基于Deeplabv3+的猕猴桃特征提取和自动分级研究*
2024-01-30郝家英曾玉娇王祥文刘文江
郝家英 ,曾玉娇 ,王祥文 ,陈 园 ,刘文江
(贵州财经大学信息学院,贵州 贵阳 550025)
0 引言
猕猴桃是我国主要的果树品种,猕猴桃口感鲜嫩,营养价值高,具有丰富的膳食纤维、微量元素、糖分、维生素A和钙、钾、铁等多种矿物元素。近年来,国内猕猴桃不断增产,产量已多年位居世界第一[1]。猕猴桃的品质分级是生产过程中提高其附加值的重要环节,直接关系到猕猴桃的经济价值和出口贸易竞争力。目前猕猴桃除单果重能进行机器识别外,其他分级指标如果径、果形、表面缺陷等都依靠人工识别,效率低且准确率不高。因此,近年来有许多学者对猕猴桃的分级进行了研究,其中崔永杰等对猕猴桃果实进行了分类鉴定,对图像进行中值滤波等操作提取缺陷,分析了如何正确识别分割出来的可疑区域[2]。屈婷等利用计算机视觉技术,实现了猕猴桃果实外形尺寸的在线监测和分级,其平均分类成功率为96.3%,单一猕猴桃的分级时间为2.5 s左右[3]。刘忠超等提出了一种利用计算机视觉与PLC相结合的大小分级控制系统,该系统的分类精度达到100%,分级速度为2.5 s/次,效率较低[4]。当前猕猴桃的缺陷识别与分级大多是基于传统图像处理技术进行,无法完全脱离人工操作,且对图像的质量要求高,可靠性差,无法满足猕猴桃现有的分级需求。
基于深度学习的图像识别算法在图像处理方面有明显优势和发展前景,能够促进水果分级的高效率、高质量,已经在苹果[5-7]、香蕉[8]、柑橘[9-10]等水果的分级中得到了广泛应用。但当前研究还存在诸多局限性,一方面是现有检测研究大多面向重量、颜色、大小等初级指标,鲜有对检测物外观和损坏情况进行检测的研究;另一方面,猕猴桃作为我国主要水果之一,相应的检测研究却较少。本研究将基于多特征融合和卷积神经网络相结合的方法来对猕猴桃图像进行检测与分级,促进深度学习技术在猕猴桃检测领域的技术实现,以此为人类提供更健康、安全、高效和优质的农产品,同时也为其他同类型农产品的检测与分级提供借鉴参考。
1 研究方法
1.1 模型架构
本文以Deeplabv3+分割算法为基础,通过分析缺陷果的缺陷面积对猕猴桃进行分级。采用轻量级卷积神经网络MobileNetV2作为图片特征提取工具,将其运用到Deeplabv3+模型中,通过空洞卷积及金字塔模型结构对猕猴桃鲜果缺陷进行分割,最后在训练好的模型上实现对果形缺陷区域的检测,并计算出其与果实面积的比率,以此来对猕猴桃鲜果进行分级处理,具体实现主要包括猕猴桃数据集的构建、神经网络模型的搭建以及数据集的训练三部分,系统流程图如图1所示。
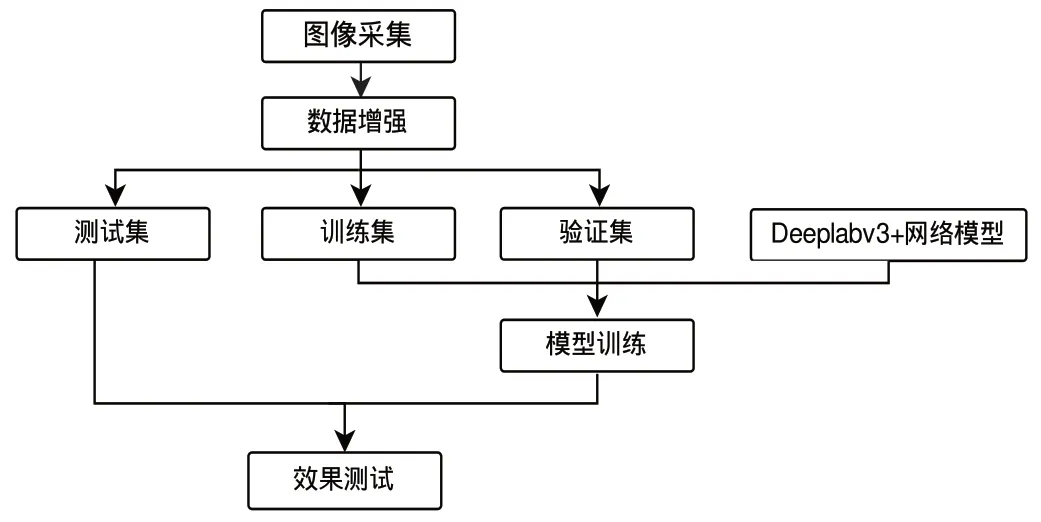
图1 系统流程图
该系统由编码器和解码器两部分构成:编码器的核心是卷积神经网络,其中包含了空洞卷积,通过采用金字塔池化模块,并引入不同膨胀率,实现多尺度信息的融合,负责图像特征提取并输出特征图。解码器模块将高层特征双线性插值得到4倍的特征,该算法将低层特征进行1×1卷积以降低其维度,使网络变得更薄。接着,通过卷积融合低层和高层特征,并通过反卷积操作将融合后的特征图恢复到与原始输入图像相同的尺寸。具体的模型构建如图2所示。
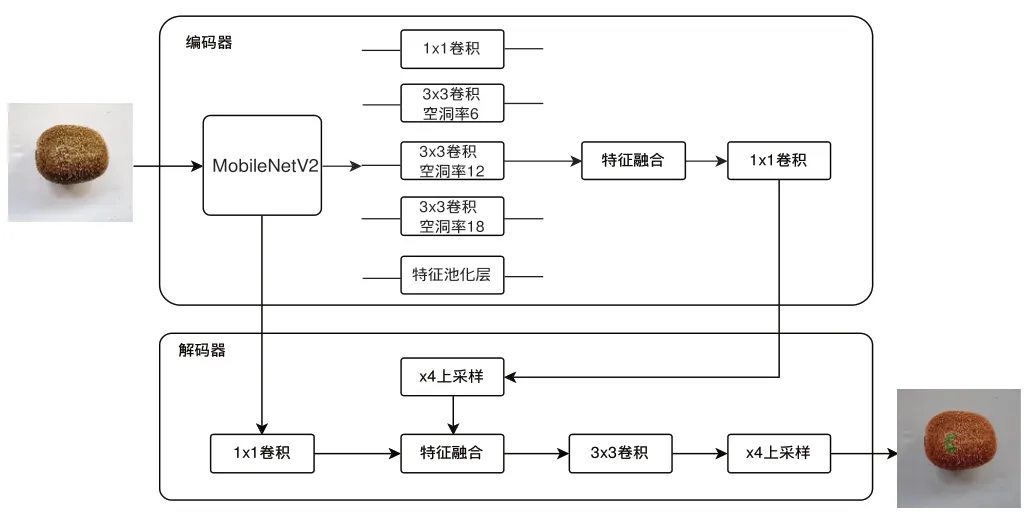
图2 模型构建
1.2 核心技术
1.2.1 Deeplabv3+网络模型
语义分割网络Deeplabv3+具有高精度、轻巧、综合性能突出的特点,它包括编/解码结构、深度卷积神经网络、空间金字塔结构,特征提取网络是Xception,卷积运算是空洞卷积运算,以Deeplabv3+作为编码模块,通过增加一个简单而高效的解码模块,实现了更好的语义分割。其中Deeplabv3+网络主要有以下两个特点:一是采用了编、译码结构,将Deeplabv3+模式作为编码结构,并在编码器的后面设计对应的译码结构,使其具有与原图同样大小的特征像素信息;二是将ResNet101中传统的卷积层引入深度可分离卷积替代,以实现快速、准确地提取目标图像中的特征像素信息。该方法通过改变扩展卷积的步长来控制输出的特征,从而实现对特征的有效编码,减少了系统的运算资源。
具体而言,Deeplabv3+网络模型通过改变空洞率来控制卷积感受野值,从而能够有效地提取任意尺寸的特征,这是以往的编码和解码技术无法实现的。同时,该模型采用了可分割的深度卷积技术,将编码结构中的目标像素特征与译码结构相结合,以达到更好的融合效果。因此,编、译码网络的结构操作更具时效性和较高的分割精度。
1.2.2 网络的轻量化
特征提取网络使用MobileNetV2代替Xception。MobileNetV2网络核心操作为深度可分离卷积,使用深度可分离卷积来降低网络的计算复杂度,以此来对网络进行压缩和提速。本文采用MobileNetV2轻量化网络,极大地降低了猕猴桃图像识别过程中的实验参数,如表1所示。

表1 两种网络参数对比
MobileNetV2网络引入了ResNet残差思想,通过高维特征结合ReLU激活层,该算法的核心在于尽可能地保留多的低维输入信息,其中,反向残差块起到了至关重要的作用,如图3所示。
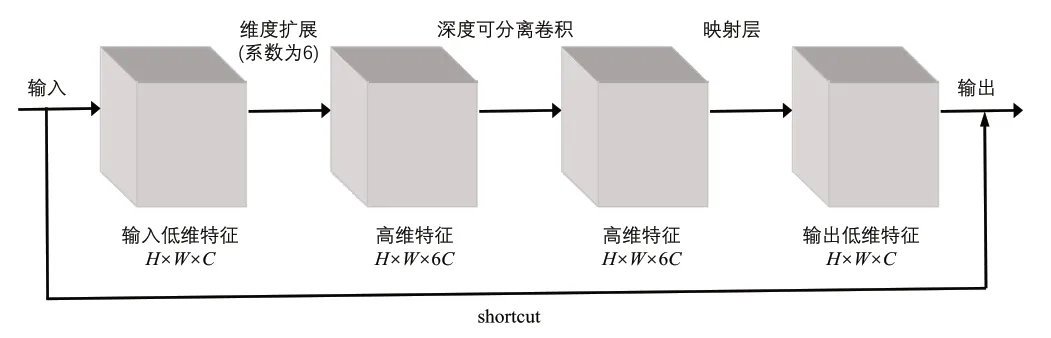
图3 反向残差块
在反向残差块中,首先,该算法对输入的低维特征进行维度扩展,将维度扩展系数设置为6,以获得高维特征,再执行深度可分离卷积,然后该算法去除了最后一个ReLU激活层,用映射层代替,最终输出低维特征。
2 数据集的构建
2.1 图片采集
本实验中的猕猴桃数据集图片来源于对购买的猕猴桃进行实物拍摄。实验中采集了466张猕猴桃图片,其中包括336张没有损伤的猕猴桃图片以及130张有瑕疵的猕猴桃图片。采集的图片分为两部分,一部分采用了空白背景,另一部分模拟猕猴桃在流水线中的场景,将其用于检测复杂背景是否会影响图片的分割效果,每张图片的分辨率均为800×800。两种实验背景下猕猴桃有无缺陷的图片对比,如图4所示。

图4 有无缺陷猕猴桃图片对比
2.2 数据增强
深度神经网络模型复杂,要实现较好的训练效果需要大量的实验数据作为基础。对已标注的数据集进行分割、模糊并随机改变图片的色调、饱和度和值等,实现对数据集的5倍增强(数据增强数据集中的一张图片如图5所示),获得2 016张没有损伤的猕猴桃图片以及780张有瑕疵的猕猴桃图片,共2 796张猕猴桃图片。在此基础上,将样本按8∶2分成训练集和验证集。

图5 数据增强
3 实验方法
3.1 评价指标
为了评价本研究改进的不同等级猕猴桃分割检测模型的有效性,选取分类的平均像素精度(MPA)和平均交并比(MIoU)作为评价指标。分类像素精度(CPA)指的是在分类i的预测中像素的正确率是i类,如式(1)所示。
其中,TP为真正例,FP为假正例,FN为假反例,TN为真反例。
类别平均像素准确率MPA指的是计算类中像素正确分类的比例Pi,再将其进行平均,如式(2)所示。
交并比IoU指的是该模型在预测结果与实际数值之间交集与并集之比,如式(3)所示。
平均交并比MIoU表示计算该模型中所有类别交并比的均值,如式(4)所示,也可等价于公式(5)。
其中,k表示种类;(k+1)表示加上了背景;pij表示把i类预测为j类的假反例FN;pji表示把j类预测为i类的假正例FP;pii表示把i类预测为i类的真正例TP。
3.2 损失函数
由于邻近等级的猕猴桃个体间的差别很小,导致邻近的猕猴桃被误认,而用交叉熵作为损耗函数,在相同的随机变量中可以测量两个不同的概率分布,并用机器学习的方法来表达实际和预测的概率分布,从而解决了相邻等级猕猴桃的错误识别问题。交叉熵损失(CE)函数如式(6)所示。
其中,K表示种类数目;y表示标记,若类别为i,则yi=1,反之为0;Pi表示输出类别i的可能性。
其计算步骤如下:1)求出e关于输入向量的每个元素的幂;2)将所有的幂相加,得到分母;3)每一个幂,作为相应位置输出结果的分子;4)输出的概率=分子/分母。
3.3 训练过程
研究采用pytorch_gpu深度学习框架,Python 3.7语言,CPU为Inte(lR)Xeon(R)Gold 5218,内存为64 GB,主硬盘SK hynik SC401 SATA 512 GB,GPU在NVIDIA RTX 2070的服务器上运行,操作系统为Windows。所有模型训练及测试都在同一硬件条件下进行。本实验将学习率设定为0.000 01,并在此基础上,逐步将学习率降低到原本的92%。同时,不同批次的训练样本数目也会影响到模型的学习速度。为了达到记忆效能的最优均衡,本文把训练批次分成两个阶段,共100个迭代,其中前50个先冻结主干训练,后50个解冻训练参数。在此基础上,将训练样本的数目设定为16,从而大大缩短了训练的时间,提高了资源利用率。在未冻结的迭代中,先将被冻结的部位解冻,然后进行完整的训练,提高训练参数,以达到记忆效能的均衡,每个批次的训练样本数目设定为4。将全部2 796张图片,按8∶2的比例分为训练集(2 237张)和预测集(559张),前50次迭代每批次训练样本为16张,后50次迭代每批次训练样本为4张。设置当验证集的损失函数10次内没有下降,即可停止训练,优化器为Adam。
4 实验结果分析
4.1 评价指标
在分割网络性能评估方面,选取平均像素精度(MPA)和平均交并比(MIoU)作为评价指标。这些指标在图像分割领域被广泛应用,可用来客观评估模型的分割效果。实验进行猕猴桃缺陷分割时,将每张图像分为了三个类别,即背景(background)、猕猴桃(tiwi)以及猕猴桃上的缺陷(tiwi_flaw)。通过对这三个类别的像素分析,能够全面了解模型在分割上的性能,以及其在边界匹配和分割精度方面的表现。
分割模型评价指标如表2所示,其展示了分割网络在不同类别下的MPA和MIoU得分。通过这些定量的结果,可以客观地评估所提出方法的有效性,并深入探讨模型在不同任务和类别上的优势与局限性。
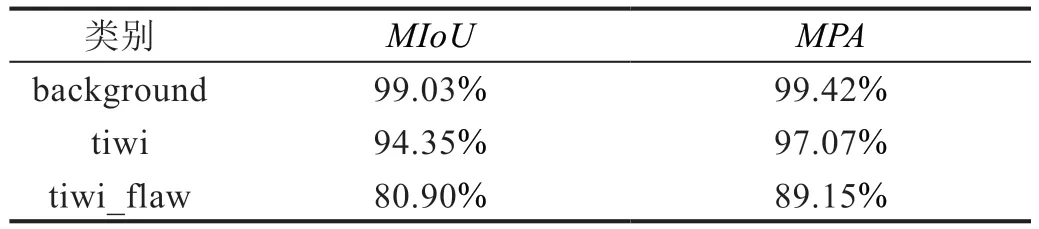
表2 分割模型评价指标
通过以上的指标,可以看出模型在背景与猕猴桃的分割任务中几乎完美地捕捉到了目标的形状和边界,而对于猕猴桃上的缺陷分割,猕猴桃缺陷像素级分类准确度达到了89.15%,猕猴桃预测缺陷的分割区域与实际缺陷标签区域之间的重叠度达到了80.90%。从评价指标可以看出这是一个很有希望的、比较准确的分割模型。
4.2 损失函数
本次实验猕猴桃图片的数据集总样本共2 796张,实验将训练集与测试集按照8∶2的比例进行划分。模型的loss值变化曲线如图6所示。
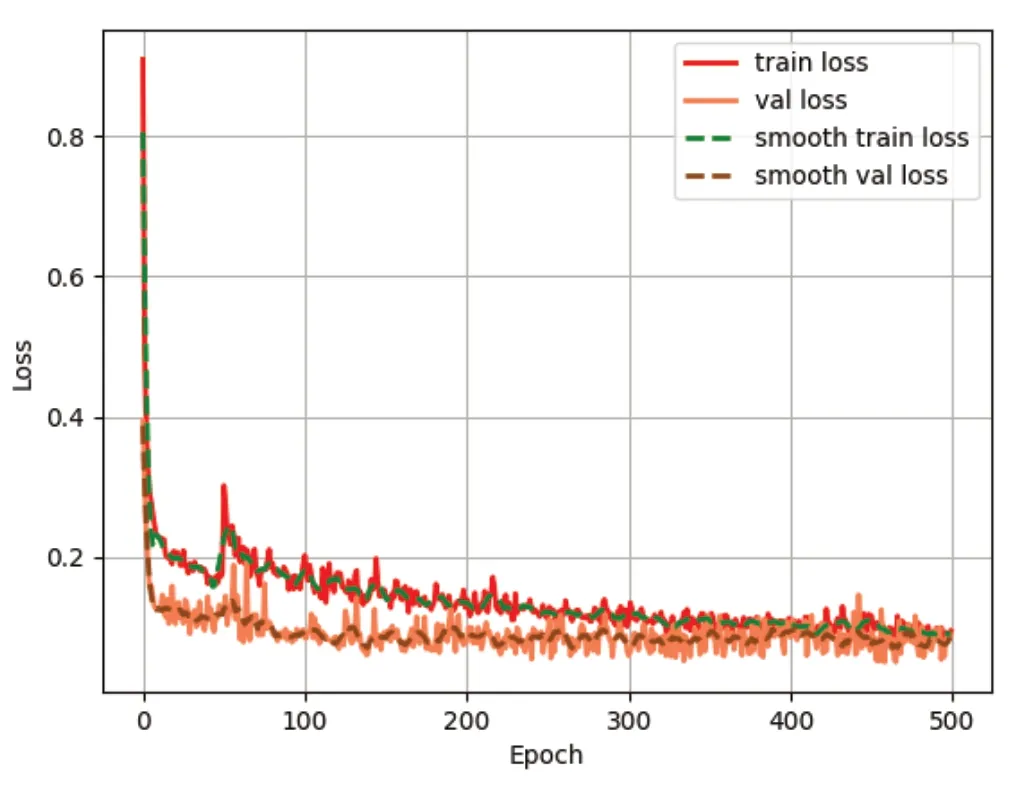
图6 图像损失函数
在图6中,横坐标代表迭代次数,纵坐标代表所计算的loss,train loss代表训练时所计算的损耗;val loss代表在确认中所计算的损耗;smooth train loss代表在训练时所计算的平滑损耗;smooth val loss代表在验证确认中所计算的光滑损耗值。Deeplabv3+模型训练时train loss从第一个迭代值0.879开始,到60个迭代值0.184,然后逐步趋于平稳,70个迭代时train loss增加到0.314,最后在500个迭代中降到0.118。val loss从第一个迭代值0.348开始,到60个迭代值0.121,然后逐步趋于平稳,最后在500个迭代时降至0.108。经过计算,Deeplabv3+模型的训练耗时2 466 s,参数值5 813 266,参数尺寸22.18 MB,操作次数1.05 GFlops,优化器为Adam。
4.3 验证结果
取24个猕猴桃作为验证实验对象,采用人工判定的方式,参照GB/T 40743—2021《猕猴桃质量等级》,将24个猕猴桃按照猕猴桃表面泥土、已愈合刺伤等面积大小分为特级、一级、二级和等外。再对样本猕猴桃图片通过旋转等操作进行5倍增强处理,得到144张猕猴桃图片用于训练识别,计算识别率结果。传统的研究对于猕猴桃的缺陷处理通常使用BP神经网络等分类网络,本次实验采用了区别于常规方法的分割网络,以此来更好地分割出猕猴桃缺陷,在缺陷分级方面得到了较好的结果。与传统模型识别率对比如表3所示,Deeplabv3+网络模型的验证集(部分示例)的测试结果如图7所示。

表3 与传统模型识别率对比

图7 Deeplabv3+模型生成结果
本方法的全等级识别率都明显高于传统计算机视觉方法,一级的识别率达到100%,二级、三级、四级识别率则分别为96.15%、95.83%和97.05%,这表明该方法在猕猴桃检测任务的准确性方面表现更优秀。同时,该方法能够降低设备的计算负载并加快运行速度,满足工业猕猴桃检测的实时性要求,在实际应用中可以更快地完成猕猴桃的检测任务,并且能够降低系统的计算负担。因此,该方法在准确性和计算负载方面具有明显的优势。
5 结论
本文在Deeplabv3+网络框架的基础上进行改进,利用MobileNetV2作为特征抽取网络减少参数和运算量,并运用此网络模型进行猕猴桃的特征抽取和分类,提高了网络的运行速度。通过图片采集、滤波处理、数据增强等步骤完成对猕猴桃的数据集归纳,进而进行网络模型训练。结果表明,该方法检测的准确性高于传统计算机视觉方法,具有训练时间短、空间复杂度低等优点。这一结果与其他文献[12]的研究结果一致,该方法在猕猴桃图像的特征抽取和分级任务上具有较好的表现。
