基于深度条件子域自适应网络的轴承跨域故障诊断研究
2024-01-18范永胜邓艾东
范永胜, 丁 雪, 邓艾东
(1.国家能源集团江苏电力有限公司,南京 215433; 2.大型发电装备安全运行与智能测控国家工程研究中心,南京 210096; 3.东南大学 能源与环境学院,南京 210096)
随着装备制造业的快速发展,旋转机械已广泛应用于各行各业[1]。滚动轴承作为旋转机械中不可或缺的零部件,因其长期受到交变载荷、磨损及化学侵蚀的作用,极易发生故障[2-3]。有效的故障诊断对及时消除设备的安全隐患[4],提高设备运行的可靠性和经济性具有重要意义。
近年来,深度学习以其诊断精度高、经验需求少的独特优势成为滚动轴承故障诊断领域的研究热点[5-6]。其中,卷积神经网络(CNN)、深度置信网络(DBN)和堆叠自编码器(SAE)等深度学习算法在故障诊断和状态监测领域取得了显著的发展。然而,高性能的故障诊断模型具有数据依赖性和敏感性,上述方法的成功应用往往基于2个主要假设[7],即训练数据和测试数据共享同一概率分布且均具有大量可靠的标签信息。但在实际应用场景中,该假设很难成立。一方面,随着机械设备的速度、负载、环境噪声等运行条件的不断变化,传感器采集的数据分布可能发生变化,从而导致模型的诊断性能下降;另一方面,设备故障很难发生,设备从正常到故障状态的退化过程需要很长时间,因此获取故障数据十分耗时且昂贵。
为解决上述问题,许多专家学者将迁移学习应用于故障诊断任务中。域适应作为迁移学习的一个重要分支,通过放宽上述2个假设条件,以寻找不同数据在特征空间中的相似性,从而减少源域和目标域的差异,实现诊断知识的迁移和数据分布的对齐,最终提高诊断模型的泛化能力。An等[8]开发了一种基于多核最大平均差异(MK-MMD)的框架,通过最小化不同域之间的差异,提高各工况下的故障诊断准确性;Li等[9]将相关对齐(CORAL)引入预测生成去噪自编码器,使模型适应负载的变化;Han等[10]提出了一种深度对抗性卷积神经网络,该网络利用额外的域鉴别器以及对抗性学习策略来学习不同领域之间的域不变特征;Wang等[11]提出了一种三元组损失引导的对抗域自适应网络,其性能优于Zhang等[12]提出的基于Wasserstein距离的对抗方法。上述方法在域适应故障诊断方面取得了一定效果,但它们主要是通过最小化源域和目标域的整体分布差异来进行全局对齐,很少考虑不同工作条件下相应子域(一个子域包含同一类别中的所有样本)间的分布差异。仅关注全局对齐会忽略不同子域之间的差异,丢失每个类别间的细粒度信息,进而导致子域之间的混乱域适应。
为解决上述问题,笔者提出了一种深度条件子域自适应网络(DCSAN)以进一步抑制不同子域决策边界间发生的负迁移。该网络由状态识别模块和条件子域自适应模块组成。状态识别模块用于对源域的健康状况进行精准分类。条件子域自适应模块利用多核局部最大平均差异(MK-LMMD)来最小化不同域间多模态映射特征之间的距离。多模态映射特征由分类器预测的置信度映射到共享特征提取器所提取的特征中得到,该映射通过考虑特征和标签的关系,有利于MK-LMMD进一步减少同一子空间中源域和目标域之间的距离,从而获得域不变特征,实现子域的对齐。笔者在江南大学数据集上对DCSAN模型的有效性进行了验证,并通过对比实验评估了DCSAN的性能,实验结果证明了DCSAN模型在子域对齐和跨域自适应故障诊断方面的有效性和优越性。
1 理论背景
1.1 无监督域适应
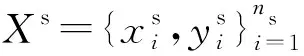
1.2 局部最大平均差异
无监督域适应主要的挑战是目标域中没有足够的样本标签,为解决该问题,研究者们大多通过最小化源域和目标域之间的距离来降低目标域的分类误差。其中,最大均值差异(MMD)[14]是域适应学习中应用广泛的非参数距离度量,可用于衡量源域和目标域之间的分布差异。MMD是一种核学习方法,能够衡量2个分布在再生希尔伯特空间中的距离。源域Xs和目标域Xt的最大均值差异可表示为
(1)
式中:dH为2个域之间的最大均值差异;p为源域的概率分布;q为目标域的概率分布;H为再生希尔伯特空间;φ(·)为再生希尔伯特空间中的映射函数。
(2)
其中,k为核函数,k(xs,xt)=〈φ(xs),φ(xt)〉,核函数k选择高斯核;若源域和目标域数据分布一致,即p=q,则dH(p,q)=0。
MMD是针对单一核变换实现不同域间距离的度量,而相关研究[15]表明,混有多个内核的MMD(即MK-MMD)可显著提高域适应的识别准确率。MK-MMD的表达式如下:
(3)
其中,dHK为2个域之间的多核最大均值差异;HK为具有多个核的再生希尔伯特空间。多核最大均值差异中的核函数k为多个核的线性组合,其表达式如下:
(4)
式中:βu为确保生成的多核k是任务所特有的约束因子;ku为不同的子核。
虽然MK-MMD也取得了一定的效果,但MK-MMD仅在2个域间进行全局对齐,忽略了2个域内同一类别子域之间的关系,这可能使每个类别中的细粒度信息丢失。为解决上述问题,笔者采用具有MK-MMD的局部最大平均差异[16]来计算跨不同域的每个类别分布之间的差异。在考虑相关子域相关性的基础上,MK-LMMD可以计算局部分布差异,使源域和目标域中同一类别相关子域间的分布更加接近。MK-LMMD可表示为
(5)


1.3 多模态特征映射
跨域自适应过程中,当设备的运行数据反映出复杂的多模态结构时,仅依靠所提取的特征进行不同领域间的自适应对齐可能存在一定困难。根据文献[17],分类器所预测的置信度中携带了潜在的反映多模态结构的判别信息。基于此,笔者通过将该置信度映射到所提取的特征中,利用置信度这一条件使特征在域适应过程中自适应对齐,从而在网络训练中捕获更多的多模态信息,更好地匹配不同子域间的分布。多线性映射策略M如下:
M(f,g)=f⊗g
(6)
式中:f为特征提取器提取的源域或目标域特征;g为分类器预测的源域或目标域在不同类别上的置信度。
基于式(6),MK-LMMD被修正为
(7)

2 深度条件子域自适应网络
2.1 模型结构
DCSAN模型结构如图1所示。所提出的网络包含状态识别模块和条件子域自适应模块两部分。状态识别部分由提取源域、目标域特征的共享特征提取器和识别设备健康状态的分类器组成。条件子域自适应部分利用MK-LMMD减少了不同域中多模态映射特征之间的分布差异,从而实现子域的对齐。
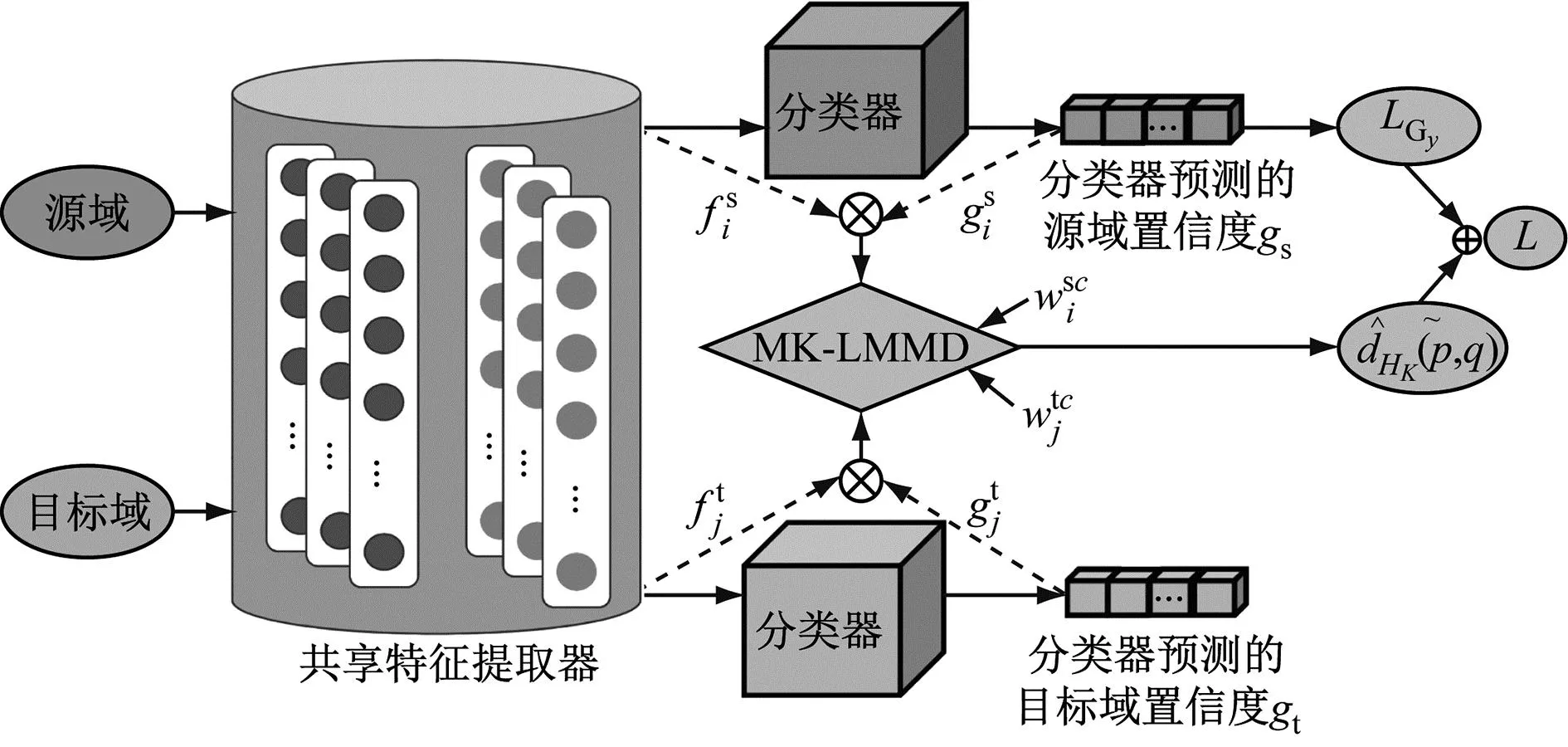
图1 DCSAN模型结构Fig.1 Model structure of DCSAN
2.1.1 状态识别
特征提取和健康状况分类是状态识别的两部分。特征提取部分采用4层卷积、2层池化和1层自适应平均池化层组成的二维卷积神经网络。健康状况分类部分由3个全连接层组成,在输出层,采用Softmax函数作为分类器来获取样本属于某一类别的置信度和其健康状况。DCSAN的具体网络参数见表1,Conv@m*1*n*n为二维卷积运算,表示m个卷积核,卷积核的大小为n。Pool@2*2为最大池化操作,表示窗口大小为2,步长为2。AdaptiveMaxPool为自适应平均池化层。FC(c)表示全连接层,其中包含c个神经元。

表1 DCSAN的网络参数Tab.1 Network parameters of DCSAN
2.1.2 条件子域自适应
将分类器预测的置信度映射到共享特征提取器所提取的特征中,得到源域和目标域的多模态映射特征。利用MK-LMMD计算上述不同域多模态映射特征之间的子域分布差异,通过减少整个训练过程中的MK-LMMD损失函数,使源域和目标域中同一类别相关子域间的分布更接近。
2.2 优化目标
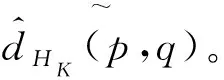
其中,
(8)
式中:Ly为交叉熵损失函数;F为共享特征提取器;Gy为分类器。
综上,DCSAN的总体损失函数L为
(9)
通过最小化L实现源域和目标域中同一类别相关子域间的对齐。
3 实验分析
3.1 江南大学(JNU)轴承数据集
采用JNU收集和提供的轴承数据集对本文所提方法的有效性进行验证。该数据集的实验装置由三相感应电机、加速度传感器、信号调节器和信号记录仪组成。加速度传感器直接安装在电机驱动端外壳的上方,采样频率为50 kHz。
在本实验中,所使用的JNU数据集包含正常状态(NC)、内圈故障(IF)、外圈故障(OF)和滚动体故障(BF)4种轴承状态,具体标签说明见表2。分别在600 r/min、800 r/min和1 000 r/min 3种转速下采集振动信号,并将JNU数据划分为Ⅰ、Ⅱ和Ⅲ 3个数据集,设置6个迁移学习任务。其中,任务Ⅰ→Ⅱ表示源域数据为转速为600 r/min时的振动信号,目标域数据为转速为800 r/min的振动信号。

表2 JNU轴承数据集标签说明Tab.2 Label description of JNU bearing data set
实验采用滑动窗口分割的方式生成样本。每种轴承状态取1 200个样本,每个样本2 500个点。笔者将一维振动信号直接转化为二维信号作为模型的输入,即一维原始数据[2 500,1]直接重构为[50,50]。选取所有的源域样本和一半的目标域样本用于训练,而剩余一半的目标域样本用于测试。
3.2 实验参数
在实验中,采用了动量为0.9,动量衰减为0.001的随机梯度下降(SGD)优化器。初始学习率为0.01,并逐渐衰减。模型训练批次大小设置为64,训练次数为15。
3.3 对比方法
为了更全面地评价DCSAN的有效性和优越性,选择3个具有代表性的方法与DCSAN进行对比:
(1) 深度适配网络(DAN)[15]:将特定任务层的深度特征映射到再生希尔伯特空间中,通过最小化MK-MMD 进一步减少域差异。
(2) 域相关性对齐方法(D-CORAL)[18]:在模型中使用相关对齐作为二阶矩匹配来减少分布差异。
(3) 基于对抗学习域适应方法(DANN)[19]:在网络中添加一个域鉴别器,通过一个极大极小博弈来提取域不变特征。
3.4 跨工况故障诊断结果
为验证本文方法的有效性,将所提DCSAN模型与其他3种对比模型分别应用于6种迁移任务,这些方法的故障识别准确率见表3。从表3可以看出,在5个跨工况自适应故障诊断任务(Ⅰ→Ⅱ、Ⅰ→Ⅲ、Ⅱ→Ⅲ、Ⅲ→Ⅰ、Ⅲ→Ⅱ)中,DCSAN模型的准确率均高于其他3种对比模型。其中,DCSAN模型的诊断准确率比对比模型的最高诊断准确率分别高6.2百分点、22.9百分点、8.8百分点、3.6百分点和7.0百分点。虽然在Ⅱ→Ⅰ迁移任务中,DCSAN的诊断准确率低于D-CORAL,但仅低1.8百分点。而在6个变工况迁移任务中,DCSAN的平均诊断准确率最高,分别比DAN、D-CORAL和DANN模型高9.5百分点、8.0百分点和13.6百分点。从表3还可以看出,DANN的平均准确率低于基于距离度量域适应方法(DAN、D-CORAL和DCSAN)的平均诊断准确率,这可能是因为DANN方法在域适应过程中产生了梯度不稳定的问题,而基于距离度量的方法不需要额外引入其他参数即可实现域自适应,较DANN模型稳定。此外,在基于距离度量的3种方法中,DCSAN模型的平均诊断准确率高于另外2种模型,这是因为DAN模型和D-CORAL模型仅关注源域和目标域的全局分布对齐,而DCSAN通过关注每个类别中的细粒度信息,可以更好地对齐源域和目标域中同一类别间的相关子域。上述实验表明,DCSAN模型具有较好的故障识别能力和良好的泛化能力。
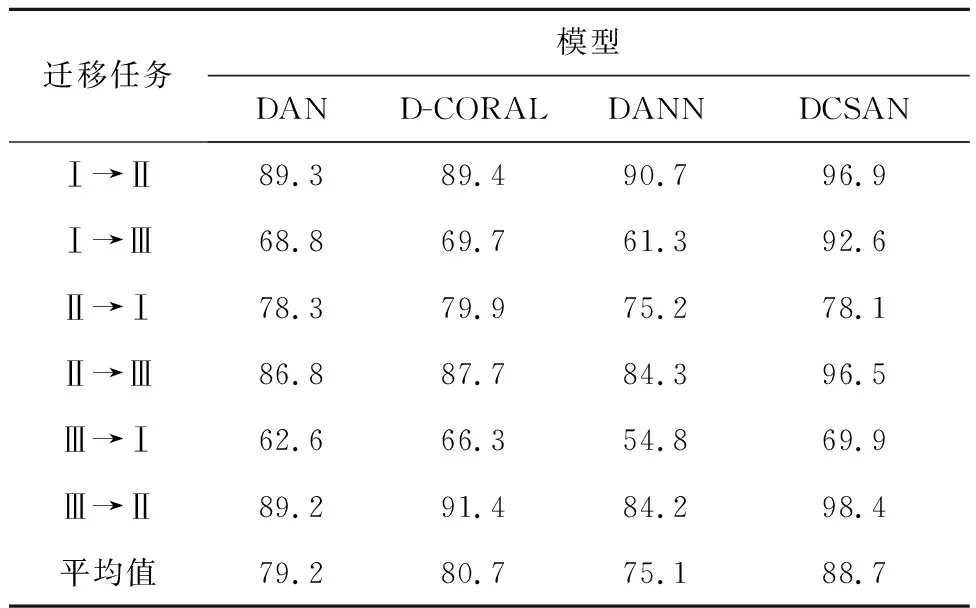
表3 不同模型的跨工况故障识别准确率Tab.3 Accuracy of cross-condition fault identification for different models 单位:%
跨工况故障诊断准确率的雷达图如图2所示,计算结果曲线所包围的面积可进一步评价每种方法的整体性能。该方法在雷达图上对应的面积值越大,表明其整体的性能和泛化效果就越好。可以看出,所提出的DCSAN模型在跨工况任务中表现出优越的诊断性能,验证了其有效性。

图2 跨工况故障诊断准确率雷达图Fig.2 Radar plot of cross-condition fault diagnosis accuracy
3.5 可视化分析
为更直观地验证DCSAN模型的有效性,使用t分布随机邻域嵌入[20](t-SNE)将各模型在Ⅲ→Ⅱ迁移任务中的高维特征可视化为二维图,如图3所示。其中,S-0表示来自源域的健康状态样本,T-0表示来自目标域的健康状态样本,其余符号命名标准相同。从图3可以看出,DANN模型的0类和1类状态仍然存在类别间重叠问题,因而准确率低于其他方法。DAN模型和D-CORAL模型虽然在类别重叠问题方面较DANN模型有所改善,但这2种方法在不同类别间没有明显的边界。而DCSAN模型不仅在同一类别间的散点能够很好地聚集在一起,而且不同类别间也具有更清晰的决策边界,这说明DCSAN网络可以更好地对齐不同域中相同类别的子域,也进一步说明了所提模型具有更好的分类性能和域自适应能力。
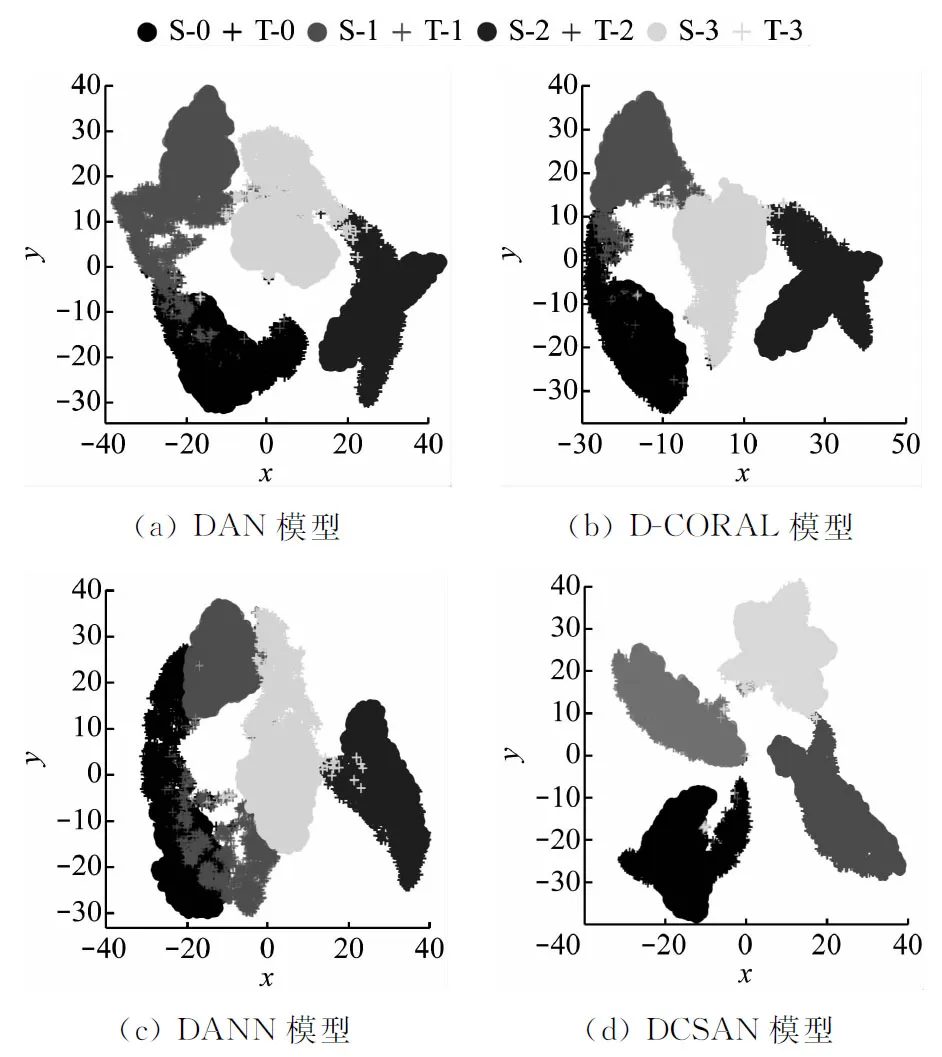
图3 迁移任务Ⅲ→Ⅱ的t-SNE可视化Fig.3 t-SNE visualization of migration task Ⅲ→Ⅱ
4 结论
(1) 将分类器预测的置信度映射到所提取的特征中可提高MK-LMMD捕获不同域间每个类别细粒度信息的能力,进一步减少了不同域间相关类别间的距离,实现了子域的对齐。
(2) 在6个变工况迁移任务中,DCSAN模型表现优异,其平均诊断准确率分别比DAN、D-CORAL和DANN模型高9.5百分点、8.0百分点和13.6百分点。t-SNE的可视化结果进一步表明了DCSAN在对齐子域方面的有效性和优越性。
