基于GAN 的中文虚假评论数据集生成方法
2023-10-08吴正清
吴正清,曹 晖
(西北民族大学 中国民族语言文字信息技术教育部重点实验室,甘肃 兰州 730030)
在当今提倡信息共享的互联网时代,购物、旅游、用餐前借鉴消费者评论已成为网络用户必不可少的环节,但虚假评论广泛存在于电子商务、餐饮、社交媒体、旅游网站中.时代日趋发展,该问题也愈发严重.但是,在研究领域尚没有完全公开的中文虚假评论数据集.中文虚假评论数据集不完备的问题给中文虚假评论研究带来不小的问题和挑战.
目前,主要有3 种构建虚假评论数据集的方法.第一种是通过在互联网上获取的评论再进行人工分类获取虚假评论数据[1].由于互联网上许多虚假评论似真似假,人为难以分辨,数据集标注准确率低,且人力物力消耗过大;同时大部分互联网公司的信息保密性导致难以获取大量数据.第2 种是通过人为书写并筛选.Ott 等[2]通过雇佣人力按照要求书写虚假评论,同时按照要求筛选真实评论,获得800 条英文虚假评论数据,这种方法在构造大批量数据时,会消耗巨大的人力物力.第3 种是通过机器模型生成.2022 年蔡丽坤等[3]提出通过机器生成具有类别属性的文本,在很大程度上缓解了大规模有标签数据集获取困难的问题.其中机器生成的方法主要有两种:传统机器学习方法以及深度学习方法.传统机器学习的生成文本的方法[4]是基于规则与概率统计的,生成之前需要构造大量手工规则,并且在大数据上效果欠佳.而当今深度学习方法弥补了传统机器学习方法的两个缺陷,且具有更强的泛化能力与语义理解能力,进而达到更好的生成效果,如循环神经网络[5-6]、编码器解码器模型[7-8]、生成对抗网络[9-12]、预训练模型[13]等.它们广泛应用于文本生成领域,且实验证明了有效性.但以上模型缺少调整生成文本序列的属性特征或通顺性及健壮性的模块,至多关注到其中一种.
因此,不同于以上工作,本文从生成文本的属性特征与通顺性及健壮性出发,在生成对抗网络[9](Generative Adversarial Networks,GAN)+强化学习[14](Reinforcement Learning,RL)通用范式的基础上,通过增加控制生成文本类别的生成器和提升生成文本通顺及健壮程度的重构器,构建了中文虚假评论数据集生成(discriminator-classifier-reconstructor GAN,dcrGAN)模型,解决了中文虚假评论数据不足且难以构造的问题,并通过实验证明该方法的有效性.
1 相关工作
当前主流的深度学习文本生成方法主要有4 种:第1 种是基于循环神经网络,第2 种是基于编码器解码器,第3 种是基于生成对抗网络,第4种是基于预训练模型.
第1 种,循环神经网络(Recurrent Neural Network,RNN)和它的变体长短期记忆网络(Long Short-Term Memory,LSTM)[5]以及基于LSTM 的门控循环单元(Gate Recurrent Unit,GRU)[6]可基于时序生成文本序列,但其经过长距离的梯度传递,容易出现梯度消失或爆炸,且无法生成具有类标签属性及特征的文本.
第2 种,Seq2Seq[7]模型及VAE[8]模型是两种典型的编码器解码器模型,通过将原始输入编码为一个下上文向量或隐变量,再解码器解码进行输出.该方法相对第1 种方法有更好的语义理解能力,但两者都缺乏控制生成文本的属性及特征的能力与创新能力,且当两者的编码器与解码器都是RNN时,容易出现梯度消失或爆炸.
第3 种,基于GAN 的文本生成方法,它的输入是从先验正太分布中采样得到的噪声,相较于第2种方法具有更强的创新能力.结合Goodfellow等[9]2014 年提出基于博弈思想的GAN 和RL 的策略梯度,2017 年Yu 等[10]提出生成文本的SeqGAN模型.同年,Lin 等[11]提出RankGAN 模型,其判别器通过整体查看一组人类和机器编写的句子集合得出相对排序分数做出评估,通过梯度策略优化生成器参数,从而生成接近人类编写的文本.以上两个基于GAN 的模型,通过GAN+RL 的方法,进行文本生成,且取得了不错的文本生成效果,但两者无法控制生成文本的属性与特征.2019 年Stanton等[12]提出基于GAN 的半监督文本分类模型spamGAN,其能够通过模型中的分类器进行虚假评论分类以及指导生成器生成带有相应类标签的英文虚假评论数据,但在中文虚假评论数据生成上,易出现生成评论属性与类别不对应以及语句不通顺的现象.以上3 个模型皆是基于GAN 并融合强化学习方法进行文本生成,取得不错效果,但在生成文本通顺性及健壮性和生成具有相应类标签的属性及特征的文本两方面有所不足.
第4 种,2021 年Pascual 等[13]提出的即插即用的K2T 模型,通过对大型预先训练的语言模型向给定引导词和引导文本的语义空间转移,文本通顺性较好.但此方法是根据引导词和引导文本进行类似于文本补全的操作,难以获取文本属性与特征.
2 虚假评论数据生成模型
生成中文虚假评论数据集的关键在于:一是生成文本具有虚假评论数据集的属性与特征;二是生成的中文文本具有较好的健壮性与通顺性;三是可以大规模批量地生成.针对这3 个关键问题,本文探索了一种基于GAN 的模型,在GAN 模型的基础上增添了控制生成文本属性与类别的分类器和优化生成文本质量的重构器,用于生成中文虚假评论数据集.
2.1 问题建立本文数据集包括有标签数据集℘L和无标签数据集 ℘U,同时两种数据集都包含虚假及真实评论.
是有标签数据集 ℘L和无标签数据集 ℘U的并集,为模型训练阶段的数据集.V为℘的词表,每条用于训练的句子
式中:词标记yt∈V为句子的第t个词标记,T为句子的长度.有标签数据集 ℘L的句子拥有两种类标签c∈C:{虚假,真实};同时,无标签数据集 ℘U也包含这两种类型的句子.本文用Prs(Y1:T,c)表示真句子的联合分布.
如图1 所示,本文模型包含5 个组成部分:生成器G、判别器D、分类器C、重构器R及Rollout模块,其中QC、QD及QR分别表示判别器、分类器及重构器的奖励分数.生成器G可以根据给定的类标签c生成带有类标签属性及特征的假句子,其中假句子是生成器G生成的文字序列,真句子是数据集中的句子.判别器D学习区分真句子与假句子,通过奖励的形式将生成的句子是真是假的信息传回到生成器G,两者之间相互竞争,生成器G趋向于生成越来越接近真实世界的句子,同时判别器D不断提高分辨生成句子真假的能力,最后达到提高生成句子质量的目的.

图1 dcrGAN 模型结构Fig.1 dcrGAN model structure
生成器G生成的句子的类标签可由类标签 C:{虚假,真实}控制[15].模型中的分类器C的作用正是如此.它使用有标签数据集 ℘L和生成器生成的假句子进行训练,通过传回分类器C在假句子上的表现的方式改进生成器G.同时通过在假句子上进行分类器C训练,也进一步提高分类器C本身的类标签 C的分类准确率,从而为生成器G带来更好的奖励,两者相辅相成.
Wang 等[16]提出的模型运用重构的方法优化了生成文本的质量.在本文模型中,重构器R针对生成句子的健壮性及通顺性的问题,从语义的角度使假句子更接近真实世界的句子.重构器R包括Ra、Rb两个子重构器.使用数据集 ℘和假句子分别在两个初始参数相同的子重构器Ra和Rb上进行训练,其中Rb放入数据集 ℘的句子进行重构,Ra放入假句子进行重构,将两个子重构器的表现之差作为奖励传递给生成器G,对生成器G进行调整,进而使生成句子更加通顺健壮.
上述的模型3 个部分的奖励通过策略梯度的方式传回到生成器G,对生成器G进行参数更新.
2.2 生成器本文生成器采用门控循环单元(Gate Recurrent Unit,GRU)[6]作为基本单元.生成器G的目的是找到最接近真实世界句子的参数化条件分布 G(Y1:T|z,c,ϑg),其中z为噪声向量,c为类标签,它们分别从先验分布Pz与Pc中随机采样得到,文中Pz为正态分布,Pc为伯努利分布,ϑg为G的网络参数.z和c共同组成上下文向量,在每个时刻都与生成的句子合并[17],以确保G生成的句子保留类标签.
从G(Y1:T|z,c,ϑg)中采样获取词序列时,词序列中的词标记通过自回归的方式生成,然后通过式(3)分解该分布,将词序列转为有序的条件序列,也就是假句子.
当进行对抗训练时,假句子生成被视为一个序列决策问题.把生成器当作强化学习代理,并使用策略梯度训练生成器,奖励是判别器、分类器及重构器在生成句子上的表现(详见2.7 节).
2.3 判别器Zhang 等[18]的研究表明,卷积神经网络(Convolutional Neural Network,CNN)[19]在机器翻译和文本分类上可以实现高性能.因此,本文的判别器D采用CNN.它通过计算一个句子趋近于真句子的概率分数D((Y1:T|ϑd)判)断句子是来自Prs(Y1:Y,c),还是来自 GY1:T|z,c,ϑg,ϑd表示判别器网络参数.
首先将合并的输入序列矩阵映射到嵌入的特征向量:
然后,使用卷积核ψ ∈Ml×k对l大小的窗口进行卷积操作,得到一个新的特征映射,并用非线性函数对新特征进行计算:
式中:i为当前进行卷积操作的位置,F2为非线性函数,⊕为元素级乘积之和,ε为偏置项.接着,对特征映射在序列长度维度做最大池化操作:
再者,为了提高模型表现力,对最大池化完的特征映射加入highway 架构[20].
最后,使用一个具有Sigmoid 激活函数的全连接层来输出输入序列是实数的概率.
式中:σ为Sigmoid 激活函数,WT、εT和 WH为highway 层的权重参数,H 为仿射变换后的非线性激活函数,τ为与H(ϖ,WH) 和 ϖ维度相同的变换门,Wo和 εo为全连接层的权重和偏置.
判别器的优化目标是:当序列为真句子时,最大化概率分数D(Y1:T|ϑd);当序列为假句子时,最小化概率分数.这是通过最小化损失实现的.
2.4 分类器分类器同样采用CNN,通过计算一个句子是否属于类别c∈C的概率分数C(Y1:T|ϑc,c)判断句子的类别.ϑc是分类器网络参数.
分类器的运行过程与判别器类似,不同之处在于分类器的损失函数.分类器的损失函数由两个部分组成:,在真句子上,由概率分数C(Y1:T|ϑc,c)计算出的交叉熵损失:,由于假句子是潜在有噪声的,为了使得分类器更准确地预测生成的假句子的类别,在计算假句子的损失时,不仅最小化交叉熵损失,还包括香农熵[12]Z (C(Y1:T|ϑc,c)).
2.5 重构器相比于Wang 等[16]重构方式,本文模型采用经过改造的变分自编码器(Variational Autoencoder,VAE)[8]作为重构器R的子模型,它有更强的文本信息捕捉能力.它的目的是通过计算真假句子重构的元素级损失之差,损失差作为奖励分数传回给生成器,对生成器进行微调,使得生成器生成的句子更健壮、更通顺.重构器R包括两个子重构器Ra和Rb,两个子模型初始化状态相同,进行并行运算.重构器如图2 所示.

图2 重构器总体架构Fig.2 The overall architecture of the reconstructor
由于重构损失随着重构样本的不同而导致其差别很大,直接将重构损失作为传回生成器的奖励分数是不稳定的,因此增加子重构器Rb作为Ra的基线模型以减小重构器奖励分数的不稳定性.其中,Ra对假句子进行重构,Rb对真句子进行重构,它们的目标是使重构得到的句子接近放入Rb中的句子.子重构器如图3 所示,主要包括编码器、连接器和解码器3 个部分.

图3 子重构器结构Fig.3 The structure of child reconstructor
编码器采用单向双层LSTM[5],解码器采用Transformer[21]的编码器.首先,将训练句子经过嵌入层计算得到特征映射,放入编码器中得到编码器状态(encoder states).然后,连接器中的多层感知机(MultiLayer Perceptron,MLP)通过编码器状态得到用来生成变分后验分布d的均值(mean)及方差(logvar),变分后验分布d要尽力拟合标准正太分布.由于从分布中采样无法求偏导,接下来采用重参数化技巧(Rep)得到状态和隐变量,将上一步得到的状态作为解码器初始状态,同时,将经过嵌入层计算的训练句子的特征映射和训练句子的位置映射相加放入解码器中,得到重构句子Yr.
式(16)、(17)分别为子重构器Ra和Rb的损失函数.子重构器损失由两部分组成:①句子重构的交叉熵损失;②连接器中变分后验分布d拟合标准正太分布的损失.本文通过最小化重构损失训练重构器Ra和Rb.为了避免训练过程中出现梯度消失或梯度爆炸,采用 JS(Jenson’s Shannon)散度作为分布拟合损失.
将两个子重构器损失之差作为传回生成器G的奖励分数R(Y1:T|ϑr),对其进行优化.
2.6 Rollout 策略如图4 所示,为了评估生成器生成句子的中间状态Y1:t的动作值,本文采用带有蒙特卡洛(MC)搜索的Rollout 策略去采样剩余T-t个词标记.Rollout 中使用与生成器G时刻保持一致的G∂进行采样,网络参数表示为.将一个N次MC 搜索表示为:

图4 MC 搜索Fig.4 MC search
2.7 强化学习部分本文视序列生成为一个序列决策问题,把生成器当作一个强化学习代理.生成器的当前状态是已生成的部分序列s=Y1:t-1;动作值是生成器将要生成的下一个词标记a=yt,它基于随机策略G(yt|Y1:t-1,z,c,ϑg)进行选择.为了得到更准确的动作值的估计值和减少方差,从当前状态开始到序列的结尾,本文将Rollout 策略运行N次,每次得到一批次的输出样本,根据Rollout 策略产生的一批次输出样本得到奖励分数Q.因此,可以得到生成器G的3 种奖励分数.
(1)判别器奖励分数:
(2)分类器奖励分数:
(3)重构器奖励分数:
从式(20)~(22)可以看到,当下一个动作值a为yT时,没有中间奖励需要生成,直接根据当前序列获得奖励分数Q.
取QD、QC及QR,先以F1 分数的计算方式对QD和QC进行混合相加得到QDC,然后将QDC与QR进行直接相加,得到总体奖励 W.
生成器代理寻求最大化期望奖励,由如下给出:
在对抗训练中,使用式(26)进行梯度上升,并更新生成器参数.
2.8 模型算法模型算法的主要步骤如下:
步骤1对模型各部分进行预训练.Stanton等[12]指出对模型进行预训练在一定程度上可以解决模式坍塌问题,因此,对模型进行各个部分的预训练:生成器使用公式(4)进行预训练;Yu 等[10]发现预训练判别器的监督信号是有信息的,有助于有效调整生成器,所以取批量次的数据集 ℘的真句子和从分布 G(Y1:T|z,c,ϑg)中采样的假句子,使用式(12)对判别器进行预训练;使用式(16)和(17)对重构器进行预训练;分类器使用式(14)取有标签数据集 ℘L中的批量真句子进行预训练.
步骤2将生成器G网络参数 ϑg赋给Rollout生成器G∂网络参数
步骤3进行Training-epochs 次对抗训练.在对抗训练中,生成器与判别器、分类器、重构器进行交替训练.生成器G根据从Pc中采样的类别c生成一批量的假句子.使用式(24)计算每个时间步的W(Y1:t-1,yt,c).通过式(26)对生成器G网络参数ϑg进行更新.取 ℘中的一批量真句子和生成器G生成的一批量假句子,每R-every-epochs 次通过式(16)和(17)对重构器R进行一次训练,更新网络参数.同样取 ℘中的一批量真句子和生成器G生成的一批量假句子,通过式(12)对判别器D进行Depochs 次训练,更新网络参数.接着取 ℘L中一批量带有类标签的真句子和生成器G生成的一批量带有类标签的假句子,以相似的方式对分类器C进行网络参数更新.为了增强训练过程的鲁棒性[22],在对抗训练中通过式(4)进行训练,每mle-everyepochs 进行mle-epochs 次.每次对抗训练结束后,都将生成器网络参数赋给Rollout 生成器网络参数.
3 实验和结果分析
3.1 数据集本文中使用的数据集是Li 等[23]的虚假评论数据集,该数据集均为上海餐厅评论,未完全公开.该数据集原本数据量为9 765 条,将其中经过分词后的评论字符数少于12、与评价事物毫不相干、标点符号数目在此条评论占比高于该评论总字符数的75%、评论中有非中文字符的这些评论进行剔除,剩余8 896 条评论.
将其中1 920 条评论保留其标签,作为有标签数据集,标签为1 代表评论为虚假,标签为0 代表评论为真实;剩余7 616 条评论不保留标签,作为无标签数据集.有标签数据和无标签数据均为同一数据域.
如表1 所示,在实验过程中,将有标签数据集按4∶1∶1 的比例分为训练集1 280 条、验证集320 条和测试集320 条,每个集合的虚假评论占比大致等于1/3.

表1 有标签数据集信息统计Tab.1 Information statistics for labeled datasets
3.2 超参数在实验中,Rollout 策略运行次数N设为16;最大的序列长度M为48,表示生成文本及放入模型中文本的最大长度,它接近于整个数据集评论长度的中位数.数据集按词进行切分,词表大小V为10 000,V中包括<UNK>、<PAD>、<BOS>、<EOS>,<BOS>、<EOS>放在每个句子的开头及结尾.为确保句子长度的一致性,长度小于M的句子会填充<PAD>至M,大于M的句子会被截断至M,<UNK>用于代替没在词表内出现的词.
模型中,生成器由每层包含1 024 个单元的单向双GRU 层以及一个为10 000 词标记提供logits的全连接层组成.对于生成器,在循环层与50 维的词嵌入层之间使用0.5 保留率的dropout.判别器和分类器的卷积核大小l由1 到M,设置多个大小,以提取更加丰富的文本特征,每种卷积核数量在100~200.判别器和分类器中,为避免过拟合,使用0.7 保留率的dropout 和L2 损失,平衡系数 β设为1.重构器的两个子模型的编码器是由包含1 024 个单元的单向双LSTM 层以及一个为10 000词标记提供logits 的全连接层组成;连接器中MLP 的隐藏层维度为128;解码器中的所有维度及单元数都以1 024 为基础,解码器块数为3.生成器、判别器、分类器及重构器都使用Adam 优化器进行训练.表2 为模型各部分优化器参数数值.
3.3 基线模型本文采用5 个基线模型进行模型性能比较,分别是spamGAN、SeqGAN、RankGAN、K2T、Base generator.spamGAN、SeqGAN 及Rank-GAN 均采用原模型;K2T 采用原模型的无引导词、有引导上下文的模式;Base generator 是本文模型的生成器.SeqGAN、RankGAN 及Base generator 的训练集为有标签数据集的训练集和无标签数据集,验证集和测试集与本文模型一致;spamGAN 的数据集设置与本文模型一致;K2T 因其为即插即用的文本生成模型,故直接在测试集上进行测试.
3.4 评价指标本文使用BLEU(Bilingual Evaluation Understudy)[24]的二元组、三元组及四元组精度作为实验的评价指标.该指标较多使用于文本生成领域.其值范围为0~1,数值越大表示生成效果越好.同时,由于本文模型也是基于对抗生成网络(GAN)搭建的模型,因此,在真实世界的数据集、而非oracle[10]生成的数据集上使用SeqGAN[10]中采用的NLL 指标对本文模型和同样以GAN 模型为基础搭建的SeqGAN、RankGAN 和spamGAN 进行比较.
式中:oracle 模型与SeqGAN 中的该模型配置一致,它相当于一个真实世界问题的人类观察者;G是生成器,Goracle是oracle 模型.在测试时,使用生成的100 000 条序列样本,并通过Goracle计算每一条序列样本的NLL 值,最后取平均值,序列生成的问题越大,损失也就越大.
3.5 实验结果
3.5.1 不同模型对比 表3 展示了不同模型在预训练60 次、对抗训练30 次的基础上,取3 次测试得到的BLEU 值的平均值,本文模型dcrGAN 在各元组的BLEU 值上都优于其他基线模型.同时,表4 中展示了本文模型比其他基于GAN 的模型取得更优的NLL 指标结果.

表3 各个模型的BLEU 值Tab.3 BLEU value for each model

表4 基于对抗生成网络的模型的NLL 值比较Tab.4 Comparison of NLL values of adversarial generative network based models
为了探究本文模型各个部分的重要性,将模型的一些部分进行更换或删除.如表5 所示,对dcrGAN 模型的各个版本的名称进行辅助解释.dcrGAN-cnn 为本文模型无重构器版本,dcrGANcnn-sq2sq 为本文模型重构器为有注意力机制的seq2seq 版本,dcrGAN-rnn-vae 为本文模型判别器和分类器与spamGAN 中一致、重构器为VAE 的版本,dcrGAN-rnn-sq2sq 为本文模型判别器和分类器与spamGAN 中一致、重构器为有注意力机制的seq2seq 版本.其中,seq2seq 重构方式与Wang 等提出的模型[16]类似,结构为双向双层LSTM,每层1 024 个单元,其他与本文模型一致.
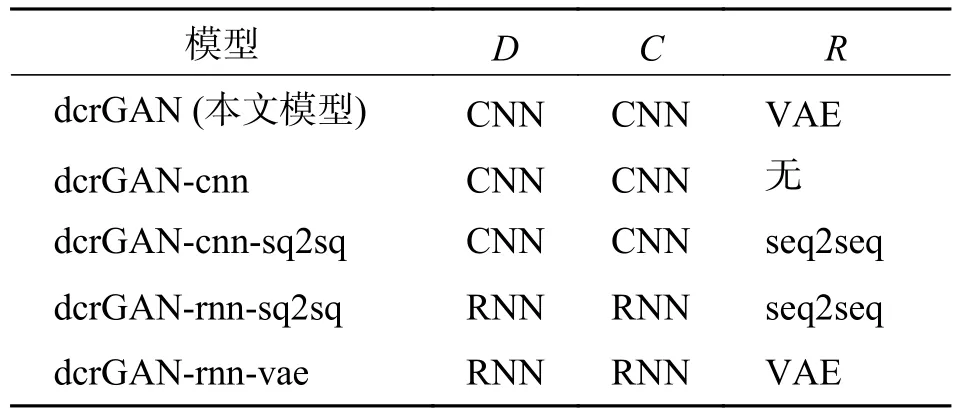
表5 各个版本dcrGAN 模型的各部分情况Tab.5 The various parts of the dcrGAN model for each version
如表5 所示,当dcrGAN 中判别器和分类器为CNN 时,模型的BLEU 值比为RNN 时更大;当dcrGAN 中重构器为VAE 时,BLEU 值比为seq2seq时更大;当dcrGAN 中,在两个模型的判别器及分类器相同的前提下,有重构器比没有重构器BLEU值更大.当dcrGAN 中判别器和分类器都为CNN时,二元组BLEU 值比其他模型都更高;但当dcrGAN 中为判别器和分类器为RNN、且存在无论重构器是seq2seq 或VAE 时,效果不及大部分模型.对于这种情况,本文考虑CNN 的判别器和分类器获取的语义信息更加多样丰富,从而产生的奖励更加拟合与重构器产生的奖励,两者相辅相成;反之,为RNN 时,三者奖励混合相加后的奖励分数指导效果更差,而没有达到进一步优化生成器的效果.因此,由实验结果得出,模型中加入重构器对文本生成效果有提升,且当判别器和分类器为CNN、重构器为VAE 时,模型生成效果最好,超过所有基线模型.
3.5.2 重构器训练方式的影响 同时,本文还对不同的重构器训练方式对实验结果的影响进行了研究.如图5、图6 所示,dcrGAN-R3 代表dcrGAN模型在重构器每隔3 次训练(R-every-epochs 为3)的情况在进行实验,并且提出其他3 种版本:dcrGAN-R1(R-every-epochs 为1)、dcrGAN-R5(Revery-epochs为5)及dcrGAN-R10(R-every-epochs为10);其中dcrGAN-R3 与表4 中dcrGAN 一致.

图5 不同R-every-epochs 下的BLEU 值Fig.5 BLEU value under different R-every-epochs

图6 不同R-every-epochs 下的困惑度Fig.6 Perplexity under different R-every-epochs
如图5 所示,在二元组BLEU 值上,任意Revery-epochs 值的dcrGAN 模型都比表4 中的基线模型大,其中dcrGAN-R5 值最大;在三元组BLEU值上,dcrGAN-R3 和dcrGAN-R5 比表4 基线模型大,其他两种略小一些,其中dcrGAN-R5 值最大;在四元组BLEU 值上,只有dcrGAN-R3 超过表4基线模型,dcrGAN-R5 略小一些,其他两个版本相差略大.图6 为4 种dcrGAN 版本模型的困惑度(值越小代表效果越好),可以看到,dcrGAN-R3 最小,为70.148 8,其他3 个版本超过dcrGAN-R3 至少6 个度.因此,R-every-epochs 为3 时,dcrGAN 模型总体效果最佳.
3.5.3 本文模型句子生成 使用本文模型dcrGAN生成句子,随机选取一些句子展示在表6 中.表6中第一部分是生成的带有虚假标签的句子,第二部分生成的带有真实标签的句子,从表中可以看到,生成的两种文本都具有较高的可读性,且较为通顺.其中,生成的虚假评论已学习到了数据集中虚假评论的结构信息以及语义信息,例如带有一长串的标点符号的评论在数据集基本都被赋予虚假标签,且大多数虚假评论都停留在餐厅的一些表面上,评论不够深入,在生成的虚假评论中可以看出这两点;反之,生成的真实评论较为深入,且富含一些个人感情,符合数据集中真实评论的特征.

表6 随机选取的dcrGAN 模型生成的样例Tab.6 Randomly selected samples generated by dcrGAN model
4 结语
本文提出了一种融合强化学习的基于对抗生成网络的中文虚假评论数据生成模型.通过增加分类器和重构器,实现了生成通顺健壮的大规模批量的中文虚假评论数据.实验结果表明,本文模型文本生成达到较好效果,超过了神经网络基准模型,在一定程度上达到了扩充中文虚假评论数据集的目的.未来的工作中将进一步研究模型中各部分之间的交互,优化生成器奖励分数,以提高模型文本生成效果.
