强化先验骨架结构的轻量型高效人体姿态估计
2024-02-12孙雪菲张瑞峰关欣李锵
孙雪菲,张瑞峰,关欣,李锵
(天津大学 微电子学院,天津 300072)
在计算机视觉领域,二维人体姿态估计一直是重要且极具挑战性的问题,具有广泛的应用场景,例如人体动作识别、人机交互、虚拟现实、视频监控、人体轨迹跟踪等[1].由于人体关节的复杂性、高度灵活性和不同质量图像、视频中人体部分的完整性、差异性等因素,在基于视觉的运动姿势、乐器演奏姿势捕捉矫正、虚拟人动作生成、外骨骼机器人中人体运动数据获取等应用场景中,人体关键点检测仍然难以满足高精度的需求.
随着卷积神经网络的迅速发展,人体姿态估计取得了巨大进展.研究人员提出了许多经典模型,旨在解决如何从图像中提取不同阶段的多尺度特征以及如何高效地融合语义、通道、空间信息等问题.Newell 等[2]利用多个基础沙漏模型提取多尺度特征,以关注人体图像的空间信息,但受网络深度的制约,模型精度有待提升.Chen 等[3]基于特征金字塔结构,提出两阶段网络,融合了多尺度特征信息,可以分别检测容易与困难2 种关键点.Xiao 等[4]首次提出单阶段姿态估计网络,采用编解码的方式,简单、有效地识别关键点,但是网络参数量较大,计算效率不高.Sun 等[5]提出高分辨率网络(high-resolution network,HRNet),能够保持原始图像的空间位置信息,通过多尺寸特征融合增强对关键点的识别能力.
虽然现有网络可以很好地完成人体关键点估计任务,但仍存在以下问题.
(1)网络无法实现精度与效率的平衡.使用轻量级模块降低模型参数量,往往会降低识别精度.如何在保持网络结构轻量化的同时提升模型的识别精度,有待进一步的研究.
(2)人体骨架结构的特有属性未被充分利用.躯干特定布局的先验知识可以帮助精准定位人体所在的位置以及关键点之间的拓扑结构,强化全局空间位置信息并且结合上下文信息,由此可以获得更好的估计效果.
(3)未结合人体关键点分布的方向特性,例如水平方向的肩部关键点和垂直方向的腿部关键点.当融合不同分辨率的特征图像时,减少空间特征信息的流失,可以有效地提升模型性能.
针对以上问题,本文提出强化先验骨架结构的轻量型高效人体姿态估计网络.为了较好地保留空间信息并融合不同尺度的特征,选取HRNet 作为基础网络.引入轻量倒残差模块(lightweight inverse residual module,LIRM),能够减少网络参数量,保持较高的估计精度.为了强化图像中关键点的空间特征和上下文信息,设计体位强化模块(postural enhancement module,PEM).提出方向强化卷积模块(direction-enhanced convolution module,DCM),改善多尺度特征融合中关键信息容易流失的情况.综上所述,利用该网络,能够轻量、高效地实现对人体关键点的估计,实现了精度与效率的平衡.
1 相关工作
在计算机视觉领域中,不同的特征提取方式可以实现不同的效果.MobileNet[6]使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息.ShuffleNet[7]提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用.Transformer 利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力.递归金字塔[8]和特征金字塔[9]模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力.自适应卷积[10]和动态卷积[11]可以根据输入自适应调整每个卷积核的权重.这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升.对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度.除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息.通道注意力[12]可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用.空间注意力[13]可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度.混合注意力[14]结合通道注意力和空间注意力,共同提升人体关键点的估计效果.
2 研究方法
假设包含人体的图像I有K个待检测的骨骼关键点.将人体姿态估计任务分为以下2 个阶段处理.1)估计K张尺寸为H′×W′的热图Hk,以表示每个骨骼关键点的位置置信度.2)利用argmax函数求出预测热图最大值点的坐标,按比例将坐标复原到原始图片尺寸,得到最终的输出结果.
2.1 整体网络框架
本文提出的网络采用强化先验骨架结构的方法,具有轻量、高效的特点,完整的网络框架如图1所示.通过步长为2 的3×3 卷积,将预处理后图像的分辨率降至目标热图的分辨率.网络共有4 个阶段,每个阶段逐步增加一个低分辨率特征图像的分支,各分支的分辨率从目标热图的分辨率开始依次减半,通道数依次加倍.将多分辨率的子网络并行连接,利用多尺度特征信息对人体姿态关键点进行估计.
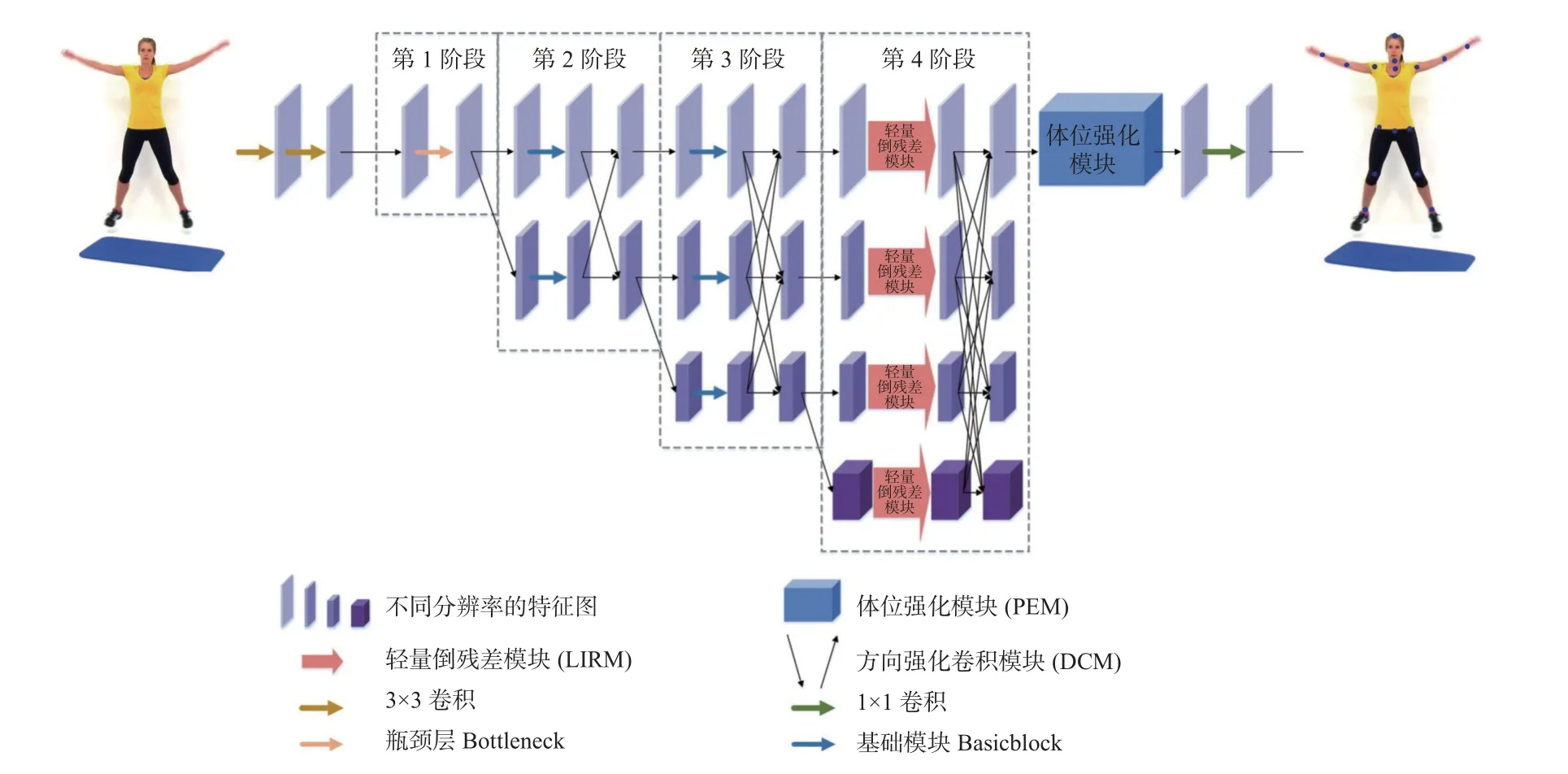
图1 强化先验骨架结构的人体姿态估计网络整体架构Fig.1 General architecture of human pose estimation network with enhanced priori skeleton structure
第1 个阶段用Bottleneck 提取人体姿态相关的语义信息和关键点的空间位置信息,结构如图2(a)所示.第2 和第3 阶段用Basicblock 作为特征提取模块,主要关注低分辨率特征图中所包含的人体姿态语义信息,结构如图2(b)所示.第4 阶段设计LIRM 作为特征提取模块,降低了网络参数量.在第4 阶段后,为了强化人体结构信息和关键点之间的联系,提升网络效果,采用PEM 捕捉全局空间位置信息和上下文信息.通过1×1 卷积生成高斯热图,经过后处理恢复原始图像.本文提出DCM,可以在各个阶段多分辨率特征融合过程中利用关键点分布的方向性,提取到更丰富的关键点特征信息,便于特征在网络中的传播与融合.

图2 瓶颈层和基础模块的结构Fig.2 Structure of bottleneck and basicblock module
2.2 轻量倒残差模块
HRNet 可以缓解特征提取过程中尺度变换导致空间特征信息丢失的问题,在特征提取和融合时一直保持高分辨率,保障对输入图像的特征提取能力,因此产生了运算复杂度高、参数量大的问题.HRNet 的后3 个阶段均使用Basicblock 作为基础特征提取模块,由于第4 阶段有4 条不同分辨率的支路,导致第4 阶段所产生的参数量最多,但实际上对关键点的估计效果没有明显的提升[15].受到ConvNet[16]的启发,提出LIRM 替换网络中第4 阶段的基本模块,以实现模型精度与效率之间的平衡.
LIRM 结构如图3 所示.采用大尺度7×7 卷积核的逐通道卷积进行特征提取,大尺度卷积核可以获得大目标的特征及包含人体结构信息的上下文信息,提升估计精度.逐通道卷积运算对输入特征图像的每个通道独立进行卷积运算,无法有针对性地利用不同通道在相同空间位置上的特征信息.使用小尺度1×1 卷积核的逐点卷积,将上一步特征图像在深度方向进行加权组合,生成新的特征图像,小尺度卷积核有利于提取小目标的特征和人体关键点的局部细节信息.逐通道卷积和逐点卷积与常规的卷积操作相比,参数量和运算成本较低.LIRM 公式表示如下:

图3 轻量倒残差模块的结构Fig.3 Structure of lightweight inverse residual module
式中:Iin∈Rc×h×w为输入特征图像,Iout∈Rc×h×w为输出特征图像,D7×7为7×7 逐通道卷积,θ 为层归一化,P1×1为1×1 逐点卷积,γ 为GELU 激活函数.
本模块采用先升维后降维的倒残差设计思想.第1 个1×1 逐点卷积输出的通道数是输入通道数的4 倍,将输入特征图以高维特征表示,可以实现特征信息的扩展.经过学习和提取高维特征之后,第2 个1×1 逐点卷积将倒残差模块的输出通道恢复到模块的输入通道数.采用逆瓶颈层的结构,在不影响网络性能的情况下降低了运算量,对本文模型进行有效的轻量化处理.受到Transformer 网络结构的影响,该模块使用更少的归一化层和激活函数.仅在第1 个1×1 卷积前添加层归一化,在2 个1×1 卷积之间添加GELU 激活函数,以降低网络训练压力.层归一化在每个样本的不同通道上计算均值和方差,与逐通道卷积一致,能够提取特征图像不同通道间的差异化信息.GELU 是新颖且有效的激活函数,能够有效地避免梯度消失的问题,在众多领域中表现极佳.
2.3 体位强化模块
人体姿态估计是对图像中的人体关节点进行识别和定位,关节点构成的骨架模型是链式结构,相邻近的关节点之间具有更强的相关性,表现在通道和空间信息的差异,相关性更强的关键点应被赋予更多的关注.提出的PEM 可以利用人体先验骨架结构及多个关键点之间的联系,捕捉到丰富的全局空间位置信息和上下文信息,增强模型的表达能力.
PEM 可以提升网络对人体结构信息的感知能力,将该模块放在网络第4 阶段输出特征后,可以在最终输出特征图前进一步强化全局关键点的上下文联系.除此之外,网络第1 条分支的图像分辨率始终保持目标特征图尺寸不变,能够很好地保留空间位置信息.PEM 在通道和空间2 个方向均有效增强关键点特征表达能力,结构如图4 所示,主要包括2 个部分:转换变体卷积[17]与全局上下文注意模块[18].
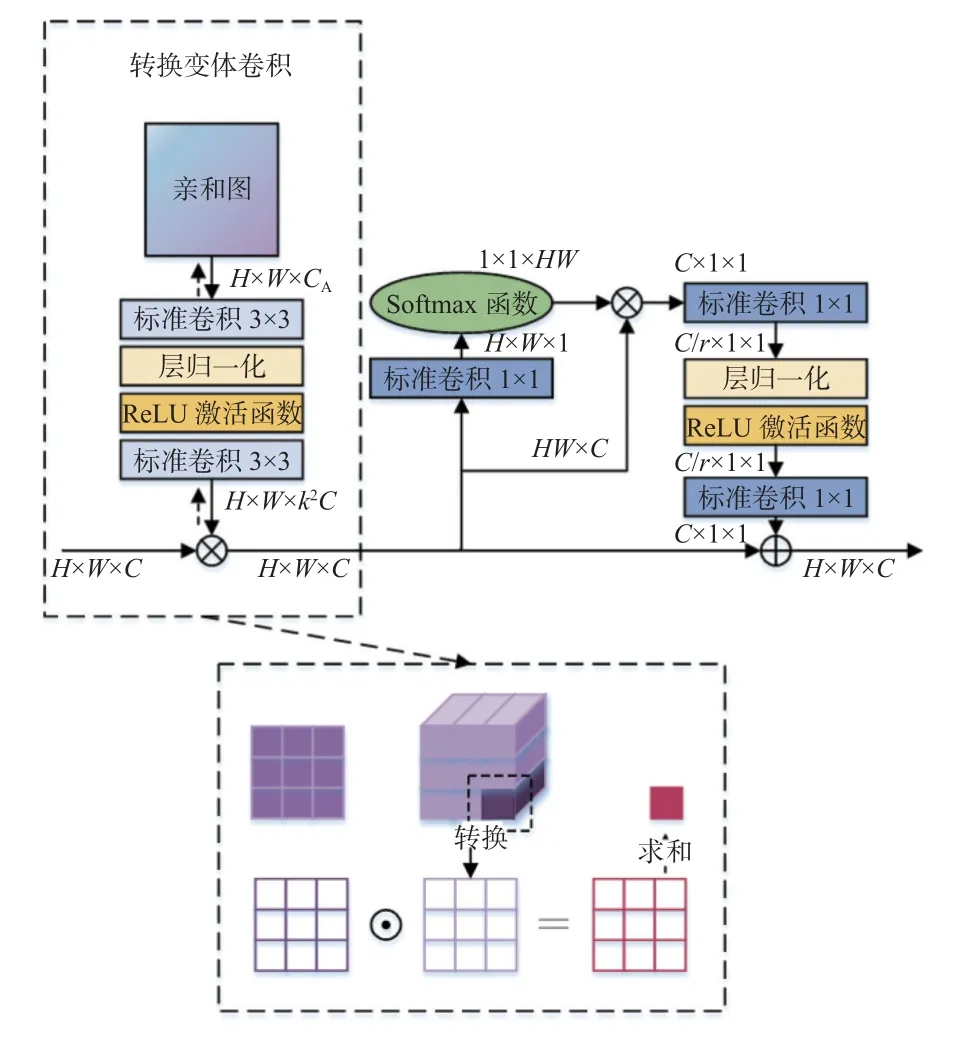
图4 体位强化模块的结构Fig.4 Structure of postural enhancement module
转换变体卷积是全局卷积,可以对整张特征图进行特征提取,较好地保留了全局空间位置信息,适合特定结构(如人体结构、手部结构、面部五官结构等)的视觉任务处理.常规的全局卷积由于权重张量较大,容易造成参数量巨大和过拟合的问题,而转换变体卷积将其分解,利用亲和图降低模型的参数量和复杂度.对于不同的输入图像,亲和图中的关联映射是共享的,所以训练后得到固定不变的亲和图,可以应用相同的权重实现快速推理.转换变体卷积将亲和图输入到权重生成模块,以此来生成全局权重.亲和图能够对整张图像进行关注,描绘像素配对关系,包含了人体姿态的一些共性信息,如头部在上肩膀在下、膝盖在上脚踝在下,可以区分多种不同的局部特征,帮助网络捕捉到不同空间区域的语义特征,高效提取不同的空间位置信息.权重生成模块通过多次执行标准卷积、层归一化和激活层来提取信息.亲和图对不同的输入进行权重共享,可以通过标准反向传播对该权重进行端到端训练,以获取最优值.亲和图映射是固定的,权重生成模块可以根据需求增减计算开销,二者融合避免了过度参数化,降低了模块的复杂度.转换变体卷积适用于跨图像属性共享领域的问题,仅增加较少的参数量,可以在人体姿态估计问题中发挥重要的作用.转换变体卷积的公式表述如下:
式中:W为通道级卷积,为亲和图,F3×3为3×3 卷积,φ为层归一化和ReLU 激活函数.
全局上下文注意模块可以充分提取图像的全局信息,捕获整张图像中人体关键点的长距离依赖关系.此外,该模块是轻量级的,减少了不必要的计算量,可以有效地建模长期依赖关系.全局上下文注意模块利用1×1 卷积和softmax 函数计算权重,通过全局注意力池化进行上下文建模,利用瓶颈转换来捕捉通道间的依赖关系,通过扩展元素相加的方式将全局上下文特征融合到整个图像.采用全局上下文注意模块,优化了全局上下文建模能力,加强了图像全局信息与局部信息的联系,对人体姿态估计的视觉任务都具有高效性.全局上下文注意模块的公式表述如下:
式中:β 为权重生成,F1×1为1×1 卷积.
2.4 方向强化卷积模块
该网络中各个阶段间的融合层用于多分辨率分支间的信息交互.传统的方法是用步幅为2 的标准3×3 卷积来降低分辨率,用最近邻上采样的方法来提高分辨率.为了缓解不同分辨率特征图像融合时造成的信息遗失问题,提出DCM.在卷积核上充分利用了躯干上关键点分布的水平和垂直方向特性,结构如图5 所示.
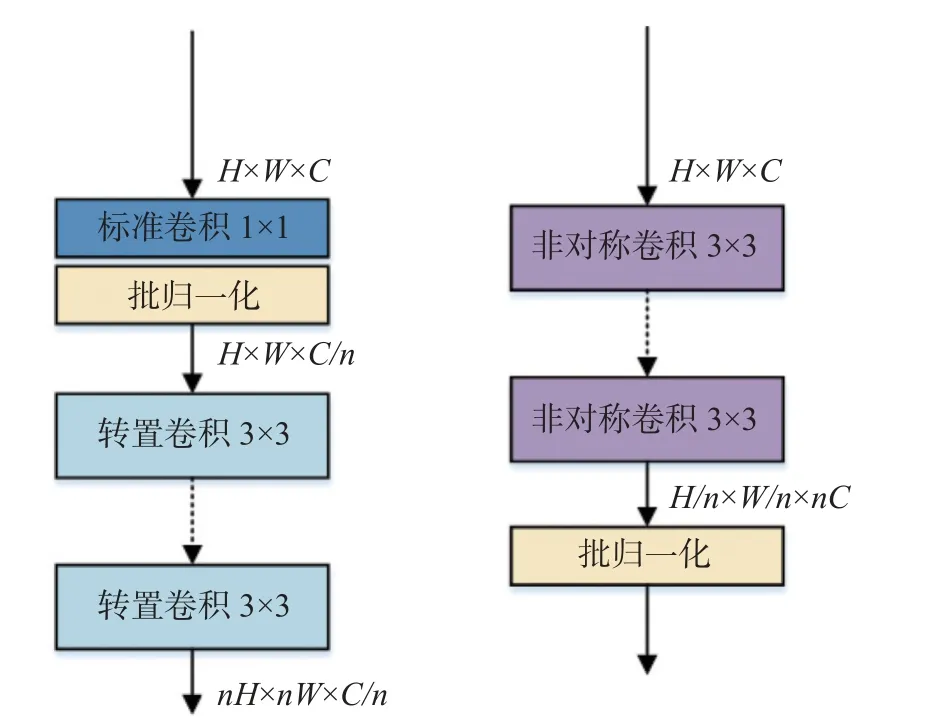
图5 方向强化卷积模块的结构Fig.5 Structure of direction-enhanced convolution module
研究表明,卷积核上参数的重要程度不同,处在中央交叉位置即卷积核骨架上的参数更加重要,更需要被网络重视,处于边角的参数影响较小[19].当降低图像分辨率时,普通的3×3 卷积对卷积核参数不进行区分处理.在初始化时参数是随机的,因此随着后续训练过程的进行,可能导致网络向着非强化骨架参数的方向优化,最终削弱了中央交叉位置上参数对于网络的作用,导致特征提取能力降低.人体关键点分布有水平和垂直的方向特性,当关键点位于卷积核骨架位置时,需要被重点强化,增强卷积核的方向性可以在下采样过程中不遗失关键信息.采用非对称卷积模块降低分辨率,将额外的水平卷积和垂直卷积叠加到普通方形卷积核骨架上,起到强化骨架上参数的作用.非对称卷积的操作原理如图6 所示.训练时对输入特征图像并行开展3×3、1×3 和3×1 卷积操作,将3 组输出特征图像叠加作为整体输出.在推理时,相当于将上述3 个卷积核叠加起来转换为1 个新的卷积核即非对称卷积进行卷积操作,得到输出特征图.采用2 种卷积操作方式得到的输出特征图是等价的.非对称卷积会在下采样过程中强化位于卷积核骨架位置的关键点,避免关键点特征信息的遗失.
非对称卷积可以表示为
式中:F1×3为1×3 卷积,F3×1为3×1 卷积,为整体卷积操作,为推理时的输出特征图像.
最近邻上采样仅使用距离待测采样点最近的像素的灰度作为该采样点的灰度,而没有考虑其他相邻像素点的影响.在人体姿态估计中,这种上采样方式会导致关键点所在的像素位置模糊,不利于关键点的精确定位.为了解决该问题,提出采用转置卷积[20]来提高图像分辨率的方法.使用1×1 卷积来转换通道数量,采用多个转置卷积将输入特征图恢复至目标尺寸.如图7 所示,转置卷积在卷积前增加了参数转置的过程,能够在上采样过程中持续提取特征信息.转置卷积中的权重是可以被学习的,通过学习获取最适合当前数据集的上采样方式.具体来说,转置卷积需要对输入进行填充,在输入特征图元素间填充s-1 行(其中s为转置卷积的步距),在输入特征图四周填充k-p-1 行(其中k为转置卷积的卷积核大小,p为转置卷积的填充数量).将卷积核参数上下、左右翻转,最后进行标准卷积运算.利用该方式不会模糊关键点所在的像素位置,能够在上采样过程中进一步提取图像特征,有利于不同分辨率特征图像的融合.
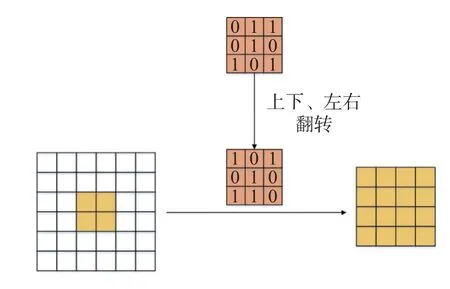
图7 转置卷积结构Fig.7 Transposed convolution structure
转置卷积操作后特征图的大小可以通过下式计算:
式中:Zin为输入特征图的行数(或列数),Zout为输出特征图的行数(或列数),s为步长,p为填充数,k为卷积核尺寸.
3 实验结果与分析
3.1 数据集与评估标准
在MPII 人体姿势数据集[21]和COCO2017 数据集[22]上进行验证测试.
糖尿病是由于胰岛素相对或绝对缺乏及不同程度的胰岛素抵抗,引起碳水化合物、脂肪及蛋白质代谢紊乱的综合征,表现为以血糖增高和(或)糖尿为特征的慢性全身性疾病。糖尿病患者住院治疗或手术时,并发症发生率和死亡率明显增高[1]。麻醉、手术的创伤刺激可引起糖尿病患者血糖应激性升高[2]。另外,术前禁食、口服降糖药停药过晚、术前胰岛素剂量的不适当调整等因素均可导致糖尿病患者围手术期低血糖发生率的增加。全麻镇静患者低血糖症状被掩盖,风险尤其高[3]。因此,围手术期在控制糖尿病患者高血糖的同时必须提高警惕,积极防治低血糖,避免患者发生致命危险。
MPII 数据集具有真实性和背景丰富的特点,有利于模拟真实情况.它包含约25 000 张图像和40 000 多个注释信息,其中包括16 个人体目标关键点的二维位置、完整的三维躯干和头部方向、关键点的遮挡标签和活动标签.数据集中约28 000 个样本用于训练,11 000 个用于测试.
正确关键点百分比(percentage of correct keypoints,PCK)是MPII 用来评估2D 人体关键点估计的标准.它定义为被准确检测到的关键点所占的比例.计算方法是将检测到的关键点与对应的真实标注值之间的归一化距离与设定阈值进行比较.目前,普遍采用PCKh@0.5 作为指标,当预测值与真实标注值之间的归一化欧氏距离小于头部尺寸因子的50%时,则认为预测正确.PCK 为通过该方法正确预测的关键点数量占总数的比例.
PCK 计算公式如下:
式中:i表示ID 为i的关键点,p为第p个行人,dpi为第p个人中ID 为i的关键点预测值与标注真值的欧氏距离,为第p个人的尺度因子,Tk为人工设定的阈值,k为第k个阈值,Tk∈[0:0.01:0.5],为Tk阈值下PCK 的平均值,δ 函数为计算符合标准的关键点数量.
COCO2017 数据集包含80 个目标类别,大约有220 000 张标注图像和5 种类型的注释信息.图片中标注了约250 000 个人体信息,每个人体都有17 个关键点标记.COCO Train2017 包含57 000 张图像和150 000 个注释信息,Val2017 包含5 000 张图像,Test-Dev2017 包含20 000 张图像.使用Train2017 进行训练,采用Val2017 验证和评估模型,给出Test-Dev2017 的测试结果.
对象关键点相似性(object keypoint similarity,OKS)用来衡量预测关键点与标注真值之间的相似性,计算公式如下:
式中:i为关键点的个数;di为关键点i的预测值与标注真值之间的欧氏距离;s为尺度因子,其值为人体检测框面积的平方根;ki为第i个关键点的归一化因子;vi∈(0,1,2) 为第i个关键点的可见性,0 表示关键点未标记,1 表示无遮挡并且已经标记,2 表示有遮挡但是已经标记;δ 函数判断条件是否成立,此处指仅判断已标注的关键点.
本实验主要对比的评价指标为平均准确度(average precision,AP),是在多个交并比(intersection over union,IoU)[0.50:0.05:0.95]间取平均值(IoU 定义为探测器预测边界框交集面积与并集面积的比值),AP0.5和AP0.75是单个IoU 阈值的指标,APM、APL是根据数据集中目标物体面积设定的指标,APM指0.322<面积<0.962,APL指面积大于0.962.平均召回率(average recall,AR)为辅助指标,在所有IoU 和全部类别上求平均值.
3.2 实验设置
实验环境如下:CPU Intel © Core i9-9900X 3.5 GHz,GPU Nvidia RTX2080Ti (11 GB)×4,Ubuntu 16.04 操作系统,Pytorch 深度学习框架.
将人体检测框的高度和宽度比例设置为4∶3,从图像中剪裁该框,将其大小调整为固定尺寸.MPII数据集的裁剪尺寸为256×256,COCO 数据集的裁剪尺寸为256×192 和384×288.数据增强时,MPII数据集包括随机旋转±30°和±0.25 的随机比例,COCO 数据集包括随机旋转±45°和±0.3 的随机比例,翻转测试均被使用,对半身数据进行了增强.使用Adam 优化器,初始学习率为0.001,一共训练210 轮,分别在170 和200 轮时降低学习率,比例为0.1.均方误差用作预测热图和目标热图之间的损失,每个关节点的目标热图是通过应用以该关节点的标注真值位置为中心的二维高斯来生成.
3.3 结果分析
为了验证所提网络中各个模块的必要性和有效性,以HRNet 为基础网络Baseline,开展消融实验,分析各个模块的性能.将本文网络与人体姿态估计的经典网络和最新主流网络进行对比,对估计结果进行可视化.
3.3.1 主干网络分析 对基础网络各阶段的模块选择进行实验分析,选取更优的主干网络,实现模型精度与效率的平衡.将LIRM 放置于基础网络中的不同位置,测试该模块所在位置对模型产生的影响,结果如表1 所示.表中,Np为参数量,FLOPs 为每秒浮点运算次数,PCKhmean为以头部长度作为归一化基值的PCK 平均值.

表1 在MPII 数据集上阈值为0.5 时不同主干网络的PCKh 平均值Tab.1 Mean values of PCKh for different backbone networks at threshold of 0.5 on MPII dataset
由表1 可见,当LIRM 仅替换网络第4 阶段的基本模块时,即模型1,参数量降低了10.2×106,而主要评价指标的平均值未降低.与基础网络相比,模型2 的参数量减少了13.4×106,PCKhmean降低了1.0%;模型3 的参数量减少了13.6×106,PCKhmean降低了1.3%.
实验结果证明,LIRM 可以在网络第4 阶段以更少的参数量,实现与基本模块相同的效果;在第2、3 阶段时,虽然进一步降低了参数量,但是对模型效果的影响较大.为了兼顾模型的精度与效率,仅在网络第4 阶段使用LIRM.
3.3.2 消融实验 通过一系列消融实验,验证所提网络的有效性.将提出的LIRM、PEM 和DCM 依次运用在基础框架上,对比不同网络结构下的评价指标,消融结果如表2、3 所示.

表2 在MPII 数据集上阈值为0.5 时不同主干网络的PCKh 值Tab.2 PCKh values for different backbone networks at threshold of 0.5 on MPII dataset
在MPII 数据集中,主要使用PCK 的平均值作为标准进行判断.由表2 可见,使用LIRM 可以减少10.2×106的参数量,在肩膀和臀部关节点的指标有所提升,肘部识别精度持平,在其他关节点处略有降低,总体上与原网络的估计效果相似.在增加PEM 后,仅增加了7×105的参数量,在各个关节点上的指标及平均值指标均有所提升,表明该模块有效地增强了人体躯干的空间特征和关键点的上下文联系,能够更好地识别人体姿态.DCM 的运用使平均值增加了0.1%,在头部关键点提升最大,精度提升了0.5%,表明在多分辨率特征图相互融合时,利用该模块可以有效地减少关键特征的遗失,实现关键点空间位置的高精度表达.
在COCO 数据集中,主要以AP 值作为标准进行判断.从表3 可见,LIRM 在COCO 数据集中的表现效果更佳,在减少了约36%参数量的同时,将AP 值提升了0.5%,实现了网络精度与效率的平衡.结合PEM 后的模型,AP 值增加了0.7%,使得网络聚焦全局空间信息和上下文联系,强化了人体全部关键点的空间位置及其之间的连接关系.DCM 进一步提升估计效果,用原始网络约74%的参数量将AP 值提升至76.7%,缓解了多分辨率特征融合时关键信息流失的问题,实现了高效的人体姿态估计.

表3 在COCO 验证集上不同网络的平均精度和平均召回率消融结果Tab.3 Average precision and average recall ablation results of different networks on COCO validation set
综合而言,经过在不同数据集上的实验测试,提出的LIRM、PEM 和DCM 均被验证了其有效性和泛化性,在主要的评价指标上都有所提高.本文模型可以在提高性能指标的同时降低部分参数量和运算量,达到轻量、高效地估计人体关键点的目的.
3.3.3 与其他模型的对比情况 在COCO 数据集上,将提出的网络与最新的主流模型进行比较,对比结果如表4、5 所示.

表4 在COCO 验证集上不同网络的平均精度和平均召回率对比结果Tab.4 Comparison results of average precision and average recall for different networks on COCO validation set
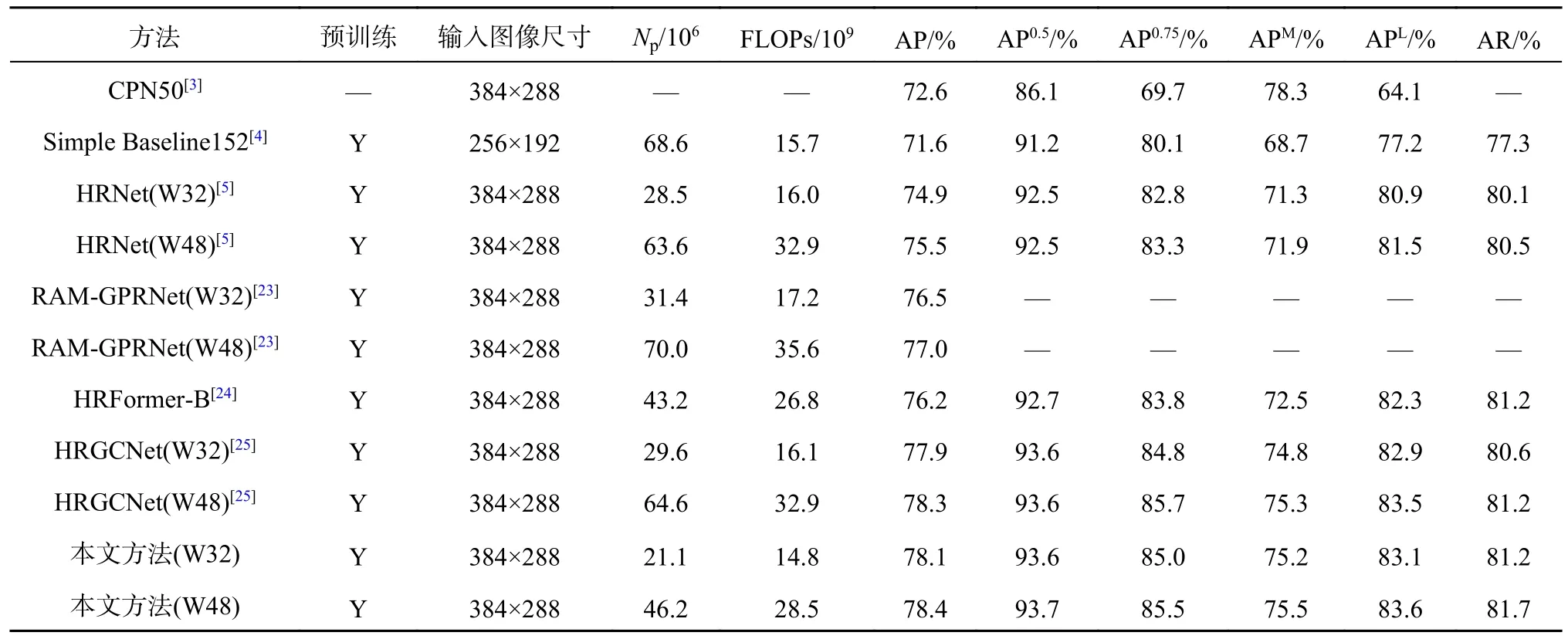
表5 在COCO 测试集上不同网络的平均精度和平均召回率对比结果Tab.5 Comparison results of average precision and average recall for different networks on COCO test set
在COCO 验证集上进行对比,当输入图像大小为256×192 时,提出的网络(W32)AP 值达到76.7%,优于其他具有相同输入的方法.与HRNet[5]相比,AP 值大幅度提高且运算量降低;与RAMGPRNet[23]相比,AP 值提高了0.7% 和0.9%;与HRFormer-B[24]相比,实现了0.9%的AP 增益;与HRGCNet[25]相比,虽然AP 值相近,但参数量和运算量更低;与AMHRNet[26]相比,AP 值有0.6%和1.0%的提升,且参数量约为其58%和65%.当输入图像大小为384×288 时,提出的网络获得了78.2%和78.5%的AP 值.与CPN[3]、SimpleBaseline[4]、HRNet[5]、RAM-GPRNet[23]、HRFormer-B[24]、HRGCNet[25]相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量.综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低.
当COCO 测试集进行对比时,本文模型实现了78.4%的AP 精度,在参数量和运算量方面表现较好.与COCO 验证集上的结果呈现一致性,实验证明了基于全局信息增强的人体姿态估计方法具有轻量高效的特点.
3.3.4 实验结果可视化 为了直观地显示模型的估计效果,对部分估计结果进行可视化,如图8 所示.可以看出,与HRNet 相比,该模型对关节点估计的位置与标注真值的结果更接近.在环境背景复杂(1)、图像中人体不完整(2)、关节点位置集中(3)、图像极度模糊(4)、遮挡(5)等情况下对关键点位置的估计更准确,局部放大对比图如图9 所示,证明该模型在各种情况下均有着出色的表现.

图8 可视化结果的对比图Fig.8 Comparison of visualization results

图9 可视化实验结果局部放大对比图Fig.9 Visualization of experimental results with partial zoom comparison
4 结语
本文针对二维人体姿态估计任务中存在的问题,提出强化先验骨架结构的人体姿态估计方法.利用该方法,轻量且高效地实现了人体关键点位置的估计.实验结果表明,该模型在COCO 验证集和测试集上的AP 值分别达到78.5%和78.4%.与基准网络相比,该模型减少了约1/3 的参数量,更适用于常规姿态,但对于特殊瑜伽动作(如朝天蹬)的估计效果存在不足,后续将在增强模型的泛化能力方面展开进一步的研究.另外,未来可在保持现有优势的基础上结合Transformer 自注意机制,实现更高精度的人体姿态估计.
