新工科背景下基于数据挖掘的学习轨迹分析
2023-12-04陈璐琳
沈 江, 陈璐琳, 潘 婷, 安 邦, 徐 曼
(1. 天津大学管理与经济学部, 天津 300072; 2. 南开大学商学院, 天津 300071)
新工科学科建设注重学科交叉和课程整合,加强自然、工程、人文等多学科的全面整合和相互融合[1],要求从教育理念、专业结构、人才培养模式以及分类发展体系进行创新和改革,以实现教育教学质量的全面提高[2],并且要求课程教学能够以学生为中心,从多个维度对学生的学习成果进行评价[3]。因此,教师需要从课程架构、课程内容以及教学模式等方面进行探索和改革。尤其是需要创新课程的表现力和应用性,实现课程教学从讲授中心课堂到学习中心课堂的转变、从授课中心课堂到需求中心课堂的转变[1]。
为实现上述目标,在新工科背景下,提出“需求导向性、结构自适应、内容模块化嵌入”为主的新教学模式。在课程的开始阶段建立学生个人和群体的数字画像,在教学过程中建立学生的学习轨迹,根据学生的学习进程适用不同的教学模块,并嵌入到教学过程中,实现以学习和需求为中心的新工科教学课堂。其中的关键环节在于教师如何及时对学生的学习进展进行分析和评估,以针对性地采取相应的教学措施。从而实现教师和学生之间的良性互动,以帮助教师及时发现在教学过程中可能存在的问题[4],提高学生学习阶段结果反馈与改进跟踪的自动化、智能化与人性化水平[5]。
学生学习轨迹分析是当前新工科教学方法的重要探索之一,指在教学过程中通过对不同教学阶段中学生的学习进展进行分析,以了解学生学习的变化趋势,能够描述学生习得的知识由少增多、由浅入深的过程。通过这一方法,能够帮助教师更好地理解学生的学习进展,从而实现学业预警、个性化教学、自适应学习以及学习资源的推荐[6-7]。同时也可以从增量角度对学生的学习进展进行评估。
随着“互联网+”时代的来临和大数据技术的发展,在线下教学过程中恰当的使用线上教学工具,通过建立线上教学平台实现线上线下融合式教学模式[8],为学生的学习轨迹记录、分析和评估提供了便利。在线教学工具的使用过程中,学生会在其中留下学习痕迹,借助数据挖掘工具,教师能够了解学生的学习状况,并对学生的学习过程做出干预[9-10]。在这一背景下,文章构建了一个基于预测模型的学生学习轨迹分析框架,帮助教师对学生的学习进展进行分析和评估,以提高教学质量,为培养未来多元化、创新型卓越工程人才提供坚实基础。
一、 文献综述
1. 基于数据挖掘的学习成绩预测
对学生学习轨迹进行分析的前提是能够及时、准确地了解学生的学习进展。传统方法是通过构建学生学习特征和学习进展之间的因果关系模型,对学生的学习情况进行分析和预测。学生学习轨迹分析通过阶段性对学生的综合表现进行成绩预测,然后根据预测结果对个别表现可能较差的同学进行干预,进而提高学生的整体表现[11]。相关的成绩预测研究多借助于多元线性回归的方法,尽管能够较好地分析变量和结果之间的因果关系,但是往往也面临预测结果准确率较低的困难[8,10,12]。
近年来,更多的学者采用基于机器学习或者深度学习的方法来提高学生学习成绩预测的准确性,例如贝叶斯方法[13-14]、最近邻方法[15]、神经网络[16-18]、支持向量机[18]以及深度学习[19-20]等方法。为进一步提高预测准确性,在崔立志等[20]的研究中,借助了例如学生的家庭背景等人口统计学信息,但是上述信息涉及学生个人隐私,在大部分的课程中并不适用。另一个导致预测模型结果不尽人意的原因在于缺少学生前期数据。为解决这一问题,多数学者采取协同预测的方法以提高预测准确率。陈曦等[21]将知识图谱和协调过滤的方法应用于学生的学习成绩预测中,以解决学生成绩预测数据不足的情况,但是这要求教师能够了解学生其余课程的信息,在单个课程中实施存在一定的困难。
由于在大部分的高校中,教师会长期负责某一课程的教学工作,因此通过历史的教学数据帮助提高预测模型的效果是可行的。但是由于个体的不同,学生的个性化特征对于预测结果的影响难以估计。采用多个基础的预测模型进行集成被认为是帮助提高学生表现预测准确率的有效途径[22]。集成模型的目的在于尽可能地降低不确定性所带来的影响。Adaboost方法是一种有效的集成方法,并且在学生学习成绩预测的应用中取得了比较好的结果[23]。本文在现有Adaboost方法的基础上进行了一定的改进,以提高对大多数学生预测的准确性。
2. 影响学生学习成绩的特征分析
研究表明,学生的初期能力、对课程学习的认知以及课程的参与程度都会直接影响学生的学习成绩[11]。学生的初期能力是影响学生学习成绩的重要因素。一般来说,学生在基础课程中取得的成绩以及在课程学习过程中的成绩都可以作为衡量学生初期能力的标准[12,24]。
学生对课程学习的认知则主要表现为学生对学习的兴趣或者学习态度[12,25]。对课程学习充满兴趣的学生会更容易取得较好的成绩。课程参与度代表了学生在课程学习过程中所付出的努力。研究表明积极地参与到课程当中是学生取得良好成绩的关键[12]。学生的在线活动也被认为和学生的学习表现之间有显著的关系[6],例如学生参与课程讨论、课程学习以及课程测验的次数等都会对学生的学习效果产生影响[8]。
当前,大部分研究对学生的参与程度评价集中在学生的任务性行为,例如学习课程、参与测验以及在线时间等[8,26]。而在教学过程中,教师可以通过创新教学模式帮助学生更好地参与到学习当中,例如通过设计多元化的教学场景,在教学中引入场景化教学,促使实现多元教学,帮助实现学习和实践的结合,通过开展开放式、多向度的理论与实践互动实践新工科建设[27]。案例分析和分组讨论也是当前教学模式中的常见环节,因此学生课程中不同学习场景的参与度也应当被考虑到。
尽管一些研究也表明例如社会、家庭、学校环境等外部环境因素,学生的学习动机、性格构成、情感情绪等内在特质以及生活行为表现也会对学生的学习成绩产生影响[21]。但是基于信息获取的成本以及这些因素在大部分课程中并不适用,为此本文结合在线教学过程和教学改革中的特色教学模式,采用必修课平均分、选修课平均分、先导课测试成绩来表示学生的初期能力,并随着课程的进展,加入过程中的测验成绩和上一期的预测成绩。学生在课程中的参与次数、在线活动参与次数、是否选择优先参与场景化教学活动、案例分析回答次数以及团队展示得分等用来反映学生的积极性以及课程参与度。
二、 基于数据挖掘的学生学习轨迹分析
1. 分析框架
基于数据挖掘的学生学习轨迹分析由3个主要部分构成:数据获取、成绩预测和教师干预。
第一步,借助雨课堂、慕课以及UMU等在线学习工具,教师鼓励学生在课程教学过程中通过在线工具实时发言,同时利用在线教学工具对学生学习活动以及学生和教师的互动过程进行记录。并且对上述数据进行处理,录入到预测模型中。
第二步,在初始的模型中根据学生在课程中初期测试的结果,对预测模型进行训练。并随着课程的发展,对预测模型进行不断地更新和迭代。
第三步,预测模型对学生当前可能的学习成绩进行预测,输入学生必修课平均分、选修课平均分、先导课测试成绩、课堂测试成绩、课程参与次数、在线活动参与次数、是否选择优先参与场景化教学活动、案例分析回答次数以及团队展示得分等。其中在课程开始阶段,学生的初期能力为先导课成绩或者初期测试的成绩以及必修课平均分和选修课平均分,在后续的课程中则采用上一次的预测成绩或者临近一次的课程测试成绩作为输入。同时模型输出学生当前阶段的学习成绩预估。
第四步,将学生预测成绩结果绘制成图表形式,并构建学生学习成绩的轨迹曲线,根据学生学习轨迹的发展趋势,对教学过程中存在的问题进行分析并及时干预。同时学生的学习轨迹曲线也能够反映学生在学习过程中的增量变化过程。
2. 基于Adaboost方法的学生成绩预测
Adaboost方法是一种自适应的集成算法,通过对样本不断进行迭代来构建多个预测模型,并将不同模型的结果进行加权求和来得到最终的预测结果。一般来说,Adaboost方法在迭代过程中降低预测结果正确的样本的权重,提高预测错误样本的权重,以及提高对奇异样本预测的准确率。根据重新采样后的样本构建下一个模型,在完成迭代后根据预测模型的误差自适应地调节各个预测模型的权重。其中给予误差率更低的模型更高的权重,最后根据各预测模型的权重和结果得到最终的预测结果[28]。Adaboost算法的具体过程如下。
第一步,构建由N个学生样本构成的初始训练集{(X1,y1),…,(XN,yN)},其中Xi表示学生i在在线课程中的课堂特征的集合,yi表示学生i的期末成绩。Xi={x1,…,xm}表示学生i在线课程中的m个特征,用于评估学生在在线课程中的表现。初始训练集均匀的包括全部的学生样本,用表示在初始情况下学生样本i的分布概率,则
第二步,将训练集输入到回归模型中,得到预测模型rt。对训练集在预测模型rt上的误差进行计算:
在这里采用了绝对误差的立方来表示样本误差,目的是增加预测误差带来的影响。预测模型rt的总误差可以表示为:
对预测模型rt分配权重:
进一步更新样本分布的概率:
其中Zt表示归一化系数,在此步骤中对基本的Adaboost模型做出了调整,在Adaboost中:
其目的在于提高误差较高的样本在模型中的占比,以避免在训练集中发生过拟合。但是由于学生成绩预测的不确定性较高,很难准确和全面的掌握所有影响因素,因此在调整后的Adaboost方法中迭代的目的是增加误差较低样本的占比,因为这些样本受到不确定性因素的影响更小。
第三步,在T轮迭代后停止迭代,对wt进行归一化处理得到预测模型rt的归一化权重ηt,并得到最终的预测结果:
三、 模型验证及结果分析
1. 数据来源和特征
本研究选取某高校智慧城市相关课程的两个年级的学生学习情况为实验数据,实验数据来源于在线教学过程中记录的167名学生的学习活动记录,在第一个年级学生的课程中,特征的统计性描述结果如表1所示。
由表1可知,必修课平均分数值分布在52至99分之间,平均分为77.27分。选修课平均分分布在60至99分之间,平均分为79.56分。先导课成绩分布在69.50至82.30分之间,其中占比最大的得分区间为(72.50,75.50],平均得分为76.34分,一般来说,学生成绩的等级划分成[90,100]为优秀,[80,90)为良好,[70,80)为中等,[60,70)为及格,低于60分为不及格。因此学生的初始水平多处于中等和良好水平,通过课程学习可以有一个明显的提升。根据参与课程次数的统计,发现75%的学生能够参与全部课程,20%的学生有一次缺席,5%的学生有两次缺席。44%的学生在场景化教学中显示出较高的积极性,剩下的56%的学生在后续的教学中也能够及时积极参与其中。有30%的学生能够积极参与在线活动。参与案例分析的次数在0至5次不等。学生的团队合作能力分布在70至92.58分之间,其中占比最大的得分区间为(80,85],平均得分为83.34分,学生的团队合作能力处于良好和优秀水平。
2. 模型验证
为了验证本文提出的方法的性能,研究团队使用不同的基准模型对数据进行运算,以预测学生的学习成绩。在教育数据挖掘研究中,经常使用自适应增强(Adaptive Boosting, Adaboost)、支持向量机(Support Vector Machine, SVM)、人工神经网络(Artificial Neural Network, ANN)、线性回归(Linear Regression,LR)等模型来预测学生的学习成绩。本研究使用这些模型作为实验的基准模型。
首先将两个年级的167名学生作为开发集,在构建模型时采用超参数调试法优化算法。其中第一个年级的93名学生数据为训练集,第二个年级的74名学生的数据为测试集。由于原始数据的输入输出数据的量纲和物理意义不尽相同,对原始数据进行归一化处理。上述数据预处理步骤,为成绩预测模型做好了数据的铺垫,避免因为原始数据缺失、重复、不合理、不一致而导致模型无法训练。高质量输入数据是训练出性能好的分类模型的必要基础,因此数据预处理是数据挖掘之前必不可少的一个重要环节。随后采用平均绝对误差(Mean Absolute Error, MAE)、均方根误差(Root Mean Square Errors, RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)、90分位精度百分比(90th Percentile Precision, 90PPR)对预测结果进行误差分析。
第一,MAE衡量了预测值误差的平均模长,表示为真实值与预测值之间的离差绝对值之和,取值范围从0到正无穷,不用考虑方向。公式如下:
第二,RMSE反映了样本的总偏离程度,定义如下:
第三,MAPE是相对误差度量值,表示预测值与真实值差值占真实值的百分比。取值越小,模型准确度越高。定义如下:
其中n为样本总数,yi和是第i个样本的真实值和预测值。评价指标的值越小,说明模型表现的越好,模型的预测精度越高。
第四,90PPR是90分位精度百分比,表示预测值与真实值误差小于10%的样本占总样本的百分比。取值越大,模型准确度越高。定义如下:
其中n为样本总数,yi和是第i个样本的真实值和预测值。∃(·)为示性函数,当括号内的值为真时,取1,否则取0。评价指标的值越大,说明模型表现的越好,模型的预测精度越高。
实际训练过程中,模型的结果会产生小范围的波动。因此本节所有实验均重复进行多次,并取多次结果的平均值作为最终实验结果,实验结果如图1所示。
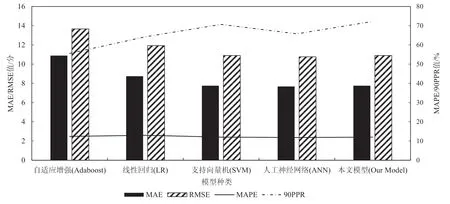
图1 实验结果
在本文实验中对比了Adaboost、SVM、ANN、LR和本文模型的预测性能。与LR、ANN相比,SVM的预测性能更好,其MAE指标比LR降低了11.32%,与ANN基本持平。RMSE比LR降低了8.6%,与ANN基本持平。MAPE比LR降低了7.4%,与ANN基本持平。90PPR比LR提高了10.04%,比ANN提高了7.43%。本文提出的基于SVM作为弱回归器,且引入概率采样和损益函数的模型得到了最佳的预测性能,与采用Adaboost相比,MAE下降了28.77%,RMSE降低了20.23%,MAPE降低了3.22%,90PPR提高了27.2%。
3. 学生学习轨迹分析
进一步根据上述预测模型,对学生的个人学习轨迹进行分析。根据预测结果图2给出了在第二个年级部分学生的学习成绩成长轨迹。其中,横坐标代表时间,纵坐标代表不同时间的学生成绩,不同曲线代表不同学生。
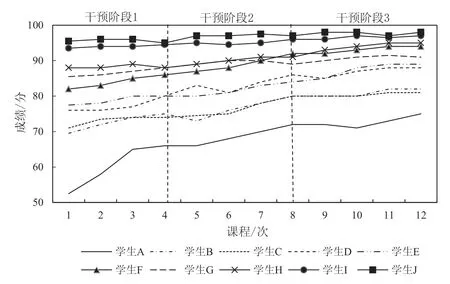
图2 学习成绩成长轨迹
结合课程进展和教学干预将学生的学习过程分为了3个阶段:干预阶段1,干预阶段2和干预阶段3。在干预阶段1,即感知需求阶段,通过对学生初期成绩的预测和分析,了解学生的学习基础和学习目标。同时在这一阶段也是学生对专业知识进行学习和掌握的关键阶段。干预阶段2,即理解干预阶段,根据学生前期的学习轨迹,针对性地和学生展开教学互动,重点是帮助学生理解和应用所学知识。在干预阶段3,即巩固提高阶段,通过对学生学习成绩的分析,根据学生的学习进展,帮助学生巩固或提高当前的学习。
根据图2,在干预阶段1,学生A的初始成绩未及格,学生B、C的初始成绩低于平均分,学生D、E的成绩在均值附近,学生F、G、H的成绩较高于均值,成绩良好,学生I、J的成绩优秀。在这一阶段,教师可以通过一对一或者一对多的方式和学生进行互动,对学生的学习需求进行分析,并且结合学生的前期成绩对学生进行个性化学习目标的思维导图构建。例如,学生A、B、C的学习基础相对较差,针对这部分学生,前期应重点帮助提高学生的学习基础,了解学生的学习薄弱点。在教学互动中,可以适当增加对此类学生知识性的提问和互动。学生I、J的学习基础相对较好,针对这部分学生,教师应当在初期着重培养学生对课程的学习兴趣,引导学生对课程内容进行深入思考。
在干预阶段2,学生A的成绩大幅提升,学生B、C、D、E的成绩也有所提升,提升幅度略小于A,学生F、G、H、I、J的成绩提升幅度较小。在这一阶段,教师可以通过场景化教学升级,提高学生对课程的关注度。通过在视频案例中嵌入模型讲解,使学生加强对模型的理解,将视频案例与模型讲解相结合,实现网上的“实战模拟”,以丰富的教学模式加深学生的记忆。此外,学生B和D在阶段2中的成绩出现较为明显的下滑,此时教师应通过及时的互动来发现学生在教学过程中面临的问题,并采取相应的干预措施。通过教师和学生之间、学生和学生之间对课程知识的分析讨论甚至是激烈争辩,帮助学生深入理解课程知识。
在干预阶段3,学生A的成绩在经过短暂平稳期后又有大幅提升,学生B、C、E、F、G、H的成绩也有所提升,提升幅度略小于A,学生D的成绩提升较小。学生I、J的成绩趋于稳定在优秀水平。在这一阶段,部分学生的成绩存在下滑,通过和学生的互动交流发现,主要原因在于在课程末期学生对课程的学习兴趣下降。因此采用多元化角色扮演形式,通过脱口秀、课程展示等多种形式,引导学生对案例进行分析和讨论,帮助学生巩固知识和提高能力。在此阶段,教师应当针对性地对学生提出建议,帮助学生认识到知识掌握的不足,并帮助学生认识到在学习过程中取得的进步,保持学生对课程学习的兴趣和积极性。
为了进一步对学生学习轨迹分析和干预措施的有效性进行说明。图3和图4分别显示了两个年级所有学生的各维度特征值和最终成绩在干预前后的表现对比。
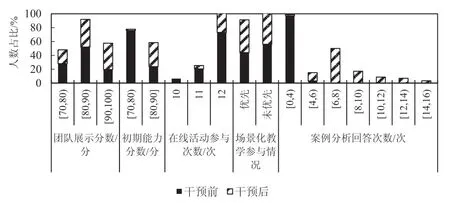
图3 各维度特征值干预前后对比
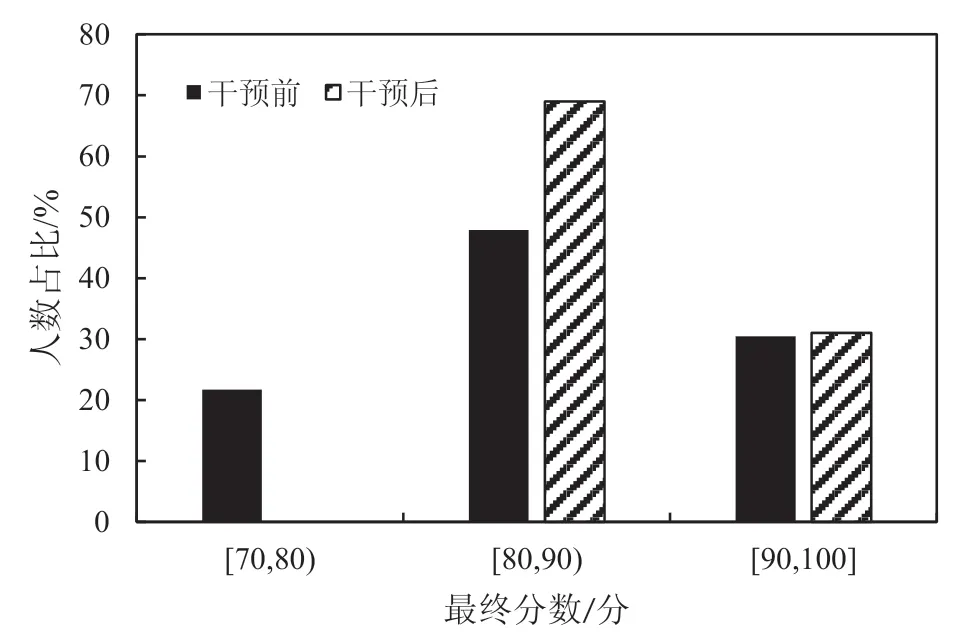
图4 最终成绩对比
如图3所示,采用干预和学生学习轨迹分析的学生初始能力评分显著提升,64%的人可以达到80分及以上,全勤的比例达到95%。学生的场景化教学参与积极性有了明显提升。有56%的学生在场景化教学中显示出较高的积极性,与未采取干预的年级相比,场景化教学的参与率在采取干预后的增幅为12%。学生参与案例分析的积极性显著提升,86%的学生回答次数在6次及以上,在未采取干预的年级,没有学生能够参与6次及以上。采取干预后,团队展示的成绩有了明显提升,并且最终的学生成绩表示(见图4),学生的学习成绩有较大的提升,优秀的比例为31%,且其余学生成绩均在80分及以上,验证了学生学习轨迹分析和干预措施的有效性。
四、 结论和建议
本研究提出了一种基于Adaboost方法的学生学习轨迹方法分析,其中引入了损益函数来表示预测误差率带来的影响,并根据预测的结果生成学生学习轨迹。通过和基线模型的对比表明,所提出的模型能够较好的预测学生成绩,并且能够保证更多的学生成绩预测结果在一个可用的范围内。同时,基于学生学习轨迹分析做出的相应教学措施切实提高了学生的在线学习成绩。综合教学干预措施和最终效果,提出以下建议。
1. 制定学生需求图谱,实现分层次教学
根据上述预测模型可以分析得到每个学生的学习轨迹,教师可以动态跟踪学生的学习轨迹,通过分析学习轨迹制定学生需求图谱,动态设计学习模式。通过学习轨迹分析结果和学生需求图谱,对表现欠佳的同学,处于基础阶段的学生,针对性地解决学生疑难问题,夯实课程学习基础;而对于表现较为优秀的同学提供补充性资源和拓展性知识链接,创设开放、复杂的问题情景和任务,提高其逻辑思维能力,进而满足不同学生的学习需求[29]。
2. 教学场景与教学资源有机配置,实现场景化教学
根据上述模型分析可得,是否参与场景化教学是影响学生学习成绩的重要因素。因此教师可以将教学场景和教学资源有机结合,在场景化教学中调动学生的积极性,从而使教学资源价值最大化。具体来说,将学术研究和专业实践的优质成果融入教学内容,提高课程学术价值的同时融入视频、实际案例等多形式内容资源,而不仅局限于文字和理论描述,充分利用线上的丰富资源和线上教学的实时互动功能,提高教学质量和效率。
3. 数据驱动课程评价,实现跟踪式教学
上述模型只选取了部分特征对学生的学习成绩进行预测,未来可融合质性评价和线上的实时学生学习数据监测等手段,实现课程全过程的学生行为画像,精准有效地针对学生个体形成学习档案,利用学生行为数据预测学生的学习成绩,实现跟踪式数据驱动的教学评价。
