引入自上向下特征融合的小目标检测算法*
2023-11-25刘笑楠武德彬刘振宇
刘笑楠,武德彬,刘振宇,戚 雪
(沈阳工业大学 信息科学与工程学院,沈阳 110870)
0 引 言
近年来,基于深度学习的目标检测算法飞速发展,已经应用于医疗、生活、交通等领域,主要分为两阶段目标检测算法和一阶段目标检测算法。两阶段目标检测算法先基于候选区域生成候选框再进行分类和回归得到检测结果,包括R-CNN[1]、Fast-RCNN[2]、Faster-RCNN[3]等;单阶段目标检测算法直接进行预测的端到端目标检测,如SSD(Single Shot Multibox Detector)[4]、YOLO[5]、YOLOv2[6]、YOLOv3[7]、YOLOv4[8]等。单阶段目标检测算法相较于两阶段目标检测算法具有更快的检测速度,但是检测精度略低于后者。在目标检测中,将面积尺寸小、分辨率低的目标归为小目标。除了以上特征,小目标还具备容易被噪声影响以及被漏检和误检的特点,故提高小目标检测精度成为目标检测中不可或缺的重要部分。
虽然传统SSD算法采用了多尺度特征检测,但是没有考虑到不同卷积层之间的空间关系,整个模型传递过程是单向卷积传递信息,随着卷积层数增多,细节语义信息逐渐丢失,所以未充分利用各层之间的关系,导致不同层的特征信息未得到充分利用,从而影响模型对小目标的检测效果。针对上述问题,Li等人[9]和Liu等人[10]利用不同尺度特征融合的思想分别提出FSSD(Feature Fusion Single Shot Multibox Detector)算法和RFB-Net算法。FSSD算法将3个浅层特征层进行拼接融合,有效提高了小目标检测效果。而RFB-Net算法则是结合Inception结构构造RFB模块,增强网络感受野的同时增强了检测效果。Fu等人[11]将主干网络更换成ResNet101并利用反卷积传递信息以提高识别小目标的检测精度。杨艳红等人[12]利用特征金字塔(Feature Pyramid Network,FPN)[13]的思想,将特征层上采样与上一层特征层融合保持了较高的检测精度。张震等人[14]利用轻量级网络与层级特征融合的方法,提高了算法对小目标检测的有效性。陈鸿坤等人[15]利用浅层特征重利用模块将特征进行重利用后再进行特征融合,旨在强化小目标的检测效果。
由于浅层特征层包含许多空间位置信息,深层特征层有丰富的语义信息,而上述方法未充分利用两者之间的关系,故本文提出一种改进的自上向下进行特征融合的TTB-SSD(Top to Bottom SSD)小目标检测方法。该方法先利用PANet[16]多尺度特征融合网络构造自低层向高层和自高层向低层的两条特征提取路径,并反复提取浅层特征信息得到丰富的语义信息;再将浅层特征层的位置信息与细节信息利用空洞卷积[17]下采样传向深层特征层,并在各输出特征层的外部利用FPN特征金字塔整合不同层的语义信息,构造自上向下的特征传递路径;最后进行特征融合,获得新的特征图。上述方法能将深层特征层丰富的语义信息传到各层,从而增强对小目标的检测效果。
1 TTB-SSD算法
针对传统SSD算法采用单向传递未充分利用各特征层之间关系的问题,本文在原SSD算法的基础上提出TTB-SSD改进算法,整体网络结构如图1所示。

图1 TTB-SSD算法网络结构
该算法采用与SSD算法相同的VGG16主干网络,其6个特征层分别命名为Conv4_3、Conv5_3、Fc7、Conv8_2、Conv9_2、Conv10_2。为了克服原网络浅层特征层对小目标检测精度不高的问题,先将Conv4_3、Conv5_3、Fc7、Conv8_2这4个不同尺度的特征层经过PANet模块进行特征融合,将更多多尺度语义信息传递到浅层特征层,从而使提取到的特征具有更多的细节信息。为了增强深层特征信息,将Conv9_2特征层进行3×3卷积特征提取,并与PANet自下向上传播路径中的特征信息进行Concat特征拼接,使深层特征层获得浅层特征层的空间信息和多尺度语义信息。为了强化每一层小目标的语义信息,本文方法利用FPN的思想,将Conv4_3、Fc7、Conv8_2、Conv9_2和Conv10_2这5个特征层融合后的特征图结果进行1×1卷积平滑,并得到平滑后的新特征图。Conv11_2层特征图由于已经具有丰富的语义信息则直接输出。最后,进行分类回归预测并利用非极大值抑制筛选预测框得到最终预测结果。
1.1 自上向下特征融合结构
PANet多尺度特征融合模块仅针对Conv4_3、Conv5_3、Fc7、Conv8_2这4个特征层进行特征反复提取以及融合,未考虑利用全局语义信息。为了增强小目标特征信息,TTB-SSD算法利用FPN思想构建了一种自上向下的特征融合结构,即将高层特征层的语义信息逐层传递到低层特征层中,如图1所示。Conv11_2深层特征层丰富的语义信息通过双线性插值上采样,再进行3×3卷积特征提取,然后依次与前一个特征层进行特征融合。通过上述方法构造一个自上向下的特征传播路径,旨在将深层语义信息传递到每一个输出特征层,从而增强每一个输出特征层对小目标检测的准确率。最后,在特征信息传递到每一个特征层后进行Concat特征拼接得到特征融合后的新特征图。
1.2 PANet特征融合模块
为了解决浅层特征层缺少语义信息的问题,TTB-SSD算法引入了PANet多尺度特征融合模块,如图2所示。首先将Conv4_3、Conv5_3、Fc7、Conv8_2这4个特征层进行3×3卷积特征提取。为了增强多尺度语义信息,将卷积后的Conv8_2的特征图进行上采样并进行3×3卷积,构造自上向下的特征增强路径,并与卷积后的Fc7、Conv4_3的特征图进行特征融合,旨在将深层特征层的语义信息保留并传递到浅层特征层。而为了将浅层特征层的空间信息传递到深层特征层,构造自下向上的正向传递路径,为保证融合的特征图尺寸相同,将Conv4_3层的新特征图利用空洞卷积进行下采样,扩大感受野的同时能够获得多尺度的上下文语义信息,并在Fc7和Conv8_2特征层进行特征融合得到新的特征图。

图2 PANet多尺度特征融合模块
1.3 深层特征融合模块
Conv9_2深层特征层虽然在多层卷积后具备丰富的语义信息,但是容易造成小目标的位置空间信息的损失。本文使用多尺度特征信息避免这种损失,先对Conv9_2的特征图进行3×3卷积来减少通道数从而提取上下文信息,再将PANet特征提取网络中自下向上路径中的多尺度语义信息与空间信息通过空洞卷积下采样与批归一化(Batch Normalization,BN)层并经过ReLU激活函数激活,将两者进行Concat特征拼接融合。深层特征融合模块结构如图3所示,该结构在增强了Conv9_2的位置空间信息与多尺度语义信息的同时增强了自下向上的特征传播路径,有助于提高对目标位置和分类的检测准确率。
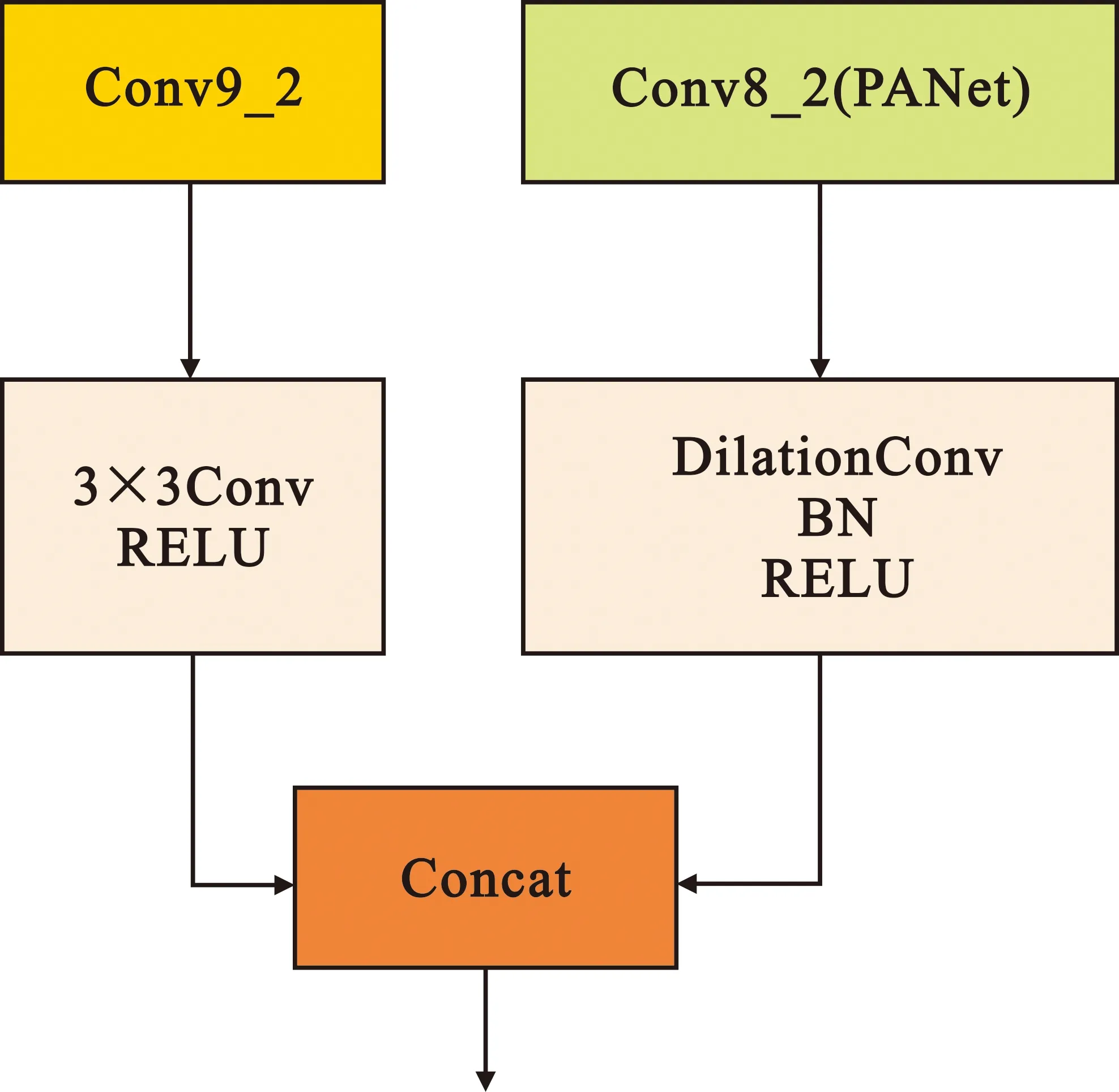
图3 特征融合模块
1.4 损失函数
本文算法的损失函数由分类损失函数和位置损失函数两部分构成,公式如下:
(1)
式中:N表示匹配正样本候选框的个数;x表示预测框类别信息;c表示该类别置信度;l表示预测框的位置信息;g表示实际框的位置信息;Lconf和Lloc分别表示分类损失函数和位置损失函数;α通常设置为1。
分类损失函数采用softmax多类别损失函数,如式(2)所示:
(2)
(3)

1.2.1.2.1整理由护士长助理每日负责对心血管内科治疗室所有物品,药品进行整理,采取优先合理放置必需品,清理放置在现场的非必需品。根据用药频率由近及远的放置,常用药品使用频率高,需放置于易取区域内,每日及时补充药品,经常检查药品有效期,及时销毁将过期及质变药品。
位置损失函数采用smoothL1损失函数,计算公式如下:
(4)
(5)
(6)
(7)
(8)

2 实验结果及分析
2.1 实验数据集与实验环境
本文实验配置与环境条件为Windows10操作系统,NVIDIA GeForce RTX3060;编译环境为torch-1.8.0,torchvision-0.9.0,python3.8。
实验根据PASCAL官方划分的PASCAL VOC2007和PASCAL VOC2012两个训练数据集共16 551张图片进行混合训练,在PASCAL VOC2007test数据集共4 952张图片进行算法性能评估,并在输入图像尺寸为300 pixel×300 pixel大小下进行实验。该数据集包含aeroplane、bicycle、boat、bus、car、motorbike、train、bird、cat、cow、dog、horse、sheep、bottle、chair、diningtable、potteplant、sofa、tvmonitor、person共20个类别。
2.2 训练过程及分析
实验使用的预训练模型为VGG16模型。训练采用SGD优化器,模型总共迭代120 000次共116个训练周期。模型训练Batch size为16,初始学习率设为0.001,并在迭代80 000次和100 000次学习率依次下降10倍生成新的学习率0.000 1和0.000 01,最后在120 000次得到最终的模型。整个训练过程中根据分类损失函数和位置损失函数以及总损失绘制的损失函数曲线如图4所示,可以发现TTB-SSD的分类损失值、位置损失值以及总损失值都小于SSD损失值,证明TTB-SSD预测目标更接近于真实目标,从而证明了本文算法性能的优越性。

图4 损失函数曲线
2.3 实验结果及分析
2.3.1 PASCAL VOC2007测试集性能检测对比
为验证模型的有效性,表1展示了TTB-SSD算法与近些年流行的目标检测算法在PASCAL VOC2007测试集上的实验结果,采用整体平均精度(Mean Average Precision,mAP)作为评价指标,公式如下:

表1 在PASCAL VOC2007测试集本方法与其他方法对比(IOU=0.5)
(9)
(10)
式中:r表示选取的阈值;P表示各阈值下的精度;N表示类别总数量。通过表1可以发现,TTB-SSD算法相较于Faster R-CNN[3]目标检测算法在VGG16和ResNet101的主干网络下,mAP分别提高了5.7%和2.5%;相较于目标检测算法YOLOv1[5]和YOLOv2[6],mAP分别提高了15.5%和5.2%,而与原始SSD[4]算法相比提高了1.7%;与其他改进的SSD算法如FSSD[9]、DSSD[11]、RSSD[18]相比都有所提高,分别提升0.1%,0.3%和0.4%。通过以上实验对比,证明TTB-SSD算法在目标检测精度上有明显优势。
2.3.2 小目标检测性能评估
为了更全面验证TTB-SSD算法性能,以及对小目标检测精度进行评估,实验沿用了MS COCO数据集的评价指标,面积小于32 pixel×32 pixel的物体为小目标,面积大于96 pixel×96 pixel的为大目标,而面积介于两者之间的为中等目标。
实验使用在IOU阈值为0.5条件下检测整体平均精度和在IOU=0.5∶0.05∶0.95的条件下检测小目标的平均精度两个评价指标对原始SSD算法、基于ResNet50主干网络的SSD算法以及TTB-SSD算法进行了对比,结果如表2所示,可见在IOU阈值为0.5的条件下,TTB-SSD整体检测精度较原始SSD算法和基于ResNet50主干网络的SSD算法的精度分别提高了2%和6.7%,有明显的提升优势。而对于小目标的检测精度,TTB-SSD较原始SSD算法和基于ResNet50主干网络的SSD算法的精度分别提升了5.7%和6.8%,证明TTB-SSD算法对小目标检测精度有较大提高。
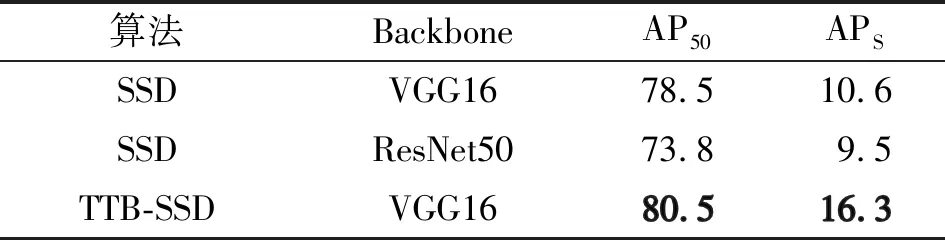
表2 小目标算法性能比较
2.3.3 单类别实验结果及分析
为验证TTB-SSD方法对各类别目标,尤其是小目标的检测效果,本文对数据集中20个类别进行了单类别比较,实验结果如表3所示。由表3可以发现TTB-SSD算法对16个类别物体的检测精度都超过原始SSD算法以及基于ResNet50主干网络的SSD算法,其余4个类别仅以微弱的差距落后,尤其对于bird、bottle、potteplant、chair等这样的小目标检测结果有着明显优势。其可视化对比结果如图5所示。

表3 单类别精度比较

图5 单类别检测结果可视化
2.3.4 定性结果分析
为了更直观地说明TTB-SSD算法的有效性,图6展示了原始SSD算法与TTB-SSD算法在PASCAL VOC2007测试集的部分检测效果图,可以发现SSD算法对小目标检测精度并不理想,图(a)所示图例中均存在漏检的小目标船只、远处的车辆或小盆栽,而这些目标在图(b)所示的结果图中均被正确检出。由此可见,TTB-SSD算法在复杂背景下对小目标具有更强的检测能力。
3 结束语
为了解决原始SSD算法对小目标检测效果不够理想的问题,本文将PANet多尺度特征提取网络和深层特征融合模块相结合,并构造了一种采用自上向下语义信息传播路径的TTD-SSD算法。实验结果表明,该方法在原数据集评价指标下目标检测精度高达78.9%,在COCO数据集中的小尺寸目标的评价指标下小目标检测精度高达16.3%,较原始SSD算法提高5.7%,可见TTD-SSD算法在小目标检测方面具有明显优势。但是,由于本文方法引入了多尺度特征融合模块,造成模型变大,故今后还需在保证精度的条件下研究模型轻量化问题。
