基于云计算技术的电力系统能量实时调度技术研究
2023-11-30刘鑫
刘 鑫
(国网山东省电力公司东阿县供电公司)
0 引言
云计算是当前主流的分布式数据运算技术, 具有安全可靠、扩展灵活、数据处理能力强、数据处理设备利用效率高的优点, 能够将分布杂散的多种计算资源有机结合起来[1], 并借助于虚拟技术实现数据计算资源的高效整合[2]; 同时, 云计算技术采用分布式存储和因特网通信, 与采用数据集中式存储和内部网络通信的传统式分布式计算也有很大区别。正是基于云计算这些显著的特点, 传统的电力系统能量调度算法已经无法通过云计算平台实现[3]。因此, 应当以云计算技术的特点为依据来对电力系统能量调度算法进行设计和优化[4]。首先, 云计算能够对计算资源的数据处理能力进行估算, 不同计算资源的数据处理能力存在较大差异, 在进行新算法的设计优化时, 尽可能将数据和问题进行小型化处理, 以保证数据计算资源的高效利用; 其次, 由于云计算采用了因特网通信, 新算法要最大限度减少计算资源之间的通信, 以减小通信延迟对算法运行的影响; 再次, 云计算采用分布式数据存储, 新算法要遵循“就近处理”的原则, 以最大限度减小节点之间的数据交换[5], 保证数据处理的高效性。
1 电能调度与负荷预测
负荷预测是基于先前记录的负荷数据, 对当前时间之后的某个时间点或某个时间段的负荷情况进行预测。有很多因素都会对负荷预测产生影响, 诸如系统的运行特性、线路的拓扑结构、负荷的变化分布情况等, 负荷预测需要满足一定程度的精度要求, 负荷预测的精准度越高, 对电能的合理调度产生的影响就越小, 负荷预测是电力系统能量管理的重要组成部分,对电网运行的经济性产生很大影响[6]。
随着智能电网的逐步构建, 电力系统市场化运营的逐步推进, 负荷预测的精准程度不仅会对电能的合理调度产生影响, 还会对整个电网的运行稳定性乃至电网的安全运行产生影响, 所以说对不同类型负荷的运行特性、变化规律进行有效辨识是进行电力系统能量调度的前提条件, 而对记录的历史负荷数据中的个别坏数据进行辨识和修正是保证负荷预测精准性的基础。在进行负荷预测的时候, 历史负荷数据是进行负荷预测的基本依据, 并且要搭建合理高效的负荷预测数学模型, 在大量历史负荷数据的基础上进行大量的研究与试验, 同时对负荷预测数学模型和新算法进行不断的优化升级, 这样才能够保证负荷预测数学模型跟精确的反应出负荷的实际变化规律。
2 基于改进型K-Means 的负荷数据预处理技术
2.1 K-Means 型聚类数据处理方法
K-Means 算法能够很好的应用在数据挖掘中, 但是其中存在的缺点必须进行改进才能保证其应用效果, 由于初始k值会对最终结果产生很大影响, 所以必须通过合适的手段确定合理的k值; 通过合适的手段选取聚类中心; 根据实际情况构建合理的数学模型。依据就近原则选取距离被修正负荷数据最近的历史负荷数据作为聚类中心, 再根据电力负荷的运行特征进行取值, 从而事实现迭代次数的降低、最终结果稳定性的提升。对于初始k值来说, 引入评价聚类个数效力的评价公式, 通过评价公式的运算得出最合理的初始k值, 评价公式定义为:
其中:
初始k值为聚类个数,N为总数据个数,n为采样数据个数,xj是每一个聚类中第j条负荷曲线,z是每一聚类的中心。
上述公式反应出: 合理的聚类个数k值, 要保证类内数据的高聚合性, 即类内数据要最大限度接近于类中心, 这就是类内距离, 这个是主要的评价参数;同时要保证类间数据的低耦合性, 即类间数据要最大限度的互相远离[10]。在上述评价公式中,Inter(k)函数通过对类间数据的间隔进行计算来描述类间的差异, K-Means 方法通过计算Weigth(k) 公式的最小值来获取最合理的聚类个数k值。
针对负荷曲线的运行特性, 引入变化率的概念,以更好的对聚类算法中的距离概念进行描述, 同时变化率也能够实现对分类过程的细化处理。经过改进后的K-Means 聚类算法同时采用了距离和负荷变化率两个描述参数, 这样能够更精确得到预测负荷特性曲线, 能够也能够更好的对该曲线进行解释说明:
改进型K-Means 的实现流程如图1 所示。
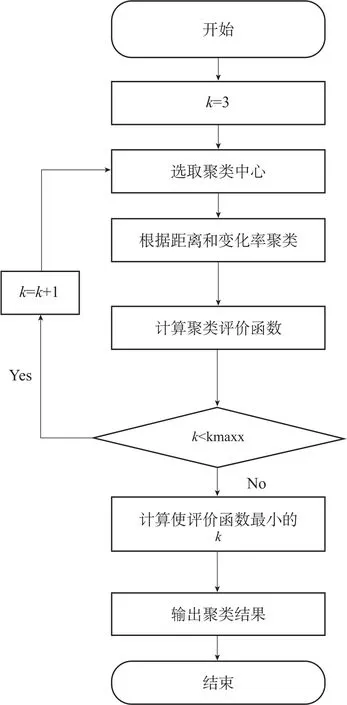
图1 改进型K-Means 的实现流程
2.2 基于改进型K-Means 的负荷数据预处理方法
电力系统的负荷特性曲线具有相似性和平滑性的特点, 相似性是指邻近几天内同一类型的负荷特性曲线具有相似的波动特征, 曲线形状大致相同; 平滑性是指邻近负荷点的负荷值不会发生很大变化。
从负荷预测的角度进行分析, 对坏数据的修正实际上也是一种负荷预测, 以负荷特性曲线的相似性和平滑性为依据来对坏数据进行近似替换, 为后续的负荷预测提供数据依据。从模式识别的角度进行分析,坏数据的修正过程实际上就是一个对比判定的过程,将含有坏数据的负荷特性曲线与同类的常规负荷特性曲线进行对比分析, 从而得到正常数据的近似值。因此这就要求以大量的历史负荷数据为依据, 对这些数据进行系统化的分析和总结, 将特征类似的数据进行归类分组, 得到几组具有显著特征的负荷曲线。
坏数据通常存在数值异变的特征, 依据这个特征利用负荷数据突变辨识法就能够将坏数据从历史负荷数据中辨识出来。首先对于某个数据点i, 对它自身与前面最近一个正常的负荷数据点j进行负荷变化率计算, 由公式(4) 计算得到; 然后对历史负荷数据中同类负荷曲线这两个时间点的负荷变化率的数值波动范围, 对比刚计算得到的待验证点负荷变化率是否在正常的范围内, 来判定此点的数据是否为坏数据。
采用改进K-Means 算法对需要被修正的负荷曲线进行聚类运算, 得出k条负荷特性曲线; 将需要被修正的负荷点移除; 对需要被修正的负荷点附近的多个点与负荷特性曲线相应点的距离; 将距离最短的负荷特性曲线作为进行数据修正的参考特性曲线。将参考特性曲线直接平移到需要被修正的负荷特性曲线上, 根据需要被修复点附近的数据进行重新拟合, 这样能够相对较真实的反应负荷特性曲线的变化趋势。数据修复公式:
其中,Xd是修正后的负荷特性曲线,Xc是需要被修复的负荷特性曲线,Xt是需要被修复的负荷特性曲线的参考特性曲线,ChR(i) 是需要被修复的负荷特性曲线所属的参考特性曲线在第i数据点的负荷变化率,i=p,p+1,…,q。
3 基于改进K-Means 型的负荷数据并行化方法
电力系统的负荷特性曲线的数据量很大, 通常在离线的情况下进行负荷预测。不同的负荷特性区间之间基本不具有关联性, 便于进行分布式计算, 这与云计算的基本思想是相契合的, 负荷预测的离线操作特性也保证了云计算能够很好地运用在负荷预测计算中。
首先将大数据进行合理的分解操作, 生成大量的小数据集合, 然后将多个小数据集合分别经由云计算集群中的结点采用并行计算的方式实现Map 运算,并将运算结果再次通过云计算集群中的结点并行实现Reduce 任务, 生成最终结果。如图2 所示描述了Map_Reduce 的实现机制。在数据输入阶段, 由作业跟踪器从主节点的存储单元上获取数据片信息; 在Map 阶段,由作业跟踪器分配多个任务处理单元实现Map 运算从而得到中间结果; 在Shuffle 阶段完成中间结果的重新排列; 在Reduce 阶段, 由作业跟踪器分配多个任务处理单元实现Reduce 运算; Reduce 运算完成后, 由作业跟踪器和主节点输出最终计算结果。
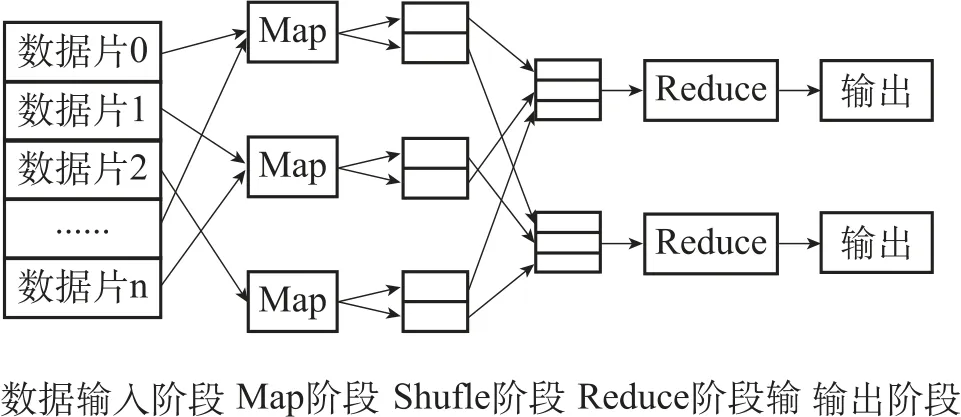
图2 MapReduce 的实现机制
4 算例验证
选用某地区某年的全年负荷数据对算法进行仿真验证, 预设异变数据、畸变数据两种坏数据进行辨识并修正, 其结果如下: 对这一年十月份的负荷数据进行聚类分析, 得出各种聚类下的聚类评价参数Weight值, 从中提取Weight值最小的聚类个数k值, 得到对应的最佳聚类个数下的负荷特性曲线。聚类个数与Weight值之间的关系如表1 所示。

表1 聚类个数与聚类评价指标的关系
所以得到最优的聚类个数是4。
通过提取的负荷特性曲线对需要被修正的异变数据和畸变数据进行修正得到修正结果如图3 和图4 所示。
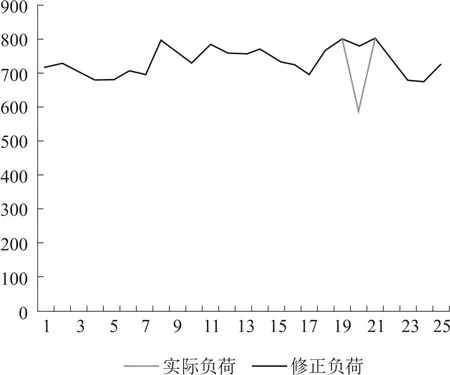
图3 单个异变数据修正结果
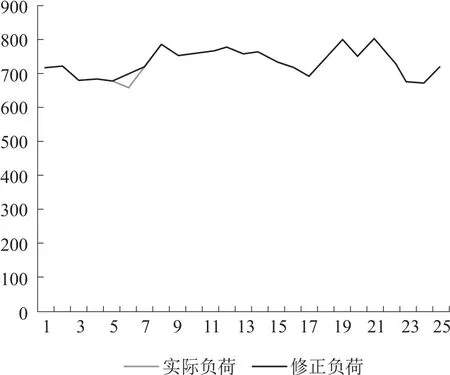
图4 连续畸变数据修正结果
从图3 中可以看到, 算法对单个异变数据进行了有效的辨识和修正。将修正结果与正常值进行比对, 经过大量实验验证, 平均误差能够控制在1%左右, 极个别负荷点出现大于2%的误差, 但该点不具有代表性。
改进型K-Means 算法对单个异变数据和连续畸变数据具有较高的辨识率, 并能对坏数据进行有效的修正, 试验结果良好, 满足要求。
5 结束语
本文分析了基于云计算技术的电力系统能量调度技术, 重点对进行负荷预测中的负荷数据预处理问题进行了深入研究, 对典型的K-Means 算法进行了优化升级, 通过对优化后的算法进行试验验证, 该算法的应用效果良好, 随后将该算法进行了MapReduce 改造, 最终得到了能够有效采用云计算技术的负荷预测数据预处理方法, 基于此方法即可实现电力系统能量的高效实时调度。
