一种浅层非对称结构的视网膜血管分割网络
2023-10-28王耀,顾德
王 耀,顾 德
(江南大学 物联网工程学院,江苏 无锡 214122)
0 引言
糖尿病是由血液中葡萄糖的积累引起的[1]。糖尿病使人面临各种疾病的风险,如肾衰竭、视力丧失、牙齿出血、神经衰竭、下肢癫痫发作、中风、心力衰竭等[2]。糖尿病性神经病变是由肾单位的破坏引起的,而糖尿病性视网膜病变是由脑神经元损伤引起的,这会导致视网膜感染,并可在早期阶段逐渐损害视力[3]。因此,糖尿病患者必须进行全面的眼科检查,在此期间必须由眼科医生检查视网膜。光学相干断层扫描、眼底荧光素血管造影、裂隙灯生物显微镜检查和眼底成像是识别患眼的一些方法[4]。
根据世界卫生组织进行的调查,糖尿病[5]是第七大致命疾病。此外,通过补充统计,糖尿病患者人数大幅增加,攀升至4.22亿。数据显示,18岁以上的糖尿病患者人数从4.7%增加到8.5%,而一些最贫穷的人更容易患糖尿病。葡萄糖水平的最大升高对血管有显著影响,导致眼睛血液渗出,人体视觉系统减弱[6]。另一方面,人类天生具有治愈疾病的能力。当大脑识别到血液泄漏时,它会刺激周围组织来处理这种情况。因此,它会导致新血管的零星形成,但由此产生的细胞是贫血的[7]。
视网膜眼底图像分析是一种有用的医疗处理操作。眼科医生可以使用视网膜血管分割来帮助他们诊断各种眼部问题[8]。因此,包括糖尿病视网膜病变、高血压、动脉粥样硬化和黄斑变性在内的疾病可以改变动脉的形态,从而改变其直径、曲折度和分支角度。医生通过观察眼底血管的弯曲度、长度、宽度、分叉情况等来获得眼底疾病的临床病理特征[9]。将视网膜眼底图像中的视网膜血管进行精确分割将有助于医生更加容易识别这些临床病例特征,使医生更好的帮助病人进行眼底病变的诊断[10]。视网膜血管形状复杂、分支较多,对其进行精确分割需要专业医生将图片中的每一个像素点进行正确归类,这使得人工分割血管非常耗时。由于眼底图像质量以及病变产生的一些疾病特征使得部分区域血管不明显,人为分割容易出错。通过分割算法将视网膜眼底图像中的血管进行精确分割能够帮助医生分析复杂的视网膜眼底图像,减少了医生的诊断时间和误诊几率,计算机化分割策略近年来引起了科学工作者极大的兴趣,许多细分方法已经被提出[11-13]。然而,现有的视网膜血管分割方法存在灵敏度较差,细小血管难以被分割的问题。
关于视网膜血管分割算法大体可分为基于传统算法和基于深度学习算法两大类。传统算法包含阈值分割法、基于线检测器检测法、形态学法等。文献[14]提出了一种基于线检测器的血管检测方法,用于识别主要血管区域,然后应用马尔可夫模型检测去除噪声后的视网膜血管。文献[15]提出了一种基于多尺度图像增强与底帽变换相结合的混合方法,其中分割任务是基于形态学操作执行的。文献[16]提出了一种基于概率补丁的降噪器来缓解阻碍血管分割的噪声,其中使用了改进的Frangi滤波器和降噪器。另一种是基于深度学习的方法,文献[17]基于深度学习技术设计了一种具有编码-解码结构的U-Net全卷积神经网络模型,U-Net网络分为编码阶段和解码阶段,这两个阶段结构是对称的,在两个阶段之间通过跳跃层将相应的特征进行连接,这使得网络可以对图片进行像素级的分割,在数据集图片数量较少的情况下也能获得较好的分割性能。文献[18]提出了密集残差网络(DRNet)分割视网膜图像中的血管。在DRNet中,采用了一种双残差块的残差结构来增加网络的深度,使得网络可以获得更加复杂的语义信息。
传统的语义分割网络使用相同数量的编码器和解码器,同时保持对称的架构设计。这增加了网络的整体深度和可训练参数的数量。此外,传统网络使用多个池化层来减小特征图的大小,使得最终的特征图尺寸变得太小,无法表示原始特征图中的微小目标。在视网膜血管分割过程中,传统的编码解码架构将导致大量微小血管无法被正确分割而使算法的灵敏度变得很低。为了避免分割后细小血管像素模糊、丢失等现象,提升血管分割灵敏度和精确度,本文设计了一种新的视网膜血管分割算法。该网络将残差通道注意力模块(RCA,residual channel attention)和多尺度空洞卷积模块(MDC,multiscale dilated convolution)相结合作为特征提取模块。网络中通过两次Strided Conv操作来将特征图尺寸减半,相比于传统网络中多次使用池化操作减小特征图尺寸的操作,Strided Conv在将特征图尺寸减少的同时,还可以提取特征图中的信息,整个网络也只使用了两次Strided Conv操作,减少了因特征图尺寸改变所导致的特征图信息丢失现象。值得注意的是,为了减少网络深度加深导致的信息丢失的问题,整个网络使用了两次特征通道融合操作,将不同网络深度的特征信息进行通道层融合,减少了原始特征图中因为多次卷积操作而丢失的信息,每一次特征图尺寸减半操作都需要对应尺寸扩张操作将特征图尺寸,由于本网络只使用了两次尺寸减半操作,因此减少了整个网络的权重参数。网络权重参数的数量为7.2 MB,相比于传统网络参数数量更少。
1 模块设计及网络结构
1.1 残差通道注意力模块(RCA)
深度学习领域中的注意力机制(attention mechanism)和人类的视觉选择性注意力机制类似,往往关注于已收集信息的某些特定部分。考虑到该机制在辨别和聚焦方面的优势,注意力机制已广泛应用于各种人工智能领域。然而,大多数致力于获得更好性能的方法不可避免地增加了模型的复杂性。文献[19]提出了一种有效的通道注(ECA)模块,使用1D卷积来避免压缩和激励块中的降维操作,这大大降低了模型的复杂性,同时保持了优异的性能。然而,在ECA模块中,仅仅使用平均池化会丢失大量信息,为了减少信息丢失,本文采用平均池化和最大池化来获得更精细的通道注意模块,通道注意机制通过自动学习来学习每个特征通道的重要性,并使用获得的重要性来增强重要特征,抑制对视网膜血管分割任务不重要的特征,从而进一步增强网络对于血管的辨别能力。通道注意机制(CA)通过自动学习来学习每个特征通道的重要性,由于眼底视网膜图像中亮度不均匀、血管形状以及病理噪声等都会对血管的分割造成干扰,CA通过增大含有血管像素的特征图通道的权重来增加网络对血管像素的学习能力,抑制视网膜眼底图像中噪声的干扰。
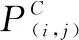

图1 CA模块
(1)
(2)
Pr=σ(Pm1D+Pa1D)
(3)
Po=Multiply(P,Pr)
(4)
为了解决神经网络中层数加深所导致的梯度消失和梯度爆炸等问题,更好地发挥注意力机制的作用,网络采取残差网络(ResNet,residual network)[20]模块相结合的方式构造了如图2所示的残差通道注意力模块(RCA),使用批量归一化(batchnormalization)、ReLU激活、3×3卷积层和Spatialdropout来构造残差学习块,然后在最后引入通道注意力模块来增加残差模块所提取特征图中重要特征通道的权重值。

图2 RCA模块
1.2 多尺度空洞卷积模块(MDC)
受到文献[21]启发,为了捕获到更加完整的视网膜血管边缘特征,本文构建了如图3所示的多尺度空洞卷积模块(MDC)。多尺度空洞卷积模块采用残差网络结构,首先使用一个3×3的普通卷积进行初步的特征提取,然后利用批量归一化和ReLU激活函数滤掉其他冗余信息。为了获得不同范围的特征信息,在多尺度空洞卷积模块中使用3种不同感受野的卷积核来对视网膜血管特征图进行边界信息的提取;然后将3个空洞卷积的输出进行通道拼接。拼接后 的信息经过一次1×1的卷积将通道数变为和输入通道一样,最后与通过残差结构将原始输入的特征图进行维度拼接与特征融合,在提升血管特征提取精度的同时,还可以获得丰富的血管边界特征信息。普通卷积感受野范围有限,如果需要增大感受野则需要增大卷积核对大小,但这又会大大增加网络的参数数量,使用空洞卷积可以在不增加参数量的情况下增加卷积核的感受野,但是连续使用相同空洞率的空洞卷积会造成网格(gridding)效应等问题,为了解决 “网格化”问题,本文参考了文献[22]的方法,使用了一个空洞率r=[1,3,5],卷积核大小为3×3的多尺度空洞卷积,多尺度空洞卷积可以在不改变卷积参数量的前提下,通过增大空洞率来提升卷积核的感受野。同时,多尺度空洞卷积的特征提取能够覆盖更多的像素点,可以提取到不同尺寸视网膜血管的特征,能够获得视网膜血管更远距离的上下文信息,得到更加细致的血管边界特征。
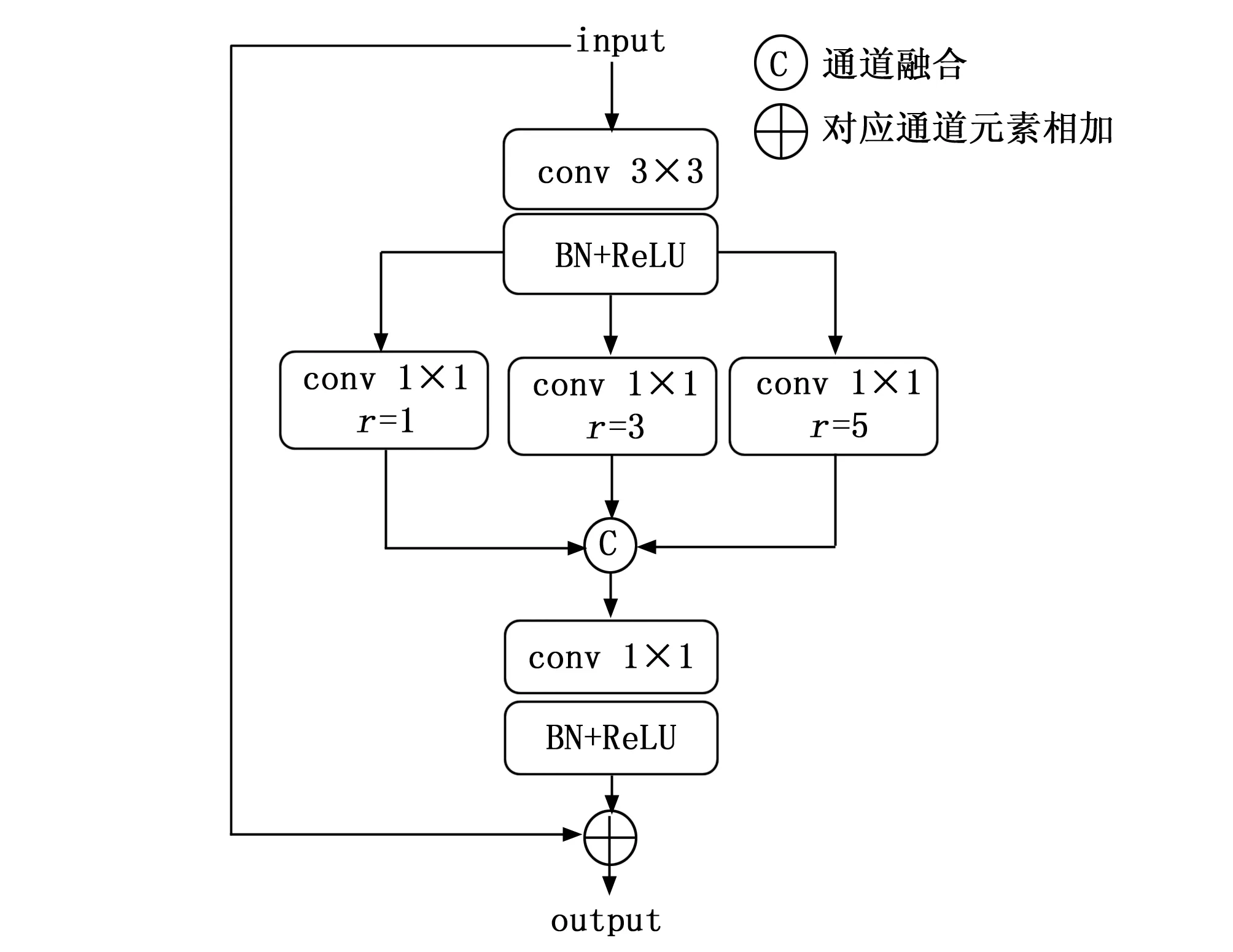
图3 MDC模块
1.3 网络结构
本文设计了一种的新的视网膜血管分割网络。如图4所示,网络以残差通道注意力模块(RCA)和多尺度空洞卷积模块(MDC)相结合来作为特征提取模块提取眼底图像的血管信息,这不仅可以解决加深网络所导致的网络退化问题,同时可以使网络捕获到多尺度的血管信息,增加特征图中重要信息的权重。网络通过两次跨步卷积将特征图进行两次尺寸减半,再进行一次特征提取操作,之后通过一次反卷积操作将特征图尺寸扩大一倍。将第一次尺寸减半操作的输出继续进行一次特征提取操作,然后将此次特征提取的输出与第一次特征提取的输出和第一次反卷积的输出进行通道融合,然后通过1×1卷积操作压缩融合的特征图通道数,将通道压缩后的特征图再进行一次特征提取操作,然后进行第二次反卷积操作,此时,特征图经过第二次反卷积操作的输出尺寸与网络输入图像的尺寸一样,将它们进行特征融合来获得网络深层与浅层的特征,然后将此次融合的特征进行1×1卷积和特征提取操作,然后通过1×1卷积对其进行通道压缩,最后经过sigmoid函数对其分类得到最终预测血管图。网络中每一次卷积后都经过一次数据归一化和ReLU操作来缓解梯度消失。网络中特征提取通道数最深为64层。

图4 网络结构
2 实验结果与分析
2.1 数据集与预处理
本文使用了两个公开可用的数据集,即DRIVE和CHASE-DB1。DRIVE数据集由40个RGB图像组成,每幅图像的像素为584×565,每张图像带有视网膜血管的像素级专家注释。这些图像是使用佳能 CR5眼底相机捕获的。DRIVE数据集提供了20个训练图像和20个测试图像的预定义官方数据拆分。CHASE-DB1数据集包括28个RGB图像,每幅图像的像素大小为999×960,每张图像带有视网膜血管的像素级专家注释。这些图像是使用NidekNM-200D眼底相机捕获的。CHASE-DB1数据集提供了20个训练图像和8个测试图像的预定义官方数据拆分。为了适应本文网络模型,将DRIVE、CHASE-DB1数据集图片的大小扩大为592×592、1 008×1 008,并将图像中非眼球部分用零填充。为了获得更合理的结果,本文在评估时将分割结果裁剪为初始寸。为了增强网络的鲁棒性,本文采用随机旋转和水平、垂 直和对角线翻转的方式来增加DRIVE、CHASE-DB1数据集的训练图像。
2.2 损失函数
二元交叉熵(BCE,binary cross entropy)损失函数是二分类问题中常用的一个Loss损失函数,其公式为:
(5)
式中,gi为像素点的二元标签0或者1,pi为像素点i输出属于gi标签的概率。
2.3 参数设置
本文实验环境为云服务器,显卡为RTX 3090。模型在TensorFlow 2.5.0框架上进行实验,batch size设为4,选择Adam作为优化算法,训练总轮次为100,前75次学习率设置为10-3,后25次学习率设置为10-4。
2.4 评价指标
为了定量分析模型的分割结果,并能够更好地与其他网络进行对比.本文采用准确率(accuracy)、灵敏度(sensitivity)、特异性(specificity)、和AUC(area under ROC curve)值作为评判标准。AUC的值越接近1,表示模型的分割能力越好。准确率、灵敏度、特异性的定义如下:
(6)
(7)
(8)
式中,TP表示正确分割的血管像素点数;TN表示正确分割的背景像素点数;FP表示错误分割的血管像素点数;FN表示错误分割的背景像素点数。
2.5 实验结果
本实验在DRIVE、CHASE-DB1数据集上对本文网络分割结果进行验证。分割结果如图5所示,图中第1~2行为DRIVE数据集图像,第3~4行为CHASE-DB1数据集图像,图(a)~(d)分别为原图、标签、本文算法所分割的结果和分割细节对比图。由图可知,本算法可以很好地将视网膜眼底图像中的血管分割出来,针对传统网络无法识别分割的血管末端细小血管,本文算法也可以将其精确识别分割出来。值得注意的是,本文算法在DRIVE和CHASE-DB1数据集上测试结果所得精确度分别达到了0.968 5和0.973 9,灵敏度分别达到了0.840 3和0.865 0,这表明本文算法不仅可以精确识别眼底图像中的像素点,同时能够精确识别视网膜眼底图像中的细小血管。
图5 不同数据集分割结果
在DRIVE和CHASE-DB1数据集测试的ROC曲线如图6所示,图6(a)和(b)为分别在DRIVE数据集和CHASE-DB1上测试得到的ROC曲线。在两个数据集上AUC的值分别达到了0.986 3和0.989 9,表明血管存在误分割的可能性较小。

图6 不同数据集ROC曲线
2.6 算法对比
为了验证本文改进模型在眼底视网膜血管分割上的分割性能的优越性,将本文方法在DRIVE和CHASE-DB1公共眼底图像数据集上进行测试,以Accuracy、Sensitivity、Specificity,和AUC作为评价指标与近年相关算法做对比。表1和表2分别展示了在DRIVE和CHASE-DB1所示将本文所提算法在DRIVE和CHASE-DB1数据集上的性测试结果与目前先进的算法进行对比,其中最优指标加粗表示。相较于原始的UNet分割结果,在DRIVE数据集下的测试结果,本文算法在精确度、敏感度、特异性和AUC值4个评价指标分别提升了1.27%,4.62%,0.1%和0.16%,在CHASE-DB1数据集上分别提升了1.31%,4.74%,1.08%和0.34%,其中在两个数据集的测试中,精确度均提升了1个百分点以上,灵敏度均提升了4个百分点以上,其中,由于CHASE-DB1数据集的分辨率999×960,比DRIVE数据集的584×565高,所以在CHASE-DB1数据集的测试精确度和灵敏度均比DRIVE数据集更高,对于分割网络中尺寸减半所导致的细小血管消失问题,所受到的影响更小,这也证明了更高的分辨率对于视网膜眼底图像血管分割效果有益,因此本文所设计的网络中只使用两次尺寸减半操作,通过通道连接将不同深度的特征信息融合对于提升视网膜眼底图像血管分割的精确度和灵敏度是有效的,相比近年来的其他算法的分割结果,本文算法在精确度,灵敏度和AUC值也均取得了最高值,因此对于视网膜血管分割,本文所题方法更具优势。

表1 DRIVE数据集上的平均性能指标评估结果

表2 CHASE-DB1数据集上的平均性能指标评估结果
3 结束语
为了避免分割后细小血管像素模糊、丢失等现象,提升血管分割灵敏度和精确度,本文设计了一种新的视网膜血管分割算法。将RCA和MDC模块相结合作为网络的特征提取模块。网络中特征图尺寸减半和尺寸扩大操作均只使用了2次,减少了网络因特征图尺寸改变所导致的微小血管的丢失现象,特征图的通道数最多为64层,网络权重参数只有7.2 MB。与此同时,网络通过融合操作使得深层特征图与对应尺寸的浅层特征图进行通道融合,减少了因为网络深度加深所导致的信息丢失问题。实验结果表明,本文算法结构有效提高了灵敏度和精确度,能够减少视网膜眼底图像中微小血管无法被分割的情况,相比其他算法对视网膜血管分割更具优势。
