一种基于随机权神经网络的类增量学习与记忆融合方法
2024-01-09李德鹏曾志刚
李德鹏 曾志刚
人和其他高级动物可以在其一生中学习并记住许多技能,这种连续学习不同任务的能力被称为连续学习(Continual learning,CL).相比之下,人工神经网络(Artificial neural networks,ANNs)在接受新任务训练时,通常会迅速忘记如何执行之前的任务,这种现象称为灾难性遗忘[1].从网络拓扑的角度来说,遗忘的发生是由于连接主义网络的本质:其信息均被存储在模型参数中,直接在新任务上训练网络会修改连接权值并偏离旧任务,从而不可避免地发生遗忘[2].从数据分布的角度来说,大多数ANNs 只是为了学习某一特定任务而建立,其中训练与测试数据为独立同分布(Independently identical distribution,IID).该条件假设了一种静态场景,即数据分布不随时间的推移而发生变化.然而,现实世界中流式数据(Streaming data)的不确定性使得预训练模型无法应对非IID 任务.与此同时,遗忘的发生并不是因为网络容量有限(同样的网络在交错或联合训练时仍可以学习许多任务)[3],而是源于现实世界中流式数据往往以任务序列的形式先后出现,其中每个任务的数据可能会在一段时间后消失,甚至由于内存限制或隐私问题而无法存储或重新访问[4].因此,研究有效且高效的CL 方法以克服ANNs 中的灾难性遗忘具有重要意义,对于通用人工智能的发展也至关重要.
近年来,CL 受到了越来越多的关注[5-8].根据学习过程中如何处理与利用特定于任务的信息,CL方法可以大致分为以下三类:
1 ) 扩展方法(Expansion method)[9-11]: 这类方法的典型特征为不断增加单独的模型参数以适应新类别,即: 模型通过冻结以前的任务参数或者为每个任务分配一个副本,从而逐步为新任务添加额外的网络分支.例如,文献[12]通过在新任务的训练过程中扩展网络节点,提出一种可自适应更新的动态网络以增加对新类别的特征表征能力.其虽然可以有效防止遗忘旧任务,但往往会导致网络规模随着任务数量的增加而增加.此外,扩展方法通常受限于“多头” (Multi-heads)设置,其中每个任务都具备一个专有的输出层,而且测试阶段一般需要提供任务的身份(Task identities,Task-ID)才能正确匹配已经学过的、特定于该任务的头(Head)[7].
2 ) 重放方法(Replay method)[13-15]: 这类工作通过保存部分原始样本或使用生成模型生成伪样本,以在学习新任务时进行联合训练.作为一种经典的重放方法,梯度情景记忆(Gradient episode memory,GEM)[16]在学习新任务时利用有限的历史数据依次限制每个任务的损失函数不增加.在此基础上,平均梯度情景记忆(Averaged GEM,A-GEM)[17]和逐层优化梯度分解(Layerwise optimization by gradient decomposition,LOGD)[18]分别通过考虑所有旧任务的平均损失来放松约束、在不同情景中指定共享和特定于任务的信息以缓解遗忘.文献[19]进一步构建基于少数示范性样本的目标检测网络用于低温电子显微镜粒子拾取.重放方法通常依赖旧任务数据的数量和质量.一方面,由于内存限制或隐私问题可能根本无法存储或重新访问;另一方面,不断训练生成模型也会导致复杂性逐渐增加,而且需要额外注意避免模式崩溃.
3 ) 基于正则化的方法(Regularization-based method)[20-22]: 通过施加惩罚限制重要参数,使其在后续任务的训练过程中不发生较大变化.文献[23]首次提出了一种弹性权值巩固(Elastic weight consolidation,EWC)方法,该方法利用量化的权值重要性有选择地保护对于旧任务重要的权值来学习新任务.在此基础上,文献[24]以在线方式基于损失函数计算权值重要性,并提出了突触智能(Synaptic intelligence,SI)算法.文献[4]提出的记忆感知突触(Memory aware synapses,MAS)可以进一步用于无标签情况.文献[25]通过寻找不干扰先前任务权值更新的正交投影,提出了正交权值修改(Orthogonal weights modification,OWM),在新任务上训练时,其权值只允许沿着输入空间的正交方向进行变化.文献[26] 基于知识自蒸馏(Knowledge self-distillation)技术设计了一种域增量学习基准并创新性地用于持续人群计数.它们仅向目标函数引入正则化项而不需要扩大网络规模或存储旧任务数据.
然而,现有的CL 方法为了减轻灾难性遗忘难以同时满足最小化计算、存储和时间需求,往往对这些条件中的两个或全部做出妥协[15].大多数CL模型都是在深度神经网络(Deep neural networks,DNNs)上实现的,并严重依赖反向传播(Back propagation,BP)算法.因此,这些方法不仅训练耗时,而且在任务序列的训练过程中对超参数的设置极为敏感.更为重要的是,它们潜在地需要多次遍历访问(对应较大的epoch)任务数据以获得更好的性能,往往不利于保留旧任务的信息,甚至由于隐私限制可能是不可行的[16].对比之下,生物脑显然已经实现了高效且灵活的连续学习方式.以上基于DNNs的CL 模型与高级动物在学习能力上的显著差距促使我们进一步借鉴生物脑的认知机制.
近年来,具有跨学科特性的类脑智能引起了众多研究人员的关注[27-29].本质上说,类脑智能算法是从神经元、突触和神经环路的基本和涌现特性中获取灵感,从而对其结构、机制或功能进行数学建模,以找到类脑生物特征.这与人工智能密切相关,因为更好地了解生物大脑将进一步构建更加智能的模型.为此,本文将随机权神经网络与生物大脑的相关工作机制联系起来,提出了一种新的再可塑性启发的随机化网络(Metaplasticity-inspired randomized network,MRNet)用于类增量学习(Class incremental learning,Class-IL)场景.具体地,本文的主要贡献如下: 1) 以前馈方式开发了一种多层随机权网络结构,并设计了具备记忆功能的再可塑性矩阵,用于指导输出权值的更新;2) 为了有效兼容非IID 任务以及伴随出现的新类别,进一步构造了具有解析解的通用CL 框架,从而实现学习与记忆融合;3) 通过设计不同难度和未知顺序的任务序列,MRNet 相比于现有的CL 方法可以有效且高效地应用于Class-IL,表明本文方法进一步拓展了传统机器学习算法在图像分类任务上的分析能力.
与现有工作相比,所提方法的优势见表1 所示.具体地: 1) MRNet 利用任务之间共享的随机权值和解析解实现了以前馈方式构建,只需要访问一次当前任务的数据(相当于epoch 始终为1),具有易于实现、参数高效、收敛速度快等优点,是一种更加通用的CL 方法;2) MRNet 只需要巩固最后一层的解析解而无需逐层优化模型参数,无需存储旧数据或构建数据生成器,也无需增加网络尺寸;3) 由于不需要调整学习率等超参数,其模型更新只需要较少的人为干预且具有较强的任务顺序鲁棒性.
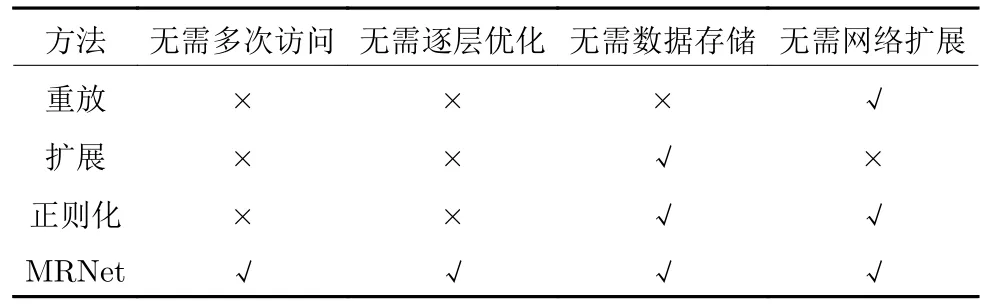
表1 不同类增量学习方法的特性Table 1 Characteristics of different Class-IL methods
1 相关工作
1.1 连续学习场景
本节主要介绍3 种不同的连续学习场景以阐明其难度和普遍性,即任务增量学习、域增量学习和类增量学习[14,18].图1 以手写数字识别数据集MNIST[30]为例,将其拆分为5 个独立的二分类任务.这里仅给出该任务序列的前两个.一个CL 模型依次在任务t(t=1,2,···,5) 上完成训练后需要识别所有见过的 2t个类别 (C1,C2,···,C2t)[24].
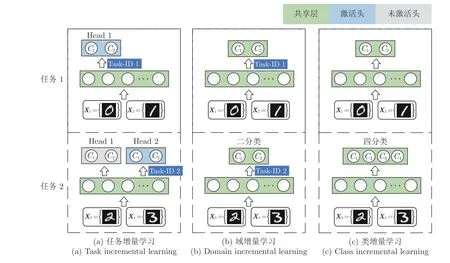
图1 三种连续学习场景Fig.1 Three continual learning scenarios
1 ) 任务增量学习: 该场景所使用的网络结构具有Multi-heads 输出层,这意味着每个任务都有自己的输出单元,只有匹配某一任务的Head 才会被激活并作出预测.同时,网络的其余部分通常在任务之间共享.由于需要不断增加网络尺寸和始终提供被测任务的Task-ID,这也是最简单的连续学习场景,如图1(a)所示.
2 ) 域增量学习: 不同于将知识从旧任务转移到新任务的域自适应,域增量学习旨在使用单一模型同时兼顾新旧任务的性能.该场景的典型特点是神经网络结构总是固定的,如输出单元对于所有任务都是相同的,但输入分布不断变化.同时,是否需要提供Task-ID 取决于任务序列的标签是否一致,如图1(b)所示.
3) 类增量学习: 要求模型不仅能够识别目前学过的类别,而且可以适应未来任务中出现的新类别.相应地,神经网络的输出节点数与任务序列所包含的类别总数保持一致.在学习过程中被测任务的身份也不再需要,这是开放环境中最为常见的场景,如图1(c)所示.因此,我们将本文的研究重点集中在最具挑战性和普遍性的Class-IL 场景中.
1.2 类增量学习定义
Class-IL 基本定义如下: 假设给定任务t(t=1,2,···,T)的输出类别数为Ct.类似传统单任务学习,类增量学习模型M(θ1) 表示在第1 个任务上完成训练并能够识别C1个类,其中,θ1为当前模型参数.不同的是,M(θt)(t ≥2) 的目标是在完全不访问或者部分访问旧任务数据等情况下(见表1)学会如何执行新任务并且不忘记旧任务[15,21],从而需要累计识别个类.这意味着测试过程中的样本可能来自迄今为止所学过的任务 1~t中的任何一个或多个,这可以通过预分配个输出节点来容纳所有可能出现的类别.
1.3 随机权神经网络
上世纪90 年代,文献[31]提出的随机向量函数链接网络(Random vector functional link networks,RVFLNs),以及文献[32]提出的具有随机权值的浅层网络结构为随机权神经网络(Random weight neural networks,RWNNs)的发展奠定了基础[33-35].作为一类随机化前馈神经网络,RWNNs的典型特征在于网络参数(输入权值和偏置)仅在给定的区间内随机产生,因此只需解析求解输出权值.由于RWNNs 易于实现且收敛速度快,从而受到了广泛的关注[35-37].近年来,具有代表性的RWNNs包括: RVFLNs 的改进版[38]、随机配置网络(Stochastic configuration networks,SCNs)[39]和宽度学习系统(Broad learning system,BLS)[40]等.相比DNNs,它们的学习形式更加符合生物脑功耗低、实时性快等特点[34,41-42].
1.4 再可塑性
在神经科学领域,突触可塑性(Synaptic plasticity)表示学习与记忆功能的重要细胞机制,其中长时程增强与长时程抑制是突触可塑性的两种主要表现形式.再可塑性(Metaplasticity)作为突触可塑性的一种高级形式,它表示突触可塑性的可塑性,即突触活动的过往史(Activity history)对后续的突触可塑性产生的影响,这表明突触的可塑性依赖于当前的突触“状态”[43-45].再可塑性一般发生在给予一个前期刺激(Priming stimulation)或经历之后,且这个前期刺激的影响能够持续存在,导致后续长时程增强的诱导阈值明显改变.受再可塑性的启发,我们将根据先前任务节点之间的连接权值来度量模型参数重要性[4](见第2.3.2 节).
2 类增量连续学习模型
2.1 问题描述
无论是DNNs 还是RWNNs,其本质上都是针对某一特定任务而建立的联结主义模型,并假设所有样本满足IID 以确保训练与测试数据均服从同一概率分布,从而形成单一、固定的映射关系.然而,该假设忽略了开放环境中流式数据的不可预见性:一方面,未来数据的分布一旦发生变化,就会导致映射关系集之间的覆盖或者干扰;另一方面,新任务的出现往往伴随着新类别,使得其在后续训练过程中难以兼容标签分布的变化.因此,当它们在类增量学习场景中依次面向不同任务时都会遭受灾难性遗忘的影响.具体地,在算法层面所面临的问题概括如下.
1 ) 由DNNs 建立的CL 模型均是通过BP 算法实现的,在任务序列的学习过程中对超参数(例如学习率、epoch、mini-batch 等)的设置极为敏感.为此,通常会选择较小的学习率和较大的epoch 以获得更好的性能,但会导致耗时的训练过程且针对当前任务优化的超参数往往不再适用于过去和未来的任务.更为重要的是,在不访问旧任务数据的情况下多次遍历新任务数据,不仅不利于保留旧任务的信息而且可能由于隐私限制根本无法满足.
2 ) 作为一种替代性方法,尽管RWNNs 随机初始化输入权值和偏置并解析评估输出权值避免了误差反传,但是仍无法直接面向任务序列.首先,仅随机初始化的连接权值难以保证增量式地提取具有判别性的特征;其次,特定于任务的输出权值仅考虑了当前任务的信息,导致其只适用于传统的单任务学习;最后,输出权值的更新缺乏理论依据与指导,即无法实现学习与记忆融合.因此,需要进一步的改进.
2.2 思想方法
MRNet 的目标是在求解新任务的解析解时,将其引导至新旧任务的公共低误差区,而不是只关注某一特定任务.例如,过参数化 (Over-parameterization)使得新任务的解可以无限接近旧任务,不同可训练参数的最终设置可以产生相同水平的学习性能,任务序列间的相似性以及现有CL 方法的研究进展都为MRNet 的可行性提供了保证[7,23,46].其核心思想是首先在旧任务上评估输出权值的重要性,然后在新任务上训练时仅更改对于旧任务而言不重要的部分,从而保证模型在新旧任务上的性能.
MRNet 网络结构如图2 所示,主要包括一个全局的预训练特征提取器、随机初始化的扩展输入层和隐含层.其输入既可以是原始数据X也可以是特征向量Xf.在这种设置下,全局网络仅在复杂任务序列时使用且可以是任何架构.为了简化符号,本文使用X来表示两者.假设给定任务t(t=1,2,···,T)的训练样本,其中Xt为输入,Yt为输出,Nt为样本个数,Mt和Ct分别为输入模式和输出类别数.例如,在图像分类任务中,Mt表示图像的大小,Ct表示图像的独热编码(One-hot coding)标签.
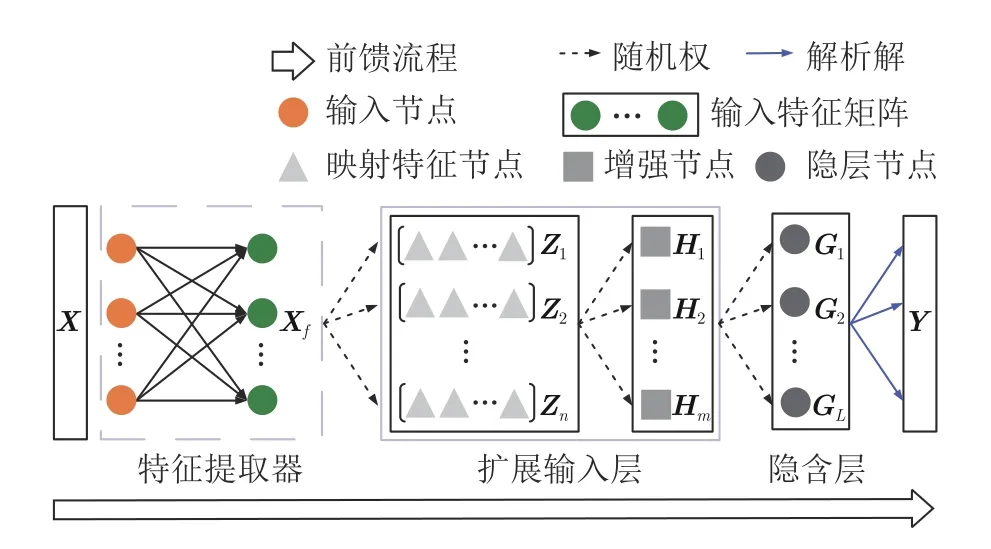
图2 用于连续学习的MRNet 结构Fig.2 MRNet architecture for CL
从算法实现的角度来说,训练过程包括阶段1:初始化MRNet;阶段2: 学习与记忆融合.具体地,第2.3.1 节首先通过第1 个任务随机初始化1 个固定大小的基网络,并在后续的任务中保持不变;然后,第2.3.2 节设计了具备记忆功能的再可塑性矩阵用于指导输出权值的连续更新;当第2 个任务出现时,第2.4.1 节构造了目标函数,并创新性地推导出解析解,第2.4.2 节进一步将其推广至任意长的任务序列;最后,第2.5 节给出了上述两阶段训练的算法实现步骤.
2.3 初始化MRNet
2.3.1 传统单任务学习
一个基本的MRNet 包括n组映射特征节点(每组k个节点)和m组增强节点(每组1 个节点).其中映射特征节点用于对原始输入样本或特征向量进行特征处理;增强节点则作为网络额外的输入.不同于BLS 及其变体[40,42],MRNet 简化了从扩展输入层到输出层的直接连接用于匹配判别信息,因为从先前任务中学习到的判别信息对于后续任务而言往往是不具有判别性的[11],具体见第3.4节消融实验.任务1中,,Y1∈的训练过程与传统RWNNs 的单任务学习类似.如图2 所示,首先第i组(i=1,2,···,n)映射特征节点的输出可以表示为
式(4) 通过引入一个额外的常数约束λ并在矩阵ATA对角线上添加一组接近于0 的正数来近似.它不仅可以在一定程度上避免过拟合,而且可以保证矩阵在病态条件(Ill condition)下近似解的存在.
在学习完任务1 中的C1个类别后,模型M(θ1)的输出权值W可以通过式(5)计算,即
因此,式(5) 为仅通过任务1 得到的优化权值(这里W=).进一步地,预测误差矩阵为
其中,E1=[e1,1,···,e1,p,···,e1,N1]T,e1,p ∈RC1对应于任务1 中第p个训练样本 (X1,p,Y1,p) 的残差.需要指出的是,W将在后续任务的学习中不断更新.
2.3.2 构造再可塑性矩阵
本节为MRNet 在连续学习过程中如何更新输出权值提供理论依据与指导.根据第2.2 节可知,模型参数重要性发挥着类似突触再可塑性的作用.其中,每个输出权值的再可塑性越高,其重要性越低,对旧任务性能的影响也就越小,因此可以优先改变以兼容新任务的分布;相反,输出权值的再可塑性低则表示其重要性高,那么这部分理想上应保持不变,从而保留模型对旧任务的记忆.因此,我们围绕节点之间的连接权值度量其重要性,并用来巩固MRNet 的输出权值.
对于任意的任务t(这里以任务1 为例),首先利用交叉熵损失(Cross-entropy loss)函数ℓ(,Y1)保证模型M(θ1) 所建立的映射关系与任务1 中数据D1=(X1,Y1) 之间分布的近似,其中,=A1W;然后,通过对输出权值W添加无穷小更新量ΔW观察损失函数的变化,可以近似表示为
实际上,根据文献[48]中描述的特性,式(8)中一阶导数的平方是式(9)给出的计算耗时的海森矩阵(Hessian matrix)的等价且有效替代方法,即
本质上来说,式(9)中二阶导数反映了ℓ(1)本身相对于W中每个元素的变化率.相应地,F1中较小的元素值表明其对损失函数的影响不大;反之亦然,从而实现了对旧任务记忆的保留.因此,我们将具备记忆功能的F1命名为再可塑性矩阵并用于MRNet 输出权值的自适应更新.
需要指出的是: 1) MRNet 在任务1 上完成网络结构初始化,并在接下来的任务中保持不变;后续MRNet 的初始化均指在前一个任务上持续获得再可塑性矩阵Ft(t=1,2,···,T -1).2) 式(8)虽然涉及了梯度计算,但仅仅是一阶且不需要梯度信息反传.因此,以上过程仍然是高效且易于实现的.3) 一旦完成Ft的计算,相应任务的数据Dt不再保留.4) 除非另作说明,下文中出现仅下标不同的同一个变量均表示在特定任务t下的相同含义.
2.4 学习与记忆融合
本节详细介绍如何将再可塑性矩阵用于MRNet 连续学习过程以实现输出权值的有效更新,包括: 1) 针对任务2 构造目标函数并创新性地推导出解析解;2) 进一步推广至任意长的任务序列.
2.4.1 处理两个任务
当任务2 出现时,我们利用F1=P1⊙P1指导输出权值W中的元素有选择性地接近或偏离最近一次得到的,其中,运算符⊙表示逐元素积,即矩阵对应位置元素相乘、所得矩阵维度不变.于是,MRNet 的目标函数可以表示为下列一般性问题
其中,λ1控制着模型在学习任务2 时对任务1 的保护程度;RC1表示仅在任务1 上根据式(5)得到的优化权值的第l行;P1,l ∈RC1表示相应的输出权值重要性.注意到式(10) 中第1 项负责任务2 的学习,而任务1 的所有记忆都包含在第2项中.因此,MRNet 鼓励其输出权值W的解空间围绕先前任务获得的.
式(10) 可以通过KKT (Karush-Kuhn-Tucker)条件[49]求解如下:
其中,υ2,p ∈RC2表示拉格朗日乘子并对应任务2中第p个训练样本 (X2,p,Y2,p).分别对式(11) 中的决策变量W,E2和υ2求偏导可以得出
经过整理,得到
其中,标量γ1=λ1N2表示任务1 与任务2 之间的权衡(Trade-off).
注意到式(15) 中传统矩阵相乘与逐元素积的共存导致难以推导出输出权值W,为此,本文进一步结合逆运算的特点,创新性地提出了一种分块矩阵对角化(Partitioned matrix diagonalization,PMD)方法: 1) 分别对矩阵W,F1和Y2按每一列分块,得到W=[W1,···,Wc,···,WC1],F1=[F1,1,···,F1,c,···,F1,C1] 以及任务2 的输出Y2=[Y2,1,···,Y2,c,···,Y2,C2];2) 矩阵F1,c(c=1,2,···,C1) 被对角化为Λ1,c ∈RL×L;3) 在学习完任务2 中的C2个新类别后,模型M(θ2) 输出权值W=[W1,···,Wc,···,WC]∈RL×C(其中,C=C1+C2) 的每一列都可以采用递归的方式独立地解析为
2.4.2 面向任务序列
本节将两个任务的情况推广到任意长的Class-IL.对于包含CT个新类别的任务T(T ≥2),下面给出统一的CL 框架,即
其中,γt=λtNt+1表示任务t与任务t+1 之间的权衡.同时,注意到当T=2 时,式(18) 等同于式(16).进一步地,当再可塑性矩阵取为单位阵并忽略不存在的项时,式(16) 等同于式(5).这从理论上证明了单任务学习是CL 的一种特殊情况.
2.5 算法描述
从算法实现的角度来说,MRNet 本质上属于一种特殊的正则化方法,其仅通过一个二次惩罚项实现对旧任务的记忆.这是因为最近一次得到的输出权值包含了先前所有见过任务的信息.一旦在任务t上完成训练并得到输出权值Wt和再可塑性矩阵Ft,该任务的数据Dt不再需要存储和访问.如式(17)所示,此时先前任务上得到的输出权值Wt(t=1,2,···,T -2) 均可以被丢弃,可以在无需Task-ID 的情况下累积更新.这意味着MRNet 的内存随任务数量的增加基本上保持不变.具体地,其训练过程包括两个阶段: 阶段1: 初始化MRNet;阶段2: 学习与记忆融合.
3 仿真实验与结果分析
本节将通过5 个评价指标、5 个基准任务序列和10 个比较方法验证所提方法的优越性.首先给出实验设置,然后在不同难度的Class-IL 场景中进行实验,最后进行参数灵敏度分析和消融实验.
3.1 实验细节
3.1.1 评价指标
为了全面评估CL 方法的有效性和高效性,本文采用测试精度、跨任务传递知识的能力、整个执行时间和参数存储需求来同时描述模型质量.假设任务序列的长度为T,具体如下.
1 ) 平均测试分类精度(Average test accuracy,ACC): 在迄今所有见到过的任务上测试分类精度的平均值,即
其中,RT,t表示在任务T上训练完后,模型在任务t上的测试分类精度.
2 ) 后向迁移(Backward transfer,BWT)[16]: 表示学习完任务T与学习完任务t两种情况下的模型分别在任务t上的测试分类精度之差,即
本指标反映了模型对旧任务知识的保留能力.BWT为负值意味着模型在遇到新任务后降低了之前任务的性能,较小的BWT则意味着灾难性遗忘.
3 ) 前向迁移(Forward transfer,FWT)[50]: 通过定义CL 模型相对于独立训练的模型在任务t上测试分类精度的提高,即
除上述三个精度相关的指标(均越高越好),我们还引入另外两个指标,具体如下.
4 ) 累计运行时间(Cumulative running time,Time),单位: s.
5 ) 模型最终参数量(Final number of parameters,No.Para.),单位: MB,用于综合评估模型质量.我们注意到,大多数CL 方法仅使用ACC 验证其优越性而忽略最小化计算、存储和时间需求等.
3.1.2 数据集
本节按照Class-IL 场景的通用设置来生成不同难度的任务序列[14,25,51],即分别划分FashionMNIST,CIFAR-100 和ImageNet 基准数据集.每个序列中的任务均独立地来自于原始基准数据集.我们使用[DATASET]-C/T表示一个任务序列总共包含C个类别并被均匀地划分到T个任务中,这意味着每个任务都需要学习C/T个新类别.下面简述如何生成任务序列.
1 ) 对于FashionMNIST,将10 个类别划分为5 个二分类任务,对应任务序列FashionMNIST-10/5 如图3 所示.模型每学习完一个任务立即丢掉该任务的训练数据(重放方法除外),然后等待新任务的出现.尽管由5 个简单的二分类任务组成,传统的ANNs 学习该任务序列仍具有挑战性.

图3 FashionMNIST-10/5 任务序列Fig.3 FashionMNIST-10/5 task sequence
2 ) 对于CIFAR-100,将100 个类别分别划分为5 个包含20 个自然图像类的任务序列(CIFAR-100/5)和10 个包含10 个自然图像类的任务序列(CIFAR-100/10),如图4 所示.CIFAR-100/5 中包含更多的类,增加了每个任务的难度;而CIFAR-100/10 则通过增加任务序列的长度,测试CL 方法的信息保留能力.

图4 CIFAR-100 任务序列Fig.4 CIFAR-100 task sequence
3 ) 对于ImageNet,我们使用其子集ImageNet-200,让模型分别增量学习不同长度的任务序列.类似地,所得到的ImageNet-200/10 和ImageNet-200/50 分别需要模型具有连续学习10 个20 分类任务和50 个4 分类任务的能力.
3.1.3 比较方法
本节将本文提出的MRNet 在Class-IL 场景中与现有经典和最先进的7 种CL 方法相比,包括MAS[4],GEM[16],EWC[23],SI[24],OWM[25],IL2M[15],PCL[11].为了使得比较更加全面,我们还与3 种非CL 方法进行比较,包括一种仅适用于单任务学习的RWNNs,即BLS[40],基于L2 正则化的微调,在整个任务序列上离线联合训练(Jointly training,JT),其通常被认为是CL 方法关于评价指标ACC的上界.
3.1.4 网络参数
1 ) 网络结构: 为了公平比较,所有方法对所有划分的任务序列分别使用类似大小的网络结构.对于FashionMNIST-10/5,基于BP 算法的比较方法使用一个多层感知机(Multi-layer perceptron,MLP),即[784-800-800-10];BLS 与MRNet 则分别通过随机初始化固定的基网络[748 -(10 × 10 +1 500) -10]、[784 -(10×10+700) -800 -10] (对应n=10,k=10,m=700,L=800).由于该任务序列较为简单,故没有使用预训练特征提取器(见图2).对于CIFAR-100,一个标准的ResNet-56 用于特征提取.我们按照OWM[25]中的实验设置,首先使用由整个训练集预训练的特征提取器来分析原始图像,然后将得到的特征向量依次输入CL 模型中(与FashionMNIST-10/5 实验相似的网络结构).即CIFAR-100/5 与CIFAR-100/10 是增量学习不同类别特征和标签之间的映射关系.我们将预先训练好的特征提取器同时应用于MRNet 和所有比较方法.对于ImageNet-200,我们接下来评估MRNet 是否能够学习具有挑战性且不涉及使用训练集获取预训练特征提取器的新任务[11].例如,先以Tiny-ImageNet-200 作为辅助数据在ResNet-50 上进行预训练,然后从ImageNet 余下的800 个类别中随机选择200 个用于划分任务序列.这符合人类学习的特点,即我们倾向于为具有挑战性的任务做充分的准备,而不是没有任何先验知识.需要指出的是,当使用预训练特征提取器时,其在本文所提MRNet 和所有比较方法中都同样使用.
2 ) 参数选择: 对于所有基于BP 算法的比较方法,我们使用由其作者发布的开源代码或流行的第三方代码,并进行了大量的调参.学习率取自 {0.1,0.01,0.001},mini-batch 大小设为100 (用于FashionMNIST 和CIFAR-100 划分的3 个任务序列)或 {100 和20} (用于ImageNet 划分的2 个任务序列).进一步地,根据GEM[16]等方法中的实验设置,我们将简单任务序列(FashionMNIST)的epoch 设置为1,即当前任务样本在简单序列中仅允许被访问一次;对于具有挑战性的任务序列(CIFAR-100和ImageNet)的epoch 放宽为不加以限制;而本文所提MRNet 对所有任务序列的epoch 始终为1.对于重放方法,我们始终保留4.4 k 个随机样本集(FashionMNIST)以及限制重放预算为2 k 个样本(CIFAR-100 和ImageNet);对于扩展方法,保证其在学习完所有的任务后与基网络相同规模;对于正则化方法,权衡系数针对不同任务序列选自集合{100,1 000,10 000,100 000},MRNet 的相关设置见第3.3 节参数分析.
3.1.5 实验协议
在训练过程中,仅重放方法可以存储和访问少量先前任务的训练数据,而其他方法只有当前任务t的训练样本可供模型训练.在测试过程中,当模型学完T个任务时,测试样本来自迄今为止所有学过的任务 1~T,且无需告诉模型Task-ID,然后计算评价指标(见第3.1.1 节).同时,我们在每个基准数据集所划分的任务序列(见第3.1.2 节)上独立重复10 次实验,并记录这些结果的平均值和标准差.其中,每次实验中的任务顺序(Task ordering)都是随机分配且未知的,以验证模型在开放环境中的实用性.
3.2 结果与讨论
3.2.1 FashionMNIST
表2 给出了MRNet 与10 种经典和最新的比较方法在FashionMNIST-10/5 任务序列上的连续学习性能.实验结果通过5 个评价指标在该任务序列上独立重复10 次实验获得,并记录了这些结果的平均值和标准差.其中,每次实验所提供的任务顺序均从5 个2 分类的任务中随机分配.作为非CL方法,BLS 和L2 只能针对IID 任务建立特定的输入输出映射关系,而且一旦训练完成,该映射不再发生改变.其中,尽管BLS 在单任务学习中表现良好,对于任务序列只记得最近一次学习的任务,而之前的任务被完全遗忘.L2 对待所有模型参数施加同样程度的惩罚,仍导致模型偏向特定任务的学习.
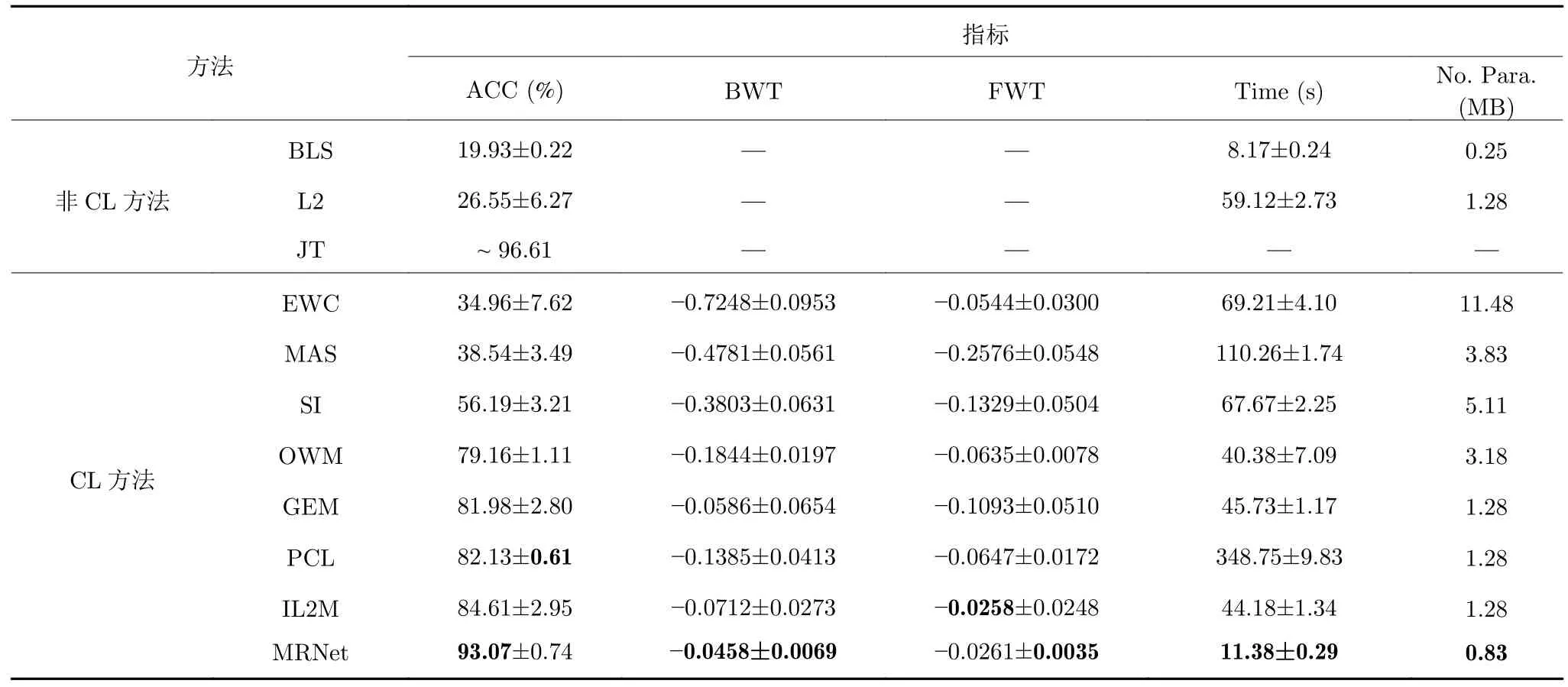
表2 连续学习FashionMNIST-10/5 任务序列对比实验Table 2 Comparative experiments on continuously learning FashionMNIST-10/5 task sequence
首先关于ACC,我们注意到余下CL 方法基本都可以在MNIST-10/5 任务序列上获得较好的性能,而一旦换成FashionMNIST-10/5 则呈现出不同程度的下降.一般来说,类增量学习对于无需网络结构增加和使用旧任务数据的正则化方法(EWC,MAS,SI 和OWM)来说尤其困难.扩展(PCL)和重放(GEM 和IL2M)方法的性能普遍较好,很大程度上归因于网络结构的增加和旧数据的使用,其中IL2M 是最强基线(Baseline).对比之下,MRNet 的ACC 高出IL2M 8.46%.此外,通过ACC 的标准差可知,大多数CL 方法非常容易受序列中任务顺序的影响,而MRNet 执行10 次随机分配的实验都具有一致的ACC,且仅次于具有Multi-heads设置的PCL[11].这意味着本文所提方法通过解析解可以提高任务顺序鲁棒性.
其次,一个可取的CL 模型还应该具有较大的BWT 和FWT.MRNet 的BWT 值最接近于0,表明其对于旧任务知识的保留能力高于其他方法.重放方法(GEM 和IL2M)的BWT 值明显高于其他方法,这在一定程度上是因为它们在学习新任务时访问旧任务数据.而当模型保留的旧任务数据非常有限时往往会导致类别不平衡问题.与此同时,IL2M 进一步存储了历史任务类别的统计信息,其FWT=-0.0258 在所有方法中最大.MRNet 的FWT=-0.0261 意味着其尝试借助先前任务的信息以更好地学习(至少尽可能不阻碍)新任务.
最后,MRNet 在Time 和No.Para.上明显优于其他基于BP 算法的CL 方法,表明其具有参数高效、收敛速度快和易于实现等优点.同时,这两个指标也在一定程度上反映了模型质量.然而,现有CL 方法大多只关注ACC 而忽略时间、计算成本和存储需求.因此,FashionMNIST-10/5 实验通过5个评价指标更加全面地验证了本文所提方法的有效性和高效性.
3.2.2 CIFAR-100
尽管在FashionMNIST-10/5 任务序列上的实验结果表明MRNet 能够有效缓解灾难性遗忘,但是所建立的CL 模型仅仅用于依次学习5 个简单的2 分类任务.本节将面向更复杂的分类任务以及更长的任务序列.图5 给出了Class-IL 场景中不同CL 方法在CIFAR-100/5 和CIFAR-100/10 两个任务序列上的ACC,分别需要模型具有连续学习5 个20 分类和10 个10 分类任务的能力.结果表明,本文所提MRNet 明显优于其他方法.对于图5(a),BLS 将所有见过的任务识别为最近一次任务中的类别;L2 在学完任务2 时也已经开始遭受严重的灾难性遗忘;除了OWM,其余正则化方法(EWC,MAS和SI)均表现出不同程度的遗忘.MRNet 分别比基于重放的IL2M 和基于扩展的PCL 高出8.30%和5.26%.同样的结论也可以从图5(b)中得出.
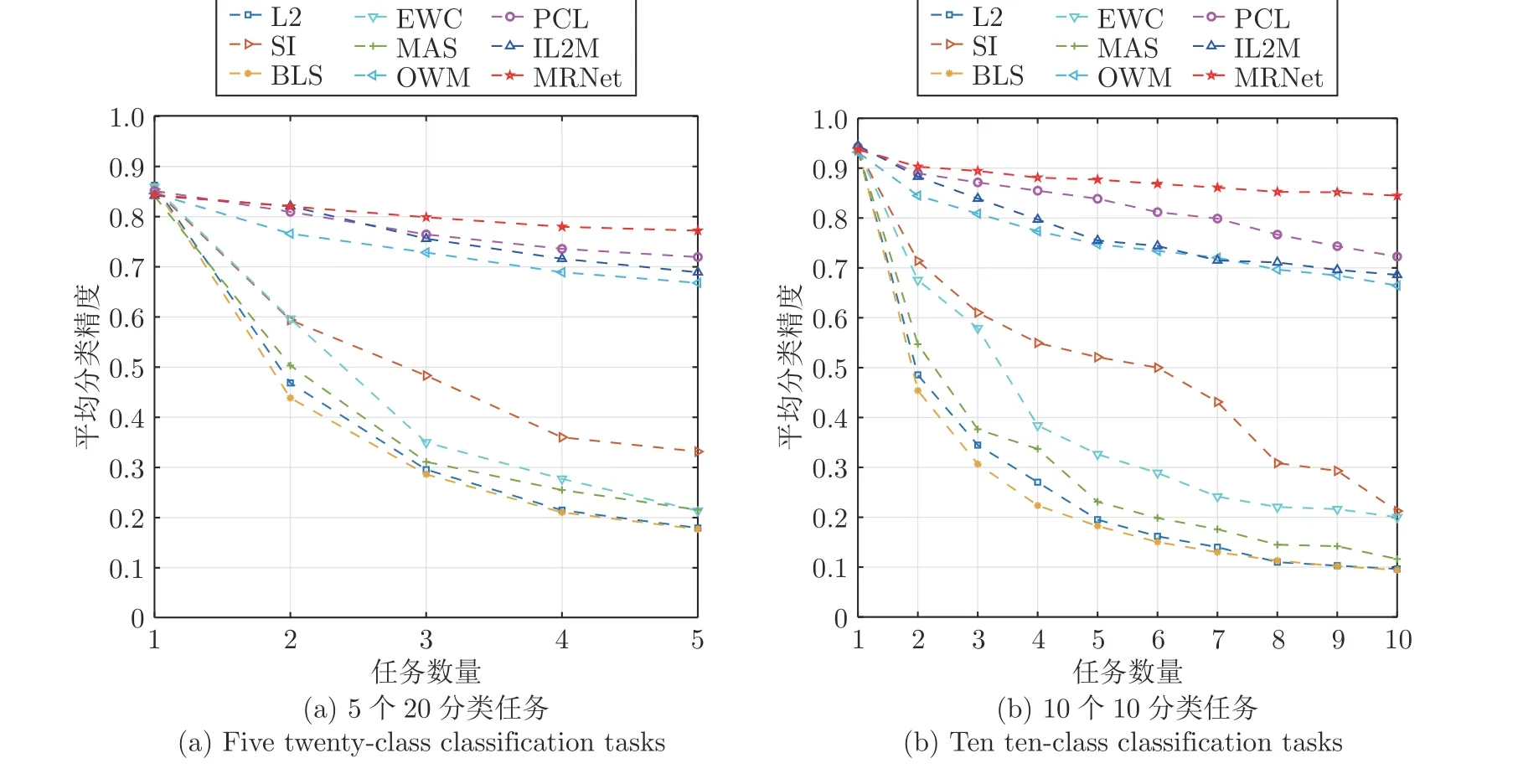
图5 不同方法在CIFAR-100 任务序列上的分类精度曲线Fig.5 Classification accuracy curves of different methods on CIFAR-100 task sequence
3.2.3 ImageNet
表3 进一步给出了不同方法在ImageNet-200上的实验结果.相比FashionMNIST 和CIFAR-100 任务序列,该实验中单任务的学习更具有挑战性,多任务之间的干扰更容易发生.首先,虽然MRNet 在ImageNet-200/10 任务序列中的ACC仅高出PCL 约0.1%,但是后者的参数量比MRNet 多36.16% (同表2),时间需求比MRNet 高上百倍;其次,MRNet 在ImageNet-200/50 任务序列中的标准差略低于PCL,但其ACC 高出PCL 3.47%且明显优于IL2M 和OWM;最后,我们注意到从ImageNet-200/10 到ImageNet-200/50,IL2M 的学习性能显著降低.这在一定程度上是因为基于重放的IL2M 允许使用2 k 个样本大小的缓冲区,但任务数量的增加导致新旧任务之间的数据不平衡问题越来越明显.总的来说,本文方法具有精度高、计算/内存成本低和训练时间快等优点.

表3 连续学习ImageNet-200 任务序列对比实验Table 3 Comparative experiments on continuously learning ImageNet-200 task sequence
3.3 参数分析
除了第3.1.4 节给出的超参数设置,下面进一步讨论MRNet 在T个任务之间引入的权衡系数,即{γ1,γ2,···,γT-1}.如前所述,MRNet 作为一种再可塑性启发的类增量学习算法,其关键在于“稳定性”和“可塑性”之间的平衡.从算法实现的角度来说,CL 模型不仅需要维持先前任务的信息,而且需要克服旧任务对新任务的干扰.为此,我们从1≤λt ≤108中选取不同数值在CIFAR-100/5 任务序列上进行比较实验.表4 记录了模型学习完新任务t(t=1,···,5)后,在所有见过的t个任务上的ACC,即At;同时,给出了学习完5 个任务时模型的BWT 和FWT.评价指标均越高越好.在此基础上,我们对不同权衡系数进行了灵敏度分析.为了简化描述,定义γt的大小表示对旧任务的保护程度,并依次分为: “无保护”{1,1,1,1},“欠保护”{1,1,1,1}×102,“适当保护”{1,1,1,1}×104,“过保护”{1,1,1,1}×106和“全保护”{1,1,1,1}×108五种情况.1) “无保护”情况: MRNet 仅记得当前学习过的任务,由于整个过程几乎完全偏向新任务的学习,使得FWT 出现了正值,这意味着模型使用(牺牲)先前学到的知识来提高新任务的性能;2) “欠保护”情况: 类似于“欠拟合”,其对旧任务的保护程度非常有限,重点仍然是当前任务;3) “适当保护”情况: 该程度的保护适用于本文所提的MRNet,有效实现了未知任务序列的学习与记忆融合;4) “过保护”情况: 学习的重点转向历史任务,导致多任务之间出现干扰;5) “全保护”情况: 模型通过限制当前任务的学习以维持历史任务的信息,因此BWT出现了正值.
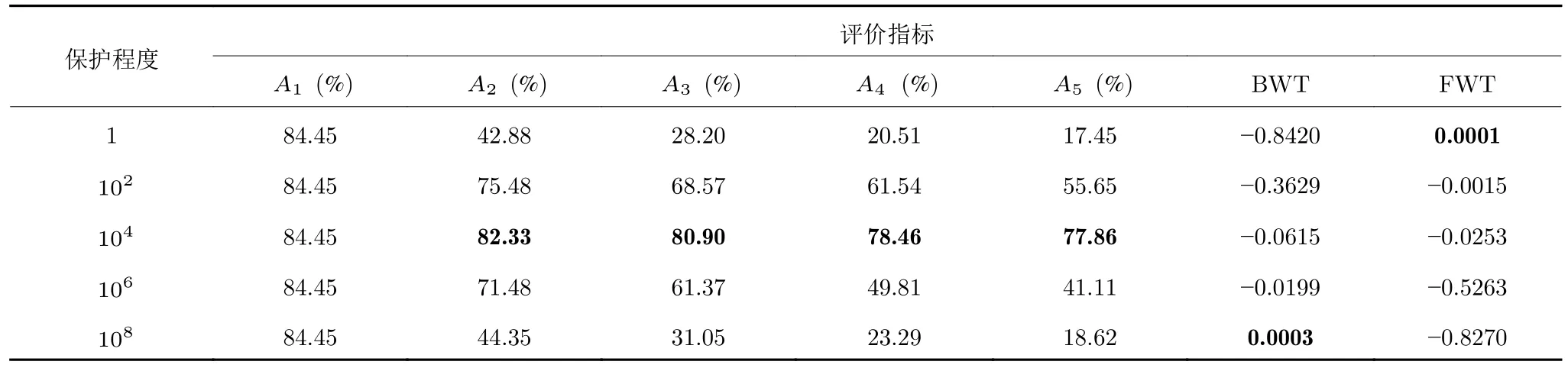
表4 权衡系数灵敏度分析Table 4 Sensitivity analysis on the trade-off coefficients
需要指出的是,参数分析的目的是为MRNet 确定对旧任务的保护程度并提供合适的权衡系数候选集.因此,可以在{1,1,1,1}×104的基础上对γt进行微调.此外,我们注意到基于BP 算法的正则化方法,如(Online) EWC[20,23]、SI[24]和MAS[4]对权衡系数极为敏感,不仅容易受其他超参数(学习率,mini-batch 等)的影响,而且在不同任务序列上的设置也完全不同.换句话说,这些方法对旧任务难以预先设定好保护程度.
3.4 消融实验
在第2.3.1 节提到,MRNet 在随机初始化基网络时简化了从扩展输入层到输出层的直接连接,用于匹配判别信息.如表5 所示,分别给出了在FashionMNIST-10/5 任务序列上不使用和使用直连结构的实验结果.可以看出,当MRNet 带有直连结构时,其仅在第1 个任务上的分类精度A1优于没有直连的情况.这是因为将从扩展输入层到输出层的信息作为额外输入确实有利于增加所提取特征的判别信息,从而出现较高的A1.然而,从旧任务中学习到的旧类的判别信息在新类之间以及旧类和新类之间往往不具有判别性,这导致其A2~A5,BWT 和FWT 明显降低,加剧了灾难性遗忘的发生.
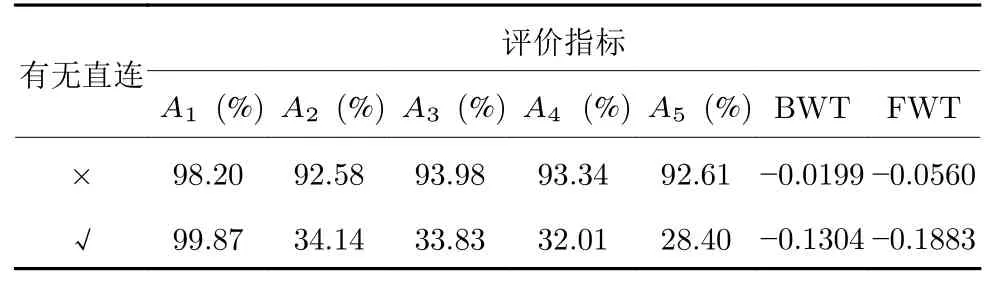
表5 MRNet 结构分析Table 5 Analysis on MRNet architecture
4 结束语
本文基于随机权神经网络建立了统一的连续学习框架,用于有效兼容未来非独立同分布任务以及伴随出现的新类别,并给出了无需梯度下降算法的解析解,包括受启发于突触再可塑性构造了具备记忆功能的权值重要性矩阵用于自适应地调整网络参数,从而维持对历史任务的记忆.与现有经典和最先进的连续学习方法相比,所提MRNet 具有参数高效、收敛速度快、人为干预度少等优点.与此同时,它打破了现有连续学习方法需要多次遍历访问(对应较大的epoch)当前任务的数据以在新任务上获得更好性能的约束,是一种更加具有通用性的学习与记忆融合模型与算法.然而,MRNet 结构包括一个全局特征提取器和特征到端的简单分类器,这表明本文所提方法需要借助预训练模型.因此,我们将在MRNet 基础上进一步建立端到端的连续学习器.
