改进YOLOv5的多车辆目标实时检测及跟踪算法
2023-10-14蒲玲玲杨柳
蒲玲玲, 杨柳
(1.西南交通大学唐山研究生院, 唐山 063000; 2.西南交通大学综合交通大数据应用技术国家工程实验室, 成都 611756; 3.西南交通大学信息科学与技术学院, 成都 611756)
对于车辆的跟踪研究属于目标跟踪问题中的多目标跟踪问题,多目标跟踪的解决步骤一般为两步,目标检测和目标数据关联。先使用目标检测算法将感兴趣的目标进行定位和分类,再使用目标数据关联算法,将不同帧之间的相同目标进行关联,以确定不同帧中的目标是否为同一目标。在多目标跟踪问题上,除了目标检测算法的性能对跟踪性能影响大以外,前后帧之间的目标数据关联也同样影响着跟踪的性能。多目标跟踪发展到现在,根据Re-ID(re-identification)模块是否融入目标检测网络,可分为DBT(detection-based tracking)和JDT(joint detection tracking)两类[1],前者将目标检测和Re-ID模块分为两个网络实现,具有较高的准确率,是当前基于深度学习的视觉多目标跟踪的主流方法;后者将DBT两模块联合,具有较高的运行速度,是近两年发展的新趋势。
如何提高多目标跟踪的推理速度一直是近年来研究的热点。Wojke等[2]提出了DeepSORT算法来进行多目标跟踪。毛昭勇等[3]使用EfficientNet作为YOLOv3的骨干网以提高检测速度,将推理耗时的骨干网替换为轻量级网络,减小目标检测网络的推理时间。武明虎等[4]将YOLOv3的损失函数和网络结构进行改进后,与SORT算法相结合进行目标跟踪,跟踪速度最快可达14.39 fps。Zuraimi等[5]将YOLO和DeepSORT用于道路上的车辆检测和跟踪,权衡精度和时间后,证明了使用YOLOv4要好于YOLOv3,在GTX 1600ti上的以YOLOv4为目标检测网络的DeepSORT的总体跟踪速度为14.12 fps。Zhang等[6]提出了FairMOT算法,该算法在大小为输入图像的1/4的高分辨率特征图上使用无锚框的方式进行目标检测和目标外观特征提取,使特征图上的目标中心更准确地对齐到原图上,获取更准确的目标外观特征。Liang等[7]为避免使用JDT方式进行目标跟踪时,两个学习任务在一个网络中出现恶性竞争问题,提出了CSTrack模型,以推动每个分支更好地学习不同的任务。CSTrack模型在单GPU上推理速度为16.4 fps,有较高的多目标跟踪速度。
YOLO发展至今已有多个版本,YOLOv5基于他的灵活性和较低的推理时延,多位学者将其应用在目标检测和跟踪领域。赵桂平等[8]以YOLOv5框架为基础,借鉴了两步法的优点,在边框生成方面进行改进,提高了YOLOv5的检测精度。Wang等[9]使用YOLOv5s进行目标检测,使用SiamRPN进行单目标跟踪,综合跟踪速度为20.43 fps。Neupane等[10]使用YOLOv5进行检测,使用质心算法进行跟踪,跟踪速度最高可达38 fps,但是仅在手工绘制的一小块跟踪框内进行跟踪,不进行长时间跟踪。黄战华等[11]使用YOLOv5m进行检测,使用位置+声源信息进行跟踪,在平均2个目标的情况下跟踪速度达到34.23 fps,但在跟踪时只能定位一个声源,多声源情况下会存在干扰,多目标跟踪时,跟踪精度差。张文龙等[12]使用EfficientNet、D-ECA(DCT-efficient channel attention module)注意力模块、AFN(associative fusion network)改进YOLOv5,平均跟踪速度为10.84 fps。张梦华等[13]为解决多个行人交错运动时出现跟踪错误的问题,在使用YOLOv5+DeepSORT对目标进行跟踪后,再引入ReID(re-identification)技术去纠正行人的运动轨迹,提高跟踪的精度。此方法在YOLOv5+DeepSORT跟踪方式上额外增加了ReID网络,虽然提高了跟踪精度,但由于引入更多的神经网络,故需要消耗更多的推理时间。以上基于YOLOv5的检测+跟踪算法,均有较快的跟踪速度,但可能更适用于少目标或单目标跟踪,用于多目标跟踪时跟踪精度和推理速度还需再提高。
基于上述方法启发,提出ReID特征识别模块,将该模块添加到YOLOv5网络中,使YOLOv5网络在输出目标边界框的同时输出目标的特征信息,以代替DeepSORT中的特征提取网络,从而提高目标跟踪的推理速度。同时提出一种基于动态IOU(intersection over union)阈值的非极大值抑制算法,该算法根据每个边框的置信度为每个边框设置不同的IOU阈值,以提高目标彼此覆盖场景下的跟踪精度,对较多目标进行更准确的实时跟踪。
1 基于YOLO的多目标跟踪算法
对于车辆的多目标跟踪为目标检测和目标跟踪两步。目标跟踪主要是将目标的位置和表观特征等信息进行关联,得出相邻帧之间那些目标是同一个目标。目标检测的工作主要是在图像中找出感兴趣的目标对其进行定位和分类。基于深度学习的目标检测模型发展到现在,可以分为以R-CNN(region-CNN)为代表的基于候选框(two-stage)的算法模型和以YOLO为代表的基于回归(one-stage)的算法模型两类[14],前者算法模型在精度上高于后者,后者在推理时间的表现上好于前者。使用目标检测算法对道路上车辆的检测,除了对算法的精度有要求外,还需对其推理时间有一定要求。故选择基于回归的一步式YOLO目标检测算法来保证较小的推理时间。
1.1 YOLO目标检测算法
YOLO网络发展至今已有多个版本,其结构一般分为骨干网、特征融合层、3个不同大小的预测头。其用3个不同大小预测头分别检测不同大小的目标,以在追求速度的同时保证精度。
YOLOv4基于YOLOv3网络结构进行改进,在提高精度的同时也提升了推理速度。YOLOv4为降低主干网的推理时间,在残差网络的基础上组合成CSP(cross-stage-partial)模块,CSP模块能够在加快模型推理速度的同时尽可能的保持精度性;使用SPP(spatial pyramid pooling)结构将不同大小的特征进行融合,增加网络的感受野,有利于检测出图像中不同大小的目标;为将特征进行充分融合,设计PANet(path aggregation network)特征融合网络,相比于YOLOv3采用的FPN(feature pyramid networks)自顶向下单向特征融合方法,PANet采用自底向上再自顶向下的双向融合方法,获得更丰富的目标特征信息。
YOLOv5同YOLOv4一样使用CSPDarknet、Neck和3个输出头的网络结构,模型架构与YOLOv4相似。YOLOv5有s、m、l、x 4种大小的结构相同,但宽度和深度不同的模型可供使用,4种模型推理速度依次降低,推理精度依次升高。在训练时YOLOv5使用Mosaic数据增强将4张图片合并为一张图片进行输入,减小训练花费的时间同时变相增大batch_size;使用自适应锚框计算,能在小目标的检测上有更好效果;在主干网中使用focus结构,起到减少计算量和提高速度的作用。YOLOv5有两种CSP结构,在主干网中使用CSP1结构,在Neck网络中使用CSP2结构,以此加强特征融合能力和减少计算量。且CSP结构深度随模型的深度变化而变化。
1.2 改进YOLOv5的多目标跟踪网络结构
JDE(joint detection and embedding)算法[15]通过在YOLOv3的3个预测头中添加特征层,将对目标特征的输出也交给YOLO网络,提高了多目标跟踪的推理速度,但在3个不同分辨率的特征层上面进行特征提取,当相邻帧中同一目标大小变化明显时,可能检测结果是不同的预测头输出的,由于检测头的分辨率不同,从而导致同一目标在相邻帧获取到的特征相差过大,导致跟踪失败。FairMOT[6]算法为了提取到更准确的目标特征,将输入图片设置为1 088×608,在1/4原图大小的特征图上进行目标位置预测和特征提取,跟踪精度得到了提升,但输入图片分辨率大且在较大特征图上预测和特征提取会非常耗时,导致跟踪速度过慢。基于此,将YOLOv5模型进行改进,使YOLOv5在输出目标位置信息的同时输出目标的特征信息。改进后的YOLOv5网络结构如图1所示,在YOLOv5网络中添加ReID模块,该模块由特征输出模块和ID(identity)分类模块共同模块组成。
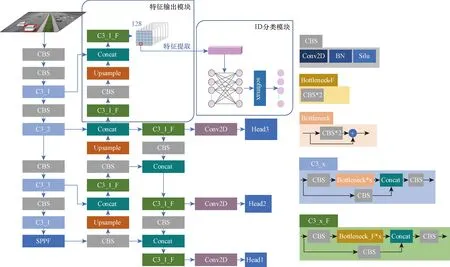
图1 改进后的YOLO网络结构Fig.1 Structure of improved YOLO
1.2.1 特征输出模块
神经网络学习过程中,低层特征分辨率更高,包含更多的位置、细节、颜色等信息,但由于经过的卷积较少,其语义信息含量低,噪声更多;高层特征包含更多的语义信息,但其分辨率低,对细节的感知能力较差。且如果在较小的特征图(1/8、1/16、1/32)上提取表观特征,会因为特征图分辨率太小,导致特征图上的目标中心不能很好地与原图中心对齐,出现表观特征提取粗糙的问题;如果在较深层特征层上提取特征,会获得更多的语义信息,较少的颜色和细节等浅层信息,导致不同目标的提取到的特征不能很好地区分。
以上两种提取方式均容易造成目标跟踪错误。故特征输出模块为使目标能够提取到较为精细准确的特征,将PANet继续自底向上进行上采样到1/4原图大小,再与主干网中1/4原图大小的特征进行融合,最后输出原图1/4大小的128维的特征图,作为提取目标特征的特征池。与浅层1/4原图大小的特征层进行融合后,特征池不仅包含丰富的语义信息,也包含丰富的颜色细节等信息,可为不同目标提供有区别的特征。且得益于特征池的高分辨率,能为邻近目标提供精准的特征。
在训练阶段使用标签直接定位到特征池128维特征,如图1所示的网络框架图中检测图上的用红色框框出的车辆位置,对应到特征池中的红色框框出的单位128维特征;在推理阶段提取目标特征时需结合YOLO输出的目标位置信息,定位到特征池单位128特征。使用目标的位置信息在特征池中定位目标特征,提取到和目标唯一对齐的单位128维特征作为该目标的特征。
1.2.2 ID分类模块
ID分类模块用以训练网络的目标特征识别能力,使网络能够输出正确的和不同目标有区别的目标特征,其仅在训练模型时使用。ID分类模块设计为两层的全连接层,设计128个节点进行输入,ID总数个节点进行输出,将特征识别问题转换为ID分类问题。在训练模型时,将目标的真实框中心定位到特征池上,从特征池中提取该定位处的128维特征,将该128维特征作为全连接层的输入,将ID总数数量的节点作为全连接层的输出,并且采用softmax对输出的数据进行归一化,获得该目标的类别概率。然后使用交叉熵损失函数计算ID损失。softmax函数表达式为
(1)
式(1)中:zi为第i个节点的输出值;zc为第c个节点的输出值;C为输出节点的总数。
1.3 动态IOU阈值的非极大值抑制算法
公路监控安装并非总是正对车辆,如果摄像头安装在公路边侧,离摄像头较远的哪一方公路上的车辆在视频里会很容易出现彼此覆盖的情况。对于彼此覆盖的目标检测,针对不同的问题有不同的解决方法。其中,针对覆盖场景构建对应数据集,直接进行训练,但是由于覆盖的多样性和数据的难收集性这种方式非常困难;如果是神经网络提取的特征不充分,可以针对损失函数和网络结构进行改进;如果是网络特征提取充分但是在覆盖场景下仍表现不好,可以考虑是非极大值抑制(non-maximum suppression,NMS)将相邻的检测框过滤了。
车辆经过目标检测网络检测后,非极大值抑制会基于边框置信度和IoU(intersection over union)阈值抑制重叠的边框。当相邻目标的检测框彼此重叠面积较大,会出现只留下一个目标的检测框,另一个目标的检测框被抑制的情况,导致对其中一个目标检测失败,进而导致跟踪失败。为此,提出一种基于动态IoU阈值的非极大值抑制(dynamic non-maximum suppression,DNMS)算法。DNMS算法对YOLO预测到的边框赋予一定的信任,根据每个边框的置信度得分,对每个边框设置不同的IoU抑制阈值。对边框置信度得分越大的置于更多的信任,设置更大的IoU过滤阈值,来保留相互大面积覆盖的正确边框。
DNMS算法中引入两个超参数supC和supT,分别用作过滤掉置信度较低的边框和根据置信度设置IOU阈值,两个参数的数值可根据数据集等实验因素自由确定。当计算出的IOU阈值小于0.35时,设置为0.35,以避免不同车辆边框覆盖面积很小就被抑制掉。DNMS算法伪代码如下,其中Ni为第i个边框的IOU阈值。

DNMS算法Input: The list of initial detection boxes, B = {b1,b2,…, bN}; The list contains corresponding detection scores, S = {s1,s2,…, sN};Output: The list of remaining detection boxes after DNMS, D = {b1,b2,…, bn}; The list contains corresponding detection score C={s1,s2,…, sn}1: D = {}; C = {}2: while (B ≠ Empty) do3: m = Max(S)4: M = bm; N = sm5: D = D∪M; C = C∪N; B=B-M; S=S-N6: forbi inB do7: Ni= (si -supC) * supT8: if 0.35> Ni > 0 then9: Ni = 0.35 10: end if11: if IoU (M, bi)> Nithen12: B = B -bi; S = S -si13: end if14: end for15: end while16: returnD, C
1.4 损失函数设计
对于ID分类模块,采用交叉熵损失函数进行损失计算,其余损失函数采用YOLOv5原设计损失函数。
ID分类模块损失函数为
(2)
式(2)中:M为类别的数量;当样本i真实类别为c时yic取1,否则取0;pic为样本i属于类别c的概率;N为样本总数。
对于目标检测的置信度损失Lconf,为二元交叉熵损失,可表示为
(3)
对于目标检测的类别损失Lcls,为二元交叉熵损失,可表示为
(4)

对于目标检测的位置损失Lloc,为GIoU损失,可表示为
(5)
式(5)中:IoU为预测框和真实框的交并比;Ac为同时包含预测框和真实框最小矩形面积;U为预测框和真实框的并集。
目标检测的损失和可表示为
Ldet=Lconf(o,c)+Lcls(o,c)+Lloc
(6)
最后,总的损失函数可表示为
(7)
式(7)中:wdet和wid分别为通过任务的独立不确定性自动学习方案[16]学习得到的目标检测损失权重和ID类别损失权重。
1.5 多目标跟踪
基于改进YOLO的多车辆场景目标跟踪的跟踪流程图如图2所示。视频流输入后,会先使用改进后的YOLO算法检测出每帧中目标的位置和特征信息。然后将目标的位置信息采用卡尔曼滤波进行预测,预测目标的下一帧位置,使用当前帧目标位置和上一帧目标预测位置进行马氏距离计算,得到目标和轨迹的位置距离;使用当前检测的特征和轨迹近100个特征进行余弦距离计算,取最小的距离作为目标和轨迹之间的特征距离。之后将获得的两个距离进行数据匹配来判断相邻帧的目标是否为同一目标。匹配算法主要使用匈牙利匹配和IOU匹配,先使用匈牙利对目标和轨迹之间的位置信息和特征信息进行匹配,若匹配成功则将该目标直接加入到轨迹,若匹配失败,则再进行IOU匹配,匹配成功则加入轨迹,匹配失败则创建新轨迹。

图2 跟踪流程图Fig.2 Flow chart of tracking
提出的多目标跟踪算法未特别说明处均使用多目标跟踪流程进行跟踪。
2 实验结果与分析
2.1 实验环境
实验操作系统为64位Windows10;硬件环境主要包括:Intel(R) Xeon(R) W-2223 CPU@3.60 GHz、内存32 GB、训练环境中显卡型号为NVIDIA TITAN xp,验证环境显卡型号为NVIDIA Quadro P2200、深度学习框架为pytorch。训练的数据集采用UA-DETRAC[17]公开数据集。在训练改进后的YOLOv 5 m时采用在coco数据集上训练好的权重结果作为预训练权重,训练批次(batch_size)设置为16,训练轮数(epoch)设置为50个。
2.2 数据集与评判指标
数据集采用UA-DETRAC公开数据集,该数据集是车辆检测和跟踪的大规模数据集,数据集主要拍摄于北京和天津的道路过街天桥,并手动标注8 250个车辆和121×104个目标对象外框[17]。车辆分为:轿车、公共汽车、厢式货车和其他车辆。天气情况分为:多云、夜间、晴天和雨天。在使用该数据集前将原始数据的xml格式标签转换为YOLOv5所需的标签格式,因为需要进行ID识别,故需要在标签中包含类别和位置的同时添加目标的ID。YOLOv5修改后的标签格式定义为:<目标类别、目标x坐标中心、目标y坐标中心、目标宽、目标高、ID>。
为评价跟踪的性能,采用Dendorfer等[18]提出的多目标跟踪算法评价指标进行评价,主要选取多目标跟踪精度(multiple object tracking accuracy,MOTA)、MT(mostly tracked)、ML(mostly lost)、IDs(ID switch)、假阳性(false positive,FP)、假阴性(false negative,FN)作为评估指标,另添加每秒帧数(frame per second,FPS)评估模型每秒处理的帧数。其中MOTA用于评价多目标跟踪的精准度,用以统计在跟踪过程中误差的积累情况,其表达式为
(8)
式(8)中:FNt、FPt、IDst、GTt分别为第t帧时FN、FP、IDs、GT指标的数值;t为帧数。
2.3 结果与分析
2.3.1 YOLOv5+ReID跟踪实验
为提高多目标跟踪模型的推理速度,在目标检测网络上选择推理速度更快的YOLO。YOLO有多个版本,将ReID模块添加到YOLOv4和YOLOv5上,与使用YOLOv4和YOLOv5为目标检测网络的DeepSORT算法(分别简写为YOLOv4和YOLOv5)对比,实验结果如表1所示。结果表明,将ReID模块添加到YOLOv4上,与以YOLOv4为目标检测网络的DeepSORT相比,MOTA指标下降了4个百分点,但推理速度有一定的提升。将ReID添加到YOLOv5上,与以YOLOv5为目标检测网络的DeepSORT对比,MOTA指标值不变,但推理速度却明显快于后者。YOLOv5相对于YOLOv4有更快的推理速度,并且在添加ReID模块后,得益于YOLOv5丰富的特征提取能力,MOTA指标并没有下降,故选择YOLOv5作为多目标跟踪网络。
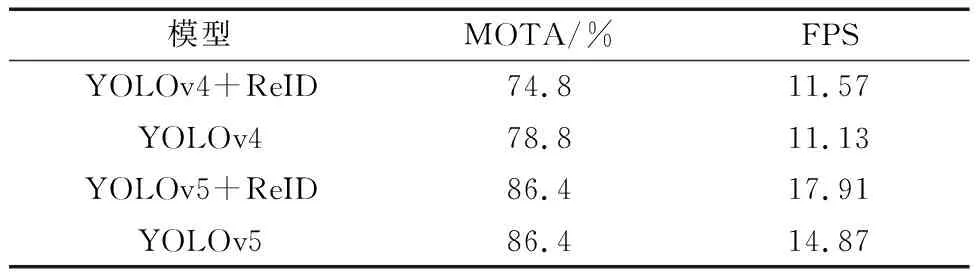
表1 ReID模块应用Table 1 ReID module application
多目标跟踪算法的推理时间主要花费在目标检测和特征提取上,经过本文方法将目标检测模型进行优化,使目标检测模型在输出目标位置信息的同时输出目标的特征信息,从而提升模型在进行多目标跟踪时的推理速度。特别是在目标多的情况下,与原算法的推理时间对比越明显。以使用YOLOv5作为目标检测网络的DeepSORT[2]和YOLOv5+ReID为例,如表2所示的两种模型在不同目标数量下的推理时间对比,可以看出,在2~4个目标的情况下,所提出的YOLOv5+ReID算法和DeepSORT算法的推理时间差值为3.83 ms,在14~16个目标的情况下,推理时间差值达到17.97 ms,推理时间差随目标的增多而增大。

表2 不同目标数量下的推理时间对比Table 2 Comparison of reasoning time under different number of targets
JDE[15]算法在3个不同分辨率的特征层上面进行特征提取,当相邻帧中同一目标大小变化明显时,可能检测结果是不同的预测头输出的,由于检测头的分辨率不同,从而导致同一目标在相邻帧获取到的特征相差过大。如图3(a)所示,在左侧图像上两车辆ID分别为67和68,右侧图片上则为69和70,发生ID切换,对同一车辆跟踪失败。所提出的YOLO+ReID算法中,不同预测头预测的目标均在同一个特征池中提取特征,在相邻帧中目标大小变化明显时,无论检测结果是那个输出头输出的,都根据输出头输出的目标位置信息在同一个特征池中定位特征。如图3(b)所示,在左侧图像上两车辆ID分别为42和43,右侧图片上仍为42和43,没有发生ID切换,对同一车辆跟踪成功。

图3 IDs对比Fig.3 IDs comparison
采用IDs指标来评判JDE算法和YOLOv5+ReID算法对目标ID切换的数量。验证数据采用UA-DETRAC数据集中6个不同场景的视频段:MVI_20011、MVI_30761、MVI_40192、MVI_40241、MVI_63544、MVI_63563进行验证。实验结果如表3 所示,JDE算法的IDs为399,YOLOv5+ReID算法的IDs为65,两者相比,YOLOv5+ReID的目标ID切换量明显较JDE少。

表3 IDs数量对比Table 3 Comparison of IDs quantity
2.3.2 DNMS算法检测实验
为验证DNMS算法对彼此遮挡目标的检测有效性,选取UA-DETRAC数据集中摄像头倾斜于车道布设所获得的视频段:MVI_63544和MVI_40241作为验证数据,其中MVI_40241视频段中的车流量相对MVI_63544视频段中的车流量大,车辆总数也远高于MVI_63544视频段。使用NMS算法、DIOU-NMS[19]算法、Soft-NMS[20]算法和DNMS算法进行对比,采用FN(false negative)和FPS指标来评判算法在两个视频段上漏检的车辆数量。表4为非极大值抑制算法对比结果。在对车辆的漏检上,本文算法在MVI_40241上漏检量为1 021,明显少于对于其他3种算法,在MVI_63544视频段中的漏检数为172,与其他算法持平。在推理速度上,所提出的DNMS算法相对于NMS算法,由于计算量更大,故在推理速度上会比较慢,但相对于DIoU-NMS和Soft-NMS算法,本文算法更有优势。

表4 非极大值抑制算法对比Table 4 Comparison of non maximal suppression algorithms
针对彼此覆盖的目标,采用DNMS算法代替原有的NMS算法。分别在所提出的YOLOv5+ReID算法和JDE[15]算法上验证DNMS对彼此遮挡目标检测的有效性。实验结果如图4所示,其中,图4(a)、图4(c)使用NMS算法进行边框抑制,图4(b)、图4(d)使用本文提出的DNMS算法进行抑制。可以看出,在图4(a)和图4(c)中的红色椭圆框中,框出的车辆里,有一个车辆无检测框,而在图4(b)和图4(d)中,该车辆的检测框得以出现。实验结果表明,使用本文提出的DNMS算法能够检测到NMS算法不能检测到的车辆。

图4 DNMS实验结果Fig.4 DNMS experimental results
采用FN指标来评判使用DNMS的模型分别在MVI_40241视频段和MVI_63544视频段,漏检的车辆数量。实验结果如表5所示。YOLOv5+ReID使用DNMS算法后在两个视频段上漏检分别减少312和5;JDE使用DNMS算法后在两个视频段上漏检数量分别减少22和2。实验结果表明,将所提出的DNMS算法用在其他模型上也仍然有效。

表5 漏检数量对比Table 5 Comparison of missing inspection quantity
2.3.3 改进YOLOv5的目标跟踪实验
使用以YOLOv5为目标检测网络的DeepSORT[2]和JDE[15]、FairMOT[6]算法和本文算法,在UA-DETRAC数据集上6个不同场景的视频段,共9 389帧上进行推理精度和速度的对比。
实验结果如表6所示。FPS指标在每张图的跟踪数量为7~16上计算得到。由表6可知,将YOLOv5网络结构加上ReID模块,和基于无锚点预测边框和在1/4原图大小上直接进行目标预测的FairMOT算法对比,在UA-DETRAC数据集上,本文算法的FPS为17.91,明显高于该算法的5.71。和JDE算法相比,所提的YOLOv5+ReID算法的IDs为65,明显小于JDE算法的399。和DeepSORT算法相比,本文的YOLOv5+ReID的平均推理时间减少了11.41 ms。

表6 多目标跟踪算法的性能对比Table 6 Performance comparison of multi-target tracking algorithms
将DNMS算法运用在YOLOv5+ReID模型上,相对于YOLOv5+ReID模型,跟踪精度MOTA提升了3.9个百分点。实验结果表明,所提出的YOLOv5+ReID+DNMS算法相对于其他算法,在保证推理速度的情况下,在跟踪精度上有明显的优势。
3 结论
为将多目标跟踪模型应用在多车辆场景下,从而设计低推理时延高精度的跟踪模型。针对多目标跟踪推理时间长的问题,在YOLOv5网络结构上进行改进,设计了ReID模块,该模块将YOLOv5的PANet继续上采样,获得一个特征池,使改进后的YOLOv5模型在输出目标位置信息的同时输出特征信息。针对车辆间彼此覆盖的情况,为提高跟踪精度,提出一种基于动态IOU阈值的非极大值抑制算法,该算法根据每个边框的置信度得分,对每个边框设置不同的IOU抑制阈值,以此减少车辆密集场景下对车辆的漏检。实验结果表明,在YOLO网络中添加ReID模块能明显地减少目标跟踪的推理时间;使用基于动态IOU阈值的非极大值抑制能明显的增加目标跟踪精度。将ReID和基于动态IOU阈值的非极大值抑制用在YOLOv5模型中,与FairMOT、JDE、DeepSORT算法进行对比,改进后的模型有较好的跟踪精度和实时性。
