基于Mask R-CNN 倾斜影像筛选的建筑物三维模型高效重建方法
2023-12-03樊孝常梁玉斌崔铁军
樊孝常,梁玉斌,杨 阳,崔铁军
(天津师范大学地理与环境科学学院,天津 300387)
建筑物三维模型在城市规划、灾害分析和应急响应等领域具有广泛应用.常见的三维建模方式主要包括三维建模软件手工建模、三维激光扫描点云建模和摄影测量技术建模.手工建模需要研究人员基于点线面进行模型构建,建模过程耗时耗力;而激光扫描建模设备昂贵,数据采集过程复杂[1].
随着无人机(unmanned aerial vehicle,UAV)技术的快速发展,其成本低、时效高、响应迅速的优势日益显现[2-3].无人机数据在各领域的应用越来越广泛[4-5].运动结构恢复算法(structure from motion,SFM)和多视图立体匹配算法(multi view stereo,MVS)的不断完善,使基于无人机影像的摄影测量技术能够更好地实现实景三维模型的重建[6-7].无人机影像构建的实景三维模型在施工场地土方测量和公路边坡灾害识别等各个方面都有较强的实用性[8].建筑物是三维模型的重要组成部分,倾斜影像增加了建筑物的立面纹理结构信息,逐渐成为建筑实景三维建模的主要数据来源[9-10].然而,与常规航空影像相比,倾斜影像显著增加了摄影测量数据处理的复杂性,如何高效准确地构建建筑物三维模型成为摄影测量的研究热点[11-13].李大军等[14]应用Mask R-CNN 神经网络识别无人机影像中的建筑目标,发现它比传统航空影像的建筑识别更加高效与智能.陈丽君[15]改良传统Mask R-CNN 算法,增加了训练模型的稳健性,提高了识别建筑影像的准确率.邵振峰[16]提出了一种基于航空立体像对的人工目标三维提取与重建方法,研究开发了一体化立体影像平台,通过平台实现了部分复杂建筑目标的三维提取与重建.
传统倾斜摄影测量实景三维建模方法利用全部影像进行建模,普遍适用于建筑密度高的城市区域,但对于建筑密度较低的村镇区域来说,该方法未能充分利用照片内含的语义信息,引入了大量非建筑区域的非必要同名点,降低了三维重建的效率.因此,本研究将深度学习技术与摄影测量技术结合,在图像匹配之前筛选包含建筑的影像,在不损失建筑物模型信息和精度的前提下,提高建筑物三维建模的效率.
1 研究方法
本研究将深度学习技术与摄影测量技术相结合,首先利用深度学习技术构建并训练Mask R-CNN 神经网络模型,使用该模型剔除倾斜影像中不包含建筑的影像,然后将筛选出的影像与下视影像结合,组成参与建模的影像集.利用摄影测量技术进行建模,研究出一种不降低最终建模精度且有效减少模型构建时间的方法.本研究过程主要包括6个部分,分别为数据获取、数据准备、Mask R-CNN 神经网络模型的构建及训练、含建筑影像筛选、三维重建和对比评估,具体技术流程如图1 所示.
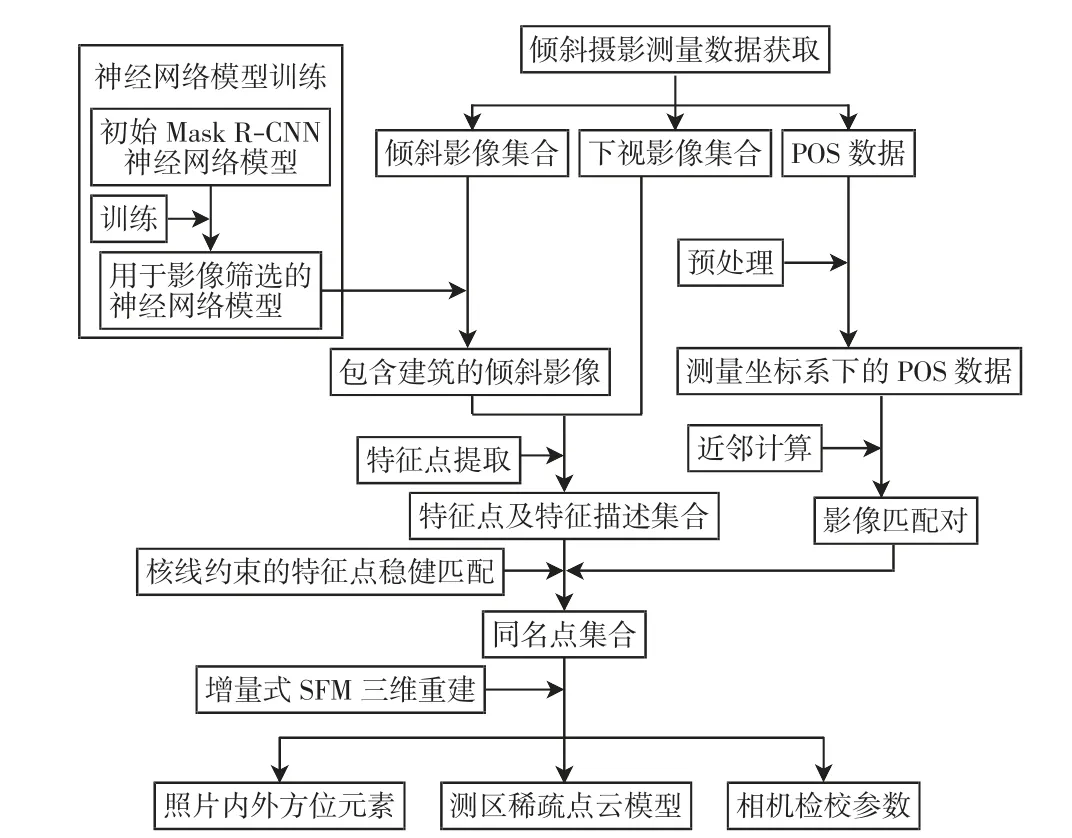
图1 技术流程图Fig.1 Technical scheme
1.1 影像筛选
Mask R-CNN 神经网络结构识别建筑目标的流程主要包括4个部分:①特征提取,将影像输入CNN 网络提取特征;②获得建议框,通过区域生成网络得到影像目标的可能位置,用矩形建议框标记;③分类和回归,利用感兴趣对齐层对建议框微调,得到较为准确的目标位置及大小;④像素分割,以像素级形式分割ROI,并按类别划分其像素,具体流程如图2 所示.
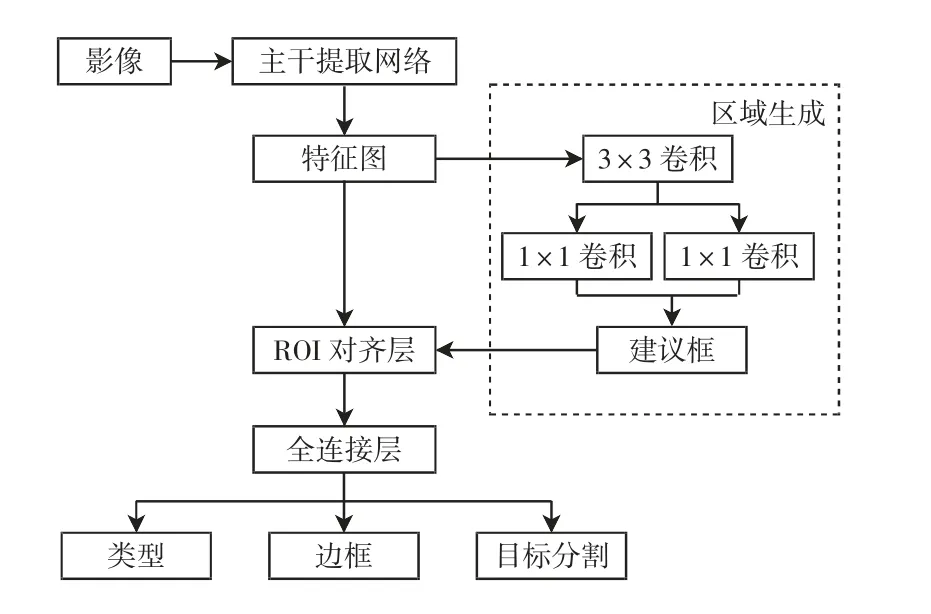
图2 Mask R-CNN 建筑目标检测流程图Fig.2 Flowchart of Mask R-CNN detection
1.2 摄影测量三维重建
根据构建方式的不同,将SFM 分为增量式SFM与全局SFM.增量式SFM 在三维重建过程中能够逐渐增加参与迭代计算的影像数量,直至所有影像都参与模型的构建.为使三维重建更具稳健性,本研究采用增量式SFM 构建方法.首先对研究区进行影像识别,获取输入影像包含的内参数信息;然后进行特征提取与构建图像对.使用尺度不变特征变换算法(scale-invariant feature transform,SIFT)及其改进算法进行特征提取,增强匹配的稳健性. 本研究在特征匹配之前,根据POS 信息将影像两两生成匹配对,控制影像匹配的数量;之后进行特征匹配,按照生成的影像匹配对逐个进行匹配.影像匹配结束后,利用RANSAC 算法剔除误匹配的特征点,得到可靠的匹配点.在上述过程的基础上进行增量式重建,得到优化后的影像参数及初始的空间点;最后进行三维点上色与重新三角化,根据对应影像位置的颜色对三维点进行上色处理,得到三维稀疏点云模型.
2 实验与分析
本研究的数据处理过程均在Dell Precision Tower 7810 工作站中完成,工作站操作系统为Windows 10专业工作站版,处理器为Intel Xeon E5-2630,内存为128 GB,同时配有NVIDIA Quadro M4000 的显卡.使用Python3.6、CUDA9.0、cuDNN7.0.5、TensorFlow-GPU1.9.0和Keras2.16 进行实验环境的搭建.
2.1 研究区概况与数据说明
研究区位于广西省来宾市武宣县(23°37′9″N~23°39′26″N,109°39′24″E~109°42′27″E),东西长约为5.7 km,南北宽约为4.7 km,总面积约为9.1 km2. 研究区是平坦的乡村区域,主要包含大片的农作物种植区、零散分布的村落、道路、裸地、树林和水塘等.研究区卫星影像信息如图3 所示.
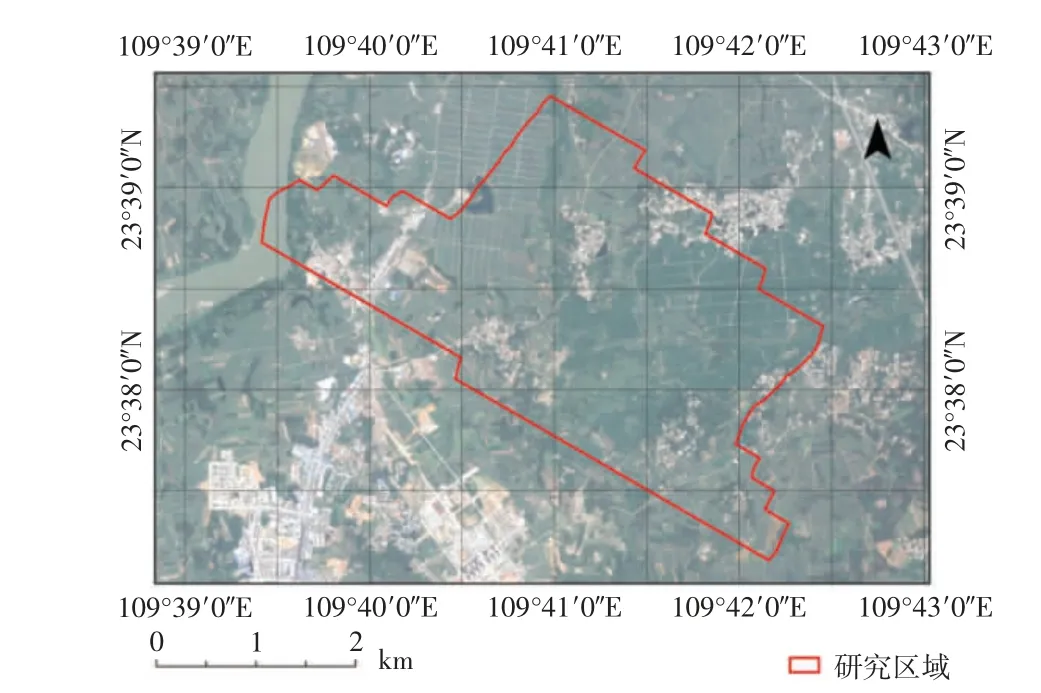
图3 研究区卫星影像图Fig.3 Satellite image map of the studied area
2018 年秋季,使用垂直起降的固定翼无人机搭载倾斜摄影系统采集影像数据. 研究区每个镜头均拍摄1 955 张影像,5个镜头共获得9 775 张影像.摄像机1—5 号镜头分别对应无人机飞行方向的后、前、右、左、下5个方向.无人机同时搭载有GPS/INS 组合系统,能够准确获取航测时曝光点位的POS 数据.POS数据包含2 部分内容:一部分记录每个曝光点位的绝对位置;另一部分记录无人机在每个曝光点位相对于导航坐标系的飞行姿态,即每个曝光时刻该无人机的侧滚角φ、俯仰角ω、偏航角κ.无人机影像在研究区的POS 分布如图4 所示.由图4 可以看出,影像的曝光点位均匀分布于研究区内,无人机每条航线间相互平行.

图4 研究区POS 分布图Fig.4 POS distribution map of the studied area
本研究首先用CrowdAI 官方提供的用于Map Challenge 比赛的数据集(数据集1)进行预训练[17],该数据集包含了针对建筑物的大量人工标注完善的卫星影像瓦片,将这些数据用于神经网络的预训练,可使模型从卫星影像中初步识别包含建筑的区域.数据集1 共包括训练集、验证集和测试集3个部分.训练集部分标注了280 741 张影像瓦片,验证集部分标注了60 317张影像瓦片,测试集没有标注.卫星图像标注示例如图5 所示.

图5 卫星图像数据标注示例Fig.5 Example of satellite image annotation
不同于数据集1 的影像区域,研究区内不仅建筑分布分散,地表还增加了许多绿色植被,需要人工标注出具有研究区特色的数据集(数据集2),进一步训练神经网络模型.数据集2 是对无人机下视影像进行人工标注后获得的瓦片数据,包括2 306 张训练集瓦片,600 张验证集瓦片.无人机影像数据标注示例如图6 所示.

图6 无人机影像数据标注示例Fig.6 Example of UAV image data annotation
2.2 建筑实例分割
2.2.1 神经网络模型的训练
数据集1 含有大量建筑密集的影像瓦片,故使用数据集1 进行模型的预训练.预训练共包括160 轮,每轮训练1 000 步.预训练过程训练集及验证集的损失分布如图7 所示.

图7 预训练损失分布图Fig.7 Distribution of pretraining loss
由图7 可以看出,模型训练在0~65 轮之间损失值逐渐降低,准确度逐渐提升;而65 轮之后的训练由于训练次数过多,出现模型过拟合的现象.其中,在第62 轮时取得最低验证集损失值,将第62 轮得到的权重文件作为预训练部分的结果.
使用数据集2 进行模型的精准训练,将预训练获得的权重文件作为训练的初始权重文件,在此基础上进行29 轮训练,每轮训练100 步.精准训练过程训练集及验证集的损失分布如图8 所示. 由图8 可以看出,模型在第24 轮时取得最低验证集损失值,将第24轮得到的权重文件作为精准训练部分的结果.Mask RCNN 神经网络预测模型的最终训练集损失值为0.683,验证集损失值为1.033.
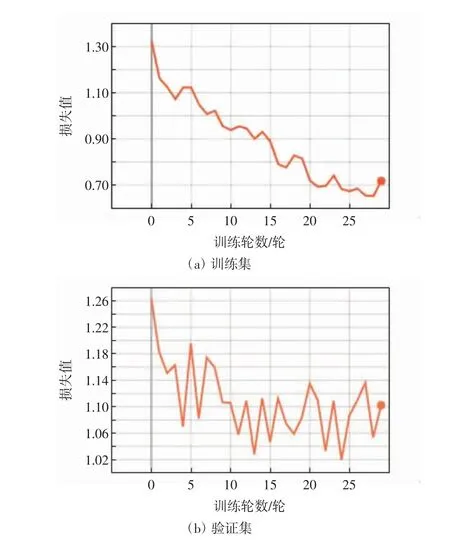
图8 精准训练损失分布图Fig.8 Distribution of precision training loss
2.2.2 影像筛选
将倾斜影像剪切成能够输入神经网络尺寸(300×300 像素)的瓦片,利用Mask R-CNN 神经网络预测模型对倾斜影像进行筛选.为保证最终模型的完整性,该步骤只对后、前、右、左4个方向镜头的影像做筛选,下视影像全部保留参与重建.每个镜头筛选影像用时分别为47.02、47.03、46.42 和48.25 min,均在47 min 上下波动;每个镜头筛选出包含建筑的影像的数量分别为1 359、1 367、1 361 和1 409 张,共7 451张无人机影像用于研究区三维模型的构建.图9 为2 组单幅影像神经网络建筑识别的效果展示.由图9 可以看出,神经网络识别出的建筑分布与影像中实际建筑分布情况基本一致,神经网络的建筑检测结果符合影像的真实情况.

图9 建筑检测结果示例Fig.9 Example of Building inspection results
2.3 方法对比
常规三维重建过程不做地物类型区分,将全部影像作为输入数据进行整体三维重建;而基于本研究方法的三维重建过程则利用神经网络筛选的倾斜影像和全部下视影像对研究区进行三维重建.2种重建方法都通过OpenMVG[18]和增量式SFM 分别进行图像匹配和三维重建.对比2种方法的效率与精度,结果如表1 所示.

表1 三维重建时间及精度统计表Tab.1 Statistics of 3D reconstruction time and accuracy
由表1 可知,从建模精度来看,常规三维重建方法和本研究方法的均方根误差分别为0.68 像素和0.69 像素,基本一致;从建模时间来看,常规方法总共耗时24.33 h,而本研究方法总共耗时12.31 h,节省了49.4%的数据处理时间.
2种三维重建方法生成的稀疏点云图如图10 所示.从图中可以看出,与常规方法相比,本研究方法的点云数量在研究区边缘区域较为稀疏,在建筑分布区域无明显差异.
2种方法建模对应的重投影误差统计分布直方图如图11 所示.
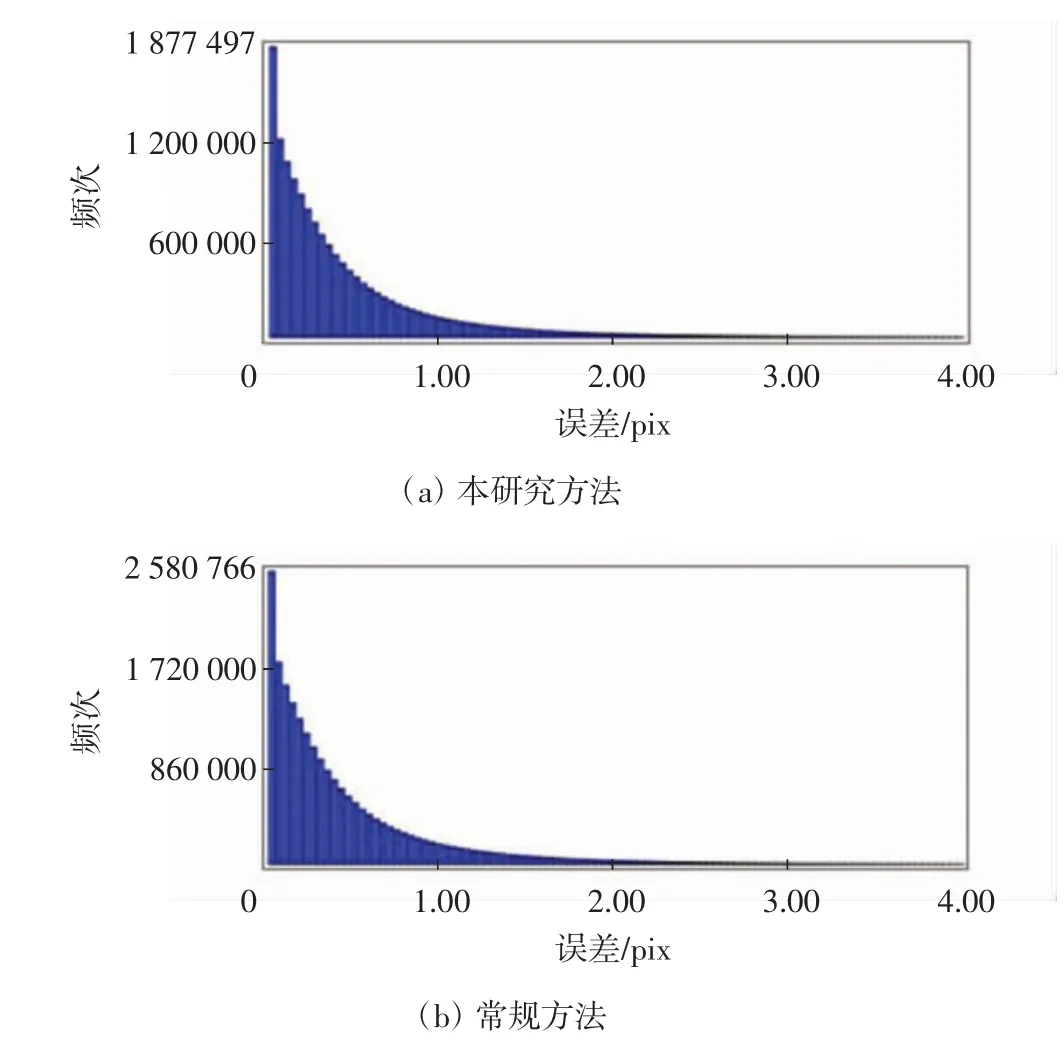
图11 重投影误差统计分布直方图Fig.11 Statistical distribution histogram of reprojection error
由图11 可知,2种建模方法的重投影误差频率分布较为相似,大部分像点重投影误差都集中在1个像素以内,误差较小.从像点数目来看,常规方法建模的像点数比本研究方法建模的像点数多了约703 000个,本研究方法的像点数在地表建筑较为密集的区域比较集中,其他区域较为分散;常规方法建模会在全区域生成像点,像点数比本研究方法多较为合理.在常规方法和本研究方法稀疏重建的基础上,进一步对研究区域内某一建筑密集区进行密集点云重建,重建结果如图12 所示.

图12 用于密集点云对比的建筑Fig.12 Comparison of buildings selected for dense cloud comparison
使用开源软件Cloud Compare 计算对应密集点之间的距离.先将2种建模方法生成的每栋建筑的密集点云进行对齐处理,使用该软件的M3C2(multiscale model to model cloud comparison)插件计算2个密集点云之间的对应点距离.选定的5 栋建筑对应密集点之间距离的统计结果如表2 所示.
由表2 可以看出,5 栋建筑对应密集点的标准差均在0.04~0.06 m 范围内,对应到影像上为0.57~0.86个像素.建筑1、4 和5 对应密集点的最大距离略大,主要集中在窗户和遮挡严重的区域,这些区域的密集匹配稳定性较差.建筑2 和3 的对应密集点最大距离均小于1 m.建筑密集点云和2种方法生成密集点的对应距离如图13 所示.由图13可以看出,对应密集点之间的距离在窗户和不易观测的墙体角落等区域较大,大部分对应密集点的距离都在厘米尺度,本研究方法与常规方法生成的密集点云结果基本一致.
3 结论
为了减少建模时间与计算量,提升影像建模的效率,本研究提出了一种使用深度学习技术对影像进行筛选的方法,并将该方法用于影像三维重建,与常规方法做对比,得到以下结论:
(1)本研究方法在建模之前使用神经网络模型对村镇区域的建筑影像进行筛选,减少了影像的数量,比常规方法建模节省了49.4%的时间,提升了建模效率.
(2)筛选包含建筑的影像并未减少建筑相关影像之间的匹配.从建模的重投影误差来看,常规方法的均方根误差为0.68 像素,本研究方法的均方根误差为0.69 像素,两者基本一致.从2种方法生成的点云模型对比来看,2种方法大部分对应密集点之间的距离均在厘米尺度.本研究方法与常规方法在建模精度上基本一致,表明减少非建筑图像数量不会降低三维重建的精度.
综上所述,本研究方法构建的影像模型的精度与常规方法相差不大,但大大减少了影像建模的时间,提高了效率,实验结果达到预期效果,这为特定地区的三维建模任务提供了一种效率高、计算量少、成本低的可行方法.
