融合信息对抗及混合特征表示的社交网络谣言检测方法*
2024-03-01朱贺
朱 贺
(河南师范大学图书与档案信息中心 新乡 453007)
0 引 言
线上社交网络为信息的传播提供了快速的传播通路,而谣言作为信息的一种特定存在形式,自然也包括其中。谣言传播造成了巨大的经济损失,同时也给社会的平稳运行提出了严峻的挑战。在新冠疫情的背景下,多种涉及民生事件的谣言被居心不良的个人或者团体捏造并传播,对社会和谐、民心安定和政府治理造成了巨大的负面影响。谣言的传播已经成为了一项社会问题,相关领域的研究必须给与足够的重视。
现有高性能的谣言检测方法大多建立在广泛的特征提取和大规模的数据分析上,此类方法在一定程度上提高了谣言检测的效率和精度,使得在大规模传播事件中实现对谣言的甄别成为了可能。然而,需要指出的是,网络环境并不是“一尘不染”的,在广泛的自由互动的背景下,舆情参与个体变得更加复杂,舆情事件中往往也会包含着一定量的虚假评论或恶意陈述。遗憾的是,数据驱动的谣言检测方法并未对舆情信息中充斥着的各种“噪声”做出应有的应对,这也就限制了谣言检测精度在当前日益复杂的舆情传播背景下进一步的提高。
基于此,本研究提出了一种融合信息对抗及混合特征表示的社交网络谣言检测模型,从而在现实情形中广泛存在不实表达的背景下,增强模型对于“噪声信息”的容抗性,提高谣言检测的准确度。本模型利用混合特征呈现的方法,从传播时序和扩散结构双重维度来解析舆情事件,提取抽象化的高维谣言鉴别变量,克服了单一考虑“树形拓扑”或者“时序依存”时特征呈现不充分的缺点。此外,借助于信息对抗,在网络构建及学习过程中,采用竞争机制,利用舆情评论数据生成对抗性的虚拟噪声声音,推动谣言鉴别器在成功识别提取的混合谣言特征的同时,不断对生成的对抗性声音做出有利于正确识别谣言方向的应答,达到同步提升模型谣言检测精度和噪声容抗性的目的。
1 相关研究
现代谣言检测研究的重点在于适用于大规模且自动化的舆情处理,受益于人工智能技术的发展,线上社交网络上舆情信息的即时识别变得不再遥不可及[1-2]。一部分学者认为,谣言同真实信息之间存在着一些显性的,诸如在语法、句法、词汇或者情感表达等特征标志位的不同,而这些标志位的特征差异正可被利用作为识别谣言的依据[3-5]。Gupta等[6]从发布的舆情信息中提取了一个多达45个标志位的谣言特征集,建立了一个即时的评估线上舆情可信性的分析系统。Popat[7]提出了一类包含“断言性短语”“词语符号”“主观判断”等变量的谣言判定特征集,并比较了在不同特征集组合下的谣言检测效果。为了提高谣言的识别效果, Yang[8]和Sun[9]在谣言特征标志集中进一步加入了对谣言发布个体特征的描述,实现了对谣言特征更加全面的呈现。这些基于特征的谣言鉴别方法为自动化谣言检测提供了可能性,然而在任务前期却需要耗费大量的人力进行特征的筛选,提高了谣言鉴别的成本。此外,在现实情形中,不同平台、不同兴趣群的社交群体之间的信息交互方式是不同的,这就要求基于特征的谣言鉴别针对不同的平台设计不同的特征集,而这也就限制了此类方法跨平台的泛化能力。
机器学习特别是深度学习技术的发展促进了数据驱动的谣言检测方法的研究。得益于智能化的信息分析流程,数据驱动的谣言检测不再需要依赖于前期大量的人工特征提取,真正实现了谣言检测方法的自动化,提升了其跨平台的适用性[10-13]。为了降低话题偏移对突发性事件中谣言检测精度的影响,Alkhodair等[13]提出了一个基于word2vec和循环神经网络RNN的融合监督及非监督性学习过程的谣言检测模型。Ma等[14]提出了两类“自上而下”和“自下而上”的树形结构递归神经网络来呈现谣言传播过程中相关信息之间的层级结构关系,同时,在其随后的研究工作中[15],注意力机制也被融入到了树形结构的构建过程中,提高了关键性谣言检测信息点的识别。刘勘等[16]基于双层LSTM及迁移网络,分析并提取了用户及传播特征,提出了一种在无标注数据情况下的跨领域谣言检测策略。上述数据驱动的方法提高了谣言检测的准确性,但却只考虑了谣言传播的时序或结构特征,缺少了更加全面的混合特征的呈现。同时,现有的数据驱动方法也没能对现实情形中广泛存在的“噪声”信息做出充分的应对,而这也就进一步限制了此类方法在谣言检测效果上的提升。
生成对抗网络GAN在其提出之初就引起了学术界和业界极大的关注,被广泛的应用于图像和视频生成等非监督性学习任务之中。在“生成器”和“鉴别器”之间的对抗学习机制的作用下,生成对抗网络变得有能力提取出原本不易被学习或者提取出的“非显性特征”。为了将适用于非监督学习的生成对抗网络移植到监督学习的谣言识别任务中,Ma等[17]首次提出了信息对抗的概念,他们利用基于循环神经网络RNN的生成器产生争议性的对抗言论,从而给鉴别器更大的压力使其更好的识别谣言文本中具有指示性的辨别特征。孟佳娜等[18]基于对抗神经网络提出了一个混合文本信息以及图片信息的跨模态谣言检测模型,提高了谣言检测的特征迁移能力。Cheng等[19]建立一个具有智能化自学习能力的谣言信息输入序列修正模型,他们提出的基于GAN的模型框架很好地解决了谣言识别过程中“谣言”和“非谣言”数据的不平衡性。基于对抗学习的谣言检测方法加强了对谣言数据中“噪声”信息的处理能力,然而,由于生成对抗网络对于非监督学习的特异性,其模型关注的重心落在生成器而不是鉴别器上,生成器的对抗机制必然会降低鉴别器的鉴别效果,这就要求在针对有监督任务时对鉴别器应做额外的加强处理,但遗憾的是,上述研究却没能给出有效的解决。
2 融合信息对抗及混合特征表示的社交网络谣言检测方法
本研究提出的融合信息对抗及混合特征表示的谣言检测方法(简称IHCR,代指Information-campaign and Hybrid Characteristic Representation)在整体上可以看作是一个具有部分参数共享的“双步”模型:在“第一步”中,为了提升对噪声信息的容抗性,本模型借鉴了Wasserstein GAN(WGAN)[20-21]以及Auxiliary Classifier GAN(ACGAN)[22]的模型构建思想,提出了监督性学习任务背景下的生成对抗网络,实现了针对谣言信息流的信息对抗机制;此外,考虑到谣言特征识别的全面性,在本步中,生成对抗网络中的“生成器”模块将被特别加强,通过融合图卷积网络GCN[23]以及双向门循环网络Bi-GRU,实现谣言信息中的传播结构特征和时序依赖特征的混合提取。考虑到生成对抗网络在模型构建思想上对于鉴别效果的抑制作用,直接使用第一步“鉴别器”的输出作为谣言推断的依据将会提高谣言误判的可能性,因此,本模型特别引入了“第二步”基于自注意机制self-attention的判别网络:此步中的网络一方面接受“第一步”中提取的混合特征,维持信息对抗机制;另一方面,对“鉴别器”做进一步的加强处理,从而在保证噪声容抗性的同时,从整体上提高谣言鉴别的准确性。模型的整体结构如图1所示。
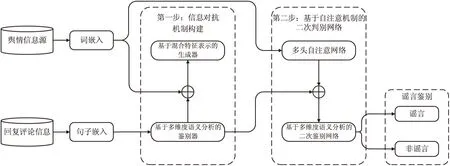
图1 模型整体框架图
2.1 信息对抗机制的构建
本模块对应于本研究提出的“双步”模型的第一步。在本模块中,我们将结合WGAN和ACGAN,提出适用于谣言检测任务的有监督学习背景下的信息对抗机制:利用加强的具备混合特征提取的生成器,产生对抗性的虚拟声音参与训练,从而提升模型对 “噪声”的容抗性。需要强调的是,区别于其他基于GAN的模型,本研究提出的方法不再使用随机数据产生对抗性样本,而是使用真实舆情事件的回复评论数据。图2是基于一则从“医保缴费信息”引发的新浪微博舆情事件中提取的抽象化的传播网络示意图(截取部分信息)。 图2中所有信息相对于时间轴的先后次序蕴含了舆情传播网络的时序特征;同时,回复评论信息相对于信息源的不同位置构成了多层级的拓扑网络。图中在各个信息节点上人为加入了自连接环,目的在于后续结构特征的分析及提取。本模块将依据此抽象化的传播网络图提取舆情信息的结构特征以及时序特征,并加以融合。

图2 抽象化的传播网络示意图
2.1.1基于混合特征表示的生成器
在本部分中,我们将利用回复评论数据生成对抗性的虚拟声音,相关网络结构如图3所示。为了表述的简洁性和清晰性,下述的回复评论数据均代指已经利用句子嵌入Sentence Embedding方法映射到句子表示空间的高维向量。

图3 基于混合特征表示的生成器结构图
a.舆情信息结构特征提取:依据舆情事件相关的回复评论数据建立传播网络,网络中的节点为回复评论信息,连边根据回复评论之间的层级关系建立。再在生成的传播网络的节点上加入自连接环,得到最终关于回复评论信息的关系网G。
依据建立的信息关系网G生成邻接矩阵A和节点的度矩阵D。为了提取直接相邻节点之间的结构信息,我们需要采用单层的图卷积操作
(1)

(2)
其中W2为第二层的可学习权重,L2即为最终提取的舆情信息结构特征。
b.舆情信息时序特征提取:考虑到时序特征提取的效果以及网络结构的简单性,我们选择利用门循环网络GRU来分析回复评论数据之间的时间依赖关系。
令xt表示一个回复评论数据流在t时刻对应的信息,那么,GRU网络中相关变量的更新将遵循以下公式
(3)

上述操作可以提取正向舆情信息流的时序特征,然而,在谣言检测的实际操作中仅仅依赖正向的时序特征往往是不够的。因此,我们进一步加入了反向舆情信息流的时序特征提取操作。通过堆叠正反向的GRU网络,最终可以得到双向的深度Bi-GRU网络,连接其输出的正向及反向时序特征,即可得到最终在整体上的时序特征表示ha,t。
c.结构特征和时序特征融合:采用公式(3)所述的更新规则,将结构特征L2映射为hb,t,其维度和ha,t完全一致。为了实现融合结构特征和时序特征时权重的自动调整,我们利用Attention机制,其Attention权重α通过以下公式计算
(4)
其中,γ和Wh是注意力网络中待学习的参数。那么得到的融合特征为
(5)
为了产生类似舆情信息源的对抗性声音,我们需要利用反卷积操作,将句子空间表示的ht映射到词表示空间内
(6)

2.1.2基于多维度语义分析的鉴别器
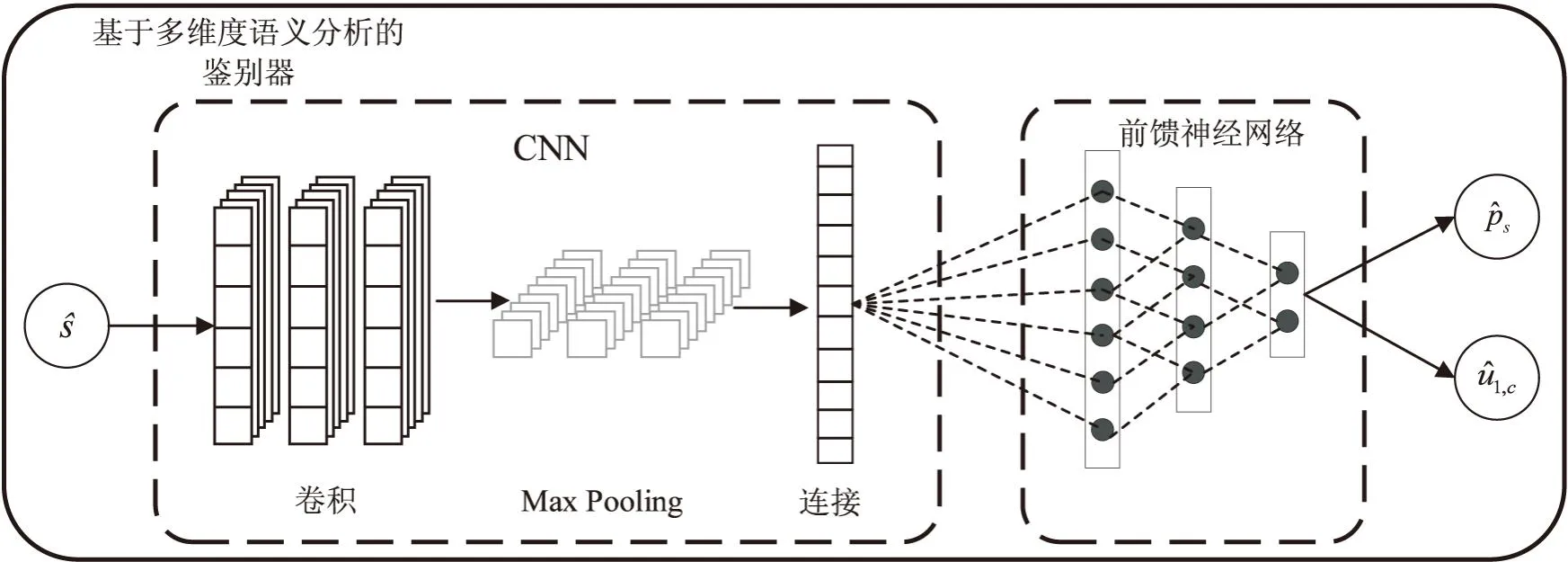
图4 基于多维度语义分析的鉴别器结构图
对于三个卷积层,输出通道数被固定为相同的值,其卷积过程通过以下公式实现:
(7)
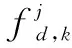
v=Concatenate(v1,v2,v3)
(8)
再将其输入到一个多层的前馈神经网络中:
(9)

2.1.3“第一步”的优化目标
鉴别器的输出包括两类,即判定输入为信息源而不是生成信息的概率,以及舆情信息的谣言分类概率。令Ls和Lc分别表示上述两类概率输出的损失函数,其形式为
(10)
其中Nt为训练样本数,y为训练样本的真实分类。为了提高训练的稳定性,我们借鉴了WGAN中Lipschitz约束的使用,在随机样本的梯度范数上添加了一个正则化项
GP=
(11)

那么,对于生成器其优化目标为最小化Lc-Ls,对于鉴别器其优化目标为最小化Lc+Ls+GP。在此优化目标的作用下,生成器将持续向迷惑鉴别器的方向优化,同时,鉴别器也将在保证谣言鉴别准确率的前提下,不断深挖非显性的谣言特异特征。
2.2 基于自注意机制的二次判别网络

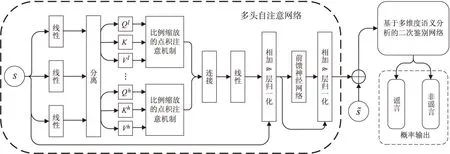
图5 基于自注意机制的二次判别网络结构图
2.2.1混合自注意机制的判别网络
自注意机制的引入目的是为了进一步提取舆情信息源s中隐藏的高维特征信息。对于一个具有h个Head的多头注意力(Multi-head Self-attention)网络,使用Qj,Kj和Vj分别代表第j个Head的Query,Key和Value矩阵,他们的计算方法为
(12)
(13)
其中,d是比例缩放系数。连接所有Head输出的特征,可以得到整体的多头注意输出Z'
Z'=Concatenate(Z1,Z2,…,Zj)WZ
(14)
其中,WZ是自学习权重。为了防止原始输入信息过多的特征丢失,我们在自注意网络中使用了残差连接,进一步使用layer normalization后,输出变为
Z=Layernorm(s+Z')
(15)
参照Transformer[27]中的方法,我们将多头注意力网络的输出同一个全连接的前馈网络相连,同时保留残差连接和layer normalization,得到的输出为
Oatt=Layernorm(Z+ZWf+bf)
(16)
其中,Wf和bf分别是前馈网络的权重及偏置矩阵,Oatt即为从舆情信息源s提取的多维度特征矩阵。
2.2.2“第二步”的优化目标
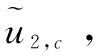
(17)
其中,μ是一个超参数,用于调整从原始信息源和生成的对抗性声音中习得知识的权重。
我们使用交叉熵作为“第二步”模块的优化目标,其包括两部分:对于原始信息源的损失评估以及对于生成的对抗性声音的损失评估
(18)
3 实验与分析
为了验证本研究提出的模型(简称IHCR),在此部分中我们将基于公共数据集展开对比实验,证实本模型的谣言检测效果,检验在有噪声数据影响时,本模型对于干扰信息的容抗性。
3.1 实验数据
对比实验将利用在谣言鉴别领域被广泛使用的两个数据集展开,即PHEMEv5[25]和新浪微博[26]数据集。PHEMEv5数据集是在Twitter平台上爬取的关于5类话题事件发表的5 802条相关信息及其后续评论,该数据集信息的承载语言为英文,采集时间为2016年。新浪微博数据集是从新浪微博平台获取的包含多类话题事件的4 664条相关信息及其后续评论,该数据集信息的承载语言为中文,采集时间为2016年。两个数据集中所有的信息都别标记为“谣言”和“非谣言”两者中的一类。两个数据集具体的细节信息在表1中给出,选取这两个数据集的目的是为了验证我们提出的模型跨平台及跨语言的适用性。

表1 PHEMEv5和新浪微博数据集统计信息
3.2 评估指标及主要参数设置
为了全面地体现谣言检查效果,同时方便横向的模型比较,本研究选取了国内、外谣言检测学术界常用并被普遍认可的四个评估指标,即准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1得分四个指标,其计算方法为
(19)
其中,TPc,FPc和FNc分别表示正确预测的正例个数,错误预测的正例个数和错误预测的负例个数。
我们使用PyTorch来实现我们的模型。对于模型中相关参数的选择,本研究进行了大量的对比实验,比较了不同参数设置下谣言检测的效果,并找出了检测效果最优的一组作为最终的参数组合,具体为:词嵌入和句子嵌入维度设定为300,“第一步”模块生成器中的Bi-GRU的隐层数为2并使用Dropout,鉴别器中的CNN的输出通道数为128,后续连接的前馈神经网络的隐层数为4。使用He initialization方法来初始化“第一步”信息对抗模块中的可学习权重,并选用Adam算法来优化损失函数,其超参数为β1=0.5,β2=0.9。在“第二步”二次鉴别模块中,设置自注意的多头数为3,后续全连接的前馈网络的输出维度为256,仍然选用Adam算法来优化第二步的损失函数,此处的超参数为β1=0.9,β2=0.999。两步中的学习率都设置为1e-3,并随着学习过程逐渐下降。实验中各结果通过五折交叉验证得到。
3.3 对比实验选取的参照模型
为了验证本模型的谣言鉴别效果,我们从现有研究中选取了9种具有代表性的模型来进行对比,包括一种传统的基于决策树构建的模型(DT-Rank[27])、一种基于树形传播网络构建的模型(BU-RvNN[14])、两种基于RNN的模型(DA-RNN[28]和GRU-R[26])、两种基于CNN的模型(Text-CNN[29]和TDRD[30])、一种基于混合特征提取的模型(GGNN[31])和两种基于GAN的模型(GAN-GRU[17]和RG-GAN[19]):
①DT-Rank:一种通过分析包含有争议事实的信息来对趋势消息进行分类的决策树模型。
②BU-RvNN:一种基于递归神经网络构建的,通过回溯信息传播路径推断谣言真实性的模型。
③DA-RNN:一种基于循环神经网络的方法,该方法通过识别潜在的时间敏感表征来捕获谣言信息特有的上下文变化。
④GRU-R:一种利用深度堆叠GRU单元构建的,通过在不同时间间隔内聚合判别性特征来鉴别谣言的模型。
⑤Text-CNN:一种基于卷积神经网络的文本分类器,其利用微调技术来学习文本分类任务中的指向性特征向量。
⑥TDRD:一种基于主题的CNN模型,其预测的主题特征被合并到源信息中,从而辅助谣言的检测。
⑦GGNN:一种混合时序和结构特征的谣言检测方法,该方法将GRU和GCN相结合,分析并融合了信息流和层次节点之间的非显性关系。
⑧GAN-GRU:一种基于GAN的谣言检测方法,该方法使用对抗性学习策略施压分类器,以获得更强的谣言指示性表示。
⑨RG-GAN:一种结合了GAN和强化学习的模型,通过有选择的在信息中插入生成的词向量来提高模型对于噪声信息的容抗性。
3.4 谣言检测结果及分析
表2中呈现的是本研究提出的IHCR模型和9种对比实验方法在谣言检测任务上的检测效果。每种检测指标的最优值我们使用粗体字来标示。从表2中可以看出,本研究提出的方法在两种典型的中文及英文语境中均有最好的谣言检测准确率,分别是88.5%(PHEMEv5数据集)和95.7%(新浪微博数据集),相较于对比方法中在谣言检测准确率指标上最好的GGNN分别提升了3.1%和4.1%。观察在“谣言”和“非谣言”分类的下F1得分,本研究提出的方法在两个数据集上相较于所有对比方法均得到了最高的得分,体现出IHCR有能力在谣言的各类别上挖掘并识别出区别于它类的指示性信息特征。

表2 IHCR和对比模型在PHEMEv5和新浪微博数据集上的谣言检测效果
分析表2可知,相较于基于数据驱动的模型,基于特征的DT-Rank的检测效果明显要略逊一筹,在各个指标上的结果几乎都是最低的,反映出基于特征的方法在跨数据集泛化能力上的不足。基于RNN的方法目的在于提取时序特征,而基于CNN的方法分析的重点落在了信息结构特征的挖掘,从表2中可以看到,其识别效果是不及基于混合特征提取的模型GGNN的,而这也是本研究将混合特征表示融入到信息对抗的出发点。GAN-GRU和RG-GAN均是基于对抗生成网络构建,虽然提高了网络对噪声数据的容抗性,但其生成的对抗数据会影响鉴别器的鉴别效果,拉低了谣言分类的准确率,GAN-GRU的准确率仅有78.3%和76.5%,而这也就是本研究构建二次判别网络的动因。
3.5 消融实验分析
为了验证本研究提出模型中各个组成模块存在的必要性,在本部分中我们设计了一系列消融实验,分析在特定组成部分缺失的情况下模型对于谣言检测的效果。各变体模型详述如下:
①w/o GCN:移除“第一步”中生成器中的结构特征提取网络,生成器仅提取时序特征。
②w/o GRU:移除“第一步”中生成器中的时序特征提取网络,生成器仅提取结构特征。
③Random-G:使用随机初始化而不是“第一步”学习得到的生成器作为“第二步”二次判别网络的输入。
④w/o ATT:移除“第二步”中的自注意力网络,仅使用后续连接的和“第一步”鉴别器同构的网络进行谣言判别。
⑤w/o GAN:完全移除“第一步”信息对抗模块,仅使用二次判别网络进行谣言检测。
⑥w/o SEC:完全移除“第二步”二次判别网络,仅使用信息对抗模块进行谣言检测。
消融实验的谣言鉴别效果如表3所示。可以看出,相较于本研究提出的模型完全体,各变体模型在谣言识别的准确率和F1得分上均有了一定程度的降低,反映出所有组成模块都是必要的,任意一模块的缺失都会限制IHCR对谣言特征进行全面分析的能力。特别的,w/o GRU下的谣言检测准确率要明显低于w/o GCN,说明相较于结构特征,信息的时序依存性在谣言检测任务上具有更高的影响权重。Random-G的谣言检测效果在两个数据集上都是最差的,随机初始化的生成器不仅没能提供任何谣言检测的线索,反而对模型产生了误导,这也就从侧面印证了“第二步”继承的从“第一步”习得的生成器的必要性以及正面的促进作用。w/o GAN不尽如人意的谣言检测效果证实了单一的信息对抗机制对于鉴别器输出的抑制作用,而w/o SEC构型下较低的准确率则反映出了信息对抗的必要性。
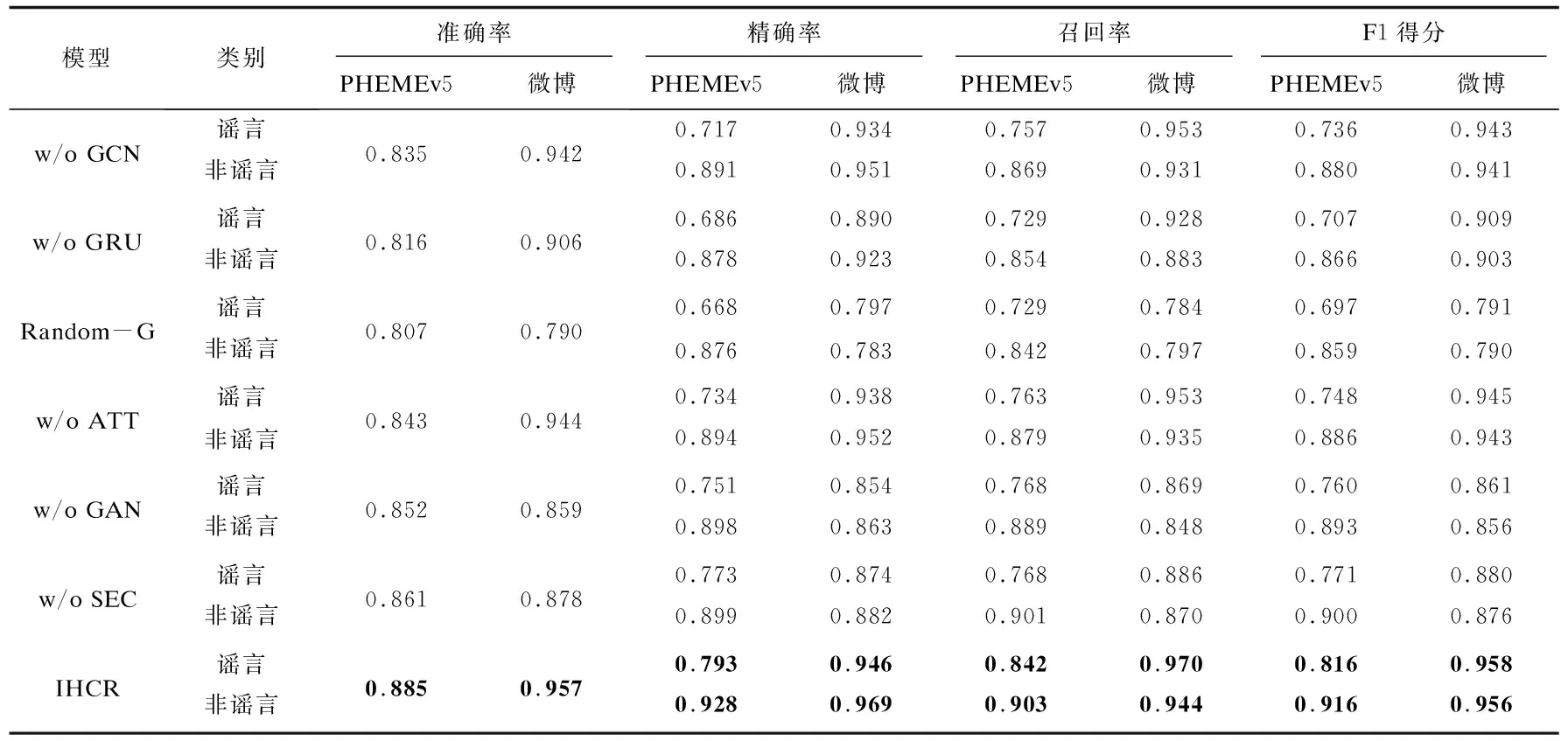
表3 消融实验结果
3.6 噪声容抗性分析
在本部分的实验中,为了分析IHCR对噪声信息的容抗性,我们在PHEMEv5和新浪微博数据集的回复评论信息中人为插入了一定比例的噪声数据,从而研究在噪声信息影响情形下IHCR对谣言的检测效果。我们设计了两种模型训练策略进行比照:策略一是利用混合有噪声的数据集训练整个模型;策略二是利用原始数据训练“第一步”信息对抗模块,再使用混合有噪声的数据集训练“第二步”二次鉴别模块。所有的参数及初始化方法保持和原始设定一致。表4和表5中呈现的是两类训练策略下的谣言检测结果。在策略一下,随着噪声占比的提升,谣言检测效果并没有呈现出单调的下降趋势,谣言检测准确率在整体上比较稳定,这就说明我们提出的模型对于噪声信息并不敏感,具有较好的噪声容抗性。在策略二下,谣言检测效果随着噪声占比的提升而逐渐下降,但是下降的速率并不显著,噪声占比从10%提升到50%,谣言检测准确率仅下降了2.1%(PHEMEv5)和4.1%(新浪微博)。相较于大部分对比实验中的模型,即使在训练策略二下,IHCR仍是具有竞争力的,这就进一步反映出我们提出的信息对抗背景下混合特征表示的有效性。
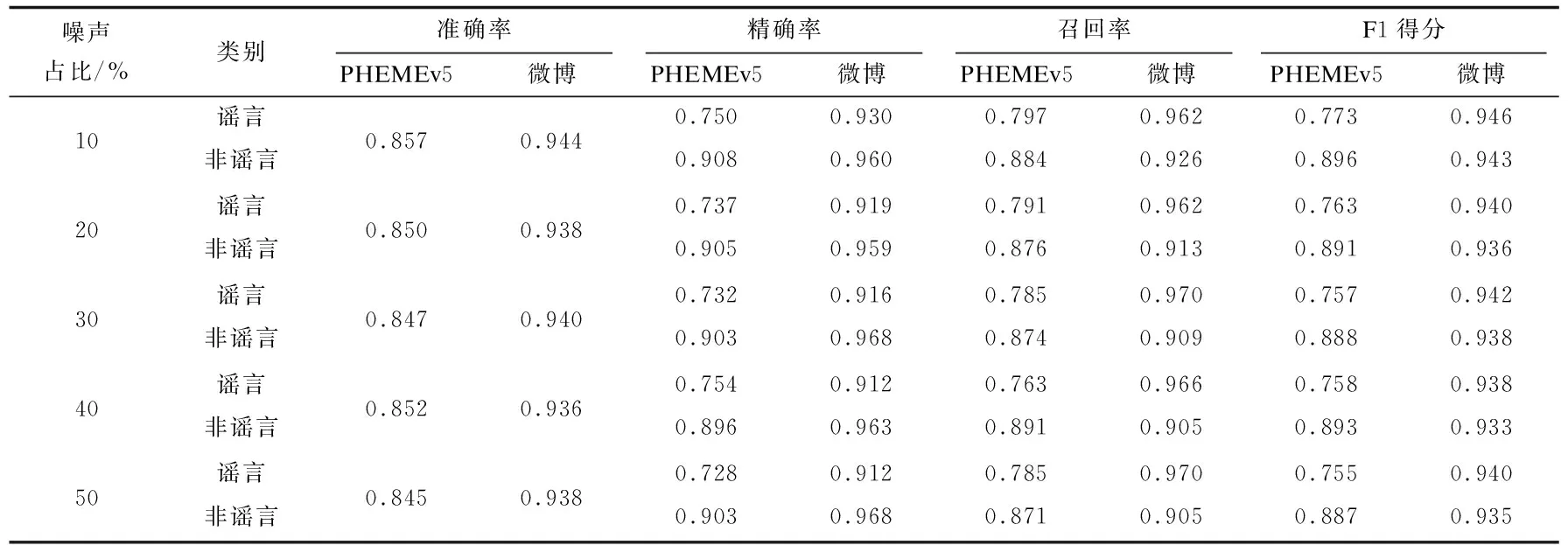
表4 按策略一训练时不同噪声占比情况下的谣言检测效果

表5 按策略二训练时不同噪声占比情况下的谣言检测效果
4 结 语
本研究提出了一种融合信息对抗及混合特征表示的谣言检测模型。区别于现有的直接移植非监督性学习中的对抗生成网络GAN来搭建有监督的谣言检测模型,本研究提出了一种具有部分参数共享的“两步走”模型,从而克服了对抗机制对有监督学习造成的负面影响,实现了在提升检测效果的同时,增强模型对于噪声容抗性的目的。此外,为了进一步赋能信息对抗模块中生成器对于特征的表达,本研究搭建了有机混合时序特征及结构特征的深度网络,实现了对舆情信息在多种维度上的特征呈现。借助于真实的社交网上的舆情信息,本研究比较并分析了提出模型的谣言检测效果,结果表明,在中文及英文语言环境下,本研究提出的模型均有能力在保证低噪声敏感性的同时提升谣言检测的准确率。
