陶瓷与教育领域的知识图谱构建和智能问答应用研究
2023-10-12彭骏捷宋光华章义来
聂 宇,黄 娜,李 超,彭骏捷,宋光华,章义来
(1.景德镇陶瓷大学 信息工程学院,江西 景德镇 333403;2.广东松发陶瓷股份有限公司,广东 潮州 521031;3.景德镇艺术职业大学,江西 景德镇 333000)
0 引言
信息技术的高速发展,促进了智能问答系统在各领域的运用。智能问答系统分为两类,一类是专门性问答,另一类是一般性问答。通常情况下,用户能够自由提问并且获得他们理想的解答。专门领域的问答系统,对于用户的提问只能做浅层分析回复,有时甚至会出现回答的内容与问题不相关的情况。如果用户在其他方面提出了疑问,系统就无法解答。
当前,人们大多习惯通过搜索引擎获取知识,但是传统关键字组合匹配技术并不能准确获得用户需要的结果。而智能问答系统是基于大量语料数据,经过自然语言处理和数学模型计算后,能够和人类进行对话的综合性知识系统,可以在理解用户语义的情况下,获取用户所需的准确数据。
在陶瓷与教育领域,通过大数据技术的不断深入应用,已经汇聚了大量和陶瓷教育相关的数据。但是这类数据在表达、组织管理及存储方法等方面并不完全一致,因为缺少统一的数据处理标准,所以很难充分反应每一种数据之间的联系。
随着互联网中智能服务的不断迭代升级,知识图谱已经被广泛地应用在智能问答、智能搜索和个性化推荐等领域中[1,2]。以知识图谱为基础的智能问答研究,从分析方法上来看目前主要可以分为两种类型:一是以语义为基础的方法,二是以检索为基础的方法。以语义为基础的方法主要是将问题转化成更有逻辑的形式之后再使用结构化的查询语句在知识图谱中获取到合适的答案。具有逻辑形式注释的语料库被Zettlemoyer[3]与Kwiatkowski[4]采用并且进行监督训练。Liang等[5]提出将正则表达式替换为基于依赖组合语义的结构化查询。后者通常更侧重于有效地提取题目或者答案的特征和正确答案的顺序。针对这一问题,张克亮等[6]以本体三元组(BET)为中心设计并实现了一个面向航空领域的问答系统(AMS),在实际的应用中,该系统均有良好的表现,取得了预期的效果。Yao等人在文献[7]中利用依赖性分析刻画问题的问句得到了关系图,并且定位到了一定范围内的关系和实体。通过比较所得主体图和问句生成的图,对所有节点沿着图进行排序和运算,获得正确答案。
本文将从陶瓷与教育领域的数据入手,通过构建知识图谱开展研究,以知识图谱技术为陶瓷与教育领域的智能问答应用提供有效的数据支撑。
1 语料库和知识图谱构建
目前我国教育行业数据十分丰富,有较多的成熟数据集可用,因此,可以快速便捷地导入Neo4j图数据库形成知识图谱,实体与实体之间的关系可以借助知识图谱直观展现出来。
然而,陶瓷类的数据没有成熟可用的数据集,因此,本实验将通过爬虫技术在互联网中获取陶瓷类相关数据,以统一的数据标准格式构建陶瓷类数据集,并最终用于陶瓷领域的知识图谱的研究和建设。
1.1 数据来源
本研究采用多种搜索引擎(包括“百度”“必应”“搜狗搜索”),经过对多种搜索结果的比较,最后确定国学诗词为教育类知识图谱数据源。
陶瓷类数据,则选取“了了亭”网站的数据为陶瓷类语料库数据源。“了了亭”是景德镇陶瓷艺术专业网站,在当代陶瓷收藏界享有盛名。本文所建设的陶瓷类语料库包括“陶瓷工艺”“陶瓷美术”“陶瓷历史”等内容。
1.2 数据获取
本文主要采用爬虫技术对“了了亭”网站的“陶瓷工艺”“陶瓷美术”“陶瓷历史”三个专栏进行定向数据获取,并将数据存储成不同的CSV文件以便后续构建不同语料库时使用。
在对页面进行解析和数据提取之后,对所获取的数据进行格式化处理。表1显示从“了了亭”网站上得到的一些“陶瓷历史”资料情况,这些资料全面而详实,为陶瓷语料库建设提供了有力支撑。
1.3 数据清洗
本文爬虫所获取到的陶瓷类数据,还包含有一些与问答不相关的语气词和形容词等,这些内容对问答系统数据逻辑和答案生成有不利影响。为了确保项目爬取到的数据信息是比较客观且高质量的,就需要通过编程进一步进行数据清洗,以剔除掉那些效果不佳甚至是起到消极效果的词,减少此问答系统中不稳定的部分,主要处理的非法字符示例如表2所示。

表2 非法字符处理示例
1.4 图谱构建
在完成数据获取和语料库建立后,进一步开始构建知识图谱。
本文获取到的国学诗词教育类数据量比较大,通过对教育类数据的分析后发现,得到的数据大致分为诗歌、作者、简介、内容以及其他实体类型。在完成实体分析后,进一步完成实体间的关系的填充,形成可用于图谱构建的三元组数据。该系统所构造的三元组数据量大,共包含43007种实体和52802种关系,为知识图谱的构建提供了丰富的数据。
本文采用Neo4j图形数据库来管理三元组数据,当数据保存到Neo4j数据库中时可通过自身端口对数据执行增、删、改、查等操作。如表3所示,统计了部分知识图谱的数据量。

表3 知识图谱数据量
2 智能问答系统构建
2.1 BiLSTM-CRF命名实体识别算法
(1)BiLSTM模块
LSTM(Long-Short Term Memory),也就是长短时记忆网络,它是RNN中的一种变体,能够处理RNN中出现的梯度爆炸现象,非常适合时序数据建模。在LSTM中加入三种结构,分别为:记忆门、遗忘门和输出门;其中记忆门确定信息是否被储存,遗忘门确定信息是否忘记,而输出门则用来判断当前的状态。
因为LSTM模型具有单向结构,它对句子建模过程中不能编码从右侧到左侧或从后面到前面的信息,所以对上下文语境及语义信息处理并不理想。所以我们采用了BiLSTM(Bi-directional Long Short Term Memory) 双向长短期记忆网络,它能够较好地捕捉双向依赖关系,并通过处理每一个词序列采用前向LSTM和后向LSTM,使每一个时刻特征具有前向依赖关系和后向依赖关系。
(2)CRF模块
CRF(Conditional Random Field)是条件随机场的英文缩写,它可以通过相邻标签之间的关系得到最佳预测序列[8],就BiLSTM-CRF算法模型来说,CRF的功能就是通过BiLSTM预测输出序列使得目标函数达到最优化。
在本论文所做BIO标注时,BiLSTM输出序列对每一个字都预测最大概率标签并获得非归一化概率分布,然而允许存在单字词概率最优和全句概率偏差等问题,利用CRF对其约束之后就可以获得全句最优标签预测,特征转移概率是CRF所学习的。
对输入序列为X=(X1,X2...Xn),预测输出序列为Y=(Y1,Y2...Yn)的分数可表示为公式1,即转移概率与状态概率相加:
此处用A来代表转移矩阵,P来代表BiLSTM的输出得分矩阵。标签序列Y的概率值通过softmax得到:
CRF网络各节点分别表示预测值,根据BiLSTM所输出预测序列,搜索网络中概率最大路径,对输出命名实体进行标签标记识别,完成命名实体识别。因此训练以最大化概率为目的P(y|X),可以用如下所示的对数似然来达到。
通过维比特算法进行预测解码获得解的最优路径:
y*=argmaxscore(x,y′)
(4)
2.2 TextCNN关系识别算法
在命名实体识别工作结束后,关系识别是对各实体之间关联的关系属性和知识图谱上相应关系属性的匹配识别操作。比如,问一句:“李白有什么诗歌?”确定实体标签“李白”后,从知识图谱上查找实体的关系属性为“介绍”“诗”等。本论文中把TextCNN模型用到关系识别中,不同于RNN和其他序列模型,TextCNN具有简单的网络结构,但是引入已训练的词向量仍然可以取得非常理想的结果,并且具有非常快的训练速度。首先提取语句上下文特征,然后送入TextCNN网络中做卷积运算,得到问句序列与候选关系属性两者的语义向量[9],再做相似度计算可得关系并识别结果。TextCNN的构造比较简单,训练量较快。如下所示为TextCNN的网络结构如图1所示。

图1 TextCNN网络结构图
上图输入为使用预训练词向量(Word2Vector或glove)法获得的Embeddinglayer。每个词向量采用无监督方式进行训练。
以往提及CNN,一般都被视作CV领域并应用于计算机视觉方向上的作品,但Yoon Kim对CNN输入层进行了部分变形进而提出文本分类模型TextCNN。
2.3 架构设计
智能问答的系统架构如图2所示,系统整体自顶向下依次为应用层、逻辑层以及数据层。

图2 系统架构设计
(1)数据层
数据层为整个智能问答系统提供了数据支撑[10],其主要由以下几个步骤构建:首先利用爬虫获取数据,随后通过命名体识别和知识抽取完成教育领域知识图谱的构建并保存在Neo4j图数据库中,其中陶瓷领域语料库采用TXT文件保存为实体词典,并通过命名实体识别进行问句中的实体关系标识任务。
(2)逻辑层
逻辑层以知识图谱为主线,结合问答流程相关算法向应用层提供对外服务的API接口。当系统获得前端发送过来的问题之后,需要先解析问题的语义,当理解了用户的意图与目标之后,再从知识图谱上检索出相应的回答,然后将其回传至用户。这一层的主要API接口简介:
(A)自然语言自动问答
功能说明:在获取到用户的提问数据后,进行问句分析,之后查询Neo4j数据库内容,最后返回答案。假如未获得回答,返回预设的回复模板。
(B)问句分析
功能说明:在获取到用户的提问数据后,先识别实体,再获取所指向的属性或者关系,最后基于实体以及关系/属性构建对应的Cypher询问语句并得到回答。
(3)应用层
主要是前端Web页面,这是智能问答系统的入口,其中功能模块为问答服务、语音播报、默认提问。
2.4 智能问答系统展示
本文搭建了一个简易的智能问答系统页面,后端使用Python 3.7 +Flask开发,前端采用VueJS 3开发,基于MySQL 8数据库,在Ubuntu 22.04环境下部署构建。通过对话界面中的输入框,可以完成提问操作。系统在找到用户提问的答案后,会直接回传答案并显示在页面上,而且因为与语音合成模块连接,所以该系统会以文字与语音两种形式来呈现答案。图3所示是一个问答的例子,例如输入一个问句“康熙彩的意思是什么?”网页返回的回答是“古彩,硬彩”,从而让用户获得了一个理想的回答。
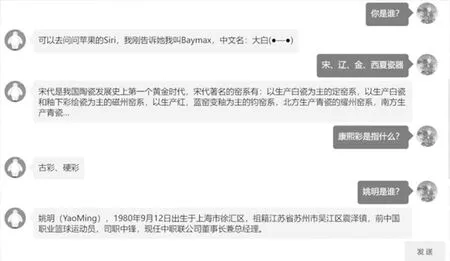
图3 问答系统示例
3 结论
智能问答系统提供了高效、准确的知识获取解决方案。相比于传统的搜索引擎作为知识获取载体,显然更贴近人类的沟通方式,这给大家获取信息提供了新的便利。
(1)本文根据笔者的创新性想法,对基于知识图谱的智能问答系统有关技术与理论展开研究。
(2)本文对基于深度学习的实体识别进行研究,并结合BiLSTM-CRF模型设计实体识别算法。本研究采用BiLSTM-CRF充分挖掘上下文信息并对问句中选实体进行定位。
(3)本文对基于TextCNN关系识别技术进行研究,结合余弦相似度进行计算,选择出合适的候选属性。
(4)结合本文的有关算法模型在知识图谱智能问答系统的基础上进行设计与实现,实际使用情况表明,以知识图谱为载体的智能问答系统能够满足用户对信息获取的要求,本研究获得了理想的结果。
智能问答技术涉及信息检索、自然语言处理等多门学科,属于综合研究范畴。但以知识图谱为基础的智能问答系统尚处初步研究阶段,许多方面有待完善。今后还将继续拓展知识图谱的内容,不断优化智能对话系统,并通过历史数据分析,提升问答系统综合性能。
