基于宽度和深度模型以及残差网络的综合能源负荷短期预测
2023-12-18罗东晖李鹏程臧向迪张文昕祝晋尧严敬汝
栗 然, 罗东晖, 李鹏程, 臧向迪, 张文昕, 祝晋尧, 严敬汝, 回 旭
(1.华北电力大学 电气与电子工程学院,河北 保定 071003;2.国网宁波供电公司,浙江 宁波 315010;3.国网河北省电力有限公司电力科学研究院,河北 石家庄 050021;4.国网保定供电公司,河北 保定 071000)
0 引 言
快速的经济发展和物质需求导致煤炭资源趋于紧张,过去粗放式能源消费和污染排放也将导致环境恶化和气候变化[1]。为实现资源整合和多种能源的高效利用,综合能源系统(Integrated Energy System, IES)的概念应运而生。IES从空间尺度上可分为跨区级、区域级和用户级,用户级规模较小、负荷波动较大,准确的负荷预测方法对电网规划和安全运行十分关键[2]。
随着计算机算力的不断提升,深度神经网络在预测领域的运用越来越广泛,诸如LSTM、卷积神经网络 (Convolutional Neural Networks, CNN)等神经网络在负荷预测方面有着十分出色的表现[4-11]。部分文献将原始数据分解为多个子序列并进行分类,针对不同种类的子负荷采用对应的预测手段,再将各类子序列预测结果相加从而得到最终的预测值,常见的负荷分解手段有EMD和小波分解方法[12,13],文献[14]采用对高次子序列2次分解的方法降低了其复杂度,解决了高次子序列强非平稳导致的预测精度差的问题,以上文献均有负荷分解-预测-重构过程,重构过程难免会发生误差的累加从而导致模型健壮性变差。文献[15]利用主成分分析(PCA)对模态分解得到的模态分量进行降维剔除冗余后利用LSTM进行预测,但是剔除部分数据难免会造成信息的缺失导致精度下降。
IES负荷预测相较于传统单负荷预测的主要区别在于IES存在多种负荷相互耦合的情况,如何利用多元负荷之间的耦合关系提升预测精度是一大研究方向,文献[16]采取深度置信网络进行特征提取再采用多任务回归进行负荷预测。文献[17]采用多任务学习将LSTM网络作为共享层并行对冷、热、电负荷预测模型进行训练,实现对负荷之间的耦合信息的利用。文献[18]采用CNN多通道卷积和负荷像素重构方法,同时提取了异种负荷之间以及负荷在空间上的耦合特征,将这些特征输入LSTM中,获得了良好的预测效果。
部分文献将较新的机器学习架构引入到负荷预测中,文献[19]将Google发布的Wide&Deep模型修改后应用于负荷预测,文中将Wide部分由深度神经网络替代,Deep部分由LSTM替换,将负荷的时间特征作为Wide部分的输入,将负荷时间序列作为Deep部分输入。文献[20]在文献[19]的基础上,将Deep部分结构改进为LSTM和XGBOOST融合模型,并且将特征进行交叉组合获得新特征作为Deep部分的输入。以上两种模型Wide部分均用来寻求时间特征与负荷之间的关系,但是时间特征与负荷之间的关联较弱,通过深度神经网络获取的特征十分有限,耗费计算机算力的同时对预测精度的提升不大。并且时间特征经由深度神经网络处理后无法完全剔除无关信息,引入噪声会使最终的预测误差增大。以上LSTM模型皆为浅层模型,对深层时序特征提取能力较弱。
综上,为了解决冷、热、电3种负荷之间关联信息难以提取的难题,首先将3种负荷进行CEEMDAN分解得到多个IMF分量,分解后的分量相较于原数据复杂性更低,降低了关联信息提取的难度。但得到的IMF分量仍具有大量的冗余信息,因此采用PCA将IMF分量进行主成分提取和信息密度排序;其次构造参考传统深度ResNet网络结构并构建深度ResNet-LSTM网络。为了充分利用不同信息密度的信号,将信号根据信息密度从大到小依次输入深度ResNet-LSTM网络,此为整个模型的Deep部分。随着网络加深,模型不可避免的会出现训练缓慢的问题,最后为了提高模型的训练速度添加Wide部分,并在传统Wide&Deep-LSTM模型的基础上,改进Wide部分的输入。由实验结果可知所提出的模型具有良好的收敛速度和预测精度。
1 完整集成经验模态分解
完整集成经验模态分解(CEEMDAN)是一种在经验模态分解(EMD)之上发展起来的信号分解方法。EMD方法与传统的小波分解和傅里叶分解不同,该方法无需事先设定基函数,而是根据信号本身的时域局部特征,将复杂的数据分解成有限的、通常是少量的几个本征模函数(intrinsic mode functions, IMF),因此该方法对非平稳非线性信号的分解具有较好效果。完整集成经验模态分解在EMD的基础上对原信号加入自适应、零均值、固定方差的白噪声改变原有信号的极值分布,解决了EMD方法处理间隔信号和噪音信号时出现的模态混叠问题[12]。
2 主成分分析
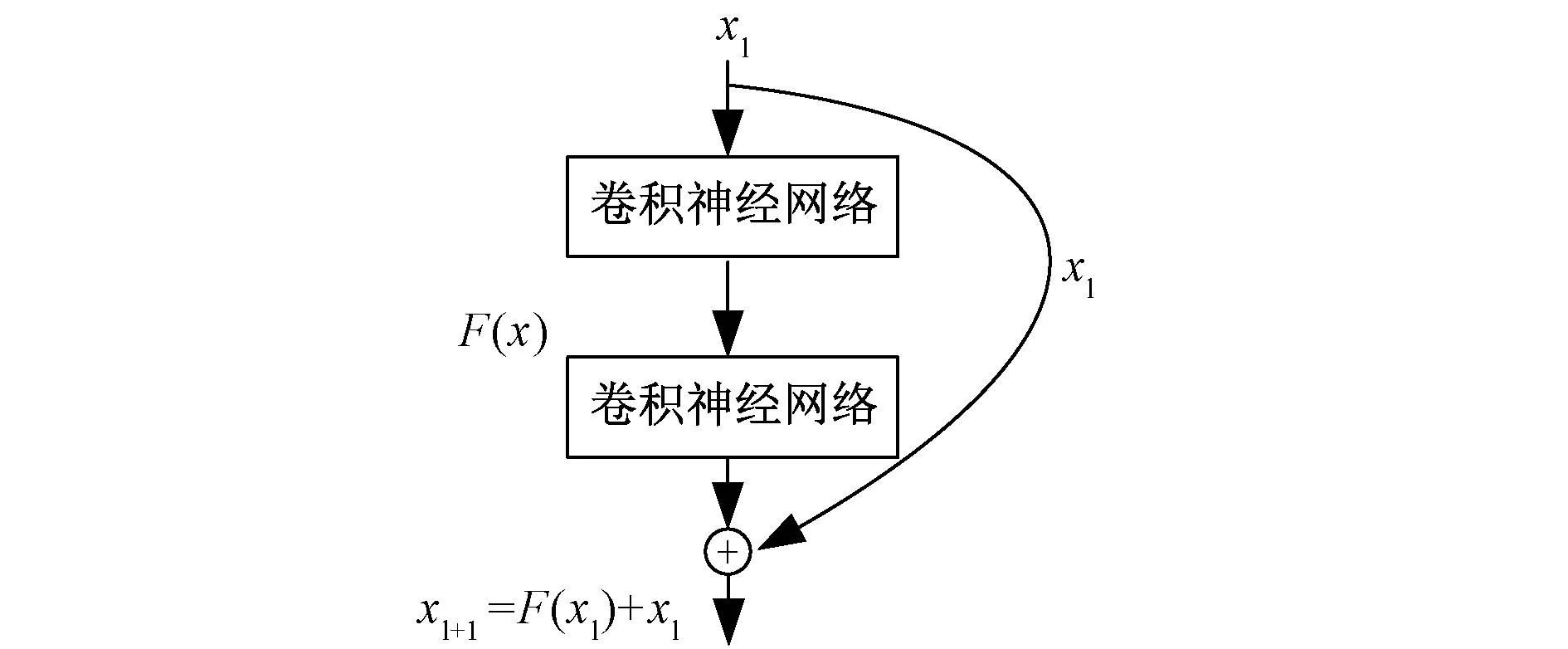
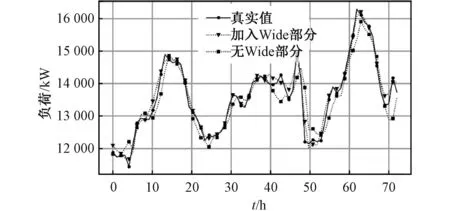
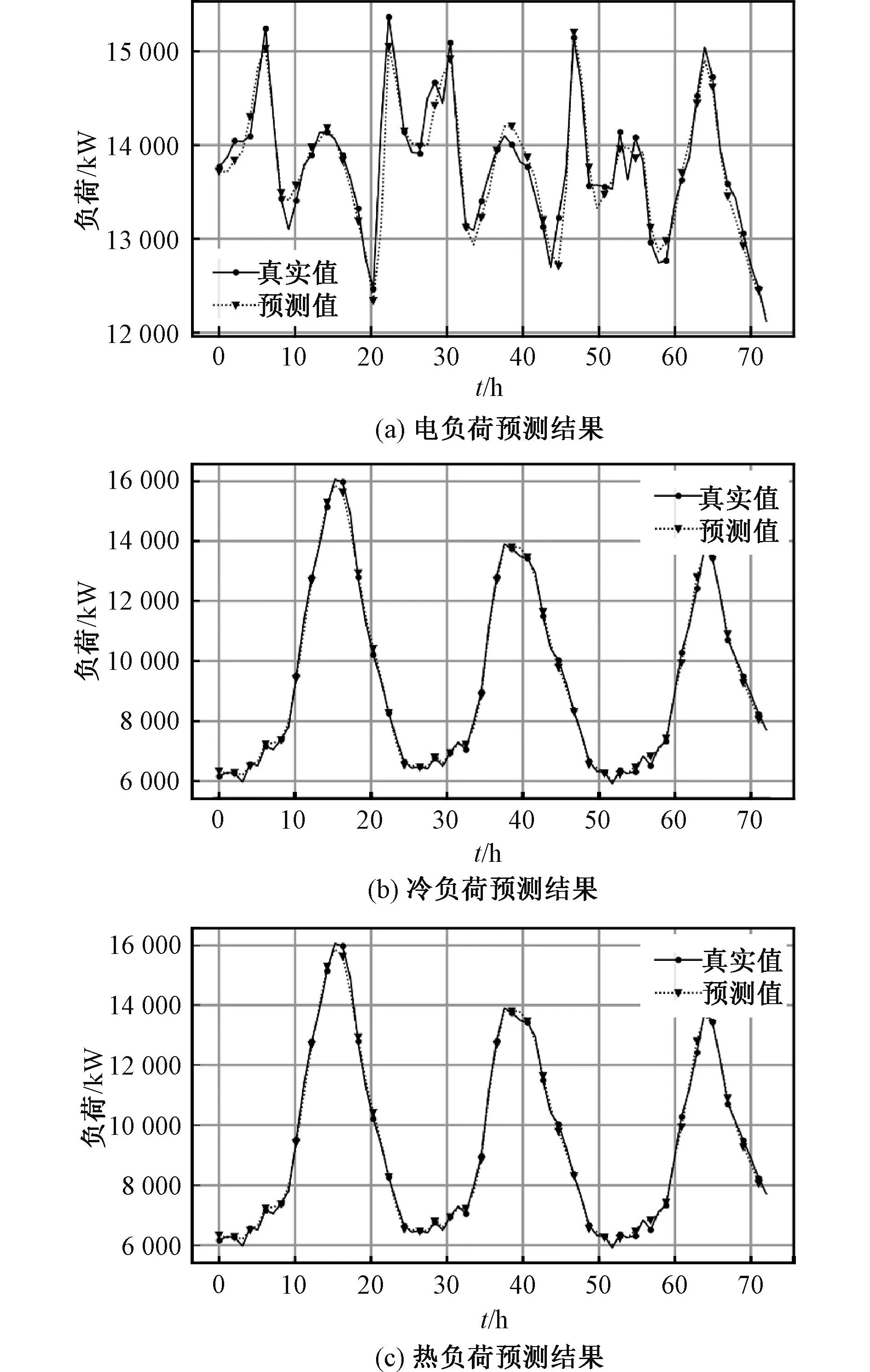
主成分分析是一种数据降维方法,通过将n维数据数据映射到n个正交的坐标轴上,实现映射到前几个坐标轴上的维度特征方差最大,最后的几个坐标轴包含的数据方差几乎为零。由于可以认为方差越大的数据所含的信息越多,因此通过舍弃方差较少的数据只保留前面k(k 长短期神经网络(LSTM)相较于传统循环神经网络引入了“门”结构,通过采用“遗忘门”让神经网络“忘记”之前没有用过的信息;采用“输入门”根据当前的输入补充最新的记忆;采用“输出门”根据最新的状态、上一时刻的输出和当前的输入来决定输出,以上结构有效解决了传统循环神经网络存在的长期依赖问题。 残差网络(ResNet)于2015年由何凯明在论文[21]中提出,其思想是让网络中的每一层进行残差映射而不是直接进行底层映射,该论文提出在底层映射假设为H(x)的情况下使堆叠的非线性层拟合残差映射F(x)=H(x)-x而不是对直接对底层映射进行拟合,这样就变成了对F(x)+x的映射,从而可以获得更好的拟合效果以及训练效果。具体的网络构造方法是将当前网络的输入和当前的输出进行拼接作为下一层新的网络的输入从而得到一个更深的神经网络,最差的情况是当前网络不起任何作用直接将输入数据进行输出即残差为零,这样即使结果不能变的更好但也不会变得更差,从而解决了神经网络层数增加反而导致精度反常下降的难题。一个残差模块的定义如图1所示,而更复杂的残差网络由多个残差子模块堆叠构成。 图1 典型残差网络模块示意图Fig. 1 Classic ResNet schematic diagram 传统的LSTM网络由于存在层间梯度消失、网络退化等问题往往无法搭建得过深[22],一般以2到3层最为常见。为了加深网络提升特征提取能力,本模型将传统ResNet中的CNN替换为LSTM,提出一种深层ResNet-LSTM网络。并且考虑到不同方差的数据所含的信息量不同,根据信息量的高低进行梯度输入。以3个模块堆叠为例,信息量最高的数据从模块1输入,其余数据随着信息量递减分别由模块2、3输入,模型结构如图2所示。这样信息量高的数据相较于低信息量数据可以通过更深的网络从而提取到更多的特征且降低了运算量。在单个模块层数的选择上,考虑到过深的LSTM存在梯度消失的问题,本模型将层数定为2层。 图2 深度ResNet-LSTM模型结构Fig. 2 Deep ResNet-LSTM model structure Wide&Deep模型是谷歌于2016年提出一类用于分类和回归的模型,模型由线性的Wide和非线性Deep两部分构成,使其同时具备对出现过特征的记忆能力和未出现过特征的泛化能力[19]。 文献[19]、[20]将深度部分网络替换为浅层LSTM,将宽度部分网络替换为全连接层,输入替换时间信息和天气信息,使得模型可以用于负荷预测。在此基础上,本文将深度部分的LSTM网络替换为深度ResNet-LSTM网络,使之对更深的信息具有更强的提取能力;宽度模型的输入部分加入临近时(前3个小时,即t-1、t-2、t-3时刻)和临近日(前3天该时刻,即t-24、t-48、t-72时刻)的负荷数据,这些负荷量与目标负荷量之间的相关性极高[18],可以进行快速且具有一定精度的预测,宽度模型的快速预测减少了深度部分的预测量,这使得整个模型训练速度更快。改进后的模型结构如图3所示。 图3 Wide&Deep-ResNet模型结构Fig. 3 Wide&Deep-ResNet model structure 将数据分为训练集、测试集,训练集输入模型对权重进行训练和优化,以预测t时刻电负荷为例,训练步骤如下: (1)将临近时(前3个小时,即t-1、t-2、t-3时刻)和临近日(前3天该时刻,即t-24、t-48、t-72时刻)的电负荷数据以及天气信息和时间信息作为Wide部分输入。 (2)将前144 h的冷、热、电负荷数据(即t-144,t-133, …,t-1时刻)进行CEEMDAN模态分解,将分解获得的若干数量的IMF分量进行PCA处理,根据方差大小将得到的数据进行排列并分为3组。 (3)搭建3模块堆叠ResNet-LSTM网络,将方差最大的第1组数据输入第1层子模块,第2组数据输入第2层子模块,方差最小的第3组数据输入第3层子模块。 (4)将Wide部分和Deep部分的输出进行拼接输入输出层得到模型输出,并根据评价指标优化模型。 最后再利用最优模型进行预测并输出预测结果。模型搭建流程如图4所示。 图4 模型搭建流程Fig. 4 Flow chart of building of model 实验数据来源于美国亚利桑那州立大学的CAMPUS METABOLISM项目,项目网站记录了亚利桑那州立大学4个校区去年年初至今的全天24 h负荷使用情况。选取了坦佩校区2020年全年(2020年1月1日至2020年12月31日)冷、热、电负荷情况作为实验数据,时间分辨率为1 h,按照80%和20%的比例划分训练集和测试集。 由于各种原因原始数据中一般存在异常数据,异常数据的存在会影响正常的分析结果因此需要对异常数据进行剔除。采用箱形图对异常数据进行筛选,并对筛选出来的异常数据采用K近邻算法(K-Nearest Neighbor)进行均值替代。冷、热、电负荷数据在大小上存在明显的大小关系,对数据进行归一化可以降低模型的训练难度,归一化公式如(1)所示。 (1) 对冷、热、电负荷做皮尔森相关性分析,相关系数绝对值表1所示。相关系数0.6~0.8为强相关、0.8~1.0为极强相关。可见3种负荷之间存在强相关性。 表1 冷、热、电负荷Pearson相关系数 将归一化后的时间序列做CEEMDAN处理,分解为频率从高到底排列的若干个本征模态函数(IMF)和残差(Res),对电、冷、热负荷进行分级后可得到32个IMF分量。将所得的IMF分量进行PCA处理得到32个维度特征,根据这些维度特征的方差大小分为3组,本文参考文献[23-25]的阈值选取方法,将数据分组阈值确定为95%,即将方差贡献率为95%的前若干个维度特征归类为第1组,对剩余的特征同样以95%为阈值再进行一次分组,得到第2组以及第3组数据,具体的分组情况如图5所示。 图5 维度特征分组情况Fig. 5 Dimension feature grouping station 为全面分析所选方法的有效性,选择以下2个指标来评估模型的性能,分别是平均百分比误差(Mean Absolute Percentage Error, MAPE)和均方根误差(Root Mean Squared Error, RMSE),计算公式如下。 (2) (3) 基于Wide&Deep-ResNet-LSTM方法的负荷预测工作在TensorFlow框架下展开,实验室硬件配置如下:CPU:Intel(R) Core(TM) i5-8265U CPU @ 1.60G Hz 1.80 GHz、内存:8 G、GPU:Nvidia GeForce MX250。 模型由Deep和Wide两部分组成,两部分结构分别为深度ResNet-LSTM网络和全连接层,其中神经元数量待确定。网络输入为待预测点前144 h数据,因此TIMESTEPS设为144。为防止出现过拟合情况,在训练过程中采取dropout操作,保留概率参数keep_prob=0.7,batch_size=32。 模型采用ADAM(Adaptive Moment Estimation)优化算法,公式如下: (4) 损失函数为均方误差(Mean Squared Error, MSE),公式如下: (5) 单个残差模块中神经元个数越多,模型对特征的提取能力也就越强,但是同时也会增加每轮训练所需的时间、降低模型的收敛能力。图6展示了模型在不同神经元数量下训练样本在前100轮训练中的均方误差变化的过程。其中图(a)表示改变残差模块中神经元数量(分别为128、64、32、16、8,全连接层神经元数量保持为(32,16,1))后模型收敛过程,图(b)表示改变全连接层神经元数量(分别为(32,16,1)、(64,32,1)、(128,64,1),残差模块神经元数量保持为8)后模型收敛过程。可见,本文所提模型具有良好的收敛性,并且参数变化对模型收敛性影响较小。 图6 模型收敛过程Fig. 6 Convergence process of model 神经元数量越多,模型的拟合能力往往越强,训练所需的时间也随之增加,神经元数量需要结合模型的预测精度和训练时间进行综合确定。改变残差模块和全连接层神经元数量后模型的预测精度以及收敛时间如表2、表3所示。 表2 改变残差模块神经元数量的预测结果 表3 改变全连接层神经元数量的预测结果 观察表2数据可知,随着神经元数量的增加,预测精度不断上升,迭代轮数不断下降;但是由于单次迭代所需的时间增加,训练总时间在神经元数量为32时达到最小然后不断上升,观察到32神经元后再增加神经元数量对精度提升不明显,因此综合考虑后将残差模块中的神经元数量确定为32个。观察表3数据可知,增加全连接层神经元数量对模型预测精度和收敛速度影响较小,本文确定全连接层神经元数量为(32,16,1)。 最终模型超参数如表4所示。 表4 模型超参数设置 为验证所提Wide&Deep-LSTM中Wide部分的有效性,设置3类模型,模型1采用LSTM模型;模型2采用Wide&Deep模型,Wide部分输入时间特征和天气信息,Deep部分为LSTM;模型3采用Wide&Deep模型,Wide部分在模型2的基础上加入临近日和临近时负荷数据,Deep部分与模型2相同。 以电负荷为例,3类模型迭代收敛过程如图7所示,3组实验训练效果如表5所示。 表5 不同Wide输入训练结果 图7 不同Wide输入收敛过程Fig. 7 Convergence process of different Wide-part input 由实验结果可知,模型3相较于其余两个模型收敛过程更加稳定,在花费最少迭代次数的同时取得了最小的RMSE值。模型2的RMSE值则居于另外两个模型之间,迭代次数与模型1相同,所花费的训练时间最长。实验表明模型3相较于其他模型拥有更好的收敛速度,这是因为:强相关数据经由Wide部分进行一次快速简单预测后再输入Deep部分,减少了Deep部分的工作量。并且由于Wide部分结构简单,模型复杂度增加不大,总体上对模型收敛起到了加速作用。 为了探究Wide部分对最终预测精度的影响,继续对让模型1与模型3进行训练,最终两种模型的MAPE值分别为1.26%、1.19%,RMSE分别为238.30 kW、217.82 kW,可见加入Wide部分后负荷预测精度有进一步的提升。预测结果如图8所示。 图8 负荷预测结果Fig. 8 Result of load forecasting 为了分析Deep部分结构对实验结果的影响,设计了多个模型进行对比,各个模型Deep部分结构以及输入如表6所示。 表6 Deep部分运行方式比较 所有模型均含有Wide部分,Wide部分输入为临近日、临近时以及天气、日期信息。训练结果如表7所示。 表7 不同模型结果比较 过横向对比可知,电负荷的预测精度在3种负荷中是最低的,热负荷次之,而冷负荷的预测精度最高。这是由于电负荷相较于冷、热负荷波动更为迅速且存在更多的不确定性,而热负荷相较于冷负荷容量较小导致其波动相较于冷负荷更为剧烈,这导致3种负荷种电负荷的预测难度最高,热负荷次之,冷负荷最低。 观察模型1、3、4的结果,模型3与模型4模型结构相同,区别在于模型3的输入为单种负荷数据而模型4为3种负荷,结果上模型4电、冷、热3种负荷(下文不做说明均按电、冷、热顺序排列)的MAPE值相较于模型3分别降低了11.2%、4%、2.9%,而RMSE值也有所下降,这说明模型可以提取到多种负荷之间的耦合特征,从而提升预测精度。模型1在模型4的基础上对负荷数据进行了CEEMAN和PCA处理,MAPE值在模型4的结果上再次降低了35%、56%、38%,并且在训练时间上也降低了57%、38%、55%,这是因为数据经过处理后相较原始数据虽然在维度上有所上升,但是每个维度的数据却变得更加简单,降低了复杂特征的提取难度,从而使得模型可以更好地提取负荷间的耦合特征。 观察模型1、2、7的结果,模型2在模型1的基础上增加了LSTM的深度,但是预测结果反而变得更差,MAPE值分别上升了3.3%、6.8%、10.8%,训练时间则增加了169%、50%、161%,这是由于单纯的增加网络深度并不能保证提升模型的精度,增加层数为模型带来更高拟合能力的同时也带来了参数过多难以优化、梯度消失、网络退化[22,23]等问题,这些问题的出现反而会使精度下降,而随之而来的网络参数的增加使得训练时间大大增加。模型7在模型2的基础上将7层LSTM模型替换为等深度的ResNet-LSTM模型,由结果可知,模型7相较于模型2的3种负荷的MAPE值分别下降了7.3%、2.9%、9.8%,RMSE值分别下降了16.09 kW、8.56 kW、0.05 kW,相较于模型1在电、热负荷的预测精度上均有所提升。这说明RseNet-LSTM模型可以有效解决网络加深时产生的网络退化问题。同时更深的网络可以提取到深层次的特征,从而提高最终的预测精度,这点在相对最复杂的电负荷预测上体现的最明显。观察模型3、4、5、6的结果,模型5、6分别在模型3、4的基础上利用RseNet-LSTM模型加深了模型深度,均在电负荷以及热负荷上取得了更高的预测精度,该结果同样说明了利用ResNet-LSTM增加网络深度的有效性。 观察模型7、8的结果,模型8相较于模型7在MAPE值上降低了4.3%、3.0%、1.2%,RMSE值降低了6.37 kW、1.36 kW、0.03 kW,在训练时间上则分别降低了0.1 h、0.06 h、0.03 h,这是因为通过将数据在不同的深度输入模型,一方面减少了深层网络处理数据的量,从而加快了训练速度,另一方面也减少了无用信息的产生,更少的无用信息可以让模型算力更加集中,从而提高了预测精度。 模型8对3种负荷连续72 h(2021年1月1日~2021年1月3日)的预测结果如图9所示。 图9 用户级IES负荷预测结果Fig. 9 Result of user level IES load forecasting 为了充分挖掘冷、热、电负荷之间的关联特征以提高负荷预测的精度,提出了一种基于Wide&Deep-ResNet框架采用CEEMDAN和PCA的综合能源系统负荷短期预测模型。主要得出如下结论: (1)本文通过改进Wide&Deep模型中Wide部分输入可以有效简化收敛过程从而减少训练时间并且提高预测精度。 (2)通过将负荷数据CEEMDAN、PCA处理后按照方差大小分批梯度输入本文所提深度ResNet-LSTM模型再进行预测可以有效获得负荷中和负荷间蕴含的深层信息,提升预测精度以及训练速度。 (3)所提模型对电、热负荷有较好的预测效果,而对冷负荷预测效果则相对一般,可能的原因如下: ①冷负荷本身预测难度低,因而加深网络对预测精度提升效果不明显,反而网络参数的增多更容易产生过拟合; ②ResNet神经网络在实际应用中不能完全消除网络退化造成的负面影响。3 模型搭建
3.1 长短期神经网络
3.2 ResNet-LSTM模型

3.3 Wide&Deep-LSTM改进模型

3.4 用户级IES负荷预测流程

4 数据处理
4.1 数据介绍
4.2 数据预处理

4.3 CEEMDAN以及PCA处理


4.4 基本评价指标

4.5 模型超参数设置
5 结果分析
5.1 模型收敛性分析




5.2 不同Wide部分输入分析


5.3 Deep部分结构与输入对比分析


6 结 论
