基于YOLO-RW模型的机器视觉原木端面识别定位
2023-10-12曾小山张小波
曾小山,张小波
(江西环境工程职业学院 汽车机电学院,江西 赣州 341002)
0 引言
露天堆放的原木受到存放时间、存储地点、天气和光线等多种因素的影响,导致部分原木端面出现了裂缝和霉菌等缺陷。此外,一些原木在采伐时遭受了切割和割伤等情况,给原木端面图像的采集和检测带来了很大的困难,影响了图像的正确识别效果。
针对上述问题,相关人员进行了一些有益的探索和研究[1-5]。例如,以原木剖面图为实例,栾新等[1]设计了一种分层分类器,该分类器可以单独识别目标,成功解决了不规则端面的模式匹配问题。梅振荣[2]则采用最小二乘法椭圆拟合的方案,解决了原木端面的处理和径级识别问题。林丽华[3]对多尺度小波变换边缘检测算法进行了改进,主要针对原木图像质量进行了优化,优化后的算法在保证原木轮廓边缘完整性和连续性的同时,大幅提高了原木图像的质量。霍东旭[5]采用了基于Canny算法的边缘检测方法对原木图像进行处理,通过去除噪声和计算边缘振幅,成功地检测出更多原木端面的边缘细节,优化后的方法显著提高了原木端面图像的清晰度和边缘识别率。赵亚凤等[6]采用自适应阈值分割、随机森林分类器的训练和预测以及图像增强算法,成功解决了在有阴影的图像中进行分割的问题。这种方法不仅能够有效地进行阴影消除,还可以提高图像的识别准确率。然而,以上方案的算法复杂度较高,导致原木端面识别的效率不高,同时在图像信息处理时可能会出现信息不完整的情况,从而可能导致检测遗漏并降低系统的可靠性。此外,自适应阈值响应滞后等问题也会影响系统的性能。
目前,深度学习技术在图像处理领域取得了巨大进展,其中基于You Only Look Once(YOLO)模型的目标检测方法得到了广泛的应用。本研究提出一种名为YOLO-Raw Wood (YOLO-RW)的新型深度学习模型,专门应用于原木木材材积图像的端面识别和定位。YOLO-RW模型结合了各个版本的YOLO模型的优缺点,并在数据增强、模型结构和损失函数等方面进行了优化,从而提高了模型的精度和鲁棒性。通过试验,本模型能够有效地缓解原木端面的裂纹、霉菌、切割痕迹、复杂背景以及阴影等干扰因素,大幅提升了图像中的原木端面目标识别准确率,为实现原木材积的自动检测奠定了基础。
1 YOLO模型介绍
YOLO是一种基于深度学习的目标检测模型,将目标检测问题看作是一个回归问题,通过一个神经网络直接预测出目标的类别和位置。YOLO算法在物体检测上具有速度快、检测效果好等优点,因此在目标检测领域得到了广泛应用。YOLO从v1到v7版本进行了多次改进[7],下面将对其进行简要介绍。
YOLOv1 (You Only Look Once version 1, YOLOv1)由Joseph Redmon等在2015年提出。YOLOv1的核心思想是将目标检测问题转化为一个回归问题,即将物体的位置和类别信息直接预测出来,而不是先进行区域提取,再对提取的区域进行分类和回归。YOLOv1网络结构由全卷积神经网络(Fully Convolutional Networks ,FCN)构成,由输入层、卷积层、下采样层、全连接层和输出层组成。其中,卷积层和下采样层用于提取特征,全连接层用于将特征映射到输出层,输出层负责输出检测结果。相比传统的目标检测方法,YOLOv1 具有检测速度快、准确率高的优点,但也存在定位误差较大、对小目标检测效果较差等缺点。
YOLOv2(You Only Look Once version2)是2017年提出的目标检测算法。相比YOLOv1,其解决了召回率和定位精度不足的问题。YOLOv2使用Anchor机制和K-means聚类,提高了召回率,并将浅层特征与深层特征相连,有助于对小尺寸目标的检测。YOLO9000能够实时检测超过9 000种物体,主要基于YOLOv2。其速度更快、精度更高,可以适应多种尺寸的图像输入。
YOLOv3 (You Only Look Once version 3)是YOLO系列的第三代目标检测算法,由Joseph Redmon 等在2018年提出。相较于YOLOv2,YOLOv3在提高检测准确性的同时,进一步提高了检测速度,通过卷积模块、主干网络、批量归一化、交叉熵损失函数、预测框调整和多尺度预测等方法,YOLOv3在检测准确性和速度上都有了显著提高,成为目标检测领域的一个重要算法。
YOLOv4(You Only Look Once version4)于2020年由Alexey Bochkovskiy等提出,相较于前一版YOLOv3,其采用CSPNet骨干网络、多尺度训练策略、多样化的数据增强、高斯混合损失函数、预训练模型、Bag of Freebies和Bag of Specials等技术进行改进,从而在检测准确率和速度上均有了显著提升,同时具有更好的泛化能力。
YOLOv5(You Only Look Once version5)由Ultralytics于2020年提出。相较于YOLOv4,YOLOv5采用了轻量级的模型结构,引入了大量的模型优化技术,包括自适应多尺度训练、优化的anchor boxes、流式数据加载和缓存和NVIDIA Apex混合精度训练等,从而在检测准确率、速度和模型大小等方面均有显著提升,成为目标检测领域中一种性能优秀的算法。
YOLOv7(You Only Look Once version 7)最大的贡献是用原始的视觉几何组(Visual Geometry Group,VGG)网络代替ResNet[9-10]网络,在训练时,使用ResNet-style的多分支模型,在测试时,转化成VGG-style的单线路模型,主要的方法是在测试时,将训练时的多分支模型进行合并得到一条单线路模型,即将1× 1卷积、BN(批标准化)与3×3卷积进行合并。而YOLOv6与YOLOv7的发行时间非常接近,这里不过多阐述。
YOLO从v1版本到v7版本进行了大量的更改,其中包括主干网络的更改、卷积模块的更改、损失函数的更改和训练的策略等。然而现有版本的YOLO对于木材端面检测仍然存在不少问题:低版本的YOLO模型识别率不高,高版本对于训练样本数量高,对于仅有较少量样本的木材端面图像集难以适用,且高版本的YOLO运行要求也高,一定程度限制其使用范围。因此,如何选择合适的结构用于检测自己特定的数据集并达到良好的识别效果是一个很有挑战的问题,本研究面向木材端面检测需求,结合YOLO系列模型的特点,从数据增强、特征融合和损失函数优化等多方面入手,提出一种适用于原木端面检测的新模型。
2 YOLO-RW改进算法设计
2.1 识别对象分析
本研究木材堆放图像的采集地点为江西省赣州市上犹县某国营林场及龙南市某乡镇木材检验所,复杂原木端面拍摄图像如图1所示。由图1可知,木材端面的轮廓摄影距离近,在光线充分照射的情况下能够维持基本的颜色和形状特征,但木材堆积的密集度和木材的保管时间过长会导致木材端面的腐蚀、裂纹等缺陷,从而使木材端面的形状特征不规则且不完整。

图1 复杂原木堆积图像Fig.1 Complex log stacking image
在木材端面径级识别方法中,传统的R-G(红-绿)色差分割方法难以在图像中含有大量木材端面轮廓的情况下完全分离木材轮廓。虽然支持向量机可以对密集堆放的原木端面进行检测识别和分类,但是由于正负样本的限制,无法适应所有环境中的原木轮廓径级识别。因此,本研究通过数据增强、优化网络结构等方法,对原木端面图像进行处理,并通过端到端的整体训练使神经网络自适应地学习原木端面轮廓所需要的特征,从而实现在复杂环境下精确识别原木端面轮廓。
2.2 YOLO-RW主干网络优化
基于对YOLO模型内容的阐述,受数据集中图像数量较小的限制,原木检测任务并不适合过于复杂的网络结构(YOLOv6,YOLOv7等),而早期的YOLO版本(YOLOv1,YOLOv2等)对于目前的深度学习框架性能不佳。因此本研究采用YOLOv3的主干网络框架并作大量的简化和改进,模型的整体流程如图2所示。

图2 YOLO-RW模型结构Fig.2 YOLO-RW model structure
YOLO-RW由3部分组成:下采样模块、融合模块和预测模块,其中,下采样模块使用3×3的卷积层、批归一化层、激活函数层和若干组ResNet Block组成,这一模块将输入图像下采样到52×52大小的特征图,如图2右下角所示。接着,下采样至26×26大小的特征图与13×13大小的特征图,再经过融合模块进行特征融合,该模块的设计基于注意力特征融合(Attentional Feature Fusion,AFF)[16],将不同维度的特征融合到一起。具体来说,给定2个不同尺寸度的特征图(x,y),低维度特征图y经过卷积核为3×3,步长为2的卷积层进行下采样,再经过一层1×1的卷积层获得低维特征图,而高维特征图x经过一层全局平均池化层获得全局特征,经过3×3的卷积层与ReLU激活层,最后再经过一层1×1的卷积层获得高维全局特征图,将2种特征相加,再经过一层sigmoid层,分别与原特征x、y相乘,得到最终的融合特征,具体流程如图2左下角所示。之后将得到的3种维度的特征图分别经过一层3×3的卷积层,得到最终的预测特征,该特征的维度与yolov3中的结果相同,最后根据预测结果得到输出图像。
2.3 YOLO-RW损失函数设计
通过对各类损失的研究与试验,YOLO-RW共有3种损失,置信度损失、分类损失以及定位损失。其中,置信度损失使用二元交叉熵损失,见式(1)。
(1)

分类损失同样使用二元交叉熵损失,具体损失见式(2)。
(2)

(3)
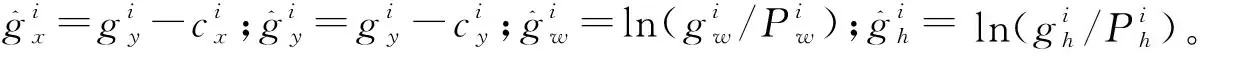
因此,模型的总损失见式(4)。
L(o,c,O,C,l,g)=λ1Lconf(o,c)+λ2Lcla(O,C)。
(4)
式中,λ1、λ2、λ3为损失的权重,用来平衡各个损失,在YOLO-RW中,分别将其设置为1、0.1和0.1。在后面的消融试验中,将证明上述损失函数组合使得模型具有最佳的检测效果。
3 试验
3.1 评价方法
机器视觉目标检测是一项非常重要的任务,需要在图像的复杂信息中准确地找到预定的目标,并通过算法获取目标的大小和位置信息。为了评估算法的优劣,常用的机器视觉技术指标包括精度、召回率、平均精度均值和交并比等。本研究将采用客观的评估标准来评估原木端面轮廓识别的准确性,并使用上述指标对训练后的模型进行评估。同时,将寻找适当的阈值[11],通过预测的置信度来筛选最佳目标。这些评估方法将有助于衡量算法性能和提高目标检测的准确性。
(5)
(6)
(7)
式中:Precision为准确率;Recall为召回率;mAP为平均精度;TP(True Positive)为检测结果正确,并且结果呈现阳性;FP(False Positive)为检测结果错误,并且结果呈现阳性;FN(False Negative)为检测结果错误,并且结果呈现阴性;μ为阈值;k为样本数量。
首先,考虑模型的整体性能,通过多次迭代优化,筛选出平均精度(mAP)值最高的模型。接着,需要在迭代出的模型中对阈值这个参数采取足够的关注度,并适时地对其数值加以改变,这样做的目的是必须考量准确率、召回率和IoU这三者之间的权值关系,使之能够自适应地检测当前环境下的原木端面。对于准确率和召回率,需要在堆积的原木中识别每一根原木的端面,因此应当优先选择准确率。对于IoU,本研究只需要每一根原木端面的中心点,所以对IoU要求不会特别严格。
3.2 原木端面图像数据集
根据原木端面的物理及形状等特点,在选择神经网络的训练素材时,需分别考虑4种特征(端面完整、割伤、形状不规则和有阴影)的原木端面图像,在林场及木材检查站拍摄原木堆积场景图像256张。各个图像的占比见表1。

表1 各类原木图像占比Tab.1 The proportion of images of various types of logs
图像的标注情况如图3所示,由图3可以看出,图像的分辨率各不相同,并且不同的图像间存在着背景复杂、原木密集和色彩单一等特点。因此,为了能够全面地提取到不同特点图像的特征,防止过拟合,需要补充训练样本的数据量,因此需对图像进行图像数据增强操作。

图3 数据集样本标记 Fig.3 Dataset sample labeling
3.3 原木端图像集的数据增强
数据增强是一种数据预处理技术,通过对原始数据进行各种变换和扭曲,生成更多、更丰富的数据样本,从而提高模型的泛化能力和鲁棒性。对于原木检测任务而言,存在以下问题。1)数据量远小于YOLO模型所需的数据量,这会导致模型过拟合。2)检测目标过于密集,模型训练容易陷入局部最优解,影响模型精度。3)模型难以泛化。因此,选择一种合适的数据增强方法显得非常重要。
本试验对原木数据集进行了翻转、调高对比度与饱和度、旋转、随机裁剪和缩放等操作,为保证图像的原始比例,并使得图像能够适应网络的输入,增强后的图像进行了等比例的缩放,缺失的位置由黑色像素填充,如图4所示。
为能够让模型提取到复杂图像分布的特征,对不同的原木图像进行裁剪与拼接作为一种图像增强方法,具体选定4张原木图像,在每一张图像上随机裁剪208×208像素大小的子图,并将裁剪到的4张子图拼接成1张图像作为训练数据,结果如图5所示。

图5 原木图像拼接增强Fig.5 Log image stitching and enhancement
另外,还使用了添加高斯噪声[11]等简单的图像增强方法。最终,将所得到的256原木图像增强至2 048张图像。这种增强方法的有效性将在后面的消融试验中进行验证。
3.4 模型参数优化试验
训练的模型需要对图片中的原木端面进行检测、定位及分类,采用mAP值对目标进行性能评价,通过训练找到mAP值最高的模型,然后仔细分析,当模型的阈值发生改变时,其准确率、召回率和IoU是如何跟随阈值的变化而变化,以确定模型的最佳阈值。
针对如何找到一个平均精度(mAP)值最高的模型这个问题,最直接的方法就是对模型进行大量的迭代训练,每一个模型的输出应当设置好合适的迭代次数,本研究根据实际情况,设置迭代次数为1万次,并且输出模型频率是一个模型/百次迭代,因此可获得100个训练模型,然后在这些模型中寻找mAP值最高的那个模型,并把该模型确定为最终模型。试验结果如图6所示,由图6可以看出,当迭代次数达到4 500次时mAP已趋于稳定,不再发生变化,mAP的最大值是87.67%,即为最优模型。

图6 平均精度曲线Fig.6 Average accuracy curve
在图7的准确率-召回率曲线图像中,其曲线在坐标系第一象限占据的区域面积很大,表明该模型对原木端面的识别定位及分类效果较佳。
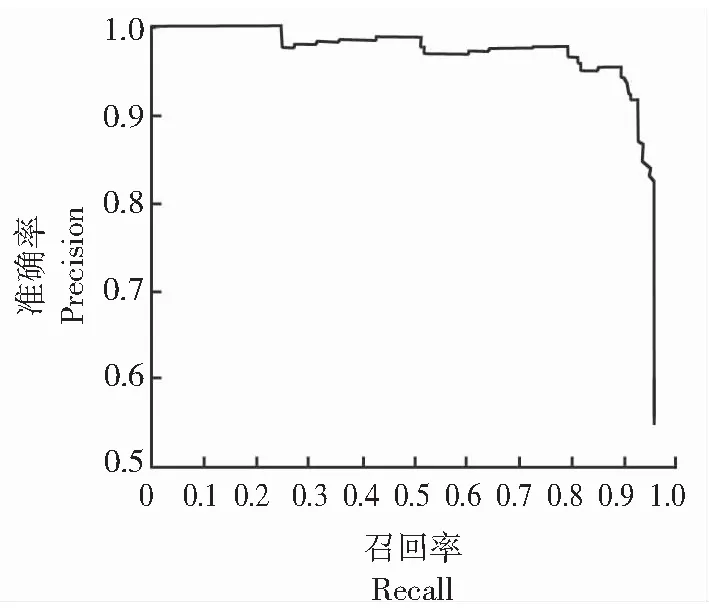
图7 准确度-召回率曲线Fig.7 Precision recall curve
最优模型选取出来后,考虑到模型实际使用的阈值,采用预设的阈值对其进行筛选。在原木端面识别系统中,设定本研究中模型的优先级由大到小为:准确率、召回率、IoU。另外,为了同时兼顾准确率和召回率,采用F1分数(F1-score,式中用F1-score表示)作为分类的评估衡量指标[13]。
(8)
试验结果如图8所示,置信度阈值(Threshold confidence level)是一个小于1的数,图8中用横坐标表示,其大小范围为0~1。Precision、IoU、F1-score及Recall这4个参数的大小也不超过1,用百分数形式表征。 由图8可知,当阈值等于0.50时,模型的各个指标表现优异,说明此时的模型处于最优状态。
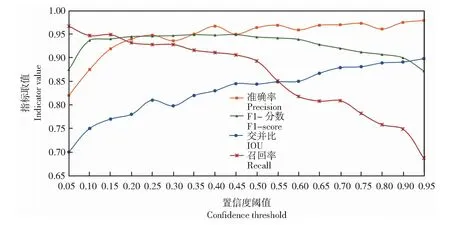
图8 不同阈值下的准确率、召回率、F1分数和交并比Fig.8 Precision, Recall, F1-score, and IoU under different thresholds
3.5 模型性能分析
选定的模型采用端到端的联合方式进行了训练[13]。在训练的具体参数方面,主要对初始学习率、权重衰减率和动量因子等几个重要参数进行调整和设定,通过训练,这些参数的值分别为1×10-3、5×10-4、0.9。图片像素大小为416×416像素。每个GPU用于处理单个图像,当模型的精度达到收敛时,模型将停止训练。需要注意的是,模型需要及时测试比对。模型的最终输出结果,必须将识别原木端面目标的概率作为重要指标,仅保持概率值为0.8以上的区域。
模型能否准确提取图像中有价值的数据信息是一个非常重要的环节,为此,基于无监督的K-means聚类算法计算当前数据锚的预训练数值。并用欧氏距离作为衡量数据对象间相似度的指标。模型训练共耗时4 h,一共为训练次数12 000次,其损失值变化情况如图9所示。

图9 损失值变化曲线图Fig.9 Loss variation curve
由图9可知,模型在初始迭代期间(前1×103次迭代)快速拟合,损失值迅速变小,迭代次数达到4×103次后,损耗值趋于稳定,迭代次数越多并不意味着模型的好坏,反之过多的训练可能导致过度拟合。
YOLO-RW模型经过12万次迭代后,对原木端面的检测效果如图10所示,可见模型对原木端面存在裂纹、凹凸不平、端面轮廓不规则和图像背景复杂等情况有很好的识别能力。由于在模型训练过程中对数据集进行了增强处理,该模型在光线强弱变化较大的应用场景以及其他复杂的场景中也具有很好的适应性。图10为复杂情景下YOLO-RW的识别效果,由图10可以看到,在具有复杂背景的情况下(图10(a)),模型依然能够准确地识别到原木的位置并进行较为准确的预测。在大量不规则的原木中,模型也可以识别到原木的准确位置,即使在较难识别的区域中(图10(b)中右下角),模型可以给出预测结果,这种结果可以有效地提高模型的召回率。在更加综合的图像中图(10(c)),模型依然保持着良好的效果,这些结果体现了YOLO-RW强大的识别能力以及泛化能力。

图10 复杂情况下YOLO-RW识别效果Fig.10 YOLO-RW recognition effect in complex situations
3.6 消融和对比试验
图11为所提出的方法与不同检测方法的结果,为了从多方面体现所提出模型的优越性,选取了YOLOv3、YOLOv5、文献[14]以及文献[15]4个模型作为结果对比的基准模型,从图11中的识别对比结果和图12给出的各模型召回率可知,YOLOv3检测到的结果较少,表明其召回率较低,YOLOv5虽然检测到了非常多的结果,但却存在许多错误的判断,这是由于YOLOv5在原木检测任务中模型过于复杂,出现了过拟合,而文献[15]与文献[16]在不规则的原木图像下表现均不佳。由此可证明本研究所提出的YOLO-RW在端面检测正例的召回率明显高于其他基准模型。

图11 不同模型的原木端面检测对比结果Fig.11 Comparison results of log end face detection for different models

图12 不同模型召回率对比结果Fig.12 Comparison results of recall rates between different models
此外,为了定量地分析各个模型的检测结果,使用30张测试样本,共840个原木端面进行检测,其中端面完好的原木79个,复杂背景下的原木247个,霉变端面216个,不规则形状端面298个。各个模型的检测出的个数结果见表2。由表2中可以看出,YOLOv5在各种端面的检测中都优于YOLOv3,需要注意的是,虽然YOLOv5检测出了更多的原木数,但其检测错误的数量也同样多,这是由于网络复杂产生的过拟合现象,而本研究所提出的模型在各种端面的检测任务中都获得了最理想的结果。
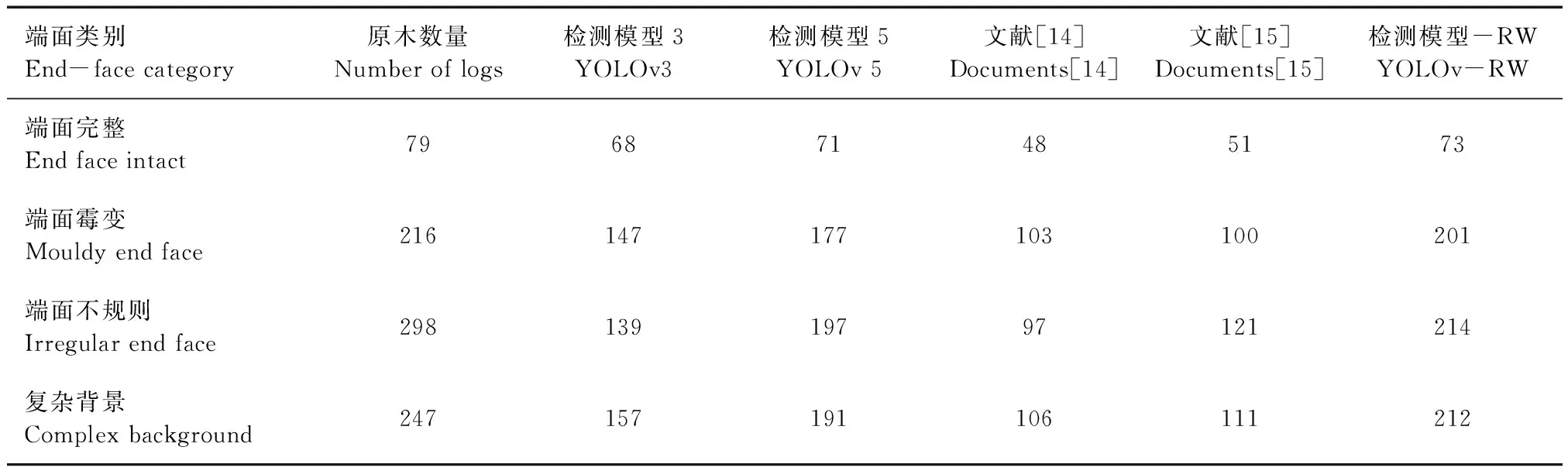
表2 不同模型正确检测出原木端面数量对比Tab.2 Comparison of correctly detected number of log end faces by different models
为进一步证明研究中所提出的每项优化措施合理性以及优越性,进行了消融试验,以目前效果最好的YOLOv7作为基准,分别对所提出的融合模块、损失函数以及数据增强方法进行控制变量,对30张图的840个原木进行检测率的分析,其结果见表3。
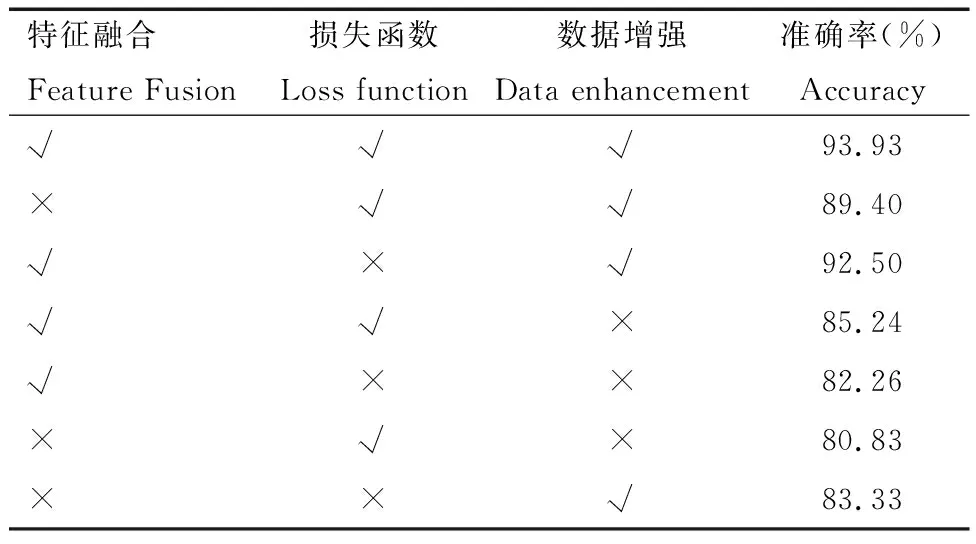
表3 模型优化措施影响检测率的消融试验Tab.3 Ablation tests in which model optimization measures affect the detection rate
从表3中可以看出,同时使用本研究所提出的方法时检测效率最高,其中损失函数对结果的影响较小,其次是特征融合,而数据增强产生的影响较大。
4 结论
原木木材端面识别与定位是木材材积检测系统中最关键的步骤之一,原木木材由于存放场地、存放时间等因素,原木端面会存在伐痕、开裂、凹凸不平和阴影等缺陷,从而导致原木木材材积的智能检测可靠性和稳定性不高。为此,本研究提出一种专门应用于原木木材材积图像的识别YOLO-RW模型,该模型综合分析了各个版本的YOLO模型的优缺点,并通过数据增强、特征融合和损失函数等方面进行优化,从而得到了适合原木检测的端到端新模型。与其他原木检测基准模型相比,本研究提出的方法具有更高的精度和鲁棒性。最后,采用mAP值对目标进行性能评估,通过训练找到mAP值最高的模型,确定模型的最优阈值。试验表明该模型的检测精度高、速度快,在复杂环境下可靠性和稳定性均表现优异。然而,YOLO-RW模型仍存在不足,具体为模型需要耗费大量的计算资源,这导致系统功耗和系统稳定性难以兼顾,对此,将对模型做进一步研究和验证,降低模型的复杂度,以期减少其对系统资源的消耗,提升模型的稳定性和可应用性。
