面向试验数据的标签本体及标签实例推荐方法*
2023-11-20张骁雄张明星谢志豪任智颖
张骁雄,张明星,3,谢志豪,任智颖
(1.国防科技大学第六十三研究所,南京 210007;2.国防科技大学大数据与决策实验室,长沙 410073;3.南京信息工程大学电子与信息工程学院,南京 210044;4.中国兵器工业计算机应用技术研究所,北京 100089)
0 引言
在信息系统中,标签是根据项目内容分配的关键词或术语[1]。标签有助于描述项目,方便用户更好地检索和浏览到相关内容,同时提升管理者对项目分类和智能化管理的便捷性。随着互联网数据规模的爆炸式增长,标签在信息检索及信息管理领域变得尤为重要。例如,在网易、新浪等新闻网站,通常每一条新闻都包含标题、摘要等信息,用户利用不同的标签分类更好地检索感兴趣的新闻题材;在图书管理、商品管理等领域,运营者可以通过标签更好地归类和管理物品,从而有助于建立更高效的管理系统。
鉴于标签为信息检索领域带来的诸多益处,近年来,研究者通过分析用户使用标签信息以及标签的特征信息,提出了基于标签的推荐系统。例如,SHEN Y 等通过挖掘新闻标签的潜在相关性,提出了基于标签间概率关系图的个性化新闻推荐方法[2]。LI M 等利用用户历史使用标签的信息建模用户的兴趣偏好进行视频推荐[3]。相比传统的推荐算法,基于标签的方法不仅能够提高推荐结果的准确性,同时为标签的智能化管理带来便利。
随着装备大数据建设要求不断提高,装备大数据建设进程陆续推进,试验数据逐渐成为装备数据的重要组成部分[4]。试验鉴定数据建设围绕数据组织管理、获取整编、分析挖掘、共享应用、运维管理和基础配套方面的需要,为全军试验历史数据提供统一的数据采集整编工具。不同试验鉴定机构每年产生试验数据量巨大,现有的数据管理工具,仅仅对采集和整编后的数据进行管理,无法直观展现数据中实体及关系,并且传统的数据管理工具,无法快速、准确、智能地推荐数据的相关信息。为此,本文提出了一种面向试验数据的标签及标签实例推荐方法,旨在通过构建标签及标签实例库实现与用户相关的标签推荐。
1 相关研究
1.1 装备试验鉴定
装备试验鉴定是考核武器装备性能指标,评价装备质量优劣的必要手段,其发展不仅需要前沿的研发技术支撑,同时需要先进的管理系统提供支持[5]。
随着各类装备的不断改进,试验数据来源的不断扩展,现有的基于人工的采集整编系统无法满足数据管理完整性、高效性、便捷性的要求。为此,胡晓枫等设计了一种采样大数据架构的装备试验数据管理平台,将在线采集、离线采集等方式采集的数据进行汇聚整合,并通过分布式数据存储系统对试验数据进行高效存储,有效提升装备数据管理能力[6]。叶海明等梳理了试验数据采集整编的标准化思路,开发了自动化数据采集系统,实现多源异构试验数据的连接及作战试验主数据的获取,有效地提升了数据的采集效率,降低了人力需求[7]。
上述研究从数据采集、数据存储等方面进行探索,取得了初步的成果。但针对现有试验数据来源广、维度多、类型杂等大数据特点,存在以下不足:1)无法直观展示数据中实体与关系,如装备之间的关系等;2)无法快速、准确、智能地推荐数据的相关信息,实现数据高效利用。
1.2 推荐算法应用
大数据时代信息过载问题为人们搜索及管理数据带来了困扰。推荐系统通过对用户的行为数据分析,捕获用户的行为习惯及兴趣偏好,从而提升信息数据分配和获取的效率。
自从推荐系统的概念被提出以来,推荐算法的应用领域不断扩展,如新闻、影视、电商、医疗、军事等。传统基于内容的推荐算法,对项目的特征进行分析,从而为用户推荐相似项目。例如艾楚涵等从专利的文本信息中构建词袋模型,从文本的摘要和标题等特征中学习不同专利之间的相似度,实现了针对不同发明人的个性化专利推荐系统[8]。另一种被广泛应用的协同过滤推荐算法通过分析用户的反馈数据,学习用户或项目之间的相似度,从而为用户推荐可能感兴趣的项目。ZHANG R C 等将矩阵分解技术应用到协同过滤算法中,提高了电影评分预测的准确率,从而进行有效的电影推荐[9]。
由于项目的特征信息和用户与项目间的交互信息相对匮乏,因此,传统推荐算法普遍存在数据稀疏问题。近年来,研究者尝试在推荐系统中加入额外的辅助信息,如标签、图像、文本、知识图谱等。冀欣婷提出融合标签和知识图谱(combining tag and knowledge graph for recommendation,CTK)的模型[10],通过给用户标注的项目标签信息和知识图谱中丰富的项目属性信息,提高推荐结果的准确性和可解释性。
然而,现实场景中的推荐任务更为复杂,数据来源更为广泛。为此,本文通过试验数据的相关标签及标签实例构建知识图谱,设计一种智能推荐方法,不仅实现多源异构信息的融合,同时为试验数据管理提供支撑。
2 方法设计
下页图1 为该方法的总体设计图,共分为4 部分:标签本体构建部分、标签实体特征提取部分、标签与标签实例映射部分以及用户智能推荐部分。其中,标签本体构建主要包括从结构化数据、半结构化数据、非结构化数据中,采集装备数据和构建被试装备、试验任务、试验装备、陪试装备、试验人员等本体标签库;随后,从音频数据、图像数据、纸质数据、文本数据、视频数据中提取标签实体特征;然后,利用基于规则的方法和基于自然语言处理的方法完成标签与标签实例间的映射;最后,结合用户使用标签信息和标签特征信息进行试验数据智能推荐。

图1 标签及标签实例推荐方法的总体设计Fig.1 Overall design for tags and tag instances recommendation
该方法可采用完全硬件实施、完全软件实施或结合软件和硬件的形式实施。能够将试验数据采集的多结构化数据,通过构建标签与标签实例库,从海量试验数据中,实现结合用户偏好以及标签特征,智能化精准地为其推荐标签并进行可视化展示。
2.1 标签本体构建
本体是由概念组成的体系,强调了概念之间的关系。标签是对实体的概念性描述,可以有效地表述实体。根据不同来源的数据进行标签本体构建,具体可分为试验数据采集和构建本体标签库两部分。
2.1.1 试验数据采集
试验数据主要通过纸质数据方式、电子文件方式、结构化数据方式获取,根据不同的数据来源,设计不同的数据采集方法提取结构化数据、非结构化数据以及半结构化数据。对于结构化数据可以通过直接映射的方法从现有关系数据库获取;半结构化数据如网页数据通常以键值对出现,因此,可以通过手工方法或利用监督学习方法,从已标注的数据集中学习抽取规则进行自动抽取;非结构化的文本数据利用自然语言处理技术进行实体和关系抽取。同时,提取各样数据中的数据要素,例如装备标识、装备名称、试验数据采集时间、试验任务等相关信息。
2.1.2 构建本体标签库
在数据本体概念构建中,本体是对领域内的不同实体概念、属性及其相互关系进行抽象和约束而得到的一种规范[11]。领域内数据集主要面向领域相关人员服务,对本体的要求较高。本体构建首先需要确定本体领域与范围,随后列举本体中的关键项并确定类和类的结构。图2 为装备本体构建示意图。通过对装备数据的了解和剖析,采用树形图对采集到的试验数据类型和属性进行分类,构建被试装备、试验装备、陪试装备、试验任务和试验人员等本体概念,创建标签库。

图2 装备本体结构示意图Fig.2 The structure for weapon ontology
2.2 标签实体特征提取
将2.1.1 中采集到的数据,实现多模态数据的实体特征提取,从而构建实体标签实例。其中主要多模态数据包括:图像数据、文本数据、音频数据、视频数据以及纸质数据。对于不同数据来源的特点,针对性地提出不同算法进行标签实体特征提取。
2.2.1 图像数据
针对图像数据,采用基于改进的卷积神经网络模型的图像目标识别算法[12],首先将原始图像中的装备目标进行标记,并将其转换为224*224 的标准图像,输入到卷积神经网络模型,进行图像特征提取,在每层卷积层以及Inception 层的输出口添加一个压缩、激励(squeeze and excitation,SE)模块更新图像特征参数的权重,接着接入池化层对卷积层和Inception 层输出的特征进行降维处理,将池化操作输出的结果输入到全连接层中转化为一维向量,最终输入至softmax 分类器中输出识别结果,通过使用改进的卷积神经网络模型的图像识别模型,识别出图片中的装备类型以及装备在图片中的位置,从而进行图片中的实体标记。
2.2.2 文本数据
针对中文文本试验数据,使用深度学习方法,对文本中的实体进行识别。首先,整理包含名词的词典,包含国家重要人物名称以及装备名称,构成领域词典;然后,选取一些包含本体概念的文本人工进行标注,标注出国家,装备以及重要人物的名词,使用中文词典和深度学习网络LSTM-CRF 模型[13],对已经标注的数据进行模型训练,将训练好的模型,对大规模文本信息进行实体识别;使用关键词抽取模型以及设定规则的关系抽取模型,获取出文本中已经抽取出的实体与实体之间的关系特征,从而获取到文本中的实体与关系信息,构建标签实例库。
2.2.3 音频数据
将获取到的试验音频数据,获取音频的时间长度、比特率以及采样率等信息,使用卷积神经网络捕获音频在不同频域的响度随时间变化的特征,使用支持向量机(support vector machine,SVM)的分类方法,在音频特征样本空间中寻找一个将训练集中的正例和反例两类样本点分割开来的分类超平面,并对音频数据进行分类,从而识别标签实体信息。
2.2.4 视频数据
将获取到的视频数据,获取视频的时间长度,编码格式、编码标准以及比特率特征进行提取,同时,使用基于聚类的方法和对视频进行关键帧提取,提取视频中的实体,针对通用视频中的关键帧提取,使用基于聚类的方法,利用视频帧之间的相似度将帧对象进行分组,使得类似的帧对象成为一个簇,从而将视频划分为不同的聚类,使得类内部的视频内容上相似,而类间视频在内容上有很大差别,最后将每个聚类中最靠近聚类中心的视频帧加入结果集。
对于运动类视频数据的关键帧提取,使用融合多路特征和注意力机制的强化学习关键帧提取算法[14],该算法使得视频特征提取过程无须镜头分割和人工提取特征,该算法通过融合特征思想,首先使用深度神经网络分别提取视频帧中的运动特征和静态特征,并将其进行融合,然后使用自注意力机制提取视频序列的全局特征,随后根据全局特征计算各个视频帧的重要性程度,从而获取到视频中的关键帧。
2.2.5 纸质数据
针对数据来源为纸质的数据,使用光学字符识别(optical character recognition,OCR)技术,对文本资料对应的图像文件进行分析、识别和处理,其中包括获取文字及版面等信息的过程。随后识别图像中的文字,并返回文本的形式。使用基于CRNN 的深度学习模型[15],利用卷积神经网络(convolutional neural networks,CNN)做图像特征工程的优势与长短时记忆网络(long short-term memory,LSTM)做序列化识别的优势相结合,不仅提取了数据的鲁棒特征,同时能够通过序列识别避免了传统算法中难度极高的单字符切分与单字符识别。此外,序列化识别中也嵌入时序依赖,能够将纸质文字通过OCR 技术转换为文本数据,再通过文字识别技术,对识别出的文本进行实体识别,关键词抽取以及实体关系抽取操作,获取到纸质数据中的实体和实体关系信息。
2.3 标签与标签实例映射
通过构建本体概念,确定数据标签,通过抽取到的图像、视频、文本、音频、纸质数据特征,获取实体信息,从而构建标签实例。基于本体概念模型,采用多策略综合的方法[16],包括基于规则的映射方法和基于语义的映射方法,从各类形式的数据中,进行标签与标签实例映射,获取到<标签1-关系-标签2>和<标签1-关系-标签实例>的三元组信息,并填充到当前的本体映射中,具体方法可分为基于规则的映射和基于语义的映射。图3 为标签与标签实例映射关系图。其中被试装备标签与装甲车、飞机、坦克等多个装备标签实例映射,测试标签隶属被试装备标签。

图3 标签与标签实例映射关系图Fig.3 The mapping relationship between a tag and tag instances
2.3.1 基于规则的映射
基于规则的映射主要依靠先验知识。标签之间的层次结构是一种较强的先验知识,即已知标签实例属于某个标签子类的情况下,进而推测出实体也属于相应概念的父类。如测试标签隶属被试装备,则测试标签中包含的标签实例同样属于被试装备。使用关联规则挖掘方法[17],查找各标签之间的关系,筛选基于标签本体概念和标签实例关系程度高的标签实例,将其填充到规则模型中,利用监督学习的支持向量机模型,对待挖掘的标签与标签实例进行映射关系预测,最后,通过人工核查预测结果,将预测出正确的每一个标签下对应的标签实例,丰富到属性集中。基于规则的分类方法具有简单高效,准确率高的优点,但仍需要人工不断编写和完善规则。
2.3.2 基于语义的映射
针对无法使用关联规则提取的属性,利用提取句子之间的句法关系和词与词之间的语义关系的方法,使用基于RoBERTa 与实体边界预测的方法[18],包括文本编码模块、实体边界预测模块以及BiLSTM_CRF 属性预测模块[19],首先通过RoBERTa 对输入文本进行编码,获取其隐含层状态向量,然后将其分别输入实体边界预测层与BiLSTM_CRF 属性预测层。在实体边界预测层,采用0/1 编码的方式标注实体头部与实体尾部,然后计算两个序列标注的损失值start_loss 与end_loss,在BiLSTM_CRF 属性预测层,首先将实体边界预测层的输出结果作为特征,并将其与文本向量拼接,输入至BiLSTM_CRF对文本属性标签进行预测,然后计算其损失值att_loss,最后,在模型优化时,综合考虑3 个损失值,并对其进行加权求和,通过反向传播实现模型整体的优化,得到候选属性的列表最后形成属性。
2.4 智能推荐
基于用户特征和标签实体特征融合的推荐方法如图4 所示。通过提取用户信息,例如用户所属组织、级别、所属任务、负责的资源、用户使用习惯以及最近一次使用标签信息,提取用户信息的特征表示,与提取到的标签实体特征表示融合,经过融合注意力机制得到用户特征和标签实体特征的融合,训练网络模型,从而推荐与用户相关的标签,通过标签库查询技术推荐标签实例的相关信息,并可视化展示。
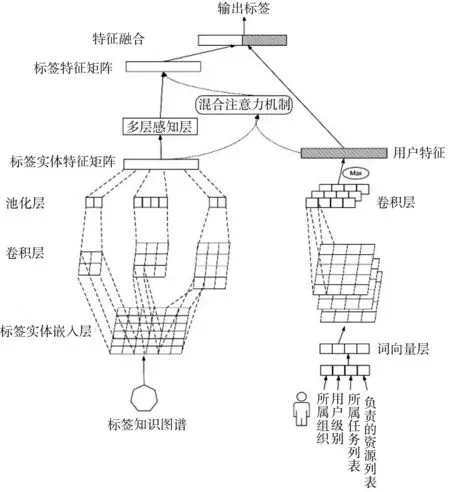
图4 标签推荐模型Fig.4 Tags recommendation model
2.4.1 提取用户特征
在数据库中选择用户的相关信息,如用户所属组织、级别、所属任务、负责的资源、用户使用习惯以及最近一次使用标签信息对用户特征进行建模。首先通过预训练词向量得到用户信息的向量值,然后将用户表示向量输入到卷积神经网络,进行卷积和池化操作,提取与用户相关的信息特征,形成用户特征矩阵。
2.4.2 提取标签库标签特征
将从标签库中获取到标签实体,记作ekj,ekj代表第k 种关系所对应的标签实体集合中的第j 个实体,分别将不同关系对应的实体映射到低维向量空间中,得到标签—实体嵌入矩阵,将矩阵送入到KGC NN 模型中得到标签—实体特征矩阵Sr[20]。卷积层中通过不同窗口的大小提取标签—实体特征,对嵌入矩阵中的每一个可能的位置进行滤波处理,最后使用最大池化方法进行特征选择,得到实体矩阵Sr。
其中,Er表示标签—实体的嵌入矩阵,G 表示特征提取的滤波核,⊙代表点积操作,relu 表示非线性激活函数,b 表示relu 的偏置参数,max 表示最大池化操作。
2.4.3 融合用户特征和标签实体特征
将标签—实体特征矩阵Sr和用户—项目标签嵌入矩阵T 一同作为混合注意力模型的输入,计算不同关系标签—实体的混合注意力权重aT。
其中,aT表示注意力权重,函数是一个矩阵相乘函数,Tu与S 相乘后,经过函数归一化得到注意力权重。
将KGCNN 模型的输出结果与标签特征矩阵一同送入多层感知器(multilayer perceptron,MLP),通过MLP 中多个全连接的神经网络层进行训练之后,再与混合注意力权重相乘得到标签实体特征矩阵I。
2.4.4 标签及标签实例推荐
利用混合注意力机制将用户特征和标签实体特征融合,经过全连接层,最终得到与用户相关的标签。将得到的标签在已经建立的标签及标签实例知识图谱中,通过查询技术,得到与用户相关的标签及标签实例,并进行可视化展示,形成推荐。推荐结果不仅能够直观地显示相关的实体与关系信息,同时提高了推荐数据的准确性和便捷性。
3 实验与分析
3.1 实验数据集
本节使用的第1 个数据集是Group Lens 实验室提供的Movie Lens 电影评分数据集,该数据集采取CF 和关联规则相结合的方法进行推荐,本文使用的是ml-latest-small(以下简称ml-ls)数据集,该数据集是Movie Lens 的最新版本。此外,本文还根据该数据集中的电影实体定义了3 种关系,分别为film_director、film_stars 和film_publish,通过对IMDb网站进行网页爬取获得相关信息,构建电影领域的小型知识图谱,如表1 所示。
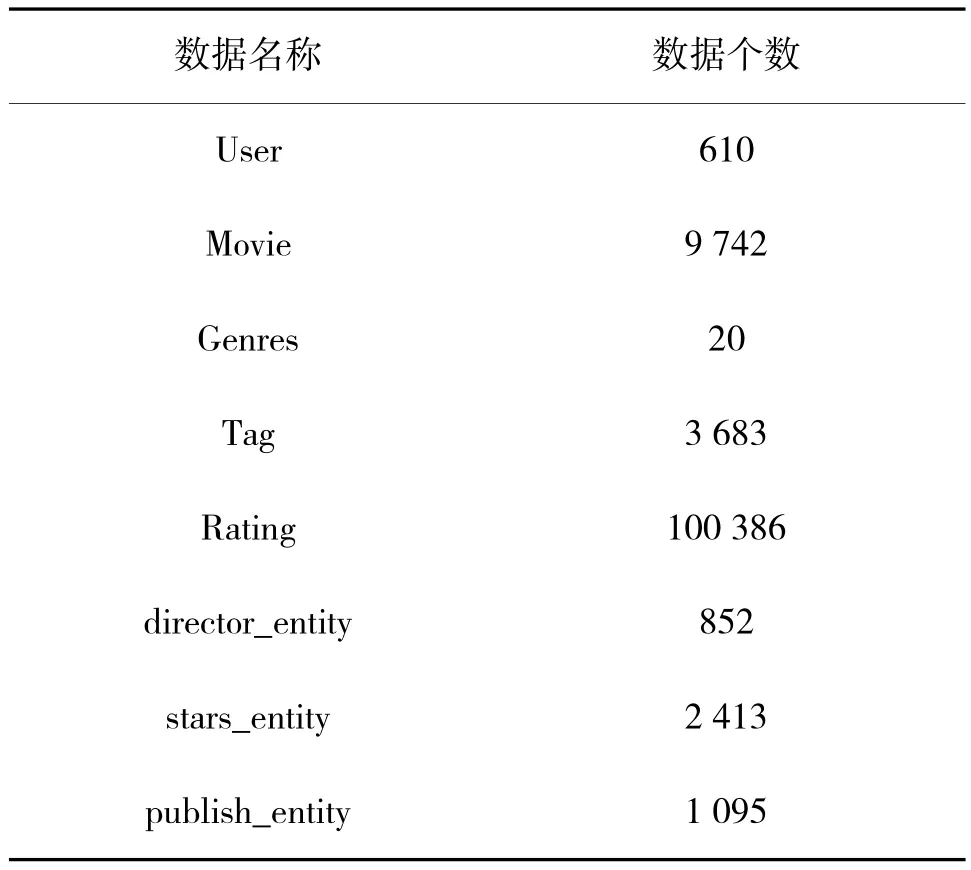
表1 ml-ls 数据集基本信息Table 1 Basic information of the ml-ls dataset
本节使用的第2 个数据集是自制试验数据数据集,该数据集包括装备实体,标签信息包括被试装备、试验装备、陪试装备、试验任务和试验人员,定义关系类型包含聚合关系、隶属关系、关联关系和继承关系。利用实体与关系构建知识图谱。具体信息如表2 所示。
3.2 实验参数设置
将实验数据随机分为训练集和测试集,使用的编译软件为Jupyter Notebook 和Pycharm,编译语言为python,模型框架使用Tensorflow 框架,基于python3.6 版本在Ubuntu18.04 操作系统环境下进行多次实验。模型的主要参数如表3 所示。

表3 实验参数设置Table 3 Experimental parameter settings
3.3 实验评价指标
本文采用平均绝对误差(mean absolute error,MAE)、均方误差函数(mean squared error,MSE)和ROC 曲线下的面积(area under curve,AUC)作为评测指标[10],下面将分别对其进行说明。
平均绝对误差是绝对误差的平均值,它能更好地反映预测值的误差情况,数值越小代表模型越好。
均方误差函数一般用来检测模型的预测值和真实值之间的偏差,是这两个值的差的平方的期望值。该值越小,说明模型的预测能力越好。
AUC 是一类用来衡量分类结果好坏的性能指标,AUC 的值越大,代表分类器的效果越好。本文将用户喜爱的物品作为正样本,不喜爱的物品则作为负样本,通过统计其正样本预测值大于负样本预测值的个数,除以样本数量,得到AUC 的值。该值越大,说明模型的分类能力越好。
3.4 实验结果分析
在本实验中,使用BOW、MFMP 两个基线模型进行对比实验。
BOW[8]:第1 个基线是词袋模型(bag-of-words,BOW),词袋模型作为基于内容的推荐,利用用户的one hot 词向量特征进行向量求和。但词袋模型不适用于用户信息,而是基于实体数据特征进行推荐。
MFMP[9]:该基线是基于Markov 矩阵分解的推荐模型,常用于协同过滤算法中。在本实验中,该基线所使用的数据同BOW 模型一样,只利用原数据集中提供的一些数据。
在实验中,本文使用基线模型和本文提出基于用户特征和标签实体特征融合模型在公开数据集ml-ls 数据集进行对比,对比分析结果如表4 所示。

表4 不同模型实验对比结果表Table 4 The comparison between different model results
通过对比基线模型和本文提出的模型在ml-ls数据集上MAE、MSE 和AUC 的性能指标值,本文模型相比BOW 和MFMP 的平均绝对误差(MAE)和均方误差值(MSE)分别下降了8.82%和5.56%,证明了该模型在推荐结果上的稳定性;AUC 指标提升13.33%,说明模型能够有效地利用用户信息以及标签信息,挖掘标签信息的特征,从而更好地挖掘潜在的语义空间以及用户之间关联信息。相比之下,BOW 和MFMP 仅利用电影的特征信息而忽视了用户特征对其偏好建模的重要性。此外,本文模型在融合用户特征和标签实体特征中使用卷积神经网络模型,能够更好地对实体中的特征进行抽取和利用,更有效地提高了推荐系统的稳定性和准确性。
进一步地将本文提出的基于用户特征和标签实体特征融合模型在自定义领域数据集——试验数据集进行实验,实验结果与开源数据集ml-ls 上结果相近。通过对比两个数据集,如表5 所示,发现ml-ls 中包含了更丰富的实体信息和电影评分数据,这对推荐系统的性能提供了有效的帮助,而试验数据集中融合了更复杂的用户—标签以及标签—标签间的关系信息,这无疑增加了推荐的难度。最终的实验结果证明该方法适用于不同领域数据集,能够在更复杂的领域场景下进行有效的推荐。

表5 不同数据集下模型实验结果Table 5 Model results under different datasets
4 结论
本文提出一种面向试验数据的标签及标签实例推荐方法。针对试验数据的多模态化,使用多种方法有效抽取多模态数据的实体与实体关系信息,使用基于规则的映射方法和基于语义的映射方法,对标签本体与标签实例进行映射,最终根据用户特征和行为特征进行标签推荐。
该基于用户特征和标签实体特征融合的推荐方法,优势在于考虑到了用户自身特征,使用标签记录以及用户标签偏好,同时利用基于注意力机制的KGCNN 网络模型,学习到标签的语义特征和用户复杂行为特征对推荐的影响,推荐结果更加准确有效。目前,本文提出的面向试验数据的标签及标签实例推荐方法,已应用于研制的历史数据采集整编软件中,并支撑各单位试验历史数据的数据特征提取、标签推荐等应用。
