融合法条的司法裁判文书摘要生成方法
2023-10-12魏鑫炀秦永彬唐向红黄瑞章陈艳平
魏鑫炀,秦永彬,2,唐向红,2+,黄瑞章,2,陈艳平,2
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 省部共建公共大数据重点实验室,贵州 贵阳 550025)
0 引 言
通过对我国法官案件判决过程的调研发现,法官的审判过程中包含有“从案件事实认定,到法律适用选择,最后得出裁判意见”的审判逻辑脉络[1]。裁判文书是总结法官审判过程的重要文书,是体现法官审判依据的重要载体,这也意味着裁判文书中蕴含着法官在整个案件审判过程中的审理逻辑脉络;通过裁判文书我们就能够从中发现“案件事实,适用法律,裁判意见”之间的关联关系,这也是裁判文书重要的逻辑结构特点。而文本摘要任务旨在从一篇或多篇相同主题的文本中抽取能够反映主题的精简压缩版本[2,3],这就意味着裁判文书的摘要也蕴含有重要的法官审理逻辑脉络,如图1所示。

图1 专家摘要中法条与案情描述的对应关系
从图1给出的裁判文书专家摘要示例中可以看出,案件涉及到的主要法条为《中华人民共和国继承法》第二条、第三条、第五条和第十条,而专家摘要的案情部分均与这几个法条高度关联。传统的文本摘要方法直接应用于司法文本时没有考虑这一重要的逻辑结构特点,会导致生成的最终摘要丢失了相关的重要信息,从而使摘要性能达不到预期效果。
因此,通过分析这一重要的法官审理逻辑脉络,我们发现法条的选择与案件的案情描述有着强烈的联系。所以本文参考法官这种审理过程中的审判逻辑脉络,充分利用法条这一外部知识,通过法条辅助生成裁判文书的摘要,使得生成的裁判文书摘要能够最大程度保留原文中的关键信息,提升司法摘要生成的性能。
1 相关工作
自动文本摘要生成算法按实现方式一般分为抽取式(extractive)和生成式(abstractive)[4]。对于传统的抽取式摘要技术,主要是通过统计文本中的共现信息来进行自动文本摘要生成;Mihalcea等[5]提出的Textrank算法为传统抽取式摘要生成算法的代表之一。这些算法主要是通过统计文本中的一些文本特征来进行重要成分筛选,但是对于裁判文书,包含有冗长的案情描述部分,甚至一些重要的事实或证据都不会赘述,文本特征并不明显,运用传统的统计方法容易将这些重要信息丢失。随着机器学习的发展,许多研究人员也将机器学习算法运用到文本摘要任务中;Nallapati等[6]提出SummaRuNNer,Liu[7]提出Bertsum,它们均是采用序列标注的方法抽取出重要的句子组成摘要;这类方法需要提前标注好的数据,并且它们都是进行句子级别的建模,从而忽略了文档中关键词的作用。
相对于抽取摘要来说,生成式摘要的发展时间比较短;See等[8]在基于注意力机制的seq2seq[9]模型基础之上提出了指针生成网络,有效缓解了oov(out-of-vocabulary)问题,可读性问题和重复词问题;近年来随着bert[10]的发展,许多基于bert预训练的文本摘要生成技术被提出,并取得了不错的效果,如BertSumExt[11]和基于UniLM[12]的方法。生成式文摘方法大多都趋向端到端的过程,这就导致了文本摘要生成过程的封闭性,完全由模型自行训练,没有额外信息的辅助,这就会导致原文本中许多重要信息的丢失;在关键信息众多且细微的裁判文书中更是如此。
通过引入外部知识能够有效帮助指导模型保留文章的重要信息,Kai等[13]通过构建模板从文中抽取出关键信息来指导摘要生成;Kundan等[14]通过引入文章的话题作为外部知识辅助摘要的生成;Chen等[15]提出了KIGN模型,该模型通过TextRank抽取出文章中的关键信息来辅助文本摘要生成;但是由于裁判文书的结构性以及包含有法官的审判逻辑脉络,用TextRank对原文本进行关键字抽取,依旧会丢失许多重要的信息。因此本文参考法官的审判逻辑脉络,利用法条逆向辅助保留裁判文书中的重要信息,使得生成的摘要更加符合专家摘要的形式,从而提升摘要生成的性能。
对于司法领域的自动文本摘要,国外的发展要比国内早,目前其主要是利用统计模型,图模型以及分类模型等传统文摘模型[16]来对司法文本进行自动化摘要生成[17]。但是由于国内外的司法体系的不同,国外的司法文本摘要方法并不适用于我国的司法文本摘要生成。而国内相关的司法领域摘要研究尚处于初级阶段,因此本文主要参考新闻领域的摘要研究方向,结合司法领域特点来进行相关的摘要方法研究。
2 方法介绍
2.1 方法概述
基于法官的审判过程和审理逻辑脉络,本文通过引入法条作为外部知识,以此来辅助裁判文书的司法摘要生成。首先对于裁判文书原文部分,我们利用经典的指针生成网络构建一个encoder-decoder框架的抽取式摘要生成模型;然后基于attention机制构建一个关于法条的外部知识编码器;最后将两个模型进行融合输出,通过外部知识来辅助生成最终的司法摘要。整体的模型架构如图2所示。
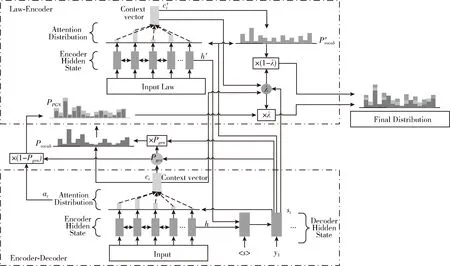
图2 融合法条的司法裁判文书摘要生成模型
2.2 seq2seq模型
在通用领域的自动文摘技术中,Seq2Seq已经成为了一个主流的模型框架,本文采用的基础模型也是基于Seq2Seq模型的指针生成网络。Seq2Seq的模型结构主要包含Encoder和Decoder两个过程,通过Encoder将源文本映射成一个向量,然后Decoder将中间向量转换为相应的文本摘要;即首先将拥有N个词的源文档S=(w1,w2,w3,…,wN) 依次输入Encoder端编码成一个中间层的隐藏状态,之后用Decoder来将该隐藏状态进行解码,最后输出含有M个词的序列Y=(y1,y2,y3,…,yM)。
经典的Seq2Seq在Encoder端是一个双向的LSTM,这个双向的LSTM可以捕捉原文本的长距离依赖关系以及位置信息,编码的词嵌入经过双向LSTM后得到编码状态hi。 在Decoder端,解码器是一个单向的LSTM;在训练阶段,Decoder端将参考摘要词依次输入,在时间步t得到解码状态st; 最后结合上下文向量ct计算得到词典的概率分布Pvocab, 用于预测生成的下一个词。其中上下文向量ct使用注意力机制计算得到,具体计算过程如下
(1)
at=softmax(et)
(2)
(3)
Pvocab=softmax(f(st,ct))
(4)
其中,v,Wh,Ws,battn均为可学习的参数,f表示一个线性函数;得到的注意力分布at可以看作是源文档S中词的概率分布,用来帮助decoder生成下一个词。
2.3 指针生成网络
指针生成网络(pointer-generator network,PGN)是基于Seq2Seq的文本摘要生成模型,它结合传统的Seq2Seq模型与指针网络,通过指针(pointer)机制从源文本中复制单词,有助于准确地复制信息,同时保留通过生成器产生新单词的能力。
传统的seq2seq在计算权重之后会对Encoder的状态进行加权,得到上下文向量c,以此来计算出词典概率分布Pvocab; 而指针网络则在计算权重之后选择概率最大的Encoder状态作为输出,即计算得到输入源文本的词的概率分布at。 指针网络使用不同于传统seq2seq的注意力机制来从输入序列中选择合适的词作为模型的输出,这有助于准确地复制信息,并且使得模型在输出序列中可以有机会生成未录入词典的新词。
对于本文的司法摘要任务来说,由于词典的大小是有限的,许多关键的词语可能不会被收录在词典中,这就可能使得在生成最终摘要时丢失了这些关键信息。我们可以通过Seq2Seq模型计算得到相应的词典概率分布Pvocab(w), 以及通过指针网络计算相应的输入序列的概率分布at, 最后计算一个合适的权重Pgen将两个概率分布结合以得到待生成词的最终概率分布PPGN(w)。 这就使得模型有机会选择从输入的源文本或者从词典中生成合适的词作为摘要,也就可以将这些丢失的关键信息复制到生成的摘要文本中,使得生成的摘要更加准确与合理;下面是具体的计算过程
(5)
(6)

2.4 法条的外部知识编码器
指针生成网络作为主流的自动文摘生成模型,在新闻领域取得了非常不错的性能;但是在司法领域,由于法律文本的特殊性,蕴含有法官审判逻辑脉络的裁判文书直接使用指针网络进行摘要的自动生成时,模型可能会忽略了这种隐含的重要审判逻辑脉络,进一步导致源文本(裁判文书)中重要信息的丢失,从而降低了生成的摘要的性能。因此本文从法官审判逻辑脉络的角度出发,引入法条作为外部知识,使用一个关于法条的外部知识编码器,将每篇裁判文书所涉及到的相关法条内容进行知识编码,结合指针生成网络来进一步保留源文档中的重要信息,从而提升司法摘要生成的性能。
本文的法条外部知识编码器主要是使用一个双向的LSTM来对法条内容进行编码,与指针生成网络中的Encoder端类似,将法条外部知识作为输入,该外部知识为数据预处理阶段得到的关于法条具体条文内容的关键词;之后计算得到一个中间向量,通过中间向量计算得到一个全局的词典概率分布P′vocab(w), 最后将指针生成网络计算得到的概率分布PPGN(w)与P′vocab(w) 进行融合得到最终的概率分布Pfinal(w)。 通过这样的外部知识编码方式,能够使得源文档中与法条内容相关的信息得到加强,从而提升了准确词语生成的概率,进一步提升了整个司法摘要生成的性能。
如图2中所示,本文所采用的模型结合了裁判文书原文以及涉及的相关法条内容,共同来生成相应的司法摘要。对于输入的源文档(裁判文书)S=(w1,w2,w3,…,wN) 以及相关的法条外部知识K=(k1,k2,k3,…,kM), 均采用一个双向的LSTM来进行编码操作,从而分别得到一系列的隐藏状态 (h1,h2,h3,…,hN) 和 (h′1,h′2,…,h′M), 之后通过将两个编码器的最一个隐状态hN与h′M进行连接转换后得到Decoder端的初始状态s0
s0=ReLU(Wf[hN,h′M])
(7)
式中:ReLU=max(0,x),Wf是一个可学习参数。
对于裁判文书和法条外部知识的Encoder部分,参考式(1)、式(2),可计算得到相应的注意力权重分布
eti=vTtanh(Whhi+Wsst+battn)
(8)
e′tj=v′Ttanh(W′hh′j+W′sst+b′attn)
(9)
at=softmax(et)
(10)
a′t=softmax(e′t)
(11)
其中,at为裁判文书Encoder的注意力权重分布,a′t为法条外部知识的注意力权重分布,v,v′,Wh,W′h,Ws,W′s,battn,b′attn均为可学习的参数,而st则为Decoder在时间步t的隐状态,可通过下式计算得到
st=f(st-1,yt-1,ct-1,c′t-1)
(12)
式中:st-1为Decoder在时间步t-1的隐状态,yt-1为Decoder在时间步t的输入,f为一个非线性函数,本文采用LSTM作为函数f;ct-1和c′t-1分别为裁判文书Encoder和法条外部知识Encoder的上下文向量,可通过下式计算得到
(13)
(14)
如图2所示,本文所采用的模型是通过将指针生成网络计算得到的概率分布PPGN(w) 与P′vocab(w) 进行结合得到最终的概率分布Pfinal(w)
Pfinal(w)=λPPGN(w)+(1-λ)P′vocab(w)
(15)
式中:PPGN(w) 为裁判文书通过指针生成网络计算得到的概率分布,可通过式(4)~式(6)、式(12)、式(13)计算得到;P′vocab(w) 为法条外部知识计算得到的词典概率分布,可通过式(4)、式(12)、式(14)计算得到。对于参数λ,它的作用是调节PPGN(w) 与P′vocab(w) 之间的权重,因此需要能够根据解码状态st, Decoder输入yt-1, 裁判文书上下文向量ct, 和法条外部知识的上下文向量c′t来进行调整,因此可通过下式进行计算
(16)
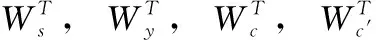
最后,本文使用对数似然函数作为模型的训练损失函数,损失函数如下
(17)

3 实验及分析
3.1 数据集

此外,本文通过构建正则表达式,从数据集中提取出每条数据涉及的相关法条进行统计分析,如图3所示为整个数据集涉及的法条数量分布统计。从图中我们可以看到,整个数据集中,每条数据中涉及的法条数量在“0~17”条之间,其中涉及到3条法条的数据最多,有709条;而每条数据所涉及的法条数量主要集中在“0~9”条之间。因为法条是案件审理逻辑脉络的重要组成部分,因此为了确保法条信息的完整性,本文将每条数据涉及的法条均纳入后续处理阶段。
本文在得到数据集中相关法条的统计数据之后,设计爬虫将涉及到的法律条款从网络上爬取,构建了一个法条库;在数据预处理阶段,从法条库中匹配每篇裁判文书中涉及到的法律条文,将匹配到的条文具体内容作为外部知识;为了降低法律条文中的噪声影响,进一步通过Textrank算法对条文具体内容中的关键词进行统计抽取过滤,将过滤得到的法条关键信息作为外部知识添加到数据集中。
3.2 实验设置
本文采用pytorch框架进行模型的搭建,对于裁判文书和法条的Encoder端均采用512维的双向LSTM,对于Decoder端则是采用512维的单向LSTM;在词向量方面,本文采取随机初始化的方法,将词向量的维度设置为512维,其在持续训练的过程中会不断调整。此外,在进行词典构建时,通过将裁判文书与法条进行联合统计,最终选择了两万个词语构建词典。在整个训练与测试过程中,经过数据预处理阶段,输入的文本长度得到压缩,因此本文中输入的源文本最大长度设置为700,经过统计,能够有效满足模型和数据的要求;生成的文本摘要词数最大长度设置为200,法条外部知识的最大长度设置为100。在训练过程中,本文设置的学习率为0.001,累加器的初始值设置为0.1,训练的batch大小为32。评价指标则采用通用的ROUGE评价指标进行性能评价,将自动生成的摘要与参考摘要进行比较,其中ROUGE-1衡量unigram匹配情况,ROUGE-2衡量bigram匹配,ROUGE-L记录最长的公共子序列。
3.3 基线模型
Lead-3[18]:采用抽取文章的前三句文本作为整篇文章的摘要,由于新闻的重要信息通常都集中在文章的前半部分,因此Lead-3算法能够取得不错的效果。
Textrank:将句子作为节点,句子之间的相似度作为边构建图,通过基于图的排序算法计算句子的重要度,最后抽取排名高的句子组成摘要。
Bertsum:将摘要过程抽象为分类问题,通过BERT获取到原文的句子向量表示,之后通过分类器从句向量中获取到文章的文档级特征,用于最终的摘要提取。
seq2seq+attention模型以及指针生成网络模型(PGN)作为本文的基础对比模型,在2章节中已进行详细介绍。
3.4 实验结果与分析
为了进一步验证我们模型的有效性,本文进行了一系列的对比实验;将我们的模型同所提基线模型进行实验对比,实验结果见表1。

表1 在测试集上模型的ROUGE得分
由表1可以看出,在F1指标上,我们的方法比主流的指针生成网络性能分别高出(1.37 ROUGE-1,4.91 ROUGE-2,3.91 ROUGE-L);比基础模型(baseline)性能分别高出(6.57 ROUGE-1,6.64 ROUGE-2,6.44 ROUGE-L);比Textrank性能分别高出(10.63 ROUGE-1,8.26 ROUGE-2,12.14 ROUGE-L);Lead-3模型则获得了最低的性能。对于抽取式摘要模型,Textrank模型的性能远远高于Lead-3模型,这也进一步说明了司法裁判文书和新闻领域文本的不同之处,新闻领域文本中的重要信息主要会集中在文本前半部分,而司法文本的重要信息则是分布在整篇文章之中,因此Lead-3算法用于司法摘要取得了极差的性能。从性能结果来看,生成式摘要模型(baseline,PGN)的性能均明显高于抽取式摘要模型Textrank,Textrank主要是基于文章中的句子相似度来抽取句子作为文本摘要;在新闻领域,重要的信息通常会在文章中重复出现,而在司法文本中,重要的信息如判决结果等,通常只会出现一遍,因此计算所得的权重会比较低,从而有很大概率不会被抽取作为文章摘要,所以Textrank算法应用于司法领域也具有一定的局限性。
基于BERT的摘要抽取模型在性能上优于Textrank主要是得益于BERT模型在语言表征方面的强大能力,分类器在获得深层次的句子表示之后能够较为准确地判断句子是否属于摘要句。然而由于模型是基于句子进行文本摘要抽取,最终摘要保留了过多冗余信息,因此性能较基于词进行摘要的生成式模型偏低。
对于生成式摘要模型,可以看到性能均优于抽取式模型,并且加入了指针网络的PGN性能也优于基础模型,符合我们的实验预期。而我们的模型主要是在生成式模型PGN的基础上融入了法条作为外部知识信息来辅助生成摘要,我们的模型性能相对于PGN模型和基础模型(baseline)来说均有了一定的提升,这也佐证了参考法官的审判逻辑脉络,融入法条作为外部知识,通过法条逆向保留裁判文书重要信息这一方法的有效性。从表1可以看出,在加入法条作为外部信息之后,对于F1值,我们的模型在ROUGE-1提升了1.37,在ROUGE-2和ROUGE-L均提升了3个点以上,而ROUGE-2和ROUGE-L主要代表生成的摘要和专家摘要之间的长序列的重合度。
从表2可以看到我们的摘要模型采用beam search算法生成的摘要与专家摘要的对比,我们可以看到模型自动生成的摘要基本保留了案件的重要事实,生成的摘要也比较通顺,在长序列上高度与专家摘要重合,但是对于案件细节,生成摘要与专家摘要仍有部分不足,以及涉及的案件金额生成也仍有欠缺。

表2 生成的摘要与专家摘要对比
对于民事裁判文书的重要逻辑结构:“案件事实,适用法律,裁判意见”,我们模型所生成的摘要也基本保留。并且从表2中可以看到,专家摘要给出的事实描述部分有:“合同有效”、“已支取贷款”、“未如期还款”、“违约”;PGN模型生成的摘要中却丢失了“已支取贷款”的重要事实;而本文模型生成的摘要则保留了这一案件事实,且对于“已支取贷款”的描述转化为了“原告按照合同的约定向被告发放了借款”,基本完整保留了与专家摘要一致的案件事实。
这也进一步说明了我们模型生成的摘要与专家摘要拥有更高的相似性,也比较符合我们的实验预期。
4 结束语
本文中我们提出了一种引入法条作为外部知识编码的文本摘要生成方法,不同于传统的自动文摘方法,我们借鉴裁判文书中蕴含的法官重要的审判逻辑脉络,通过提取案件涉及的法条作为外部知识,逆向辅助模型保留文摘生成过程中裁判文书的重要信息,提升裁判文书摘要生成的性能。实验验证,我们提出的方法在实验效果上可以得到很好的提升。不过,我们意识到法条的相关应用工作仍有不足,如嵌套法条的特殊情况,我们将在下一步工作中继续深入研究,以期获得更好的司法摘要生成性能。
