数字科技馆智能管理系统设计
2023-11-19成海民付桂琴贾俊妹刘瑜珊
成海民,付桂琴,贾俊妹,刘瑜珊
(河北省气象服务中心,河北 石家庄 050021)
0 引 言
数字科技馆采用互联网信息技术,建立“永不闭馆”的线上科技馆,融科学性、互动性、趣味性于一体,通过VR 体验、互动游戏、浏览学习等方式[1-6],全时空、系统性地向公众普及科学知识、开展科普教育,激发公众探索科技奥秘的兴趣,启迪科学观念,努力为公众营造从实践中学习的网络情境[7]。集科普展示、游戏互动、虚拟体验于一体的数字科技馆的安全、顺畅、稳定运行,需要功能齐全、稳定可靠的智能管理系统做支撑。数字科技馆的智能管理系统主要包括科普展厅管理模块和数据处理模块。
1 技术方法
1.1 数据持久化服务
数据存储采用SQL Server关系型数据库[8],通过使用性能高、速度快的Dapper.Net 的ORM 与数据库进行交互,减少不必要的与数据库进行连接、读取、写入等底层交互代码。对Dapper.Net 进行了二次封装,同时减少了重复代码、冗余代码,精简了代码量,提高了运行效率。
1.2 权限验证服务
通过使用.net core 的中间件技术,对所有访问请求进行拦截;通过读取每个请求头中的Authorization 的token 内容(token 是通过登录接口产生),对token 进行解析和验证处理;通过合法的token 来获取其对应的用户信息[9],如用户名、昵称、用户类型、角色等,并把这些用户信息记录到当前请求中,在同一请求以后的所有操作中都可以获取当前用户信息,并可以基于当前用户角色和权限来判断是否可以访问对应的请求接口,增加系统的安全性和保密性。
1.3 异常处理服务
通过使用.net core 的中间件技术,对所有访问的请求进行拦截,当发生异常时,系统记录异常的详情信息,如异常内容、发生位置、代码位置等,这些异常详情信息会记录到数据库中,方便快捷地跟踪、定位、解决异常问题,提高响应速度。其次,把异常信息的拦截放到全局范围,与正常的业务逻辑分离,减少冗余代码量,保证业务逻辑代码的精简、高效。
1.4 功能日志服务
通过使用.net core 的中间件技术对所有访问的请求进行拦截,记录当前请求的所有信息,如请求头、请求路径、请求内容等,这些信息记录到文件中,可以配置异常处理服务,方便重现异常、定位异常原因、解决异常问题。
1.5 业务功能模块服务
采用传统的三层架构来开发业务功能模块,每一层的职责更加清晰明了[10]。采用IOC 框架减少代码之间的耦合程度,同时在Service 层添加AOP 的拦截,把一些公共、与主业务逻辑代码无关的操作抽离出来,如缓存、事务、日志等,大大减少了重复代码,并且使主业务逻辑代码更加清晰,减少了潜在的维护成本。
2 系统设计
2.1 科普展厅管理
图像采集模块对展览空间进行三维图像或三维场景采集,并基于展览空间的三维图像或三维场景生成平面图和三维图;同时对展览空间内各展项进行三维图像采集,使得展厅内展览空间和全部展项更加具有真实性和完整性。
展示模式包括点击展示和搜索展示,由参观人员自主选择。点击展示为点击三维图展示区域中各展项,从而对该展项对应的展示界面进行显示;搜索展示为点击搜索框,输入对应的展项名称,进而对搜索的展项名称对应的展示界面进行显示。
展示效果评估用于对各展项的关注度系数和各展项对应的倾向情感类型进行评估,包括展项关注度分析和评论倾向分析。
1)展项关注度分析。在设定展览时间段内,对各展项对应的观看频次进行统计,包括各展项对应的点击量和搜索量,并将各展项对应的点击量和搜索量进行累加,得到各展项对应的观看频次,记为GPi,GPi为第i个展项对应的观看频次;在设定展览时间段内,获取各展项对应的单次观看时长并进行累加,得到各展项对应的观看总时长,记为KSi,KSi为第i个展项对应的观看总时长;在设定展览时间段内,获取各展项对应的单次讲解语音倾听时长并进行累加,得到各展项对应的讲解语音倾听总时长,记为TSi,TSi为第i个展项对应的讲解语音倾听总时长;将各展项对应的点击量和搜索量分别记为DIi、SUi,DIi、SUi分别为第i个展项对应的点击量和搜索量,将DIi、SUi代入式(1)可得:
式中:ZMi为第i个展项对应的展示模式影响指数;a1、a2分别为点击展示和搜索展示对应的权重值。
基于各展项在设定展览时间段内的观看频次、观看总时长、讲解语音倾听总时长、展示模式影响指数评估各展项的关注度系数,得出展项的关注度系数公式:
式中:ηi为第i个展项对应的关注度系数;N为所有展项对应的观看频次总和;b1、b2、b3和b4分别为观看频次、观看总时长、讲解语音倾听总时长和展示模式影响指数对应的影响因子[11];KS′i为第i个展项观看时长对应的参考值;TS′i为第i个展项对应讲解语音时长参考值。
2)评论倾向分析。设定褒义、中性和贬义三种评论情感类型,提取展项每条评论的情感关键词[12-13],与云存储库中的评论情感关键词相匹配,得到相应的评论情感类型。
将所有展项对应的每条评论的情感类型进行梳理,把相同情感类型对应的评论归类,形成所有展项对应各情感类型的评论集合,根据评论集合统计各展项对应的倾向情感类型。
具体方法为:统计所有展项对应各情感类型的评论数量,筛选出每个展项评论数量最多的情感类型,并统计各展项评论数量最多的情感类型数量,若某个展项中评论数量最多的情感类型数量只有1 个,则该情感类型即为该展项的倾向情感类型,若某展项中评论数量最多的情感类型数量有2 个,则需要进一步识别;若情感类型为褒义和贬义,则该展项的倾向情感类型为中性;若情感类型为褒义和中性,则该展项的倾向情感类型为褒义;若情感类型为贬义和中性,则该展项的倾向情感类型为贬义;若某展项中评论数量最多的情感类型有褒义、中性和贬义3 个,则该展项的倾向情感类型为中性。评论倾向分析流程如图1 所示。

图1 评论倾向分析流程
2.2 留言数据处理
留言板服务器的留言业务数据包括留言数据和回调接口,其中回调接口与留言板服务器一一对应。留言板服务器将业务数据发送至审核服务器,审核服务器解析留言数据的数据类型,与目标审核方法进行匹配,依据匹配的目标审核方法对留言数据进行审核,判定留言数据是否合规,并生成审核结果[14]。
对于图片类型的留言数据,如果图片中没有文本数据,则进入图片识别模型进行识别并分类,再按照预设的图片分类标准标记图片。当图片分类为正常时,表明图片中不存在违规信息,图片数据通过审核;当图片分类为异常时,表明图片中有违规信息,图片数据未通过审核。
如果图片中有文本数据,则使用OCR 技术提取图片中的文本数据,并与数据库中的关键词进行对比,若数据库中有与该文本数据相同的关键词,表明可以建立该条文本数据与关键词之间的映射关系,该条留言数据具有违规信息,审核结果为不通过[15]。若该文本数据不存在与数据库中相同的关键词,则将文本数据和预设的关键词输入文本相似度模型,输出两个文本的相似概率,根据相似概率和预设阈值判断该文本数据是否通过相似度审核,若通过相似度审核,则建立文本数据与关键词之间的映射关系,表明该条留言数据具有违规信息,审核结果为不通过;若未通过相似度审核,则表明该条留言数据没有违规信息,审核结果为通过。图片数据审核流程如图2 所示。
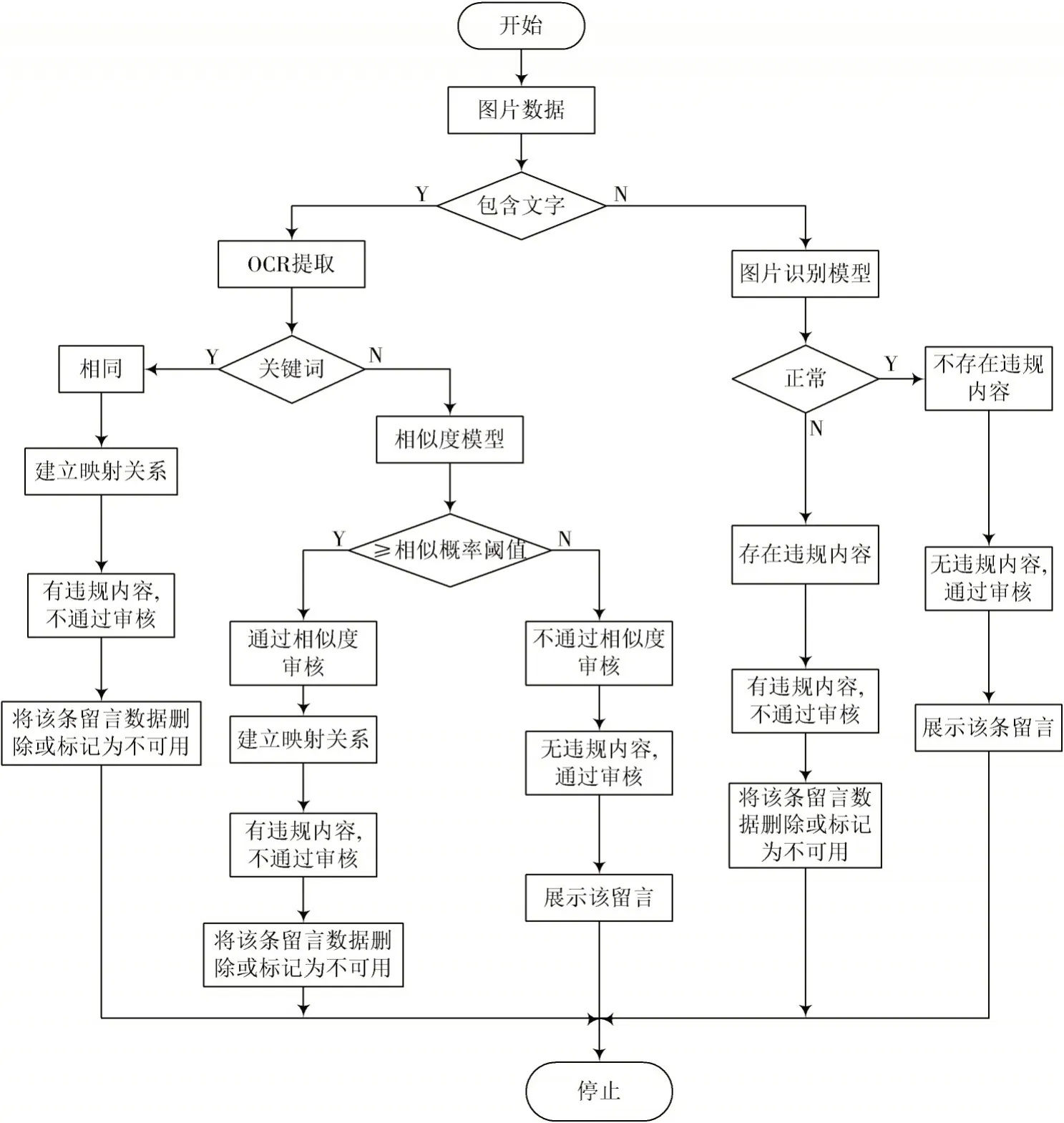
图2 图片数据审核流程
调用回调接口,将审核结果发送至留言板服务器,当留言板服务器接收到的审核结果是通过时,表明可以展示对应的留言数据,比如将评论内容发布到公共端,或将文章公开到公共平台等。
当留言板服务器接收到的审核结果为不通过时,可以直接删除对应的留言数据,也可以将对应的留言数据标记为不可用,禁止将其发布到公共端或者在留言展示区展示等。
2.3 线上商城数据处理
当用户在数字科技馆的线上商城浏览商品时,会进入到商品搜索页面,用户在商品搜索页面输入搜索指令,获取相应商品的数据信息[16],数据处理系统运用特定的推荐逻辑实现商品精准推荐。
1)数据获取
数据获取模块获取用户的历史购买报告,数据提取模块对历史购买报告进行文本提取,根据历史购买报告的文件格式,采用相应的文本提取方法[17]。历史购买报告可以是PDF,jpeg、png 等图片格式以及Word 格式。PDF 形式的购买报告可通过基于Java 的、支持PDF 文档制作的Apache PDF box 工具库获取用户购买报告的整份报告内容或报告中某页的文本信息;jpeg、png 等图片格式的购买报告可通过OCR技术获取用户购买报告的文本信息;Word格式的购买报告可使用poi、poi-ooxml或poiscratchpad框架提取用户购买报告中的文本信息。
提取的报告文本中的关键词包括商品名称和商品价格,并依次通过商品-商品标签映射表获取关键词所对应商品的商品标签,商品标签可以是多级标签,例如,与马克杯对应的商品标签包括:杯-A1、杯-A2、杯-A3。其中,“杯”代表马克杯的大类标签,A1、A2、A3代表等级划分。等级划分基于商品价格可预设不同的价格区间,不同区间对应不同等级划分标签。当商品价格位于相应的价格区间时,对该商品映射相应的标签,通过对商品进行标签划分,可以准确地获取商品的属性信息[18]。
2)数据分析
数据分析模块将当前用户历史购买报告中的商品标签和属性信息输入商品推荐模型,得到输出结果,依据输出结果生成推荐商品的推荐集[19]。商品推荐模型为多分类多标签深度神经网络模式,内部神经网络层由输入层、两个或多个隐含层及输出层组成,各层之间完全连接,即第i层的每个神经元一定与第i+1 层的每个神经元相连通[20-21],结构图如图3 所示。多分类多标签深度神经网络模式以当前用户历史购买记录中的商品标签和用户的基本属性作为参考,在商品推荐时通过对商品类别的加权统计,确定推荐的商品。

图3 神经网络结构
多分类多标签深度神经网络模式的训练方法是将线上购物的每个消费者的购物记录中的商品标签、消费者属性和实际购买商品作为资料集,自动学习消费者基本属性以及商品标签与实际购买商品之间的关系[22]。
神经网络模型通过将当前用户历史购买报告中的商品标签与当前用户的属性信息进行对比,得到同一类别标签所有商品的推荐系数,并按照推荐系数的比例得到推荐商品的推荐集。例如,当前用户的搜索指令为“马克杯”时,神经网络模型在用户历史购买报告中为“杯”的商品标签与搜索指令进行匹配,并获取商品的推荐系数;同时,可预设推荐阈值,以推荐系数大于或者等于推荐阈值的商品构建推荐商品的推荐集。
3 结 论
本文设计一种数字科技馆的智能管理系统,该系统主要包括展厅管理、留言数据分析、网上商城数据分析等部分。
科普展厅管理模块通过设置互动展示区域实时显示参观人员对其观看展项的评论,根据评论分析出各评论对应的展项主体,进而对各展项对应的各条评论进行情感类型分析,判断参观人员对各展项的倾向情感类型,从根本上提升了参观人员对科技馆展厅内各展项了解程度的全面性。
留言数据分析系统通过留言数据和回调接口的业务数据解析和审核,有效提高了留言数据的准确性;同时,采用识别模型提高了留言数据审核的准确性。模型识别过程可有效提高图片数据和文本数据的识别效果,提升留言数据审核的准确率和审核效率。
网上商城数据采集分析系统根据用户的历史购买报告以及用户的搜索指令为用户推荐合适的商品,为不同用户提供不同推荐商品集。通过分析已有用户的购买报告及基本属性,并加入用户当前的商品选择操作对应的用户属性、商品标签和实际购买商品信息,使商品推荐模型得到进一步的训练优化,以提高后续商品推荐的准确性。采用的多分类多标签深度神经网络模式通过了解当前用户的购物偏好,持续学习,提高推荐准确度,给用户带来正确的商品选择信息,从而提升用户对商品的购买力。
