基于主成分分析法优化神经网络的滆湖组黏性土抗剪强度预测
2023-10-14顾春生唐鑫朱常坤陆志锋刘涛张其琪
顾春生, 唐鑫, 朱常坤*, 陆志锋, 刘涛, 张其琪
(1.江苏省地质调查研究院, 南京 210080; 2.自然资源部地裂缝地质灾害重点实验室, 南京 210080)
近年来,数学方法在地质工程研究领域得到快速发展[1-2];多元回归算法、套索回归算法(least absolute shrinkage and selection operator,LASSO)、聚类分析、反向传播神经网络(back propagation neural network,BPNN)、因子分析、主成分分析(principal component analysis,PCA)等机器学习算法,在建立特定地质参数的反演预测模型过程中得到广泛应用[2-4]。吕树胜等[3]将层次聚类算法运用到了土体分类过程中。李澄清等[4]运用BP模型建立了土体细观力学参数的反演模型。王晨晖等[5]运用主成分分析法、粒子群算法实现对广义神经网络模型的优化,建立了多因素影响下地震震级预测评价模型,为地震震级预测提供参考。韩晓育等[6]运用LASSO算法筛选出目标参量的强相关、非共线性参数,有效提升了伊犁河中长期径流预报模型的精度。袁颖等[7]运用PCA算法从多个参数中提取影响地裂缝危险性的主成分,消除了解释变量之间的线性关系,进一步提高了苏锡常地裂缝危险性预测模型的效率和精度。而神经网络模型虽在提升模型精度方面效果显著,但模型可解释性方面缺陷明显。LASSO算法在高维度样本降维方面效果显著,聚类分析等特征选择方法在因子重要性分析等领域效果显著,但运用上述单一方法建立预测模型,预测效果不理想。在数据维度高、信息量大,试验成本高、指标较难获得等情况下,适当运用多种数学方法可以显著提高地质参数预测模型的预测精度、泛化能力以及模型的可解释性[8]。
土体抗剪强度是边坡稳定性评价、土压力计算过程中无法回避的重要指标。为此,学者们对特殊岩土体强度特性开展了研究。王文军等[9]通过研究淤泥固化土的无侧限抗压强度,并建立了预测模型。范婷婷等[10]研究了砂类土抗剪强度与孔隙比之间的关系,并建立了理论表达式。陈鸿宾等[11]通过土工试验,总结出了重塑红黏土含水率、干密度与其抗剪强度参数间的关系。孔令亚等[12]通过室内试验探究了含水率、夹层厚等因素对巴东地区软弱岩层强度的影响。蔡国庆等[13]运用统计回归方法榆林Q3黄土等特殊土体物理力学指标的相关性进行了研究并给出了指标间经验公式。但上述针对特殊土抗剪强度研究采用的经验公式及多项式拟合等常规方法均易受异常样本干扰导致较差拟合效果;当样本量较大时拟合效果也会显著降低。
苏锡常地区滆湖组地层是一种较为典型的土层,其具有埋深浅、强度高、分布广泛等工程地质特性[14-15],其对区内地下空间开发与地表建筑设计等方面具有重要意义。然而,学者对滆湖组黏性土层的抗剪强度等工程地质特性研究较少。
鉴于此,为了研究苏锡常地区滆湖组黏性土抗剪强度特性,运用PCA对多维样本数据进行降维,构建具有非共线特征的主成分,研究个主成分与抗剪强度参数间关系。最终建立基于PCA-BPNN模型的滆湖组黏性土抗剪强度预测模型。为运用数学方法研究土体工程地质参数及海量室内土工试验数据价值的深度挖掘和利用提供参考。
1 模型概述
1.1 PCA概述
岩土体工程地质参数之间多具有一定相关性[9-13,16];当相关性较强的参数共同作为解释变量进行参数预测时,预测样本会包含重叠信息量;而这种解释变量之间存在较强相关性的特征被称为多重共线性;当重复选取具有多重共线特征参数时,会提升模型复杂程度,降低计算效率与精度[1,7];甚至造成模型的过度拟合,降低模型泛化能力。而PCA是一种可以将具有相关性的多维自变量进行矩阵变换,简化构造出低维度、互不相关的新变量,且新变量可以尽可能多地保留原始数据信息的数学方法[17-19]。
在PCA中样本信息量是用主成分方差来衡量的,主成分方差越大,样本在此维度下的信息量越大[19]。PCA通过计算主成分贡献率和累计贡献率来确定主成分个数;而主成分贡献率为提取出的主成分方差与原始变量总方差之比[20-21]。具体主成分提取及参数计算过程如下。
步骤1将m个具有n维变量的总体样本Xnm用矩阵表示为

(1)
步骤2计算协方差矩阵;对样本数据进行标准化处理,并消除量纲影响;继而求出样本各参数的相关系数矩阵R。
步骤3然后根据相关系数矩阵R及其特征方程,按式(2)计算出主成分特征值λi;并按大小进行排序λi≥λi+1≥ 0。
步骤4计算主成分贡献率和累计贡献。
|λE-R|=0
(2)
(3)
(4)
式中:E为单位矩阵;p为样本参数维度;R为n维样本参数的相关系数矩阵;λi为第i个参数维度对应的主成分特征值;CP为第i个主成分方差贡献率;ACP为前i个主成分方差累计贡献率;λl为第l个参数对应的主成分特征值;λk为第k个参数对应的主成分特征值。
步骤5确定主成分数量;求因子载荷矩阵β。建立主成分方程Fi=βi1X1+βi2X2+…+βipXp;由因子载荷矩阵对样本主成分进行解释、提取,建立新变量矩阵。最终完成对高维样本的降维。
此时,新变量可以作为BPNN模型的输入层;既保留了原始样本大部分信息,又大大降低了预测模型的复杂程度。
1.2 BPNN模型
BPNN模型是逆向传播训练的多层前馈神经网络,是应用最广泛的神经网络模型之一[3-4]。BPNN模型由输入层、隐含层和输出层三部分组成;各部分通过权值、偏置值和激活函数相互联系;根据计算误差对神经元权值和偏置值进行迭代和修正;最终得到理想的神经元权值参数矩阵的方法,即BPNN模型[20]。
将运用PCA算法筛选出的变量作为 BPNN模型的输入层;至此,PCA-BPNN模型的结构构架搭建完毕;模型结构如图1所示。

图1 PCA-BPNN模型结构图Fig.1 Structure of PCA-BPNN model
1.3 模型精度评价
为了比较不同模型运行效果,用预测值与样本真实值的均方根误差、相关系数进行综合评价。
(5)
(2)拟合优度(R)。用拟合优度R评价模型效果,R趋近于1,模型拟合的效果越好;R趋向于0,拟合效果越差,R的计算公式为
(6)

2 基于PCA算法的参数分析
2.1 地质背景
滆湖组黏性土层在苏锡常地区广泛分布(图2),是地下空间开发利用、地基与基础工程建设常涉及的重要工程地层之一。第四系滆湖组地层上段和下段是一套灰色、青灰色、黄灰色、灰黄色的可塑-硬塑,含铁锰质斑点的黏性土,以粉质黏土和黏土为主的典型黏性土层,具有埋深浅、分布广、强度高等工程地质特性,为良好基础持力层[14-15]。

图2 苏锡常地区滆湖组黏性土分布图Fig.2 Distribution map of cohesive clay in Gehu Formation in Su-Xi-Chang area
因此,开展滆湖组黏性土抗剪强度特性研究,对指导苏锡常地区地下空间开发利用、建筑工程勘察设计等工作具有重要意义。
2.2 滆湖组黏性土工程地质参数统计
研究对象为苏锡常地区711组滆湖组黏性土室内土工试验数据,样本中含有11个解释变量(表1),2个研究变量(c、φ)。然后对数据进行多参数相关性分析,计算得到样本各参数相关系数矩阵(图3);结果显示:各参数基本服从正态分布,样本具有较好的代表性。样本11个解释变量与黏聚力相关系数均大于0.4,有4个大于0.6;而与内摩擦角的相关系数大于0.4的也有5个;说明各参数单因子建模对抗剪强度的预测水平较低。解释变量之间存在9组参数两两相关系数大于0.8。说明解释变量内部也存在较强相关性;如重复选取强相关待选参数作为模型因子势必会造成预测模型的稳定性与精度。因此,消除滆湖组黏性土参数间多重共线性是提高岩土体抗剪强度参数预测模型精度与泛化能力的重要环节。

表1 滆湖组黏性土参数统计Table 1 Parametric statistics of Gehu Formation cohesive soil

图3 样本参数概率分布及相关系数热图Fig.3 Heat map of probability distribution and correlation coefficient of soil parameters
2.3 基于PCA算法的滆湖组黏性土参数分析
2.3.1 主成分分析过程
运用PCA算法对11组滆湖组黏性土工程地质试验数据进行变换,求取特征值;得到的主成分特征值λ1=5.73,λ2=4.03,λ3=0.52;其余主成分特征值均小于1;说明第一、二主成分对原样本的解释力度优于原变量的平均解释力度;第三主成分解释力度已大幅降低,其余主成分解释力度依次降低(图4),从而确定主成分数量不大于3个。此时,第一主成分贡献率为52.1%;当主成分维度为2时,累计贡献率达到88.8%;当主成分维度为3时,累计贡献率为93.5%(图4);此时参数维度得到大幅降低,即能保留样本大部分信息量,又避免了参数之间的多重共线性。
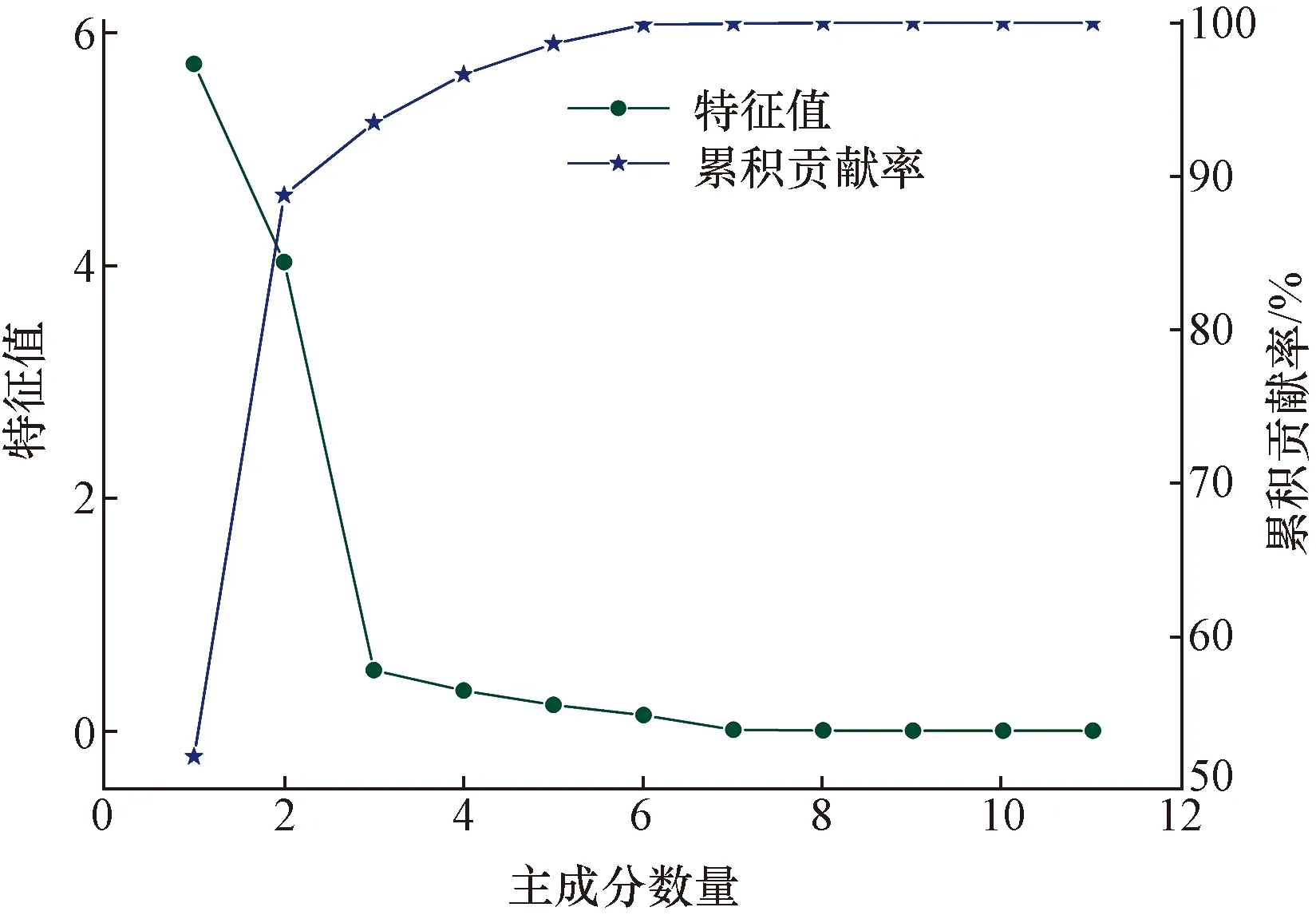
图4 PCA碎石图Fig.4 Stone map of principle components
通过主成分得分散点图(图5)可知,黏土与粉质黏土散点分布,均在PC1方向上具有较大方差;粉质黏土和黏土样本未出现较为显著的分类;因此,仅从已有样本数据出发,滆湖组黏性土没有必要对粉质黏土与黏土单独建立预测模型。根据图5中主成分参数荷载可得:两组原参数(e0、w)与(γ、γd、γsat)组内参数在载荷图中位置几乎重叠,说明组内参数含有较多相似信息;并呈现组内正相关,组间负相关关系。结合表2中各主成分得分系数,参数(e0、w)与(γ、γd、γsat)的得分系数相对较大,说明这两组参数对第一主成分贡献显著。

表2 主成分得分系数Table 2 Coefficient of principal component score

蓝线为参数载荷图5 主成分得分散点与参数荷载图Fig.5 Score plot of principal component and parameter load diagram
从第一、二主成分中主要变量e0、w、γ的样本三维散点图(图6)可知,随着孔隙度越大,天然含水率越高,天然重度与饱和重度等越低的规律。说明第一主成分综合反映了滆湖组黏性土孔隙特征、含水率特性。同理,第二主成分中参数wl、wp、IP、等具有较大贡献;综合反映了滆湖组黏性土中塑液限等参数之间的相互影响趋势,并将第二主成分归纳为滆湖组黏性土的水稳特性。
滆湖组黏性土含水率、孔隙度、天然重度三参数之间均存在较强线性关系[图6(a)];塑液限、塑性指数三参数间也存在较强线性关系[图6(b)]。这种因变量间的强相关关系表明多维样本数据本身存在大量冗余信息,也证明采用PCA算法对样本参数进行降维的必要性。
2.3.2 主成分与抗剪强度关系
根据由βip组成的主成分得分系数矩阵β(表2),将主成分写成由原始变量组成的线性方程[式(7)]。在将其所得各主成分与样本抗剪强度参数绘制出的散点图(图7)可知,代表土体孔隙特性的第一主成分与黏聚力呈负相关,与代表土体水稳性的第二主成分呈正相关。结果表明,土体孔隙特性越显著,水稳性越弱,抗剪强度越低。

图7 主成分与抗剪强度参数散点图Fig.7 Scatter plot of principal component and shear strength
如将主成分作为解释变量,直接建立抗剪强度参数主成分回归模型,即式(8)、式(9);此时,主成分回归模型对抗剪强度参数的拟合优度分别为Rc=0.54、Rφ=0.69。主成分回归模型的解释变量个数大幅降低,但模型拟合精度则有较大提升空间。
Fi=βi1X1+βi2X2+…+βipXp
i=1,2,3;p=1,2,3…
(7)
式(7)中:Fi为样本对应第i个主成分的主成分综合得分;Xp为样本的第p维参数数值。
c=-0.86F1+0.36F2-3.23F3-173.56
(8)
φ=-1.35F1+0.27F2-0.81F3-12.4
(9)
综上所述,通过主成分分析法可将滆湖组黏性土11个参数,简化为3个主成分;即保留了大部分原始信息,又避免了多维变量之间多重共线性的影响。第一主成分代表土体孔隙特性,与黏聚力和内摩擦角均呈负相关关系;第二主成分代表土体水稳性,与黏聚力和内摩擦角均呈正相关关系。表明土体孔隙特性越显著,水稳性越弱,抗剪强度越低。
但仅通过主成分回归模型建立的隔湖组黏性土抗剪强度参数预测模型精度有提高空间[式(8)、式(9)],可选择将主成分变量[式(7)]作为神经网络模型的输入层,建立抗剪强度参数的PCA-BPNN预测模型。
3 基于PCA-BPNN的抗剪强度预测
3.1 BPNN模型参数
将上述主成分得分矩阵作为输入层,基于MATLAB软件,对711组样本建立PCA-BPNN预测模型,具体步骤如下。
步骤1数据预处理.对711组样本进行归一化。训练集样本数为421,测试集样本取145,剩余145组为预测集样本,可以用于模型验证。
步骤2输入层变量数为3,输出层变量数为2;隐含层数量可以依据式(10)确定。
(10)
式(10)中:h为隐含层数量;m为输入层数量;n为输出层数量;a为1~10的可调整常数(为避免过度拟合取3)。

步骤4模型参数结果。
通过对样本的多次学习训练,确定隐含层神经元为5时,BPNN预测效果良好。此时,BPNN模型3个主成分为输入层,其输入层至隐含层的权值与偏置值,以及隐含层-输出层权值与偏置值计算结果如表3所示。最终将样本代入训练好的模型即可得到预测结果。

表3 BPNN模型的权值和偏置值Table 3 BPNN neural network’s weight and bias values
3.2 预测结果及误差分析
将711组土工试验数据划分为训练集、测试集与预测集,代入训练好的模型进行,迭代运算的拟合优度R分别为0.96、0.95、0.96,可见该模型具有较高可靠性,如图8所示,以主成分分析结果变量作为输入层,建立PCA-BPNN模型,可以实现对滆湖组黏性土抗剪强度参数的有效预测。

Y为预测模型的预测值图8 神经网络模型拟合效果Fig.8 Effect of neural network model prediction set
为验证PCA-BP模型预测效果,从预测集样本随机选取60组样本进行预测。结果显示:样本黏聚力均值c=49.59kPa,模型预测均值c=50.96 kPa,MAE=7.03 kPa,RMSE=8.33 kPa;预测集与真实值相关系数为R=0.94,模型假设检验P<0.05;可见预测数据与实际值基本一致,模型对黏聚力的拟合程度较强(图9)。

图9 模型对黏聚力的预测效果Fig.9 Effect of cohesion prediction model
而随机样本内φ均值为14.9°,模型预测φ均值为14.3°,MAE=0.73°,RMSE=0.92°,R=0.87,模型假设检验P≤0.05;对内摩擦角的拟合程度较强,但略低于黏聚力预测模型(图10)。

图10 模型对内摩擦角预测效果Fig.10 Effect of internal friction angle prediction model
3.3 预测模型对比分析
为了研究模型预测效果,将总体711组试样数据代入训练好的PCA-BPNN模型,将预测结果与主成分回归模型进行对比。结果显示:PCA-BPNN模型对抗剪强度参数c、φ预测性能得到在均方误差等性能方面得到全面提高(表4)。

表4 预测模型性能参数对比Table 4 Comparison of model performance parameters
由此可知,基于PCA-BPNN算法建立的滆湖组抗剪强度预测模型既实现了模型输入变量的降维,降低了模型计算量,提高了计算效率,又能消除解释变量之间共线特性,实现多参数土体参数的高精度预测。
4 结论
通过对苏锡常地区第四系滆湖组711组土黏性土室内试验样品数据分析,建立了滆湖组黏性土抗剪强度PCA-BPNN预测模型;得到如下结论。
(1)运用PCA算法可将滆湖组黏性土11维参数变换成3维主成分;第一主成分贡献率为52.1%第二主成分贡献率为36.6%;当主成分维度为3时,累计贡献率达93.5%,三维主成分包含了大部分样本信息。第一主成分可归纳为土体孔隙特性,与黏聚力和内摩擦角均呈负相关关系;第二主成分可归纳为土体水稳性,与黏聚力和内摩擦角均呈正相关关系;土体孔隙特性越显著,水稳性越弱,抗剪强度越低。
(2)建立了基于PCA-BPNN算法的滆湖组黏性土抗剪强度反演预测模型。结果显示:模型预测结果与试验样本基本一致,模型的拟合优度R>0.85,随机样本c预测均方根误差<6.84 kPa,φ预测均方根误差<1.9°;说明该模型可靠性高,能够对滆湖组黏性土抗剪强度参数进行有效预测。
(3)引入PCA算法建立特殊土参数预测模型,可以避免人工筛选预测变量的不确定因素,不仅能够实现高维解释变量降维,又能够保留样本大部分信息,从而增加了模型的可靠性。引入PCA算法消除多维变量间多重共线性,避免直接运用神经网络模型可能引发的过拟合问题;既提升了模型预测精度(均方误差角度),又能在一定程度上提高预测模型的泛化能力。为运用数学方法研究土体工程地质参数及海量室内土工试验数据价值的深度挖掘和利用提供了参考。
