基于高光谱技术的杏品种判别
2024-01-15王润润张淑娟苏立阳王林杰卢心缘孙海霞
王润润,张淑娟,苏立阳,王林杰,卢心缘,孙海霞
(山西农业大学农业工程学院,山西晋中 030800)
杏的种类繁多,其营养成分和口感差异很大,因此需要探究一种快速、无损的品种判别方法,以满足消费者对不同品种杏的消费需求。
光谱技术作为新型的无损检测手段,在农产品品质检测和品种判别等方面具有广泛的应用。李翠玲等人[1]利用叶绿素荧光光谱结合反射光谱的分析方法鉴别甜瓜种子品种,判别正确率达到98.0%。赵旭婷等人[2]基于高光谱技术研究竞争性自适应重加权算法结合极限学习机对油桃品种进行判别,预测集相关系数为0.931。李雄等人[3]建立柚子品种判别模型,结果表明去差异化后750~930 nm 波段范围判别模型的预测相关系数达到0.86。刘飞等人[4]基于油菜籽皮红外光谱信息对油菜籽的品种和产地进行判别,最优判别正确率分别为97.9%和98.4%。张鹏等人[5]运用近红外光谱技术,研究苹果品种(嘎啦、乔纳金、金冠、寒富) 的近红外判别模型,对未知样品判别正确率为85.00%~95.00%。杨春艳等人[6]基于傅里叶变换红外光谱技术,利用逐步判别分析法对金银花品种和产地进行判别研究,正确率依次达93.20%和96.13%。吴振等人[7]利用无机元素结合多元统计分析对我国5 类柚子品种进行有效区分。有研究采用荧光光谱的一阶导数光谱建立判别模型,卓椒3 号、卓椒4 号、卓椒5 号辣椒种子的品种判别正确率均达到100.0%。
选取4 种不同品种的杏作为研究对象,采集其光谱信息;对比优选多种预处理方法;采用RC 和SPA 方法提取特征波长,结合PLSR 方法建模判别,为建立不同品种杏的种类判别提供参考,为杏产业链的发展提供技术支持。
1 材料和方法
1.1 试验材料
以“6-1”杏、网红杏、晋梅杏和扁杏4 种杏为试验对象,试验中所使用的样本均为2022 年7 月份在山西省晋中市太谷区果树所获得。采摘时挑选形状相近、成熟度统一、无病虫害、质量均匀的杏。试验共采集600 个样本,“6-1”杏、网红杏、晋梅杏和扁杏4 种杏样本各150 个,根据Kennard-Stone(K-S)算法,按3∶1 的比例分别对4 个品种的试验样本划分校正集与预测集,每个品种校正集样本数为113 个,预测集样本数37 个。校正集样本总数452,预测集样本总数148 个。
1.2 光谱信息采集
采用由北京卓立汉光有限公司开发的“Gaia Sorter”高光谱分选仪采集不同品种杏的光谱信息。
平均光谱曲线见图1。
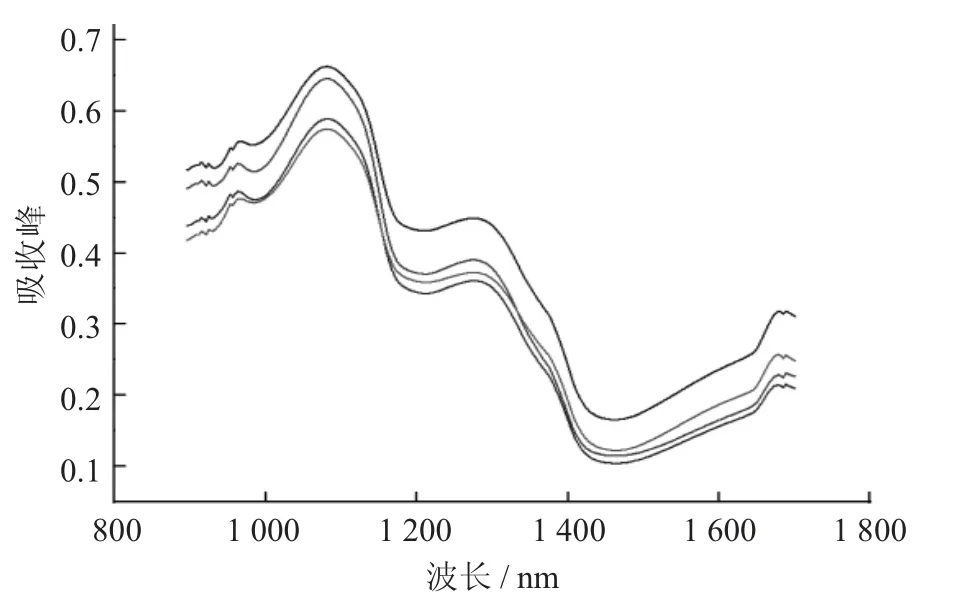
图1 平均光谱曲线
由图1 可知,4 种杏光谱反射率曲线整体趋势一致,只存在吸收强度上的差异,可能与杏的品种、形状、大小和质地有关。因此,推测杏的品种将导致其光谱的差异。光谱曲线分别在1 080,1 275 nm 附近存在突出吸收峰,而在985,1 211,1 462 nm 附近存在波谷。其中,985 nm 附近的波谷是由O-H 基团的二倍频振动导致的;1 275 nm 附近的波峰则是与C-H 的3 倍频伸缩振动有关。
1.3 数据处理方法及评价指标
1.3.1 光谱数据的预处理
由于获得的原始光谱数据不仅会提取样本的有效信息,同时也包含了仪器、背景、环境等与样本无关的冗余信息,为了降低这些冗余信息的影响,研究采用的光谱预处理方法包括SG、MA、MF、Baseline、SNV、MSC。
1.3.2 提取特征波长
原始光谱数据包含波段范围宽作为输入模型计算时间过长,且存在信号谱带重叠。因此,建模时需要筛选特征波长,从而减少建模时间、简化建模过程、提高模型的稳定性。采用的方法主要有RC 方法、SPA 方法。
1.3.3 偏最小二乘回归分析
偏最小二乘回归(PLS) 可以进行多变量数据分析,其原理是:先将各种变量数据矩阵分解为多种主成分数据矩阵,并计算每个矩阵的贡献率,再优选出贡献率较大的成分进行回归分析。
1.3.4 模型评价标准
采用决定系数R2和均方根误差RMSE 2 个值来判别模型的效果。
计算公式为:
式中:yi——样本的实测值;
n——样本数量。
2 结果与分析
2.1 光谱数据的预处理
试验采用SG、MA、Baseline、MF、SNV 和MSC共6 种预处理方法后建模,分析不同预处理所建模型的预测能力。
不同预处理建立PLSR 模型结果见表1。
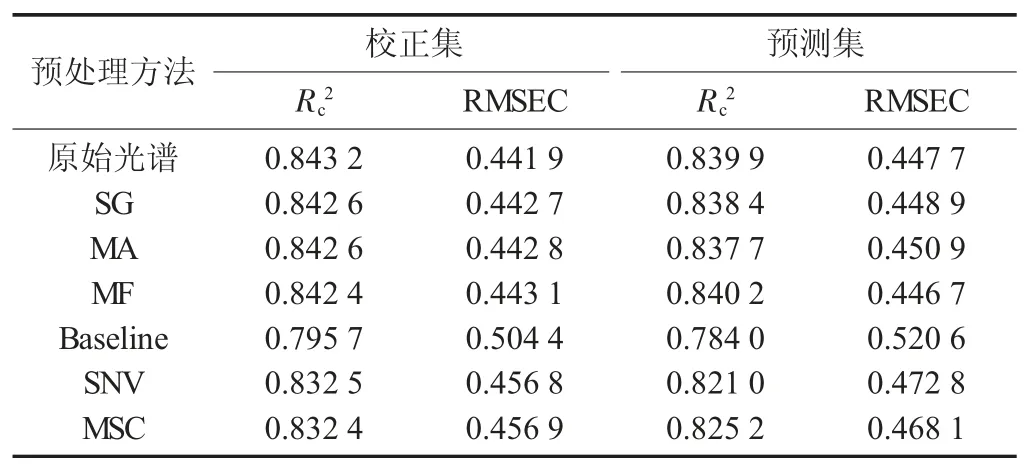
表1 不同预处理建立PLSR 模型结果
由表1 可知,除MF 预处理外,其余5 种预处理建立的PLSR 模型的Rc2和Rp2都有所减小,RMSEC和RMSEP 都有所变大。MF 预处理后的Rc2和Rp2分别 为0.842 4 和0.840 2,RMSEC 和RMSEP 分 别0.443 1 和0.446 7,MF 预处理最优。
2.2 特征波长选择
2.2.1 RC 方法提取特征波长
回归系数法(RC) 是利用全波段光谱数据建立PLSR 模型,然后计算回归系数,再利用局部极值法来确定特征波长,共选出10 个,分别为956,1 023,1 084,1 144,1 176,1 262,1 386,1 469,1 634,1 666 nm。
RC 提取特征波长见图2。
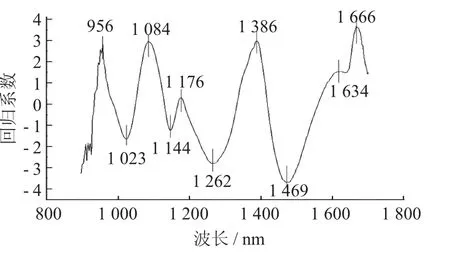
图2 RC 提取特征波长
2.2.2 SPA 方法提取特征波长
连续投影算法(SPA) 是通过计算样本波长之间的投影,并将投影向量的最大值定为样本的特征波长值。
特征参数数量与均方根误差关系图见图3,特征参数优选分布图见图4。
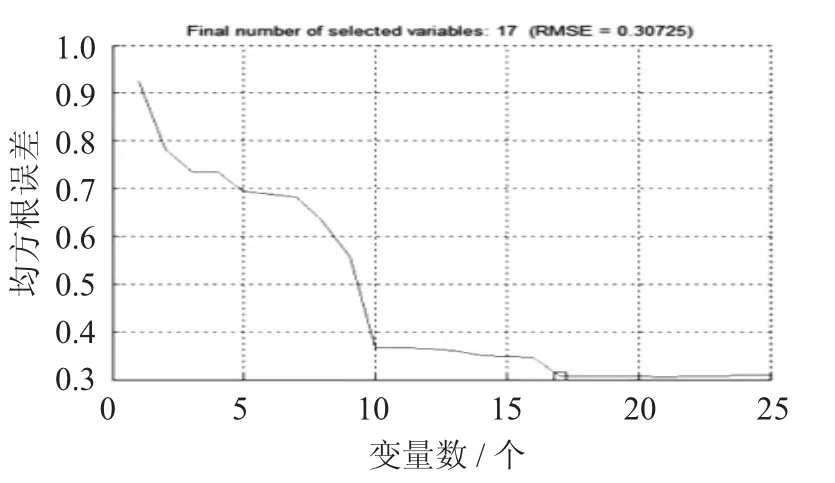
图3 特征参数数量与均方根误差关系图
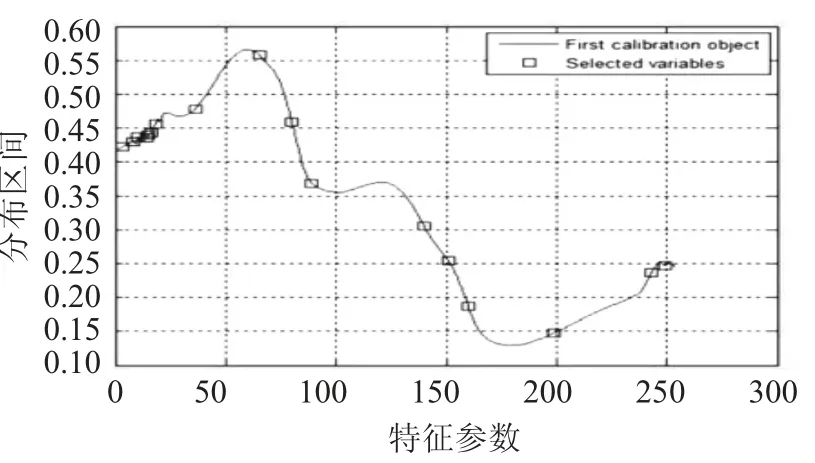
图4 特征参数优选分布图
由图3 可知,当最终选择变量数为17 个时,均方根误差最小,提取的17 个特征波长值分别是902,918,924,937,940,943,950,1 007,1 100,1 147,1 176,1 338,1 373,1 402,1 526,1 666,1 685 nm。
2.3 建模结果分析
将4 类不同品种的杏样本进行赋值作为判别依据,“6-1”杏赋值为1;网红杏赋值为2;晋梅杏赋值为3;扁杏赋值为4。在建立判别模型的过程中会出现非整数的情况,需要采用阈值进行判别。当判别值大于等于0.5,小于1.5 时判别为“6-1”杏;当判别值大于等于1.5,小于2.5 时判别为网红杏;当判别值大于等于2.5,小于3.5 时判别为晋梅杏;当判别值大于等于3.5,小于4.5 时判别为扁杏;当判别值不在这些区间内则为判别错误。
基于全波段、RC 和SPA 的PLSR 判别模型见图5。
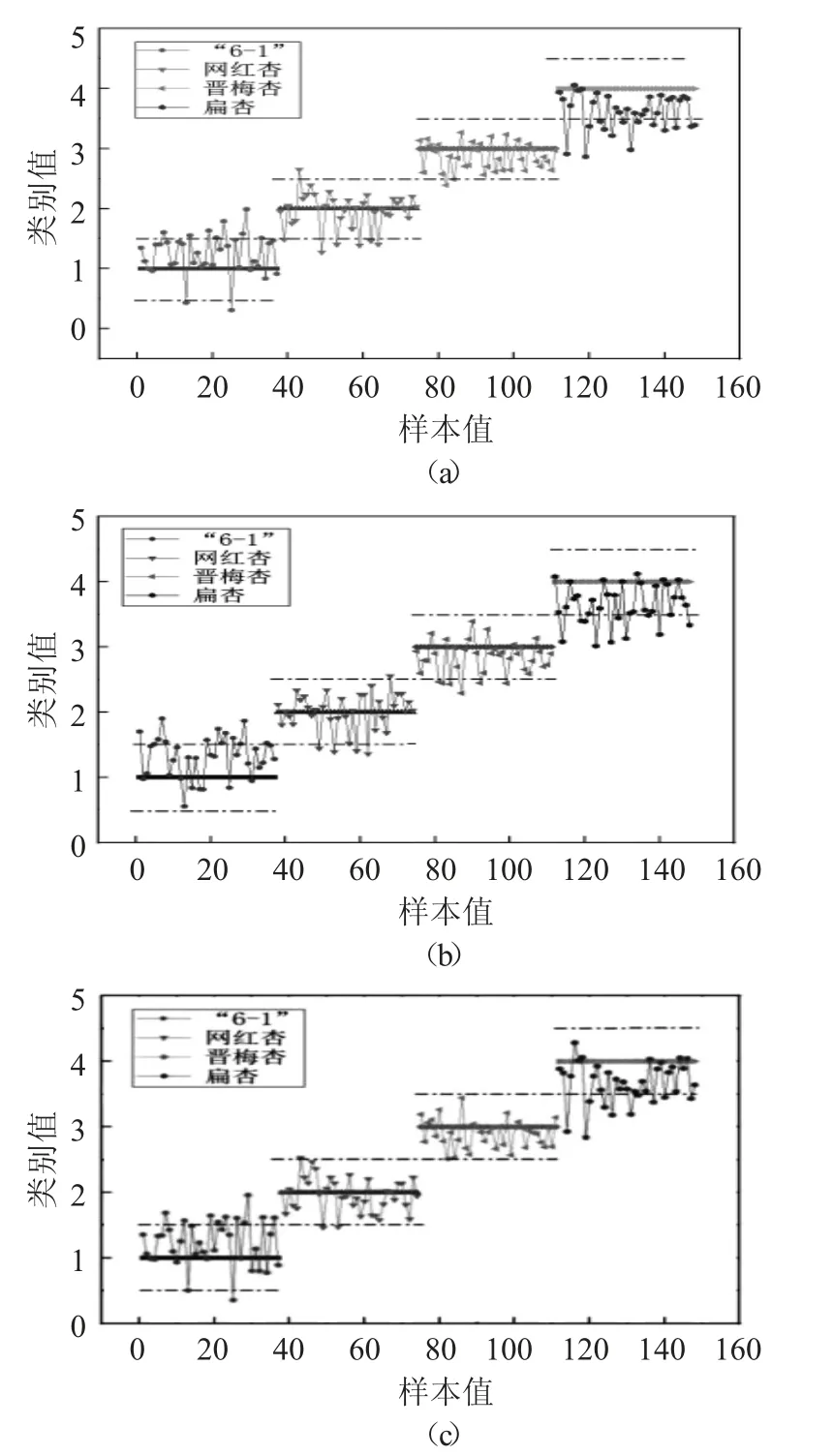
图5 基于全波段、RC 和SPA 的PLSR 判别模型
由表2 可知,通过比较NOR(全波段) -PLSR、RC-PLSR、SPA-PLSR 这3 种方法预测的建模效果,发现SPA-PLSR 的建模效果最好,预测集的综合判别率高达84.44%。
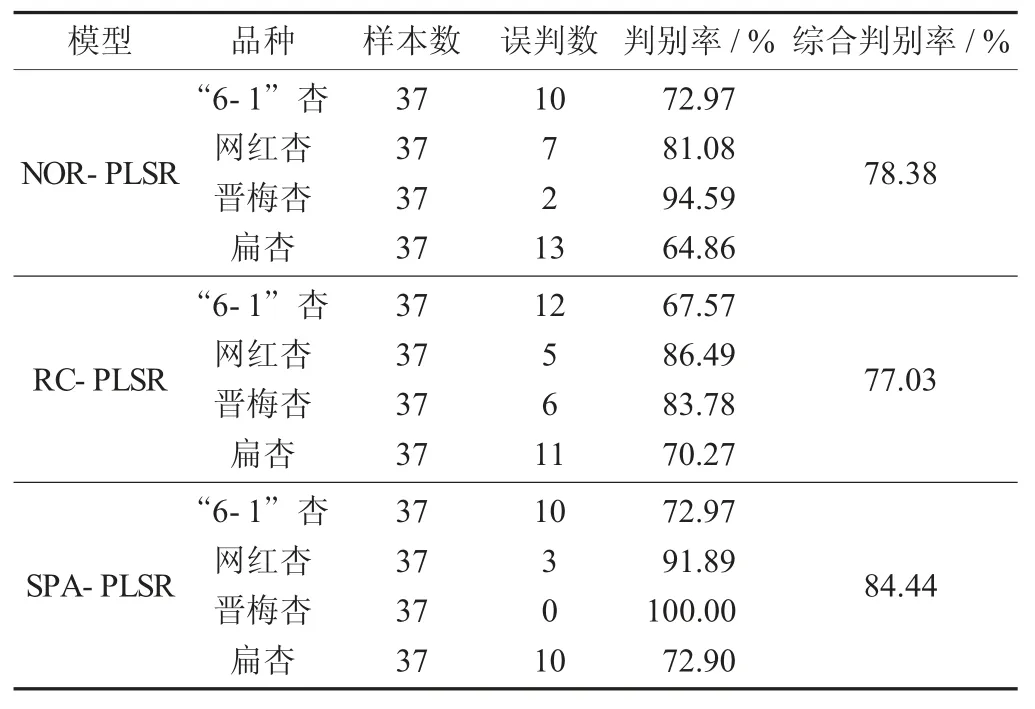
表2 各模型判别结果统计
各模型判别结果统计见表2。
3 结论
通过采集“6-1”杏、网红杏、晋梅杏和扁杏4 个品种的光谱信息,采用SG、MA、Baseline、MF、SNV 和MSC 共6 种预处理方法,建立PLSR 模型,MF 方法预处理效果最优。针对预处理后的光谱数据,采用RC 和SPA 方法选取特征波长建模。结果表明,SPA-PLSR 模型效果最佳,总判别率达到了84.44%,4 个品种的判别率分别达到了72.97%,91.89%,100.00%,72.90%。
