混合相似性度量的仪表询价电子表格结构识别
2024-02-05徐传运马莹丽李星光
徐传运,马莹丽,李 刚,舒 涛,李星光
(1.重庆理工大学 两江人工智能学院, 重庆 401135;2.重庆师范大学 计算机与信息科学学院, 重庆 401331)
0 引言
在仪表询价过程中,企业对无人化处理仪表询价电子表格的需求快速上升。自动化处理用户需求,实现无人化询价,对提高员工工作效率,降低企业人力物力成本有十分重要的意义。
目前,电子文件询价已成为国内各仪表企业的主要询价信息来源,其中各类报表文档占多数。在询价过程中,各个用户提供的产品物料清单(BOM)不一致,产品参数描述相对模糊,表格结构复杂多样,导致仪表企业大多收到样式不固定,数据排列混杂且具有嵌套表头的半结构化询价电子表格。无人化询价系统难以理解提供的仪表询价电子表格,因此各仪表企业仍普遍采用人工处理询价表格的生产经营模式,但人工方式工作量大,成本高、效率低,且无法及时响应。因此,本文对仪表询价电子表格的结构识别进行了研究,达到自动化识别询价电子表格的结构和理解隐含的逻辑关系的效果,为构建无人化询价系统奠定基础。
电子表格结构识别的目标是分析表格的行、列和单元格信息,提取表格中数据的结构信息,得到行列分布规律与逻辑结构。然而,当进行电子表格自动处理时,电子表格布局的复杂性和多样性给表格结构识别和计算机的自动处理带来了挑战[1]。
仪表询价电子表格的结构识别存在以下挑战:表格具有便于体现数据关系和灵活性强的特点[2],导致其往往会出现数据种类繁多、格式杂乱、不好整理的问题;询价表格与实际应用联系紧密,具有结构性低、数据冗杂,潜藏大量有价值数据[3]的特点;表格数据通常具有一定的专业性,表达的语义也不唯一,数据标注难度大且成本高。但在已有研究中,并未以大量仪表询价电子报表为对象,国内外对电子表格的识别主要集中在表头和属性上,并且大多利用传统方法,如基于规则、分类以及模式匹配[4]的方法研究表结构。
针对以上问题,本文对仪表询价电子报表数据特点进行分析,通过相似性度量的方式对仪表询价中大量使用的纵向电子表格结构识别进行研究,主要贡献为:
1) 提出混合相似性度量电子表格结构识别方法(hybrid similarity metrics for table structure recognition,HSMTSR):通过混合多种相似性度量的方法对表格的结构进行解析识别,将表格解析识别为表头、表体(索引、属性和数据)和表尾等部分,可以高效识别各种仪表电子表格结构。
2) 提出基于向量空间的单元格类型相似度(cell type similarity,TySim):有效提取电子表格单元格的类型特征,其结合特征向量化仪表询价电子表格,并用余弦相似度处理向量化的电子表格。
3) 收集真实流量仪表询价参数电子表格,构建流量仪表电子表格数据集(flowmeter spreadsheet dataSet,FSDS),便于研究仪表电子表格结构。
4) 有效识别仪表询价电子表格结构,为实现无人化仪表询价系统提供便利,节省人力物力资源,提升工作效率。
1 相关工作
1.1 表格结构识别
表格结构识别是表格理解分析中重要的子任务之一,其目标是识别表格的布局结构和层次结构。
据调研,近5年来针对表格识别的数据集多为PDF文件或者表格图片,缺少直接针对电子表格的数据集。PDF表格数据集有ICDAR2013[5]和PubTables-1M[6]等。表格图片数据集有ICDAR2019[7]、FUNSD[8]、PubTabNet[9]、WTW[10]和DECO[11]等。而电子表格数据集大多来自Web上的HTML表格或开放数据平台的表格,它们在组成、大小和注释方法上有很大差异,而且多数未公开数据集的标注。同时,由于企业不愿分享公司内部文件,且工商业电子表格的复杂性更高,因此研究者们对企业电子表格的研究要少得多。鉴于此,本文收集了某公司仪表询价电子表格,通过分析、筛选和脱敏等预处理建立了真实数据集FSDS,该数据集体现了仪表询价电子表格的不规范性和复杂性的特点,便于本文研究电子表格结构。
国内外相关研究也大多针对PDF表格或者表格图片,研究者们早期通常使用基于规则和启发的传统方法来分析和识别表格结构,例如将表格结构定义为一棵树,根据几何分布优化参数来理解表格结构[12]或从PDF文档中反解表格视觉信息[13]。随着深度学习和自然语言处理的发展,研究者们也开始利用各种语言模型处理表格图片,如LSTM[14]、Transformer[15]、BERT[16]及LayoutLM[17]模型均取得了良好的效果,其中BERT及其变体RoBERTa[18]、LayoutLM及其变体LayoutLMv2[19]和PICK[20]在表格图片结构识别任务中表现出较为稳定且高效的性能。而电子表格没有语法和数据模型,也没有统一的收集标准和收集格式[21],因此针对电子表格,大部分应用程序主要通过HTML和XML从Web上的半结构化数据中提取关系数据来进行结构识别,或使用VBA编程[22]实现启发式或基于规则的电子表格结构识别。但基于规则的方法成本高,且现有研究大多用于结构复杂性不高的表格,因此本文采取新的研究思路,结合表格中的文本相似度进行表格结构识别研究。
1.2 文本相似性度量
仪表询价电子表格中的数据具有专业性强、语义不唯一性和数据标注难度大且成本高等特点,不利于计算机理解。而文本相似度是广泛应用的文本分析算法模块,有助于计算机理解语言。受此启发,本文利用相似性度量的方法对表格结构进行解析识别,有助于计算机自动识别电子表格结构。
相似度用来判断事物之间的相似性,通常利用事物之间的距离来进行衡量,一般距离值越小,相似度越大[23]。目前,基于距离的相似度度量方法可分为3类:基于序列的方法、基于集合的方法和基于向量空间的方法。
基于序列的方法指将字符串看成序列,利用序列的相似性来计算两者之间的性质,主要包括Levenshtein距离[24]、Affine Gap距离[25]以及Jaro距离[26]等方法。
基于集合的方法指将字符串看成集合,利用集合的相似性或者距离来计算两者之间的性质,主要包括Dice度量、Jaccard度量和TF/IDF度量[27-28]等方法。
基于向量空间的方法指将字符串向量化,利用向量之间的距离来计算两者之间的性质,主要包括欧氏距离[29]和余弦相似度[30]等方法。
本文对具有多源、异构和结构多样等特点的仪表询价电子表格进行了结构识别研究,尤其是具有层次结构的表格,提出了融合表格单元格特征的类型相似度TySim和表格结构识别方法HSMTSR。同时,在构建的FSDS数据集上达到高效自动识别仪表询价电子表格结构的效果。
2 电子表格结构形式化定义
纵向电子表格RS通常由若干个行数据组成,可表示为
RS=[r1,r2,…,rn]T
(1)
式中:ri(i=1,2,3,…,n)表示表格中的一行数据;n表示行数;S表示sheet名。
本文把表格分为结构化表格和非结构化表格两大类,将结构化表格定义为表体区域不存在嵌套单元格的表格,反之为非结构化表格。同时,将表格的行数据分为表格的表头、属性、数据和表尾4类,其中属性(包括索引)和数据两类数据共同构成表格的表体,具体定义如表1所示。

表1 电子表格行数据类别定义
表格结构识别可转化为一个判断每行数据类别的问题,即一个多分类问题。设电子表格RS的类别标签序列为AL,结构识别方法为TSRM,则标签序列和模型可表示为
AL=[a1,a2,…,an]T
(2)
AL=TSRM(RS)
(3)
式中:ai(i=1,2,3,…,n)指表格中的某行数据ri的标签,ai∈{0,1,2,3},0为表头标签,1为属性标签,2为数据标签,3为表尾标签。
3 方法
结合第2节电子表格结构形式化定义,提出结合Levenshtein距离、Dice系数和TySim相似度的混合相似性度量电子表格结构识别方法HSMTSR。
3.1 HSMTSR表格结构识别
如图1所示,HSMTSR表格结构识别方法将整个表格解析识别为表头、属性、数据、索引和表尾,其运行体系结构如图2所示,将整个电子表格作为输入,经过两阶段解析识别表格结构。其中,第一阶段为整体解析,将表格解析识别为表头、表体和表尾;第二阶段为局部解析,将表体解析识别为索引、属性和数据。

图2 HSMTSR方法运行体系结构
整体解析:利用基于仪表参数词库的关键词相似度匹配方法解析识别表头和表体。在仪表领域专家指导下,通过分析数据集,积累专业知识,建立仪表属性词库,其中包括仪表询价所需的相关参数和别名信息。根据建立的词库进行相似度匹配,把出现属性的表格单元格标记为1,没有出现属性的标记为0,将整个表格转化为一个n×m的矩阵,可表示为

(4)
式中:rij∈{0,1};n为表格行数;m为列数。
取矩阵Matn×m行元素之和的最大值所在位置作为表体开始位置,若最大值有多个,则取位置较大的行号值,即可解析识别出表头和属性所在位置。
利用混合相似度方法HSMTSR解析表体和表尾。根据式(5)计算出行数据的混合相似度 MixSim,并根据阈值λ判断是否相似。若MixSim≥λ,则判断2行数据相似,同为表体数据;若MixSim<λ,则判断2行数据不相似,所在位置中行号值大的行数据为表尾数据,行号值小的数据为表体数据。由于表格的多样化,判断相似时设置固定阈值并不合适,于是将阈值λ动态的设置为每个表格行相似度的均值。
局部解析:又可称为表体解析,将表体具体解析识别为索引、属性和数据3类。把表体左上角的第一个单元格作为索引,通常指序号、位号或编号等信息。索引跨越的行数为索引区深度Dindex,并称索引对应的列数据为索引数据。根据Dindex可判断属性区跨越的行数,将表体前Dindex行作为属性区(除索引外),其余为数据区。值得注意的是,由于表格的不规范性,索引区深度Dindex可能与属性区深度Datt不一致,这时需寻求索引区所在行的单元格深度最大值作为索引区深度,并更新索引和属性区域。
3.2 混合相似性度量
3.2.1 混合相似度MixSim
结合Levenshtein距离、Dice系数和余弦相似度的优缺点,本文中提出基于余弦相似度的类型相似度TySim来提取表格单元格类型特征,并采用线性加权的方式融合3种相似性度量方法生成混合相似度MixSim,可表示为
MixSim=αLevSim+βDiceSim+γTySim
(5)
式中:α+β+γ=1,α、β、γ是实验值,经实验本文中α取0.35,β取0.35,γ取0.3。
3.2.2 基于向量空间的类型相似度TySim
结合电子表格单元格的类型特征向量化仪表询价电子表格,用余弦相似度处理向量化的电子表格,从而得到行数据的TySim,并以此为基础判断行数据是否相似。
电子表格单元格的类型特征TyVector由单元格类型ctype、单元格数据类型dtype以及单元格数据长度slen组成,可表示为
TyVector=[ctype,dtype,slen]
(6)
式中:ctype∈{0,1,2,3,4,5},0表示空(empty),1表示字符串(string),2表示数字(number),3表示日期(date),4表示布尔型(boolean),5表示错误(error)。dtype∈{0,1,2},0表示单元格数据中全为字符,1表示全为数字,2表示既有数字又有字符。
向量A、B的余弦相似度可表示为
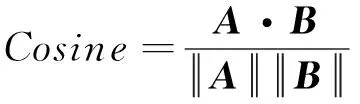
(7)
归一化的余弦相似度可表示为
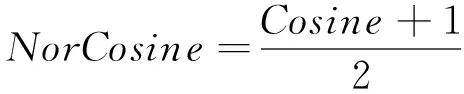
(8)
则单元格a,b的TySimcell可表示为
TySimcell(a,b)=NorCosine(TyVectora,TyVectorb)
(9)
行数据x,y的TySim可表示为
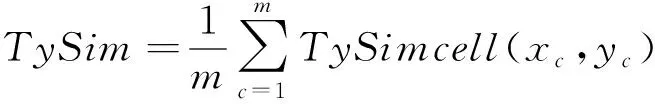
(10)
式中:m为表格列数;xc为行数据x中第c个单元格;yc为行数据y中第c个单元格。
3.2.3 基于序列的Levenshtein相似度
Levenshtein距离是编辑距离的一种,指在2个字符串之间,由一个转为另外一个所需的最少编辑次数。其中,编辑操作包括更换、删除和插入,其相似度函数和距离函数可以通过一个递减函数互相转换。
对于字符串X、Y,用动态规划的思想来计算Levenshtein距离,则X的前i个字符和Y的前j个字符的Levenshtein距离表示为

(11)
式中: |X|、|Y|分别表示字符串X、Y的长度;1X[i-1]≠Y[j-1]是一个指示函数,仅当X[i-1]=Y[j-1]时,值为0,其余时候为1。
字符串X、Y的Levenshtein相似度可表示为
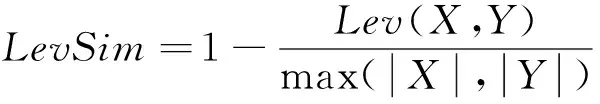
(12)
式中:Lev(X,Y)表示字符串X、Y的Levenshtein距离。
3.2.4 基于集合的Dice相似度
Dice系数(dice coefficient)是衡量2个集合的相似度的一种指标。当把字符串理解为一种集合时,Dice系数也可用于度量字符串的相似性。
字符串集合A、B的Dice相似度可表示为
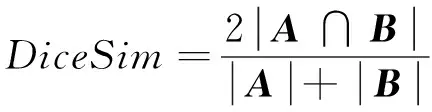
(13)
4 数据集构建
4.1 数据集概况
本文以某仪表公司的电磁流量计询价电子表格作为实验数据集,表格中包括仪表概况、工艺条件、转换器和变送器等相关参数信息。
电子表格通常按照内容布局分为纵向表格、横向表格和混合表格三大类。鉴于人们的使用习惯和数据集情况,本文主要针对纵向电子表格(表格中属性和数据均为上下关系)进行结构识别。因此,本文的相关表格描述统一指纵向仪表询价电子表格,典型表格样例如表2所示。
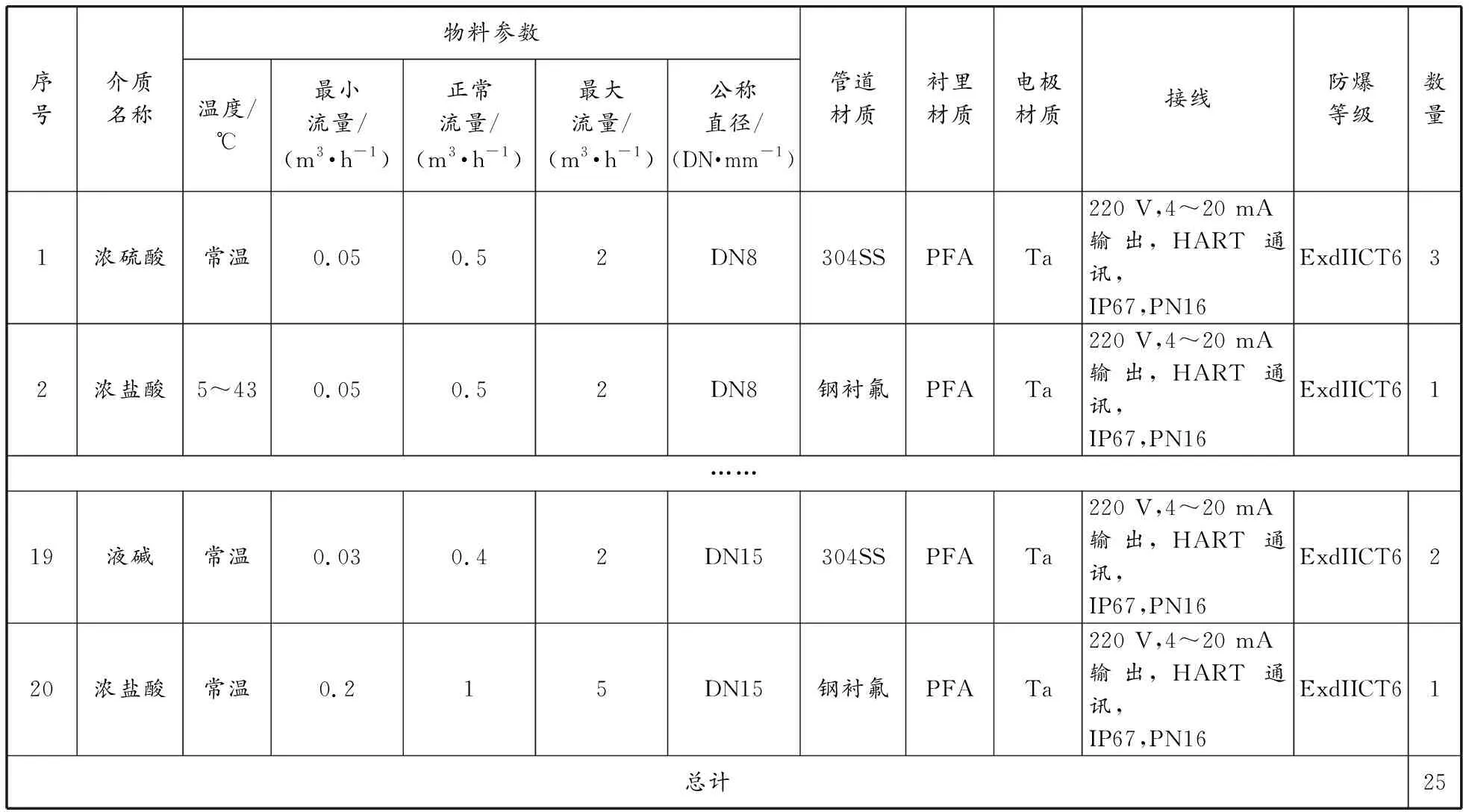
表2 纵向表格样例
本文对收集的电子表格进行清洗、筛选和规范化,构建了流量仪表电子表格数据集FSDS,其概况见表3。整个数据集包含714个Excel电子表格文档(xls格式262个,xlsx格式452个),750个sheet(一个Excel电子文档可能包含多个sheet,xls格式273个,xlsx格式477个)和8 574行数据。其中,结构化表格54个、非结构化表格660个;结构化sheet数55个、非结构化sheet数695个。
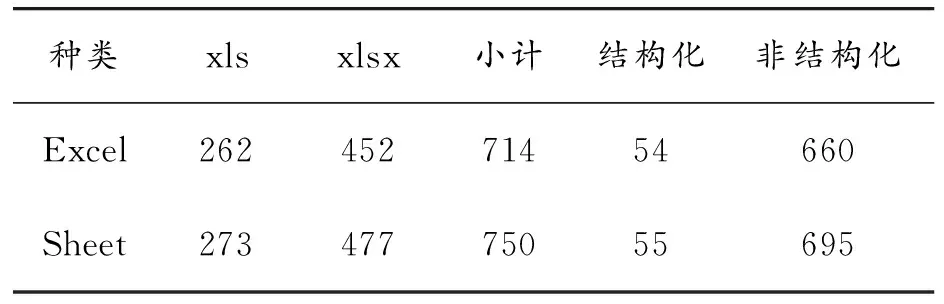
表3 数据集概况
4.2 数据预处理
数据预处理主要包括数据清洗和数据脱敏两类。本文中数据清洗包括去除冗余信息和规范存储数据;数据脱敏主要采用数据替换的方式,隐藏了公司和个人相关的敏感信息。
4.3 数据标注
针对提出的HSMTSR方法和表格结构识别任务对数据集进行标注。标注内容包括表格结构区域(表头、表尾、数据、属性)、表格类型(结构化、非结构化)、表格名称、sheet名称、表格编号等信息。其中,标注区域格式采用电子表格中单元格坐标的表示方式,如表体区域为A1:F9,采用json格式存储标注,并组合表名和sheet名称命名标注文件。
5 相关实验
5.1 实验设置
实验硬件环境为Intel(R) Core(TM) i5-9500 CPU,NVidia GeForce RTX 2080 Super GPU。软件平台为Python3.7,利用xlrd、xlwt模块对电子表格进行读写,设置相似度阈值λ,取值为表格行相似度均值。混合相似度MixSim中α为0.35,β为0.35,γ为0.3。
5.2 评价指标
分别利用准确率(accuracy)、查准率(precision)、召回率(recall)和F1值(F1-Score)评估算法的优劣程度。
加权宏平均(Weighted-average):给不同类别分配不同权重(权重根据该类别的真实分布比例确定),每个类别加权后再相加。

(16)

整表识别准确率:整表中全部解析识别正确的表格数目Nright和总表格数目Ntotal的比例。
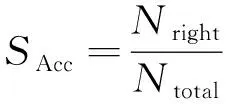
(17)
5.3 对比实验及分析
LevSim字符串匹配准确度高,DiceSim可解决字符串连续问题,TySim可提取表格单元格的特征,所以考虑利用级联的思想,充分发挥各种相似度算法的优点,从单个相似度度量到结合2种相似性度量,再到结合3种相似性度量,以及设置不同权重在数据集FSDS上进行相关实验,实验结果如表4所示。
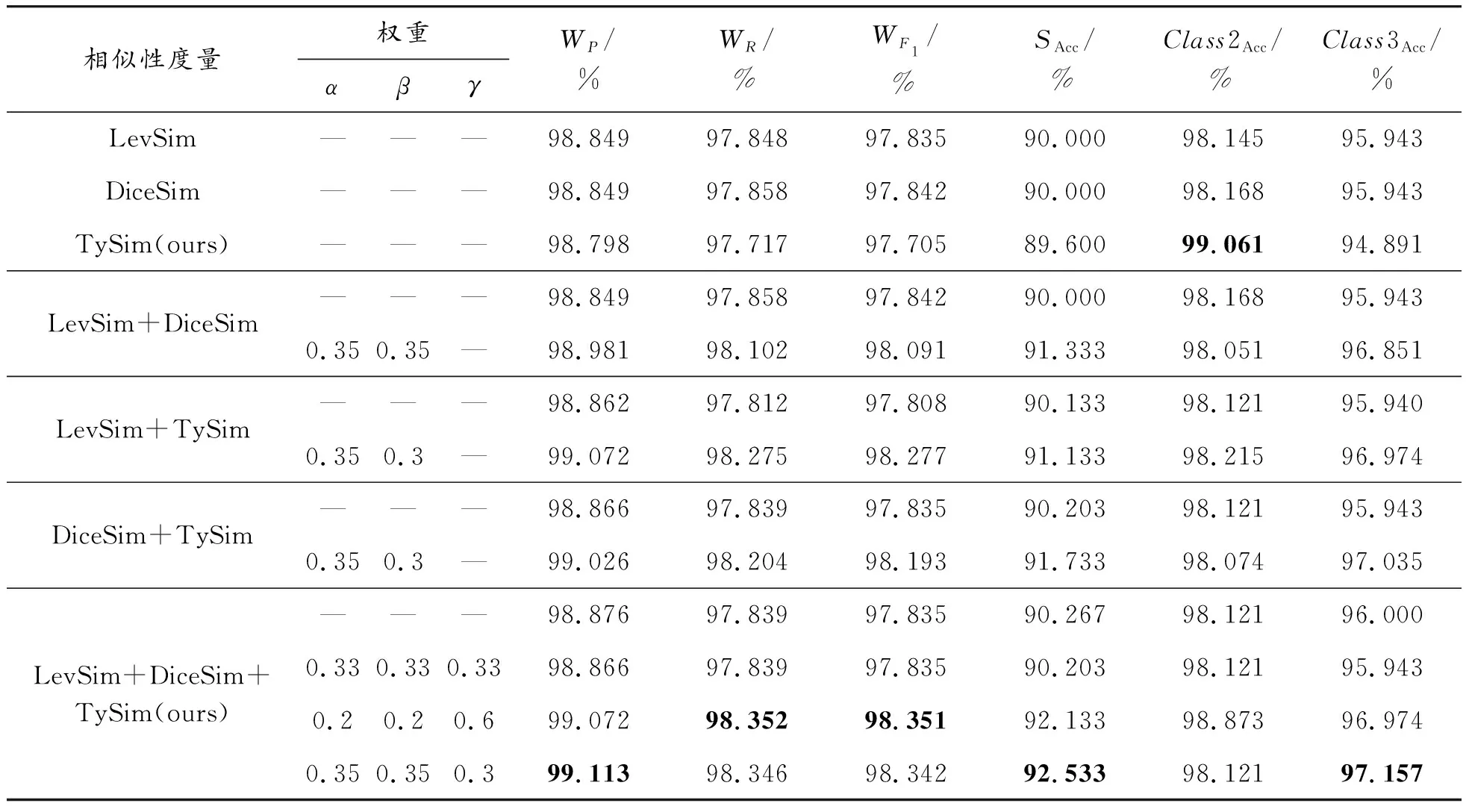
表4 实验结果
表4中列举了在单相似性度量、双相似性度量、混合相似性度量、加权双相似性度量和加权混合相似性度量等多种条件下的实验结果对比。从表4可知,LevSim和DiceSim可有效对表格中文本字符串进行精确匹配,结合TySim提取了表格中的特征,对类别2和类别3的精确分类有正向作用。混合相似性度量实验中,整表识别准确率SAcc、查准率WP及类别3分类效果Class3Acc均有所改善,证明混合相似度方法的有效性。
上述3种单相似性度量方法各具优势,但在融合各种方法时,需要优化各种方法的权重占比。由表4可知,未加权的混合相似度的算法识别准确率SAcc虽有所改善,但效果不明显,可考虑利用线性加权的方式对各种相似性方法进行平衡。实验结果表明,混合相似度中平均分配权重不合理,需要重新分配不同的权重。而单个相似度实验表明,LevSim和DiceSim方法实验效果基本持平,而TySim提取了表格单元格的类型特征,并基于余弦相似度来计算,是从向量方向上进行区分,与前2种相似性度量区别较大,因此我们选择给LevSim和DiceSim分配同样的权重,给TySim分配不同权重。加权实验结果表明,当分配不同权重给TySim时,准确率开始发生较大变化,当TySim的权重稍小时,效果更加明显,且当α=0.35,β=0.35,γ=0.3时效果最好。
图3和图4为单相似性度量、加权混合双相似性度量和加权混合相似性度量的各个指标对比实验柱状图。
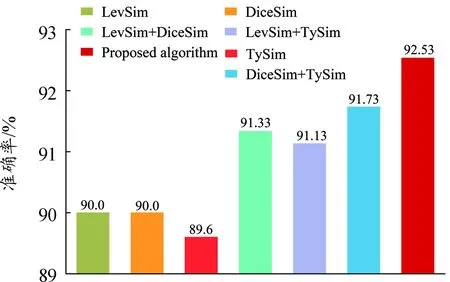
图4 表格准确率
〗
由图3、图4可知,与未加权的相似度实验对比,加权的混合相似度在SAcc、WP、WR和WF1上表现较好,且在混合双相似性度量的实验中加对应权重,实验效果也有相应的提升,证明了加权平衡的有效性,有效提高了表格识别的准确率。
6 结论
对自动化仪表询价电子表格的结构识别进行了研究,提出的HSMTSR方法可有效解析识别仪表询价电子表格结构,构建的真实流量仪表询价电子表格数据集FSDS为研究分析表格结构提供了便利。实验结果表明,HSMTSR方法可使表格行分类准确率达到97.157%,整表结构识别精度达到92.533%,证明该方法的可行性和有效性。自动化仪表询价电子表格结构识别的实现和准确率的提升为构建无人化询价系统奠定了基础,未来将结合语义进行表格内容识别和参数提取,完成无人化询价系统的构建。
