细粒度学习行为分析在信息化教学中的应用
2024-01-17刘金凤徐展兰朝凤
刘金凤,徐展,兰朝凤
细粒度学习行为分析在信息化教学中的应用
刘金凤,徐展,兰朝凤
(哈尔滨理工大学 测控技术与通信工程学院,黑龙江 哈尔滨 150080)
现代化线上教育技术在教育教学中的应用受到国家和各大高校的高度重视.为了将线上教学结果有机结合到高校教育过程,将通过线上学习平台提取学生的学习过程数据,对学生个人的学习行为及学习效果进行分析预测,旨在打破传统课堂教学过程中的“填鸭式”“满堂灌”的陋习.将收集的粗粒度数据进一步细粒度化,得到细粒度参数,从而发现学生的隐性数据,如学习兴趣、学习态度等.实验结果表明,细粒度指标在预测学生的总评成绩上起到了至关重要的作用.通过粗粒度指标及细粒度指标,归类出五种不同类型的学生群体,确定若干典型行为特征,为教师对学生学习行为干预给予针对性地参考.
细粒度参数;学习行为分类;数据提取;特征重要性判别
1 信息化教学现状与问题
利用信息技术所提供的自主探索、多重交互、合作学习、资源共享等学习环境,把学生的主动性、积极性充分调动起来,可以使学生的创新思维与实践能力在整合过程中得到有效的锻炼.为了改善信息化教学模式,将信息技术更好地融合到基础课程交互平台建设中,进行信息技术与课程的“大整合”,建设数字化教育环境,必须深度挖掘学生信息库数据,优化教学过程和评价体系,提高教学效率和教学效果.
目前,已有众多研究者利用数据挖掘技术分析教育领域的学习数据.屈泳[1]等通过视频观看完成率、课程访问次数、论坛参与情况、单元测验成绩、期末测验成绩等五个指标对课程学习成绩进行预测.胡祖辉[2]等通过成绩数据、上网数据、学生的个人信息探究学生的学习质量.You[3]等通过线上平台数据,挖掘出影响成绩预测结果的关键指标.刘桂梅[4]提出了多维细粒度的思想,将七种学习行为特征划分为多个维度,分析比较不同学习模式.王畅[5]通过学生在各个学习网页上点击的总次数作为数据来源对学习成绩进行预测.但目前挖掘出的学习数据仍然都为粗粒度指标,而且只在粗粒度指标上进行变化分析.事实上这些粗粒度指标,不能细致地反映学生的学习行为.一个学习者的粗粒度指标较好,并不能说明学习者的学习积极性较高.所以需要细化粗粒度指标,挖掘更深层含义的细粒度指标,结合粗粒度指标与细粒度指标,观察学习者的学习行为.
本文利用云计算、大数据等技术,以Jupyter,VisualStudio Code等软件平台和学习通等APP为载体,将整个教学资源重新整合,构建出了更完善的在线学习平台.该平台打通了校园内网和外网的连接,实现了优质教学资源的共享化和教育信息化,利于学生学习过程数据信息的深度挖掘.本研究中的数据信息就来自于该在线学习平台.
2 在线平台粗粒度信息提炼
数据收集来自104名大学生,学生使用完善的在线学习实验平台,通过教师端查询学生学习过程中的各类数据,将其作为粗粒度指标来源,再利用SPSSStatistics对粗粒度信息数据进行整合、统计与分析,为后期提取细粒度信息提供有效的数据支撑,对采集到的原始数据进行预处理得到粗粒度指标信息[6].数据处理需要从大量、分散、缺失的数据中抽取并推导出对解决问题有价值、有意义的数据,经过清洗、集成、归一化、标准化的手段得到处理后的数据集.数据处理过程见图1.首先分析数据,选取重要内容,通过算术和逻辑运算得到进一步的信息,按照相关信息进行有效地分组,再将整理好的数据集成合并,并统一单位,化为数值型数据.由于不同变量的数值存在量纲的差异,因此还要进行归一化处理,采用线性函数归一化方式,对原始数据进行线性变换,通过原始数据和最小值的差值占最大值和最小值之间的比例换算,将所有数据压缩至0~1区间内进行比较.对处理后的数据再进行深入挖掘,选用合适的算法进行训练得到符合实际情况且效果较好的行为特征指标.数据深入挖掘的工具选用SPSSModeler[7],通过软件内置的机器学习算法,分析数据获得预测知识.
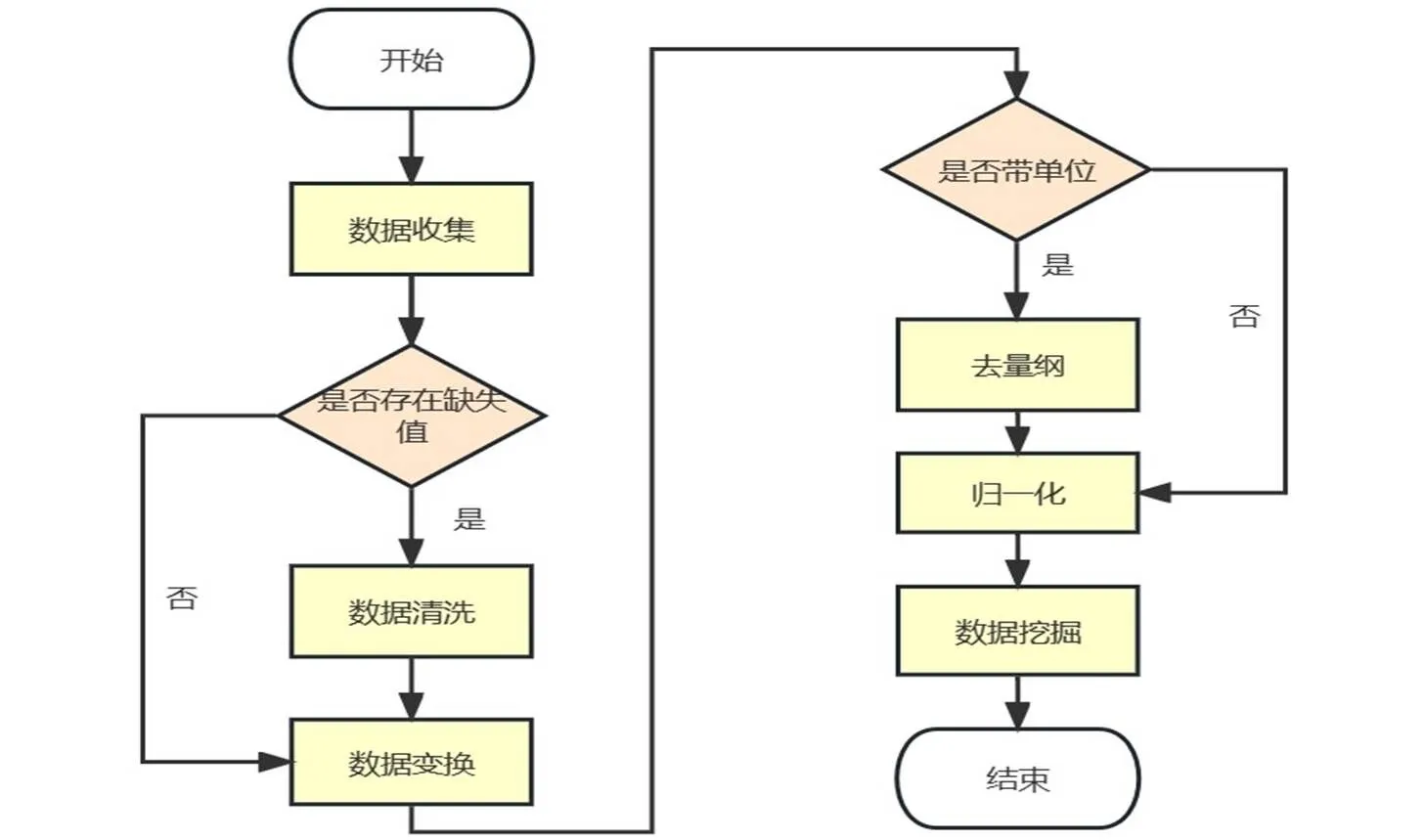
图1 数据分析与处理
3 细粒度分析及重要特征提取
3.1 细粒度参数提取
通过对不同角度的粗粒度指标深入解读,基于时间维度对粗粒度指标参数进行细化,得到细粒度指标.细粒度信息作为数据粒度在空间尺度的更高程度细化,能提供数据分析微观视角,具体指标内容及含义见表1.
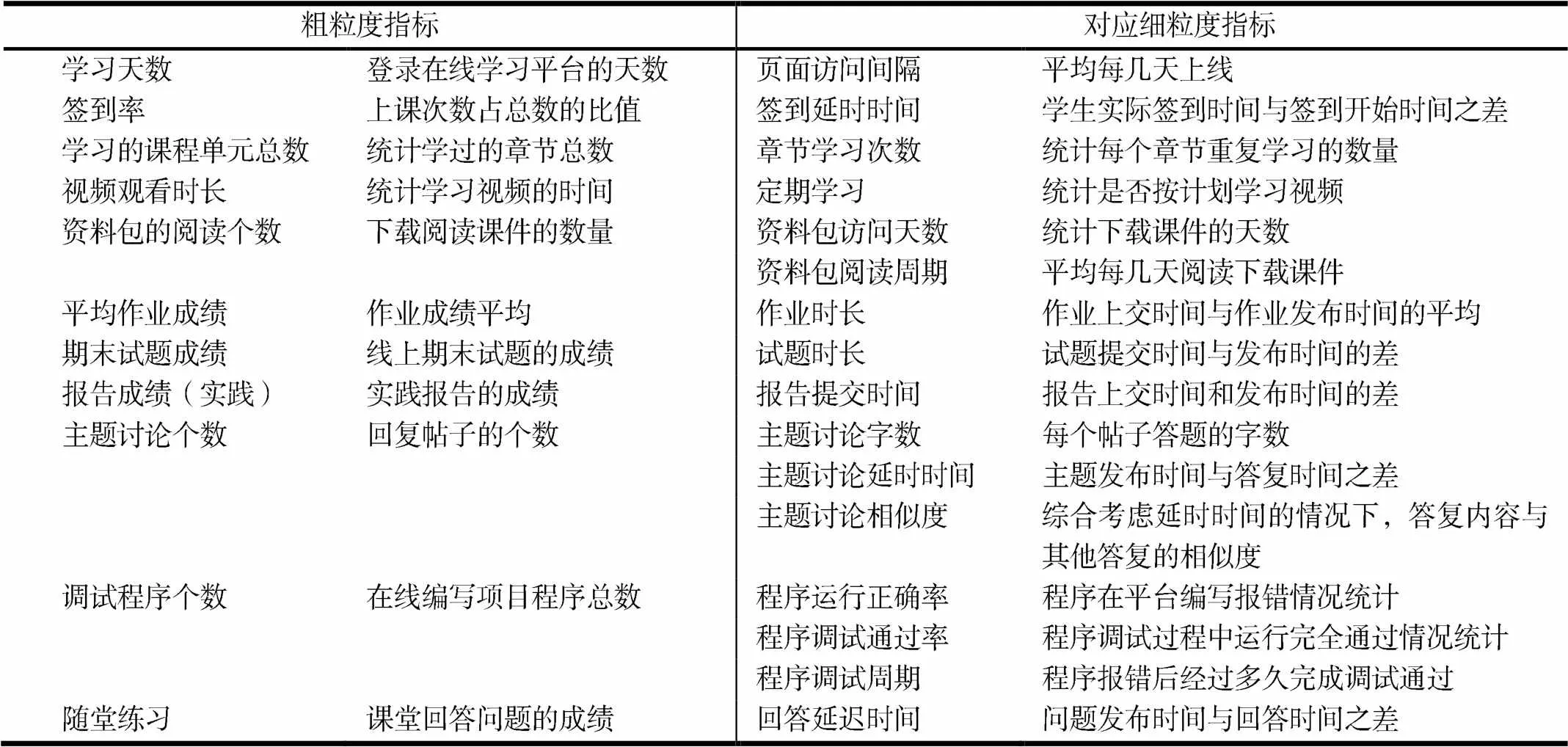
表1 粗粒度指标及细粒度指标
3.2 目标预测及重要特征提取
目标预测就是根据预处理过的数据集,得到目标变量的预测值,比较目标预测值和目标变量实际值,针对两者的相关性进行相应的分析研究,确定构建函数预测模型的合理性,以对未来的数据或测量特征值进行预测.
在研究中,基于粗粒度指标及细粒度指标对目标变量总评成绩进行回归预测,通过预测模型将粗粒度指标及细粒度指标进行混合排序,得到对预测结果影响大的指标特征.由于期末试题成绩指标是总评成绩的组成部分,所以预测指标不含期末试题成绩.同时,为了细致地观察指标对目标预测的影响,将持续时间较长的指标,如视频观看时长、定期学习、签到延时时间、程序调试周期再进一步划分,分为中期指标和终期指标,观察两者对预测结果的影响.
不同预测算法其原理不同,得到预测结果也不同.本研究综合考虑准确率最高,指标重要性排序罗列因素最多的要求下,进行算法选择,采用机器学习算法MLP神经网络进行学习行为的分析与预测,有效预测指标28个,将数据样本集的80%作为训练集,20%作为测试集.根据MLP神经网络对综合成绩预测,所得平均绝对误差为0.103,平均相对误差为0.011.通过影响因素分析可以得到的重要指标中,粗粒度指标为报告成绩、资料包阅读个数、平均作业成绩、视频观看时长.细粒度指标为测试时长、程序调试通过率、签到延时时间、章节学习次数、作业时长、主题讨论字数.验证得出细粒度指标对学习者成绩的预测至关重要.
3.3 学习行为分类
基于粗粒度指标及细粒度指标进行总评成绩的预测,虽然通过结果的高低,可以看出一个学生对于这门课程掌握知识的多少,但是仅仅从成绩的高低,不能准确掌握学习者对课程学习所体现的学习态度、学习习惯等学习行为结果.所以要深入分析特征指标映射出的学生的学习行为[8],并对其进行延深思考.
通过选取上文提出的所有粗粒度及细粒度指标,对学习者群体进行聚类,对不同的学生群体之间加深认知,从学习习惯、学习方式、学习积极性等多角度了解学生,针对每个学生群体进行不同的学习鞭策.
3.3.1常用聚类算法目前实际应用中的聚类分析方法有很多种类型.根据不同的类型罗列聚类算法见图2.不同的划分方式有不同的优缺点,可以用于处理不同需求的聚类任务.数据样本的类型、数据集的规模、数据存在噪声等问题都将会影响聚类算法的选取.基于划分的聚类方法是通过样本点之间的距离计算相似度,将数据集合划分为若干个簇.基于层次的聚类方法通常以树状图的形式表现凝聚或分裂两种聚类方式,该方法可解释性强.基于密度的聚类方法通过观察样本点分布的密集程度,密集程度高的为簇,低的作为噪声处理.基于模型的聚类方法是通过数据样本的真实分布计算模型参数,最后利用所得模型完成聚类[9].模糊聚类是将隶属度的思想应用到聚类,输出为数据属于每一簇的可能性.
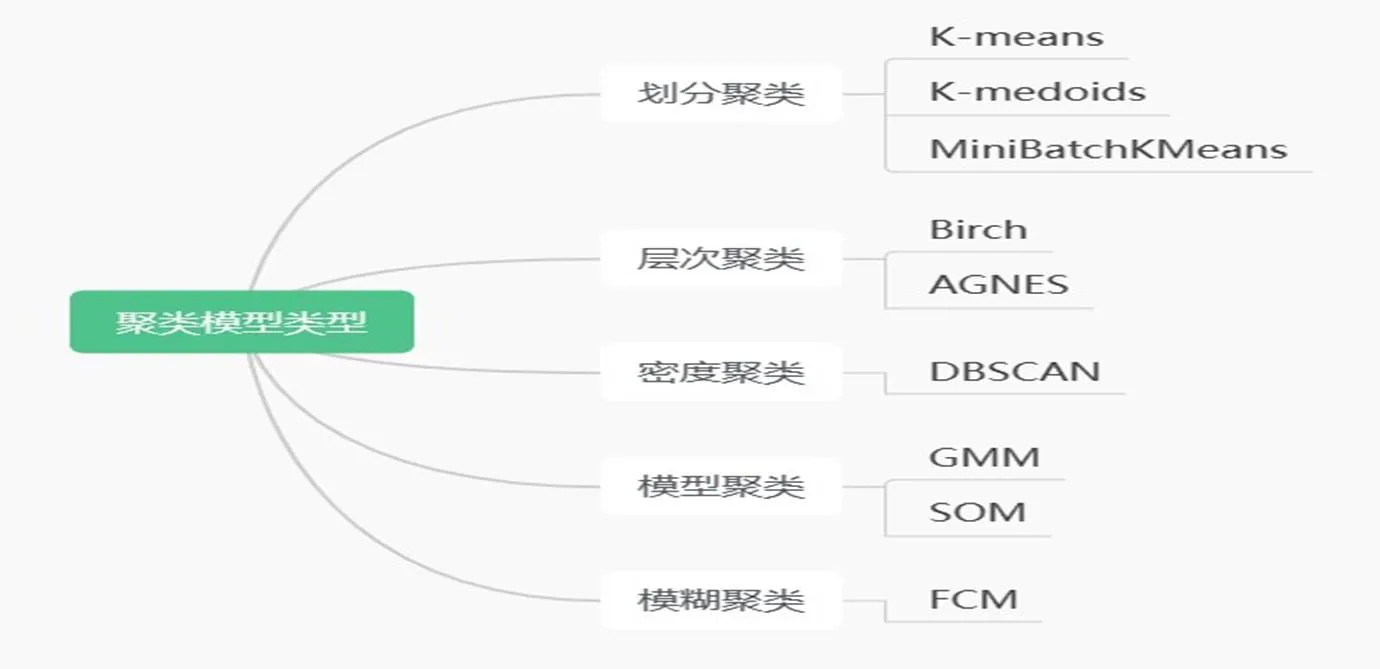
图2 聚类算法
3.3.2聚类指标聚类完成后通过六种内部指标对聚类结果进行评判,评估指标介绍见表2.内部评价指标仅利用数据集的属性特征,不考虑数据集的样本标签,对聚类算法的优劣进行评价.通过计算总体的相似度、簇间平均相似度或簇内平均相似度来评价聚类质量.

表2 内部评价指标介绍
3.3.3聚类流程及结果通过机器学习聚类算法对学生群体进行合理的分类,学习者聚类算法流程见图3.用户进入系统后,选择适合自己数据集的聚类模型进行训练,查看聚类结果,再选用聚类内部指标对训练模型进行评估,针对评估值的好坏再进行下一步的操作.若对评估结果不满意,用户可以重新选择聚类算法对数据集进行聚类.如果用户想要预先指定需要划分的簇数个数,就可以选择划分聚类的K-means等算法,否则就选择密度聚类DBSCAN等算法.如果用户的数据集样本规模大,就可以选择采用层次聚类Birch聚类算法.不同的聚类算法,其原理和分类结果不尽相同,需要根据聚类目标和总体分类要求来综合衡量采用何种聚类算法.
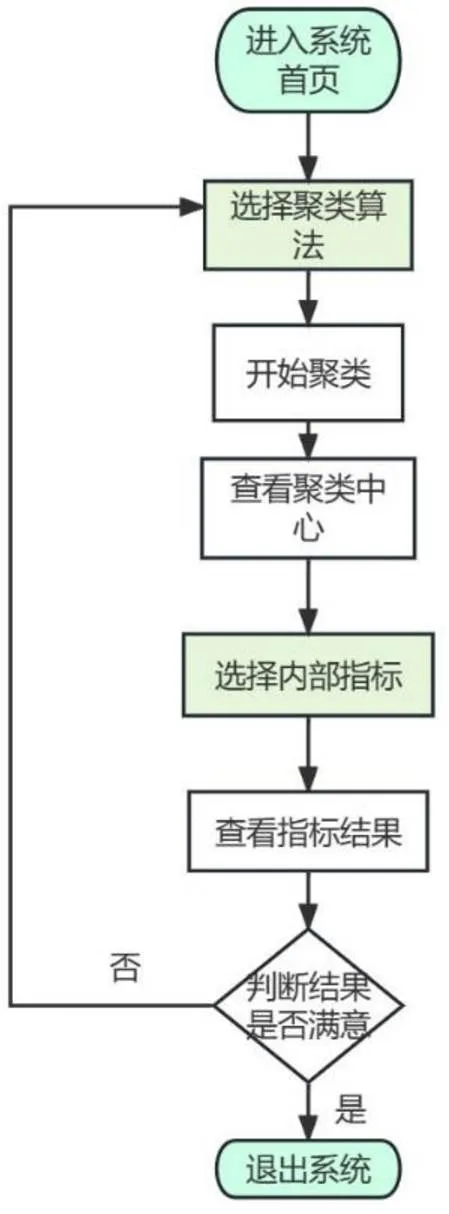
图 3 聚类流程
以分类边界清晰、类间分布人数相对均匀为目标,采用划分聚类K-means算法基于粗细粒度指标对学生进行分类.样本数总共为104,分成五类,聚类人数分别为23,16,19,22,24个,分类结果见图4.图4中每个颜色表示一类,且每类的聚类中心由黑色加号标明.
采用划分聚类K-means算法得到CH指标为90,SC为0.398,DBI为0.984,S_Dbw值为0.124,RMSSTD为0.175,RS为0.479.通过观察,CH值很高,SC指标和S_Dbw值在0~1之间,DBI小于1,RS值大于RMSSTD,表示K-means算法对于该数据集聚类效果很好,类内紧密又类间分离,综合考虑了簇的紧凑性、分离性以及不均匀性等因素.
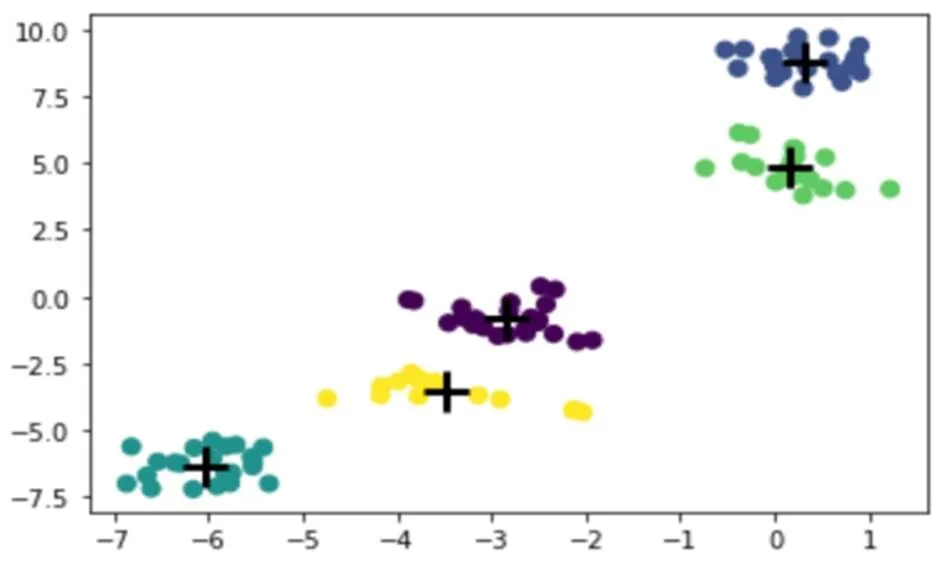
图4 K-means数据分类结果
3.3.4聚类分析对比每类中心的粗粒度指标和细粒度指标数据,罗列变化较大的指标参数(见表3~4).

表3 K-means聚类结果Ⅰ

表4 K-means聚类结果Ⅱ
通过表中的参数,结合粗粒度指标及细粒度指标,对比分析每一类群体的特点:
(1)第1类群体签到延时时间最长,课堂内发布的随堂练习成绩最高,讨论字数很高,课后学习即课件资料包的下载忽略不计,视频观看时长几乎没有,平均作业成绩中等偏上,报告成绩中等.这类群体学生具有拖延行为,喜爱交流学习,动手能力突出,但不爱课后复习,不爱听课,学习积极性中等.该类群体属于交流学习行为.
(2)第2类群体总评成绩不合格.除签到延时指标及资料包相关指标外,其他指标都是最低,即对学习任务的完成度都很低,每项任务都只浏览过,但都没有认真完成,更没有进行深入的学习思考.这类群体对这门课毫无兴趣.该类群体属于跟风学习行为.
(3)第3类群体总评成绩最好.绝大部分指标都为最高,签到延时时间也是最短.反映了这类群体上课的积极性及对知识的掌握程度最高,体现了学生较强的自我管理能力.该类群体属于听课学习行为.
(4)第4类群体相比于其他类群体在资料包的学习上特别突出,资料包阅读个数及资料包访问天数都为最高,平均作业成绩高但答题时间也最长,而且视频的观看时长很低.反映了这类群体喜欢探索性学习思考,独立学习能力较高.该类群体属于独立学习行为.
(5)第5类群体程序调试通过率最高,课后学习即课件资料包的下载没有,视频观看时长也很低,签到延时时间很长,不爱讨论,作业及报告成绩都中等偏下.不参加课时安排内的活动,只完成作业报告等重要考核,而且程序调试成功率过高,缺乏调试过程,证明他们不考虑学习的过程,只关心学习的结果.这类群体学习属于临时抱佛脚行为.
针对第1类群体而言,教师提高课内外互动,并加强小组合作,便能提升第一类学习群体的学习积极性.针对第2类群体而言,教师不仅需要对学生单独沟通,还需要单独设立不同内容进行深度测试,保证学习质量.针对第3类群体而言,发现学生感兴趣的课程和内容,并针对同一视频观看频次或者程序调试过程中出现的问题可以给予针对性指导.针对第4 类群体,教师无需过多干预,只需要增加项目的可操作性和资料的适用性及完整性.针对第 5类群体而言,可以更多地展示课程学习内容的前置知识和后续学习项目,以进一步提高学生的积极性.
4 结语
在信息化教学环境下,本文对学习者学习过程中产生的行为数据进行了多角度分析,最大程度挖掘线上教学模式下所产生粗粒度指标,再基于时间维度等进一步细化粗粒度参数得到细粒度指标,结合粗粒度指标与细粒度指标,通过一系列预测算法找到影响学生学习效果的重要特征指标,并且预测出学生的成绩与实际值进行对比.通过机器学习聚类算法对学生群体分成五类,发现一些具有普遍性的学习行为特点及规律,预测学生对课程知识点的掌握情况,并有效判别出学生的学习态度和学习的兴趣程度,分数高者并不一定会认真学习这门课程,分数中等的学生不一定就对这门课程兴趣低,所以需要利用深度学习算法对学生的学习态度和学习行为进行细化分析,准确定位,才能更好地帮助学生完成课程学习.
将粗、细粒度信息相结合能使原认知评估体系具有空间尺度多样化特征.因此,研究应该兼顾粗粒度信息及深层细粒度信息,提升预测效果,挖掘隐含规律.但目前在线学习平台找到可提炼的细粒度指标自由度不大,而且不能通过平台跟踪学生的学习轨迹,需要进一步改进.
[1] 屈泳,陈春芳,阮小军,等.MOOC学习环境下的学习行为评价建模与应用[J].高师理科学刊,2022,42(10):66-73.
[2] 胡祖辉,施佺.高校学生上网行为分析与数据挖掘研究[J].中国远程教育,2017,23(2):26-32.
[3] YOU,JI Won.Identifying significant indicators using LMS data to predict course achievement in online learning[J].Internet and Higher Education,2016,29(8):23-30.
[4] 刘桂梅.基于学习者行为的模式识别及成绩预测研究[D].长沙:湖南大学,2021.
[5] 王畅.基于学生在线学习行为的成绩预测方法研究[D].桂林:桂林电子科技大学,2022.
[6] 黄戌珺.基于在线学习行为分析的学习效果预测方法研究[D].武汉:华中师范大学,2018.
[7] 秦世名.面向在线学习行为分析的学习效果预测方法研究[D].武汉:华中师范大学,2019.
[8] 陈坤.基于在线学习社区学习者学习行为的建模与预测研究[D].武汉:华中师范大学,2019.
[9] 王玉晗,罗邓三郎.聚类算法综述[J].科技资讯,2018,16(24):10-11.
[10] Hassani M,Seidl T.Internal Clustering Evaluation of Data Streams[J].Trends and Applications in Knowledge Discovery and Data Mining,2015,9441:198-209.
[11] 鲁杰,闫炳基,赵伟,等.基于不同算法的高炉操作炉型聚类效果对比[J].工程科学学报,2022,44(12):2081-2089.
[12] 李瑞珠.多指标聚类算法的研究[D].广州:广东工业大学,2021.
Application of fine-grained learning behavior analysis in information teaching
LIU Jinfeng,XU Zhan,LAN Chaofeng
(School of Measurement Control Technology and Communication Engineering,Harbin University of Science and Technology,Harbin 150080,China)
The application of modern online educational technology in education and teaching has been highly valued by the state and universities.In order to combine the online education outcome with the process of university education,this study is targeted to pick up learning behavior index of undergraduates to effectively predict individual learning behavior and learning efficiency,through online platform.The purpose is to break the bad habits of cramming and filling the classroom in the process of traditional classroom teaching.Further refine the collected coarse-grained data to obtain fine-grained parameters and discover students′ hidden data,such as learning interest,learning attitude and so on.The experimental results show that fine-grained indicators play an important role in predicting students′ overall grades.Through the analysis of indicators,identify five different types of student groups and several typical behavior characteristics are determined,so as to have a deeper understanding of students′ learning progress.
fine-grained parameters;learning behavior classification;data extraction;discrimination of feature importance
1007-9831(2023)12-0093-06
TP391.4
A
10.3969/j.issn.1007-9831.2023.12.016
2023-04-28
黑龙江省高等教育教学改革项目( SJGY20210384)
刘金凤(1978-),女,黑龙江哈尔滨人,副教授,博士,从事算法优化设计、信息技术应用研究.E-mail:1097246760@qq.com
