基于机器学习的低渗透砂岩聚合物驱采收率预测
2023-10-14蒲堡萍魏建光周晓峰尚德淼
蒲堡萍, 魏建光*, 周晓峰, 尚德淼
(1.陆相页岩油气成藏及高效开发教育部重点实验室, 大庆 163711; 2.东北石油大学石油工程学院, 大庆 163319)
据估计,约2/3的石油在初次生产后留在油藏中[1]。低渗透砂岩储层是可观的采油储层,但由于储层物性、化学剂、注入能力等因素的限制,化学驱在低渗透储层的应用较少。低渗透储层非均质性显著,油层的非均质性及水油的黏度差导致注入水前缘不规则,出现水未波及区的剩余油和水波及区的残余油。因此,以提高宏观波及系数为主,以提高微观洗油效率为辅,主要利用聚合物增加注入水的黏度,降低油水流度比,提高波及系数,可有效提高采收率[2]。
前人研究中,在现场规模应用前,提出的化学提高采收率方案都要进行实验室评估[3-6]。岩心驱替实验需要耗费研究人员大量的时间、精力和成本,而机器学习可以成为提高筛选效率和研究变量关系的更快速、准确、智能的方式,从而解决这些问题。研究表明,对低渗透油藏的采收率预测分为现场生产资料预测和实验室数据预测。现场预测可以直接促进粗放调整生产[7-10],实验室预测可以促进精细油藏科学问题研究[11]。目前,学者们针对现场预测的研究较多,而关于实验室预测研究较少。机器学习方法已经广泛应用于石油工程领域,岩心化学驱替实验为增产措施提供第一手资料。但由于天然岩心不易获得且实验过程耗时较长,矿场在未取得实验数据时凭借经验开始采取增产措施,缺乏科学的决策过程。因此,建立可靠有效的采收率预测模型对化学驱方案快速的实施,给予决策科学的论证过程及可靠的采收率数据,促进实验变量关系的进一步探索具有重要意义。但目前针对不同机器学习算法进行低渗透砂岩聚合物驱替实验预测模型的综合比较研究鲜见报道,尚未建立实验-模型一体化研究体系。
鉴于此,首先进行了3个聚合物驱替实验项目获取实验数据,其次构建14种机器学习模型进行评估,最后选出最优的模型进行特征重要性分析,建立可靠有效的采收率预测模型。研究成果有助于筛选聚合物驱方案和研究影响采收率的元素,稳健且快速地在低渗透储层应用。
1 材料和方法
1.1 实验材料和仪器
如图1所示,主要的实验材料和条件:50 mD渗透率的天然露头方岩心,岩心尺寸为4.5 cm(长) × 4.5 cm(宽) × 30 cm(高);模拟地层油45 ℃下黏度为9.7 mPa·s;粉状抗盐中分JD1200-1600;模拟地层水矿化度为2 520 mg/L(弱矿化水);恒温箱实验温度为45 ℃。

图1 实验主要材料Fig.1 Principal experimental materials
如图2所示,主要的实验装置:ZMY型致密岩心渗流特性测定仪(海安石油科研仪器有限公司);恒速恒压注入泵;DF-101S集热式恒温加热磁力搅拌器;EUROSTART 20搅拌器;FY-ZK型抽真空预处理系统(南通市飞宇石油科技开发有限公司);并联岩心夹持器;渗透率自动测定仪。

图2 实验主要设备装置Fig.2 Principal experimental equipments
1.2 实验方案
设计了单岩心不同聚合物注入量驱油实验5组,不同聚合物注入浓度驱油实验5组,如表1所示。聚合物最大注入量为0.3 PV,最小注入量为0.1 PV,注入量增量为0.05 PV。聚合物溶液质量最高注入为2 500 mg/L,最低注入为500 mg/L,注入增量有两种步长,分别为700 mg/L和300 mg/L。为了控制注入速度剪切变量,将聚合物溶液注入速度定为0.1 mL/min。此外,设计了并联岩心不同变异系数(0.4 、0.7)条件下驱油实验2组,考察聚合物在非均质储层对驱油效果的影响。

表1 聚合物不同注入量和浓度实验方案Table 1 Experimental schemes of different injection amounts and concentrations of polymers
1.3 实验方法
1.3.1 单岩心不同聚合物注入量
①测量实验用岩心的基本物性参数,如表2所示;②实验准备工作,安装双向阀检查装置气密性;③抽真空并饱和水,抽真空时间为48 h;④饱和模拟地层油,并放置45°恒温箱熟化48 h;⑤水驱至平均含水率达98%,恒速驱替0.01 mL/min;⑥抗盐中分JD1200-1600不同聚合物注入量驱替(0.1、0.15、0.2、0.25、0.3 PV);⑦后续水驱至含水率达98 %。实验步骤及过程状态如图3所示。

表2 聚驱注入量和注入浓度实验岩心基础参数Table 2 Core basic parameters of polymer flooding injection amount and injection concentration experiment

图3 实验步骤及过程状态Fig.3 Experimental phases and state of the process
1.3.2 单岩心不同聚合物浓度
①测量实验用岩心的基本物性参数;②重复1.3.1节的步骤②~步骤⑤;③抗盐中分JD1200-1600不同聚合物注入浓度驱替(500、1 200、1 800、2 500 mg/L);④后续水驱至含水率达98 %。实验步骤及过程状态如图3所示。
1.3.3 双管并联岩心不同变异系数
①筛选驱油实验用岩心;②配置模拟地层水,地层水矿化度2 520 mg/L,模拟地层油,45 ℃条件下模拟地层油黏度为9.7 mPa·s;③利用手摇泵对岩心加围压维持在5 MPa;④利用真空泵对岩心抽真空48 h;⑤利用手摇泵饱和地层水,以压力表读数维持在0.5 MPa不变停止饱和过程;⑥饱和模拟地层油,驱替至出口端不再产水为止。之后将岩芯夹持器放置于45°恒温箱熟化48 h;⑦按照不同实验方案,采用恒速进行岩心水驱油实验,并联驱油实验时,注入端统一注、采出端单独计量;⑧利用抗盐中分JD1200-1600聚合物驱替,聚合物浓度1 500 mg/L、注入量0.2 PV;⑨后续水驱至含水率达到98 %,每隔一定时间记录出口端采油量、采水量和注入压力,当采出端综合含水率连续3个点达到98 %时,终止实验。不同变异系数条件下岩心基础参数如表3所示。

表3 不同变异系数条件下岩心基础参数Table 3 Core foundation parameters under different coefficient of variation
2 数据预处理
原始数据来自1.3节3个实验。收集的数据集涉及395条数据记录,这些数据记录分为训练集(80%)和测试集(20%)。特征输入数据由9个影响因素组成:聚合物浓度、聚合物注入量、变异系数、渗透率、孔隙度、聚合物类型、注入压力、累计注入孔隙量、含水率。唯一输出目标为采收率。原始数据基本统计描述如表4所示。

表4 原始数据基本统计描述Table 4 Basic statistical description of original data
2.1 缺失值处理
使用随机森林填补法进行缺失值处理,它具备随机性和不确定性,更加符合真实数据分布。
2.2 相关性分析
使用皮尔逊相关系数计算,用热力图呈现图像,并用欧氏距离及内平方距离法进行聚类优化相关系数等级。如图4所示,渗透率与孔隙度的相关性最高,含水率与采收率相关0.85,在低渗透注水油藏中每日配注水应格外注意吸水。此外,聚合物浓度与压力相关0.62,这是因为聚合物封堵了较高渗透层,阻力系数变大,压力升高。值得注意的是,低渗透油藏普遍存在聚合物注入困难,残余阻力系数应小于10。霍尔导数是一种新的注入能力评价方法[12],该方法已应用于俄罗斯苏托尔明斯克油田二元复合驱。此外,皮尔逊只能表示线性相关,而非因果关系。皮尔逊相关系数的计算公式为

图4 变量之间的皮尔逊相关性Fig.4 Pearson relationship among variables

(1)

2.3 输入数据处理
针对不同的机器学习算法特性进行归一化或标准化处理,计算公式为
(2)

(3)
式中:(Xmin,Xmax)取值范围为(0,1),其中,Xmin为最小特征值;Xmax为最大特征值;Xstd为离散标准化;Xscaled为特征相对缩放;X为特征值;μ为样本平均值;S为标准偏差;Z为标准化。
通过标准化计算,特征值被定心和缩放,平均值和标准偏差被存储。
2.4 离散值处理
对离散数值进行分类标签编码或热独码处理。分类标签的内涵为对原始数据进行集合运算,并且将顺序标签映射到对应的数值。若存在矩阵[145.0 140.0 38.5 … 38.5],经过顺序分类标签后转变为[0 1 2 … 2]。
热独码的内涵为每个类别创建一个二进制列,返回稀疏矩阵或密集数组。若存在2个特征向量PV[0.2 0.1 0.15]和PC[1 500 500]
则有寄存器状态矩阵为

(4)
式(4)中:第一排数字编码00101表示Line0携带PV2=PV[2]⟹PV=0.15(聚合物注入量0.15 PV)和PC1=PC[1]⟹PC=500(聚合物浓度500 mg/L)特征信息,它扩展了离散特征的欧式空间。
2.5 异常值处理
应用孤立森林算法检测异常值。在驱油物理实验过程中,设备故障或不稳定时获取的数据可能存在异常。孤立森林算法核心在于,假定随机超平面划分(蒙特卡洛)数据空间,密度低的数据将被孤立,而密度高的点将被多次划分。
3 机器学习方法
在这项工作中,应用6类机器学习算法来讨论在低渗透砂岩聚合物驱预测的表现:线性回归、最近邻回归、支持向量回归、神经网络回归、独立树回归、集成树回归。
使用Python编程语言,Visual Studio Code编辑器,scikit-learn、tensorflow、xgboost、scipy.stats、matplotlib、pandas、numpy、tpot软件包,graphviz,draw.io软件,以及自定义模块来辅助完成这项工作。
3.1 多元线性回归
简单线性回归在石油开发领域的应用是有限的,因为在大多数情况下,存在多个相关变量的预测。多元线性回归用于对多个独立预测变量和单个因结果变量之间的关系进行建模。这种方法的优点是可以更准确地理解每个单独因素与结果的关联[13]。它还可以理解所有因素作为一个整体与结果的关联,以及各种预测变量本身之间的关联。
将训练集使用多元线性回归模型(multiple linear regression model,LR)初步拟合,而模型的最优参数是在自定义函数下获得的,并进行预测。除此之外,使用了最小绝对收缩和选择算子模型(least absolute shrinkage and selection operator,Lasso)、岭回归模型(ridge regression,Ridge)和弹性网络回归模型(elastic net regression,EN)。它们之间的区别在于惩罚项,即损失函数。Lasso使用L1正则化、Ridge使用L2正则化、EN使用L1或L2正则化。
3.2 最近邻回归
K邻近算法(k nearest neighbor,KNN)可用于回归和分类问题。它通过重新采样将当前特征向量对应于为特征空间的一点,用加权样本表示它的K个最邻近时间,并假设依赖于一个基于已知的欧几里得距离,从而得到类别标签或者预测值[14]。利用自定义函数和超参数网格搜索,将权重与k值联合优化,最终确定使用p=2欧式距离以及最优的k为2。
3.3 支持向量回归
支持向量机(support vector machine,SVM)最近在模式识别和函数逼近应用中引起了极大的兴趣。支持向量回归(support vector regression,SVR)是从支持向量机发展而来。SVR的优势在于模型对异常值具有鲁棒性,具有全局最优,并且支持在高维构建非线性关系,具备较好的泛化能力[15]。
使用径向基函数(radial basis function,RBF)拟合模型。RBF通过测量输入向量和径向基函数中心之间的欧几里得距离来发挥作用,并在隐藏层中执行非线性变换。超参数由网格搜索进行优化选择惩罚因子C和Gamma函数。参数先验设置为0.001≤C≤10 000和0.001≤Gamma≤100,如图5所示。

图5 惩罚因子和Gamma的变化对R2的影响(训练集)Fig.5 Influence of penalty factor and change in Gamma on R2 (training set)
3.4 多层感知机回归
多层感知机(multilayer perceptron,MLP)也称为前馈神经网络,被广泛应用在分类或回归问题。MLP的输出由隐藏层节点的输出的线性组合产生,其中每个神经元通过函数映射输入的加权平均值[16]。
MLP模型基础计算公式为
Out=F[∑(WX)+b]
(5)
式(5)中:Out为输出向量;W为每一层神经元之间的权重;X为输入变量;b为偏置向量;F为隐藏层内激活函数。
使用修正线性单元(linear rectification function,ReLU)作为激活函数,本质为分段线性函数,将所有负值转变为0,这称为单侧抑制。它在避免梯度爆炸和梯度消失问题具有优势,适合采收率预测,因为采收率不为负数。ReLU定义为
F[∑(WX)+b]=max[0,∑(WX)+b]
(6)
采用自适应矩估计(adaptive moment estimation optimizer,Adam)优化器,一种基于低阶矩自适应估计的随机目标函数一阶梯度优化算法。它适用于非平稳目标、噪音和稀疏梯度的情况。在非均质聚合物调驱实验中,高、低渗透层的分流采收率变化较大的,因此Adam优化器可以有效捕捉这些差异。
本文模型由一个输入层(21个神经元)、2个隐藏层,分别具有128、32个神经元和一个输出层组成。在分析中,学习率和一阶矩向量指数衰减率的网络参数分别设置为0.001和0.9。
3.5 决策树回归
决策树(decision tree,ET)属于非监督算法,应用于回归或分类问题,是数据挖掘中常用的技术。它表示属性和对象的映射关系。每个节点代表对象,决策点表示预测值[17]。值得注意的是,决策树的预测为分段常数近似,而非连续。它属于贪婪算法,通过局部最优逼近整体最优。但有时它并不能达到全局最优,集成树算法可以优化此问题。
在初步建模中,树枝无限分级的最大深度为16,空间及时间消耗较大且泛化能力较弱,在模型剪枝中优化确定最大深度超参数为8。
3.6 引导聚集回归
引导聚类算法分别为:袋装分类器(bagging classifier,Bag)、随机森林(random forest,RF)和极限随机树(extra tree,ET)。
Bag通常引入相同的样本大小,有放回地(含原始值的3/4和剩余1/4的随机选择替换)。每个引导样本都有弱分类器,它可以是线性回归或决策树算法。对于回归问题,最终模型是基于所有独立分类器的预测平均值构建的。
RF是引导聚集算法的一种应用。它的优势在于可以处理高维度数据,无需降维,与单一决策树相比不容易过拟合,并且可以判断特征重要性。通常情况下,需要随机抽样训练决策树,随机选择属性节点分裂属性(重复),最后直到不能分裂,建立大量决策树形成森林。使用网格交叉验证搜索找到超参数的最佳值。
与Bag和RF相比,ET也是装袋算法的应用,它将每颗决策树组合在一起获得最好的预测结果。同样,使用网格交叉验证搜索最佳超参数。
假设存在一颗随机向量树Θ,使得预测树h(X,Θ)可以用数值表示。假设训练集独立于随机向量Y、X,那么预测值h(X)的均方泛化误差可表示为
EX,Y[Y-h(X)]2
(7)
通过取第k颗树的平均值来形成{h(X,Θk)}。当森林中的树木趋向于无穷大时,有

(8)
将式(8)表示PE*(forest)作为向量森林的泛化误差,其中,forest为向量森林;PE*为泛化误差;ak为第k颗树的平均值;Θk为第k颗向量树;EΘ为随机向量Θ的概率平均值。
因此将向量树tree的平均泛化误差定义为
PE*(tree)=EΘEX,Y[Y-h(X,Θ)]2
(9)
假设对于所有Θ,EY=EXh(X,Θ)有

(10)
3.7 梯度提升算法回归
讨论3种提升算法,分别为:自适应提升(adaptive boosting,AB)、梯度提升(gradient boosting,GB)和极限梯度提升(extreme gradient boosting,XGB)。
提升方法和装袋方法一样,属于集成弱分类器方法,比独立分类器更可靠。一般情况下,提升方法通过加法模型将基础模型进行线性结合,每次训练将筛选偏差更小的模型并提升权重,迭代此过程最终使得训练数据拟合而没有明显的错误。
AB模型遵循此原则,很好地利用了弱分类器进行级联。通过先验值最终确定估计器为150和学习率为0.1。
GB模型通过在之前建立模型损失函数的梯度下降方向建立模型,即通过优化损失函数来生成模型。使用先验值确定损失类型、学习率和估计器分别为平方误差、0.1和100。
XGB模型遵循梯度提升原理,并且它使用了带正则项的目标函数来避免过拟合,采用近似分割算法(全局和局部)和列压缩存储来减少计算量提速,应用稀疏感知来处理缺失值问题[18]。使用随机搜索来寻找最佳超参数。
假设IL和IR分别为二叉树分裂后的左节点和右节点,则令I=IL∪IR,分裂后的损失减少定义为
(11)
式(11)中:I为当前节点的实例集;gi为一阶梯度统计量(二阶泰勒展开);hi为二阶梯度统计量;λ为叶子权重惩罚因子,γ为叶子数惩罚因子。
此外,提取分裂点。令集合Dk={(x1k,hn),(x2k,hn),…,(xnk,hn)}表示第k个特征值和二阶梯度统计量。
定义一个秩函数表示特征值k小于z的实例的比例为

(12)
式(12)中:z为输入树集合;x为特征值;h为二阶梯度度量。
秩函数的目标是找到分裂点{sk1,sk2,…,skl},减少计算和提速,使得

(13)

XGB模型通过筛选每棵树的最小损失和分裂点增加预测值准确度和提高计算速度。
4 性能评估
选择5个指标作为模型的评估标准。平均绝对误差(mean absolute error,MAE)计算公式为

(14)
均方误差(mean square error,MSE)是对MAE的补充,其内涵为预测值与真实值的偏差,越小则表明预测值越接近真实值。
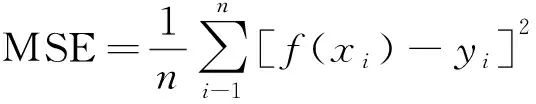
(15)
平均绝对百分比误差(mean absolute percentage error,MAPE)与量纲无关,对负值误差的惩罚大于正值误差,取值越小越准确。
(16)
均方根误差(root mean square error,RMSE)表示预测值与真实值的样本标准差,对离群点有更大的惩罚。

(17)
决定系数(coefficient of determination,R2)是准确度参数,计算公式为
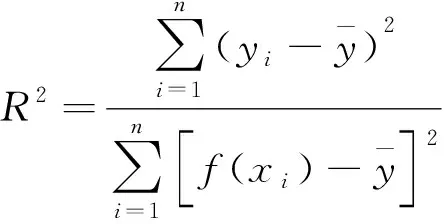
(18)

5 结果
建立14种模型来验证最佳的性能,并在模型的基础上分析特征参数,模型评价结果如表5、图6和图7所示,根据决定系数可知,LR模型是预测能力最差的模型。如图8、图9所示,MLP模型、XGB模型和RF模型在预测阶段表现出色。这3种模型几乎完美的捕捉到采收率实际值,不足之处在于RF与XGB模型在双管并联岩心变异系数较大时,分流转向点的采收率误差较大,而MLP模型捕捉的采收率误差较小。这意味着神经网络在预测非均质性岩心分流转向性有潜力,预测能力更强大,但MLP模型的复杂程度(计算时间与储存空间)比RF与XGB模型大。在模型表达上RF与XGB比MLP模型更简洁,对计算机硬件要求更低,稳定性更强,更容易解释模型结果。尽管预测数据局部存在误差,但这是由于数据量太小所致,当有充足的数据量支持时误差将会减小。

表5 14种模型泛化性能评价指标(测试集)Table 5 Evaluation indexes of generalization performance of 14 models (test set)

图6 14种模型评价性能对比(测试集)Fig.6 Comparative evaluation performance of 14 models (test set)

图7 11种模型在训练集及测试集与实际值的对比散点图Fig.7 Scatter diagrams of 11 models in the drive and test set with respect to actual values

图8 表现最佳的3种模型在测试集预测实际值能力图Fig.8 Capability map of the three best performing models to predict actual values in the test set

图9 预测性能最好的3种模型预测值与实际值散点对比图Fig.9 Dispersion comparison between predicted and actual values for the three best predictor models
当进行采收率预测时,对比3种模型的5项性能评价指标,如表5所示,RF、XGB和MLP模型5项指标差异非常小,这表明结果相当稳定与可靠。根据感兴趣的观测点绘制趋势差异图,如图8所示,可以看出,在观测点20~30预测值与实际值之间存在波动,这与聚合物封堵高渗透层使流量转向低渗透层有关。如图10所示,实验室采收率数据分布与XGB模型数据分布几乎一致,这从概率统计学表明模型十分可靠。并且采收率服从非参数核平滑分布,正态分布无法准确描述采收率数值分布,这也解释了多元线性回归模型R2仅为0.795,因为采收率不是简单线性分布。此外,观察到采收率最大分布在30%~35%,表明此区块大规模可采油瓶颈采收率为35%,调驱后部分最大可动油约为45%。

柱状图为散点分布数量统计;蓝色曲线为非参数核平滑分布图10 采收率数据集分布散点及分布图Fig.10 Distribution distribution and distribution diagram of the retrieval factor dataset
此外,对比了3种模型的绝对误差分布,如图11所示,XGB模型的误差离群点最少,高度集中在-0.5 ~ 0.5,呈对称分布整体可靠度最高;RF模型次之,误差离群点较多,负数一侧比正数一侧多,表示了比实际值更低的采收率;MLP模型误差的离群点多,统计分布表明正数一侧较多,意味着比实际值更高的采收率,3种模型的误差均呈正态分布,表示良好的模型适用性。

蓝色曲线为正态分布图11 绝对误差散点及分布图Fig.11 Scatter and distribution diagram of absolute errors
如表5所示,3种模型的决定系数均为0.99,表现出特征值对采收率的解释程度,该模型的参考价值高。RF、XGB和MLP的平均绝对MAPE分别为0.016、0.019和0.037,它是模型预测值准确性的统计标准,越小越准确。MAE表明模型具有描述采收率的精确度,RMSE表明模型具备良好的测量精密度。
6 讨论
聚合物在低渗透砂岩驱替中的采收率,与储层物性(渗透率、孔隙度、变异系数)、外来流体(聚合物浓度、聚合物注入量、聚合物类型)和油藏指标(含水率、累计注入孔隙体积、压力)的关系是复杂的。因此,研究不同的机器学习的结果是必要的,选出预测准确度最高的3种模型来分析聚合物驱在低渗透油藏中采收率的影响。
如图12所示,XGB模型特征重要性表明,含水率与累计注入孔隙量在采收率贡献中占比0.6和0.225,这与注水开发补充油藏能量一致[19]。含水率随聚合物浓度增加而降低,注入聚合物通过增加黏度来减少含水率,浓度越高含水率降幅越大。

图12 XGB模型与RF模型特征重要性Fig.12 Important characteristics of the XGB and RF models

(19)
式(19)中:fw为含水率,%;Qw为产水量,cm3;Qo为产油量,cm3;Kw为水相渗透率,mD;Ko为油相渗透率,mD;μw为水的黏度,mPa·s;μo为油的黏度,mPa·s。
XGB模型捕捉到含水率特征变量对于采收率的重要性,不仅在数值上几乎完美的预测变化而且与油层物理采油过程相契合。

RF模型特征重要性基本与XGB模型相一致,值得注意的是RF模型提高了孔隙度的重要性,削弱了非均质性的重要性,这可能表明精细油藏在采收率贡献上具有潜力。
将MLP模型的神经网络可视化,如图13所示。可以推断,聚合物浓度为1 500 mg/L、非均质系数0.7、注入压力和累计注入孔隙体积对模型比较重要,并且聚合物浓度1 500 mg/L产生积极影响,非均质系数0.7产生积极与消极影响,因为在初始注水时,高渗透层的采收率占据主导地位,此时为积极影响,而低渗透层贡献较少,此时为消极影响。注入压力与累计注入孔隙体积协同积极或消极。

PC_2500表示聚合物溶液浓度2 500 mg/L;PT_JD1200-1600和PT_DQ-10表示聚合物名称;VF_0.7表示变异系数0.7;PV_0.3表示注入聚合物溶液剂量0.3 PV图13 MLP模型连接21个输入特征和第一个隐藏层(128个神经元)的权重Fig.13 Weight of the MLP model connecting 21 input features and the first hidden layer (128 neurons)
7 结论
对某低渗透砂岩试验区进行室内大型岩心聚合物驱替实验,筛选395条真实有效的实验数据。基于驱替物理过程,建立了14种应用广泛的机器学习预测采收率模型,并对它们进行了评估,得到以下结论。
(1)室内天然岩心化学驱替实验是低渗透储层开发重要的环节,给予增产措施关键的参数。建立岩心驱替关系预测模型和数据库可促进化学驱筛选效率,并且建立的模型可在相似区块充当“先知”,快速科学的得到关键参数及采收率,避免经验主义,为昂贵和费时的物理实验争取时间和节约成本。
(2)所构建的14种机器学习预测模型中,随机树、多层感知机和极限梯度提升模型表现性能很好,可以较好地捕捉驱油采收率变化,它们在测试集的确定系数均为0.99,表明较高的变量解释程度。随机树模型采收率预测的均方根误差仅为0.836%,多层感知机为0.855%、极限梯度提升为0.859%,表明采收率预测值较高的测量精密度。
(3)随机树和极限梯度提升模型特征重要性表明影响采收率数值由强至弱分别为:含水率、累积注入孔隙体积、渗透率、非均质系数、孔隙度、聚合物注入量、聚合物浓度、注入压力。多层感知机第一个隐藏层权重表明累积注入孔隙体积与压力对采收率有重大影响。
