基于贝叶斯随机方法的高原湖泊水位模拟预测
2024-02-21韦彦玲高泽坤顾世祥
韦彦玲,王 飞,陈 晶,高泽坤,高 凯,顾世祥,
(1.云南农业大学城乡水安全与节水减排高校重点实验室,云南 昆明 650201;2.云南秀川水利水电勘察设计有限公司,云南 昆明 650021;3.云南省水利水电勘测设计研究院,云南 昆明 650021)
天然湖泊水位的变化是流域降水、径流、蒸发、气温、风速、水资源管理、湖泊管理等诸多自然-社会二元因素共同作用的结果[1],存在非常复杂的非线性关系和不确定性。建立具有物理意义的数字孪生流域分布式水文模型是无限逼近湖泊水位变化真值的理想化途径。但各类用水消耗等基础资料条件、各个因子变量交互作用刻画都影响到输出结果质量。SVR和BP模型是常用的机器学习模型,可以较好地捕捉湖泊水位复杂的非线性关系[2-3],但无法考虑时序变化[4-5],且多为灰箱或黑箱模型,利用数据值实现,不干扰数据的统计分布和内部关系以及问题的物理性质,容易出现过拟合问题且多不能给出明确的解析表达式[6]。基于Copula的建模方法中,Vine Copula是一种统计动力学模型,可将高维的联合分布分解为二元联结的层次结构,能有效地描述高维变量之间的相依性,并在洪水特征、降雨径流模拟、湖泊水位、干旱预测等成功应用[7-10]。在实际预测中,单一模型预测结果存在较大不确定性,不能充分捕捉数据特征[11],且都有自身的优缺点。为克服单一模型的局限性,国内外学者构建了组合预测模型来整合单一模型发挥优势[5,12-14],但是确定性的组合模型无法定量评估模型结构的不确定性。
贝叶斯模型平均(BMA)是一种基于贝叶斯统计学的模型选择方法,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[15-16]。BMA也被广泛应用于水文学领域,如Wei等基于BMA算法整合不同数据源降水信息,结果表明BMA集成降水产品表现出更好的性能[17]。Yang等通过BMA方法在8个ET模型的基础上对日ET估算改进,结果表明BMA方法优于个体ET模型[18]。俞明哲等利用BMA方法构建全球尺度洪水中长期预报模型,有效减小模型不确定性[19]。周婷等基于BMA方法对ELM、SVM、MARS3种模型的径流预测结果组合,获取可靠的中长期日径流预测结果[20]。然而目前基于机器学习模型和统计动力学模型结合的BMA集成预测长时序湖泊水位的研究较少。本文针对流域各类用水消耗信息缺失条件下,引入贝叶斯随机预测方法,对选择气象水文因素与前1月水位作为变量的Vine Copula、BP和SVR模型的预测结果构建了贝叶斯模型平均(BMA)对长时序湖泊水位进行集成预测,提高预测精度,并以杞麓湖为例检验,以期为湖泊水位调控、干旱预警管理、水生态保护治理等提供参考。
1 材料与方法
1.1 研究区域概况
杞麓湖是云贵高原上一个封闭型高原湖泊,是关系通海县经济和民生的“母亲湖”,为当地周边农业提供灌溉,具有调蓄、防洪、养殖和调节气候等功能。杞麓湖盆区地处低纬高原,属于亚热带半湿润季风气候,四季不分明,冬无严寒,夏无酷暑,四季如春,主要分干湿两季。自20世纪80年代中后期以来,杞麓湖水质受污染的程度日趋严重[21]。2010年前后连续几年的干旱造成杞麓湖天然补水减少、湖泊及流域地下水位较低,流域水生态安全面临严重威胁,湖泊治理与保护形势至今仍然十分严峻。
1.2 数据来源
①通海气象站1964—2019年逐月降水、温度、蒸发等观测资料;②经过径流还原分析得到的杞麓湖1964—2019年逐月入湖径流量数据;③杞麓湖1964—2019年逐月实测水位。
1.3 研究方法
从水文循环的角度分析,水位变化主要受降水、温度、蒸发、径流以及前期水位的影响。将降水(P)、温度(T)、蒸发(E)、径流(F)、前一月水位(Zt-1)作为解释变量,分别构建Vine Copula、BP、SVR模型进行长时序水位预测。Vine Copula、BP、SVR的3种模型预测值分别用V1-V3表示。
V1(t)=VC(Z(t-1),P(t),E(t),F(t),T(t))
(1)
V2(t)=BP(Z(t-1),P(t),E(t),F(t),T(t))
(2)
V3(t)=SVR(Z(t-1),P(t),E(t),F(t),T(t))
(3)
BMA方法是利用贝叶斯统计理论建立的概率预报模型,具体公式推导参见文献[22-24]。它的基本原理如下:设目标月份的水位(即预测变量)为X1,给定观测值Z=(Z1,Z2,…,Zt),则BMA(VC,BP,SVR)模型的预测变量X1的概率密度函数表达式为
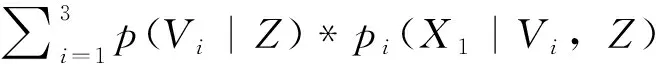
(4)

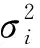

(5)
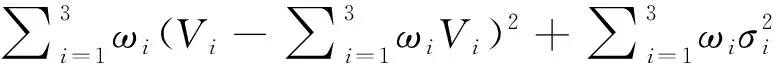
(6)

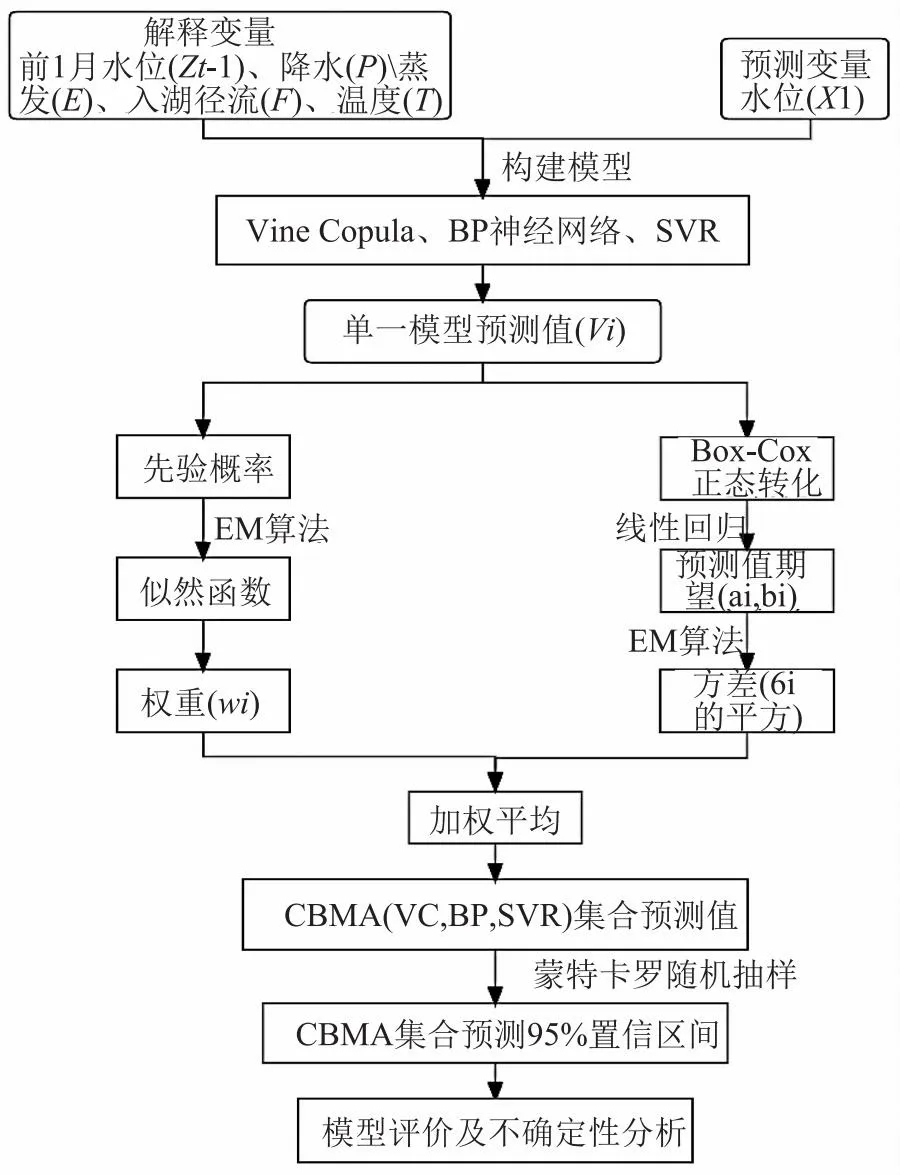
图1 组合模型湖泊水位预测流程图
为评估模型预测杞麓湖水位的效果,采用平均偏差(ME)、均方根误差(RMSE)、符合指数(IA)、Nash-Sutcliffe效率系数(NSE)等4个常用的误差统计指数。
2 结果与分析
2.1 模型预测结果分析
在模型构建中,将70%的数据样本作为训练集,30%的数据样本作为验证集。将单一模型和组合模型实测值与预测值对比并计算统计指数,如图2所示。在单一模型中,Vine Copula模型预测精度最高,BP和SVR模型预测精度相差不大,但是SVR模型预测精度稍微高于BP模型。BMA(VC,BP,SVR)模型预测精度都高于单一模型Vine Copula、BP和SVR模型,其ME、RMSE、IA和NSE分别是0.05,0.15,0.991,0.962。BMA(VC,BP,SVR)模型得到的Vine Copula、BP和SVR模型权重分别为0.39、0.26、0.35,可看出模型预测精度越高,在BMA构建的模型中所占的权重也较高。
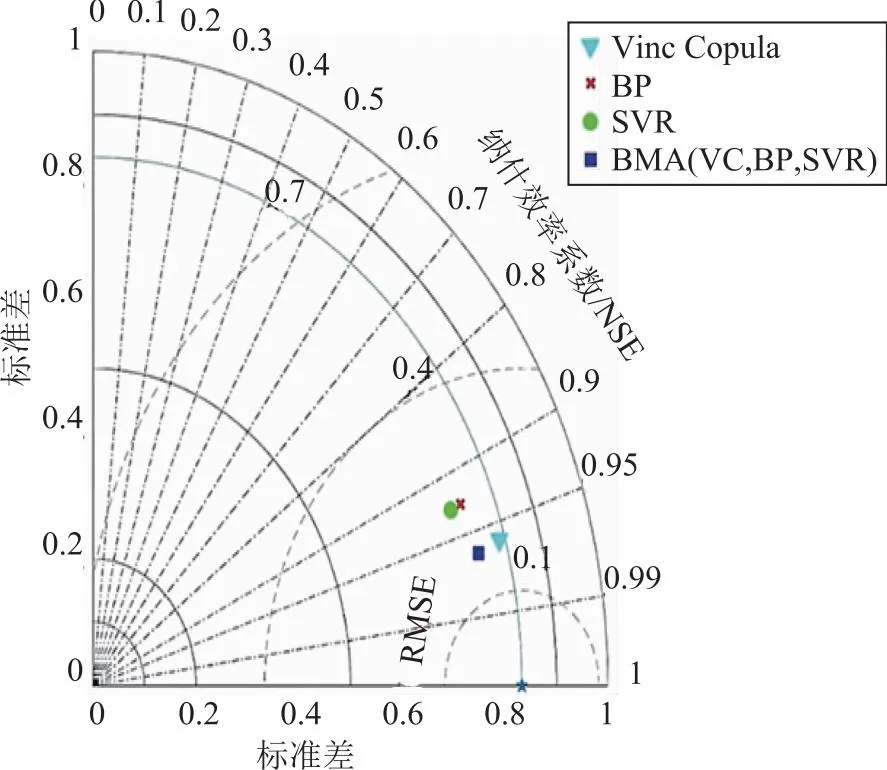
图2 (VC,BP,SVR)不同模型对实测值的泰勒图
将各模型预测水位和实测水位对比,如图3所示。对水位的变化过程各模型均能较好描述,预测水位的趋势基本与观测水位一致,BP(R=0.97)和SVR(R=0.97)模型的水位预测值与实测值偏离较大,Vine Copula模型和BMA(VC,BP,SVR)模型预测序列与观测序列基本重叠,但是在一些出现峰值的情况预测结果不理想,与观测序列有些偏差。在一些个别年份BMA(VC,BP,SVR)模型预测误差大于单个模型,主要体现在BP和SVR模型的水位预测值与实测值偏离较大的月份,这可能是因为BMA的权重值是由3种模型训练集数据获得的,权重的不稳定性会导致测试集个别月份预测效果减弱,同时在3种预测模型中预测效果较差的月份占比较多,会降低组合预测精度,甚至低于单一模型中预测精度最好的模型。在整体预测中,BMA(VC,BP,SVR)(R=0.99)模型预测精度高于Vine Copula(R=0.98)。
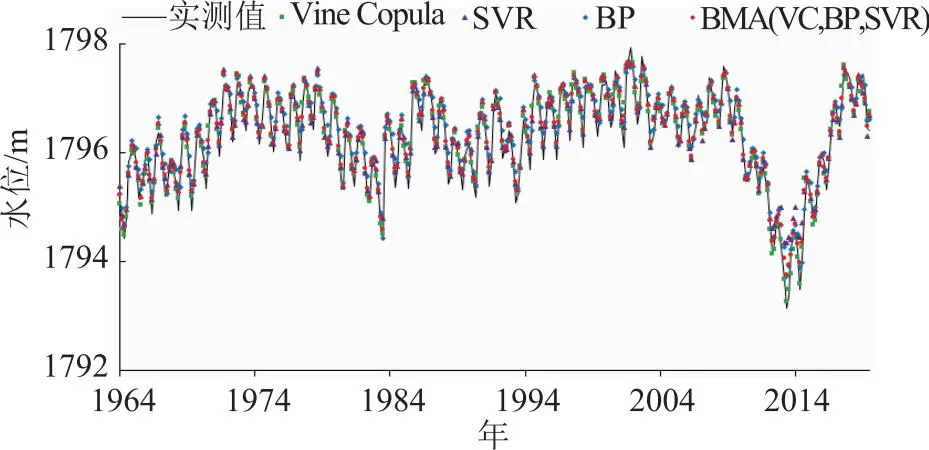
图3 (VC,BP,SVR)不同模型逐月水位预测值与实测值时间序列对比图
VC,BP,SVR,BMA等不同模型预测误差统计见表1,在单个模型中BP模型相对误差小于15%、20%、25%的占比最多,SVR模型在相对误差小于25%的占比高于Vine Copula模型,这表明BP和SVR模型对时间序列的局部特征捕捉能力更强,可以避免重要特征丢失;而Vine Copula模型在相对误差5%和10%的占较多,可以较好捕捉时间序列的时序特征,在整体上和极值的预测结果更加准确。BMA(VC,BP,SVR)模型可以整合单一模型预测优势,使相对误差小于15%的占比得到提升,提取更多数据特征,提高预测精度。

表1 不同方法模型的预测误差比较
VC,BP,SVR,BMA不同模型误差如图4所示,误差大部分在[-0.4,0.4]范围波动,其中Vine Copula模型平均误差较接近于0轴,但是个别误差偏离0轴较大;BP和SVR模型误差分布比较均匀,偏离0轴较大,使得预测精度较低;而BMA(VC,BP,SVR)模型的误差分布偏离0轴较小,误差分布比较均匀,围绕平均值上下波动。从整体看BMA(VC,BP,SVR)模型能够综合各模型优势,稳定准确地预测杞麓湖水位变化。

图4 (VC,BP,SVR)不同模型预测误差分布
为了验证BMA方法对预测效果的提升,还构建了BMA(BP,SVR)模型,误差统计指数如图5所示。可看到BMA(BP,SVR)模型ME,RMSE,IA,NSE值分别为0.01,0.163,0.989,0.953,预测精度高于单一模型BP和SVR模型。水位过程线对比如图6所示,可看到BMA(BP,SVR)(R=0.98)模型偏离实测水位较小,更接近于实测水位的峰值点和极值点。总体而言,不管BMA(VC,BP,SVR)模型还是BMA(BP,SVR)模型的预测精度都大于单一模型,对水位特征捕捉更充分,也进一步说明了BMA在多模型预测中提高预测精度的优越性。

图5 (BP,SVR)不同模型对实测值的泰勒图

图6 (BP,SVR)不同模型逐月水位预测值与实测值时间序列对比图
2.2 不确定性分析
基于区间宽度和覆盖率两个指标对BMA(VC,BP,SVR)模型预测序列的95%置信区间来分析结果的不确定性,评估模型性能。水位实测值(Z)、BMA(VC,BP,SVR)水位预测序列以及95%水平的置信区间如图7所示,可看到95%置信区间内有大部分的水位实测值,只有66个值在不确定性区间外,其水位实测值的区间覆盖率达90%,表明95%置信区间效果较好,不确定性较小。总体上可以看出,BMA(VC,BP,SVR)在湿季(5—10月)有56个实测值在置信区间外,而干季(11月—次年4月)只有10个实测值在置信区间外,且湿季的区间宽度比干季的大,说明水位预测精度在干季要高于湿季,且湿季水位预测的不确定性较大,还需要从模型结构中关于湿季的预测方法进一步改进。湿季水位预测不确定性较大的原因可能是湿季降水比较多,降水和入湖径流各月份之间波动较大,3个模型不能对这一降雨径流过程进行准确、有效地描述,由此造成湿季预测结果的偏差。
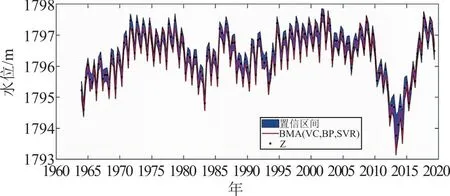
图7 BMA(VC,BP,SVR)模型预测逐月水位的95%不确定性区间
3 结语
在流域各类用水消耗信息缺失条件下,利用降水、温度、蒸发、径流以及前1月水位作为水位的预测因子构建Vine Copula、BP和SVR模型获得水位预测值,基于贝叶斯统计理论将机器学习模型和统计动力学模型结合构建BMA(VC,BP,SVR)和BMA(BP,SVR)模型,并应用到杞麓湖来提高长时序湖泊水位预测精度和不确定性分析。
(1)BMA方法都能够在一定程度上集合不同模型优势,提高预测精度。BP和SVR模型对时间序列的局部特征捕捉能力较强,Vine Copula模型对时间序列的时序特征描述更好,BMA(VC,BP,SVR)和BMA(BP,SVR)模型预测精度高于单一模型,但还是对一些峰值捕捉不好。
(2)95%置信区间表明,BMA(VC,BP,SVR)模型区间覆盖率达90%,不确定性较小。
(3)湿季降水比较多,降水和入湖径流各月份之间波动较大,BMA(VC,BP,SVR)模型湿季水位预测精度低于干季,且不确定性较大。
(4)在进行流域长时序水位预报时,考虑影响水位变化的物理基础和各因素并选择合适的预报因子,同时综合多种预报方法,可有效降低长期水位预报的不确定性。此外,研究采用预见期为1个月,可满足多模型综合预报方法在该研究区有效性的论证,而该方法在不同预见期的有效性可能会有所区别,还需结合实际调度需求进一步检验,探索不同预见期下的最优预报方案,以更加合理地指导水位调度。
