基于文本解析的栅格类图表知识抽取方法
2023-11-06黄梓航陈令羽蒋秉川
黄梓航,陈令羽,蒋秉川
(1.战略支援部队信息工程大学 研究生院,河南 郑州 450001;2.战略支援部队信息工程大学 地理空间信息学院,河南 郑州 450001)
图表将繁冗的数据以直观形象的形式展现出来,在地理信息表达和传输等领域应用广泛[1-2]。随着互联网技术的不断发展,泛在图表成为大众接收各类信息的主要渠道之一,包含了大量具有重要价值的各类信息,通过爬取解译可为具体应用提供数据支撑。图表数据和时空数据相结合,可以极大程度提升人类的空间感知和认知能力。特别是人工智能技术的不断进步,为计算机快速理解和应用这类图表数据提供了新的技术支持,丰富了图表数据的应用领域和层次。
网络数据中的泛在图表按照数据类型可以分为2 种:一种是矢量型图表,数据可以通过访问对应的数据库直接进行提取;另一种是栅格型图表,本质上就是栅格型数据图像,文件中记录的是不同位置上的像素值,依靠计算机视觉技术进行信息提取。矢量数据的解析主要停留在数据层面的处理上,方法相对成熟,研究栅格类图表数据的智能解析成为热点和难点问题[3-7]。
图表数据在形成过程中经过了一定程度的综合,实现栅格图表的完全解译难度很大。针对海量泛在图表,能够快速根据特征标签检索出对应的信息,再进行针对性的数据解译更符合时空大数据的研究规律。本文通过分析图表结构,解析关键文本信息,抽取图表中的关键知识,构建图表特征标签体系,具体方法如图1所示。
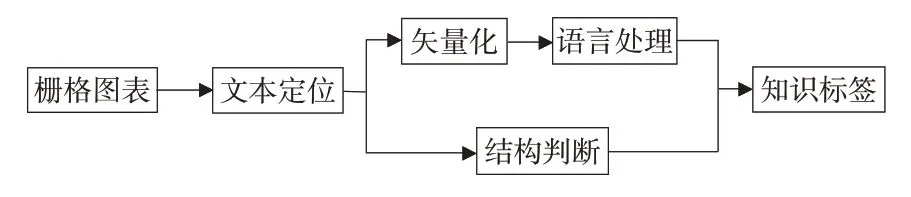
图1 栅格类图表数据知识标签体系构建流程
1 图表文本定位与矢量化
图表文本定位与矢量化是从栅格图表中提取出文字信息的位置和内容,将图表中的所有可能的知识识别出来,为知识标签判断提供基础,包括离线识别和在线识别2 种方法。在线识别主要是借助主流的云工具,例如腾讯云、百度云、阿里云等,提供了相应的文字信息位置判断和识别的在线服务,能够为图像数据中文字信息的快速识别和分析提供相应接口,且具有很高的准确性和效率,但仅支持互联网情况下的识别,对应的离线工具价格昂贵。离线识别不需要连接互联网,主要通过文本检测和内容识别2个环节抽取文本信息[8-11]。综合分析现有方法和图表数据的特点,采用CRAFT+CRNN 的方法进行文本定位与矢量化[12-14]。
1.1 基于CRAFT的文本检测与定位
基于CRAFT检测文字区域的基本原理是设计一个深度神经网络,通过预测单个字符的高斯热图以及字符间的连接性来检测文本。其主要思想是:
1)图像分割,采用u-net结构,先下采样再上采样,聚合深层和浅层特征。
2)非像素级分割,将一个字符视为一个检测目标对象,而不是一个词组(所有的词组都由若干个字符构成),即不把文本框当作目标。
3)标注时采用文本框级别的标注,而非字符级别的标注,并使用了一种弱监督学习思路(先利用合成样本进行预训练,再将预训练模型对真实数据集进行检测,得到预测结果,经过处理后得到高斯热度图作为真实数据集的字符级标签)。
由于CRAFT 方法具有先进的性能和良好的泛化性,特别适合于栅格类图表中各类文本的检测和定位。
1.2 基于CRNN的文字内容矢量化
文字识别是对序列的预测方法,CRNN 采用了对序列预测的RNN 网络。通过CNN 将图片的特征提取出来后采用RNN对序列进行预测,最后通过一个CTC的翻译层得到最终结果。主要采用的是CNN+RNN+CTC三层网络结构,从下到上,依次为:
1)卷积层,使用CNN,从输入图像中提取特征序列。
2)循环层,使用RNN,预测从卷积层获取的特征序列的标签(真实值)分布。
3)转录层,使用CTC,把从循环层获取的标签分布通过重新整合等操作转换成最终的识别结果。
泛在栅格类图表的质量难以得到保证,噪声和干扰信息多、图像不清楚的情况普遍存在。在进行文本矢量化之前,可先进行灰度变换、滤波操作、图像二值化等图像预处理,减少无关信息,在一定程度上恢复包含的文本特征信息从而增强特征可检测性和矢量化效果,提高提取的效率与准确率。
2 文本块结构判断
图表隶属于视觉传达信息的范畴,将知识、信息的概念和统计数据等进行视觉整理,用形状、颜色和文字、数字来表达,视觉化某种事物的现象或某种思维的抽象观念,以生动的表达形式传递信息,蕴含丰富的知识体系和内容,具有直观性和易懂性的特征。通过对图表的结构进行拆分,从各个文本块对应的结构特征上对图表的信息表达进行研究,是进行知识标签构建的关键环节[15]。
2.1 图表数据的结构解析
根据表现形式,可以将图表分为柱状类图表、线状类图表、点状类图表、多边形类图表和其他类图表等6 种类型。图表蕴含的丰富信息,主要通过图表结构形式表现出来,不同的结构中包含的文字、数字内容,能够解译出不同的信息内容。
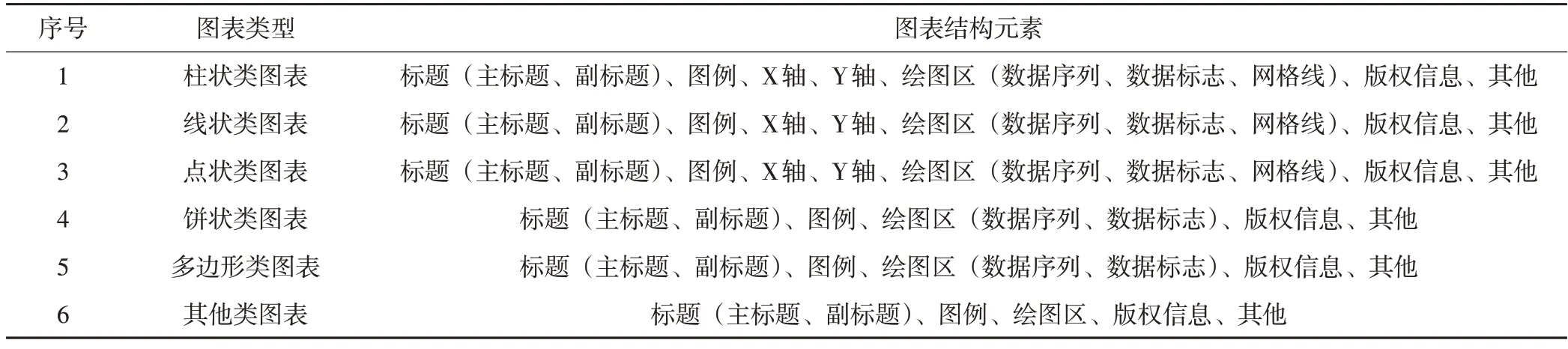
表1 图表结构(元素)解析
知识标签的内容主要通过图表中的文字信息体现,不同位置的文字信息对应知识标签的价值含量也不相同。泛在图表的知识抽取是在图表结构解析的基础上,通过自动化的方式提取图表中的文字信息,并自动判别其对应的图表结构,判断信息的价值含量。基本思路是首先将图表中的所有文本信息识别出来并记录其对应的位置信息,然后根据统计规则或者机器学习的方式进行结构识别,提取对应的底层特征信息,并进行文本矢量化,抽取核心关键信息。
2.2 文本块的类别判断
文本块类别判断是在文本识别的基础上,根据文本块特征,基于相应类型图表的结构判断其对应的结构特征。主要有基于机器学习和基于模板匹配2 种方法。
2.2.1 基于模板进行类别的快速判断
基于模板的类别判断主要是在文字信息识别和图表结构解析的基础上,进行文本块的类别判断。相较于普通图像,图表数据的设计和生成具有明显的规律性,特别是基于常用的软件工具生成时,提供了固定的模板,可以快速进行底层特征的类别判断。在总结分析大量图表数据的基础上,得到了主要图表数据的结构分布模板,表2 为主要图表类型中图名和图例的分布情况统计。
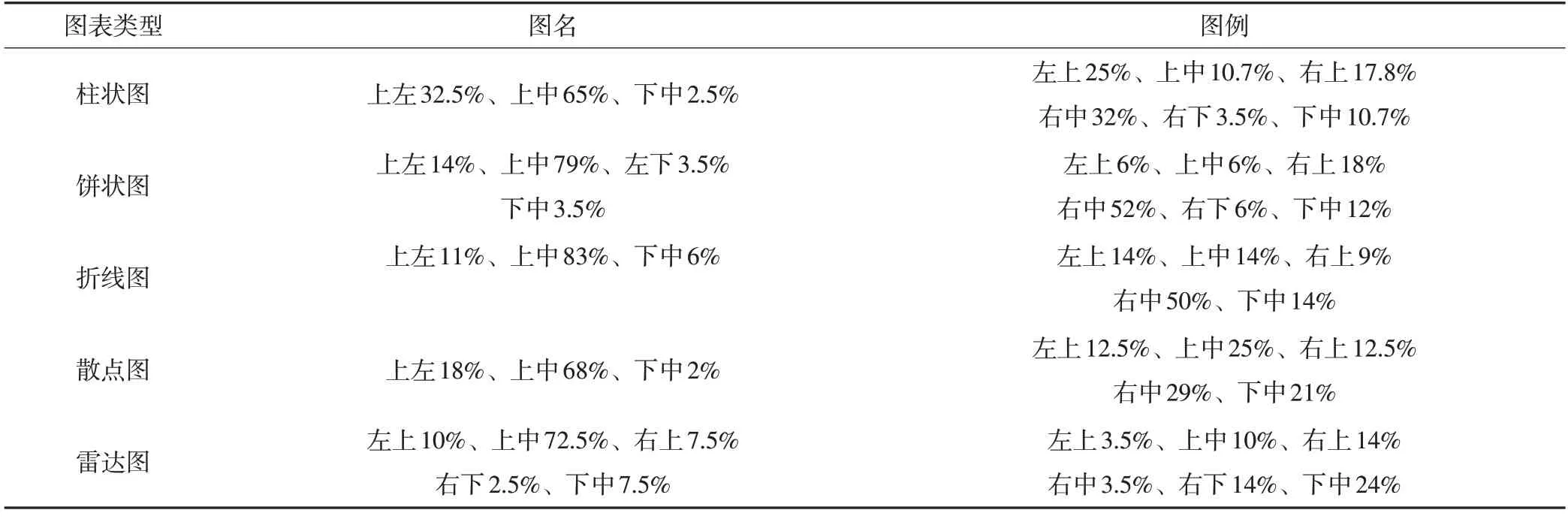
表2 常用图表的结构模版
基于表2,结合文本块的位置信息,可以快速进行文本块的类别识别,并进行知识的抽取和利用。
2.2.2 基于机器学习的方法进行类别判断
基于模板进行文本块的类别判断便捷迅速,针对特定软件生成的图表数据准确率高,但是存在不同类别数据之间的模板位置有交叉,面向泛在图表数据的准确率会降低等问题。根据文本块的几何信息,基于统计学和机器学习的方法,判断其对应的图表结构要素,可以有效解决这一问题。主要步骤如下:
1)通过手工标注的表示,建立了特定类别图表的结构样本集。因为分布特征差异明显,不同类别的图表建立不同的结构样本集。
2)将标注的样本转化为特征数据,并计算特征值,选取文本块的起始点位置和长宽作为特征。记录图表数据中对应的位置信息、矢量化结果和对应结构类型。
3)构建CNN 神经网络,对样本数据进行训练和测试,并进行新数据的结构预测。
根据2 种方法的特点,可以发现基于模板进行类别判断的方法主要适用于规则图表,特别适用于特定软件自动生成的图表数据,能够快速准确地进行类别判断,不同软件生成的图表在结构模板上会有部分不同;基于机器学习的方法进行类别判断适用于各类泛在图表,具有较强的普适性,但是准确性和训练模型强相关。
3 知识标签体系的构建
图表的知识标签主要对应时间、地点、人物、事件、事物、现象、场景等社会七要素[16],是表示图表某类关键知识特征的词语。知识标签抽取是结合文本块类型,对文本块的矢量化结果进行分词,并判断其对应的知识标签属性,具体过程如图2所示。
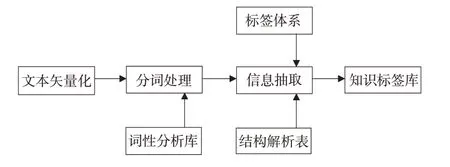
图2 知识标签抽取流程
将矢量化进行分词,并根据分词结果进行词性和特征标签判断是知识标签抽取的难点和重点,综合比较目前的分词工具,选用哈工大LTP分词工具,可进行词语属性的识别和判断。根据图表结构解析结果,设定两级标签体系:一级标签对应图名、图例两个图表结构中的知识标签,是图表的主要知识标签;二级标签对应图表区和坐标轴等其他内容,是图表的次要知识标签。
4 实验与分析
4.1 图表文本定位与识别
利用CRAFT 方法,对栅格类图表进行文本定位,得到的结果如图3所示。
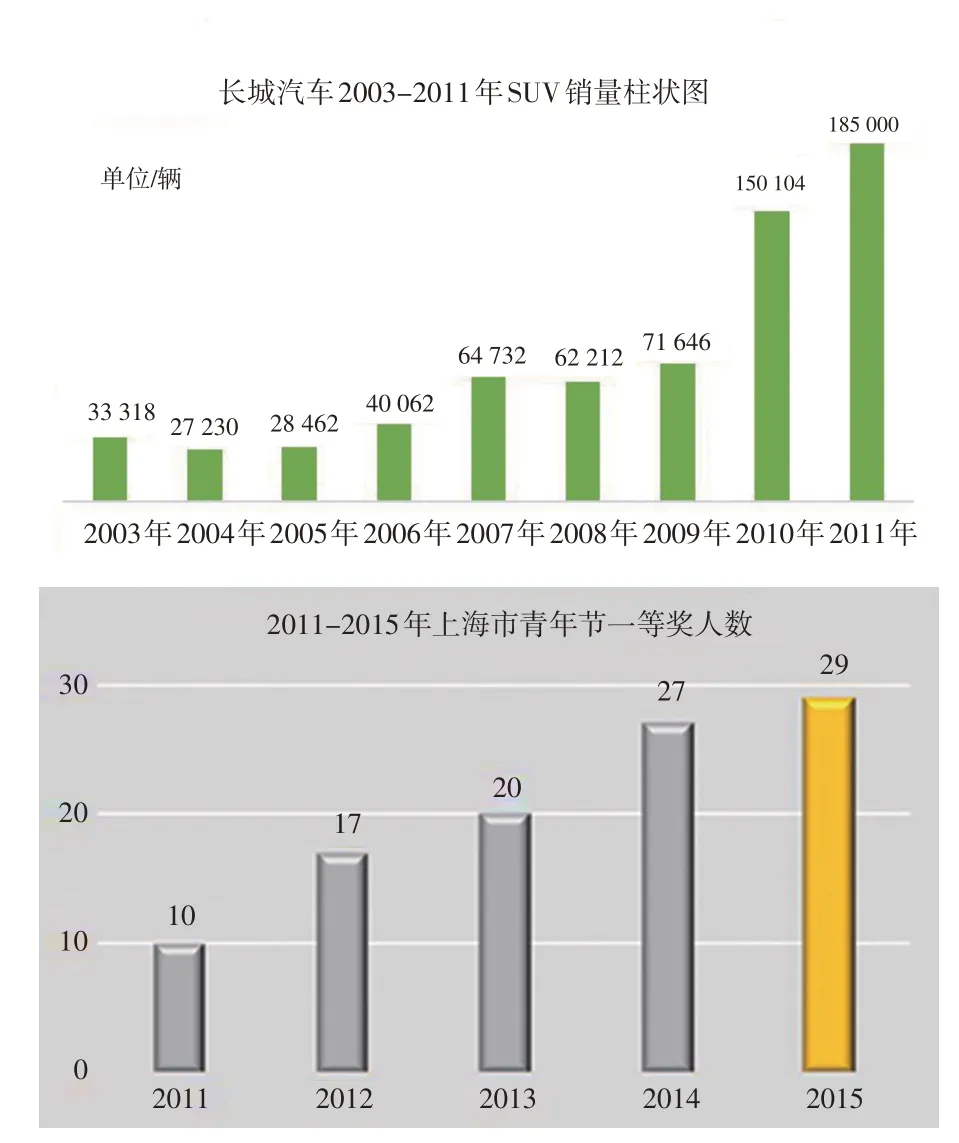
图3 CRAFT算法的图表文本定位结果
采用CRNN 方法进行文字识别,为提高识别效率,首先将本文块进行二值化,然后再进行矢量化,得到的结果如图4所示。

图4 基于CRNN的栅格文本块矢量化结果
分析图3、4 可以发现:利用CRAFT+CRNN 的方法对栅格类图表中的文本进行定位和识别,具有较高的准确度。分别对100 张栅格类图表进行文本定位和识别测试,定位准确率和识别准确率均达到90%以上的图表数量为93张,说明了该方法的有效性。
4.2 结构类别判断
以柱状图和饼状图为例,通过手工标注,建立了图表结构样本集。其中,柱状图按照标题、X 轴、Y轴、图例、图表区5 类结构进行构建,训练集包括250个样本,测试集包括30个样本;饼状图按照标题、图例、图表区3类结构进行构建,训练集包括130个样本,测试集包括30个样本。测试集的30个样本中,包含Office、Echart和泛在图表各10个。分别利用模板和机器学习方法进行测试,得到结果如表3所示。

表3 结构类别判断结果/%
分析表3 可以发现针对常见软件生成的规范图表,基于模板和机器学习方法进行图表结构解析得到的准确率基本相同,但是基于模板的方法所消耗的时间和空间资源远小于机器学习方法;针对随意性更强的泛在图表,机器学习方法准确性更高,要明显优于模板方法。在实际应用中可以根据具体需求选择不同的判断方法。
4.3 知识标签体系构建
根据图2,构建图表的两级知识标签体系,以图5为例,得到结果如表4所示。
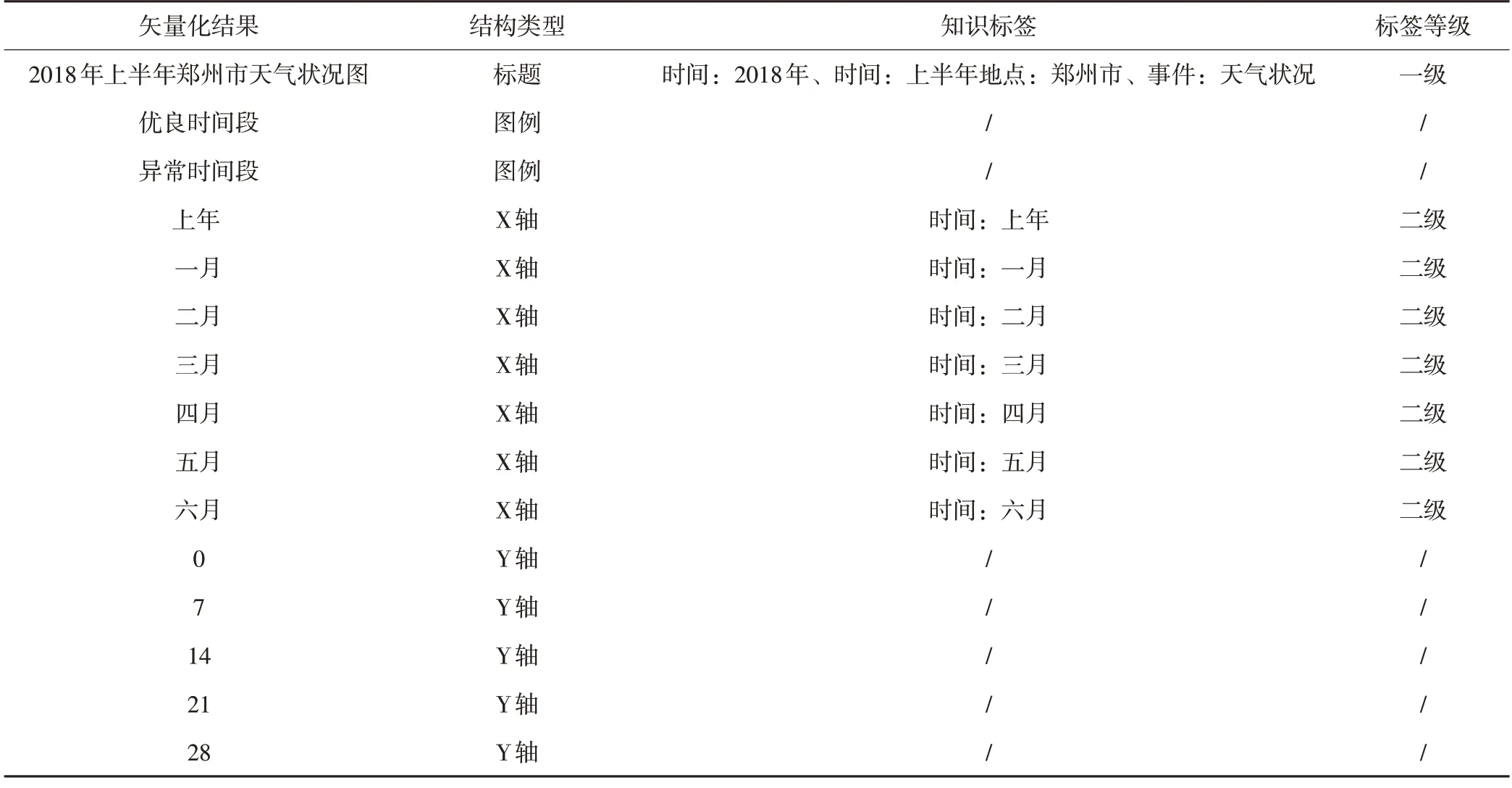
表4 知识标签构建体系
分析表4,可以发现图5中的主要信息均被抽取出来,形成了能够表达图表核心内容的两级知识标签体系。
5 结语
作为泛在信息的一种主要类型,栅格类图表包含了丰富的时空信息。本文设计并实现了一种栅格图表知识抽取方法,将文本信息作为理解图表数据的主要内容,结合栅格类图表的特点,采用CRAFT和CRNN方法分别进行文本定位和内容矢量化,解决了栅格图表中关键信息的矢量化问题。通过对图表结构进行解析,总结图表数据的结构特点,根据不同情况选择模板匹配和机器学习2 种方法能够进行文本块的类别判断。利用自然语言处理技术,实现了知识的自动理解和抽取,建立栅格类图表的知识标签,有助于海量数据的快速检索和理解,可以为泛在信息特别是图像类数据的智能解译提供一种新的思路。
