基于Venn-Abers预测器的系统日志异常检测方法
2023-11-02顾兆军潘兰兰刘春波
顾兆军 潘兰兰,2 刘春波 王 志
1(中国民航大学信息安全测评中心 天津 300300)
2(中国民航大学计算机科学与技术学院 天津 300300)
3(南开大学网络空间安全学院 天津 300350)
0 引 言
系统异常检测是一个计算机系统稳定运行的必要条件。现代计算系统正面临着由大型服务器集群支持的爆炸式增长,云计算、分布式计算平台的出现使大型数据中心的部署成为一种趋势。这些系统的规模和复杂性不断增加,遭受错误和故障的概率就会越来越大,使异常检测变得更具有挑战性。系统日志详细记录系统运行期间的系统状态和重要事件,几乎所有的计算机系统中都有相应的日志系统。
利用系统日志数据进行异常检测的方法大致分为以下几类:(1) 基于数据分布的统计学异常检测模型[1],根据总体数据分布识别突出或不符合分布的数据为异常点,但是该方法只适用于点异常的检测;(2) 最近邻方法[2]和基于聚类的异常检测方法[3],假设正常数据位于密集的区域,异常则远离该区域,这两种方法对于数据分布稀疏和密集区域具有未知分布的数据集不可用;(3) 基于长短期记忆网络的深度神经网络模型Deeplog[4],将系统日志建模为自然语言序列,可以通过日志模式检测是否偏离正常行为从而检测异常;(4) 基于深度学习[5-6]的异常检测方法。这些算法只能给出一个预测(对于分类,它是预测标签;对于回归,它是预测值),并未对预测结果进行可靠性评估,即对预测结果的可信程度的评估以及对该评估有效性的保障。目前较为流行的概率预测的算法有一致性预测器和Venn-Abers预测器,一致性预测器在置信度下给出p值作为预测可靠性的估计[7],但这不是直接概率。本文将引入一种将常规预测器的结果转换为概率的算法,给出预测结果的概率估计值,使结果更加直观。
引入统计学习算法Venn-Abers预测器是具有有效性保证的,该方法可以对日志异常检测结果进行可靠性评估,也就是对预测结果的正确性进行有效的概率预测。它是基于概率对数据进行分类的机器学习框架,任何机器学习算法都可以作为它的底层算法。Venn-Abers预测器唯一需要的假设条件是数据服从可交换性假设[8],可以通过日志数据轻松满足,并且不需要日志数据服从特定分布,就可以保证预测概率的有效性。研究表明,Venn-Abers预测器在很多领域可以取得有效的概率预测结果[9-11]。将Venn-Abers预测器引入日志异常检测领域中可以有效地检测系统日志异常。
本文采用真实系统的HDFS日志数据集评估本文方法,Venn-Abers预测器已被证明可以完美校准[12],根据三种基础算法分别开发三种Venn-Abers预测器[13]用来检测系统日志异常。从系统日志异常预测结果的有效性和准确性两个方面比较基础算法和Venn-Abers预测器的性能。同时提出对Venn-Abers预测器处理数据的计算方法,并减少计算多概率预测值的时间。实验结果表明,引入Venn-Abers预测器进行系统日志异常检测正确性的评估是有效和准确的。
1 基于Venn-Abers 预测器的日志异常检测模型
图1给出了基于日志异常检测的总体框架。日志异常检测框架总体包含两个部分:日志预处理和日志异常检测。日志预处理包括收集日志信息、日志解析和日志的特征化提取三部分。在日志异常检测过程中,选择三种基础算法LR、SVM和RF,基于基础算法预测得分构建对应的Venn-Abers预测器,Venn-Abers预测器得到的是测试对象对应标签为1的多概率区间。为了和基于静态阈值的方法进行比较,将多概率区间拟合为单个概率值,通过概率值和标签的分布关系确定动态阈值并实现最终的分类预测。
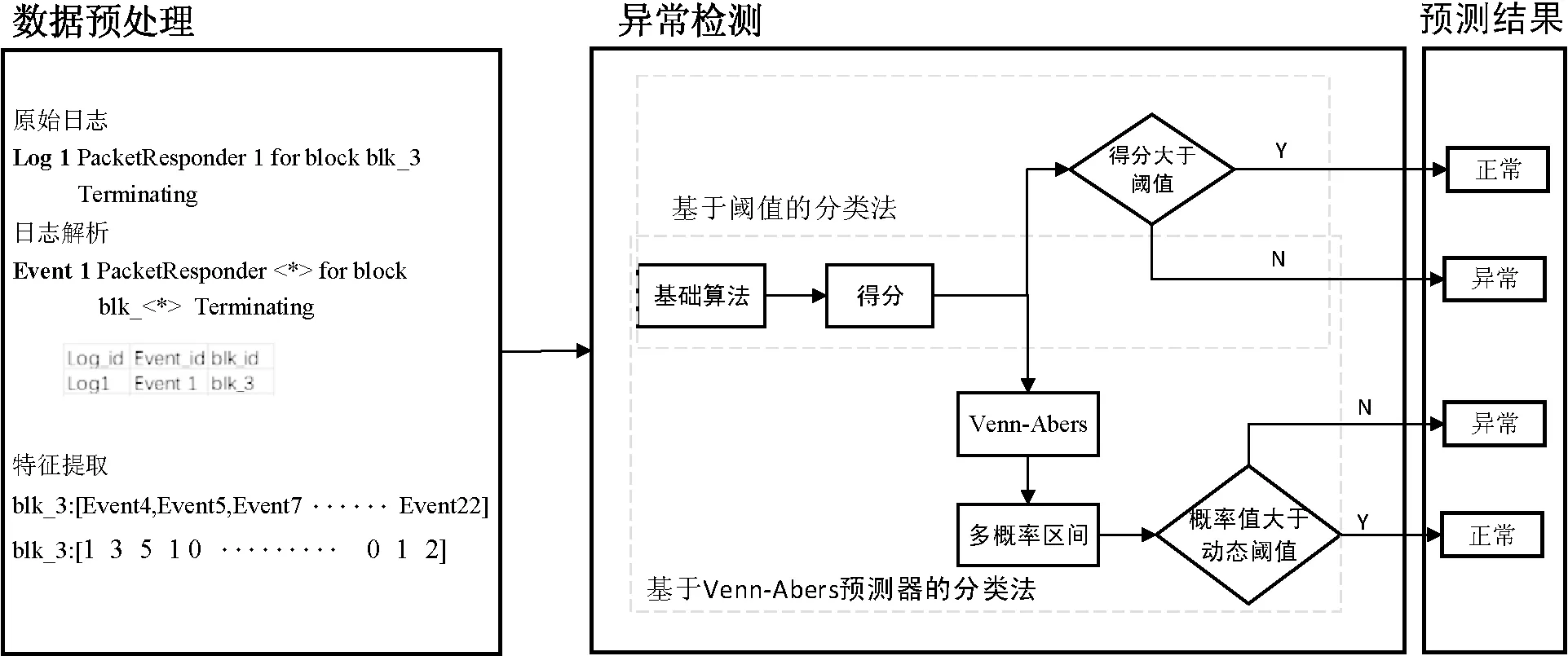
图1 基于日志异常检测的总体框架
1.1 日志预处理
系统日志异常检测的第一个阶段是日志预处理,包括收集日志信息、日志解析和日志的特征化提取三部分。现代大型系统通过生成日志来记录系统运行时信息,每条日志都包含时间戳、日志优先级、系统组件和日志条目本身等信息的非结构化数据。通常,日志消息使用一组字段记录特定的系统事件,图1中Logs部分展示了从Amazon EC2平台上收集的HDFS日志中提取的1个日志行[14],为了便于呈现,省略了部分字段。
日志解析的目标在于提取一组日志事件模板Event,即从日志数据内容中区分出常量部分(固定的纯文本)和变量部分(例如图1中的blk_id)[15]。日志事件模板Event主要包括常量部分和通配符,其中常量部分是指构成固定的纯文本,它对于每个事件发生都保持不变,并且可以显示日志消息的事件类型;通配符是指携带运行时信息的状态和参数的值(例如,IP地址和端口:10.251.31.5:50010),它们在不同事件发生之间可能有所不同,使用一个形如<*>的字符串替代。本文为每个不同的日志事件模板编号为Event_id,每个日志事件模板对应一个标识符block_id,如图1中的Parsing部分。
上一步解析的结果可以用于生成事件计数矩阵X,事件计数矩阵将被送到日志异常检测模型中。在事件计数矩阵中,将具有相同block的事件模板放在一行,即每一行代表一个块block,将每一行的事件模板统计出次数,即每一列代表一种事件类型。Xi,j单元格中的值记录事件j在块i上发生的次数。为了避免直接在矩阵X上检测异常,引入TF-IDF[16]为该矩阵进行预处理。TF-IDF是信息检索中一种公认的启发式方法,它通常用作信息检索和文本挖掘中文档的特征表示。
1.2 日志异常检测
1.2.1基于Venn-Abers预测器的日志异常检测
本节将介绍基于Venn-Abers预测器来评估基础算法对日志异常检测结果预测正确的可能性。Venn-Abers预测器是一种将预测结果转换为概率的算法[8],通过应用保序回归将其他分类器的输出转换为概率。假设本文得到了一个标准的二分类问题:一组训练示例(z1,z2,…,zn-1)。每个zi由一对对象xi和标签yi组成,可能的标签有两种,即y∈Y={0,1}。给出一个新的对象xn,任务是预测新对象xn的标签yn,并对预测正确的可能性进行估计。
为了构造Venn-Abers预测器,首先用观察的训练集训练分类器并使用分类器为新对象xn输出预测分数s(xn),在带有标签0和1的二分类问题中,通过将预测分数与固定阈值c进行比较,并在s(xn)>c时将xn的标签预测为1,从而获得实际的预测类别,因此s(·)在此称为评分函数。许多用于分类的机器学习算法都可作为分类器的评分函数,在本文中,采用SVM和LR的决策函数(Decision function)作为评分函数,RF采用类概率预测函数作为评分函数。Venn-Abers预测器将递增函数f(·)应用于s(x);试图“校准”分数[17],以便将f(s(x))用作x的标签为1的预测概率。
本文使用“成对相邻违反者算法”找到的单调非递减的保序回归函数f(·),给定得分分类器对应的Venn-Abers预测器是定义如下的多概率预测变量。尝试将两个不同的标签0和1用于测试对象xn。令s0为 (z1,z2,…,zn-1,(xn,0))的评分函数,s1为(z1,z2,…,zn-1,(xn,1))的评分函数。
f0对应的保序回归为:
((s0(x1),y1),(s0(x2),y2),…,(s0(xn-1),yn-1),
(s0(xn),0))
(1)
f1对应的保序回归为:
((s1(x1),y1),(s1(x2),y2),…,(s1(xn-1),yn-1),
(s1(xn),1))
(2)
这样Venn-Abers预测器输出的多概率预测为(p0,p1),其中p0=f0(s0(x))和p1=f1(s1(x))。
1.2.2Venn-Abers预测器运行效率优化方法
Venn预测器会为每个测试对象尝试所有可能的标签,需要针对每个测试对象的可能标签训练一个基础算法模型,由于计算效率低下,故只适用于小数据集。随后提出Venn-Abers预测器,对每个测试对象的所有可能标签只需要训练一个模型,也就是本文采用的方法可以对日志异常检测结果进行有效性的预测。但是在实验过程中,发现由训练集标签和训练集对象得到的保序回归序列分布过于密集,不符合预期。
分析原因发现采用HDFS日志数据提取出29个事件模板从而形成29维的特征向量,但由于HDFS记录的日志行为单一[18]使不同特征向量之间的差异较小,特征向量高度相似或重复。这种情况下,模型得分也会大量重复或相似,因此设计了如下算法。
步骤1得到特征向量的得分s(xi)。
步骤2将得分s(xi)和对应的标签yi打包成具有两个元素的元组(s(xi),yi)。
步骤3并对元组(s(xi),yi)进行升序处理。
步骤4对于重复的得分,将其标签yi累积求和并取平均值作为该得分新的标签Newy。
这样有益于保序回归序列f0和f1的离散化分布同时降低后续实验测试对象多概率p0和p1的计算时间并提高计算效率。
2 评估方法
本文将使用标准损失函数将Venn-Abers预测器与已知的概率预测器进行比较。由于Venn-Abers预测器输出的是概率对(p0,p1)而不是点概率,因此需要将它们拟合到标准框架中,以便从p0和p1中提取一个概率p。
2.1 算法有效性评估指标
概率预测可以提供对预测的可靠性估计,同时估计的概率是有效的。有效性意味着对预测标签的估计概率是无偏的,这意味着该估计概率等于或接近预测正确的观察频率。本文使用平方损失函数来检验概率预测的有效性。
假设p是测试对象x预测标签的概率值,如果该对象对应的标签预测是正确的,y=1,反之y=0。该预测的平方损失函数为:
λsq(p,y)=(y-p)2
(3)
该损失函数的特点是:当预测正确时,预测的概率值越大,则损失函数越小;预测错误时,预测的概率值越小,则损失函数越大。
使用平方损失函数时,Venn-Abers预测输出一个概率区间[p0,p1],现阶段的任务是找到最优的概率值p[19]。如果预测错误,y=0,则使用p0作为预测概率值可以使损失函数达到最小。因此,由于本文使用p而没有使用p0造成损失p2-p02;同理如果预测正确,y=1则由于使用p而没有使用p1造成损失(1-p)2- (1-p1)2。p2-p02在p=[0,1]严格增函数,(1-p)2-(1-p1)2在p=[0,1]区间是严格减函数(1-p)2-(1-p1)2。因此,当p满足如下方程时平方损失函数取得最小值:
(4)
因而,得到:
(5)
在计算Venn-Abers的预测结果的损失函数时,将式(5)分别代入λsq中计算损失函数,损失函数越小,预测的有效性越高。因此,基于损失函数的概率预测或多概率预测的有效性的指标定义为,对N个测试样本的概率预测结果中,平均的损失函数值:
(6)
2.2 算法评估指标
实验中使用精确率(Precision)、召回率(Recall)、F1值(F1-measure)和准确率(Accuracy)作为每次预测结果的评价指标。假设0代表正常,1代表异常,则统计模型分类结果得到:
1)TP:预测结果为异常,实际也是异常的个数。
2)FP:预测结果为异常,实际是正常的个数。
3)TN:预测结果为正常,实际也是正常的个数。
4)FN:预测结果为正常,实际是异常的个数。
精确率公式为式(7),它表示模型预测到的异常中真异常的比例,同时可以衡量模型降低误报率的能力。
(7)
召回率公式见式(8),它表示模型预测到的异常占数据集中总异常的百分比,同时可以描述模型识别正例覆盖范围的大小。
(8)
准确率公式为式(9),它表示模型判断正常的日志和异常日志占总日志的百分比。
(9)
F1值公式为式(10),它指精确率和召回率的调和平均数,用于综合衡量模型的精确率和召回率。
(10)
3 实验与结果分析
实验环境为: Intel®CoreTM i5-4200U CPU @ 1.60 GHz,8 GB RAM和Windows操作系统。数据集[16]来自亚马逊在EC2节点上部署的Hadoop集群,运行样本Hadoop map-reduce作业近39个小时,生成的HDFS日志数据是由相应领域专家手动标记的。HDFS 数据集中每个标签标注的是一个会话是否正常。一个会话是一个块ID相关的若干条日志,可以认为是系统对一个块执行的一系列操作。一个会话中只要出现一个异常事件就认为该会话是异常的。具体来说,有11 175 629条原始数据记录,形成575 061个操作会话,在575 061个会话中,16 838个被标记为异常,在实验过程中将其作为基本事实。
该数据集仅包含添加、移动和删除等事件的日志及其异常情况。HDFS是以一系列的文件块为存储单位的,每个文件块都有独自的ID[20]。实验过程按照8∶2划分测试集和训练集。首先将原始数据处理为事件模板,共29种不同的事件模板。具有相同块ID的事件模板组合在一起并形成一个向量。每个向量的维度对应着不同的事件模板,维度的值表示该模板的事件出现的次数,因此事件计数矩阵具有575 062×29的维度。但是真正实验过程中却发现许多向量是完全相同的。事实上,只有580个不同的向量,即大多数文件块都经历共同的执行动作。图2和图3展示了用Venn-Abers绘制出全部向量和根据1.2.2节改进后的向量对应的f0和f1。在全部向量的图2中,因为存在大量重复的向量,使f值的离散程度很差,而改进后的图3中,f0和f1值的分布是明显的。所以在以下实验结果中采用580个特征向量的数据集。

图2 全部向量作图结果
3.1 算法有效性比较
采用损失函数对算法有效性进行比较。平均损失函数值是在所有情况下真实类别与预测结果概率之间的差异的平均平方和。真实类别必须为正常(0)或者异常(1),而预测结果概率可以是0到1之间的值。对于一组预测值,平均损失函数值越低,预测校准越好。将数据按照特征向量的不同分为大小不同的四份数据集,用于损失值的测试,具体运行结果见表1。基于SVM开发的Venn-Abers预测器简称为SVM-VA、基于LR开发的Venn-Abers预测器简称为LR-VA和基于RF开发的Venn-Abers预测器简称为RF-VA。得到的损失值都产生了不同程度的下降,表明了Venn-Abers预测器具有改善分类性能的能力。
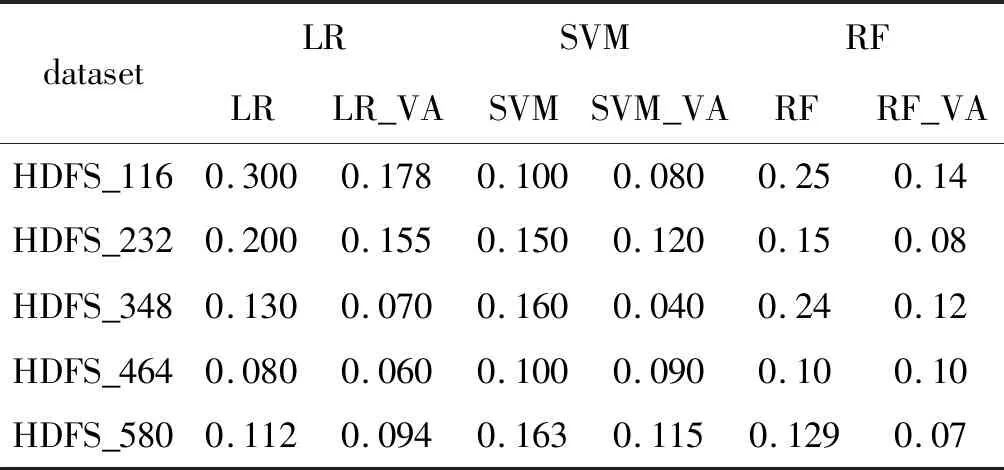
表1 不同大小数据集下LR-VA、SVM-VA、RF-VA、LR、SVM和RF算法的平均损失函数值结果对比
箱型图主要用于显示数据统计分布,图像生成方式是通过排序,提取一组数据的上边缘、下边缘、中位数和两个四分位数,连接两个四分位数形成箱体,再连接中位数和上下边缘。图4为LR、SVM、RF、LR-VA、SVM-VA、RF-VA在全部数据集下损失值的箱型图。从损失值的中位数可以看出,LR-VA模型相对于LR模型降低了3.6%, SVM-VA模型相对于SVM模型降低了6%, RF-VA模型相对于RF模型降低了4%。从整体分布来看,LR-VA、LR、SVM-VA、SVM、RF-VA和RF的四分位差分别为0.085、0.088、0.035、0.06、0.04和0.12,可以很容易看出RF-VA和SVM-VA模型主要分布在较低的区域并且跨度很小。综合评价具有最低的损失值的模型是RF-VA和SVM-VA模型;其次是LR-VA模型;表现最差的是RF模型,损失值数据比较发散。Venn-Abers预测器的有效性评估标准均小于相应的基础方法的评估标准,这表明Venn-Abers预测器进行的概率预测比相应的基础预测方法更有效。
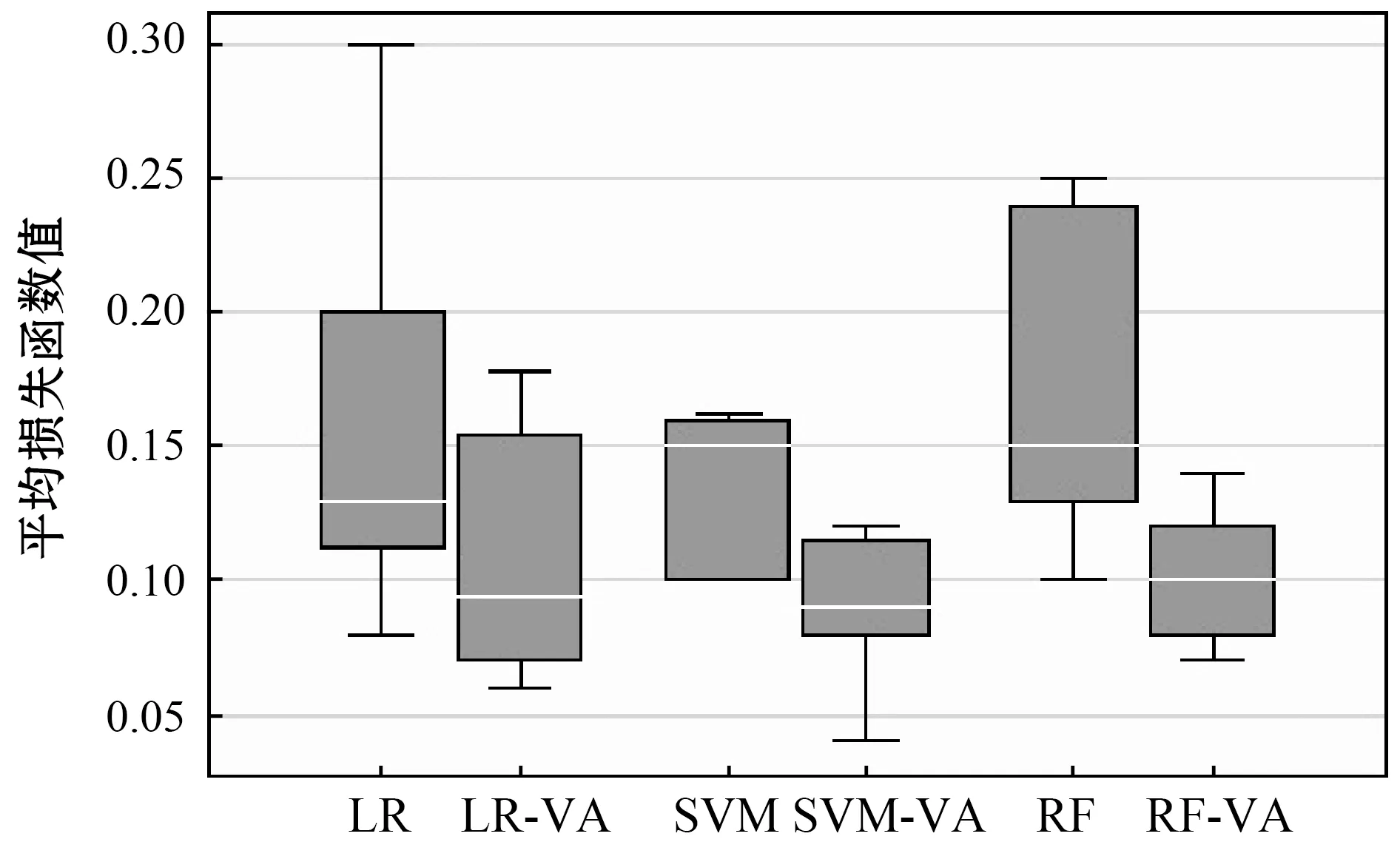
图4 数据集的平均损失函数值结果箱型图
3.2 算法性能比较
在第2节将Venn-Abers预测器输出的概率对(p0,p1)拟合为一个概率值p,从而和基于静态阈值的基础算法方法进行比较。由于概率值p代表预测标签为0的概率,p值越大则预测标签为0的可能性越高,p值越小则预测标签为0的可能性越低,即标签为1的可能性越高。在本文的日志异常检测过程中,标签为0代表预测日志是正常的,标签为1代表预测日志是异常的。本文展示出预测标签(0和1)和概率值p之间的分布散点图,若Venn-Abers预测器得到的p值结果在[0, 1]区间呈现两极分化,说明Venn-Abers预测器的质量很好,如图5(d)、图6(d)和图7(d)所示。但是在实验过程中发现p值的分布并不仅仅局限于0和1的附近,存在处于中间的p值。那么根据p值在[0, 1]区间的分布情况对测试对象的标签进行再次预测。具体可以通过设置阈值c,来对2.1节的准确性评价指标进行一定程度的控制,若p>c则说明该测试对象对应的标签为异常。在实验过程中,通过调整阈值c的大小[21],以使预测准确性尽可能接近1。

图5 不同阈值下LR模型预测概率值p和标签分布关系
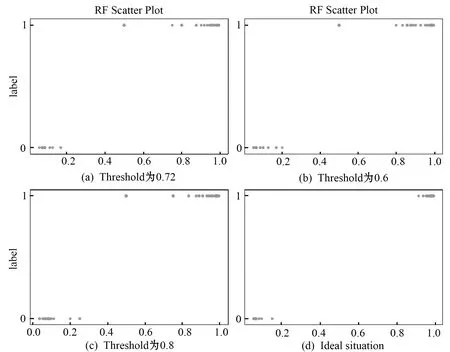
图7 不同阈值下RF模型预测概率值p和标签分布关系
在图5(a)LR模型中,会发现p处于[0.6, 0.8]之间比较密集,这部分p值对应什么样的标签对实验结果有很大的影响。故设置三个阈值c取值分别为0.6、0.72和0.8来检测密集区间内的日志异常的变化情况,p值和测试标签的分布情况如图5所示。当c取0.6时对应图5(b),此时处于[0.6, 0.8]区间内的p值对应的标签均为异常。当c取0.8时对应图5(c),此时处于[0.6, 0.8]区间内的p值对应的标签均为正常。
取中间值0.72时,使[0.6, 0.8]区间内对应的p值对应的标签既有正常又有异常,如图5(a)所示。这样可以通过评价指标得出使异常检测结果更加准确的阈值。通过这种方式可以把概率值转化为预测结果,进而得到三组基于Venn-Abers的实验结果,简称VA_0.6、VA_0.72和VA_0.8,与基于静态阈值的基础算法通过柱状图进行实验对比。实验结果显示与基于静态阈值分类的方式相比,基于Venn-Abers的分类方式不仅能够成功检测异常,而且其Accuracy、Recall、Precision和F1值均有不同程度的提高。图8为LR和Venn-Abers实验结果对比柱状图,当c=0.72时,通过Venn-Abers分类器得到的实验结果最好,其中Accuracy和Recall提高了0.02和0.03,Precision和F1值提高0.01。在c=0.8和0.6时其结果不如基于静态阈值的基础算法,因为此时Venn-Abers分类器得到的实验结果出现较多的FP和FN。
图6中显示了在SVM算法中当阈值c=0.6、0.72和0.8时,p值和标签的分布情况。图9为基于静态阈值的基础算法SVM和基于Venn-Abers预测器的实验结果,可以看出c=0.72时基于Venn-Abers预测器的Accuracy和F1值提高了近0.07,Recall提高了0.13,误报率从0.12降低到0.03;c=0.8时,由于FP数量增多导致Accuracy、Precision和F1值降低;c=0.6时,FP数量减少但是效果没有c=0.72好。补充在RF算法中的情况,在图7中展示了RF算法中当阈值c=0.6、0.72和0.8时,p值和标签的分布情况。会发现RF算法中p值和标签的分布会更加趋于两极,中间的离散点相对较少,说明RF算法相对适合这种日志异常检测问题的分类。从图10可以看出基础算法RF的实验结果是三种算法中最好的,当c=0.72时,Accuracy和Recall提高了0.03和0.05, F1值提高0.02,但是Precision降低0.02。从图10可以看出,基于Venn-Abers算法的Precision均低于基础算法RF,说明基础算法RF对日志异常中的漏报检测效果很好。实验结果表明,与三种基于静态阈值的基础算法相比,开发的三种Venn-Abers预测器的方法会动态改变c值以适应数据的变化,大多数情况下能作出更好的判断。

图9 SVM和Venn-Abers实验结果柱状图
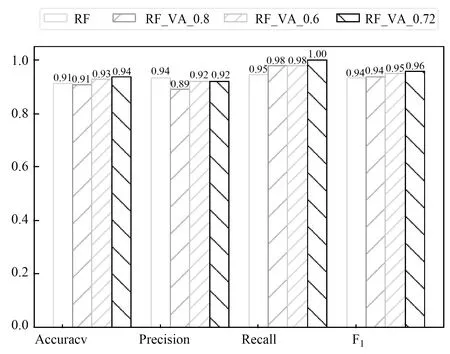
图10 RF和Venn-Abers实验结果柱状图
对于概率值p在[0, 1]区间的分布进行分析,如果概率值p分布在[0, 1]区间的两极,那么检测效果会是最好的。分析LR模型中概率值p的分布会发现p=0.487 805出现91次,p=0.689 441出现3 190次,p=0.765 957出现12 665次。追溯概率值p对应的特征向量会发现,同一个概率值p对应的特征向量相似度很高,只有某一个维度不同。比如p=0.689 441对应的特征向量只有事件11出现6次和事件12出现2次的不同。同样的情况出现在SVM模型和RF模型中,p=0.738 409出现13 258次,概率p值对应的特征向量要么重复,要么高度相似。单个模型的检测不能对高度相似的特征向量作出很好的判断,如果能使用模型融合取不同算法的优势,则可以进一步细致地对日志数据进行判断,从而得到更好的检测结果,这也是下一个阶段的研究内容。
4 结 语
在这项工作中,采用HDFS真实数据集来对系统日志异常进行检测。本文引入灵活的机器学习框架Venn-Abers预测器,可以对日志数据进行精确有效的概率预测。代替传统分类器仅预测未知对象的单个标签,这种预测器在一定程度上补充了预测标签正确的可能性。在概率预测有效性方面,开发了三种Venn-Abers预测器与三种基础算法进行比较。损失函数的实验结果表明,尽管采用相同的基础分类方法,但随着样本数量的增加,Venn-Abers预测器的有效性保持不变。在概率预测准确性方面,Venn-Abers预测器计算出预测标签的概率值,通过统计概率值和预测标签的分布情况,动态设置最佳阈值,能更加准确地检测日志异常情况。同时,对Venn-Abers预测器计算概率值方法的改进,使算法运行效率得到提高。实验结果表明Venn-Abers 预测器不仅对机器学习预测日志数据结果的正确性进行有效性评估,而且对日志数据进行了更高效、准确的分类。
在下一个阶段的研究中,将研究更多不同的评分分类器集成到该原型平台,以检测系统日志的异常。不同的模型有各自的长处,性能具有差异性,将引入模型融合使各个模型发挥出优势,来进一步提高日志异常检测的准确性。
