基于扩散模型的多模态引导图像合成系统
2024-01-02何文睿高丹阳周羿旭朱强
何文睿,高丹阳,周羿旭,朱强
(1.北京信息科技大学 计算机学院,北京 100192;2.浙江大学 计算机科学与技术学院,杭州 310058)
0 引言
近年来,随着ChatGPT、文心一言等生成式大模型的提出,人工智能生成内容(artificial intelligence generated content,AIGC)技术受到学术界的广泛关注[1]。AIGC在图像、文本、音频、视频等多样性内容创作任务上,以其创新性的生成方式引发了研究者们的浓厚兴趣[2]。研究初期,大部分AIGC相关任务使用基于生成对抗网络(generative adversarial network,GAN)实现,其通过对抗训练策略,致力于产生逼真的数据样本。然而,GAN方法在训练过程中的复杂性和不稳定性,以及可能出现模式坍塌现象和难以控制的样本生成质量等固有问题,限制了其进一步的发展。
随着具备更优越性能和更强大处理能力的大型模型技术逐渐成熟,生成式人工智能逐渐采用“大模型+大数据”的结合策略。例如,OpenAI发布的DALL·E2模型融合了预训练CLIP(contrastive language-image pre-training)模型和扩散模型,实现了从文本到图像的生成;Google提出的Phenaki使用预训练的双向掩码Transformer模型,对文本进行编码并直接生成视频内容;Deepmind研发的Alphacode运用大规模基于Transformer的语言模型,实现代码自动生成任务[3-5]。上述模型的出现,标志着AIGC领域正朝着更为高效和多样化的方向迅速发展,为多领域的创作和应用带来了新的机遇和挑战。
目前,生成式大模型可依据其所应用的任务类型,粗略划分为九大范畴,其中包括但不限于:文本生成图像、文本生成视频、图像生成文本、图像生成图像等。作为图像生成图像领域中的经典任务之一,生成式图像合成任务旨在基于用户所提供的参考图像,在确保合成图像的主体真实一致的前提下,实现图像中前景与背景的巧妙无缝融合。此外,该任务还能根据用户的文本输入,完成细粒度的修改与微调。如,Zhang等[6]深入探讨了前景元素在图像中的空间定位与尺度信息的预测;Zhan等[7]致力于消除前景物体引发的不必要遮挡,以提升图像的观赏质量。
生成式图像合成任务的发展为现实生活中的具体应用领域带来了优势。以电子商务领域为例,传统商品图像的制作过程涉及线下拍摄、图像优化及细节调校等复杂阶段,通常需多次迭代以获得理想的商品图像结果。然而,将生成式图像合成方法引入此任务,可实现自动生成高品质商品背景图,同时通过文本描述等方式实现低成本的细节微调,极大降低了时间和人力资源成本,提升了生产效率与灵活性,为用户提供了更为高效、便捷及个性化的商品展示解决方案。但在具体实际应用过程中,其仍存有一定局限性:若完全采用生成式合成方法,则无法确保商品主体的一致性;然而,若采用简单的前后景拼接方式,则可能导致前后景不协调,难以保障图像逻辑性等问题。因此,需在模型的创造能力与控制能力之间找到平衡点,以保证创造性实现生成多样化背景,同时强化控制能力,以确保主体和前后景之间的一致性与真实性。
考虑到在该任务中,涉及到文本和图像两种引导信息,因此,我们选择生成式大模型Stable Diffusion作为基本生成框架,并结合提示处理优化等模块,提出了一个聚焦于电子商务领域的商品图像合成任务的解决范式,极大降低了传统方式所带来的时间和人力资源成本,提升了生产效率与灵活性。
1 相关工作
1.1 生成式图像合成
图像合成(image composition)任务旨在将一张图像的前景与另一张图像融合,生成一张新图像。在该过程中,必须解决前后景之间的不一致等问题,包括但不限于外形、尺度和语义等方面的不协调。针对这些关键子问题,研究者们提出了多项子任务,具体包括:1)物品放置:为前景物体确定适宜的位置、尺度与形状[8];2)图像融合:解决前后景边界不自然的难题[9-10];3)图像和谐:透过调整色调、色温等视觉特征,增强前后景的视觉一致性[11-13];4)阴影生成:为新融合进背景的前景物体生成与背景中光影方向一致的阴影,以提升合成图像的整体真实性[14-15]。为了应对上述诸多问题,本文同时借助于掩码图控制和生成式融合策略,以实现视觉一致性。
1.2 提示工程
提示工程(prompt engineering)的主要目的在于设计和优化预训练语言模型的输入文本,以引导模型生成更为符合用户预期的输出。近年来,随着诸如ChatGPT等大模型的发布,提示工程的概念得到了更为广泛的应用,其现今涵盖了对大模型输入的调整,包括对文本输入和图像输入的合理调整,确保模型生成结果更加契合用户的预期[16-17]。
文本提示的设计通常需要满足以下两个关键要求。1)明确的指导:所使用的文本提示应当具有清晰且具体的表述,以确保模型能够充分理解其意图;2)正确的格式:鉴于大模型对于输入格式的要求,文本提示的格式应严格符合其规范。为了获得有效且高质量的文本提示,Yao等[18]引入了一种全新的知识引导上下文优化策略,以增强可学习文本提示在面对不可见类别时的泛化能力;Ma等[19]提出了一种高效且可解释的方法,以提升模型对于文本提示上下文的学习理解能力;Wang等[20]则提出了多任务提示调优策略,首先从多个任务特定的源提示中提取知识,以学习一个单一的可迁移提示,紧接着通过乘法低秩更新学习适应每个下游任务的共享提示;而Diao等[21]则提出了一种新颖的主动提示方法,通过任务特定的示例提示(使用人工设计的CoT推理注释),将大型语言模型应用于多样的任务领域。
在充分考虑商品图像合成任务的特点后,本文选择将文本和图像两种模态的数据同时作为提示以控制生成,提出了逆向文本提示方法实现将图像转换成文本提示并进行优化。
1.3 扩散模型
扩散模型(diffusion model)原本是物理学中的模型,后来科学家们借鉴该思想,提出了一种图像生成方法并建立生成模型[22]。扩散模型学习从噪声样本中恢复原始数据,独特的训练方法克服了GAN的局限性,如梯度消失导致的生成器训练失败、对抗性学习的过高计算成本和不易收敛等问题。目前,基于扩散的生成大模型,例如DALL·E2和Imagen,获得的图像水平已经实现对GAN多方面的超越[23-25]。
Stable Diffusion是一个基于扩散理论的文本到图像生成式大模型,由于该模型是基于扩散理论研发的,因此具有更高的稳定性。同时为了减少计算复杂度,使用了在潜在表示空间上进行扩散的方法,不仅降低了训练和推理的代价,而且能保持极好的图片生成效果,且能在更大的空间尺度上生成高质量的图像,并兼顾细粒度上的真实性和清晰度[26]。
但由于Stable Diffusion模型参数量庞大、训练非常困难,本文选择使用轻量级训练插件ControlNet,以引导生成图像的内容和风格。
2 多模态引导图像合成系统的构建
本文提出的多模态引导图像合成系统架构如图1所示,主要包括3个模块。
1)图像提示生成模块:利用原始图像和参考图像生成深度图与掩码图,作为图像引导信息,保证商品图融合时的位置合适且无杂乱背景生成。
2)文本提示生成模块:利用图像和文本作为提示信息,通过文本引导的方式对生成的图像进行微调,以符合预期。
3)合成图生成模块:融合图片提示与文本提示,生成前后景一致且符合审美与逻辑的新的商品图。
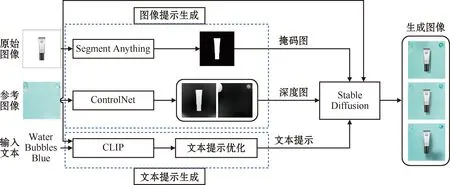
图1 多模态引导的图像合成系统结构Fig.1 Structure of multimodal guided image composition system
2.1 图像提示生成模块
图像提示包含两个关键信息,即掩码图和深度图。其中,掩码图旨在确保原始图像的前景物体的完整性。深度图为模型提供先验空间分布,保证在新图像的生成过程中,原图的前景元素得以保持优先地位。掩码图和深度图的并用,保证了图像生成过程中更高的准确性和可控性。其不仅在生成图像中实现了前景的无缝融入,也在细致处理中避免了不必要的干扰,进一步提升了生成结果的质量与真实度。
2.1.1 基于 Segment Anything 的掩码图生成
本文借助图像分割工具Segment Anything得到掩码图,其结构如图2所示。该模型支持灵活的提示,可以实时计算掩码以允许交互式使用,并且具有模糊性意识。强大的图像编码器计算图像嵌入,文本提示编码器嵌入提示,然后将这两个信息源组合在预测分割掩码的轻量化的掩码解码器中预测掩码[27]。本文系统使用时仅需输入图像。

图2 Segment Anything结构Fig.2 Structure of Segment Anything
Segment Anything能够准确地识别和定位图像中的前景物体,为其生成相应的掩码,进而在生成过程中为Stable Diffusion模块提供有针对性的区域引导。这种精细的引导方式有助于确保生成结果与原始图像的前景区域之间的无缝结合。
2.1.2 基于 ControlNet 的深度图生成
本文所提出的商品图生成范式旨在创造出与输入参考图像风格和构图相符的背景图像。理论上,可以通过训练额外的LoRA模型来实现[28]。但考虑到LoRA模型的训练代价昂贵,且其泛化能力有限,无法满足多样化的用户需求,因此,选择采用ControlNet,其结构如图3所示。
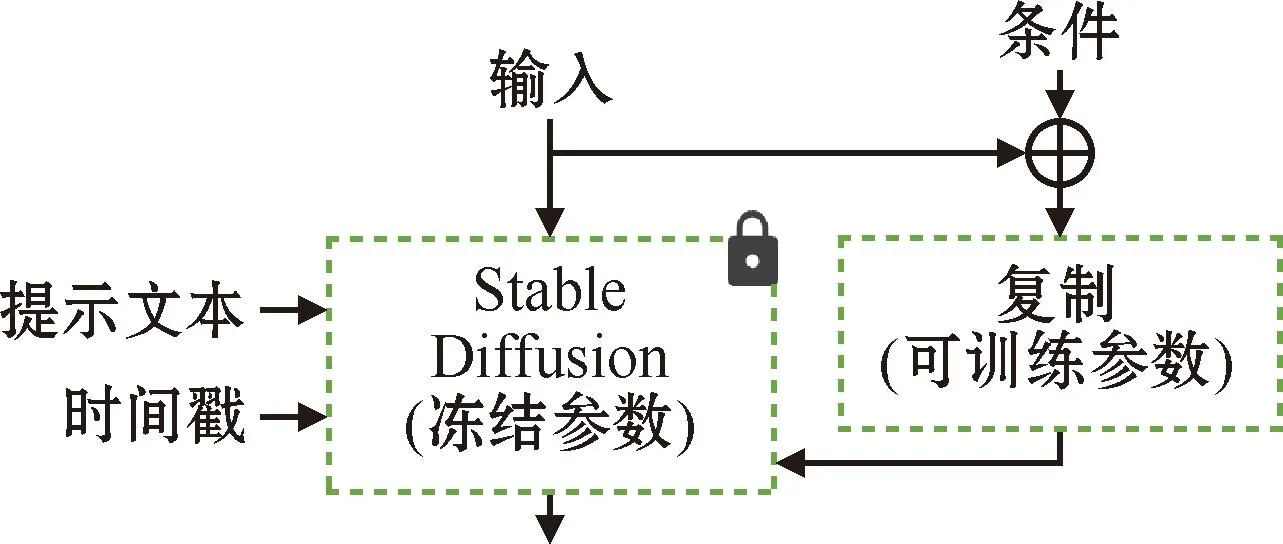
图3 ControlNet结构Fig.3 Structure of ControlNet
图3中左侧为标准Stable Diffusion,ControlNet的引入可以控制Stable Diffusion并使其支持更多的输入条件,如语义分割图、关键点图等。ControlNet包含两部分参数:冻结参数部分和可训练参数部分。其中冻结参数部分固定原始权重,保留Stable Diffusion原有的图像生成能力;可训练参数部分的参数在训练阶段会进行更新,逐步提高模型能力。利用复制的方式,能够有效避免模型在数据集较小时出现过度拟合的情况,同时保留模型从数十亿图像中达到的生成质量。本文系统使用时仅需输入图像。具体来说,本文利用ControlNet中的Reference_Only处理器,通过该处理器,只需附加一张额外图像,即可得到高质量的输出结果。同时利用Depth_Midas处理器,以提取输入图像的深度信息,从而获得精确的深度图。得到的深度图在明确生成图像中物体的分布方面具有关键作用,既确保生成结果的物体分布与参考图像相似,同时避免在主要物体周围产生杂乱无章的干扰物体[29-30]。
2.2 文本提示生成模块
文本提示包括两个部分:逆向文本提示是参考图像转换得出的文本信息;原始文本提示由用户直接提供。其中,逆向文本提示有助于确保生成图像与参考图像的相似性,而用户输入的原始文本则为生成图像提供了预期描述,对生成图像的主题、元素以及整体风格等方面起到了约束作用。将两种不同的文本提示相结合,赋予了生成过程更高的灵活性和可控性,既保证了生成图像与参考图像的一致性,又能够满足用户的个性化需求。
2.2.1 基于 CLIP 的逆向文本提示生成
通过将参考图像特征转化为文本形式,为生成过程提供了视觉特征辅助,使得生成的图像在构图与风格上更接近于参考图像。具体来说,逆向文本提示来自于参考图像,借助CLIP模型,参考图像的视觉信息被转化成文本信息,称为逆向文本提示。
CLIP核心结构如图4所示,包含文本编码器和图像编码器。其预训练分为两个阶段:第一阶段是通过一个大规模的文本数据集训练模型,使其能够理解文本之间的关系;第二阶段则是使用一个大规模的图像和文本对数据集,同时训练图像编码器和文本编码器,使得模型能够将含义相同的文本特征和图像特征进行匹配。
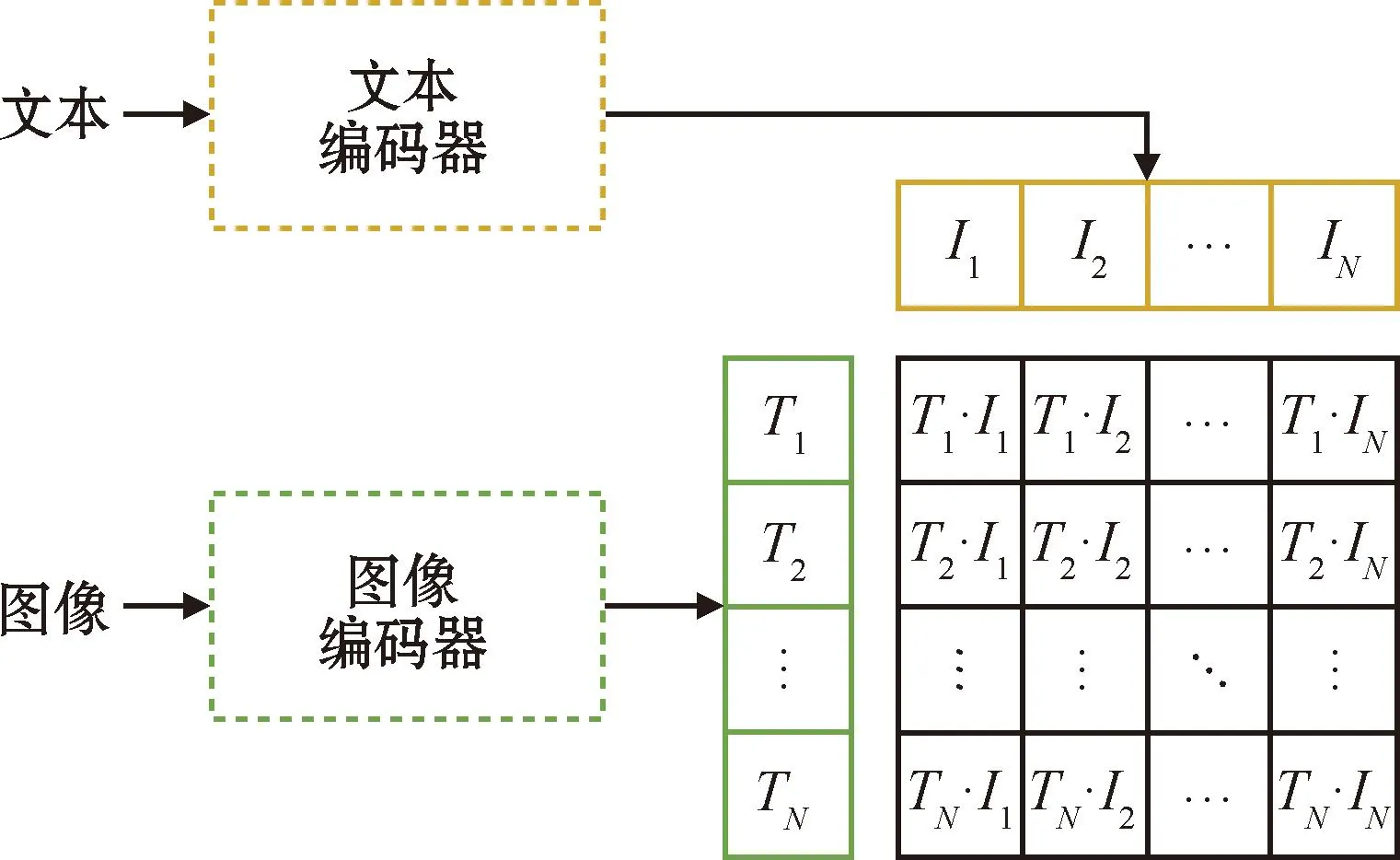
图4 CLIP结构简图Fig.4 Structure of CLIP
2.2.2 文本提示优化
考虑到Stable Diffusion对输入的文本提示有严格的格式要求,对于随意输入文本生成的图像,达不到预期的生成视觉效果与质量。因此,本文选择利用大语言模型ChatGPT对文本提示进行优化,使其完全符合Stable Diffusion的输入规范。优化操作的引入,确保文本提示的规范性和准确性,让模型能够更精确地理解用户意图,从而生成更具质量的图像。
2.3 合成图生成模块
合成图生成模块在图像生成过程中综合了多重信息输入,包括:原始图像作为引导生成过程的视觉图像基础;经过图像分割模块得到的掩码图,用于精确定位前景物体区域;利用Depth_Midas处理器得到的深度图,提供先验空间分布信息;结合了图像和文本的提示信息微调生成图像。
具体来说,该模块采用生成式模型Stable Diffusion实现,能够有效融合多模态的引导信息,并生成符合约束条件的高质量图像。在生成过程中,Stable Diffusion结合了不同需求,实现多源数据充分结合,能够生成既符合预期又灵活多样的图像预测集合。
3 实验
3.1 实验设置
本文使用标准Stable Diffusion模型和ControlNet架构,具体参数设置如表1和表2所示。实验环境配置如下:CPU为Intel (R) Xeon (R) Gold 6154 CPU @ 3.00 GHz,GPU为NVIDIA GeForce 3090,显存为24 GB,操作系统为基于 Liux 内核的 Ubuntu 5.4.0-164-generic,编程语言为Python 3.10,深度学习框架为Pytorch。

表1 Stable Diffusion部分参数设置Table 1 Parameter settings for Stable Diffusion

表2 ControlNet部分参数设置Table 2 Parameter settings for ControlNet
3.2 实验结果
图5所示为采用本文的图像合成系统对3个产品进行生成的结果示例,每个示例均包含输入原图、参考图及最终的生成图像。

图5 采用本文的图像合成系统生成的结果示例Fig.5 Examples of generated results using our image composition system
从图5可以看出,生成的图像中,前景物体能够被完整地保留并融合到生成的背景图中,不存在缝隙、错位等情况,同时生成的背景图像与参考图像一致且根据具体情况进行了细节调整与修改。
接下来,我们将对提出的系统中的不同模块进行详细结果展示与分析。
3.2.1 逆向文本提示
逆向文本提示对生成效果的影响如图6所示,其中逆向文本提示是指利用参考图像得到的文本提示;通用文本提示是图片生成式任务中常用的提示内容,如“高画质”“高分辨率”等词语。从结果中可以看出,逆向文本提示生成的图像更加美观,且没有杂物和异常阴影出现。由于逆向提示充分,内容包含了对参考图中的物品以及颜色的准确描述,对图像生成进行了更细粒度和严格的文字约束,因此其生成的图像更接近参考图。而使用一些通用的文本提示,并不能对生成图片的质量提供帮助。

图6 逆向文本提示对生成效果的影响Fig.6 The impact of reverse text prompts on the generation effect
3.2.2 图像提示
深度图对生成效果的影响如图7所示。可以看出,在未使用深度图的情况下,背景中出现大量多余杂物且物体位置凌乱,严重影响图片观感。而添加深度图后的生成结果,不仅画面元素与参考图像高度相似,而且物体分布美观。有效证明了参考图为模型提供了可参考的信息,指导图像生成在更有力的约束下进行,结果更加符合用户审美与预期。

图7 深度图对生成效果的影响Fig.7 The impact of depth maps on the generation effect
4 结束语
针对电子商务领域,本文提出了一种商品图像合成任务的解决范式。在使用 Stable Diffusion 平台的基础上,利用 CLIP、ControlNet、ChatGPT等算法和工具来对图像生成的效果进行优化。引入了图像提示模块,利用掩码图和深度图引导图像合成,实现了对图像主体和背景边界的优化;引入了文本提示生成模块,实现了部分提示词的自动书写以及对全部提示词的优化。从消融实验的结果可以看出,本文设计的多模态引导图像合成系统显著提升了图像生成的效果,能够有效生成前后景一致的图像,有利于图像生成技术在各个领域内的推广和应用,具备一定的实用价值。
