基于簇级匈牙利与联盟博弈联合的CF mMIMO导频分配算法*
2023-11-25谭景戈毛翔宇郑建宏
谭景戈,毛翔宇,郑建宏
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
无小区大规模MIMO(Cell-Free Massive Multiple-Input Multiple-Output,CF mMIMO)是一种无线网络部署体系结构[1],被认为是6G和未来无线移动通信的核心技术之一,受到了越来越多研究者的关注。CF mMIMO系统中存在大量配备有单个或多个天线的接入点(Access Point,AP)分布在不同的地理位置,并通过回程链路连接到中央处理器(Central Processing Unit,CPU)。这些AP在相同的时频资源上向所有用户(User Equipment,UE)提供服务。该系统以“用户为中心”,缩短了AP与用户之间的平均距离,大幅降低了路径损耗,使全区域信号均匀覆盖,为无处不在的无线通信提供一致的服务质量。
CF mMIMO系统采用时分双工(Time Diversion Duplex,TDD)工作模式,因此,在上行训练阶段通过导频序列进行信道估计获得的信道状态信息(Channel State Information,CSI)可用于下行链路,从而显著节省无线资源。然而,由于正交导频数量的限制,用户间需要复用导频,从而产生导频污染,使系统性能受到严重影响。为了减轻导频污染带来的性能损失,文献[1]提出了一种贪婪导频分配算法,采用迭代的方法更新最低速率用户的导频;文献[2]提出了一种改进的贪婪导频分配算法,利用位置信息分配导频。然而与接近最优的结果相比,这两种算法有很大的性能差距。主要原因是贪婪算法是一种局部搜索方法,而这两种算法未充分利用CF mMIMO系统的特性。文献[3]提出了一种结构化的导频分配方案,从空间角度减轻了用户复用导频造成的导频污染,但是用户簇边缘的用户容易受到严重的导频污染[4]。文献[5]提出了一种基于禁忌搜索的导频分配算法,通过创建禁忌列表避免导频分配结果陷入局部最优。文献[6]提出了一种基于遗传算法的导频分配算法,利用生物进化的思想不断优化导频分配方案。文献[7]利用经典的匈牙利算法来解决导频分配问题。该算法对用户吞吐量有较大提升,优于多种竞争方案,但由于该算法是在用户级的基础上迭代使用匈牙利算法,因此计算复杂度相当大。同时该算法的收益矩阵只考虑了单个用户的吞吐量,并没有从全局出发考虑所有使用相同导频用户的吞吐量。文献[8]提出了基于联盟博弈的导频分配方案,将使用相同导频的用户划分为一个子联盟,然后采用博弈的思想来改变用户使用的导频,以此优化导频分配方案。文献[9]提出了一种基于用户信道条件优劣的导频分配算法。该算法对mMIMO系统的性能有一定提升,但需要先采用一定的判断策略得到每个用户的信道条件。
鉴于此,本文提出一种基于簇级匈牙利与联盟博弈联合的导频分配算法,从全局的角度对文献[7]中匈牙利算法的收益矩阵进行改进。在此基础上,利用联盟博弈的思想避免因固定的导频使用次数而带来的性能上限。仿真结果表明,该导频分配算法性能优于多种典型导频分配算法。
1 系统模型
本文考虑了一个CF mMIMO系统,在其覆盖范围内随机分布M个配置单天线的AP和K个配置单天线的用户,其中M≫K,并假设所有AP都通过无损回程链路连接到CPU,如图1所示。

图1 CF mMIMO系统
M个AP在相同的时频资源下为K个用户提供服务。受大小尺度衰落的影响,信道可建模为
(1)
式中:gm,k,βmk,hmk分别表示第m个AP和第k个用户之间的信道、大尺度衰落系数和小尺度衰落系数。
CF mMIMO系统帧结构为上行训练、上行链路传输、下行链路传输,如图2所示。用Tc、Bc和τc分别表示信道的相干时间、相干带宽和相干间隔,满足τc=Tc·Bc。在上行训练阶段,AP根据已知的每个用户发送的导频序列估计与每个用户间的CSI。设τp为上行训练阶段的长度。当τp>K时,可以将长度为τp的K个相互正交的导频序列分配给K个用户。考虑到系统的频谱效率,τp不能太大。因此,部分用户会复用导频序列。

图2 系统帧结构
1.1 上行训练阶段
假设给用户k分配的导频序列为φk(||φk||2=1)且训练阶段导频均为全功率发送,则第m个AP接收到的信号可以表示为
(2)
式中:ρp表示导频信号的归一化信噪比;ωp,m~CN(0,1)是信道中的加性高斯白噪声。
第m个AP根据接收导频信号yp,m估计与每个用户之间的信道系数gm,k,k=1,2,…,K。设yp,m在φk上的投影为
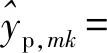
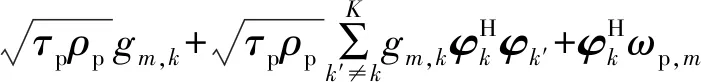
(3)

(4)


(5)
1.2 上行链路传输阶段

(6)
式中:ρu表示归一化上行链路信噪比。
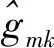

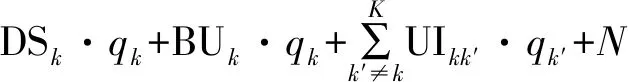
(7)

第k个用户上行链路吞吐量为
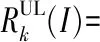

(8)
2 问题描述
从式(3)、(4)和(8)中可以看出,导频分配在用户的上行链路传输中起着重要作用,它决定了用户的信道估计性能,从而决定了用户的上行链路吞吐量。在本文中,我们的目标是找到最佳的导频分配方案,以便最大化用户的吞吐量。与文献[5]类似,该组合优化问题可以表示为
(9)
式中:I=[I1,I2,…,IK],Ik∈φ,∀k。
3 现有匈牙利导频分配算法
文献[7]中提出了一种基于匈牙利算法的导频分配方案。该算法在每一步都涉及到一个适当的二部图定义,以便匈牙利算法可以用于执行匹配。
现有匈牙利导频分配算法(算法1)实现步骤如下:
输入:K,M,τp,φ,最大迭代次数MIThung1
输出:导频分配结果I
1从φ中随机选取导频分配给每个用户。
2 fori=1:MIThung1
3 fork=1:K
4 以用户k为中心找出距离其最近的τp-1个用户组成集合Sk,剩余用户组成集合Tk。
5利用匈牙利算法重新为Sk中的用户分配导频。
6 end
7 if 算法收敛
8 break;
9 end
10 end
3.1 运行匈牙利算法

(10)

3.2 收益矩阵元素的定义
(11)
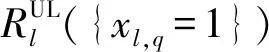
(12)
4 基于簇级匈牙利与联盟博弈联合的导频分配算法
4.1 簇级匈牙利算法
对匈牙利导频分配算法的改进,主要在对待重分配导频的用户集Sk的重定义和收益矩阵A的重定义,从而降低复杂度并提高系统性能。与现有匈牙利导频分配算法不同,我们先用K-mean聚类的方法对用户进行分簇,然后依次在每个簇内利用匈牙利算法分配导频。在定义收益矩阵元素时,不再只考虑被重分配导频用户的吞吐量,而是考虑所有使用此导频用户的吞吐量之和。
4.1.1 用户集Sk的重定义
由于用户和AP在空间上随机分布在CF mMIMO系统中,因此距离用户通信范围内的多个相邻AP具有不可忽略的信道增益[10]。基于此,先利用K-mean算法将距离较近的用户归为一个簇并给簇内用户分配相互正交的导频序列。
K-mean聚类算法(算法2)实现步骤如下:
输入:K,τp,MITk-mean,用户位置矢量U,收敛判决参数ε
1在覆盖范围内随机生成V(V=K/τp)个用户簇质心C=[C1,C2,…,CV]。
2 fori=1:MITK_mean
3 计算每个用户与所有质心间距离矢量dk。
4根据dk以就近原则让用户选择用户簇v并采用竞争机制使每个簇中用户不会超过τp个。
7 break;
8 end
9 end
10所有用户簇复用同一套导频序列,同一簇中用户使用相互正交的导频序列。
在用户分簇结束之后,就可将第v个用户簇v中的用户设为用户集Sv,而其余K/τp-1个用户簇中的用户设为Tv,然后利用匈牙利算法为Sv中的用户分配相互正交的导频序列,这样在每次的迭代中可以减少τp倍匈牙利算法的使用。
4.1.2 收益矩阵元素的重定义
文献[7]中的匈牙利导频分配算法对收益矩阵元素的定义仅考虑了Sk中单个用户的吞吐量。事实上,当Sk中使用第q个导频序列的用户不同时,对Tk中使用此导频的K/τp-1个用户的吞吐量会有不同程度的影响,所以将整个系统中所有使用第q个导频用户的吞吐量之和作为收益矩阵元素会更有利于目标函数最大化。因此,重定义收益矩阵元素如下:
(13)
根据重定义的收益矩阵,利用匈牙利算法迭代地为每个用户簇中的用户分配导频直到系统总吞吐量收敛。
4.2 联盟博弈
由于用户聚类时每个簇的用户个数是均分的,且簇级匈牙利算法并不会改变使用某个导频的用户数,固定的导频使用次数会带来一定的性能上限,所以本文采用联盟博弈的思想优化经过簇级匈牙利算法之后的导频分配。它类似于穷举搜索,然而如果已经有了一个较好的导频分配方案,那么联盟博弈算法将具有更低的复杂度。简单来说,如果已经有一个最优方案,那么联盟博弈算法将迭代一次后结束。
4.2.1 联盟结构和效用函数的定义
将K个用户划分入τp个不相交的子联盟,联盟结构N={N1,N2,…,Nτp}表示联盟的划分形式。整个联盟结构的划分需要满足如下要求:使用相同导频序列的用户划分入同一子联盟,且同一子联盟中的所有用户使用的导频序列相同。
可以将系统中用户的总吞吐量看作当前联盟结构的效用函数,这样联盟博弈可提升总吞吐量。
4.2.2 联盟博弈调整规则
本文借鉴文献[11]在联盟博弈论中的调整规则,即每个参与者的行为遵循增加所有用户的效用函数之和。为了让每个用户受益,联盟结构需要不断调整直到最终稳定。

(14)
从定义1可以看出,任何想要加入另一个子联盟的用户都不会损害所有用户的平均利益。

根据上述讨论,本文所提的基于簇级匈牙利与联盟博弈联合的导频分配算法(算法3)实现步骤如下:
输入:K,M,τp,U,MITk-mean,MIThung2,MITcoal2,ε
输出:联盟结构N
1根据算法2对用户进行分簇并初始化导频分配。
2 fori=1:MIThung2
3 fori=1:K/τp
4 利用匈牙利算法对第i个用户簇中的用户分配导频。
5 end
6 if 算法收敛
7 break;
8 end
9 end
10形成联盟结构N={N1,N2,…,Nτp}。
11 fori=1:MITcoal2
12 fork=1:K

14 break;
15 end
16 end
17 if 联盟结构稳定
18 break;
19 end
20 end
5 仿真结果与分析
本文考虑的场景为在1 km×1 km的正方形面积上随机分布着M个单天线AP和K个单天线用户。为了避免边界效应,本文将上述通信区域与8个相同分布区域相邻,以这种环绕技术来模拟具有无限区域的网络,并采用相关对数阴影衰落和三段路径损耗对大尺度衰落系数进行信道建模[1]。本文对上行链路数据的传输采用文献[12]中分数功率控制的方法以达到均衡用户吞吐量的目的。具体仿真参数设置如表1所示。
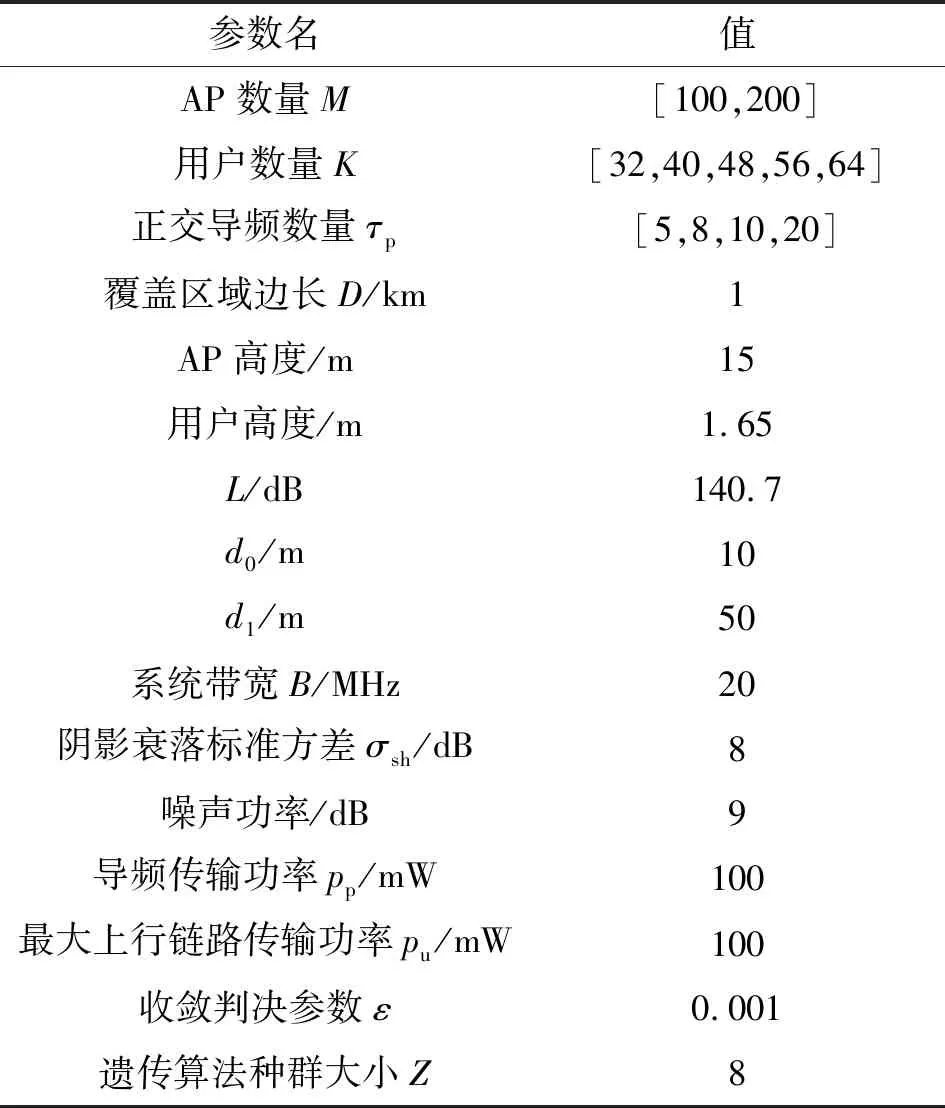
表1 仿真参数设置
首先,将本文所提出的导频分配算法(K-ImpHungarian-Coal)的性能与随机(Rand)[1]、贪婪(Greedy)[1]、聚类(K-mean)[3]、遗传(GA)[6]、匈牙利(Hungarian)[7]以及本文提出的簇级匈牙利(K-ImpHungarian)算法进行比较,其中ImpHungarian表示只改进了匈牙利算法中的收益矩阵。由于本文仅讨论上行链路吞吐量,所以匈牙利算法中收益矩阵元素只考虑用户的上行链路吞吐量。图3给出了上述几种算法上行链路吞吐量之和的累积分布函数,可以看出本文提出的导频分配算法性能优于其他典型导频分配算法。相较于Rand[1]、Greedy[1]、K-mean[3]、GA[6]算法,匈牙利类算法在系统总吞吐量上有较大提升。相较于现有匈牙利导频分配算法,改进了收益矩阵的匈牙利算法能够得到更高的吞吐量,而其后联盟博弈算法也使得吞吐量得到了进一步的提升。从图4可以看出,当同时采用改进收益矩阵的匈牙利算法时,基于簇级的匈牙利导频分配算法性能也要略好于基于用户级的方案。从图4还能看出,将经过K-ImpHungarian算法得到的导频分配方案作为联盟博弈(Coal)[8]算法的初始状态有助于Coal算法跳出局部最优。

图3 上行链路总吞吐量的累积分布函数(K=40,τp=8)
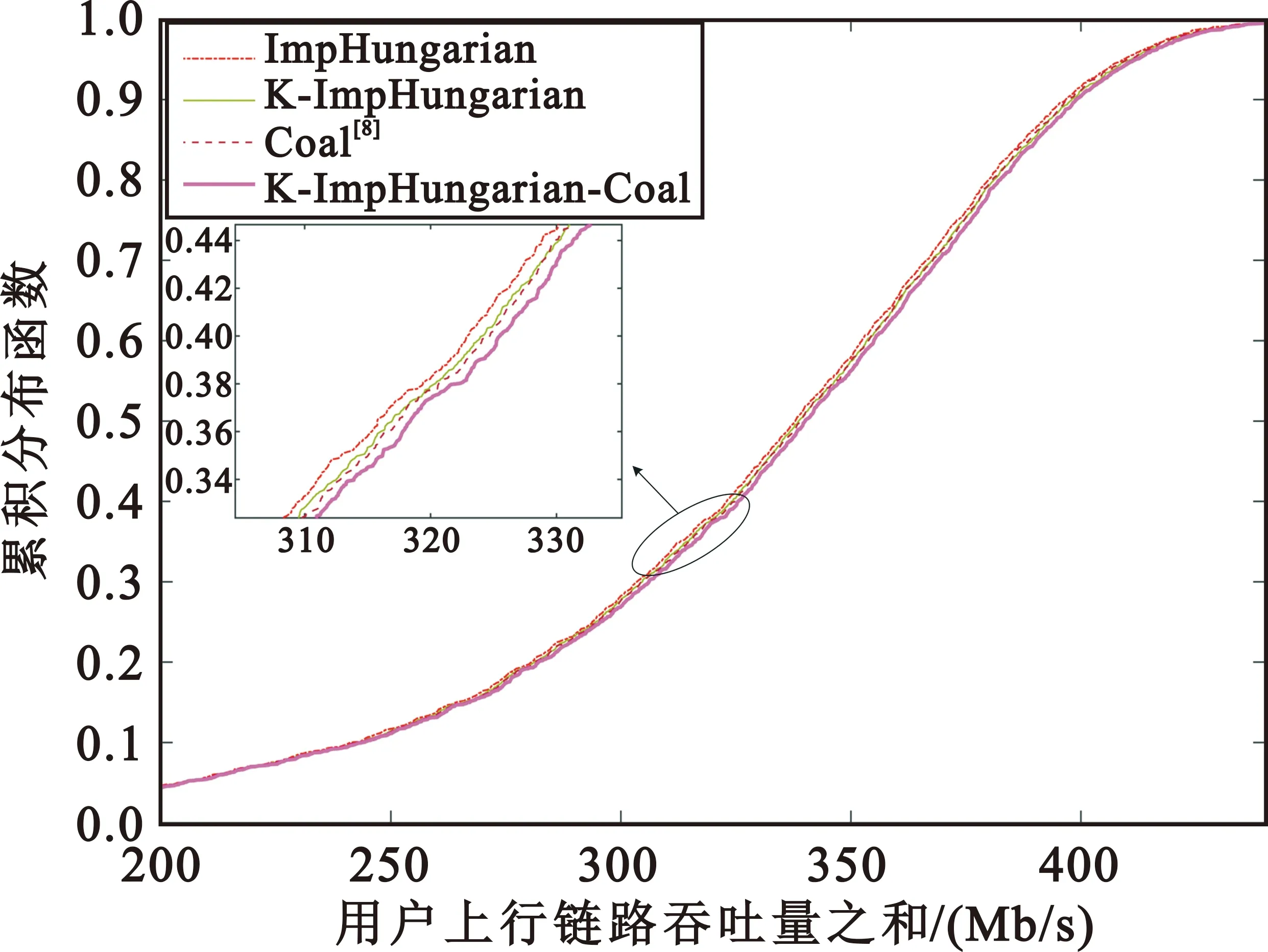
图4 上行链路总吞吐量的累积分布函数(M=100,K=40,τp=8)
图5和图6给出了上述几种算法在不同正交导频数量下和不同用户数量下95%用户可达吞吐量,可以看出本文所提算法性能优于其他典型算法,相较于Rand[1]、Greedy[1]、K-mean[3]、GA[6]、和Hungarian[7]算法,性能提升大约为85%,32%,28%,12%,11%。
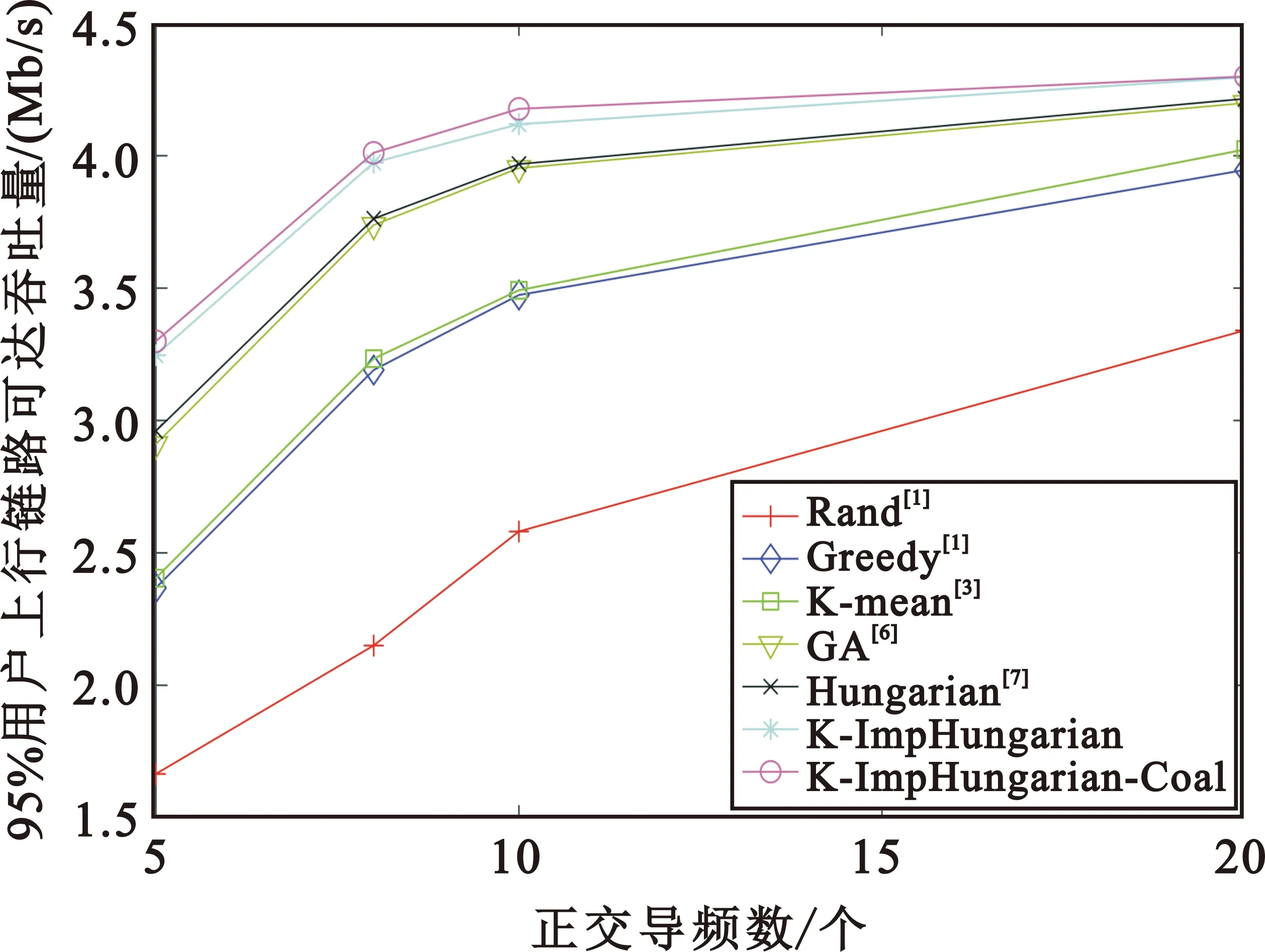
图5 不同正交导频数量下的95%用户可达吞吐量(M=100,K=40)

图6 不同用户数量下的95%用户可达吞吐量(M=100,τp=40)
因为Rand算法相当于直接分配导频,其计算复杂度可以忽略不计,所以表2只给出了其他各类算法的计算复杂度,其中,O1表示计算一次系统上行总吞吐量的线性复杂度,O2表示计算两用户间距离的线性复杂度,O3表示运行一次匈牙利算法的线性复杂度。表3给出了各算法达到收敛所需的迭代次数IT。由于GA算法后期主要是靠基因随机变异来获得性能提升,要达到最终收敛需要非常大的迭代次数。考虑到计算复杂度,本文给定了GA算法一个固定迭代次数50。从表2和表3中可以看出,相较于文献[7]中算法,本文所提算法不仅没有增加使用匈牙利算法部分的迭代次数,且在每次迭代中将匈牙利算法的使用次数减少了τp倍。从表3还能看出,将经过K-ImpHungarian算法得到的导频分配方案作为Coal算法的初始状态可以大大降低Coal算法的迭代次数。

表2 各算法的计算复杂度

表3 各算法迭代部分达到收敛所需平均迭代次数
6 结 论
本文在CF mMIMO的场景下提出了一种基于簇级匈牙利与联盟博弈联合的导频分配算法。先利用对用户聚类的方式减少直接使用匈牙利算法进行导频分配的复杂度,再从全局的角度改进了匈牙利算法中的收益矩阵,最后用联盟博弈算法避免了因为固定的导频使用次数而带来的性能上限。仿真结果表明,本文提出的导频分配算法性能优于多种典型导频分配算法。
