶段进行参数共享等,进一步提升纠错性能.
